一个基于信息熵的数据流自适应集成分类方法与流程
本发明属于数据挖掘与机器学习技术领域,涉及一种面向概念漂移环境的数据流集成分类方法,尤其提出了一种能够处理重现的概念的检测系统。实验结果表明所提出的方法在平均分类准确率上具有明显的优势,比其它集成算法消耗更少的时间,适合多种类型概念漂移的环境和具有较高的抗噪性。该系统可以应用于传感器网络异常检测、信用卡欺诈行为检测、天气预报和电价预测等众多实际应用问题中。
背景技术:
在现实世界的众多实际应用问题中,数据都是以流的形式不断产生的。这种快速到达的、实时的、连续的和无界的数据序列称为数据流(Data Streams)。在真实的数据流环境中,数据分布常常会随着时间而发生改变,这种现象反映数据流其本质可能具有不稳定。例如,天气预报所依据的规律可能会随着季节变化而发生改变;顾客网上购物偏好分析方法可能会随顾客群体的兴趣、商家信誉、服务类型等因素的变化而改变;工业用电量会随着季节交替出现周期性变化。一般地,把这种数据流中的数据分布随着时间以某种方式发生变化的现象称为概念漂移(Concept Drift)。具有因此,对于许多实际应用问题都需要我们研究与开发一种特定的面向数据流变化特征的学习机制,来快速的、实时的应对这些问题。
根据改变速度可以把概念漂移方式分为突变式(Abrupt Concept Drift)和渐变式(Gradual Concept Drift)。若在较短的时间内,数据流中数据分布突然地被另一个完全不同的数据分布所取代,则称此时数据流中发生了突变式概念漂移。此类型的漂移通常在毫无征兆的情况下发生(如传感器突然发生故障),会使准确率急剧下降甚至模型完全失效。而渐变式概念漂移则是一种慢速率改变(如传感器逐渐失灵),通常是经过较长一段时间后才能观察到,且概念漂移发生前后概念之间有或多或少的相似。而在现实环境中,数据流中概念重复出现是普遍存在的。重现式概念漂移(Recurring Concept Drift)是一种特殊类型的概念漂移,除了兼具上述两种漂移的特点外,某种概念会有规律或无规律的会重复出现,使得分类模型需要不断的进行重复训练以适应这种变化。例如一年四季的用电量数据会随着季节周期变化;社交网络中某一话题可能在固定的时间(如节日或选举)周期出现。
概念漂移是数据流挖掘中的挑战问题,近年来,针对概念漂移问题国内外学者作了大研究,主要分为基于实例选择,基于实例加权与集成学习三种方法。这些算法大多数只针对某一类型的概念漂移进行处理,并未充分考虑概念会重复出现的情况。对此类型概念漂移,要求模型能够使用历史数据,并且当重复概念发生时能够使用以往训练过的模型进行分类,从而避免重复训练。一个理想的分类模型应能增量式的学习并能适应多种类型的变化。因此,设计出能应对多种类的概念漂移的分类算法具有重要的研究意义。集成方法通过在不同时段数据来训练个体分类器来保留历史概念,因此是一种有效的处理概念漂移的方法。我们主要关注于如何构建面向数据分布规律随时间变化的数据流集成分类模型。
目前的概念漂移检测方法大多是根据模型的分类错误率来检测数据分布的变化,如文献“Learning with drift detection.”(Gama,J.,Medas,P.,and Castillo,G.,et al..Learning with drift detection.In:Proceedings of the 17th Brazilian Symposium on Artificial Intelligence.Berlin:Springer-Verlag,2004.pp.286-295.)提出的通过监控当前模型的错误率来检测变化的DDM算法(Drift Detection Method),但不能有效检测到渐变式概念漂移。随后,文献“Learning from time-changing data with adaptive windowing.”(Bifet,A.,and Gavalda,R..Learning from time-changing data with adaptive windowing.In:Apte,C.,Skillicorn,D.,and Liu,B.,et al.(eds.).Proceedings of the 7th SIAM International Conference on Data Mining(SDM 2007).Philadelphia,PA:SIAM,2007.pp.443-448.)提出了基于伯努利分布检测概念漂移方法EDDM(Early Drift Detection Method),在保证了能对突变式概念漂移的检测的同时,提高了算法对渐变概念漂移的检测效果。Nishida等提出STEPD算法,通过采集训练样本的分类准确率和对全部训练样本的分类准确率来检测概念漂移。Bifet等提出的自适应滑动窗口算法ADWIN(ADaptive WINdowing),通过比较不同子窗口之间的错误率的均值的差异来判断是否发生概念漂移。Ross等提出了ECDD(EWMA for Concept Drift Detection)算法,利用指数加权移动平均控制图(EWMA)来监控错误率,当错误率超过一定阈值,则说明发生概念漂移。
然而,以上算法大多并未考虑概念会重复出现的问题。早在1996年Widmer就提出了概念会重复出现的问题,直到最近几年才得到学术界的关注。Widmer等提出FLORA3算法,将历史的概念的描述保存起来,当的概念重现时,保存的分类器被重新激活。Nishida等提出了一种在线集成算法ACE(Adaptive Classifier Ensemble)来应对重复概念的出现。类似的方法有Ramamurthy等提出一个基于集成学习方法EB(Ensemble Building)。EB算法在数据块序列上构建一组全局的分类器,该方法不会删除历史分类器,而是有选择地从挑选全局分类器中的相关分类器。Katakis等一种采用聚类找到新概念的,基于概念表示模型。Yang等把概念看作为马尔可夫链中的状态,从概念变换的过程中学习概念转移的规律,并通过马尔科夫模型描述概念转换,选择一个与当前概念最相似的概念。Gama等采用了两层分类器的模型,第一层根据当前概念训练分类器,而其中第二层则是根据已有的概念创建分类器。当检测到概念漂移发生时,则重用第二层的分类器。等]提出了一个处理重复性概念漂移的通用框架RCD(Recurring Concept Drifts)通过多元非参数统计的方法来识别新旧概念是否来自同一分布。
技术实现要素:
技术问题:对于概念漂移,有两个问题亟待解决:一是如何快速准确的检测到概念漂移;二是检测到漂移后如何根据不同类型的变化来修正模型以适应这些变化。为此,本发明设计并实现了一种能应对多种概念变化的自适应集成分类方法及系统。主要贡献如下:
(1)针对第一个问题,提出了基于信息熵的概念漂移检测方法。从信息熵的角度出发,通过Jensen-Shannon散度来度量新旧窗口之间数据分布的距离,不仅能检测出概念漂移,且能有效地识别重复概念。
(2)针对第二个问题,设计了一种分类器池的机制,当检测到概念漂移后,若是新概念则加入分类器池中,若是重复概念则重用已有分类器。
(3)提出了一种可以同时检测概念漂移和利用重复概念的集成系统,并在人工合成和真实数据流上的实验,从分类准确率,运行时间以及抗噪性等多角度进行考察,验证提出方法的可行性和有效性。
技术方案:考虑到概念的重复性,识别历史概念的代价要比创建新的概念模型小的多,因此很有必要将数据流中历史概念的基本信息进行存储。采用分类器池来保存历史概念,每个分类器表示一个概念,当检测到重复概念出现时,快速调出相关信息进行处理,减少了不必要的重复训练。因此需要增加一个内部的概念检测方法来增加算法对概念漂移的适应性,提出的具有概念漂移检测机制的自适应集成分类算法(Ensemble with internal Change Detection,ECD)。只有当检测到有新概念时才重建新的分类器并放入分类器池中,防止重复概念出现导致的重复训练的问题,减少模型更新频率,提高模型实时分类能力和分类效果。本发明提出自适应集成算法方法,主要分两个阶段组成:概念检测阶段和集成分类阶段。
本发明提出了一个基于信息熵的数据流自适应集成分类方法。其具体步骤包括如下:
step1:初始化集成分类器及缓存区;
step2:逐个将实例移入到滑动窗口中;
step3:利用所提出的基于两个窗口的检测模型描述如下:用W1={xt+1,xt+2,...,xt+n}和W2={xt+n+1,....,xt+2n}分别表示t时刻两个连续的大小相等的窗口,W1表示参考窗口,W2表示当前窗口。用JSD(W1||W2)度量两个窗口之间分布的距离,当此值小于等于10-5(非常接近于零)时,表示两个窗口的数据分布相同,即发现重复概念;当大于10-5小于阈值τ时,认为两个窗口之间的分布无显著性差异,当大于阈值则表明此时有概念漂移发生。阈值采用bootstrap的方法计算得到。由于窗口每次向前滑动一个实例,因此能及时检测到突变式概念漂移。
step4:当检测到有概念漂移发生时,就与分类器池中的建立分类器的数据的分布进行比较,若是新概念则新建一个分类器加入到分类器池中,并把相应的数据放在缓存区;若是重复概念则重用已有分类器。分类器按照重复使用的频率从高到低排序,当分类器池中存放的分类器数达到最大值时,则替换最不经常使用的分类器。
step5:根据每个基分类器在最新窗口中实例的分类错误率,采用加权投票的方式对每个实例进行预测。
附图说明
图1 不同窗口大小的分类准确率比较。
图2 SEA数据集上分类准确率比较。
图3 Elist数据集上分类准确率比较。
具体实施方法
以下结合附图和实施例对本发明的技术方案作进一步描述。
(1)基于信息熵的概念检测算法
在信息论中,相对熵(Relative Entropy)又称Kullback-Leibler散度是衡量相同事件空间X里两个概率分布相对差距的测度。两个概率分布p(x)和q(x)的相对熵定义为:
然而,Kullback-Leibler散度不满足对称性,因此并不是严格的距离概念。Jensen-Shannon散度是一种基于Kullback-Leibler散度的距离度量,它解决了Kullback-Leibler散度的不对称性问题。信息论中的Jensen-Shannon散度能很好地表示两个数据分布之间的关系,因此本发明提出一种基于Jensen-Shannon散度的概念检测算法,通过比较两个相邻窗口中数据分布是否存在显著性差异来检测概念漂移。Jensen-Shannon散度的定义如公式(2)所示。
所提出的基于两个窗口的检测模型JSD(W1||W2)度量两个窗口之间分布的距离,当此值小于等于10-5(非常接近于零)时,表示两个窗口的数据分布相同,即发现重复概念;当大于10-5小于阈值τ时,认为两个窗口之间的分布无显著性差异,当大于阈值则表明此时有概念漂移发生。阈值采用bootstrap的方法计算得到。由于窗口每次向前滑动一个实例,因此能及时检测到突变式概念漂移。伪代码如算法1所示。
算法1 基于信息熵的概念检测算法
(2)基于信息熵的自适应集成分类系统
具体说来,用E={C1,C2,…,Ck}来表示由k个分类器组成的分类器池,同时每个分类器还附带变量用于记录该分类器被重复使用的次数,B={B1,B2,…,Bk}表示存储的相应的数据,C′表示建立的新分类器。采用滑动窗口模型来维护最新的数据,对于源源不断到达的实例(xi,yi),W1表示参考(旧)窗口,W2表示当前窗口。通过比较新旧两个窗口数据分布的距离来检测概念漂移,当检测到有概念漂移发生,就与分类器池中的建立分类器的数据的分布进行比较,若是新概念则新建一个分类器加入到分类器池中,并把相应的数据放在缓存区;若是重复概念则重用已有分类器。分类器按照重复使用的频率从高到低排序,当分类器池中存放的分类器数达到最大值时,则替换最不经常使用的分类器。接着根据每个基分类器Ci(i=1,2,...,k)在最新窗口中实例的分类错误率,按公式(4)对其进行加权,加权投票方式对每个实例进行预测。
Weight(Ci)=MSEr-MSEij (4)
其中,MSEr为随机预测分类器的均方差,MSEij为基分类器Ci在当前窗口上预测的均方差,表示在分类器Ci中预测属性值为xi的类值为yi的概率,p(yi)为yi的先验概率。在这种情况下,在分类器池中搜索代表当前的概念的分模型,减少在与学习相关的计算成本中一种新的模型,也提高了对概念漂移的适应。伪代码如算法2所示。
算法2 ECD算法伪代码
本发明的仿真结果
本系统是在CPU为2.8GHZ,内存为8GB,操作系统为Windows 7的PC机上进行实验的,实验选取3个人工合成数据集对所提出模型进行验证,如表1所示。
表1 人工合成数据集合基本信息
Table 1 Characteristic of synthetic datasets
用数据流生成器产生3种类型概念漂移:突变式、渐变式和重现式概念漂移。
HyperPlane是使用最广泛的数据流数据集,该数据集通过改变数据样本属性的权值来模拟概念漂移现象。实验中采用MOA中的数据流产生器HyperplaneGenerator生成实例改变概率为0.001的渐变式概念漂移数据集。
SEA是Street于2001年提出的,因仅含有连续型属性而著名,是经典的突变式概念漂移数据集。其基本结构是<f1,f2,f3,C>,其中f1、f2和f3为条件属性,C为类属性,仅f1,f2和C相关。当实例的属性满足f1+f2≤θ时,属于第一类,否则属于第二类。实验中首先采用数据流产生器生成包含3次突变的数据集,分别在250K,500K和750K处发生,然后采用能生成重复概念的数据流产生器生成包含3个重复概念的数据集。
Waveform数据集有3种基准波形(每一个基准波形由21个数值型属性组成),每一类别都是其中两种或3种的结合。实验中采用数据流产生器生成具有40个数值型属性波形数据流数据集,其中包括19个不相关属性。
Emailing list(简称Elist)是包含突发概念漂移和重复概念的数据集,而Spam filtering(简称Spam)则是包含渐变概念漂移的数据集,两个数据集都是以布尔型词袋模型表示。数据集均可在http://mlkd.csd.auth.gr/concept_driff.html下载,用MOA中的ArffFileStream产生器将静态的数据模拟产生数据流。
Elist模拟了连续不断的来自不同领域的各种邮件信息,用户可以根据兴趣把这些邮件标记成为垃圾或者感兴趣。共包括1500个实例和913个属性,数据被划分为5个阶段,通过用户的兴趣发生了变化来模拟概念漂移的出现。表2描述每个阶段中哪个类型的被认为感兴趣或者垃圾邮件,其中(+)表示感兴趣,(-)表示一个垃圾邮件。用C1表示用户只对医学之类的邮件感兴趣,C2表示用户对航空和棒球感兴趣,则此数据流表示C1,C2,C1,C2,C1概念序列。
表2 Emailing list数据集描述
Table 2.Characteristic of Emailing list dstaset
Spam包括9324个实例和500个属性,每个实例表示一个邮件的信息,被分为两种类型:垃圾邮件(仅占20%)和合法邮件。数据集中的垃圾邮件的特征随着时间缓慢变化。
实验采用Prequential评价策略,即每条实例先作为测试数据而后作为训练数据,这样准确率是增量更新的。采用这种评价策略不用扣留数据集来测试,从而保证最大化利用每个数据的信息,也保证准确率随时间具有平滑性。
在SEA数据集上进行测试,分别测试滑动窗口大小n取值为[500,2000],以此验证窗口大小设置对算法性能的影响。由图1可以看出,一开始,随着窗口的增大使得构建分类器的数据增多,分类准确率也随之上升。然而,随着窗口的继续增大,概念漂移发现滞后,同时,分类器的分类准确率达到了瓶颈,因而平均分类准确率略有降低。表3表明所提的方法受窗口大小设置影响很小,当窗口大小为1000时算法可以获得相对较高的分类准确率。
表3 不同窗口大小下的分类准确率
Table 3 accuracy using different window sizes
随后,所提算法与以下3个算法进行对比:Hoeffding Tree(简称HT)、RCD和Accuracy Update Ensemble(简称AUE)。其中,HT和AUE在MOA下实现,RCD可在https://sites.google.com/site/moaextensions/获取。为了便于比较,分类器池中分类器数k=15,所进行比较的集成分类算法的基分类器均采用Hoeffding Tree,叶子结点采用Adaptive Bayes预测类值,其中nmin=100,置信度δ=0.01,τ=0.05。分别从分类准确率和运行时间两个方面进行比较。
表4展示了算法在5个数据集上分类准确率情况。总体来看,集成算法获得比单分类器算法要高的分类准确率。HT算法在包含概念漂移的数据集上均表现最差,这是由于其没有任何处理概念漂移机制,因此不适合概念漂移环境。在没有概念漂移数据集Waveform上,由于数据分布相对比较稳定,所有算法差别并不大,所提出的算法并没有明显优势。而在渐变式数据集HyperPlane上,AUE获得了最高准确率,其次是所提出的算法。究其原因,是由于AUE算法不断在最新数据块上训练生成分类器,能及在应对渐变式概念漂移。而在包含重复概念的数据集SEA上,所提出算法获得了最高的准确率,这是由于增加了重复概念漂移检测机制,能及时建立新的分类器来适应突然的概念变化。在真实数据集Elist上,本发明提出算法表现最好。在Spam上表现最好的是RCD,其次是本发明所提出的算法。
在运行时间方面,如表5所示。通过比较分析发现,HT的运行时间最短,其次是本发明所提出的算法,而AUE时间消耗最长。这是由于本发明所提出的算法是一种基于数据分布的检测算法,可以快速的检测到概念漂移和识别重复概念,并且选择一个已有的模型,避免了重复训练,因此在时间上要有优势。单分类器算法HT虽然速度最快,但却在分类准确率上表现最差。
表4 不同算法分类准确率(%)
Table 4.Comparison of Classification Accuracy(%)
表5 不同算法运行时间(秒)
Table 5.Comparison of Time Consumption
在SEA数据集中发生了3次突变,从图2观察发现,所有算法变化趋势基本一致。最初阶段数据比较稳定,所有算法都保持了较高的、平稳的准确率,本发明所提出的算法并无明显优势。随着数据量的增大,概念漂移次数的增多,所以算法的分类准确率都有所下降,其中HT算法下降的比较严重,且波动较大。当在250K,500K和750K处发生概念突变时,所有算法的准确率都急剧下降,而本发明所提出的算法维持了较高的、平稳的准确率。本发明所提出的算法准确率的平均值上比HT算法高出20%左右。这是由于本发明所提出的算法能快速捕捉到概念变化,并建立新的分类器,从而及时应对这种变化。由于数据中添加了10%的噪音,也表明了本发明所提出的算法具有抗噪声能力。
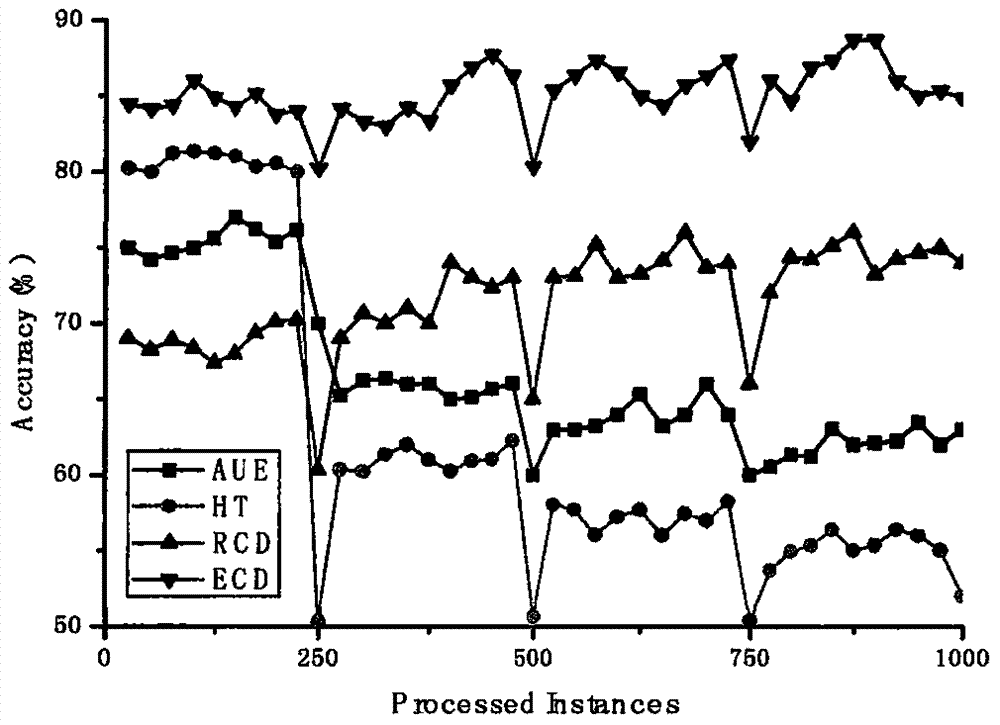
真实的数据流环境中概念变化具有不可预知性和不确定性,因此更能验证算法的泛化能力。在Elist上,准确率的变化情况如图3所示,所有算法的准确率曲线均出现不同程度的波动,这表明该数据集中存在概念漂移现象。而本发明所提出的算法的准确率曲线相对平稳,能充分利用历史分类器所拥有的知识来解决数据流概念漂移呈现周期性的问题。表明所提出方法受到数据中概念漂移影响最小,对真实的数据环境有较好的适应性。
通过实验对比分析,可得出以下结论:(1)算法在包含重复概念的数据集上具有明显优势;(2)在保持较高分准确率情况下,消耗相对较少的时间;(3)对噪声具有一定的健壮性。
- 还没有人留言评论。精彩留言会获得点赞!