基于批处理和流式处理的数据处理架构及数据处理方法与流程
本发明涉及数据处理技术领域,更具体地,涉及一种基于批处理和流式处理的数据处理架构及数据处理方法。
背景技术:
随着互联网的普及、物联网的快速发展以及智能手机等设备的广泛使用,使得人们能随时随地产生数据,引起了数据的爆炸式增长。针对大规模数据,人们已经提出分布式的批处理模型和流式处理模型。
其中,批处理模型实现了大规模历史数据的高吞吐、海量分析和挖掘,它先存储后计算,往往适用于实时性要求不高,同时数据的准确性和全面性更为重要的场景,批处理模型被广泛的应用于离线分析、离线机器学习等领域。而流式处理模型更注重于对流式数据的实时分析,数据以流的方式到达,携带了大量信息,只有小部分的流式数据被保存在有限的内存中。流式处理模型被广泛地应用在在线推荐、在线分析、在线机器学习等低延时的场景中。
然而,批处理模型和流式处理模型的数据处理模式单一、使用场景有限,它们都是针对单一的问题和场景提出的解决方案,两者之间并不具备通用性。批处理模型能够处理更加全面的数据进而得到比较准确的结果,却延时比较大。流式处理模型能低延时地进行计算,却只在内存中缓存比较有限的数据导致计算精度比较低。而随着科技的进步,现代企业越来越需要一种低延时的方法同时处理历史数据和实时数据。既能保证对整个数据集的全面处理,又能保证处理的效率。
技术实现要素:
本发明为解决以上技术的难题,提供了一种基于批处理和流式处理的数据处理架构,该架构具备批处理和流式处理的能力,因而在保证对数据集进行全面处理的同时能够兼顾处理的效率。
为实现以上发明目的,采用的技术方案是:
一种基于批处理和流式处理的数据处理架构,包括数据采集模块、批处理模块、流式处理模块、数据合并模块、数据可视化模块和资源监控模块;
其中数据采集模块用于从多个数据采集终端中获取采集的实时数据,并将采集的数据传输至批处理模块和流式处理模块;
所述批处理模块用于对接收的实时数据进行持久化处理,然后在满足执行批处理条件的情况下,采用重计算的机制对经持久化处理的实时数据进行批量处理,并根据处理的结果生成不同粒度的批处理视图;
所述流式处理模块用于对接收的实时数据采用增量计算的机制进行流式处理,并根据处理的结果生成不同粒度的流式处理视图;
所述数据合并模块用于根据具体查询需求,采用相应的合并策略对批处理视图、流式处理视图进行合并;
所述数据可视化模块用于对批处理视图、流式处理视图或合并后的批处理视图、流式处理视图进行展示;
所述资源监控模块用于对数据采集模块、批处理模块、流式处理模块、数据合并模块、数据可视化模块进行资源监控。
优选地,所述数据采集模块包括数据收集子模块和数据清洗子模块,所述数据收集子模块用于接收从多个数据采集终端中获取采集的实时数据,所述数据清洗子模块用于采用相应的过滤规则对接收的实时数据进行清洗。
优选地,所述批处理模块包括数据预处理子模块、数据处理子模块和批处理视图存储子模块;
所述数据预处理子模块用于对接收的实时数据采用数据集成技术、数据变换技术、数据规约技术进行持久化处理;
所述数据处理子模块在满足执行批处理条件的情况下,采用重计算的机制对经持久化处理的实时数据进行批处理;
所述批处理视图存储子模块用于将数据处理子模块得到的处理结果保存在Hbase中,以生成不同粒度的批处理视图。
优选地,所述流式处理模块包括数据处理子模块、流式处理视图存储子模块,其中所述数据处理子模块用于采用增量计算的机制对实时数据进行流式处理,所述流式处理视图存储子模块用于对数据处理子模块产生的数据处理结果保存在Hbase中,以生成不同粒度的流式处理视图。
优选地,所述数据采集模块采用Flume日志采集系统实现。
优选地,所述批处理模块采用Spark集群实现。
优选地,所述流式处理模块采用Storm集群实现。
同时,本发明还提供了一种基于以上架构的数据处理方法,其方案具体包括以下步骤:
S1.数据采集模块用于从多个数据采集终端中获取采集的实时数据,并将采集的数据传输至批处理模块和流式处理模块;
S2.批处理模块对接收的实时数据进行持久化处理,然后在满足执行批处理条件的情况下,采用重计算的机制对经持久化处理的实时数据进行批量处理,并根据处理的结果生成不同粒度的批处理视图;
S3.流式处理模块对接收的实时数据采用增量计算的机制进行流式处理,并根据处理的结果生成不同粒度的流式处理视图;
S4.数据合并模块根据具体查询需求,采用相应的合并策略对批处理视图、流式处理视图进行合并;
S5. 数据可视化模块对批处理视图、流式处理视图或合并后的批处理视图、流式处理视图进行展示;
S6.资源监控模块对以上流程中数据采集模块、批处理模块、流式处理模块、数据合并模块、数据可视化模块进行资源监控。
与现有技术相比,本发明的有益效果是:
本发明提供的架构通过将批处理模块、流式处理模块搭配使用,可以保证整个计算结果的精准度,同时兼顾数据处理效率。
附图说明
图1为本发明提供的架构的结构图。
图2为数据收集模块的示意图。
图3为Spark集群的计算任务执行图。
图4为流式处理模块中增量计算的流程图。
图5、图6、图7为批处理模块和流式处理模块数据同步的示意图。
图8为数据合并模块执行数据处理的流程示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
以下结合附图和实施例对本发明做进一步的阐述。
实施例1
批处理和流式处理的数据处理架构,如图1所示,包括数据采集模块10、批处理模块20、流式处理模块30、数据合并模块40、数据可视化模块50和资源监控模块60;
其中数据采集模块用于从多个数据采集终端中获取采集的实时数据,并将采集的数据传输至批处理模块和流式处理模块;
所述批处理模块用于对接收的实时数据进行持久化处理,然后在满足执行批处理条件的情况下,采用重计算的机制对经持久化处理的实时数据进行批量处理,并根据处理的结果生成不同粒度的批处理视图;
所述流式处理模块用于对接收的实时数据采用增量计算的机制进行流式处理,并根据处理的结果生成不同粒度的流式处理视图;
所述数据合并模块用于根据具体查询需求,采用相应的合并策略对批处理视图、流式处理视图进行合并;
所述数据可视化模块用于对批处理视图、流式处理视图或合并后的批处理视图、流式处理视图进行展示;
所述资源监控模块用于对数据采集模块、批处理模块、流式处理模块、数据合并模块、数据可视化模块进行资源监控。
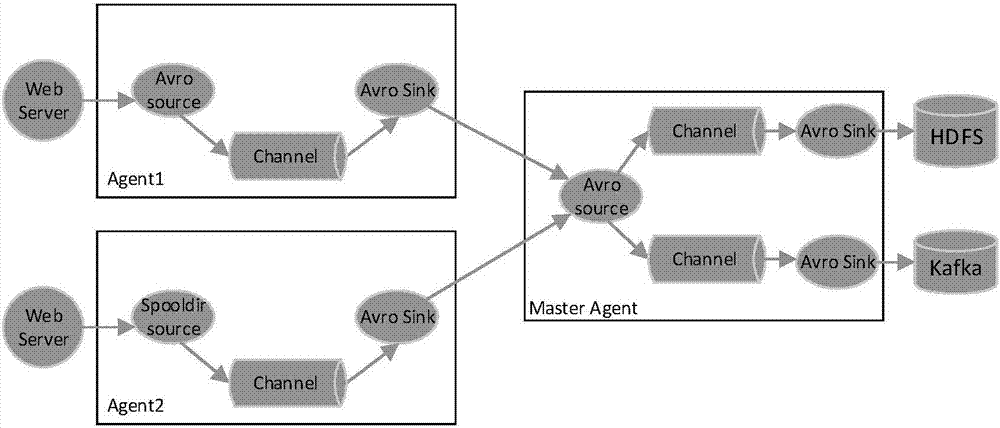
在具体的实施过程中,数据采集模块10的具体实施方式可以为:采用分布式、高可靠和高可用的海量日志采集和传输系统对多源数据进行实时接收,如Flume日志采集系统。如图2所示,该架构中设置了三个代理,分别为Agent1、Agent2和Master Agent。Flume日志采集系统使用两个Source接收外部数据,一个是Agent1中的Avro Source,用来监听一个IP和端口号,另一个是Agent2中的Spooldir,用来监听一个目录。通过对采集到的实时数据进行初步的数据过滤之后,把从两个Source接收到的数据发给Master Agent中的Avro Source。该架构采用复制策略把Avro Source中接收到的数据同时发送到File Channel和Memory Channel中,然后数据最终被传送到HDFS Sink和Kafka Sink中,以用于批处理和流式处理。
如图3所示,批处理模块20采用Spark集群实现,在实现的过程中首先构建Spark应用程序的运行环境,然后将应用程序提交到资源调度器上,该应用所需的资源会被一次性准备好,此时属于粗粒度构建环境。然后将应用程序转化为DAG图,Spark将RDD依赖关系转化为不同的stage。这里依赖关系分为窄依赖和宽依赖,窄依赖中父RDD每个分区只能被一个子RDD分区处理,而宽依赖父RDD可以交给多个子RDD分区。Spark通过贪心算法尽量使窄依赖划分在一个阶段中,并在每个stage中并行处理多个任务。执行DAG图时,首先执行不依赖其他阶段的stage,再运行依赖阶段已完成的stage,同MapReduce中的优化机制一样,Spark会考虑数据本地性和推测执行机制。批处理模块的处理结果保存在Hbase中,以生成不同粒度的批处理视图,批处理模块的处理结果、批处理视图保存在Hbase中主要是为了支持随机读写。
在具体的实施过程中,流式处理模块30采用Storm集群实现,其具体功能简述如下:
在Storm集群中,一个实时应用被设计成一个Topology,并且将Topology提交给集群,由集群中的主控节点分发代码,将任务分配给工作节点执行。一个Topology中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以元组的形式发送出去;而bolt则负责转发数据流,在bolt中可以完成计算、过滤等操作,bolt自身也可以随机将数据发送给其他bolt。其中流式处理模块30的处理结果和生成的视图都保存在Hbase中,以便新数据到达时可以低延时地进行更新操作。
同时,为了提高数据的处理效率,流式处理模块30可以采用增量计算的机制,具体过程简述如下:如图4所示,当流式处理模块有新数据到达时,会首先判断该数据是否会影响到已有数据;如果新数据影响到已有数据,则将已有数据从Hbase中取出,并且和新数据进行合并;如果新数据不会影响到已有数据,则不做处理;把上述步骤的处理结果作为新数据,采取相应的算法对新数据进行计算,生成新数据对应的实时视图,然后将生成的实时视图更新到已有的流式处理视图中。
在具体的实施过程中,为了保证流入批处理模块和流式处理模块的数据仅被处理一次,必须考虑批处理模块和流式处理模块之间的数据同步问题,其过程如下:
批处理模块和流式处理模块同时接收采集到的数据,批处理模块将数据保存在HDFS上,流式处理模块将数据保存在表中,表名用当前日期和接受的数据内容标识,通过动态维护两张表来解决数据同步的问题。如图5所示,系统开始运行一段时间后,批处理模块和流式处理模块保存相同的数据,但是批处理模块并没有到触发重计算的时间点,也即批处理模块的数据没有被计算。此时,假设流式处理模块的表是i_click。
如图6所示,到了批处理模块重计算的时间点后,触发了批处理模块的重计算,批处理模块在重计算之前会根据系统当前时间重新建一个表,用来保存实时数据。表名为i+1_click。假设在重计算期间接收的数据是block1和block2,那么此时在流式处理模块中共存两张表,一个是i_click,一个是i+1_click。i_click保存的是第i天接收到的实时数据,i+1_click中保存的是i+1天新接收到的实时数据,也即是block1和block2。
如图7所示,是系统进行数据同步后的结果。批处理模块在进行重计算后会删除表i_click,此时流式处理模块只有i+1_click表中的数据。因为此时i_click中的数据已经在批处理模块中计算,所以流式处理模块不再计算这部分数据,否则将造成数据的重计算。
在具体的实施过程中,数据合并模块40的具体实施方式可以为:针对用户的具体业务需求,合并批处理模块和流式处理模块的计算结果,从而实现在整个数据集上的查询。因此其关键点即是如何合并批处理模块计算出的批处理视图和流式处理模块计算出的实时视图,然后根据具体的业务逻辑,选择相应的合并策略。如果查询函数满足Monoid特性,即满足结合率,可以直接将批处理视图和流式处理视图结果进行合并。如图8所示,假如要查询在不同时间段物品的点击量时,首先判断输入时间段的跨度,如果其完全在批处理模块,则只需从批处理视图中查询得到相应的结果;如果其完全在流式处理模块,则只需要从流式处理视图中查询得到相应的结果;如果其横跨在批处理模块和流式处理模块,则需要分别从批处理视图和流式处理视图中查询,然后将查询结果进行合并,也即对相同物品的购买量进行简单的相加。如果查询函数不满足Monoid特性,可以将查询函数转换为多个满足Monoid特性的查询函数进行运算,对于单独的每个查询函数分别从批处理视图和流式处理视图中查询结果,然后再进行相关计算即得到最终所求结果。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!