实时互动动画的全息投影系统、方法及人工智能机器人与流程
本发明涉及人工智能领域,尤其涉及一种实时互动动画的全息投影系统、方法及人工智能机器人。
背景技术:
VR(Virtual Reality,即虚拟现实,简称VR),是综合利用计算机图形系统和各种现实及控制等接口设备,在计算机上生成的、可交互的三维环境中提供沉浸感觉的技术。而全息投影技术(front-projected holographic display)也称虚拟成像技术,是利用干涉和衍射原理记录并再现物体真实的三维图像的技术。目前,全息投影技术已经较多应用于对VR图像的显示上。
此外,机器人与人的交互方式主要以语音或者简单的动作为主要交互方式,这种交互方式比较单一,且随着科技的发展,这些交互方式越来越普遍,越来越不能满足用户的追求。因此,将VR技术与机器人交互进行结合,是现代科技亟待解决的问题。
技术实现要素:
为了解决上述问题,本发明提供一种实时互动动画的全息投影系统、方法以及人工智能机器人。
在一个实施例中,提供一种实时互动动画的全息投影系统,包括:运动捕捉模块,包括至少4个取像单元,用于实时捕捉采集对象的至少4个角度的运动数据;图像处理模块,用于实时接收并处理所述运动数据以生成运动驱动数据,并根据所述运动驱动数据,驱动渲染虚拟对象以实时生成动画影像数据;以及全息投影模块,用于将所述动画影像数据投影到全息设备上并显示。
在另一个实施例中,提供一种实时互动动画的全息投影方法,包括:通过至少4个取像单元实时捕捉采集对象的至少4个角度的运动数据;实时接收并处理所述运动数据以生成运动驱动数据,并根据所述运动驱动数据,驱动渲染虚拟对象以实时生成动画影像数据;以及将所述动画影像数据投影到全息设备上并显示。
在又一个实施例中,提供一种人工智能机器人,与一人工智能服务器连接,且至少包括上述的实时互动动画的全息投影系统,所述全息投影系统根据所述人工智能服务器的输出指令,投影全息动画。
本发明的人工智能机器人,通过结合全息投影系统,所述系统包括:运动捕捉模块,包括至少4个取像单元,用于实时捕捉采集对象的至少4个角度的运动数据;图像处理模块,用于实时接收并处理所述运动数据以生成运动驱动数据,并根据所述运动驱动数据,驱动渲染虚拟对象以实时生成动画影像数据;以及全息投影模块,用于将所述动画影像数据投影到全息设备上并显示,从而能够将虚拟现实技术与人工智能进行结合,大大提高了用户与机器人的交互体验感。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的人工智能机器人的工作状态示意图;
图2为本发明实施例提供的实时互动动画的全息投影系统的功能模块图;
图3为本发明一实施例提供的实时互动动画的全息投影方法的流程图;
图4为本发明另一实施例提供的实时互动动画的全息投影方法的流程图。
具体实施方式
下面结合附图和具体实施方式对本发明的技术方案作进一步更详细的描述。显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
请参阅图1,本发明提供一种人工智能机器人100,其与一人工智能服务器200数据连接。所述机器人100至少包括一实时互动动画的全息投影系统10。所述全息投影系统10根据所述人工智能服务器200的输出指令,投影一全息动画。
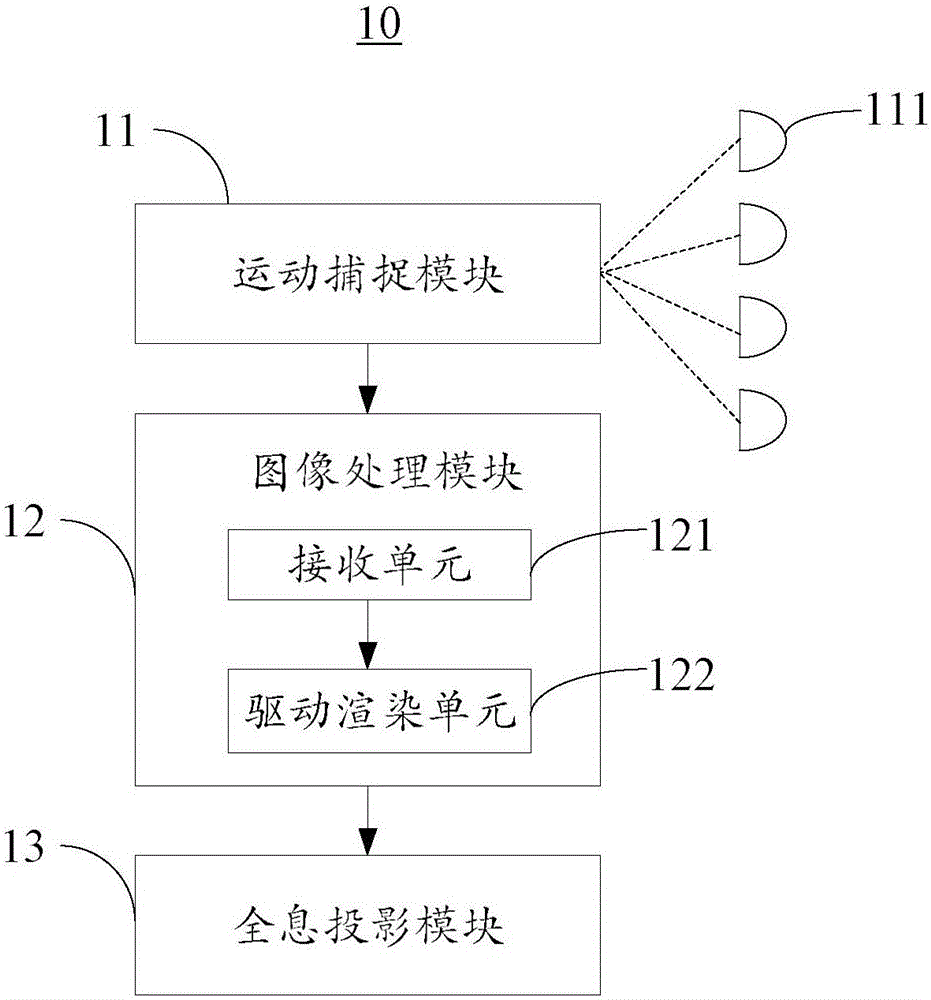
请参阅图2,具体的,所述实时互动动画的全息投影系统10包括运动捕捉模块11、图像处理模块12以及全息投影模块13。
所述运动捕捉模块11包括至少4个取像单元111,用于实时捕捉采集对象的至少4个角度的运动数据。本实施例中,所述运动捕捉模块11包括4个取像单元111,所述取像单元111分别捕捉采集对象前、后、左、右四个角度的运动数据。此外,在本实施例中,所述采集对象是具有动画效果的3D软件模型,所述运动数据包括以下至少之一:表情数据、动作数据、特效数据、控制指令,所述运动数据可从所述运动模型中截取出来。
在一个实施例中,所述运动捕捉模块包括表情数据采集单元以及动作数据采集单元至少其中之一。所述表情数据采集模用于分析所述模型中包含所述采集对象面部的图像数据,并根据所述面部图像数据确定所述表情数据。其中,所述面部的图像数据包括以下至少之一:面部整体轮廓的位置,眼睛的位置,瞳孔的位置,鼻子的位置,嘴的位置,眉毛的位置。所述动作数据采集单元用于采集与所述采集对象对应的动作数据,其中,所述动作数据包括所述采集对象的当前动作的世界坐标的位置和旋转角度。
在其他实施例中,所述运动捕捉模块还可包括更多类型的采集摸块,例如周边环境采集模块等。
所述图像处理模块12用于实时接收并处理所述运动数据以生成运动驱动数据,并根据所述运动驱动数据,驱动渲染虚拟对象以实时生成动画影像数据。本实施例中,所述图像处理模块12至少包括接收单元121以及驱动渲染单元122。
所述接收单元121用于通过一个或多个通道,分别接收所述至少4个角度的运动数据。本实施例中,所述接收模块从所述4个取像单元111接收到所述3D模型4个角度的运动数据。所述运动数据是3D画的4个视角的平面图像,且所述平面图像以四分屏方式同时显示在一个屏幕上。
所述驱动渲染单元122用于根据所述运动驱动数据,驱动并渲染对应于所述多个取像单元111视口的不同视角的所述虚拟对象,将渲染出的不同视角的所述虚拟对象合成多视口的所述动画影像数据。
所述全息投影模块13用于将所述动画影像数据投影到全息设备131(图1)上并显示。本实施例中,所述全息设备131是以四棱锥为成像载体的设备。
所述人工智能服务器200用于以下至少其中之一:对所述运动数据进行时间同步处理,以使同步处理后的所述运动数据与采集的音频数据同步;以及对所述运动数据进行均匀帧率的处理。
请参阅图3,本发明还提供一种实时互动动画的全息投影方法,包括:
步骤S301,通过至少4个取像单元111实时捕捉采集对象的至少4个角度的运动数据。本实施例中,所述采集对象是具有动画效果的3D模型,所述运动数据包括以下至少之一:表情数据、动作数据、特效数据、控制指令。更具体来说,本实施例中,所述步骤S301包括以下子步骤至少其中之一:
分析所述模型中包含所述采集对象面部的图像数据,并根据所述面部图像数据确定所述表情数据,其中,所述面部的图像数据包括以下至少之一:面部整体轮廓的位置,眼睛的位置,瞳孔的位置,鼻子的位置,嘴的位置,眉毛的位置;以及
采集与所述采集对象对应的动作数据,其中,所述动作数据包括所述采集对象的当前动作的世界坐标的位置和旋转角度。
步骤S302,实时接收并处理所述运动数据以生成运动驱动数据,并根据所述运动驱动数据,驱动渲染虚拟对象以实时生成动画影像数据。具体来说,所述驱动渲染虚拟对象以实时生成动画影像数据的步骤包括:根据所述运动驱动数据,驱动并渲染对应于所述多个取像单元111视口的不同视角的所述虚拟对象,将渲染出的不同视角的所述虚拟对象合成多视口的所述动画影像数据。
步骤S303,将所述动画影像数据投影到全息设备131上并显示。
请参阅图4,在另外一个实施例中,所述方法还包括:
步骤S304,对所述运动数据进行时间同步处理,以使同步处理后的所述运动数据与采集的音频数据同步;以及
步骤S305,对所述运动数据进行均匀帧率的处理。
本发明的人工智能机器人100,通过结合全息投影系统10,所述系统包括:运动捕捉模块11,包括至少4个取像单元111,用于实时捕捉采集对象的至少4个角度的运动数据;图像处理模块12,用于实时接收并处理所述运动数据以生成运动驱动数据,并根据所述运动驱动数据,驱动渲染虚拟对象以实时生成动画影像数据;以及全息投影模块13,用于将所述动画影像数据投影到全息设备131上并显示,从而能够将虚拟现实技术与人工智能进行结合,大大提高了用户与机器人的交互体验感。
需要说明的是,通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本发明可借助软件加必需的硬件平台的方式来实现,当然也可以全部通过硬件来实施。基于这样的理解,本发明的技术方案对背景技术做出贡献的全部或者部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例或者实施例的某些部分所述的方法。
以上所揭露的仅为本发明实施例中的较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!