一种台标识别方法及系统与流程
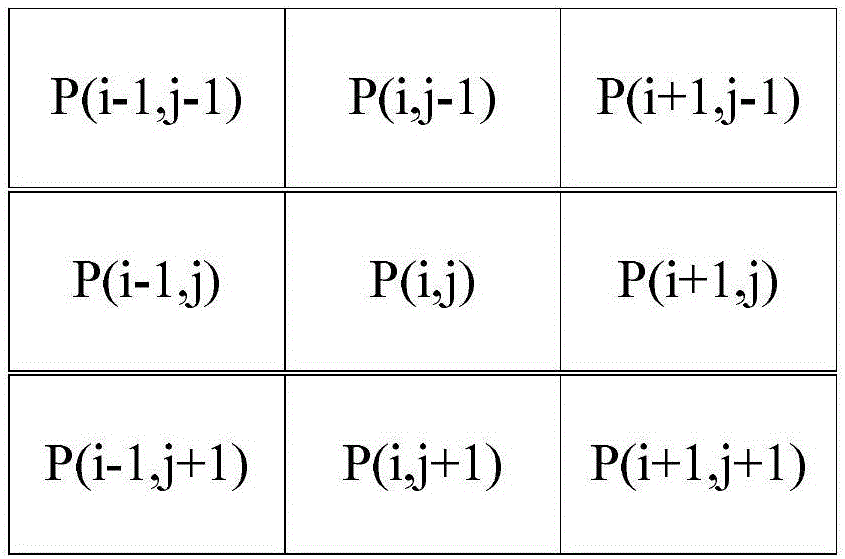
本发明涉及图像识别技术领域,尤其涉及一种台标识别方法及系统。
背景技术:
目前的台标采集方法中的原始图像是通过服务器进行实时采集,对原始图像进行图像处理形成模式库,当需要增加识别频道的列表数目时,由于某些地方频道仅在其所在区域范围内接收到,为了生成新的模式库,需要增加服务器来进行采集。因此现有技术中当识别频道的列表数目增加时,模式库也会相应增加,而终端所在区域范围接收频道数目小于模式库中识别频道的列表数目,导致进行特征匹配时间加长,延长台标识别结果,台标识别效率低。
因此,现有技术还有待于改进和发展。
技术实现要素:
鉴于现有技术的不足,本发明目的在于提供一种台标识别方法及系统。
本发明的技术方案如下:
一种台标识别方法,其中,方法包括步骤:
A、获取终端设备的所属区域,根据终端设备的所属区域加载区域模式库;
B、终端设备截取当前播放画面并进行特征提取得到特征数据;
C、将特征数据与区域模式库进行匹配,并判断匹配结果,若匹配成功,根据匹配结果获取台标识别结果;若匹配失败,则将截取的当前播放画面上传至云端,重新训练后生成所属区域新的区域模式库。
所述的台标识别方法,其中,所述步骤A之前还包括步骤:
S1、获取终端设备当前所在的区域,根据终端设备当前播放的视频画面截图后生成样本图像;
S2、对样本图像依次进行灰度化、二值化、字符分割处理后生成预处理图像;
S3、对预处理图像进行特征提取并进行字符识别后生成以区域命名的区域模式库。
所述的台标识别方法,其中,所述步骤S1具体包括步骤:
S11、获取当前终端设备所在的区域;
S12、获取终端设备当前播放的视频画面截图后,保存为样本图像文件;
S13、对样本图像文件进行高度和宽度处理后,提取包含台标图像的样本图像并保存。
所述的台标识别方法,其中,所述步骤S3具体包括步骤:
S31、对预处理图像中的英文字符、数字字符和汉字字符分别采用不同的特征提取方法后生成对应的待匹配特征向量;
S32、根据待匹配特征向量与现有台标特征向量进行匹配,获取各个待匹配特征向量与现有台标特征向量的加权距离,加权距离最小的对应的特征为待匹配向量的字符识别结果。
所述的台标识别方法,其中,所述步骤A具体包括:
A1、获取终端设备的所属区域,根据终端设备的所属区域加载本地存储的区域模式库;
A2、判断本地存储的区域模式库与云端模式库的版本是否相同,若不相同,则更新本地存储对应的区域模式库。
一种台标识别系统,其中,系统包括:
区域模式库获取模块,用于获取终端设备的所属区域,根据终端设备的所属区域加载区域模式库;
数据采集模块,用于终端设备截取当前播放画面并进行特征提取得到特征数据;
台标识别模块,用于将特征数据与区域模式库进行匹配,并判断匹配结果,若匹配成功,根据匹配结果获取台标识别结果;若匹配失败,则将截取的当前播放画面上传至云端,重新训练后生成所属区域新的区域模式库。
所述的台标识别系统,其中,所述系统还包括:
样本图像生成单元,用于获取终端设备当前所在的区域,根据终端设备当前播放的视频画面截图后生成样本图像;
图像处理单元对样本图像依次进行灰度化、二值化、字符分割处理后生成预处理图像;
区域模式库生成单元,用于对预处理图像进行特征提取并进行字符识别后生成以区域命名的区域模式库。
所述的台标识别系统,其中,所述样本图像生成单元具体包括:
区域获取单元,用于获取当前终端设备所在的区域;
图像获取与保存单元,用于获取终端设备当前播放的视频画面截图后,保存为样本图像文件;
样本图像提取单元,用于对样本图像文件进行高度和宽度处理后,提取包含台标图像的样本图像并保存。
所述的台标识别系统,其中,所述区域模式库生成单元具体包括:
特征提取单元,用于对预处理图像中的英文字符、数字字符和汉字字符分别采用不同的特征提取方法后生成对应的待匹配特征向量;
匹配与识别单元,用于根据待匹配特征向量与现有台标特征向量进行匹配,获取各个待匹配特征向量与现有台标特征向量的加权距离,加权距离最小的对应的特征为待匹配向量的字符识别结果。
所述的台标识别系统,其中,所述区域模式库获取模块具体包括:
本地区域模式库加载单元,用于获取终端设备的所属区域,根据终端设备的所属区域加载本地存储的区域模式库;
判断与更新单元,用于判断本地存储的区域模式库与云端模式库的版本是否相同,若不相同,则更新本地存储对应的区域模式库。
本发明提供了一种台标识别方法及系统,本发明中终端设备对播放识别列表中的电视画面时截图获取样本图像,减少专门设计采集地方台的服务器,进行台标识别时,根据区域加载不同的模板文件,减少特征匹配计算范围,加速台标识别。
附图说明
图1为本发明的一种台标识别方法的较佳实施例的流程图。
图2为本发明的一种台标识别方法具体实施例的流程图。
图3为本发明的一种台标识别方法具体实施例的字符坐标示意图。
图4为本发明的一种台标识别系统的较佳实施例的功能原理框图。
具体实施方式
为使本发明的目的、技术方案及效果更加清楚、明确,以下对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供了一种台标识别方法的较佳实施例的流程图,如图1所示,其中,方法包括:
步骤S100、获取终端设备的所属区域,根据终端设备的所属区域加载区域模式库。
具体实施时,本发明实施例中以Android系统为例进行介绍,其他系统也使用本发明的方法。在获取终端设备所在的区域信息后,根据终端设备所在的区域信息加载对应的区域模式库,其中区域一般为地级市或省级市。终端设备可以为智能电视、智能手机、智能平板等可以播放电视或网络电视的设备。
步骤S100具体包括:
步骤S101、获取终端设备的所属区域,根据终端设备的所属区域加载本地存储的区域模式库;
步骤S102、判断本地存储的区域模式库与云端模式库的版本是否相同,若不相同,则更新本地存储对应的区域模式库。
具体实施时,通过定位获取终端设备当前所在的区域,获取区域信息后,根据区域加载该区域模式库;比较本地和云端该区域模式库版本是否相同,如果不相同,更新本地该区域模式库,否则终端截图并特征提取,生成以区域命名的区域模式库。
进一步的实施例中,步骤S100之前还包括:
步骤S、预先对获取的终端设备的样本图像进行预处理后生成终端设备所属区域的区域模式库。
具体实施时,首先获取终端设备所在区域信息,对播放识别列表中的电视画面时,截取当前播放画面保存为图像文件,对该图像文件进行预处理,对预处理过的图像进行特征提取生成以区域命名的模式库。
进一步的实施例中,步骤S具体包括:
步骤S1、获取终端设备当前所在的区域,根据终端设备当前播放的视频画面截图后生成样本图像;
步骤S2、对样本图像依次进行灰度化、二值化、字符分割处理后生成预处理图像;
步骤S3、对预处理图像进行特征提取并进行字符识别后生成以区域命名的区域模式库。
具体实施时,通过定位获取终端设备的位置,从而获取智能设备所在区域,通过截屏接口获取当前的播放视频生成样本图像。
对样本图像一次进行图像灰度化去处图像中的无用信息后,进行图像二值化处理后将图像中感兴趣的目标与图像的背景进行分离后,再对图像进行字符分割,字符分割是将台标图像中的多个字符分割成多个单字符图像,目的是尽可能的去除字符边缘的背景信息,得到准确包含单个字符边缘的最小字符图像。
通过分割后的字符图像进行字符特征的提取,字符特征的提取就是从原始图像的大量信息中提取出最能凸显事物本质特征的少量信息作为字符识别的依据。根据提取后的字符特征与确定要识别的台标数和台标名进行计算,生成区域所用的模板库。
进一步的实施例中,步骤S1具体包括:
步骤S11、获取当前终端设备所在的区域;
步骤S12、获取终端设备当前播放的视频画面截图后,保存为样本图像文件;
步骤S13、对样本图像文件进行高度和宽度处理后,提取包含台标图像的样本图像并保存。
具体实施时,通过Android位置信息接口获取当前终端所在的区域信息,终端截图生成样本。通过判断当前电视画面是否是TVActivity画面,如果是通过Android截屏接口获取到当前播放视频画面,并保存为图片文件。通过Android图像处理接口对该保存图像进行宽度和高度处理,提取包含台标图像(其中包含台标LOGO和台标中字符)在内的图像并保存。
步骤S2中对生成的样本图像进行依次进行灰度化、二值化、字符分割处理后生成预处理图像。
图像灰度化的具体处理过程如下:
获取的图像一般是彩色图像,有必要对该图像进行灰度化处理。图像的灰度化是指通过某种方法将彩色图像转化为灰度图像。灰度图像只含有亮度信息而不包含色彩信息。图像灰度化的目的是为了除去图像中多数无用的色彩信息,从而改善图像的画面质量,使图像显示的效果更加简单清晰。RGB图像是图像处理经常使用的一种图像格式,RGB中,R是Red,代表图像像素颜色的红色分量,G是Green,代表图像像素颜色的绿色分量,B是Blue,代表图像像素颜色的蓝色分量,若R=G=B,则由这三个分量构成的颜色在视觉上呈现灰色,表示一种灰度颜色,其中R、G、B的数值被称作该图像的灰度值,在这里用g来表示。通常在一幅彩色图像中,往往会存储大量的颜色信息,图像的每个像素都具有不同的R、G、B分量,所以需要占据的存储空间很大,而这些颜色信息在后续的图像处理中并不都能起到多少作用,相反,颜色信息的差异往往会对图像分析的结果产生反作用,且进行处理时也会浪费很多的系统资源,降低系统的效率。
考虑到Android移动设备资源和处理能力有限,有必要先减少彩色RGB图像中的颜色信息,将彩色RGB图像转变为灰度图像,以节省设备的资源,提高设备处理效率。R、G、B各个分量的取值范围是0-255,因此灰度级别是256级。本文采用加权平均值法进行灰度化处理:根据实际情况对R、G、B赋予不同的权值WR、WG、WB,再取他们的加权平均值,即
其中,权值WR、WG、WB可以先设置初始值,可根据图像处理情况及时调整。
图像二值化的方法如下:图像二值化即将灰度图像中的各点原先的灰度值(例如0—255)置为最小0或最大255,只有这两个值,没有其他任何的中间值,从而将一副连续灰度变化的图像转换成一副黑白图像,只有黑(灰度值为0)或白(灰度值为255)。图像二值化的目的是将图像中感兴趣的目标与图像的背景进行分离,以方便后续的特征提取。经过二值化处理后的图像,边缘轮廓特别清楚,可以达到突出目标、淡化背景的作用。图像二值化的基本思想是先确定一个阈值,然后将所有像素的灰度值与这个值进行比较。若灰度大于等于阈值,则将原灰度值用255替换;反之,若灰度小于阈值,则将灰度值改为0。其中,阈值可以先设初始值,并根据图像处理情况进行再次调整。图像二值化处理使得图像中的背景和目标具有比灰度图更大的对比度,同时图像的数据量也比灰度图少,这样不仅能提高图像处理的效率,也能有效突出感兴趣目标的边缘轮廓及其大小和位置,为进一步的图像分析和处理作好基础。
字符分割的具体实施方式如下:如上所述,在处理后的二值化台标图像中,通常像素值为255的是白色点,即图像背景,像素值为0的是黑色点,代表字符,如果某行或某列都是背景的话,那么该行或者列的投影一定是白色,由于字符间都存在间隔,因此字符与字符之间的间隔的投影也都是白色,根据这个规律,台标图像中的字符与字符之间可进行分离。
字符分割是将台标图像中的多个字符分割成多个单字符图像,目的是尽可能的去除字符边缘的背景信息,得到准确包含单个字符边缘的最小字符图像。在本文中,采用基于投影法的字符分割技术对台标图像中的字符进行字符分割。
投影法就是数字图像在某一个方向上进行像素累加,投影法应用到字符分割时通常有水平方向和垂直方向上的投影。二值化的字符图像在水平方向上的像素分布图中行与行之间有较大的空隙,这可以作为行切分的标准。行切分之后可以利用垂直投影进行字切分,原理相同。
考虑部分台标图像中包含两行字符,因此本文釆用基于二维投影法(垂直投影和水平投影)的字符分割方法对字符进行精确分割。具体方法分为两步即两次切分,第一次切分是水平投影,确定台标图像中的字符行数,第二次是对第一次的切分结果即每一行进行字符切割,获取到该行中每一个字符。
具体过程如下:
第一次切分是对台标图像作水平投影,实现步骤如下:
(l)对灰度图像进行水平投影,统计每一行的像素灰度值之和,将结果存放在数组CountHorizontal[jHorizontal]中,其中jHorizontal表示图像的行。设widthHorizontal为图像的宽度,THorizontal为判断某一行是否是字符区域的阈值,THorizontal可设置初始值,并根据分割情况调整。StartHorizontal为单行字符区域的开始位置;EndHorizontal为单行字符区域的结束位置;CharacterHorizontal[NHorizontal]用于表示行数。初始化时jHorizontal=0,StartHorizontal=0,EndHorizontal=0,NHorizontal=0。
(2)jHorizontal++,若jHorizontal<widthHorizontal,则转至(3)继续执行;若jHorizontal≥widthHorizontal,则退出循环。
(3)若第jHorizontal行的像素灰度值之和满足CountHorizontal[jHorizontal]≤THorizontal,则表明此行为背景,转至(4);反之表明此行是字符区域,转至(5)。
(4)若StartHorizontal=0,表明此行不是字符区域,转至(2);若StartHorizontal≠0,表明此行为背景与字符区域的分界处,则EndHorizontal=jHorizontal-1,若EndHorizontal≠StartHorizontal转至(6),否则退出循环。
(5)若StartHorizontal=0,表明此行为字符区域的开始位置,则StartHorizontal=jHorizontal,转至(2);若StartHorizontal≠0,表明此行仍在字符区域内,转至(2)。
(6)NHorizontal++,记录第NHorizontal行。并更新开始位置StartHorizontal=EndHorizontal+NHorizontal*THorizontal。
当退出循环时候,NHorizontal即是总行数。
第二次切分是垂直投影,实现步骤如下:
(l)对上述水平投影的每一行进行垂直投影,统计每一列的像素灰度值之和,将结果存放在数组CountVertical[jVertical]中,其中jVertical表示图像的列。设widthVertical为图像的宽度。TVertical为判断某一列是否是字符区域的阈值,TVertical可设置初始值,并根据分割情况调整。StartVertical为单个字符区域的开始位置;EndVertical为单个字符区域的结束位置;MapCharacterVertical<NVertical,Map<StartVertical,EndVertical>>用于表示字符个数与其起始坐标、结束坐标对应关系,其中NVertical是第几个字符,而StartPot和EndPot分别是该字符的起始坐标与结束坐标。初始化时jVertical=0,StartVertical=0,EndVertical=0,NVertical=0。
(2)jVertical++,若jVertical<widthVertical,则转至(3)继续执行;若jVertical≥widthVertical,则退出循环。
(3)若第jVertical列的像素灰度值之和满足CountVertical[jVertical]≤TVertical,则表明此列为背景,转至(4);反之表明此列是字符区域,转至(5)。
(4)若StartVertical=0,表明此列不是字符区域,转至(2);若StartVertical≠0,表明此列为背景与字符区域的分界处,则EndVertical=jVertical-1,若EndVertical≠StartVertial转至(6),否则退出循环。
(5)若StartVertical=0,表明此列为字符区域的开始位置,则StartVertical=jVertical,转至(2);若StartVertical≠0,表明此列仍在字符区域内,转至(2)。
(6)NVertical++,记录第NVertical个字符以及其开始坐标StartPot和结束坐标EndPot,并更新开始位置StartVertical=EndVertical+NVertical*TVertical。
当退出循环时,MapCharacterVertical<NVertical,Map<StartVertical,EndVertical>>的大小就是每行字符总数,并且根据MapCharacterVertical<NVertical,Map<StartVertical,EndVertical>>get(i)可获取到第i个字符与其开始坐标和结束坐标。
进一步的实施例中,步骤S3具体包括:
步骤S31、对预处理图像中的英文字符、数字字符和汉字字符分别采用不同的特征提取方法后生成对应的待匹配特征向量;
步骤S32、根据待匹配特征向量与现有台标特征向量进行匹配,获取各个待匹配特征向量与现有台标特征向量的加权距离,加权距离最小的对应的特征为待匹配向量的字符识别结果。
具体实施时,步骤S31中字符特征的提取就是从原始图像的大量信息中提取出最能凸显事物本质特征的少量信息作为字符识别的依据。在字符识别系统中,特征提取是影响字符识别率高低的决定性因素。本提案针对台标图像中字符的特性,包含英文字符、数字字符以及汉字字符的特点,分别采用不同的特征提取方法。具体如下:
数字和英文字符特征提取方法:数字和英文字符进行网格特征提取,方法主要是将图像平均分成n等份,把网格内黑像素数所占的比例作为特征。具体提取步骤如下:
(1)首先将字符图像横竖平分成n个网格,举例如4个网格,记为{a1,a2,a3,a4},统计各网格内黑色像素点的个数,形成一个4维的向量。
(2)其次在垂直方向平分成w个网格,举例如4个网格,记为{a5,a6,a7,a8},分别统计各网格内黑色像素点个数,也形成一个4维向量。
(3)同理在水平方向平分成h个网格,举例如4个网格,记为{a9,a10,a11,a12},分别统计各网格内黑色像素点个数,也形成一个4维向量。
(4)根据上述方法,统计每个字符的n+w+h维,如上述12维像素点个数,保存到模板特征库中。其中,n、w、h可根据提取的特征值情况进行再次调整。
汉字特征提取方法为:汉字的笔画种类虽然繁多,但总结起来基本的笔画只有四种:横、竖、撇、捺,其它复杂的笔画都是由这四种基本笔画组合而成的。对二值化的图像按照四种笔画成分进行标记,通过把属于不同笔画成分的像素点归纳为不同的集合,可以标记出汉字的四种笔画,然后记录每种笔画集合的像素点个数可以得到汉字的笔画的四个向量参数。
综上,汉字除了提取网格特征,还提取横、竖、撇、捺特征,在匹配识别时候,先匹配网格n+w+h个区域(比如上述12维)的特征,再匹配横、竖、撇、捺的特征。
设P为二值化的图像,P(i,j)为图像中的一个像素点,坐标原点位于图像的左上角,其中i为横坐标,j为纵坐标,如图2所示。采用H表示横笔画像素点的集合。当前像素点为P(i,j),若P(i,j)=1,且P(i-1,j)=1或P(i+1,j)=1,则P(i,j)∈H。采用V表示竖笔画像素点的集合。当前像素点为P(i,j),若P(i,j)=1,且P(i,j-1)=1或P(i,j+1)=1,则P(i,j)∈V。采用P表示撇笔画像素点的集合。当前像素点为P(i,j),若P(i,j)=1,且P(i+1,j-1)=1或P(i-1,j+1)=1,则P(i,j)∈P。采用N表示捺笔画像素点的集合。当前像素点为P(i,j),若P(i,j)=1,且P(i-1,j-1)=1或P(i+1,j+1)=1,则P(i,j)∈N。
采用CountH表示某一文字图像中横笔画的像素点个数,CountV表示某一文字图像中竖笔画的像素点的个数,CountP表示某一文字图像中撇笔画的像素点的个数,CountN表示某一文字图像中捺笔画的像素点的个数。
定义了上述集合之后,按照从上至下、从左至右的顺序扫描汉字图像P,扫描之后就可以确定某个像素点隶属于哪一种笔画或哪几种笔画,分别记录四种笔画的像素点个数,从而得到一个四维的特征向量{CountH,CountV,CountP,CountN},加上上述n+w+h维网格特征,新特征值就代表了一个汉字的特征。
步骤S32中字符识别具体为:台标图像中字符特征为n(举例如{a1,a2,a3,a4})、w(举例如{a5,a6,a7,a8})、h(举例如{a9,a10,a11,a12})、{CountH,CountV,CountP,CountN},由于当前需要识别的台标数和台标名称是确定的,将上述n+w+h和{CountH,CountV,CountP,CountN},举例如16个特征作为待识别字符的特征量,通过计算台标列表中的每一个台标名称中字符的特征,形成该区域所用的模板库,以区域命名,区域信息可通过上述步骤1获取。
根据上述提取出的网格特征与汉字特征,求出各个模板特征向量的加权距离,加权距离最小的即为识别结果,进行字符识别。字符识别具体步骤如下:
1.如前所述计算字符模板网格特征一样,将待识别字符图像也分为n+w+h(举例如12)个区域。
2.如前所述计算汉字特征一样,计算待识别字符图像的横、竖、撇、捺特征。
3.将上述计算的待识别字符的n+w+h和{CountH,CountV,CountP,CountN}特征与模块的n+w+h和{CountH,CountV,CountP,CountN}进行模板匹配,求匹配差异度。举例如待识别字符与模板的{a1,a2,a3,a4}、{a5,a6,a7,a8}、{a9,a10,a11,a12}、{CountH,CountV,CountP,CountN}维特征值进行匹配。
4.对差异度求和。
5.依次提取模板的n+w+h和{CountH,CountV,CountP,CountN}(举例如16)区域与待识别字符图像相应区域进行匹配,计算各个模板与待识别字符的累加差异度,取累加差异度最小的,所对应的模板即为识别结果。
步骤S200、终端设备截取当前播放画面并进行特征提取得到特征数据。
具体实施时,终端设备要识别当前播放画面数据时,通过截图获取画面后,进行特征提取,提取与台标相关的数据。具体的采集当前播放画面数据和特征提取方法具体见以上实施例中生成区域模式库的方法所述。
步骤S300、将特征数据与区域模式库进行匹配,并判断匹配结果,若匹配成功,根据匹配结果获取台标识别结果;若匹配失败,则将截取的当前播放画面上传至云端,重新训练后生成所属区域新的区域模式库。
具体实施时,将提取的要识别的台标对应的特征数据与区域模式库中的第二特征数据进行匹配,若匹配到对应结果则获取台标识别结果;若匹配不到对应结果,则将终端设备截图获取的待识别图标文件上传,重新训练以生成新的区域模式库供识别台标图像。
本发明提供了一种台标识别方法具体实施例的流程图,如图3所示,具体流程如下:
步骤S10、开始;
步骤S20、获取区域信息;
步骤S30、根据区域加载该区域模式库;
步骤S40、比较本地和云端该区域模式库版本是否相同,如果不相同,执行步骤S60,否则执行步骤S50;
步骤S50、更新本地模式库;
步骤S60、终端截图并特征提取;
步骤S70、截图文件特征值与该区别模式库特征是否匹配,如果匹配,执行步骤S70,否则执行步骤S80;
步骤S80、获取到台标识别结果;
步骤S90、截图文件上传;
步骤S91、重新训练以生成新的该区域模式库;
步骤S92、结束。
由以上实施例可知,本发明提供了一种台标识别方法,通过获取终端设备所在区域信息,对播放识别列表中的电视画面时,截取当前播放画面保存为图像文件,对该图像文件进行预处理,对预处理过的图像进行特征提取生成以区域命名的模式库。进行台标识别时,根据区域加载该区域模式库,并比较本地和云端该区域模式库版本是否相同,如果不相同,更新本地该区域模式库。然后终端对播放识别列表中的电视画面时截图,进行图像预处理并特征提取,最后检查截图文件特征值与该区域模式库特征是否匹配,如果匹配,获取到台标识别结果,否则截图文件上传并重新训练以生成新的该区域模式库。
采用上述方法,终端对播放识别列表中的电视画面时截图获取样本图像,减少专门设计采集地方台的服务器。进行台标识别时,根据区域加载不同的模板文件,减少特征匹配计算范围,加速台标识别。
本发明还提供了一种台标识别系统的较佳实施例的功能原理框图,如图4所示,系统包括:
区域模式库获取模块100,用于获取终端设备的所属区域,根据终端设备的所属区域加载区域模式库;具体如方法实施例所示。
数据采集模块200,用于终端设备截取当前播放画面并进行特征提取得到特征数据;具体如方法实施例所示。
台标识别模块300,用于将特征数据与区域模式库进行匹配,并判断匹配结果,若匹配成功,根据匹配结果获取台标识别结果;若匹配失败,则将截取的当前播放画面上传至云端,重新训练后生成所属区域新的区域模式库;具体如方法实施例所示。
所述的台标识别系统,其中,所述系统还包括:
样本图像生成单元,用于获取终端设备当前所在的区域,根据终端设备当前播放的视频画面截图后生成样本图像;具体如方法实施例所示。
图像处理单元对样本图像依次进行灰度化、二值化、字符分割处理后生成预处理图像;具体如方法实施例所示。
区域模式库生成单元,用于对预处理图像进行特征提取并进行字符识别后生成以区域命名的区域模式库;具体如方法实施例所示。
所述的台标识别系统,其中,所述样本图像生成单元具体包括:
区域获取单元,用于获取当前终端设备所在的区域;具体如方法实施例所示。
图像获取与保存单元,用于获取终端设备当前播放的视频画面截图后,保存为样本图像文件;具体如方法实施例所示。
样本图像提取单元,用于对样本图像文件进行高度和宽度处理后,提取包含台标图像的样本图像并保存;具体如方法实施例所示。
所述的台标识别系统,其中,所述区域模式库生成单元具体包括:
特征提取单元,用于对预处理图像中的英文字符、数字字符和汉字字符分别采用不同的特征提取方法后生成对应的待匹配特征向量;具体如方法实施例所示。
匹配与识别单元,用于根据待匹配特征向量与现有台标特征向量进行匹配,获取各个待匹配特征向量与现有台标特征向量的加权距离,加权距离最小的对应的特征为待匹配向量的字符识别结果;具体如方法实施例所示。
所述的台标识别系统,其中,所述区域模式库获取模块具体包括:
本地区域模式库加载单元,用于获取终端设备的所属区域,根据终端设备的所属区域加载本地存储的区域模式库;具体如方法实施例所示。
判断与更新单元,用于判断本地存储的区域模式库与云端模式库的版本是否相同,若不相同,则更新本地存储对应的区域模式库;具体如方法实施例所示。
综上所述,本发明提供了一种台标识别方法及系统,方法包括:获取终端设备的所属区域,根据终端设备的所属区域加载区域模式库;终端设备截取当前播放画面并进行特征提取得到特征数据;将特征数据与区域模式库进行匹配,并判断匹配结果,若匹配成功,根据匹配结果获取台标识别结果;若匹配失败,则将截取的当前播放画面上传至云端,重新训练后生成所属区域新的区域模式库。本发明中终端设备对播放识别列表中的电视画面时截图获取样本图像,减少专门设计采集地方台的服务器,进行台标识别时,根据区域加载不同的模板文件,减少特征匹配计算范围,加速台标识别。
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!