一种语料生成装置和方法与流程
本发明涉及文字处理领域,特别是涉及一种语料生成装置和方法。
背景技术:
随着互联网的发展,网络检索的需求也越来越高,因此需要储备更多的关键词,以及语料,存储于云端的语料库中,供网民上网搜索时使用。
但是语言表达方式丰富多变,仅需通过若干词语随机组合,可能就会形成语句,如果语料库通过依次采集输入全部的语料,需要投入过大的精力,而且容易遗漏。现有技术有采用编辑距离的方法,通过删除、移位、插入等操作扩充语料库,但是实际操作的过程繁琐。
技术实现要素:
本发明主要解决的技术问题是提供一种语料生成装置和方法,能够通过将词语嵌套到扩充得到的句式结构中获取语料,操作简单,节省资源,同时较大程度的扩充了语料库。
为解决上述技术问题,本发明采用的一个技术方案是:提供一种语料生成装置,该装置包括:分词模块,连接至少一个单语平行语料库,用于对每一平行语料库内的语句进行分词,并对分词进行知识驱动以实现标签化;分类模块,用于识别知识驱动处理后的语句,将标签序列不同的相同含义的语句分类到同一语句簇;映射模块,用于分析每一单语平行语料库中每一语句簇中的语句,确定语句簇中所有语句的句式结构类别,确定并记录存储同一语句簇中不同句式结构类别之间进行变换时,相应的句式结构之间的标签变换的映射方式;句式结构生成模块,用于查找所有单语平行语料库中每一语句簇中相同的第一类别句式结构,并根据语句簇其中之一者的第一类别句式结构与同一语句簇中其他类别句式结构的第一类映射方式,在其余的语句簇中对第一类别句式结构按照映射方式分别进行映射,生成相应的句式结构类别;以及,语料生成模块,用于对新生成的句式结构嵌套语句簇中句式结构的序列标签对应的词语,生成新的单语平行语料库。
为解决上述技术问题,本发明采用的一个技术方案是:提供一种语料生成方法,该方法的步骤包括:对至少一个单语平行语料库中每一语句进行分词,并对分词进行知识驱动以实现标签化;识别知识驱动处理后的语句,将标签序列不同的相同含义的语句分类到同一语句簇;分析每一单语平行语料库中每一语句簇中的语句,确定语句簇中所有语句的句式结构类别,确定并记录存储同一语句簇中不同句式结构类别之间进行变换时,相应的句式结构之间的标签变换的映射方式;查找所有单语平行语料库中每一语句簇中相同的第一类别句式结构,并根据语句簇其中之一者的第一类别句式结构与同一语句簇中其他类别句式结构的第一类映射方式,在其余的语句簇中对第一类别句式结构按照映射方式分别进行映射,生成相应的句式结构类别;对新生成的句式结构嵌套语句簇中句式结构的序列标签对应的词语,生成新的单语平行语料库。
区别于现有技术,本发明的语料生成装置在通过将现有语料库中的语句进行标签化,将标签序列不同的句式格式根据句式的标签进行映射,得到更多的句式结构,填充嵌套标签对应的词语后得到更多的语料。通过本发明,能够通过将词语嵌套到扩充得到的句式结构中获取语料,操作简单,节省资源,同时较大程度的扩充了语料库。
附图说明
图1是本发明提供的一种语料生成装置的实施方式的结构示意图;
图2是本发明提供的一种语料生成方法的实施方式的流程示意图。
具体实施方式
下面结合具体实施方式对本发明的技术方案作进一步更详细的描述。显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
语料库的建设是统计学习方法的重要基础,近年来,语料库资源对于自然语言处理研究的巨大价值已经得到越来越多的认可。特别是双语语料库(bilingualcorpus),已经成为机器翻译、机器辅助翻译以及翻译知识获取研究不可或缺的重要资源。一方面,双语语料库的出现直接推动了机器翻译新技术的发展,像平行语料库为统计机器翻译的模型构建提供了必不可少的训练数据,基于统计(statistic-based)和基于实例(example-based)等基于语料库的翻译方法为机器翻译研究提供了新的思路,有效改善了翻译质量,在机器翻译研究领域掀起了新的高潮。另一方面,双语语料库又是获取翻译知识的重要来源,从中可以挖掘学习各种细粒度的翻译知识,如翻译词典和翻译模板,从而改进传统的机器翻译技术。此外,双语语料库也是跨语言信息检索,翻译词典编撰、双语术语自动提取以及多语言对比研究等的重要基础资源。双语平行语料库建设与获取存在着很大的困难,各国都投入了大量的人力、物力和财力,但是双语平行语料库的来源主要集中在政府报告、新闻法律等特定领域,不适合真实文本应用。同时,互联网上的大规模双语文本并且具有很好的时效性和覆盖性,这为双语平行语料库的获取提供了潜在的解决途径。
参阅图1,图1是本发明提供的一种语料生成装置的实施方式的结构示意图。该装置100包括:分词模块110、分类模块120、映射模块130、句式结构生成模块140和语料生成模块150。
其中,分词模块110连接单语平行语料库101,用于对平行语料库101内的语句进行分词,对分词进行知识驱动以实现标签化。分词的方法通常为采用分词工具软件。知识驱动的过程就是对语句进行标签化的过程。
分词模块110包括分词单元111、第一标签单元112和第二标签单元113。分词单元111连接到网络的分词工具软件,将待分解的语句导入到分词工具软件中进行分词操作。将现有语料库中全部的语句进行分词后,第一标签单元112按照每一完成分词的句中的词语的词性对语句添加第一标签。第二标签单元113按照词语在句中成分对语句添加第二标签。在本实施方式中,选定语料库中的语句“小红明天下午要去深圳市科技馆九层会议室参加科普知识讲座”,经过分词操作后,得到“小红/明天/下午/要/去/深圳市/科技馆/九层/会议室/参加/科普/知识/讲座”。其中,小红、深圳市、科技馆、会议室和讲座为名词,按照词性为上述7个词语标注相同的第一标签,通常标注为n(noun);明天和下午表征时间,第一标签标注为t(time);参加为动词,第一标签标注为v(verb);要、去、九层和科普知识为附加词语,可省略不做标记。第一标签标注完成后,继续进行二级标注。对于第一标签为名词的小红、深圳市、科技馆、会议室和讲座,小红为人物性的名词,为句中主语,第二标签标注为ns(noun/subject);深圳市、科技馆和会议室分别为表征地点的名词,通常为状语adverbialmodifier,但是所指的地点范围有所区别,深圳市、科技馆和会议室三者代表的范围为从大到小,因此可标注为nam1、nam2和nam3;讲座为句中宾语,标注为no对于表征时间的名词明天和下午,按照时间范围的大小,可标注为t1和t2。标注标签完成后,语料库中的语句均可以通过标签序列表征,如上述语句可标注为“nst1t2nam1nam2nam3vno”。
在其他实施方式中,分词模块110还包括第三标签单元114,第三标签单元114对经标签化处理后标签序列相同的不同含义的语句,按照词语含义对其添加第三标签。例如句子“考古学家于1965年五一节在云南省元谋县上那蚌村发现了元谋人牙齿化石”,经过分词处理标签化后,得到的标签序列和前述的句子的标签序列完全相同,但是显而易见,二者内容是截然不同的,因此需要进行区分。在本实施方式中,三种标签的添加顺序并无限定。
分类模块120用于识别知识驱动处理后的语句,将标签序列不同的相同含义的语句分类到同一语句簇。通过分类模块120的处理,将每一单语平行语料库内的语句分为多个不同的语句簇,每个语句簇中包含同一语义的语句的全部的句式结构类型,此时标签序列相同的语句具有相同的句式结构。
映射模块130分析每一单语平行语料库的语句簇中的语句,确定每一单语平行语料库的语句簇中所有语句的句式结构类别,确定并记录存储同一语句簇中不同句式结构类别之间进行变换时,相应的所述句式结构之间的标签变换的映射方式。在本实施方式中,其中一个语句簇中存储了m种句式结构,则m种结构相互之间可生成m(m-1)/2种映射关系,所有的语句簇中的句式结构进行映射,确定并记录存储生成的映射方式。
句式结构生成模块140查找每一单语平行语料库的每一语句簇中相同的第一类别句式结构,并根据语句簇其中之一者的第一类别句式结构与同一语句簇中其他类别句式结构的映射方式,在其余的语句簇中对第一类别句式结构按照映射方式分别进行映射,在其余的语句簇中生成相应的句式结构类别。
句式结构生成模块140查找所有单语平行语料库中每一语句簇中相同的第一类别句式结构,并根据语句簇其中之一者的第一类别句式结构与同一语句簇中其他类别句式结构的第一类映射方式,在其余的语句簇中对第一类别句式结构按照映射方式分别进行映射,生成相应的句式结构类别。在本实施方式中,任选一个单语平行语料库的一个语句簇,和其他单语平行语料库中的全部语句簇逐一比较。假设有n个单语平行语料库,则进行n(n-1)/2比较,找出对比的两个语句簇中相同的句式结构。在本实施方式中,对比语句簇k和语句簇l,语句簇k中有同义的句式结构a、b、c、d和e,语句簇l中有同义的句式结构d、e和f,则在语句簇k和l中,有两个相同类型的句式结构d和e。经过映射模块130的处理,句式结构d、e在语句簇k中分别同a、b、c生成映射关系并记录映射方式,在语句簇l中同句式结构f生成映射关系并记录映射方式。此时在语句簇l中,根据句式结构d、e在语句簇k中与a、b、c的映射方式,在语句簇l中建立相应的映射关系a’、b’、c’,在语句簇k中,根据句式结构d、e在语句簇l中与f的映射方式,在语句簇k中建立相应的映射关系f”,此时生成新的语句簇中包含5种类型的句式结构。
语料生成模块150对所有语句簇中生成的句式结构嵌套语句簇中句式结构的序列标签对应的词语,获得语料。多个新生成的语句簇组合,生成新的单语平行语料库。语料生成模块150包括标签识别单元151和语料生成单元152,标签识别单元151识别每一语句簇中全部句式结构中的标签,语料生成单元152将每一语句簇中全部句式结构中的标签对应的词语嵌套到句式结构中,生成语料。语料生成单元152是按照分词模块110的标签化标准对所述句式结构进行嵌套。在本实施方式中,经句式生成模块140生成的句式结构中包含标签ns,则根据该语句簇的语句含义嵌套词义,如可嵌套“小红”,或“考古学家”。
区别于现有技术,本发明的语料生成装置在通过将现有语料库中的语句进行标签化,将标签序列不同的句式格式根据句式的标签进行映射,得到更多的句式结构,填充嵌套标签对应的词语后得到更多的语料。通过本发明,能够通过将词语嵌套到扩充得到的句式结构中获取语料,操作简单,节省资源,同时较大程度的扩充了语料库。
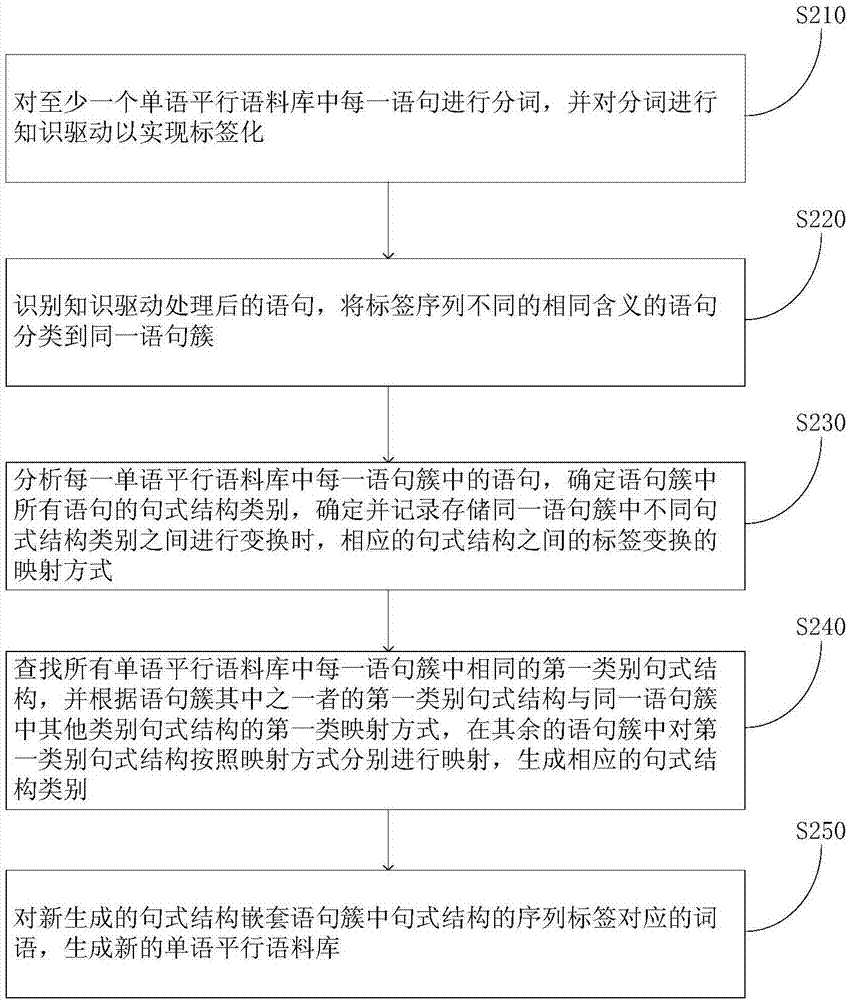
参阅图2,图2是本发明提供的一种语料生成方法的实施方式的流程示意图。该方法的步骤包括:
s210:对至少一个单语平行语料库中每一语句进行分词,并对分词进行知识驱动以实现标签化。
连接单语平行语料库,用于对平行语料库内的语句进行分词,并在分词后进行知识驱动以对语句进行标签化。分词的方法通常为采用分词工具软件。
分词并标签化的步骤包括:
s211:对所述平行语料库内的语句进行分词。
连接到网络的分词工具软件,将待分解的语句导入到分词工具软件中进行分词操作。
s212:按照词语的词性对分词处理后的所述语句添加第一标签。
选定语料库中的语句“小红明天下午要去深圳市科技馆九层会议室参加科普知识讲座”,经过分词操作后,得到“小红/明天/下午/要/去/深圳市/科技馆/九层/会议室/参加/科普/知识/讲座”。其中,小红、深圳市、科技馆、会议室和讲座为名词,按照词性为上述7个词语标注相同的第一标签,通常标注为n(noun);明天和下午表征时间,第一标签标注为t(time);参加为动词,第一标签标注为v(verb);要、去、九层和科普知识为附加词语,可省略不做标记。
s213:按照词语在句中成分对已添加所述第一标签的语句添加第二标签。
第一标签标注完成后,继续进行二级标注。对于第一标签为名词的小红、深圳市、科技馆、会议室和讲座,小红为人物性的名词,为句中主语,第二标签标注为ns(noun/subject);深圳市、科技馆和会议室分别为表征地点的名词,通常为状语adverbialmodifier,但是所指的地点范围有所区别,深圳市、科技馆和会议室三者代表的范围为从大到小,因此可标注为nam1、nam2和nam3;讲座为句中宾语,标注为no对于表征时间的名词明天和下午,按照时间范围的大小,可标注为t1和t2。标注标签完成后,语料库中的语句均可以通过标签序列表征,如上述语句可标注为“nst1t2nam1nam2nam3vno”。
s214:对经标签化处理后标签序列相同的不同含义的语句,按照词语含义对语句添加第三标签。
对经标签化处理后标签序列相同的不同含义的语句,按照词语含义对其添加第三标签。例如句子“考古学家于1965年五一节在云南省元谋县上那蚌村发现了元谋人牙齿化石”,经过分词处理标签化后,得到的标签序列和前述的句子的标签序列完全相同,但是显而易见,二者内容是截然不同的,因此需要进行区分。
s220:识别知识驱动处理后的语句,将标签序列不同的相同含义的语句分类到同一语句簇。
识别分词处理后的语句,将标签序列不同的相同含义的语句分类到同一语句簇。将语料库内的语句分为多个不同的语句簇,每个语句簇中包含同一语义的语句的全部的句式结构类型,此时标签序列相同的语句具有相同的句式结构。
s230:分析每一单语平行语料库中每一语句簇中的语句,确定语句簇中所有语句的句式结构类别,确定并记录存储同一语句簇中不同句式结构类别之间进行变换时,相应的句式结构之间的标签变换的映射方式。
分析每一语句簇中的语句,确定语句簇中所有语句的句式结构类别,确定并记录存储同一语句簇中不同句式结构类别之间进行变换时,相应的所述句式结构之间的标签变换的映射方式。在本实施方式中,其中一个语句簇中存储了m种句式结构,则m种结构相互之间可生成m(m-1)/2种映射关系,所有的语句簇中的句式结构进行映射,确定并记录存储生成的映射方式。
s240:查找所有单语平行语料库中每一语句簇中相同的第一类别句式结构,并根据语句簇其中之一者的第一类别句式结构与同一语句簇中其他类别句式结构的第一类映射方式,在其余的语句簇中对第一类别句式结构按照映射方式分别进行映射,生成相应的句式结构类别。
分析每一语句簇,查询所有语句簇中的句式结构。在本实施方式中,任选其中一个语句簇,和其他语句簇逐一比较。假设有n个单语平行语料库,则进行n(n-1)/2比较,找出对比的两个语句簇中相同的句式结构。在本实施方式中,对比语句簇k和语句簇l,语句簇k中有同义的句式结构a、b、c、d和e,语句簇l中有同义的句式结构d、e和f,则在语句簇k和l中,有两个相同类型的句式结构d和e。经过映射模块130的处理,句式结构d、e在语句簇k中分别同a、b、c生成映射关系并记录映射方式,在语句簇l中同句式结构f生成映射关系并记录映射方式。此时在语句簇l中,根据句式结构d、e在语句簇k中与a、b、c的映射方式,在语句簇l中建立相应的映射关系a’、b’、c’,在语句簇k中,根据句式结构d、e在语句簇l中与f的映射方式,在语句簇k中建立相应的映射关系f”,此时在语句簇k和l中,均包含5种类型的句式结构,句式结构得到扩展。
全部的语句簇经过两两对比,每一语句簇都经过扩展,最终每一语句簇中都包含与所有语句簇中句式结构并集数量相同的句式结构。
s250:对新生成的句式结构嵌套语句簇中句式结构的序列标签对应的词语,生成新的单语平行语料库。
获取语料的步骤包括:
s251:识别所有单语平行语料库中每一语句簇中全部句式结构中的标签。
识别每一语句簇中全部句式结构中的标签,按照标签化标准对句式结构进行嵌套。
s252:将每一语句簇中全部句式结构中的标签对应的词语嵌套到句式结构中,生成新的单语平行语料库。
将每一语句簇中全部句式结构中的标签对应的词语嵌套到句式结构中,生成新的语句簇。多个新生成的语句簇组合,生成新的单语平行语料库。在本实施方式中,生成的句式结构中包含标签ns,则根据该语句簇的语句含义嵌套词义,如可嵌套“小红”,或“考古学家”。
区别于现有技术,本发明的语料生成方法在通过将现有语料库中的语句进行标签化,将标签序列不同的句式格式根据句式的标签进行映射,得到更多的句式结构,填充嵌套标签对应的词语后得到更多的语料。通过本发明,能够通过将词语嵌套到扩充得到的句式结构中获取语料,操作简单,节省资源,同时较大程度的扩充了语料库。
以上所述仅为本发明的实施方式,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!