一种个性化消息推荐方法与流程
本发明属于互联网技术领域,尤其涉及一种个性化消息推荐方法。
背景技术:
随着网络技术的快速发展,互联网思想已经遍及生活的各个方面。世界之大,每天都发生着各种各样的事情,随之而带来的庞大信息量超出的想象。面对信息过载的现状,如何能够使用户通过某种高效快速的方法阅读到自己需要的消息是非常重要的。个性化消息推荐服务是对用户平时浏览消息的兴趣喜好变化和操作行为进行分析和预测,最终向用户推荐对其有用的消息资讯,从而使用户不需要做大量无用功。个性化消息推荐技术是个性化推荐领域的延伸应用之一,针对消息的个性化服务推荐系统应该注意以下几点:(1)因为消息时效性特别强,随时都在发生,生命周期比较短,所以在进行个性化消息推荐时,应当注重推荐当前消息给用户,而不是过时的消息;(2)由于用户的浏览兴趣并不是永久的,是跟随社会流行和热点话题变化而变化,所以在进行消息推荐时需要考虑到用户的兴趣偏好变化;(3)在进行个性化新闻推荐时需要注意用户的具体情况(时间、地点等),此外还需注意不同消息之间是否存在一定的关系等等。消息推荐算法是消息推荐系统最重要的部分,基本上决定了消息推荐系统的准确性、性能的优劣以及能否持续运行等等。消息推荐算法的探索一直是整个消息推荐中最为重要和繁荣的一个部分。推荐系统学术界一直致力于这方面的研究并总结了大量的本发明和文章。目前,主流的推荐方法可以分为:基于内容的推荐算法、基于用户的协同过滤的推荐算法,基于知识模型的推荐算法以及混合推荐算法。基于内容的推荐算法是协同过滤的延续和发展,其通过对用户历史行为进行挖掘与分析获得用户的兴趣,并向用户推荐在内容上与其兴趣比较匹配的消息;算法的核心在于对推荐对象内容特征的挖掘,以及用户基于内容的兴趣模型的建立。随着人工智能等技术的发展完善,当今的基于内容的推荐系统可以分别对用户和消息建立配置文件,通过分析已经购买或浏览过的消息内容,建立或更新用户的配置文件。系统可以比较用户与消息配置文件之间的相似度,并直接向用户推荐与其配置文件最相似的消息。基于内容的推荐算法的根本在于内容的获取和定量分析,又因为在文本信息获取与过滤方面的研究较为成熟,因此,现有很多基于内容的推荐系统都是通过分析消息的文本信息进行推荐。传统的TF-IDF公式:其中,wik表示文档i中第k维向量值,tfij表示文档i中第k个特征项的TF值,max{tfik}表示文档i中所有特征项中TF的最大值,N表示文本集的文档数,nk表示文本集中出现该特征项的文本数。虽然基于内容的推荐能够准确地捕捉用户的兴趣,进而能够为用户推荐新出现的消息和非热门的消息,但是基于内容的推荐方法有以下不足:(1)多媒体数据提取内容特征在技术上还不完善,描述文本消息通常不够充分,很难体现内容上的完整性;(2)无法挖掘用户对推荐内容的真实态度;(3)基于内容推荐的实质,其仅仅能够为用户推荐内容相似的消息。基于协同过滤的算法是推荐系统中最基本的算法,在业界得到了广泛应用。基于协同过滤的算法分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法。本发明采用基于用户的协同过滤算法,基于用户的协同过滤算法的思想就是在对目标用户进行推荐时,首先找到与用户兴趣相似的其他用户,然后把那些用户喜欢的且目标用户没有使用过的物品推荐给目标用户。基于用户的协同过滤能够根据用户的历史行为隐式地获得用户的兴趣,同时也能通过发现相似用户的方式发现用户历史行为外的信息,进而找到用户的潜在兴趣。不同于基于内容的推荐方法,基于用户的协同过滤方法能够推荐难以进行内容分析的,非结构化的信息,如视频、音频及图片等。但是,基于用户的协同过滤算法仍然面临着以下挑战;(1)冷启动问题,新的消息的点击率较少,无法获得推荐;(2)协同过滤算法随着用户量的增加,需要维护一个较大的用户相似矩阵,所以在性能上无法得到保障。基于知识的推荐在一定程度能够被看种一种推理技术。该技术的最显著特征是其并非从用户偏好的角度出发,而是针对特定领域建立规则,通过基于规则和实例的推理,实现对用户的推荐。该方法建立方法知识库,描述一个对象如何满足某一特定用户,知识库使用本体语言以实现机器可读,参考和推理都基于知识库进行。这种基于知识的推荐方法在某些特定领域取得了较好的效果,但其缺点也非常明显,即知识的获取和本体库的建立,而针对特定领域的推荐这一特点,既是其优势,也成为了该方法最主要的限制,该方法能够对某个领域内的信息进行深度挖掘并实现准确率和覆盖率都很高的推荐,但是其可扩展性和可移植性较差,需要耗费大量的开发成本,不适应开发性的平台应用。
综上所述,现有的消息推荐方法存在描述文本消息通常不够充分,很难体现内容上的完整性;无法挖掘用户对推荐内容的真实态度;仅仅能够为用户推荐内容相似的消息;新的消息的点击率较少,无法获得推荐。
技术实现要素:
本发明的目的在于提供一种个性化消息推荐方法,旨在解决现有的消息推荐方法存在描述文本消息通常不够充分,很难体现内容上的完整性;无法挖掘用户对推荐内容的真实态度;仅仅能够为用户推荐内容相似的消息;新的消息的点击率较少,无法获得推荐的问题。
本发明是这样实现的,一种个性化消息推荐方法——组合推荐(CR)算法,所述个性化消息的推荐方法根据消息的发布时间,决定该消息由哪一类算法产生推荐。当浏览时间与当前时间的间隔不大于某个值(其值由实验确定)时,采用基于内容推荐和基于用户的协同过滤推荐的混合推荐算法:(1)对历史数据按照用户浏览日期进行降序排序处理;(2)通过中文分词方法以及加入时间因子,生成用户特征配置文件和在添加截取因子的基础上生成用户当前兴趣配置文件;(3)通过生成目标用户当前兴趣配置文件的新闻与生成其他用户的用户特征配置文件的文件进行相似度计算(相似度包括内容相似度和行为相似度),获得目标用户的相似用户集,然后生成目标用户的潜在配置文件;(4)混合用户的当前兴趣配置文件和用户的潜在配置文件生成用户混合配置文件。否则,直接采用基于用户的协同过滤推荐算法:在产生目标用户潜在配置文件的相似用户集中,若某个消息被里面的某个用户数超过某个阈值(这个由系统确定)且该消息没有被目标用户浏览,则该消息被推荐给目标用户。
进一步,所述个性化消息推荐方法包括以下步骤:
现存用户配置文件,在进行消息推荐时需要考虑到用户的兴趣偏好变化,采用截取因子、时间因子以及对用户的历史数据进行处理;
利用同时考虑行为相似和内容相似的基于用户的协同过滤方法来寻找目标用户的相似用户和潜在兴趣;
用户混合配置文件UBF能够在获得目标用户的用户当前兴趣配置文件UCF和潜在用户配置文件UMF后,通过对UCF,UMF上的每个主要特征词加权得到;
推荐结果的生成,在推荐列表中,消息由两部分组成:l1,l2;l1部分有混合配置文件生成;即通过添加时间因子ε1来限定消息是否采用混合推荐方法—看消息的发布时间与当前时间的时间间隔是否小于ε1,若满足则该文件采用混合推荐方法,否则将不采用。
进一步,所述现存用户配置文件具体包括:
(1)向量空间模型,给定消息集F=(f1,f2,…fi,…,fn)和主要特征词序列K=(k1,k2,…ki,…,kl),fi能够被表示为向量空间模型(VSM)fi=(wi1,wi2,…,wil),其中wij表示特征词kj在新闻fi中的权重;wij=0表示kj不在fi中出现;利用TF-IDF方法来对文本信息进行处理。计算wij的公式如下:
wij=tf(i,j)×log[1+n/n(j)]/maxOther(i,j);
其中n(j)表示出现kj的新闻的数量,tf(i,j)是出现在fi中的kj的数目,maxOther(i,j)是出现在fi的其他特征词的最大数目;新闻集F表示成一个权重矩阵。
(2)用户现存配置文件,时间因子以及用户当前兴趣配置文件,在处理文本信息时对各个用户浏览的消息的浏览时间进行升序排序,然后生成现存用户配置文件UCF;文件选取最后浏览的s个消息用于生成用户u的当前兴趣配置文件UCFus;用户u按浏览时间降序排列的消息集表示为:所以最新浏览的s个消息集合为Fus={fu1,fu2,…,fus},ti是用户u阅读消息fui的时间;时间因子能够被定义为:
α是时间衰减参数,通过实验确定;Fu,Fus是F的子集;Fu,Fus表示为一个权重矩阵,获得用户u的现存配置文件UCF和当前兴趣配置文件UCFus的过程。
进一步,所述利用同时考虑行为相似和内容相似的基于用户的协同过滤方法来寻找目标用户的相似用户和潜在兴趣包括:
(1)混合相似性的计算,给定新闻集Fus和Fv,用户u的当前兴趣文件用户v的当前配置文件UCFv=(wcv1,wcv2,...,wcvl);则用户u与用户v的行为相似和内容相似的计算下:
simCon(u,v)=(CUFus·CUFv)/(CUFus×CUFv);
混合相似计算公式如下:
sim(u,v)=β×simAct(u,v)+(1-β)×simCon(u,v)。
(2)潜在用户配置文件和相似用户文件的生成,选择相似性最大的u个用户构造相似用户文件,通过加权计算获得目标用户u的潜在用户配置文件UMF;给定相似用户集Uu={v1,v2,…,vh},用户vi的UCFvi=(wcvi1,wcvi2,…,wcvil),用户u和用户vi的相似性为sim(u,vi),利用下式计算在MUFu中的kj的权重:
进一步,目标用户u的当前兴趣配置文件UCFus,潜在兴趣配置文件UMFu=(wmu1,wmu2,...,wmul),混合配置文件UBFu=(wbu1,wbu2,...,wbul),利用下式计算wbuj:
wbuj=γwcuj+(1-γ)wmuj。
进一步,所述推荐结果的生成具体包括:
目标用户u的混合配置文件BUFu=(wbu1,wbu2,...,wbul),新闻d0=(wd1,wd2,...,wdl),新闻d0的发布时间为t0,当前时间tcur,阈值ε1,ε2,首先检查:
tcur-t0≤ε1;
若不等式成立,则检查:
d0·BUFu≥ε2;
若成立,则将新闻d0放入l1中;
l2部分直接由基于内容相似和行为相似的协同过滤算法生成包括:
用户u的相似用户集Uu={v1,v2,…,vh},用户u和用户vi的相似性为sim(u,vi),对于消息d0,设其在用户u的相似用户集上的权重为则消息d0的相对于用户u的权重为:
选出相对于用户u的权重较大的消息放入l2部分。
本发明的另一目的在于提供一种应用所述个性化消息推荐方法的个性化服务推荐系统。
本发明提供的个性化消息推荐方法,基于内容的推荐能够准确地挖掘和描述消息和用户的特征,对于消息这种特殊的推荐对象,基于内容的推荐能够获得更高的准确性;消息具有时效性和热门性,基于内容的推荐没有新消息的冷启动问题,同时不会受消息热门程度的影响,而是直接对新闻内容进行挖掘;由于用户的兴趣随着时间的变化快速变化,结合基于用户的协同过滤的推荐结果,能够获得更全面的新闻推荐结果。本发明针对组合推荐算法设计了实验并分析了实验结果,使用F值、召回率(recall)和准确率(precision)和多样性Diversity指标衡量推荐算法性能。由此实验可知,组合推荐算法(CR)的F值、召回率和准确率高于其它算法,说明在相同的推荐列表长度下,组合推荐算法(CR)的推荐效果更好。在多样性方面虽然没有不是最优,但是比混合推荐算法(HR)、基于内容的推荐算法(CB)。实验结果符合算法设计初衷,验证了组合推荐算法与同类算法相比具有一定的优越性。
附图说明
图1是本发明实施例提供的个性化消息推荐方法流程图。
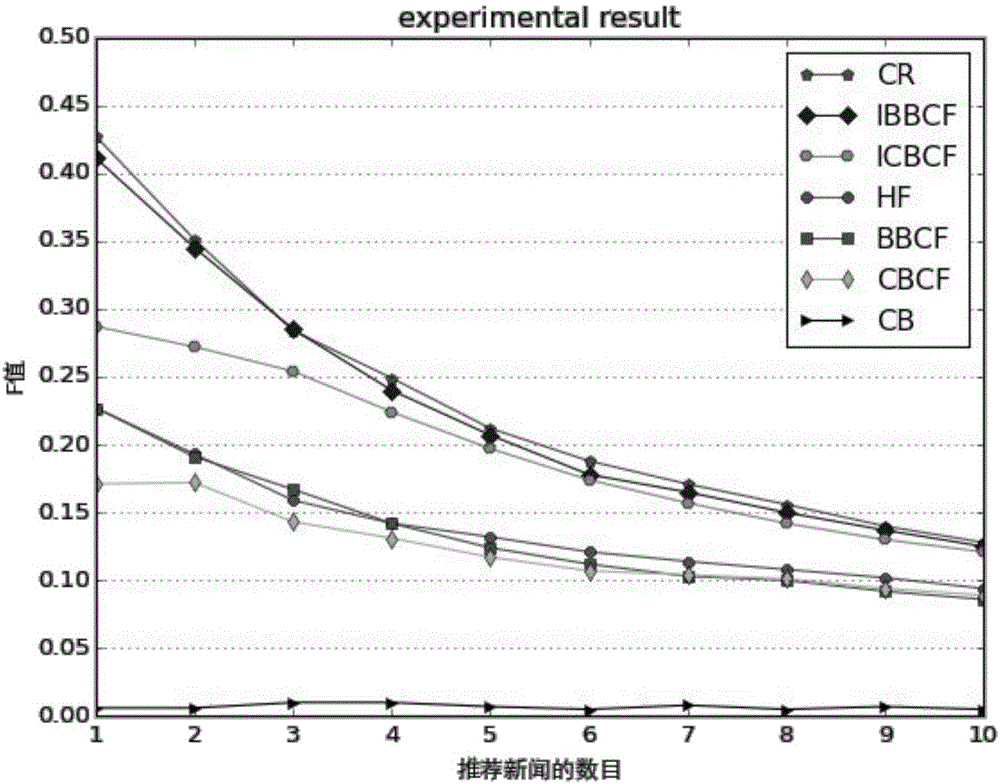
图2是本发明实施例提供的F值比较示意图。
图3是本发明实施例提供的回召率比较示意图。
图4是本发明实施例提供的精确度比较示意图。
图5是本发明实施例提供的多样性比较示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
如图1所示,本发明实施例提供的个性化消息推荐方法包括以下步骤:
S101:根据消息的发布时间,决定该消息由哪类算法产生推荐;
S102:当浏览时间与当前时间的间隔不大于某个值时,采用基于内容推荐和基于用户的协同过滤推荐的混合推荐算法;否则,直接采用基于用户的协同过滤算法。
下面结合具体实施例对本发明的应用原理作进一步的描述。
1个性化推荐方法
1.1问题定义
定义1主要特征词:设消息集F=(f1,f2,…,fn),把表示消息内容的词称为主要特征词,把有序序列K=(k1,k2,…ki,…,kl)称为主要特征词序列,其中k1,k2,…,kl表示主要特征词,l表示主要特征词的数目。
定义2用户现存配置文件:对于任何用户,把其阅读过的消息生成的文件称为用户现存配置文件,并将用户现存配置文件表示成向量形式UCF=(wc1,…,wci,…,wcl),其中wci表示在用户现存配置文件中主要特征词ki的权重。
定义3用户当前兴趣配置文件:对于用户u,把其最新阅读过的s个消息生成的文件称为用户u的当前兴趣配置文件,并将用户u的当前兴趣配置文件表示为其中表示在用户u的当前兴趣文件中主要特征词ki的权重。
定义4用户潜在配置文件:对于任何用户,利用协同过滤的方法预测主要特征词的权重。然后获得用户潜在配置文件,其能够被表示为向量形式UMF=(wm1,…,wmi,…,wml),其中wmi表示在用户潜在配置文件中主要特征词ki的权重。
定义5用户融合配置文件:对于任何用户,融合上述的用户当前兴趣配置文件和用户潜在配置文件,获得一个新的文件,称其为用户融合配置文件,其能够被表示成向量形式UBF=(wb1,wb2,…,wbi,…,wbl),其中wbi表示在用户融合配置文件中主要特征词ki的权重。
1.2现存用户配置文件
由于消息时效性特别强且消息用户的浏览兴趣并不是永久的,而是跟随社会流行和热点话题变化而变化,所以在进行消息推荐时需要考虑到用户的兴趣偏好变化。为此,本发明引进截取因子、时间因子以及对用户的历史数据进行处理。
1.2.1向量空间模型
给定消息集F=(f1,f2,…fi,…,fn)和主要特征词序列K=(k1,k2,…ki,…,kl),fi能够被表示为向量空间模型(VSM)fi=(wi1,wi2,…,wil),其中wij表示特征词kj在新闻fi中的权重。wij=0表示kj不在fi中出现。利用TF-IDF方法来对文本信息进行处理。计算wij的公式如下:
wij=tf(i,j)×log[1+n/n(j)]/maxOther(i,j) (1)
其中n(j)表示出现kj的新闻的数量,tf(i,j)是出现在fi中的kj的数目,maxOther(i,j)是出现在fi的其他特征词的最大数目。可以看出,新闻集F可以表示成一个权重矩阵。
1.2.2用户现存配置文件,时间因子以及用户当前兴趣配置文件
鉴于用户的兴趣会随着时间的变化而快速变化,而且用户的浏览兴趣往往和刚刚浏览过的前几条信息有很大的关联。所以本发明在处理文本信息时首先对各个用户浏览的消息的浏览时间进行升序排序,然后生成现存用户配置文件UCF。文件选取最后浏览的s个消息用于生成用户u的当前兴趣配置文件UCFus。
设用户u按浏览时间降序排列的消息集表示为:所以最新浏览的s个消息集合为Fus={fu1,fu2,…,fus},ti是用户u阅读消息fui的时间。时间因子能够被定义为:
α是时间衰减参数,通过实验确定。Fu,Fus是F的子集。所以Fu,Fus也可以表示为一个权重矩阵。获得用户u的现存配置文件UCF和当前兴趣配置文件UCFus的过程如算法1
表1:算法1
1.3潜在配置文件
消息用户的浏览兴趣并不是永久的,是跟随社会流行和热点话题变化而变化。所以推荐消息的列表不应该仅仅包括用户现存兴趣,也应该包括用户的潜在兴趣。考虑到消息的特殊性,所以本发明利用同时考虑行为相似和内容相似的基于用户的协同过滤方法来寻找目标用户的相似用户和潜在兴趣。
1.3.1混合相似性的计算
由于消息的特殊性,基于消息的协同过滤应考虑:行为相似simAct(u,v)和内容相似simCon(u,v)的计算。
给定新闻集Fus和Fv,用户u的当前兴趣文件用户v的当前配置文件UCFv=(wcv1,wcv2,...,wcvl)。则用户u与用户v的行为相似和内容相似的计算下:
simCon(u,v)=(CUFus·CUFv)/(|CUFus|×|CUFv|) (4)
根据公式(3)和(4),提供的混合相似计算公式如下:
sim(u,v)=β×simAct(u,v)+(1-β)×simCon(u,v) (5)
其中系数β∈[0,1],通过实验来决定。获得u和v的相似性的过程如算法2。
表2:算法2
1.3.2潜在用户配置文件和相似用户文件的生成
目标用户u和其他用户的相似性通过算法2计算。选择相似性最大的u个用户构造相似用户文件。然后通过加权计算获得目标用户u的潜在用户配置文件UMF。
给定相似用户集Uu={v1,v2,…,vh},用户vi的UCFvi=(wcvi1,wcvi2,...,wcvil),用户u和用户vi的相似性为sim(u,vi)。利用公式(6)计算在MUFu中的kj的权重。
获得潜在用户配置文件的过程如算法3。
表3:算法3
1.4用户混合配置文件的生成
用户混合配置文件UBF能够在获得目标用户的用户当前兴趣配置文件UCF和潜在用户配置文件UMF后,通过对UCF,UMF上的每个主要特征词加权得到。设目标用户u的当前兴趣配置文件UCFus,潜在兴趣配置文件UMFu=(wmu1,wmu2,...,wmul),混合配置文件UBFu=(wbu1,wbu2,...,wbul)。利用公式(7)计算wbuj。
wbuj=γwcuj+(1-γ)wmuj (7)
其中γ∈[0,1],其值通过实验确定。获得用户u的混合用户配置文件UBFus过程如算法4。
表4:算法4
1.5推荐结果的生成
由于消息的更新速度快和用户兴趣更新等问题,在推荐列表中,消息由两部分组成:l1,l2。
l1部分有混合配置文件生成。即通过添加时间因子ε1来限定消息是否采用混合推荐方法—看消息的发布时间与当前时间的时间间隔是否小于ε1,若满足则该文件采用混合推荐方法,否则将不采用。详细过程如下:
设目标用户u的混合配置文件BUFu=(wbu1,wbu2,…,wbul),新闻d0=(wd1,wd2,...,wdl),新闻d0的发布时间为t0,当前时间tcur,阈值ε1,ε2。首先检查:
tcur-t0≤ε1 (8)
若不等式(8)成立,则检查:
d0·BUFu≥ε2 (9)
若(9)成立,则将新闻d0放入l1中。
l2部分直接由基于内容相似和行为相似的协同过滤算法生成。详细过程如下:
设用户u的相似用户集Uu={v1,v2,…,vh},用户u和用户vi的相似性为sim(u,vi)。对于消息d0,设其在用户u的相似用户集上的权重为则消息d0的相对于用户u的权重为:
选出相对于用户u的权重较大的消息放入l2部分。
下面结合实验对本发明的应用效果作详细的描述。
1实验和分析
实验数据来源于DastCastle,它是财新网站2014年3月份的10000个用户的所有浏览记录。每个浏览记录包含:用户编号、新闻编号、浏览时间、新闻标题、新闻详细内容、新闻发表时间。从数据集中选取阅读超过25条的新闻用户作为训练集。令包含在网站给定的测试集中的训练集用户作为测试集,其中测试集中的用户只有一个测试记录。本发明采用F值,准确率(precision),召回率(recall)和多样性Diversity作为评价指标。
F值的定义如下:
其中准确率(precision)和召回率(recall)的定义如下:
其中U为数据集中用户的集合,hit(ui)表示推荐给用户ui的新闻中,确实在测试集中被该用户浏览的个数。由于每个用户在测试集中仅有一条测试记录,所以hit(ui)的取值只能为1或0。L(ui)表示用户ui的新闻推荐列表的长度:
其中,hit(ui)的定义同上,T(ui)为测试集中用户ui真正浏览的新闻的数目,所以T(ui)=1。在进行实验时,对于消息f0={w01,w02,…,w0i,…,w0l},若ki在f0中出现的频率排在前10,则设w0i=1,否则设为w0i=0。设s=5,α=10-6,γ=0.5,ε1=3600,ε2=0.5。
首先验证β的取值,由于测试集中每个用户只有一个测试记录,所以用F值不能获得好的效果。因此,在实验仿真中,本发明采用回召率(recall)。表5是推荐列表长度为20时,recall与β的关系。
表5:recall与β的关系
通过实验数据显示,当β=0.9时,recall最好。
接着验证F值,准确率(precision),召回率(recall)。
在图2中,随着推荐列表长度的增加,上述六种方法除CB(基于内容的推荐算法)外,F值都逐渐减少。在相同的推荐列表长度的情况下。CB(组合推荐)的F值最大,除个别点外,IBBCF(改进的基于行为相似的协同过滤)、ICBCF(改进的基于内容相似的协同过滤)、HF(混合推荐)、BBCF(基于行为相似的协同过滤)、CBCF(基于内容相似的协同过滤)依次减少。CB的F值最小。图3为回召率(recall)指标随推荐列表长度变化的情况。随着推荐列表长度的增加,六种方法的recall值都逐渐增加。在相同的推荐列表长度的情况下,除个别点外有:CR≥IBBCF≥ICBCF≥HR≥BBCF≥CBCF≥CB。图4为准确率(precision)指标推荐列表长度变化的情况。随着推荐列表长度的增加,六种方法值都逐渐减少。在相同的推荐列表长度的情况下,除个别点外:CR≥IBBCF≥ICBCF≥HR≥BBCF≥CBCF≥CB。
多样性Diversity描述了推荐列表中物品两两之间的差异性。所以多样性和相似性是对应的。假设sim(i,j)∈[0,1]定义了消息i和j之间的相似度,那么用户u的推荐列表R(u)的多样性定义式(14):
而推荐系统的整体多样性可以定义为所有用户推荐列表多样性的平均值:
图5是上述六种方法在不同推荐长度下多样性。从图中可以看出,CB算法是通过对用户先前消息的内容进行分析,然后推荐与其内容相似的消息,所以在推荐列表中的消息内容相似性特别高,进而多样性很差。IBBCF,ICBCF,BBCF,CBCF是目标用户通过找到与其行为相似或者内容相似的用户集,给目标用户推荐用户集中浏览最多的消息,所以多样性比CB好。CR是混合推荐和直接基于用户的协同过滤算法的组合,所以多样性比CB好,比IBBCF,ICBCF,BBCF,CBCF差。HR推荐的消息是与用户的兴趣模型相似度较高的消息,所以多样性与CB相似。
此外,本发明在进行推荐时,由于对消息的分类推荐,所以推荐所用的时间远远小于基于内容的算法和用户的协同过滤混合推荐算法。
本发明针对组合推荐算法设计了实验并分析了实验结果,使用F值、召回率(recall)和准确率(precision)和多样性Diversity指标衡量推荐算法性能。由此实验可知,组合推荐算法(CR)的F值、召回率和准确率高于其它算法,说明在相同的推荐列表长度下,组合推荐算法(CR)的推荐效果更好。在多样性方面虽然没有不是最优,但是比混合推荐算法(HR)、基于内容的推荐算法(CB)。实验结果符合算法设计初衷,验证了组合推荐算法与同类算法相比具有一定的优越性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!