基于词向量自动构建知识库实现辅助诊疗的方法和系统与流程
本发明实施例涉及数据处理技术领域,尤其是涉及一种基于词向量自动构建知识库实现辅助诊疗的方法和系统。
背景技术:
伴随着互联网医疗领域的诸多医患在线问答网站和手机应用服务的快速发展,海量的患者病情及各类综合信息的口语化描述,以及所对应着的医生诊断结果构成问答对,形成了宝贵的问诊知识库。由于这些记录往往是非结构化数据,而且存在大量口语化描述所导致的非规范医学术语,直接利用这些数据会存在诸多挑战。与此同时,在线问诊的患者病例中有大量重复工作,这对于宝贵的医生人力资源是一种浪费。如果能利用人工智能算法代替医生做出初步的诊断结果,将大大提升问诊效率。这个任务可以总结为:对一个新输入的患者关于自身性别、年龄、症状、疾病史等综合信息的描述,利用语句分析和相关算法,结合预先构建的领域知识图谱,返回一个患者的疾病诊断结果预测。
现有的技术方案主要有以下两种方法:1、通过搜索问答库中和患者描述相似度最高的问题,返回所对应的医生诊断结果。这类方法的主要问题是并未真正分析患者描述中出现的疾病信息,文本的相似度并不能完全反映患者病情的相似度,匹配准确度欠佳。2、通过患者点选与病情相关的症状和患病部位等信息,叠加专家预先标注的信息标签对应疾病打分,最终返回一个可能患病的概率排序。这类方法的问题是,人工打分存在极大的不稳定性和主观性,而且在需要标注的疾病数量大的时候要耗费大量的人力和时间成本,另外,对于可选症状外的信息,诊断系统无法分析利用。
有鉴于此,特提出本发明。
技术实现要素:
为了解决现有技术中的上述问题,即为了解决如何对患者的口语病情描述做出预测的技术问题,本发明实施例提供一种基于词向量 自动构建知识库实现辅助诊疗的方法。此外,本发明实施例还提供一种基于词向量自动构建知识库实现辅助诊疗的系统。
为了实现上述目的,根据本发明的一个方面,提供以下技术方案:
一种基于词向量自动构建知识库实现辅助诊疗的方法,该方法包括:
获取患者描述;
利用基于词向量建立的扩充的疾病-疾病相关因子字典,对患者描述进行关键词匹配,提取患者描述中跟医学相关的词语和表达;
检测提取出来的词语和表达是否在标准疾病-疾病相关因子字典中;
基于检测结果,结合根据扩充的疾病-疾病相关因子字典得到的疾病相关因子对应于疾病的相关性打分,计算疾病的分数;
对疾病的分数进行排序;
根据排序结果确定疾病。
进一步地,扩充的疾病-疾病相关因子字典可以通过以下方式建立:
利用医学信息训练关于疾病-疾病相关因子的词向量嵌入分布式表示模型;
基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立扩充的疾病、疾病相关因子字典。
进一步地,利用医学信息训练关于疾病-疾病相关因子的词向量嵌入分布式表示模型,具体可以包括:
获取医学信息训练语料;
对医学信息训练语料进行清洗;
统计在问答库记录中出现的高频表达方式,增大高频表达方式在分词模型中的权重,并进行中文分词,得到训练文本;
对训练文本进行训练,生成词向量嵌入分布式表示模型。
进一步地,疾病相关因子对应于疾病的相关性打分可以通过以下方式确定:
基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立替换词表;
使用扩充的疾病-疾病相关因子字典和替换词表,匹配医学信息中的疾病-疾病相关因子,计算疾病相关因子对应于疾病的相关性打分。
进一步地,使用扩充的疾病-疾病相关因子字典和替换词表,匹配医学信息中的疾病-疾病相关因子,计算疾病相关因子对应于疾病的相关性打分,具体可以包括:
利用扩充的疾病-疾病相关因子字典,对医患问答记录进行关键词的匹配,提取医患问答记录中跟医学相关的词语和表达;
检测提取出的医患问答记录中跟医学相关的词语和表达是否在标准疾病-疾病相关因子字典中;
若不在,则根据替换词表,将提取出的医患问答记录中跟医学相关的词语和表达归一化到对应的标准表达中;
基于标准表达,统计疾病及其相关因子共现的频数,得到疾病相关因子和疾病的共现频数记录矩阵;
基于疾病相关因子和疾病的共现频数记录矩阵,使用非线性变换方法,得到疾病相关因子对应于疾病的相关性打分。
进一步地,该方法还可以包括:
基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立替换词表;
检测提取出来的词语和表达是否在标准疾病-疾病相关因子字典中,具体包括:
若未检测到,则根据替换词表,将提取出来的词语和表达归一化到对应的标准表达中,得到标准化疾病相关因子;
基于检测结果,结合根据扩充的疾病-疾病相关因子字典得到的疾病相关因子对应于疾病的相关性打分,计算疾病的分数,具体包括:
基于标准化疾病相关因子,结合根据扩充的疾病-疾病相关因子字典得到的疾病相关因子对应于疾病的相关性打分,计算疾病的分数。
进一步地,疾病相关因子对应于疾病的相关性打分可以通过下式确定:
其中,Score(i,j)表示疾病相关因子对应于疾病的相关性打分;P(Di|Fj)表示患有疾病的条件概率;Di表示疾病;Fj表示疾病相关因子;Ni表示疾病频数,Ni=∑jNij,Nij表示记录频数。
进一步地,疾病的分数可以通过下式得到:
其中,DS(Di)表示疾病的分数;Di表示疾病;W(Fj)表示疾病类别映射权值;Score(i,j)表示疾病相关因子对应于疾病的相关性打分。
为了实现上述目的,根据本发明的另一个方面,还提供了以下技术方案:
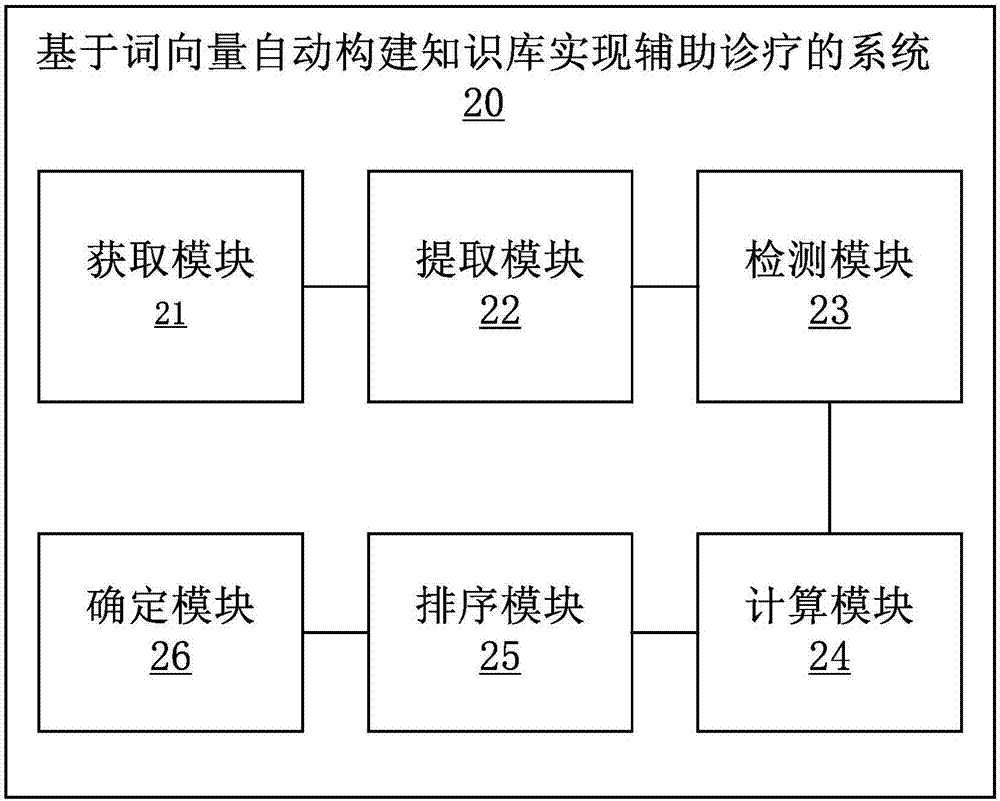
一种基于词向量自动构建知识库实现辅助诊疗的系统,该系统可以包括:
获取模块,用于获取患者描述;
提取模块,用于利用基于词向量建立的扩充的疾病-疾病相关因子字典,对患者描述进行关键词匹配,提取患者描述中跟医学相关的词语和表达;
检测模块,用于检测提取出来的词语和表达是否在标准疾病-疾病相关因子字典中;
计算模块,用于基于检测结果,结合根据扩充的疾病-疾病相关因子字典得到的疾病相关因子对应于疾病的相关性打分,计算疾病的分数;
排序模块,用于对疾病的分数进行排序;
确定模块,用于根据排序结果确定疾病。
进一步地,提取模块还具体可以包括:
词向量模型建立单元,用于利用医学信息训练关于疾病-疾病相关因子的词向量嵌入分布式表示模型;
扩充词典建立单元,用于基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立扩充的疾病、疾病相关因子字典。
进一步地,词向量模型建立单元具体可以包括:
获取单元,用于获取医学信息训练语料;
清洗单元,用于对医学信息训练语料进行清洗;
第一统计单元,用于统计在问答库记录中出现的高频表达方式,增大高频表达方式在分词模型中的权重,并进行中文分词,得到训练文本;
生成单元,用于对训练文本进行训练,生成词向量嵌入分布式表示模型。
进一步地,计算模块还具体可以包括:
第一替换词表建立单元,用于基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立替换词表;
相关性打分计算单元,用于使用扩充的疾病-疾病相关因子字典和替换词表,匹配医学信息中的疾病-疾病相关因子,计算疾病相关因子对应于疾病的相关性打分。
进一步地,相关性打分计算单元具体可以包括:
提取单元,用于利用扩充的疾病-疾病相关因子字典,对医患问答记录进行关键词的匹配,提取医患问答记录中跟医学相关的词语和表达;
检测单元,用于检测提取出的医患问答记录中跟医学相关的词语和表达是否在标准疾病-疾病相关因子字典中;
第一归一化单元,用于在词语和表达未在标准疾病-疾病相关因子字典中时,根据替换词表,将提取出的医患问答记录中跟医学相关的词语和表达归一化到对应的标准表达中;
第二统计单元,用于基于标准表达,统计疾病及其相关因子共现的频数,得到疾病相关因子和疾病的共现频数记录矩阵;
非线性变换单元,用于基于疾病相关因子和疾病的共现频数记录矩阵,使用非线性变换方法,得到疾病相关因子对应于疾病的相关性打分。
进一步地,该系统包括:
第二替换词表建立单元,用于基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立替换词表;
上述检测模块具体可以包括:
第二归一化单元,用于在提取出来的词语和表达未在标准疾病-疾病相关因子字典中时,根据替换词表,将提取出来的词语和表达归一化到对应的标准表达中,得到标准化疾病相关因子;
上述计算模块具体可以包括:
疾病分数计算单元,用于基于标准化疾病相关因子,结合根据扩充的疾病-疾病相关因子字典得到的疾病相关因子对应于疾病的相关性打分,计算疾病的分数。
本发明实施例提供一种基于词向量自动构建知识库实现辅助诊疗的方法和系统。其中,该方法可以包括:获取患者描述;利用基于词向量建立的扩充的疾病-疾病相关因子字典,对患者描述进行关键词匹配,提取患者描述中跟医学相关的词语和表达;检测提取出来的词语和表达是否在标准疾病-疾病相关因子字典中;基于检测结果,结合根据扩充的疾病-疾病相关因子字典得到的疾病相关因子对应于疾病的相关性打分,计算疾病的分数;对疾病的分数进行排序;根据排序结果确定疾病。其中,本发明实施例利用针对医学领域训练的词向量分布式表示,建立扩充的疾病-疾病相关因子关键词字典,可以利用包括通用医学资料和口语化的互联网医患问答记录在内的多源医学信息,学习构建疾病知识图谱,分析处理非标准化、口语化的患者病情描述,由此,本发明解决了如何对患者的口语病情描述做出预测的技术问题。
附图说明
为了更清楚地说明本发明实例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
图1是根据本发明实施例的基于词向量自动构建知识库实现辅助诊疗的方法的流程示意图;
图2是根据本发明实施例的基于词向量自动构建知识库实现辅助诊疗的系统的结构示意图。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
本发明实施例的基本思想是使用词向量嵌入技术,生成对通用医学信息和在线医患口语化问答记录、患者病例数据库中疾病-疾病相关因子的分布式表示,自动构建疾病-疾病相关因子的知识图谱,进而实现对患者口语化病情描述的辅助诊断。
需要说明的术语或定义如下:
疾病相关因子:可能导致、帮助判断或含有某种疾病信息的各种因子,如:疾病症状、疾病史、年龄、发病体征、性别等。
词向量嵌入:利用“Distributed Representation”的方法,将一个词语(或短语)用低维度(例如,小于1000维)的连续实数向量表示,从而可以用这些向量来区分或者表示这些词语,处理文本分类、关系提取等自然语言处理的任务。
共现频数:在一个语段或者文档中,某几个词语或者概念同时出现被称为一次共现,统计在有代表性的全部文档中的这些词语的出现数目,即共现频数。
本发明实施例提供一种基于词向量自动构建知识库实现辅助诊疗的方法。如图1所示,该方法可以包括:
S100:获取患者描述。
S110:利用基于词向量建立的扩充的疾病-疾病相关因子字典,对患者描述进行关键词匹配,提取患者描述中跟医学相关的词语和表达。
其中,扩充的疾病-疾病相关因子字典通过步骤S112至步骤S114来建立。
S112:利用医学信息训练关于疾病-疾病相关因子的词向量嵌入分布式表示模型。
其中,医学信息包括但不限于通用医学信息、医患问答记录、患者病例、与医学疾病、疾病相关因素有关的文本数据等。通用医学信息包括但不限于医学文献(例如:医学论文、医学专利文献)、教科书(尤其是医学教科书)、医学论文。
优选地,医患问答记录为网络在线医患口语化问答记录。
具体地,步骤S112可以包括:
S1121:获取医学信息训练语料。
其中,医学信息训练语料可以包括但不限于问答库、医学教科书、病例库等。
S1122:对医学信息训练语料进行清洗。
本步骤的目的是去掉无意义字符。
S1123:统计在问答库记录中出现的高频表达方式,增大高频表达方式在分词模型中的权重,并进行中文分词,得到训练文本。
S1124:对训练文本进行训练,生成词向量嵌入分布式表示模型。
在训练过程中,可以使用的训练语料包括但不限于在线医患问答记录、病人病历、教科书。本发明实施例使用但不限于Mikolov Tomasti提出的word2vec开源工具(https://github.com/danielfrg/word2vec)训练生成医学领域的词向量嵌入表示模型,并将其保存在知识库中。训练过程中,可以使用神经网络或其他训练算法。有关词向量训练的方法可以参见申请号为:201610179115.0、201510096570.X的文献,该文献在此以引用的方式结合于此。相关表示学习领域论文实验表明,更大的训练语料可以取得更理想的词向量。
举例来说,在实际应用中,可以使用分词并清洗文本数据训练300维、几十万种表述的词向量,其中部分高频词的例如表示为:
<肿瘤:0.176907,0.470268,-0.008468…共300维>
<血糖:0.149234,0.278761,-0.474681…共300维>
<发烧:0.184283,0.046142,-0.107758…共300维>
<发高烧:0.204092,0.089622,0.0057266…共300维>
<高热:0.366153,0.314256,0.073571…共300维>
在一些可选的实现方式中,对训练文本进行训练的步骤还可以包括:进行训练文本中高频词语的低维实数向量表示。
其中,低维可以根据实际情况进行设定,例如可以设置小于1000维。
S114:基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立扩充的疾病、疾病相关因子字典。
本领域技术人员应清楚,在建立扩充的疾病、疾病相关因子字典的过程中还可以建立替换词表,即基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立替换词表。
其中,医学专家结合具体预测任务,构造维护的标准疾病-疾病相关因子字典是参考了权威的教科书和规定标准,由医学专家制定并修正和维护的疾病和疾病因子的收录集合,其为标准疾病-疾病相关因子的术语集合,其需要结合要预测的具体疾病和疾病症状、疾病史、年龄、发病体征、性别等相关信息进行整理和维护。例如,心脏病、抑郁症可以作为两个标准疾病字典(集合)中的元素,而失眠、糖尿病史可以作为两个标准疾病相关因子字典(集合)中的元素。
距离度量方法包括但不限于cosine(余弦)距离、欧氏距离或者其他距离度量方法。
对于标准疾病-疾病相关因子字典中的每一个元素,使用距离度量方法来计算,并找到词向量词表中距离最近的k个词语或者短语表达方式,记录为标准疾病-疾病相关因子字典中元素的替换。由此建立异构表达方式到标准表达方式的替换词表,同时建立一个知识库的扩充的疾病-疾病相关因子字典。即:每个可替换的元素加入到原始标准疾病-疾病相关因子字典中,形成扩充的疾病-疾病相关因子字典。其中,k表示针对具体任务和数据可以调整的参数。
下面通过优选实施方式以标准症状相关因子中有“发热”这一项为例来详细说明得到扩充的疾病-疾病相关因子字典和替换词表的过程,其具体包括:步骤A1至步骤A3。
步骤A1:使用cosine距离计算与“发热”距离最近的词语或者短语表达方式,得到“发高烧”和“高热”。其中,距离参数k为2。
步骤A2:在扩充的疾病-疾病相关因子字典中,加入“发高烧”和“高热”,同时记录“发热”这一标准疾病相关因子的替换词表中包含“发高烧”和“高热”。
步骤A3:利用训练好的医疗领域词向量嵌入分布式表示模型,对标准疾病-疾病相关因子字典中的每一个元素执行相同操作,从而得到扩充的疾病-疾病相关因子字典和替换词表。
S120:检测提取出来的词语和表达是否在标准疾病-疾病相关因子字典中。
本步骤中,若检测到提取出来的词语和表达在标准疾病-疾病相关因子字典中,则不进行处理;若未检测到,则根据替换词表,将提取出来的词语和表达归一化到对应的标准表达中,得到标准化疾病相关因子。其中,替换词表通过基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充而建立得到。
上述不进行处理步骤表示采用标准疾病-疾病相关因子字典中的标准化疾病相关因子进行后续处理。
S130:基于检测结果,结合根据扩充的疾病-疾病相关因子字典得到的疾病相关因子对应于疾病的相关性打分,计算疾病的分数。
本实施例中,当未检测到提取出来的词语和表达在标准疾病-疾病相关因子字典中时,根据替换词表,将提取出来的词语和表达归一化到对应的标准表达中,得到标准化疾病相关因子;基于标准化疾病相关因子,结合根据扩充的疾病-疾病相关因子字典得到的疾病相关因子对应于疾病的相关性打分,计算疾病的分数。当检测到提取出来的词语和表达在标准疾病-疾病相关因子字典中时,使用标准疾病-疾病相关因子字典中的标准化疾病相关因子,结合根据扩充的疾病-疾病相关因子字典得到的疾病相关因子对应于疾病的相关性打分,计算疾病的分数。
其中,疾病相关因子对应于疾病的相关性打分通过步骤S132至步骤S134来确定。
S132:基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立替换词表。
S134:使用扩充的疾病-疾病相关因子字典和替换词表,匹配医学信息中的疾病-疾病相关因子,计算疾病相关因子对应于疾病的相关性打分。
具体地,步骤S134可以包括:
S1341:利用扩充的疾病-疾病相关因子字典,对医患问答记录进行关键词的匹配,提取医患问答记录中跟医学相关的词语和表达。
在一个优选的实施方式中,本步骤可以利用扩充的疾病-疾病相关因子字典,对医患问答库中的病情描述和诊断结果进行关键词的匹配,提取出医患问答记录中跟医学相关的词语和表达。
S1342:检测提取出的医患问答记录中跟医学相关的词语和表达是否在标准疾病-疾病相关因子字典中。若在,则执行步骤S1343;否则,执行步骤S1344。
本步骤逐一检测提取出来的相关词语和表达是否在标准的疾病-疾病相关因子字典中,如果在则不进行特别处理;如果不在,则根据替换词表归一化到对应的标准表达中。
S1343:不进行处理。
本步骤表示采用标准疾病-疾病相关因子字典中的标准表达进行后续处理。
S1344:根据替换词表,将提取出的医患问答记录中跟医学相关的词语和表达归一化到对应的标准表达中。
上述步骤S1344还可以包括:当词语和表达对应多个标准疾病或疾病相关因子时,进行医学相关词语和表达的规范化。
具体地,当某一表达对应多个标准疾病或疾病相关因子时,确定与该表达距离最近的标准相关因子,来替换该表达,得到对应于该患者描述的标准化疾病相关因子。
作为示例,当某个词语和表达对应着不止一个标准疾病或疾病相关因子时,使用但不限于cosine距离或欧氏距离来计算并找到与之距离最近的标准概念,用来替换当前表达方式,即进行医学相关词语和表达的规范化。
举例来说,当某个表达对应着不止一个标准疾病或疾病相关因子时,使用但不限于cosine距离或欧氏距离来计算并找到与之距离最近的标准相关因子,用来替换当前表达方式。操作得到了对于该条患者的输入内容,所包含的Q个标准化的疾病相关因子:{F1,F2,...Fj...FQ}。
S1345:基于标准表达,统计疾病及其相关因子共现的频数,得到疾病相关因子和疾病的共现频数记录矩阵。
标准疾病-疾病相关因子字典中包含两种元素:疾病和疾病相关因子。举例来说,对于m种疾病,定义为{D1...D2...Di...Dm},对于n种疾病相关因子,定义为{F1...F...Fj...Fn};将Nij初始化为零。在P条问答库记录{R1...R2...RS...RP}中,如果Rs中同时出现了Di和Fj,将Nij增加1,即某疾病和某疾病相关因子共现的频数记录一次。对P条记录进行统计,可以得到m×n的疾病相关因子和疾病的共现频数记录矩阵。
其中,P表示问答库记录条数;R1,R2...Rs...RP表示问答库记录;Nij表示记录频数。
S1346:基于疾病相关因子和疾病的共现频数记录矩阵,使用非线性变换方法,得到疾病相关因子对应于疾病的相关性打分。
本步骤在具体实施过程中,考虑到:在某条记录中,已知疾病相关因子Fj出现,那么患有疾病Di的条件概率为 条件概率虽然能在一定程度上反映疾病相关因子到疾病的可能性,但容易受到高频常见病的累积效应影响,导致在记录中出现次数量更高的常见病获得极高的条件概率。所以,最终的打分函数中还应包括一个与Ni=∑jNij有关的控制参数。这类似于文档分类领域中使用的逆文档频率思想。
优选地,疾病相关因子对应于疾病的相关性打分可以通过下式确定:
其中,Score(i,j)表示疾病相关因子对应于疾病的相关性打分;P(Di|Fj)表示患有疾病的条件概率;Di表示疾病;Fj表示疾病相关因子;Ni表示疾病频数,Ni=∑jNij,Nij表示记录频数。
上式包含了条件概率和一个对疾病频数倒数的非线性变换。最终每个疾病相关因子对应至少一个相关疾病,所对应的分数用Score(i,j)表示。
上述步骤通过使用扩充的疾病-疾病相关因子字典,匹配医学信息中的疾病-疾病相关因子,计算并在知识图谱中存储疾病相关因子到疾病的相关性打分,可以自动学习构建用于预测疾病的知识图谱。
在一个优选的实施例中,在步骤S1346之后还可以包括:定期通过A/B测试方法测试打分函数,并更新疾病相关因子对应于疾病的相关性打分。
本步骤考虑到原始问答库的数据质量、数量都会对疾病相关因子的相关性打分产生一定的影响,与此同时,在线的医疗问诊平台每天都能产生大量新的记录。所以,将有关于疾病相关性因子的打分函数保存在离线的知识库中,定期由在线的A/B测试选择效果更好的打分函数版本连接上线。
每一个版本的训练学习数据都将独立形成一个疾病相关因子到疾病的相关性打分的数据版本,由于这种相关性打分并不完全等同于某种疾病因子与疾病相关的先验概率,所以医学专家对于打分的评价只具有参考性,而其是否可以提升疾病确定的准确性和友好程度将作为最终的评价指标,以及是否对其他版本进行更换的依据。
在知识库构建过程,结合已有的知识库,可以实现对于患者输入的病情和基本信息描述进行分析,并给出可能患有的疾病的功能。
下面以一优选实施方式来详细说明得到了疾病相关因子到疾病的相关性打分的过程。其中,“喉咙肿痛”、“感冒”和“鼻塞流涕”在标准字典中。得到相关性打分的过程可以包括步骤B1至步骤B5。
步骤B1:获取原始问答库中的一条“我喉咙肿痛,这几天一直发高烧,鼻塞流涕,请问医生我得了什么病”和“可能患有感冒”的问答对。
步骤B2:对该问答对进行处理,匹配到“喉咙肿痛”、“发高烧”、“鼻塞流涕”和“感冒”。
步骤B3:按照步骤S121和步骤S122,利用替换词表将“发高烧”替换为“发烧”。
步骤B4:对3个疾病相关因子和1个疾病逐一配对,统计疾病和相关因子共现的频数,得到疾病相关因子和疾病的共现频数记录矩阵。
步骤B5:根据下式确定疾病相关因子对应于疾病的相关性打分:
其中,Score(i,j)表示疾病相关因子对应于疾病的相关性打分;P(Di|Fj)表示患有疾病的条件概率;Di表示疾病;Fj表示疾病相关因子;Ni表示疾病频数,Ni=∑jNij,Nij表示记录频数。
在一个优选的实施例中,疾病的分数可以通过下式得到:
其中,DS(Di)表示疾病的分数;Di表示疾病;W(Fj)表示疾病类别映射权值;Score(i,j)表示疾病相关因子对应于疾病的相关性打分。
举例来说,在{F1,F2,...Fj...FQ}中,对于每一个与患者描述有关的因子Fj,结合标准化疾病相关因子的种类,利用下式在每个与之相关的疾病Di上叠加打分:
其中,DS(Di)表示疾病的分数;Di表示疾病;W(Fj)表示疾病类别映射权值;Score(i,j)表示疾病相关因子对应于疾病的相关性打分。
上式中,因为不同因子对于疾病预测的判断置信度不同,所以根据因子的种类不同,赋予不同的疾病类别映射权值。其中,映射关系可以由专家根据类别属性制定。例如:“吸烟习惯”属于生活习惯类别的疾病相关因子;“发烧”属于疾病症状类的疾病相关因子,在进行计算的时候,确定类别的权值,使用不同的疾病类别映射权值。
S140:对疾病的分数进行排序。
S150:根据排序结果确定疾病。
下面以一优选实施例来详细说明利用本发明实施例得到疑患疾病的打分排序。其中,患者的病情描述为“这几天连续出现高热症状,有吸烟习惯,是得了什么病”。得到打分排序的过程可以包括步骤C1至步骤C7。
步骤C1:利用扩充的疾病-疾病相关因子字典,对“这几天连续出现高热症状,有吸烟习惯,是得了什么病”进行关键词的匹配,提取出“高热”和“吸烟习惯”。
步骤C2:检测到“高热”存在于扩充的疾病-疾病相关因子字典中,而不在标准疾病-疾病相关因子字典中。
步骤C3:根据替换词表,将“高热”替换为“发烧”。
步骤C4:根据“发烧”和“吸烟习惯”所属的种类,分别确定映射权值。
步骤C5:根据下式确定患者患有不同疾病的分数:
步骤C6:对不同疾病的分数进行排序。
步骤C7:输出排在前三位的疾病:<急性咽炎:0.143531>、<急性扁桃体肿大:0.129281>、<气管疾病:0.062088>。
上述实施例中虽然将各个步骤按照上述先后次序的方式进行了描述,但是本领域技术人员可以理解,为了实现本实施例的效果,不同的步骤之间不必按照这样的次序执行,其可以同时(并行)执行或以颠倒的次序执行,这些简单的变化都在本发明的保护范围之内。
基于与上述方法实施例相同的技术构思,本发明实施例提供一种基于词向量自动构建知识库实现辅助诊疗的系统。该基于词向量自动构建知识库实现辅助诊疗的系统可以执行上述基于词向量自动构建知识库实现辅助诊疗的方法实施例。如图2所示,该系统20可以包括:获取模块21、提取模块22、检测模块23、计算模块24、排序模块25和确定模块26。其中,获取模块21用于获取患者描述。提取模块22用于利用基于词向量建立的扩充的疾病-疾病相关因子字典,对患者描述进行关键词匹配,提取患者描述中跟医学相关的词语和表达。检测模块23用 于检测提取出来的词语和表达是否在标准疾病-疾病相关因子字典中。计算模块24用于基于检测结果,结合根据扩充的疾病-疾病相关因子字典得到的疾病相关因子对应于疾病的相关性打分,计算疾病的分数。排序模块25用于对疾病的分数进行排序。确定模块26用于根据排序结果确定疾病。
在一个优选的实施例中,提取模块还具体可以包括:词向量模型建立单元和扩充词典建立单元。其中,词向量模型建立单元用于利用医学信息训练关于疾病-疾病相关因子的词向量嵌入分布式表示模型。扩充词典建立单元用于基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立扩充的疾病、疾病相关因子字典。
在一个优选的实施例中,词向量模型建立单元具体可以包括:获取单元、清洗单元、第一统计单元和生成单元。其中,获取单元用于获取医学信息训练语料。清洗单元用于对医学信息训练语料进行清洗。第一统计单元用于统计在问答库记录中出现的高频表达方式,增大高频表达方式在分词模型中的权重,并进行中文分词,得到训练文本。生成单元用于对训练文本进行训练,生成词向量嵌入分布式表示模型。
在一个优选的实施例中,计算模块还具体可以包括:第一替换词表建立单元和相关性打分计算单元。其中,第一替换词表建立单元用于基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立替换词表。相关性打分计算单元用于使用扩充的疾病-疾病相关因子字典和替换词表,匹配医学信息中的疾病-疾病相关因子,计算疾病相关因子对应于疾病的相关性打分。
在一个优选的实施例中,相关性打分计算单元具体可以包括:提取单元、检测单元、第一归一化单元、第二统计单元和非线性变换单元。其中,提取单元用于利用扩充的疾病-疾病相关因子字典,对医患问答记录进行关键词的匹配,提取医患问答记录中跟医学相关的词语和表达。检测单元用于检测提取出的医患问答记录中跟医学相关的词语和表达是否在标准疾病-疾病相关因子字典中。第一归一化单元用于在词语和表达未在标准疾病-疾病相关因子字典中时,根据替换词表,将提取出的医患问答记录中跟医学相关的词语和表达归一化到对应的标准表达中。第二统计单元用于基于标准表达,统计疾病及其相关因子共现的 频数,得到疾病相关因子和疾病的共现频数记录矩阵。非线性变换单元用于基于疾病相关因子和疾病的共现频数记录矩阵,使用非线性变换方法,得到疾病相关因子对应于疾病的相关性打分。
在一个优选的实施例中,该系统还可以包括:第二替换词表建立单元;该第二替换词表建立单元用于基于词向量嵌入分布式表示模型,使用距离度量方法对标准疾病-疾病相关因子字典进行扩充,建立替换词表。检测模块具体还可以包括第二归一化单元;该第二归一化单元用于在提取出来的词语和表达未在标准疾病-疾病相关因子字典中时,根据替换词表,将提取出来的词语和表达归一化到对应的标准表达中,得到标准化疾病相关因子。计算模块具体还可以包括疾病分数计算单元;该疾病分数计算单元用于基于标准化疾病相关因子,结合根据扩充的疾病-疾病相关因子字典得到的疾病相关因子对应于疾病的相关性打分,计算疾病的分数。
上述描述的系统的具体工作过程及有关说明,可以参考前述方法实施例中的对应过程,在此不再赘述。
本领域技术人员可以理解,上述基于词向量自动构建知识库实现辅助诊疗的系统还可以包括一些其他的公知结构,例如处理器、控制器、存储器和总线等,其中,存储器包括但不限于随机存储器、闪存、只读存储器、可编程只读存储器、易失性存储器、非易失性存储器、串行存储器、并行存储器或寄存器等,处理器包括但不限于单核处理器、多核处理器、基于X86架构的处理器、CPLD/FPGA、DSP、ARM处理器、MIPS处理器等,总线可以包括数据总线、地址总线和控制总线。为了不必要地模糊本公开的实施例,这些公知的结构未在图2中示出。还需要指出的是,图2中的各个模块的数量仅仅是示意性的。根据实际需要,各模块可以具有任意的数量。
需要说明的是,上述各个模块的划分仅为举例,在实际应用中,可以有另外的划分方式。另外,各个模块也可以再分解为其他模块,在此不再赘述。各个模块既可以采用硬件的方式来实现,也可以采用软件的方式来实现亦或采用软硬件相结合的方式来实现。在实际应用中,上述各个模块可以由诸如中央处理器、微处理器、数字信号处理去或现场可编程门阵列等来实现。用于实施各个模块的示例性硬件平台 可包括诸如具有兼容操作系统的基于Intel x86的平台、Mac平台、MAC OS、iOS、Android OS等。
需要说明的是,本文中使用的“第一”、“第二”等表述不应理解为以各种形式来对本发明保护范围形成的限制。
以上所述的具体实施方式和实验例对本发明的技术方案、实施细节和算法有效性都进行了详细说明。应该提出的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!