用于处理质谱数据的技术的制作方法
本申请要求2015年5月29日提交的名称为“TECHNIQUES FOR PROCESSING OF MASS SPECTRAL DATA”的美国临时专利申请62/168,123的优先权,该专利申请以引用方式并入本文。
技术领域
本申请整体涉及用于处理从样品的质谱分析获得的数据的技术。
背景技术:
质谱分析(MS)广泛用于识别和定量样品中的分子种类。在分析过程中,来自样品的分子被引入到质量分析仪中,并被离子化以获得电荷,从而形成离子。分析仪对每个分子离子做出响应,得到离子质量与他们获得的电荷的比值;该值也就是质荷比m/z。检测器产生一个与离子在特定m/z下的强度有关的信号。
在将样品注入质谱仪之前,可以执行色谱分离技术。色谱分析是一种用于分离化合物的技术,诸如用于分离在溶液中保存的那些化合物,其中化合物将对与溶液接触的分离介质表现出不同的亲和力。当溶液流经这种不流动的介质时,化合物会彼此分离。常用的色谱分离仪器包括气相色谱仪(GC)和液相色谱仪(LC)。当联接到质谱仪时,所得到的系统称为GC/MS或LC/MS系统。GC/MS或LC/MS系统通常是在线系统,其中GC或LC的输出直接联接到MS。
在LC/MS系统中,在特定时间将样品注入液相色谱系统,这会触发系统采集数据。液相色谱法使样品随时间洗脱,导致分离出的分析物离开色谱柱。特定分析物离开色谱柱的时间称为保留时间。离开液相色谱仪的洗脱液被持续引入质谱仪的电离源。随着分离的进行,MS产生的质谱的组成发生变化,并且反映洗脱液的组成的变化。
通常,基于计算机的系统以定期时间间隔对质谱进行采样并记录。离子的强度响应是在其质谱中看到的峰的高度或面积。常规LC/MS系统产生的质谱可以被进一步分析。通过检查包含离子的质谱峰(强度与m/z关系)来推导离子的质量或质荷比测量。
通过检查包含离子的色谱峰(强度与时间关系)来推导离子的保留时间测量。
还可以执行质谱分析的两个阶段(MS/MS也称为串联质谱法)。MS/MS的一种独特模式被称为产物离子扫描,其中在质谱分析的第一阶段,由第一质量过滤器/分析器选择特定m/z值的母体前体离子。然后将选定的前体离子送到碰撞室,这些离子在那里被碎片化以产生产物碎片离子。然后由第二质量过滤器/分析仪分析产物碎片离子。
技术实现要素:
根据本文的技术的一个方面,一种执行样品分析的方法包括:使用包括执行质谱分析的质谱仪的一个或多个仪器分析样品,其中所述质谱仪根据调度在所述分析中操作,所述调度包括用于多个循环的质量隔离窗口,每个循环包括多次扫描,其中所述分析包括:在所述多个循环中的每个循环开始时执行第一低能量扫描,所述第一低能量扫描具有表示前体离子的m/z范围的关联m/z范围;以及在升高能量扫描中迭代地使用不同的质量隔离窗口,直到已经针对第一低能量扫描的关联m/z范围执行了碎片化;获得实验数据作为所述分析的结果,所述实验数据包括当使用质谱仪执行一次或多次低能量数据采集时获得的低能量扫描数据;使用低能量扫描数据确定前体电荷簇;以及通过将前体电荷簇的识别第一前体离子的一部分链接在一起来确定第一前体离子的峰轮廓,所述部分中的每个所述前体电荷簇来自不同的低能量扫描。该方法可包括确定具有多个维度的有界区域,所述多个维度包括m/z和保留时间;以及在升高能量扫描中迭代地使用不同的质量隔离窗口,直到已经针对有界区域执行了碎片化。所述分析可包括执行离子淌度谱分析,并且有界区域的多个维度包括漂移时间。调度器可以跟踪是否已经针对第一低能量扫描的关联m/z范围执行了升高能量数据采集。质量隔离窗口的至少第一部分可以具有根据选择大致相同数量的前体离子来进行碎片化而确定的尺寸和关联m/z范围,并且所述分析可以包括针对所述第一部分中的每个质量隔离窗口执行升高能量数据采集,由此在所述每个质量隔离窗口内具有m/z值的伴随低能量扫描的离子在所述升高能量数据采集中被碎片化。调度可以包括用于多个循环中的每个循环的循环时间,该循环时间是根据中值和均值色谱峰宽以及在所述多个循环中的每个循环中执行的扫描的最小数量中的任一个而确定的。调度的质量隔离窗口可以包括窄带质量隔离窗口和宽带质量隔离窗口。窄带隔离窗口中的每一个可以具有范围从第一最小值到第一最大值的对应尺寸,并且所述宽带隔离窗口可以具有范围从第二最小值到第二最大值的对应尺寸,其中所述第一最大值可以小于所述第二最小值。窄带质量隔离窗口和宽带质量隔离窗口中的每一个的中心m/z值可以随着扫描循环而改变。该方法可以包括执行第一处理以构造第一低能量扫描的第一前体电荷簇,所述第一处理包括:选择第一低能量扫描中的第一离子,该第一离子具有在第一低能量扫描中的所有离子中的最低m/z值的第一m/z;接收多个Δm/z值,所述多个Δm/z值中的每一个与多个电荷态中不同的一个相关联,其中所述每个Δm/z值表示具有所述多个电荷态中相关联的不同一个的同位素簇中的任意两个连续同位素之间的理论m/z距离;根据所述多个电荷态的降序排列来遍历所述多个Δm/z值,以确定在所述第一低能量扫描中是否存在具有等于所述多个Δm/z值中的一个与第一离子的第一m/z之和的关联m/z值的第二离子,其中所述遍历步骤在定位能够作为所述第二离子的单个离子之后终止;以及响应于确定在所述第一低能量扫描中存在具有等于所述多个Δm/z值中的一个与第一离子的第一m/z之和的关联m/z值的第二离子,确定该第二离子是链中第一离子之后的下一个同位素。该方法可以包括将附加离子从第一低能量扫描添加到链,其中附加离子中的每一个具有等于第一m/z与所述多个Δm/z值中的所述一个的倍数之和的关联m/z。第一低能量扫描中的离子链可以是候选前体电荷簇,并且该方法可以包括使用同位素模型执行处理以验证候选前体电荷簇。处理可以包括根据同位素模型修正包括在候选前体电荷簇中的离子的属性。用于第一前体离子的第一前体电荷簇可以被包括在第一低能量扫描中,并且该方法可以包括基于质量误差确定在第一低能量扫描中是否存在对第一前体离子的干扰,由此另一种离子共洗脱与第一前体离子相同的时间的至少一部分;确定第一低能量扫描中的第一前体离子的第一质量误差是否不在已定义的可接受质量误差范围内;响应于确定第一质量误差不在已定义的可接受质量误差范围内,确定存在对第一前体离子的干扰;确定对于第一低能量扫描之后的多次扫描,存在对第一前体离子的干扰,其中所述多次扫描的质量误差在已定义的可接受质量误差范围内;确定在所述多次扫描之后的第二低能量扫描中,前体离子的第二质量误差是否在已定义的可接受质量误差范围内,以及第二质量误差是否是相对于第一质量误差的互补质量误差值;以及响应于确定第二质量误差不在已定义的可接受质量误差范围内并且不是相对于第一质量误差的互补质量误差值,确定对第一前体离子的干扰结束并且第二质量误差是第一质量误差的互补质量误差值。实验数据可以包括当使用质谱仪执行升高能量数据采集时获得的升高能量扫描数据。前体电荷簇的一部分可以被包括在具有对应的升高能量扫描的第一组低能量扫描中,该升高能量扫描包括由于将第一组低能量扫描中的前体电荷簇碎片化而生成的碎片离子。该方法可以包括从前体电荷簇的该部分中选择第一前体电荷簇,所述第一前体电荷簇被包括在具有对应的第一高能扫描的第一低能量扫描中;以及确定第一升高能量扫描中产生自第一前体电荷簇的碎片化的一个或多个碎片离子的碎片组。该方法可以包括构造包括第一前体电荷簇和碎片组的复合前体产物离子谱;以及将复合前体产物离子谱存储在数据库中。前体电荷簇的链接在一起以形成峰轮廓的该部分中的每个前体电荷簇可处于不同的低能量扫描中,并且每个前体电荷簇可具有关联离子电流,该关联离子电流表示所述每个前体电荷簇相对于所述不同的低能量扫描中的总离子强度的强度。第一低能量扫描中的第一前体电荷簇可以具有该部分中的前体电荷簇的所有离子电流中的最大离子电流。样品可以包括一种或多种蛋白质。可以使用最少五个点来形成峰。该方法可以包括执行包括所述样品的多个样品的多次进样;以及使用所述一个或多个仪器分析所述多个样品中的每一个,所述分析所述多个样品中的每一个包括:在高能扫描中迭代地使用不同的质量隔离窗口,直到已经针对具有第二多个维度的第二有界区域执行了碎片化,所述第二多个维度包括m/z和保留时间,其中由于样品分析跨越所述多次进样中的至少两次连续进样,所述第二界限区域被完全采样第一时间,由此第一实验数据作为输入被提供到调度器,第一实验数据是作为分析所述两次连续进样中的第一进样中的多个样品中的第一个的结果而获得的,所述调度器自动确定用于所述两个连续进样中的第二进样的第二调度,其中调度器使用第一实验数据来确定第二有界区域的尚未被采样的第一部分并结合针对第二进样执行的样品分析来安排对第一部分的采样。第二有界区域的第二多个维度可以包括漂移时间,并且对第二有界区域进行完全采样可以包括对与第二有界区域的第二多维度中的每个维度相关联的范围进行完全采样。调度器用来确定第二调度的第一实验数据可以包括以下中的任何一者或多者:关于离子通量的信息,离子通量表示多个不同m/z范围区段中的每一个中的检测离子的频率;保留时间相对于采样m/z的分布;漂移时间相对于采样m/z的分布;以及漂移时间相对于采样保留时间的分布。
根据本文技术的另一方面,一种系统包括:一个或多个仪器,包括执行质谱分析的质谱仪;执行代码的处理器;以及包括存储在其上的代码的存储器,其中代码在被执行时,执行一种样品分析方法,该样品分析方法包括:使用一个或多个仪器分析样品,其中所述质谱仪根据调度在所述分析中操作,所述调度包括用于多个循环的质量隔离窗口,每个循环包括多次扫描,其中所述分析包括:在所述多个循环中的每个循环开始时执行第一低能量扫描,所述第一低能量扫描具有表示前体离子的m/z范围的关联m/z范围;以及在升高能量扫描中迭代地使用不同的质量隔离窗口,直到已经针对第一低能量扫描的关联m/z范围执行了碎片化;获得实验数据作为所述分析的结果,所述实验数据包括当使用质谱仪执行一次或多次低能量数据采集时获得的低能量扫描数据;使用低能量扫描数据确定前体电荷簇;以及通过将前体电荷簇的识别第一前体离子的一部分链接在一起来确定第一前体离子的峰轮廓,所述部分中的每个所述前体电荷簇来自不同的低能量扫描。
附图说明
在附图的所有不同视图中,相似的参考编号通常指示相同的部件。而且,附图不一定按比例绘制,而重点通常在于示出本文所述的技术的原理。
图1是根据本文技术的一个实施例的系统的框图;
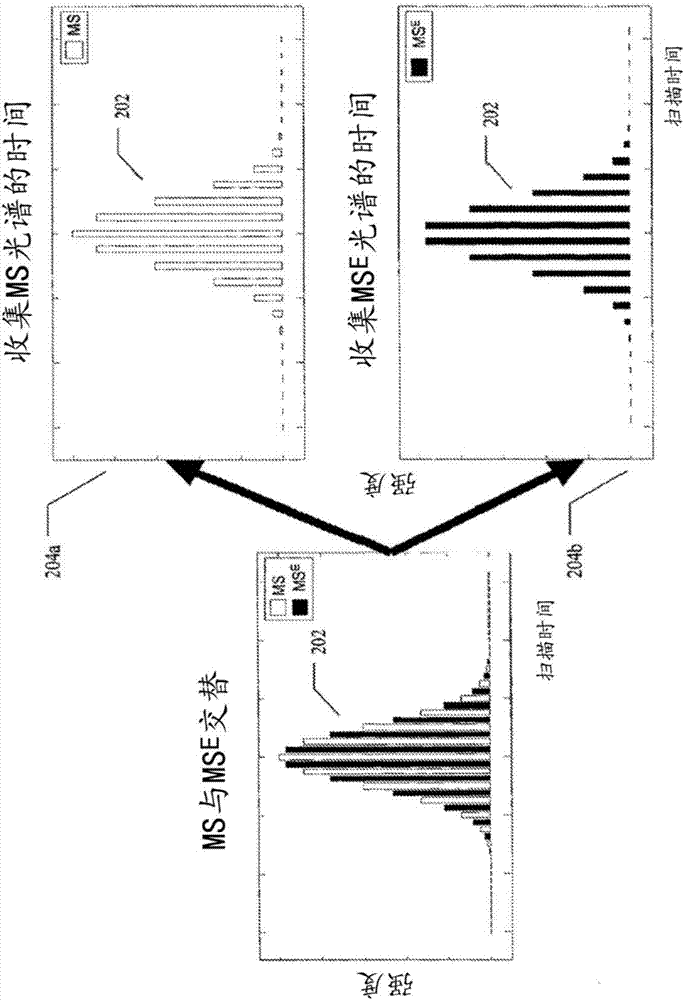
图2显示了三个相关的图,示出了根据本文技术的一个实施例的质谱的收集;
图3是可以在根据本文技术的一个实施例中使用的部件和数据的例子;
图4和图5是可以在根据本文技术的一个实施例中使用的MS扫描数据的例子;
图6和图6a是示出可以在根据本文技术的一个实施例中执行的处理的例子,该处理用于生成包括在分子的指纹或模式中的信息;
图7是可以在根据本文技术的一个实施例中采用逐次扫描的方式检测的PCC(前体电荷簇)的洗脱峰的例子;
图8是可以在根据本文技术的一个实施例中使用的信息的表格;
图9、图10、图11、图13、图14、图14A、图17、图20、图24、图27、图28和图33B是可以在根据本文技术的一个实施例中执行的处理步骤的流程图;
图12是可以包括在根据本文技术的一个实施例中的分子指纹中的信息的例子;
图15和图16是可以在根据本文技术的一个实施例中的洗脱时间内使用的不同碰撞能量设置的图示;
图18是可以包括在蛋白质抗体(PA)中的信息的例子,该蛋白质抗体在根据本文技术的一个实施例诸如监督聚类中使用;
图19、图21、图22和图26是示出可以在根据本文技术的一个实施例中执行的各种工作流程的例子;
图23是可以在根据本文技术的一个实施例中使用的前体Δ质量修正和相关单一同位素质量的表格例子;
图25是示出二硫键形成的例子;
图29是示出可以在根据本文技术的一个实施例中使用的前体离子m/z(质荷比)值在各个保留时间处的频率分布的例子;
图30是示出根据本文描述的执行多模式采集(MMA)技术的一个实施例的在不同循环扫描中的可变质量隔离窗口(MIW)和数据采集的例子;
图31是可以在本文所述的MMA技术的一个实施例中使用的不同m/z区段或区间的频率分布直方图的例子;
图32是示出包括可以在根据本文技术的一个实施例中使用的MIW设置的例子,该MIW设置包括在单个循环中变化的m/z窗口和变化的宽度;
图33是可以在根据本文技术的一个实施例中使用的各种预定碰撞能量值的表格的例子;
图34是示出使用内插法确定前体离子或PCC强度的例子,所述内插诸如可以在根据本文技术的一个实施例中结合各种数据采集技术来执行的内插;
图35是示出可以在根据本文技术的一个实施例中使用的工作流程的例子;
图36A和图36B是可以在根据本文技术的一个实施例中使用的模拟器输入的例子;
图37是在执行图35的工作流程的一个实施例中与调度相关联的输入和输出的例子;
图38是可以在根据本文技术的一个实施例中图35的工作流程中使用的空间映射的例子;
图39是示出可以在根据本文技术的一个实施例中使用的电荷态向量的例子;
图40是可以在根据本文技术的一个实施例中结合将电荷态分配给前体电荷簇而使用的表格的例子;
图41、图46A和图46B是可以在根据本文技术的一个实施例中执行的处理步骤的流程图;
图42、图43和图44是可以在根据本文技术的一个实施例中执行的各种技术的图示;并且
图45是根据本文技术的一个实施例中的强度过滤的图形表示。
具体实施方式
如本文所用,以下术语通常是指所述的含义:
“色谱法”-是指用于分离化学化合物的设备和/或方法。色谱设备通常使流体和样品分析物在压力和/或电和/或磁力下移动。根据上下文,“色谱图”一词在本文中是指通过色谱工具导出的数据或数据的表示。色谱可以包括一组数据点,每个数据点由两个或更多个值构成;这些值中的一个可以是扫描时间或对应的色谱保留时间值,并且其余的值通常与强度或量级的值相关联,后者又对应于样品的洗脱组分的量或浓度。结合本文的技术,样品分析物可以包含关注的一种或多种化合物、分子或组分。
样品分析物可以是指组合物、混合物、溶液、材料、固体、组织,或者更一般地说,是指待分析的任何物质。结合本文的技术,样品可以包含关注的一种或多种化合物、分子或组分。样品或关注的化合物通常可以是或包括任何分子,包括例如小分子诸如有机化合物、代谢物和有机化合物,以及更大的分子诸如蛋白质或肽。
保留时间-在上下文中是指色谱图中当洗脱组分达到其最大强度的时间。
离子-在上下文中是使用质谱仪(MS)检测的样品分析物的离子化分子,并且是由于在LC/MS系统中执行实验而产生的。由此,离子的特征在于其保留时间、m/z(质荷比)和强度测量值。
LE -(碰撞室的低能量状态)是指前体离子数据,并且与采集方法无关。可以利用数据相关采集模式和数据无关采集模式来采集LE数据。
HE -(碰撞室的高能量状态)是指产物/碎片离子数据,并且与采集方法无关。可以利用数据相关采集模式和数据无关采集模式来采集HE数据。高能量模式也可以被称为升高能量(EE)模式。
漂移-在上下文中是指气相中离子的迁移率的测量。质谱仪内置的一个附加实验单元根据气相离子的迁移率将其分离,从而提供离子分离的附加维度;就漂移以及m/z而言。离子迁移率与离子化分子的通过适当校准和漂移时间转换表示为碰撞横截面积(CCSA)的结构尺寸有关。这种技术被称为离子淌度谱分析(IMS)。
离子指纹-是指分子实体的经过验证的产物离子谱,包括在验证中使用的所有实验数据中每个产物离子的相对强度变化的量度。
在根据本文技术的一个实施例中,离子的强度值可以基于其曲线下面积(AUC),表示对应于其测量强度的峰。每个强度值可以被确定为诸如由记录脉冲的高斯分布形成的曲线下面积。因此,如本文所述的各种强度比可以表征为面积比。
通常,LC/MS系统可以用于执行样品分析,并且可以提供对例如蛋白质或肽以及小分子诸如药物或除草剂的质量、电荷、保留(洗脱)时间和强度的实证描述。当分子从色谱柱中洗脱出来时,它的强度轮廓或峰形会出现在一个特定的时间段,并在其保留时间处达到其最大值或峰值信号。在离子化和(可能的)碎片化(诸如结合质谱分析)后,该化合物表现为相关的一组离子。
在LC/MS分离中,离子化分子可以以单个或多个带电状态存在。MS/MS也可以被称为串联质谱法,其可以与LC分离组合进行(例如,表示为LC/MS/MS)。
现在将参照用于分析样品的示例性方法和装置来描述技术和实施例,诸如可以用于在通过执行LC/MS实验来分析样品的系统中的样品分析。应当理解,本文所述的技术可以结合其他实施例使用,并且具有比本文中为了说明和例示的目的可提供和列出的技术更广泛的应用。
图1是可以结合本文的技术使用的系统的示意图。样品102通过进样器106进样到液相色谱系统104的流体流中。泵108向进样器供应流动相溶剂,并将样品泵送通过色谱柱110以将样品分析物混合物分离成洗脱组分,洗脱组分离开色谱柱并通过其保留时间被观察。
色谱柱的输出被引入到质谱仪112中用于分析。应该指出的是,在实施例中使用的质谱仪112中包括的特定部件可以随着所使用的具体类型的质谱仪而变化。在描述了元件112之后,为了简明起见,一些可以包括在质谱仪112中的部件并未在图1中未示出。最初,样品由质谱仪的去溶剂化/离子化设备去溶剂化并且离子化。去溶剂化可以是任何技术,包括例如加热器、气体,与气体组合的加热器或其他去溶剂化技术。离子化可以采用任何离子化技术来实现,包括例如电喷雾离子化(ESI)、大气压化学离子化(APCI)、基质辅助激光解吸(MALDI)或其他离子化技术。由离子化产生的离子被送入质谱仪的碰撞室,同时电压梯度被施加到离子导向器。碰撞室可用于传递前体离子(以低能量模式)或将前体离子碎片化(以高能量模式)。
如在本文其他地方更详细地描述的那样,可以使用不同的技术,包括在授予Bateman等人的美国专利6,717,130(“Bateman”)中所述的技术,其中可以在碰撞室上施加交变电压来引起碎片化,该专利以引用方式并入本文。收集低能量下的前体(无碰撞)以及高能量下的碎片(碰撞的产物)的光谱。
一种另外的技术包括串联应用质量选择窗口,其中前体离子是根据m/z;m/z和强度;m/z、强度和离子迁移率漂移这些标准来选择的,或通过包括或排除目标化合物的列表来选择,包括以下中的任一种:m/z;m/z和强度;m/z、强度和漂移。在这里选择一个m/z值,第一质量分析仪(通常是四极杆)被设置为质量隔离窗口,并且只有在质量隔离窗口内的那些前体离子会被传输到碰撞室以引起碎片化。收集所选择的前体(无碰撞)以及其碎片(碰撞的产物)的光谱。
在质谱仪112中,碰撞室的输出被导向到质量分析仪。质量分析仪可以是任何质量分析仪,包括四极杆、飞行时间(TOF)、离子阱、扇形磁场质量分析仪及其组合。质谱仪的检测器检测从质量分析仪发出的离子。检测器可以与质量分析仪整合。例如,在TOF质量分析仪的情况下,检测器可以是对离子强度进行计数(即对射入的离子进行计数)的微通道板检测器。
存储介质124可以提供用于存储离子检测(m/z、保留时间、迁移率漂移、强度计数等)以供分析的永久性存储装置。例如,存储介质124可以是内部或外部计算机数据存储设备,诸如磁盘、基于闪存的存储装置等。分析计算机126分析存储的数据。还可以实时分析数据,而不需要存储在存储介质124中。在实时分析中,质谱仪的检测器将要分析的数据直接传递到计算机126,而不是首先将其存储到永久性存储装置中。
质谱仪112的碰撞室执行前体离子的碎片化。可以使用碎片化来确定肽的一级序列,随后识别起源蛋白质。碰撞室包括气体,诸如氦气、氩气、氮气、空气或甲烷。当带电前体与气体原子相互作用时,所产生的碰撞可以通过将前体分解成所得的碎片或产物离子而使前体碎片化。这种碎片化可以使用Bateman中所述的技术,通过将碰撞室中的电压在低电压状态(例如,低能量,<5V)和高电压状态(例如,高能量或升高能量,> 15V)之间切换来实现,其中低电压状态用于获得肽前体的MS光谱,高电压状态用于获得前体的碰撞诱导碎片的MS光谱。高电压和低电压可以被称为高能量和低能量,因为分别使用高电压或低电压来将动能赋予离子。
可以使用各种规程来确定何时以及如何切换用于这种MS/MS采集的电压。例如,常规方法以目标或数据相关模式(数据相关采集,即DDA)触发电压。这些方法还包括目标前体的耦联的气相隔离(或预选)。低能量光谱由软件实时获取并检查。当所需的质量达到低能量光谱中的规定强度值时,碰撞室中的电压切换到高能量状态。然后获得针预选的前体离子的高能量光谱。这些光谱包含在低能量下看到的前体肽的碎片。在收集到足够的高能量光谱之后,数据采集回到低能量状态,继续寻找具有合适强度的其他前体质量来用于高能量碰撞分析。
应该指出的是,不同的合适方法可以与如本文所述的系统一起使用来获得离子信息,诸如结合对用于分析样品的质谱法的前体和产物离子的信息。尽管可以采用传统的切换技术,但是实施例可以使用Bateman中描述的技术,其可以被表征为以简单的交替循环来切换电压的碎片化规程。这种切换在足够高的频率下完成的,以便在单一色谱峰内获得多个高能量光谱和低能量光谱。与传统的切换规程不同,该循环与数据的内容(m/z)无关。在Bateman中描述的这种切换技术提供对前体和产物离子两者的有效的同时质量分析。在Bateman中,高能量和低能量切换规程可作为肽混合物单次进样的LC/MS分析的一部分来应用。在从单次进样或实验运行采集的数据中,低能量光谱包含主要来自未碎片化前体的离子,而高能量光谱包含主要来自碎片化前体的离子(例如产物碎片离子)。例如,可将前体离子的一部分碎片化以形成产物离子,并且同时分析前体和产物离子,或者同时地,或者例如采用快速演替,通过向MS模块的碰撞室应用快速切换或交变电压,在低电压(例如,主要传递前体)和高电压或升高电压(例如主要生成前体碎片)之间切换来调节碎片化。根据上述Bateman的技术,采用在高(或升高)能量和低能量之间交替的快速演替的MS操作在本文中也可以被称为Bateman技术和高-低规程。
总之,诸如当使用Bateman技术来操作系统时,样品102被进样到LC/MS系统中。LC/MS系统产生两组光谱:一组低能量光谱,一组高能量光谱。这一组低能量光谱包含主要与前体相关的离子。这一组高能量光谱包含主要与前体碎片相关的离子。这些光谱被存储在存储介质124中。在数据采集之后,这些光谱可以从存储介质中提取出来,并且在采集之后通过分析计算机126中的算法来显示并处理。
由高-低规程采集的数据允许准确确定在低能量模式和高能量模式两者下收集的所有离子的保留时间、质荷比和强度。一般来讲,在两种不同的模式中看到不同的离子,并且在每种模式下采集的光谱可以单独或组合地被进一步分析。
如在一种或两种模式中看到的来自公共前体的离子将基本上具有相同的保留时间(并因此具有基本相同的扫描时间)和LC峰形。高-低规程允许在单个模式内和在模式之间对离子的不同特征进行有意义的比较。该比较然后可以用来将在低能量光谱和高能量光谱中看到的离子分组。本文描述了用于将低能量光谱的前体离子与源自前体离子的高能量光谱的碎片离子分组或关联的各种技术。
图2示出了根据本文技术的一个实施例,在应用交替的低能量模式和高能量模式产生的峰的洗脱期间获得光谱的时间。图2显示,与洗脱前体相关的色谱图可以通过多次光谱扫描从其高能量光谱和低能量光谱数据重建。
峰202表示单一前体的LC洗脱峰轮廓。横轴是时间,诸如不同的MS扫描时间或样品洗脱过程中的对应保留时间。纵轴是从色谱柱洗脱的前体的色谱图的随时间变化的浓度的任意表示。
因此,LC峰202的第一个曲线图示出了随时间推移交替采集低能量光谱(即,未碎片化的前体产生的光谱,标记为“MS”)和升高能量光谱(即,碎片化前体即产物离子产生的光谱,标记为“MSE”)。第二个曲线图204a和第三个曲线图204b分别表示MS和MSMSE光谱采集扫描和如与可以使用Bateman技术产生的前体关联的峰202的重建。图2中的曲线图204a(低能量)和204b(高能量)描绘了相同的色谱峰202,其中横轴表示时间,纵轴表示离子的强度。
由于质谱仪具有较高的质量分辨率,并且同位素在自然中的普遍存在,进入质谱仪的分子被分成一系列同位素质量峰,本文中我们将其称为同位素簇。这些峰的存在及其不同的强度是特定分子的元素组成的特征。由质谱仪离子化的分子因此产生一系列同位素电荷簇,由此表示该分子的固有同位素簇呈现电荷态的分布。因此,具有特定同位素分布和电荷态z的离子化分子在质谱中被观察为一系列m/z峰,每个峰的间隔为其电荷态的倒数(l/z)。而且,根据离子化分子的电荷分布,每个同位素簇将在特定的m/z空间被观察到;电荷越高,m/z越低,并且峰间距越小。
由于在低能量模式下产生的离子主要是前体离子产生的离子,因此它们的质谱将作为同位素电荷簇出现(如刚才所述)。在高能量模式下,离子主要是前体的产物碎片离子。因此,碎片离子同位素电荷簇分布将取决于来自前体的所得碎片质量和简约电荷态。
在峰202的曲线图中,不同密度的交替柱条表示在所描绘的LC峰洗脱期间用低能量电压和高能量电压收集光谱的时间。柱条在时间上均匀交替。曲线图204a示出了在碰撞室中施加低能量电压而得到低能量光谱的示例性时间。曲线图204b示出了在碰撞室中施加高能量电压而得到高能量光谱的时间。如204a和204b所示,色谱峰由高能量模式和低能量模式多次采样。因此样品在低能量模式和升高能量模式下均产生同位素电荷簇。
因此,当使用如Bateman中所述的高-低规程操作MS仪器时,对于单次实验运行或样品进样,分析可以导致获得由204a表示的第一组低能量质谱数据,其主要包含前体离子数据,以及由204b表示的第二组高能量或升高能量质谱数据,其主要包含碎片离子数据。
如下面更详细描述的,作为质谱分析的结果产生的这些数据通常包括扫描时间或采集时间。
在一些实施例中,图1的系统还可以包括质量分析仪中的部件(或者作为单独的部件或仪器)以另外执行离子淌度谱分析(IMS)作为分离的附加维度。在这样的实施例中,质谱数据的进一步处理可以将得到的第一形式的质谱数据扫描时间转换成对应的保留时间以及对应的离子迁移率漂移时间。如本文中其他地方更详细描述的,本文的技术可以利用扫描时间对质谱分析数据的第一形式进行处理。
再次参照图1,在操作中,样品102经由进样器106被进样到LC104中。泵108将样品泵送通过色谱柱110,并且样品被分离成洗脱组分,其特征在于其离开色谱柱110的保留时间。由泵108通过进样器106提供的高压溶剂流迫使样品102迁移通过液相色谱系统104中的色谱柱110。色谱柱110通常包括一包二氧化硅小球,这些二氧化硅小球的表面包含结合分子。来自色谱柱110的输出流体流被引导至MS 112用于分析。在一个实施例中,LC 104可以是超高效液相色谱(UPLC)系统,诸如得自马萨诸塞州米尔福德的沃特世公司的ACQUITY UPLC®系统。
MS 112的质量分析仪可以采用各种配置串联放置,包括,例如,四极杆飞行时间(Q-TOF)质量分析仪。串联配置使得能够对已经经过质量分析的分子进行在线碰撞修正和分析。例如,在基于三重四极杆的质量分析仪(诸如Q1-Q2-Q3或Q1-Q2-TOF质量分析仪)中,第二个四极杆(Q2)赋予由第一个四极杆(Q1)分离的离子加速电压。这些离子与明确引入Q2中的气体发生碰撞。这些碰撞导致离子碎片化。这些碎片进一步由第三个四极杆(Q3)或TOF进行分析。在一个实施例中,MS 112可以是QTOF质谱仪,诸如得自马萨诸塞州米尔福德的沃特世公司的SYNAPT G2™质谱仪。
作为输出,MS 112产生随时间收集的一系列光谱或扫描。质荷谱是作为m/z的函数绘出的强度。对于每个元素,光谱的单个质荷比可以被称为一个通道。随着时间的推移查看单个质量通道可提供对应的质荷比的色谱图。采集的质荷谱或扫描可以被记录在存储介质上,诸如由计算机126可访问的元件124表示的硬盘驱动器或其他存储介质。通常,光谱或色谱图被记录为值组成的数组并存储在存储装置124上。可以使用计算机126访问存储在124上的光谱,诸如用于显示、后续分析等。控制装置(未示出)为各个电源(未示出)提供控制信号,这些电源分别为系统100的部件诸如MS 112提供必要的工作电位。这些控制信号决定仪器的工作参数。控制装置通常由来自计算机或处理器诸如计算机126的信号控制。
一旦分子从色谱柱106中洗脱出来,就可以被输送到MS 112。保留时间是一种特征时间。也就是说,在保留时间t从色谱柱中洗脱的分子实际上是在基本上以t为中心的一段时间内洗脱的。该时间段内的洗脱轮廓被称为色谱峰或LC峰。色谱峰的洗脱轮廓通常以钟形或高斯曲线为特征。峰的钟形的宽度通常以其半高全宽(FWHM)来描述。分子的保留时间是峰的洗脱轮廓的顶点处的时间。出现在由质谱仪产生的光谱中的谱峰具有相似的形状并且可以采用类似的方式表征。
存储器124可以是任何一种或多种不同类型的计算机存储介质和/或设备。如本领域技术人员将理解的,存储装置124可以是具有多种不同形式中的任何一种的任何类型的计算机可读介质,包括以任何方法或技术实现的用于存储信息诸如计算机可读指令、数据结构、程序模块或其他数据的易失性和非易失性、可移除和不可移除介质。计算机存储介质包括但不限于RAM、ROM、EEPROM、闪存或其他存储器技术、CD-ROM、(DVD)或其他光存储器、磁带盒、磁带、磁盘存储器或其他磁存储装置,或可用于存储所需代码、数据等的任何其他介质,其可由计算处理器或更一般地由计算机的任何处理器或其他部件访问。
计算机126可以是包括被配置为执行存储在计算机可读介质上的代码的计算机处理器的任何商购或专有计算机系统、处理器板、ASIC(专用集成电路)或其他部件。处理器在执行代码时可以使计算机系统126执行处理步骤,诸如访问并分析存储在存储装置124上的数据。计算机系统、处理器板等可以更一般地被称为计算设备。计算设备还可以包括或以其他方式被配置为访问诸如由124表示的计算机可读介质,该计算机可读介质包括存储在其上的可执行代码,其使计算机处理器执行处理步骤。
系统100可以用于执行LC/MS实验以分析样品并且生成样品中至少一种化合物或分子的前体和产物或碎片离子的质谱。生成的质谱可以被进一步分析和/或处理以结合多种技术中的任一种来用于不同应用。结合本文的技术,可以分析质谱数据以识别并定量前体分子及其相关的产物离子。
使用系统100的任何合适的方法可以用于从样品进样获得前体离子和产物离子两者。一些方法,诸如根据Bateman中所述的高-低规程来操作MS仪器,将同时对前体离子和产物离子两者提供有效的质量分析。例如,洗脱前体在一部分时间被碎片化以形成产物离子,并且前体离子和产物离子基本上被同时分析,或者同时地或者例如采用快速演替。因此,一个实施例可以使用Bateman中所述的技术或其他合适的技术来操作MS仪器。一个实施例可以使用本文其他地方描述的技术来确定哪些产物离子来源于特定的前体,因此这些产物离子可以被表征为与多重洗脱前体相关联或者与之有关。
根据本文其他地方描述的技术,可以将与前体离子和与产物离子相关联的峰的峰形、宽度和扫描时间进行比较,以确定哪些产物离子与特定前体离子相关联。来自共同起源分子的离子(前体离子和碎片离子)具有相似的特征,诸如它们的相对强度。当一个分子从LC中洗脱出来,它的强度增加到最大值,然后强度降低,直到低于检测限(LOD)。该前体的产物离子将具有相同的行为,即产物离子与其母体前体的强度之比保持恒定,尽管他们各自的绝对强度不断变化。因此,前体离子及其相关产物的扫描内和扫描之间的相对强度必须一致,示出共同的峰形或轮廓等,如本文其他地方所述。
在如上所述的LC/MS实验中,可以通过离子的扫描时间、质荷比或质量、电荷态和强度来描述和/或参考。一个起源分子可以产生多个离子,由此每个这样的离子是前体或碎片。这些碎片来自使起源分子破碎的过程。这些过程可以发生在电离源或MS 112的碰撞室中。由于碎片离子来源于一个共同的洗脱、起源分子,所以根据定义,它们以反映其色谱峰轮廓上的每次扫描的碎片化效率(产物离子面积/前体离子面积)的强度比存在。离子形成、碎片化以及离子检测的时间一般比起源分子的峰宽短得多。例如,以半高全宽(FWHM)测量的典型色谱峰宽为5至30秒。离子形成、碎片化以及检测的时间通常在亚毫秒级。
在使用Bateman技术或的高-低规程进行数据采集以获得如图2所示的交替LE和HE扫描的实施例中,在色谱时间标度上,离子形成、碎片化以及检测的时间可以在一方面被表征为本质上是瞬态过程。于是,在这种实施例中,来源于一个起源分子的离子在观察扫描时间上的差异实际上为零。也就是说,与色谱峰宽相比,来源于一个起源分子的离子之间的亚毫秒级保留时间差较小。
相对于从完整前体离子的碰撞诱导解离产生的离子,碎片离子或产物离子与其母体前体离子相关联。通过在如Bateman ‘130专利中所述的高-低数据采集模式(在本文中也称为升高-低数据采集模式)下使用质谱仪,实现了这种关联,而无需仪器预先选择单一前体来进行后续碎片化。更具体地讲,当多个前体在基本上相同的扫描时间被同时碎片化时,相关联的离子被适当地分组。
相对于通过串联质量隔离获得的数据,选择离子进行碎片化的实际以及它何时被碎片化时的时间可以基本上不同,因此为了计算正确的强度比即产物离子/前体离子,需要外推前体离子在其实际碎片化时间的强度。这是通过生成在后续和之前的LE扫描中的前体离子的强度值之间的线性回归,并且应用相关时间间隔来实现的。
从色谱支持基质诸如色谱柱110洗脱的分子的洗脱时间和色谱峰轮廓是该分子在支持基质和流动相之间的物理相互作用的函数。分子在支持基质和流动相之间的相互作用程度决定了该分子的色谱图和洗脱时间。在复杂混合物中,每个分子在化学上是不同的。因此,每个分子可以对色谱基质和流动相具有不同的亲和力。因此,每个分子可以表现出独特的色谱图。
通常,特定分子的色谱图是唯一的,并且描述了该分子的物理化学性质。任选地用于表征给定分子的色谱峰轮廓的参数包括举例来说初始检测(抬起)时间、归一化斜率、相对于峰顶点时间的拐点时间、最大响应(峰顶点)时间、拐点处的峰宽、半高全宽(FWHM)、峰形不对称性以及最终检测(下触)的时间。
如下面更详细描述的,更一般地说,本文的技术可以结合处理第一形式的一个或多个MS数据集合来使用,如在本文其他地方所述的从相同或不同实验获得的数据集合。MS数据集合可以通过根据Bateman中描述的高-低规程或任何其他合适的方式操作MS仪器来获得。
参见图3,所显示的是示出可以在根据本文技术的一个实施例中使用的部件的例子。例子300包括仪器系统100,其表示执行如图1的系统100中所示的样品分析的仪器,诸如LC和MS仪器。在这个例子中,可以执行实验来分析样品,从而采集单个前体的MS (LE)和MS/MS (HE)数据、前体的m/z范围,或前体的在收集LE和HE数据集合之间非常窄的时间窗口内的整个m/z标度。例如,根据Bateman的高-低规程采集LE和HE数据以生成用于单次样品分析的MS扫描数据301。如上文和本文其他地方所述,用于单次实验运行或进样的这样一组MS扫描数据301可以包括两个数据集合—低能量(LE)扫描数据集合302和高能量(HE)扫描数据集合304。元素302可以表示当以低能量模式操作MS仪器时采集的MS扫描数据,并且元素304可以表示当以高能量模式操作MS仪器时采集的MS扫描数据。在这个例子中,数据集合302和304可以包括没有质量过滤的所有检测离子的完整扫描数据。
MS扫描数据301可以被提供作为数据处理(DP)引擎310的输入。DP引擎310可以体现为处理MS扫描数据301的一个或多个软件模块,由此,这样的处理包括对每个PCC逐扫描地执行前体电荷簇(PCC)形成312、峰检测314,以及PCC或前体-碎片离子关联与过滤320。DP引擎310还可以包括一个或多个其他模块322。作为输出,DP引擎310可以生成一个或多个SSPPIS(单次扫描前体-产物离子谱)350。SSPPIS表示单个PCC及其相关产物离子或碎片离子,其反映单次扫描。由DP引擎310的前述模块中的每一个执行的处理以及PCC、SSPPIS等在本文其他地方更详细地描述。同样如以下段落中更详细描述的,可以使用一个或多个SSPPIS来获得质量指纹以唯一地识别特定分子。在一些实施例中,如本文其他地方更详细描述的,相关联或相关SSPPIS可进一步组合成一个或多个CPPIS(复合前体-产物离子谱)352。
另外,DP引擎310还可以输出不匹配离子的残余组354。如本文其他地方更详细描述的,残余组354可以包括任何不匹配的PCC和/或不匹配的碎片离子。
DP引擎310可以在本文中称为非监督或无监督聚类的第一处理模式下操作,由此通过跟踪单个PCC的强度以及包含在LC峰洗脱轮廓上的每个周围SSPPIS中的其产物离子的强度,由一系列SSPPIS形成CPPIS。只保留每个SSPPIS的符合特定算法确定的与跟踪前体电荷簇或其一个或多个同位素的强度比关系的产物离子。
在LC峰可能表现出多于一个的重叠洗脱组分的典型情况下,如果在用来采集产物离子谱的相同质量隔离窗口中发现多个前体电荷簇(PCC),则SSPPIS的产生会将相同的高能量产物离子谱分配给这些PCC。采用Bateman的高-低规程来生成MS扫描数据常常如此。因此,单次扫描采集的产物离子通常与其分配的PCC具有一对多的关系。因此,一个特定的SSPPIS的废弃产物离子变成保留在属于不同PCC的不同SSPPIS中的过滤离子。这一过程的顶点导致CPPIS的产生,其中保留在其关联SSPPIS中的产物离子最有可能是属于特定前体电荷簇的合适离子。
DP引擎310还可以在第二处理模式下操作,该第二处理模式在本文中称为监督聚类,由此按照用户或算法定义的一组匹配标准,通过将已知指纹或目标分子或化合物的前体-产物离子与所有SSPPIS进行匹配,由一系列一种或多种SSPPIS来形成CPPIS,诸如可以存储在数据库或库中的SSPPIS。
如本文其他地方所述,模块312、314和320可以针对监督和非监督聚类模式执行处理。在一个实施例中,模块312和314可以针对监督和非监督聚类模式对MS扫描数据301执行相同的处理。由模块320执行的处理可以根据DP引擎310是以非监督聚类模式操作还是以监督聚类模式操作而变化。
参见图4,示出了可以被包括在根据本文技术的一个实施例中处理的质谱数据中的信息的例子。例子300示出了可以包括在第一形式的MS扫描数据301中的信息。单元401a可以表示在根据Bateman高-低规程操作MS仪器时作为执行上文结合图3描述的实验的结果而获得的前体离子光谱数据(在图3中表示为LE扫描数据集合302)。单元401b可以表示在根据Bateman高-低规程操作MS仪器时作为结合图3描述的实验的结果而获得的产物或碎片离子光谱数据。具体地讲,在利用根据Bateman高-低规程操作的MS仪器的一个实施例中,可以在单次实验或运行中采集401a和401b的数据,由此交替扫描与前体离子谱和产物离子谱关联。在例子400中,表格401a的扫描I和表格401b的对应扫描I”表示为基本上相同的第I次扫描时间采集的数据并因此表示对应的扫描,其中在该例子中I表示大于0的整数的扫描编号。对于对应的扫描编号1,表格401a的信息由扫描编号列402中的1表示,并且对于相同扫描编号,表401b的信息由扫描编号列422对中的1”表示。在例子300中,一对对应的扫描1和1”具有基本上相同的扫描时间,由此这对中的扫描1具有表格401a中的数据或低能量扫描数据,并且同一对中的扫描1”具有表格401b中的数据或高能量扫描数据。
如表格401a和401b所示,数据集合401a, 401b中的每一个可以包括不同质谱扫描的多个扫描时间的信息。对于每次扫描,可以通过执行质谱分析获得一个或多个检测质量和相关强度的列表。例如参见表格401a,列402表示扫描列表,列404表示在扫描时检测到的质量,列406表示列304中的检测质量的强度。对于扫描1,表格401a的由单元格或条目410表示的行列出检测到的质量和相关强度。对于扫描2,表格401a的由单元格或条目412表示的行列出检测到的质量和相关强度。表格401a的每一行包括质量和强度,该强度表示该行中的检测质量的强度。例如,i1是扫描1中检测到的质量ml的强度,i2是扫描1中检测到的质量m2的强度。表格401b可以包括与结合表格401b所述的信息类似的信息,但是用于交替与碎片离子数据相关联的对应扫描。参照例子300,410和430表示用于对应的扫描1和1"的对应低能量和高能量扫描数据,412和432表示对应的扫描2和2"的对应低能量和高能量扫描数据。
应该指出的是,具有基本上相同扫描时间的一对对应扫描(一个来自表格401a,另一个来自表格401b)可以表示保留时间或漂移时间,具体取决于特定实验。例如,如果在质谱分析之前执行的分离处理包括色谱分离,诸如对于LC或GC,而没有离子淌度谱分析,则扫描时间表示保留时间。如果在质谱分析之前执行的分离处理包括离子淌度谱分析但不包括色谱分离,则扫描时间表示漂移时间。如果在质谱分析之前执行色谱分析和离子淌度谱分析,则扫描时间可以表示保留时间或漂移时间。例如,对于LC/IMS/MS,一组连续的扫描时间可以形成表示一组与单个保留时间相关联的多个漂移时间的一个扫描组,由此(对应于漂移时间的扫描时间的)扫描组可以表征为嵌套在对应于色谱保留时间的两个扫描时间内或之间。例如,参照图5,示出了各自包括N个扫描的扫描组451和452的例子。在LC/IMS/MS实验中,每个扫描组451, 452可以与不同的保留时间相关联。在单个扫描组(诸如451)内,每个单独的扫描时间可以对应于不同的漂移时间。
为了具体说明,质谱数据可以具有与本文所述的不同的替代形式。在使用本文的技术时操作并且诸如图4和图5所示的前体和产物离子质谱数据可以在一方面表征为尚未由执行峰检测、将扫描和扫描时间映射或转换成对应保留时间和/或漂移时间等的其他软件处理的第一形式的质谱数据。
应该指出的是,当采用与上述根据Bateman高-低规程的方式不同的方式操作MS仪器进行实验时,可以获得包括与结合图4和图5描述的信息类似的信息的质谱数据。
参见图6,所显示的是示出可以在根据本文技术的一个实施例中执行以产生包括在分子指纹或模式中的信息的处理例子。在实施例600中,P1 602可以表示作为样品的单个分子或洗脱组分的母体前体。母体前体或单个分子具有同位素模式或簇604,在本例中为P1 A0、P1 Al、P1 A2和P1 A3。在该例子604中,每个P1 Ai表示前体P1的同位素分布,其中“i”是在0至3的范围(包括端点)中的一个值。结合本文的描述,同位素模式或簇604也可以简称为前体。当具有同位素模式604的前体经历离子化606(诸如结合MS仪器)时,前体被离子化,由此产生一系列PCC,每个PCC具有不同的电荷态610。每个前体电荷簇或PCC 610a至610c具有相同的同位素分布。同位素之间的Δm/z间距随着电荷而变化,尽管Ai内和之间的强度比是恒定的。在该例子中,洗脱组分P1 602的离子化产生3个前体电荷簇或者说PCC 610a至c。PCC1 610a的电荷为+1,PCC2 610b的电荷为+2,PCC3 610c的电荷为+3。前述前体离子或PCC 610a至c中的每一个可以作为碎片化处理612的结果被进一步碎片化,诸如结合MS仪器执行的处理,从而产生一系列碎片化组614。更具体地讲,在该例子中,PCC 610a至c中的每一个经历碎片化612,产生相关联的一组碎片化离子614a至c。在例子600中,作为将前体离子或PCC碎片化的结果产生的产物或碎片离子可以由包括在614a至c中的每个F表示。PCC1 610a可以被碎片化,产生包括来源于PCC1的碎片或产物离子的碎片化组614a。PCC2 610b可以被碎片化,产生包括来源于PCC2的碎片或产物离子的碎片化组614b。PCC3 610c可以被碎片化,产生包括来源于PCC3的碎片或产物离子的碎片化组614a。
在通过比较前体的SSPPIS来确定分子的离子指纹的一个实施例中,离子的电荷态要求数据包括漂移或CCSA。离子迁移使前体离子按照电荷分离。电荷态对色谱洗脱没有影响;因此,前体的所有电荷态具有随时间推移相同的轨迹。离子迁移使不同的电荷态分离,为DP提供了根据电荷态计算前体和产物内和之间的必要强度比的手段。然后可以将结果进行比较,并将其塌缩成单个离子指纹或复合前体产物离子谱或者说CPPIS。
在根据本文技术的一个实施例中,由P1 602表示的分子指纹由614a至c中表示的三个经识别并验证的碎片离子模式组成,这三个碎片离子模式分别用于在610a至c中表示的三个PCC中的每一个。如本文所述,根据本文技术的一个实施例也可以为包含在离子指纹中的每个产物离子存储与前体和产物离子的面积比(例如,本文其他地方描述的各种AR值)相关联的误差指示器或一致性指示器。
在根据本文技术的一个实施例中,与每个PCC相关联的属性可以包括m/z;m/z和保留时间;m/z、保留和漂移时间,或任何和所有的离子检测前分离测量或其组合。m/z或PCC或前体离子m/z的记录是A0同位素或单一同位素。在单次扫描中,PCC或前体离子的强度(诸如由610a至c中的每一个表示)可以是该单次扫描的单个PCC中的所有同位素的强度总和。例如,在扫描S1中,由PCC1 610a表示的前体离子的强度是P1 A0、P1 A1、P1 A2和P1 A3的强度的总和,如同对于扫描S1而言发生在在PCC1 610a中那样。
还应该指出的是,母体前体P1的强度或浓度等于PCC 610a至c中的每一个的强度或浓度之和。另外,该前体的同位素604的数量是其元素组成和浓度的函数,如同其每个电荷态在610中反映的那样。尽管强度分布对于所有电荷态是恒定的,但是给定的元素组成与电荷态无关,每个电荷态的同位素数量是P1按电荷态的摩尔分布的函数。特定PCC的可观测同位素的数量由质量分析仪的动态范围和检测限决定。
如本文其他地方所提到的,由图3的DP引擎310产生的SSPPIS表示单个PCC及其相关产物离子。在每次低能量单次扫描中可以为每个前体电荷簇生成SSPPIS。伴随升高能量扫描产生的产物离子在过滤之后与相同扫描中的每个PCC共享或相关联,诸如通过相对于其母体前体的强度和m/z,或者通过与产物离子目标组进行比较,从而形成独特的SSPPIS。
参照图6的例子,母体分子P1产生3个PCC或前体离子,它们全部具有相同的保留时间但具有不同的强度或浓度、不同的质量、不同的电荷、不同的m/z值和不同的漂移时间。同样如图所示,这3个PCC中的每一个可进一步经历解离,产生它们自己的产物或碎片离子模式614。
在其中使用MS仪器的碰撞室来执行前体离子或PCC的解离或碎片化的一个实施例中,随后可以是产生产物/碎片离子模式,由此电荷守恒。换句话讲,碎片离子的电荷不能超过其母体的电荷。一般来讲,前体离子解离成电荷态不超过母体前体的电荷态减去1的碎片离子,假定产物离子必须被带电才能被检测。一般来讲,电荷是守恒的,因为碎片化的前体产生两个补充离子,其中F1+F2=前体元素质量+其电荷态乘以1.007(质子质量)。例如,PCC2 +2 610b可以被碎片化成614b的两个碎片即Fm和Fn,其中每个这样的碎片具有1+的电荷。PCC3 +3 610c可以被碎片化成2个碎片即Fx和Fy,其中Fx具有1+的电荷并且Fy具有2+的电荷。如本文其他地方所述,每个碎片或产物离子还可以具有相的强度、电荷态、质量m/z等。
可以生成用于PCC1 610a的第一SSPPIS,其包括614a的碎片离子,由此表示碎片离子614a与PCC1 610a的碎片化相关联或由该碎片化生成。可以生成用于PCC2 610b的第二SSPPIS,其包括614b的碎片离子,由此表示碎片离子614b与PCC2 610b的碎片化相关联或由该碎片化生成。可以生成用于PCC3 610c的第三SSPPIS,其包括614c的碎片离子,由此表示碎片离子614c与PCC3 610c的碎片化相关联或由该碎片化生成。
在执行LC/MS/IMS分析的一个实施例中,源自相同前体(诸如P1)的PCC(诸如PCC 610a至c)可以根据其相关漂移时间在时间维度上进行区分。在这样一个实施例中,也可以基于各个碎片离子的漂移时间的差异来确定源自每个PCC的各个碎片离子,诸如如614所示。在执行LC/MS分析的一个实施例中,由于省去了IMS,因此这中漂移时间区分不可行,并且因此所有PCC可以被观察为在同一次扫描中洗脱。在这样一个实施例中,因此无法使用漂移时间作为分离或关联源自每个PCC的各个碎片离子的维度。因此,在使用LC/MS并省去IMS的这样一个实施例中,如果碎片离子可以源自PCC 610a至c中的多个PCC,则可以将相同的碎片离子中的一些包括在碎片离子组614a至c中的多个组中。例如,考虑使用LC/MS(无IMS)的一个实施例,其中碎片Fk可以具有+1的电荷态,并且因此可能源自PCC 610a至c中的任何一个,并且可以被包括在614a至c中的每一个中,因为漂移时间不可用作分离维度来进一步将碎片离子与其起源PCC相关联。
参照图6a,示出了举例说明3种不同的前体P1、P2和P3的例子,其中P1、P2和P3分别具有同位素模式或簇654、655和656。在该例中,P1至P3示出在同一次扫描中洗脱的3种前体。P1可以被离子化,产生PCC1 660a。P2可以被离子化,产生PCC2 660b。P3可以被离子化,产生PCC3 660c。PCC 660a至c出现在同一次LE扫描中。PCC 660a至c可以被碎片化662,导致产生包括在碎片离子组664a至c中的碎片离子,由此可以在同一单次碎片离子扫描(例如,同一次HE扫描)中包括664a至c的所有碎片离子。
使用以下段落中所述的技术,可以生成用于PCC1 660a的第一SSPPIS,其包括664a的碎片离子,由此表示碎片离子664a与PCC1 660a的碎片化相关联或由该碎片化生成。可以生成用于PCC2 660b的第二SSPPIS,其包括664b的碎片离子,由此表示碎片离子664b与PCC2 660b的碎片化相关联或由该碎片化生成。可以生成用于PCC3 660c的第三SSPPIS,其包括664c的碎片离子,由此表示碎片离子664c与PCC3 660c的碎片化相关联或由该碎片化生成。
因此,表示单个分子或单个洗脱组分的P1前体的指纹可以包括来自其相关的用于PCC1 660a的第一SSPPIS的信息与附加信息,诸如该PCC以及与PCC和/或离子的物理或化学性质有关的每个碎片离子的属性信息,以及属性信息诸如本文其他地方描述的一种或多种度量和相关误差指示器。以类似的方式,表示单个分子或单个洗脱组分的P2前体的指纹可以包括来自其相关的用于PCC2 660b的第一SSPPIS的信息,并且表示单个分子或单个洗脱组分的P3前体的指纹可以包括来自其相关的用于PCC3 660c的第一SSPPIS的信息。
如图6中所述,图6a中PCC 660a至c中的每一个可以存在多个电荷态,并且如果离子淌度是采集工作流程的一部分,则作为第一实例,碎片离子指纹是通过对不同充电状态应用所述过程来产生的。在不存在离子淌度的情况下,离子指纹是通过比较PCC或前体离子660a至c与产物离子664a至c的面积比来产生的,首先识别与其母体行为相似的产物离子,然后在反映母体分子的色谱洗脱的扫描中比较这些面积比。
如本文在下文中更详细描述的,所采集的扫描数据可以根据单次扫描来处理。产物或碎片离子的碎片化模式及其与其母体离子(例如PCC)的关系可以被定义为产物离子与其母体(诸如其相关SSPPIS)之间的强度关系,使得在定义其色谱峰的扫描内以及之间,这两者的面积比或强度比必须一致(在某种实验方差内)。本文中的技术利用了母体离子(诸如PCC)与其碎片之间的这种原理和关系,如同发明人所认识到的一样。详细地说,前体的碎片化模式在其洗脱过程中是一致的。为此,在不存在干扰的情况下,前体离子与其成分产物离子之间的强度关系应保持恒定。前体离子或PCC在碎片化过程中将产生的产物离子的数量是其长度/质量和浓度的函数。PCC强度在定义其洗脱轮廓的扫描上的变化(例如,增加和/或减少)率对于从该前体发出的产物离子而言是相同的。类似地,给定恒定施加的碰撞能量(eV),碎片化效率(产物离子强度/前体离子强度比率)也在定义其洗脱轮廓的所有扫描中保持恒定(在某种实验方差内),产物强度离子除以已知作为该洗脱组分的一部分的所有产物离子的强度也同样如此。
本文的技术使用验证试探法,该方法利用单次扫描和逐次扫描来跟踪和验证产物离子与母体前体离子或PCC的对齐。如下面更详细描述的,度量AR1(面积比率1)被定义为在单个(同一个)扫描时间,产物离子与其PCC的强度或面积比率。给定可以在根据本文技术的一个实施例中使用的单次扫描模式,每个PCC的强度在整个洗脱峰上被跟踪。在其中PCC最高的扫描被称为枢轴点(eV)或顶点。在洗脱峰的所有扫描/扫描时间内,PCC以及相关或匹配碎片离子的AR1度量应相同(在某个指定的容差内)。此外,作为另一种验证技术,使用另一度量AR2(面积比率2,下面更详细描述)将峰中的所有相邻扫描与枢轴扫描进行比较。简而言之,可以为PCC和匹配的(可能地)产物离子确定AR2值。PCC的AR2可以被定义为在峰的任何相邻扫描中该PCC与在PP或顶点扫描中该PCC的强度或面积比率。类似地,产物或碎片离子的AR2可以被定义为在峰的任何相邻扫描中该碎片离子与在PP或顶点扫描中同样离子的强度或面积比率。在扫描(AR1)内以及扫描(AR2)之间,PCC及其匹配的产物离子的强度或面积比率应在统计方差内一致。按照曲线下面积(AUC)的定量准确度和精确度表明,在峰上存在一个最小扫描次数。这确保该峰上有足够多的单次扫描来提供必要的统计数据,以确定哪些离子具有相似行为。
现在将描述的是可以在一个实施例中执行的用于非监督聚类的处理。它用于确定洗脱组分或分子的指纹,而不必具备关于该特定分子包括在正在执行的实验和数据分析的样品中的先验知识。结合执行样品实验诸如LC/MS或LC/IMS/MS,可能有多个分子同时洗脱(例如具有几乎相同的保留时间)。根据本文技术的一个实施例中的非监督聚类可以用于一般地确定洗脱组分的指纹,并且可以进一步有助于生成具有相同或相似洗脱时间的两个重叠或干扰组分的指纹。因此,非监督聚类可用于正确地将碎片离子与其起源分子或组分正确地关联或匹配,并正确地将碎片离子与其起源PCC相关联或匹配。如下文以及本文其他地方所述,在根据本文技术的一个实施例中,关于每个PCC和相关碎片离子的信息可以作为可由单个SSPPIS表示的单元来存储并维护。因此,如图6和图6a的例子中所示,分子或洗脱组分的单个指纹可以包括来自多个PCC的信息,并且因此包括来自多个SSPPIS的信息。如下面更详细描述的,对于作为样品的LC/MS实验的结果而产生的数据集,用于非监督聚类的处理可以确定哪些碎片离子与其应有的PCC相关联。随后,可以执行处理来确定组合或讲PCC(及其匹配的碎片离子)与特定洗脱组分或分子关联(例如,确定哪一个或多个PCC应该组合在一起并与单个洗脱组分或分子关联)。
再次参见图3,DP引擎310的PCC形成模块312可以采用逐次扫描的方式执行对LE扫描数据集302的处理,以确定每个扫描时间的一组PCC。单次扫描中的每个PCC都有相关m/z(通常是A0单一同位素)、电荷态z和强度,如本文其他地方所述。相同的PCC,如使用其相关的m/z识别的PCC,随后由LC峰检测模块314通过一系列连续扫描来跟踪。对于每次扫描,PCC的强度也被跟踪。前述跟踪的结果应该在PCC的不同连续扫描中形成强度值的峰响应,由此表示该单个PCC的洗脱色谱峰的强度包络。因此,在连续扫描中跟踪单个PCC以确定该PCC产生的洗脱峰,如图7所示。应该指出的是,可以对每个跟踪的PCC执行如图7所示的对单个PCC的结果跟踪。
参见图7,所显示的是示出在根据本文技术的一个实施例中为单个PCC确定的LC峰的图示。作为峰检测的一部分,执行处理以确保强度在从点P起点到H的连续扫描中增大,然后在从点H到P终点的连续连续扫描中减小。P起点表示峰的第一次扫描或者当该PCC的m/z可以被初始检测到的时刻。H表示峰的顶点,在该点,与该PCC的m/z相关的检测强度处于最大值。H也可以被称为枢轴点(PP)。P终点表示峰的最后一次或结束扫描,或者当该PCC的m/z不再被检测到的时刻。
在单次扫描内,前体离子与其产物离子的强度之间存在关系,这种关系是前体及其产物离子的碎片化模式的一部分。在根据本文技术的一个实施例中,可以确定表示不同扫描中相同前体离子或PCC的PCC或前体离子比率的AR2(面积比率2)度量,并将此度量与确定由该PCC产生的匹配或相关碎片离子结合使用。当最初形成SSPPIS时,每个产物离子被分配一个AR1值,其中AR1(面积比率1)等于产物离子的强度除以前体的强度。假如在前体洗脱期间的所有扫描中施加一致的碰撞能量,则洗脱轮廓的每个扫描成员的AR1值应在某种实验误差内是一致的。
在不同扫描之间,特定PCC的由扫描t1=X强度和扫描t2=Y强度生成的强度比率得到了比率X/Y。在相同的扫描t1和t2中,与同一PCC相关的碎片的行为必须在某个指定的容差内具有相似的强度比率。如果该PCC的强度在扫描t1和t2之间增大,那么其相关碎片离子的强度也必须增大。如果该PCC的强度在扫描t1和t2之间减小,那么其相关碎片离子的强度也必须减小。因此,PCC的前述强度比率可以用于区分或区别并恰当地关联来自不同PCC或前体离子的碎片。
在根据本文技术的一个实施例中,可以确定表示任何扫描之间相同前体离子或PCC的PCC或前体离子比率的AR2(面积比率2)度量,并将此度量与确定由同一PCC产生的匹配或相关碎片离子结合使用。如果任何扫描的产物离子与同一PCC有关,则这些离子必须将来自顶点扫描的相应离子的AR2比率反映为它们的PCC AR2比率。如下所述,对于PCC及其每个产物离子,AR2比率或度量可以一般地针对LC峰曲线上的每次扫描或点来确定。图7的扫描H1和H2处的FWHM点就是两个这样的点。
总而言之,对于单个PCC,在执行的处理的第一步,可以跟踪不同扫描中的特定PCC以执行诸如图7所示的峰确定。作为第二步,可以识别检测峰的具有特定PCC的最大或最大值强度的扫描,并将其表示为用来计算AR2度量的顶点或枢轴点扫描。
作为第三步,可以确定两个FWHM点:H1和H2。在第三步中,识别对应于在峰左侧(LHS或上坡)和峰右侧(RHS或下坡)上的最大强度(例如,顶点H的强度)的一半高度的点或扫描。例如,这种处理确定H左侧的点H1和H右侧的点H2,在这两个点处,强度为最大值的½(或者说PP或H点处的强度的½)。例如,峰或最大强度BMAX可以在扫描1008处,并且强度可以是在扫描1004 H1(PP的左侧)和H2 1012(PP的右边)处的IMAX/2。因此,H1表示峰的LHS上的一半高度的扫描,H2表示峰的RHS上的一半高度的扫描。
定义图7所示的PCC的上坡比率U和下坡比率D,如下所述:
上坡比率U=H1强度/H强度 公式1
并且
下坡比率D=H2强度/H强度 公式2
其中
H是识别的峰枢轴扫描处该PCC的最大强度;
H1是由点H1表示的识别的扫描中该PCC的强度;并且
H2是由点H2表示的识别的扫描中该PCC的强度。
应该指出的是,通过定义FWHM,两个FWHM点H1和H2的上坡比率U和下坡比率D两者始终导致约1/2的PCC强度比率。上面的公式1和2分别表示针对特定点或扫描的AR2比率的定制形式H1和H2。
一般来讲,可以针对每次扫描或峰或曲线上的点来确定PCC及其每个产物离子的AR2比率。扫描H1和H2的FWHM点是两个这样的点的例子。因此,可以从峰或曲线上点H处的扫描(例如,PP或顶点)以及一般地在任何其他扫描Sx之间来为PCC及其产物离子强度二者确定AR2比率:
AR2P = Int (扫描Sx, PCC)/Int (扫描PP, PCC) 公式3a
AR2f = Int (扫描Sx, Fx)/Int (扫描PP, Fx) 公式3b
对于AR2
其中
Int (扫描Sx, PCC)是一些扫描SX中表示除PP或H扫描之外的另一个扫描的PCC的强度;并且
Int (扫描PP, PCC)是当PCC强度处于检测峰中其最大值或顶点时扫描H(例如,在峰的PP或顶点处)中前体离子的强度;并且
Int (扫描Sx, Fx)是具有属于扫描Sx中的PCC的m/zx的特定碎片离子Fx的强度;并且
Int (扫描PP, Fx)是具有属于扫描H中或PP处的PCC的m/zx的特定碎片离子Fx的强度;并且
AR2f的值反映在同一扫描Sx内AR2p在给定的容差内的相似值,如果碎片离子Fx与PCC真正相关的话。
在本文描述的一个实施例中,可以如下所述首先为扫描H1和H2中的FWHM点确定PCC的AR2值(基于公式3a):
AR2 =上坡比率U =下坡比率D
=Int (H1, PCC/Int (H, PCC) = Int (H2, PCC)/Int (H, PCC)
其中
Int (H, PCC)是当前体的强度处于检测峰中其最大值或顶点时扫描H中PCC的强度;
Int (H1, PCC)是当PCC的强度处于峰的上坡或LHS上的FWHM时扫描H1中PCC的强度;并且
Int (H2, PCC)是当PCC的强度处于峰的下坡或RHS上的FWHM时扫描H2中PCC的强度;
根据FWHM的定义,用于FWHM扫描的PCC的AR2将始终为1/2,且在某种预期的容差内。
在第四步中,可以执行处理以检查扫描H、H1和H2的碎片或升高能量扫描数据,并且通过在扫描之间匹配特定碎片的质量或m/z以及将该碎片的强度比率(IR)与PCC的(如使用公式3a所确定的)AR2值的强度比率进行匹配,来确定扫描之间该PCC的碎片离子。应该指出的是,下面碎片的IR是如公式3b所表示的碎片离子ARf的AR2值。
为了进一步说明,可以执行处理以确定扫描H和H1之间的第一组匹配碎片,并且还确定扫描H和H2之间的第二组匹配碎片。例如,如果满足以下条件,则扫描H中的碎片F1被确定为与扫描H1中的碎片F1”匹配:
在某个指定的质量容差内,F1的质量或m/z与F1”的质量或m/z匹配;并且
强度比率IR计算如下:
IR=扫描H1中的F1”的强度/扫描H中的F1的强度,
其在某个指定的容差内匹配(相关PCC关于相同的扫描H和H1的)AR2。
例如,假设扫描H1处在扫描时间1004,这时碎片离子F1以质量m1和强度5,000存在,并且这时碎片离子F2以质量m2和强度5,000存在。假设扫描H处在扫描时间1008,这时碎片离子F1以质量m1和强度10,000存在,并且这时碎片离子F2以质量m2和强度6,000存在。进一步假设对于该例子,扫描H2处在扫描时间1012,这时碎片离子F2以质量m2和强度3,000存在。
然后,基于前文所述,对于扫描H和HI中的碎片离子F1,IR = 5,000/10,000=1/2,其与该PCC的½的AR2值相匹配。因此,F1被包括在该PCC的第一组匹配碎片中。
对于扫描H和H1中的F2,IR = 5,000/6,000= 0.83,其与该PCC的½的AR2值不匹配。因此,F2不包括在该PCC的第一组匹配碎片中。
对于扫描H和H2中的F2,IR = 3,000/6,000=1/2,其与该该PCC的½的AR2值相匹配。因此,F2被包括在PCC的第二组匹配碎片中。
因此,可以针对该PCC的检测峰中的每个扫描(例如,除了扫描H之外的每个扫描)确定AR2值,并且将该值包括在过滤或验证中使用的验证标准中,以确定该PCC的一组匹配或相关碎片离子。因此,对于相对于峰的每个扫描点,PCC有一个AR2值。例如,如果在该PCC的检测峰中有12个点或扫描,则该PCC将有11个AR2值(因为这12个点中有1个是峰的顶点或PP)。
应该指出的是,上文用IR表示的度量可以更一般地如公式3b中那样来表征,并且在本文中被称为另一个AR2值,它是相对于碎片离子(而不是PCC)在和PCC相同的两次扫描中的强度或面积比率来确定的。如上文和本文其他地方所述,相对于两个不同的扫描时间为该PCC确定的AR2值和在与PCC相同的两个扫描时间中为碎片离子F确定的AR2值应在某个指定的容差内相同,如果F与该PCC的碎片化相关或是通过该碎片化产生的话。
在给定扫描中PCC被干扰使得其强度不符合LC峰的情况下,近邻扫描的强度是线性回归内插,并且如果在将上坡和下坡与顶点扫描进行比较时,该PCC在异常扫描处的强度更高,则这两个AR1和AR2值应该是一致的,假定采用高斯峰形的话。因此,当比较任何近邻扫描时,在计算顶点与任何其他扫描之间的AR2值时,首先通过对近邻扫描执行线性回归和内插来验证PCC的强度。
在一个实施例中,可以执行处理以根据如上所述的扫描H1和H2的AR2值来确定这些扫描的匹配碎片的数量。然后可对为扫描H1确定的第一组匹配碎片和为扫描H2确定的第二组匹配碎片执行验证处理。这种验证处理可以包括使用一个或多个另外的验证标准,诸如使用包括其他度量(诸如AR1(面积比率1)度量)的其他标准,以及下面更详细描述的其他标准。例如,这种验证处理可以包括确定该组中的匹配碎片的数量是否至少是指定的最小数量(例如,参见图8以及本文其他地方描述的相关处理)。如果验证处理成功地验证为点或扫描H1和H2确定的匹配碎片组,则可以继续对曲线上的其他扫描或点执行该处理。否则,如果对H1和/或H2的验证处理失败,则可以使用替代技术来确定与特定PCC相关的碎片离子。
在一个实施例中,处理可进一步继续进行以确定在H1和H之间的中间点(如图7的点X1所示)上的扫描的匹配碎片的数量,然后确定在扫描H和H2之间的中间点(如图7的点X2所示)上的扫描的匹配碎片的数量。对于在点X1和X2处的每次扫描,可以执行与上文所述以及在本文其他地方结合在点H1和H2处的每次扫描所述的类似的处理。例如,对于由X1和X2表示的每次扫描,确定AR2(面积比率2)值,确定该扫描的匹配碎片组,然后确定匹配碎片组是否通过任何另外的验证标准(例如,AR1,以及本文描述的其他标准)。这些验证标准可以包括使匹配碎片集组包括最小数量的碎片。另外,所述标准还可以包括将扫描的检测碎片的数量与一次或多次其他扫描进行比较。例如,可以预期,随着PCC的强度从扫描S1增大到扫描S2,检测碎片的数量也类似地增大,由此扫描S1中的检测碎片的数量<扫描S2中的检测碎片的数量。这种标准还可以包括检查扫描S1和S2中的碎片的强度,由此扫描S1中的碎片F1的强度应类似地小于扫描F2中的F1的强度。
可以通过反复确定位于已经处理的两个其他连续扫描点之间的下一个扫描点来重复这种处理,直到PCC的峰的所有这些点都已经被处理。因此,应该指出的是,针对PCC的峰或曲线的上部(例如,包括从H1到H2的扫描点在内的上部,包括端点)中的扫描执行对中间扫描点的重复处理,并且还针对PCC的峰或曲线的下部中的扫描(例如,从点P起点到H1的扫描以及从H2到P终点的扫描)执行同样的重复处理。在一个实施例中,如果验证处理未能验证为峰的下部中在FWHM点H1和H2下方的扫描确定的一组碎片,则可以排除未通过验证处理的扫描的碎片组,并且可以继续处理在PCC的峰的下部中的任何其余扫描。
现在将描述的是另一个度量,即AR1(面积比率1)度量,其也可以被包括在用于结合确定哪些碎片离子与各个PCC相关,来验证或过滤碎片离子的验证标准中。
对于每次扫描Sj,扫描Sj中的每个产物或碎片离子Fi具有AR1(面积比率1),其可以表示为:
AR1=扫描Sj中的Fi的强度/扫描Sj中的PCC的强度
例如,在扫描S1中,假设存在强度为X的碎片F1、强度为Y的碎片F2,以及强度为Z的PCC P1,那么对于扫描S1,存在两个AR1值,其中第一个AR1值是X/Z,第二个AR1值是Y/Z。
根据本文技术的一个实施例中的处理可以使用AR1值来验证AR2值。对于使用AR2确定并且通过如上所述验证处理的每个匹配碎片Fi,现在可以使用具体碎片Fi的AR1值来执行进一步的验证处理。使用Fi的AR1执行的这种进一步验证处理可以比较碎片F1的扫描1到N(在峰中)的AR1值。如果在一定的容差内,所有这样的AR1值不相同,则碎片F1与PCC P1(其强度用于计算前述AR1和AR2值)不匹配。
用于验证特定PCC的扫描数据和相关碎片离子的验证标准还可以包括现在将描述的基于碎片化效率的另一种度量。
通常,在执行情况良好的实验中,希望不会因为采用过量碰撞能量来进行操作而导致前体离子过度碎片化。这导致在每次扫描的升高能量或碎片离子谱中出现具有质量M1的未碎片化PCC或前体离子P1的一部分。本文的技术可以确定:
1. P1是否出现在扫描S1的碎片离子或EE扫描数据中,并且如果是,
2. 确定扫描S1的EE扫描数据中P1的强度。
假定已经确定PCC或前体P1与扫描S1的产物或碎片离子F1和F2相关。对于扫描S1,P1在LE或前体扫描中具有强度X1,并且在EE碎片离子扫描中具有强度X2。下面的关系R1可以被包括在验证标准中,并且必须评估为真才能使特定扫描S1的数据有效。
关系R1
强度差X1-X2>扫描S1的EE扫描数据中所有碎片或产物离子的强度之和
前述关系R1包括左侧(LHS)的“X1-X2”。如果X1表示碎片化之前LE数据中P1的起始强度或量,并且X2表示碎片化之后P1的剩余强度或量,则表达式X1-X2表示在EE扫描数据中可能表现为碎片离子的P1的总强度或量的最大值或上限。R1的右侧(RHS)是在扫描S1的EE扫描数据中所有碎片或产物离子的强度的实际计算总和,由此表示EE扫描数据中所有可观察碎片离子的强度总和。R1的RHS应小于由R1的LHS所表示的最大值或上限。
在根据本文技术的一个实施例中,验证标准还可以包括检查为每个扫描确定的与PCC匹配或相关的碎片离子的数量。参见图7,通常可以预期,随着P起点和H之间的点的扫描时间增加(例如,从P起点向上移动到峰的顶点),应匹配的碎片离子的数量增加。另外,对于在P起点和H的包含性范围中的点P1和P2,其中P1的扫描时间<与点P2相关的另一个扫描时间,则预期包括在为点P1确定的第一组中的一个或多个碎片离子也被包括在为点P2确定的第二组一个或多个碎片中。以类似的方式,通常可以预期,随着H和P终点之间的点的扫描时间增加(例如,从峰的顶点向下移动到P终点),应匹配的碎片离子的数量减少。另外,对于在H和P终点的包含性范围中的点P3和P4,其中P3的扫描时间<与点P4相关的另一个扫描时间,则预期包括在为点P4确定的第一组中的一个或多个碎片离子也被包括在为点P3确定的第二组一个或多个碎片中。
如上所述,作为特定PCC的碎片化结果而获得的碎片的预期数量可随特定PCC而变化,并且可取决于该PCC的复杂度和强度。类似地,匹配碎片或被确定为与PCC或前体离子相关的扫描中的碎片数量可取决于PCC或前体离子的复杂度和强度。在一个实施例中,可以基于包括LE扫描中PCC的强度以及涉及(例如,表示)该PCC复杂度的属性的标准,来确定扫描中预期的特定PCC的匹配碎片的最小数量。在一个实施例中,表示扫描中的PCC复杂度的属性可以是分子量Mr(基于分子的元素组成的不带电质量)。作为变型,一个实施例可以改变用于表示分子的PCC复杂度的属性。例如,对于简单或小分子,可以使用分子量Mr(基于分子的元素组成的不带电质量)。对于肽或更复杂的分子,可以估计PCC的长度而不是Mr。PCC或前体离子的长度可随其复杂度而变化。例如,对于复杂分子诸如肽,扫描T1中的PCC是氨基酸链,并且所确定的长度可以是该氨基酸链的长度。
因此一般来讲,在扫描S1中需要与PCC匹配或相关的碎片离子的最小数量可以表示为G的函数,其中G的值是根据PCC的复杂度C和在扫描S1的LE扫描数据中该PCC的强度I确定的(例如,对于扫描S1和PCC或前体离子P1,G(C, I)=在扫描S1中要与P1匹配或与P1相关的碎片离子的最小数量)。在一个实施例中,可以使用一张由值组成的表格诸如图8中所示的表格来确定碎片的最小数量,包括可以基于本领域技术人员的专业知识和最佳实践来预先确定的信息。例如,可以基于由不同MS仪器的制造商提供或确定的信息来提供这样的最小值。
参见图8,所显示的是可以在根据本文技术的一个实施例中用于确定PCC或前体离子预期的匹配碎片的最小数量的表格的例子。表格800可以包括列802、列804和列806,其中列802中的值为表示PCC或前体离子的复杂度的属性,列804中的值表示LE扫描中PCC或前体离子的不同强度,列806标识匹配碎片的最小数量。因此,表格800的一行标识了对于同一行中列802和804中的值的特定组合所预期的匹配碎片的最小数量。在一个实施例中,列802中表示复杂度的属性可以是任何合适的属性,其一些例子在上文指出;例如,诸如分子量Mr、氨基酸链的长度,诸如对于复杂分子的情况等。
如图8所示的表格可以被用来指定在特定扫描时间对PCC预期的匹配碎片离子的最小数量,以在存在大量干扰的情况下消除严重错误。在一个实施例中,表格中指定的最小数量可以基于例如在50-60%范围内的碎片化效率(例如,可以基于本文其他地方描述的关系R1,根据经验来确定碎片化效率)。
在一个实施例中,表格诸如图8所示表格的使用可以作为最后一个步骤来执行,结合关于被确定为与针对特定PCC检测到的曲线或峰中的特定扫描的该PCC相匹配或相关的一组碎片离子的验证标准和验证处理(例如,诸如图7所示)。
在根据本文技术的一个实施例中,对于在各种扫描时间中正在确定匹配碎片离子的特定PCC,如果对于该PCC的峰的上半部分(例如,从LHS(H1扫描)上的FWHM到RHS(H2扫描)上的FWHM)中包括的所有扫描时间,验证标准不是都满足,则可以不对曲线或峰上的其他扫描点执行进一步处理。例如,如果对于PCC的峰或曲线的上半部分中的某个扫描,不满足AR1、AR2和匹配碎片离子的最小数量的验证标准,则一个实施例可以使用替代技术。用于确定在峰或曲线上半部分中的扫描的匹配碎片的这种处理可以在上半部分中的任何扫描点首次未通过验证处理时被终止(例如,未通过在一个实施例中使用的AR1、AR2、匹配碎片最小数量等验证标准)。如果验证失败发生在曲线或峰的上半部分中的任何扫描时间,则可以利用替代技术来确定与特定PCC匹配的碎片离子。如果在PCC的峰或曲线下部中的扫描(例如,从点P起点到H1的扫描以及从H2到P终点的扫描)发生验证失败,则可以对下部的其他剩余扫描继续该处理,由此排除为该特定的失败扫描确定的任何数据或碎片。
根据本文技术的一个实施例还可以使用可以为与特定分子或组分相关的每个碎片或产物离子确定的另一种度量AR3(面积比率3)。碎片Fi的AR3可以表示为:
AR3=碎片Fi (强度)/与该PCC匹配的所有碎片的强度之和
其中
Fi (强度)是与该PCC相关的碎片Fi的强度;并且
“与该PCC匹配的所有碎片的强度之和”表示与该PCC匹配的所有碎片的强度的数学总和。
在一个实施例中,可以根据每次扫描或每个扫描时间(例如,采用与本文针对AR1值描述的方式类似的方式)来为被确定为与特定PCC匹配或相关的每个碎片离子确定AR3。使用碎片离子F1的AR3值执行的验证处理可比较碎片离子F1的从扫描1到N(在特定PCC的峰上)的AR3值。如果所有这样的AR3值在一定的容差内不相同,则碎片F1与该特定的PCC不匹配(由此,作为针对扫描的A3的分母求和的碎片离子都是那些被确定为与该扫描中的PCC相联或匹配的那些碎片离子)。
因此,在非监督聚类中的这一点,对于具有如图7所示的检测峰或曲线的每个PCC,可以为该PCC的峰上的每次扫描确定一组零个或更多个碎片。使用诸如本文所述的验证标准,每个这样的碎片离子组可被进一步筛选或完善。在一些情况下,特定碎片离子组在特定扫描时间未能满足验证标准和相关处理,则该碎片离子组可被丢弃或不被进一步考虑(例如,诸如在峰的下部中的扫描时间,如本文其他地方所述),并且可以继续处理其他扫描时间产生的其他碎片组。在一些情况下,特定碎片离子组在特定扫描时间未能满足验证标准和相关处理(例如,在峰的上部的点H1和H2之间的扫描时间,如本文其他地方所述),则使用验证标准的处理可停止使用验证标准评估峰上的其他扫描时间产生的其他碎片组,并且可使用替代技术来确定哪些碎片离子与该PCC相关。
假设使用验证标准的上述处理导致针对PCC的检测峰的不同扫描时间确定了多组碎片。此时,可以执行处理以形成该PCC的SSPPIS。这种处理可以包括将在PCC洗脱峰的扫描时间上的多组碎片组合成与该PCC相关的单个碎片组,从而表示与PCC的碎片化或解离相联或由其产生的碎片组。在一个实施例中,可以将PCC的检测峰的扫描时间的多组碎片组合成作为所有这样的多组的并集的单个组,由此组合的单组碎片离子和PCC可以形成该PCC的SSPPIS。
作为在形成PCC的SSPPIS的过程中将在该PCC的检测峰的扫描时间上的多组碎片进行组合的一部分,可以将可在一个实施例中使用的不同度量诸如AR1、AR2、AR3以及任何其他度量的值进行组合。在一个实施例中,可以为AR1、AR2等确定平均值。例如,如果在PCC的峰上有12个点或扫描时间以及12个相关AR2值(分别对应于这12个点中的每一个),则可以为PCC确定平均AR2值来作为所有这12个AR2值的平均值。碎片离子F1可以在12个扫描时间中的8个的碎片离子组中出现,并且该F1具有8个AR1值(分别对应于8个扫描时间中的每一个),并且可以为F1确定平均AR1值来作为所有这些AR1值的平均值。类似地,可以针对本文所述的其他面积或强度比率度量确定平均值(例如,对于碎片离子的AR2)。还可以相对于与PCC相关的一个或多个其他属性和/或与PCC相关的碎片离子(例如,包括在与PCC匹配的单个碎片离子组中)来获得平均值。例如,在一个实施例中,碎片离子的m/z可以是碎片离子的平均m/z值(例如,相对于出现碎片离子的所有扫描时间的EE扫描数据的平均m/z)。作为变型,一个实施例可以使用在峰的顶点或点H的扫描时间出现的碎片离子的m/z值。
在处理的这一点,单个一组碎片可以与每个PCC相关或匹配,由此为每个PCC创建了一个SSPPIS。例如,参照图6,处理已经确定碎片组614a与PCC1 610相关,碎片组614b与PCC2相关,并且碎片组614c与PCC3相关。然后可以执行处理以将与特定洗脱组分或分子相关的PCC(以及相关或匹配的碎片离子,并且因此将这样的SSPPIS分组)进一步分组或组合。例如,可以执行处理来选择并分组特定的3个PCC 610a至c的3个SSPIS,从而表示这3个PCC源自同一种洗脱组分或分子,诸如P1 602。因此,将3个PCC 610a至c及其相关碎片离子组614a至c(以及与前述相关联的属性)分组的聚集结果是包括在该洗脱组分或分子的指纹或模式中的信息。包括单一洗脱组分或分子的指纹信息的前述聚集结果在本文中也可以被称为CPPIS(复合前体-产物离子谱)。
可以使用任何合适的技术将要组合成CPPIS的特定SSPPIS确定为匹配组。例如,一个实施例可以通过将每个SSPPIS的每个检测峰的每个扫描时间中的PCC的相同相对分子量Mr(在规定的容差内)进行匹配,来将3个PCC 610a至c的3个SSPPIS确定为要组合的匹配组。此外,处理可以确保在匹配组的每个SSPPIS中,PCC的每个检测峰具有相似的峰形和轮廓,其中每个峰出现在大致相同的扫描时间窗中(在某种指定的容差内)。用于验证匹配组中每个SSPPIS的哪些产物离子应被组合的处理还可以进一步包括在SSPPIS内和之间使用m/z、AR1和AR2。因此,预计前体的AR2值将遵循高斯分布。因此,如果SSPPIS的m/z、AR1和AR2值不一致(在一定容差内),则可被排除在匹配组之外。
在一个实施例中,可以诸如用并集操作将匹配组的每个SSPPIS产生的碎片离子组进行组合,以形成该洗脱分子或组分的CPPIS碎片离子组。例如,参照图6,可以将CPPIS碎片离子组确定为614a至c中碎片的并集。作为替代,处理可以进一步包括执行额外的验证处理,该处理可进一步过滤或减少在被确定为614a至c中碎片的并集的CPPIS碎片离子组中包括的碎片离子。
结合在创建CPPIS时为单个洗脱组分或分子执行SSPPIS的聚合,应该指出的是,相关属性(包括诸如m/z、AR1、AR3等的度量)以及PCC及其相关碎片离子的测量也可以被组合。在一个实施例中,AR1和AR3的误差指示器也可以是其相关的CV。
如本领域中已知的,与诸如AR1或AR3的度量有关的变化系数或CV可以被定义为标准偏差σ与均值µ的比率,其表示为:
CV公式
CV说明了与总体平均值相关的变化程度。因此,例如,可以使用碎片离子F1的相对于AR1的CV来表示与F1在PCC的峰上的强度相关的误差或一致性水平,或者相对于与洗脱组分或分子相关的所有PCC或SSPPIS。
参见图9,示出了处理的流程图,其总结了可以在根据本文技术的一个实施例中执行的用于非监督聚类的操作。流程图1200总结了如上所述的处理。在步骤1202中,可以使用样品执行实验,以获得HE扫描数据和LE扫描数据。样品可以包括一种或多种洗脱组分或分子。在步骤1204中,可以执行处理以确定LE扫描数据中的离子的PCC。在步骤1205中,可以对每个PCC执行峰检测。在步骤1206中,可以执行处理以针对每个PCC、根据包括AR1值、AR2值和其他标准的验证标准来确定与各PCC相关(例如,匹配)的一组碎片离子。验证标准可用于筛选或完善初始碎片离子组并确定每个PCC的修正碎片离子组。在步骤1208中,对于由于验证处理失败而不与一组相关碎片离子匹配的每个PCC,可以使用替代技术来确定一组相关碎片离子。在步骤1210中,可以执行处理以形成PCC的SSPPIS,其中为每个PCC确定SSPPIS,并且各SSPPIS包括PCC和源自该PCC的碎片离子的相关碎片离子组。在步骤1212中,可以执行处理以构造洗脱组分或分子的CPPIS。通过确定一组一个或多个SSPPIS来确定各洗脱组分或分子的CPPIS,其中每个SSPPIS包括源自每种洗脱组分或分子的PCC。洗脱组分或分子的CPPIS是通过组合一个或多个SSPIS的组来构造的。CPPIS可以用作洗脱分子的指纹。
结合图9,采用与本文其他地方所述一致的处理,可以在每个LE单次扫描中为每个PCC创建SSPPIS,其中从伴随EE扫描获得产物离子。伴随EE扫描中的产物离子与每个单个PCC共享(虽然按照相对于其母体前体的强度和m/z来筛选),形成独特的SSPPIS。
参见图10,示出了流程图1250,其提供在根据本文技术的一个实施例中可以在图9的步骤1206(例如,确定与每个PCC相关的碎片离子组)中执行的处理的附加细节。可以对每个PCC执行流程图1250。在步骤1214中,对于具有相关峰的PCC,确定峰的对应于H或PP(在PCC的具有最大强度的顶点)、H1和H2(FWHM扫描点)的扫描时间/点。在步骤1216中,对于FWHM扫描点H1和H2,H1是第一当前扫描点C1,H2是第二当前扫描点C2。在步骤1218中,为C1和C2确定AR1和AR2值。在步骤1220中,执行处理以根据验证标准确定C1的第一匹配碎片离子组和C2的第二匹配碎片离子组(例如,通过将碎片离子按照m/z、AR1值和AR2值以及其他标准进行匹配)。在步骤1222中,确定第一和第二匹配碎片离子组是否通过验证标准。如果未通过,则处理前进到步骤1224,在该步骤中,可以使用替代技术来确定PCC的碎片离子组。如果步骤1222评估为是,则控制前进到步骤1226,在该步骤中,确定PCC峰的上部中所有点的处理是否都完成。如果步骤1226评估为是,则控制前进到步骤1228,以对PCC峰的下部中的剩余扫描点(例如,从P起点到H1以及从H2到P终点的扫描点)执行处理,该处理是关于将下部H1到P起点和H2到P终点中的SSPPIS进行匹配,进行进一步的筛选,因为只有来自扫描H的SSPPIS中更丰富的匹配产物离子将以一致的AR1和AR2比率匹配。
如果步骤1226评估为否,则控制前进到步骤1230,以确定峰的上部中的下一组中间点C1和C2(例如,从扫描H1到H2的上部中的下一组扫描点)。如本文所述,可以通过将H与当前点C1、C2之间或者P起点与C1以及C2与P终点之间的扫描时间或距离减半,来确定每个下一组中间点。控制从步骤1230前进到1218以处理下一组扫描点。
参见图11,示出了可以在根据本文技术的一个实施例中执行的处理步骤的流程图,其用于处理PCC峰的下部中的剩余扫描点。流程图1300提供了可以在图9的步骤1228中执行的处理的附加细节。在步骤1302中,处理可以确定峰的下部中的下一组中间点C1、C2。步骤1302类似于图10的步骤1230,区别在于中间点位于PCC峰的下部。在步骤1304中,为C1和C2确定AR1和AR2值。步骤1304类似于图10的步骤1218。在步骤1306中,执行处理以根据验证标准确定C1的第一匹配碎片离子组和C2的第二匹配碎片离子组。步骤1306类似于图10的步骤1220。在步骤1308中,确定第一和第二匹配碎片离子组是否通过验证标准。步骤1308类似于图10的步骤1222。如果步骤1308评估为否,则处理前进到步骤1312以排除未通过验证标准的碎片离子组。控制前进到步骤1310。如果步骤1308评估为是,则控制直接前进到步骤1310。在步骤1310中,确定是否已经对PCC峰的下部中的所有扫描点执行了处理。如果是,则处理停止。否则,如果步骤1310评估为否,则控制前进到步骤1302。
参见图12,所示的是在根据本文技术的实施例中,可以包括在洗脱组分或分子的CPPIS中并用作洗脱组分或分子的识别指纹的信息的例子。例子900包括具有第一列PCC 902和第二列相关碎片或产物离子904的表格。该表格中的每一行表示PCC及其相关或匹配的碎片离子,如可以使用本文的技术确定的那样。该例子说明具有两个相关PCC即PCC1和PCC2的分子,其中PCC1及其相关碎片离子被包括在行910中,PCC2及其相关碎片离子被包括在行912中。通常,每行910、912可以包括PCC及其相关碎片离子的信息,诸如各种属性。为了进一步说明,元素930提供了关于行910的信息的进一步细节,如可以在根据本文技术的一个实施例中生成并使用的。行912可以包括与930类似的信息,尽管在例子900中没有示出。
如元素930所示,PCC1可以与碎片离子F1和F2相关。PCC1的属性包括m/z和电荷态z。每个碎片F1、F2的属性可以包括m/z、AR1、AR3,AR1和AR3的CV,以及本文所述和本领域已知的其他属性。如可以在根据本文技术的一个实施例中存储的用于PCC和碎片离子的其他属性可包括例如疏水性值、漂移时间或如果使用离子淌度的话碰撞横截面积(CCSA)等。
对于单独的碎片离子和PCC以及每个分子的指纹,可以存储一个或多个误差值,诸如图12所示的CV。本文所述的这样的误差值可以包括CV作为指纹数据的一致性或拟合度的量度。通常,如果分子是使用由具有相关CV的非监督聚类生成的数据的模式或指纹来识别的,则一致性越高(诸如由一个或多个相关CV指示),所得数据越好。更一般地说,除了CV之外,可以在根据本文技术的一个实施例中使用其他误差指示器。例如,一个实施例通常可以使用任何合适的误差指示器或一致性指示器,诸如标准偏差、方差等,而不是CV。
应该指出的是,对于图12中包括的每个PCC,可以存储各PCC的同位素模式或簇(例如,诸如由图6中的604所示)。
根据本文技术的一个实施例可以多次重复非监督聚类(对于同一样品,或者包括相同组分或分子的不同样品),并且以组合形式将数据的综合结果存储在库或数据库中。因此,可以以迭代方式执行非监督聚类,每次迭代更新迄今为止为所有迭代获得的分子的组合或综合指纹结果。当执行额外的迭代时,与分子的指纹相关的CV或其他误差指示器也被更新以反映所有这些已执行的迭代。
结合将来自非监督聚类的多个实例的指纹信息进行组合,应该指出的是,第一分子的第一指纹信息可以基于匹配标准被确定为与当前在库或数据库中的现有第二指纹信息匹配。这样的匹配标准通常可以包括确定一个或多个属性(包括诸如m/z、扫描/保留时间、漂移时间等的属性),以及诸如与PCC和/或指纹碎片相关的一个或多个面积或强度比率(例如,AR1、AR2、AR3)的度量之间的匹配(在指定的容差内)。
例如,这样的匹配标准可以包括例如基于扫描时间、m/z和AR1、AR3值等来确定是否存在统计学显著数目(匹配产物离子相对于库中的所有其他CPPIS的数量)的(在容差内)匹配的匹配碎片。如果确定了这样的匹配,则可以将第一指纹信息与现有的第二指纹信息进行组合。这种对CPPIS的组合通过将指纹限制为仅重复m/z值,更新任何相关度量(例如,AR1值、AR3值等)以及误差指示器诸如CV,来额外地筛选指纹。以组合形式保持的相关度量(诸如AR1值)可以是例如该度量的平均值。考虑到指纹中的任何匹配和验证产物离子的强度,AR1值可以被用来估计PCC的强度值。
结合将来自非监督聚类的多个实例的指纹信息进行组合,应该指出的是,如果根据匹配标准确定新分子的第一指纹信息不是现有分子的指纹的匹配项,则可以将该第一指纹信息作为新指纹添加到库或数据库中。
在第一时间点,诸如在执行了特定次数的非监督聚类迭代之后,可以执行额外的处理来评估针对所有分子获得的所得的综合指纹数据。这样的评估可以包括检查与指纹数据相关联的CV或其他误差指示器以确定哪个前体和/或相关碎片在识别特定分子中是“最好的”或最一致的。
例如,在第一PCC和第二PCC之间比较的第一碎片可以具有当被比较时具有指示低误差(例如,诸如低于指定阈值)或高一致性的相关CV的AR1和/或AR2值,以及与AR1值和/或AR2值相关的第二碎片,所述AR1值和/或AR2值具有指示高误差或低一致性(例如,诸如高于指定阈值)的相关CV。基于这些误差指示器,诸如第二碎片的AR1和/或AR2值的CV(第一PCC到第二PCC,或者第一CPPIS到第二CPPIS),可以在评估期间确定第二碎片应从数据库中删除,并且由于使用非监督聚类技术获得的观察结果的高误差或不合格的不一致性,将该第二碎片确定为实际上与PCC的SSPPIS或CPPIS不相关。基于误差指示器,诸如第一碎片(诸如可以包括在库或CPPIS中的第一碎片)的AR1值的CV,可以在评估期间确定重复执行非监督聚类已经确认,由于使用非监督聚类技术获得的观察结果的低误差和一致性,第一碎片与PCC相关。因此,作为这样的评估的结果,可以修改或更新组合或综合结果,诸如例如基于该评估来移除和/或添加与分子相关的指纹的一个或多个特定碎片。这样的评估还可以使用误差指示器(诸如与前体相关的AR1值的CV)确定指纹的PCC是否应在指纹中保留或者移除(例如,如果一个或多个相关的误差指示器诸如其AR1值不像以上针对碎片离子所述的方式那样满足指定的阈值水平,则移除或排除该PCC)。
参见图13,示出了可在根据本文技术的一个实施例中执行的处理步骤的流程图。流程图1000总结了如上所述的处理。在步骤1002中,可以执行非监督聚类,其中生成当前一组所得到的SSPIS,然后将其进一步分组成一个或多个CPPIS。在步骤1004中,可以将当前CPPIS组与任何现有数据组合,诸如包括先前执行非监督聚类技术所产生的数据的现有组合数据集合。步骤1004可产生组合了前体离子的结果以及表示分子指纹的相关碎片离子的当前组合数据集合。步骤1004可导致将数据集合进行组合,诸如并集方式,由此没有指纹的碎片或PCC被移除。组合的数据集合可以被存储在例如库或数据库中。
在步骤1006中,确定是否是到了执行评估处理的时间。如上所述,步骤1006可以包括例如确定是否已经执行了指定次数的非监督聚类迭代,是否经过了指定的时间量等。如果步骤1006评估为否,则控制前进到步骤1002。如果步骤1006评估为是,则控制前进到步骤1008以评估当前的组合数据集合,诸如包括从多次执行非监督聚类产生的组合信息的库或数据库的当前版本。在步骤1008中,执行评估处理以评估当前的组合数据集合。如本文其他地方所述,这样的评估可以包括检查与识别分子的每个指纹、指纹的离子等相关的误差指示器,以确定是否需要对组合数据集合进行任何更新或修正。在步骤1010中,可以根据步骤1008的评估来执行这样的更新或修正。步骤1008和1010确定例如与前体或PCC相关的哪个或哪些碎片应保留在指纹中,以及与前体或PCC相关的哪个或哪些碎片应从指纹中移除,指纹的哪个或哪些前体或PCC应保留,以及指纹的哪个或哪些PCC(以及相关的碎片)应被移除。步骤1010可以包括例如使用碎片离子的AR1、AR2和可能的AR3值的CV来确定当前与PCC相关的碎片离子是否应从指纹中移除,由此得推断该碎片离子实际上与用于识别目的的PCC或前体不相关。在步骤1012中,作为步骤1010的结果生成的更新的组合数据集合可以用作识别分子的指纹的库或数据库。
因此,流程图1000描述了一种可以执行的过程,其将非监督聚类的多次迭代的结果合并到一个组合数据集合中,该数据集合已经根据与用来识别分子的每个指纹相关的误差指示器或一致性指示器被修正或更新。流程图1000的输出可以是例如用于识别分子的库或数据库的特定版本。流程图1000的处理可以重复一次或多次以确定库或数据库的第二和更多后续版本。因此,可以执行流程图1000的处理来生成用作库或数据库的经验证和完善的组合数据集合。可以通过使用包含具有通过使用非监督聚类确定的指纹的已知分子的样品执行重复实验,来生成经完善的组合数据集合。
在一个实施例中,可以重复流程图1000的处理,直到与指纹相关的误差或一致性指示器满足指定的阈值水平,从而指示指纹数据处于“稳定状态”。例如,可以执行这样的处理,直到使用非监督聚类获得的指纹具有相关误差或一致性指示器,该指示器表示用于确定该指纹的所得的综合数据在指定的一致性水平内一致(例如,具有低于指定阈值的CV值,从而表示通过非监督聚类获得的综合数据中的相对一致性)。为识别分子的指纹所获得的这种一致性表示相关的高水平的置信度,即该指纹正确地识别该分子,并且该指纹已经将指纹的PCC与其一个或多个碎片离子正确地相关。
根据本文技术的一个实施例可以为不同的仪器类型,或者更具体地讲,为用于离子解离或碎片化的每种不同技术生成和/或利用不同的库或数据库。例如,本文的技术可以产生和/或利用第一库或数据库,该库用于使用碰撞室来进行碎片化的MS仪器,以及用于作为离子阱MS仪器等的MS仪器的第二库或数据库。
一旦使用非监督聚类生成具有一致数据的验证库,就可以对库的指纹进行比较以确定样品是否包含特定分子(其中在识别之前样品是否含有特定分子是未知的)。例如,如本文其他地方所述,经验证的库可以结合监督聚类来使用。另外,经验证的库也可与已知包含特定分子的样品一起使用,以进一步识别关于该样品的差异或异常。例如,可以知道样品包含具有库中的第一指纹的第一分子,诸如第一肽。该样品还可以包含其他分子。因此,对样品的处理诸如使用本文其他地方所述的监督聚类进行的处理,预期会产生第一指纹。如果在处理样品时有额外的不匹配离子(例如,PCC和/或碎片离子与验证库中的任何分子都不匹配),则这些额外的不匹配离子可能是由于样品中还存在的另一种分子或组分的干扰而产生的。
一般来讲,应该指出的是,多个实验产生的SSPPIS可以单独存储,或者可以以任何合适的组合形式存储,诸如本文也称为存储在数据库中的CPPIS。在根据本文技术的一个实施例中,本文的技术可以对SSPPIS形式的数据进行操作并且可以生成SPPIS。SPPIS可以采用组合形式或组合数据集合诸如CPPIS来存储。CPPIS可以被拆解成与其相关的SSPPIS,以便用于本文描述的处理。
现在将描述的是可以结合监督聚类使用的技术。监督聚类是指通过将已知目标化合物(诸如来自指纹数据库或模拟数据库)的PCC和相关碎片离子与从样品的实验结果获得的SSPPIS进行比较来创建受监督的CPPIS,由此这样的比较可以使用已定义的一组匹配项,以及保留时间、漂移(如果执行IMS的话)、m/z、AR1、AR2,以及给定匹配产物离子的话,AR3的容差。
一般来讲,在使用监督聚类的情况下,存在含有分子的已知指纹或模式的目标库(例如指纹应当针对特定洗脱组分或分子的库)。对于执行实验的给定样品(例如,诸如LC/MS或LC/MS/IMS实验),可以使用本文所述的监督聚类技术处理实验数据,以确定样品是否包含已知分子或洗脱组分。可以通过确定样品的实验数据是否与从库中获得的已知分子的已知模式或指纹相匹配,来做出这样的确定。可以采用任何合适的方式产生或获得包括已知分子的指纹信息的目标库。例如,目标库可以是使用本文所述的非监督聚类生成的经验证的库的版本。目标库的数据可以例如使用模拟器等来生成。根据监督聚类,例如,可以通过分析样品的实验数据集和来获得PCC。可以执行处理以查询库,以确定该PCC的库中是否存在现有信息。可以通过将从实验数据集合获得的PCC的属性信息与库中PCC的属性信息进行匹配,来做出这样的确定。PCC的这种属性信息可以包括例如m/z、AR1、AR3值等。
根据本文技术的一个实施例可以使用模拟器或建模软件,例如,如Geromanos, S. J.、Hughes, C.、Golick, D.、Ciavarini, S.、Gorenstein, Μ. V.、Richardson, K.、Hoyes, J. B.、Vissers, J. P.C.和Langridge, J. I. (2011),Simulating and validating proteomics data and search results. Proteomics,第11卷,第6期:第1189-1211页中所述,该文献以引用方式并入本文。
如果在目标库中找到匹配的PCC条目,则可以如本文其他地方所述,使用来自目标库的该PCC的信息执行进一步处理来进行非监督聚类,不同之处在于,不是使用顶点或峰扫描(例如,PP或H扫描)的扫描数据,而是使用来自用于PCC的库的目标指纹来执行处理。例如,不是使用或比较来自H扫描的碎片,而是使用来自PCC的库的碎片。为了进一步说明,并不是将H扫描的碎片与H1和H2扫描的碎片进行比较,诸如当执行非监督聚类时,监督聚类另选地将从实验数据获得的H1和H2扫描的碎片与从库获得的PCC的碎片离子信息进行比较。在一个实施例中,首先,来自该库的碎片按照m/z与H扫描相匹配。然后这些匹配的产物离子经历与针对非监督聚类所述相同的处理。
在采用监督聚类的情况下,使用如上关于非监督聚类所述的样品来执行实验,以获得扫描数据集合,对该数据集合进行分析以确定LE扫描数据中的PCC。然后可以针对与来自库的PCC匹配的所生成数据的特定PCC执行进一步处理。例如,生成的数据可以包括PCC1的洗脱峰,PCC1的m/z与库中的PCC1的该属性相匹配。如本文其他地方所述,在非监督聚类的情况下,可以检查LE扫描数据中PCC1的检测峰,以确保其符合表征分子洗脱峰的条件。例如,检测峰必须在峰的扫描点具有适当的强度分布(例如,从P起点增大到顶点并且从顶点减小到P终点)。
继续讨论该例子,所述库表明PCC1与15个碎片离子F1至F15相关。不同于像在非监督聚类中将EE扫描数据与来自扫描H的碎片一起使用一样,监督聚类的处理是使用碎片离子F1至F15以及从库中获得的相关属性和信息来执行。与非监督聚类的情况一样,这样的处理可以确定PCC1的库中的F1至F15与扫描H1的EE数据中的碎片之间的第一数量的碎片匹配。类似地,对于扫描H2,可以执行处理以确定PCC1的库中的FI至F15与扫描H2的EE数据中的碎片之间的第二数量的碎片匹配。这种匹配可以使用如上文结合非监督聚类所述的的验证标准和处理来执行,不同之处在于使用来自库中的PCC1的信息而不是来自H扫描的信息。例如,根据基于AR1、AR2和AR3值或碎片的任何这些组合的m/z匹配和强度比率匹配,该PCC洗脱峰的扫描的碎片离子组可以与库中的FI至F15的信息匹配。应该指出的是,AR值可以被包括在库中用于与实验计算进行比较。
下面描述的是关于监督聚类中使用的各种度量的区别的附加细节,而不是本文其他地方关于非监督聚类所述的那些。
一个区别是AR1、AR2和AR3度量计算仅对按照m/z与库碎片匹配的那些产物离子执行。类似于非监督聚类,监督聚类一开始将库碎片离子按照m/z与H扫描(在一定的容差内)进行匹配,所有后续处理与非监督聚类相同。
如同结合非监督聚类的情况,处理现在检查H1和H2扫描的碎片离子数据或EE扫描数据。对于扫描H1,检查EE扫描数据并确定来自扫描H1的EE扫描数据的哪些碎片离子与库中PCC信息的碎片离子F1至F15中的任何一个相匹配。如结合非监督聚类所述的,可以通过将m/z、AR1、AR2和AR3强度比率值(在规定的容差内)进行匹配,来在扫描H1与库之间确定这样的碎片匹配。
因此,执行处理以确定如在库中识别的PCC的碎片离子与扫描H1的EE扫描数据中的碎片之间的PCC的第一组匹配碎片。还类似地执行处理以确定如在库中识别的PCC的碎片离子与扫描H2的EE扫描数据中的碎片之间的第二组匹配碎片。例如,如果满足以下条件,则库中的碎片F1被确定为与扫描H1中的碎片F1”匹配:
库中F1的m/z与扫描H1中F1”的m/z在某个指定的容差内匹配;并且
强度比率IR计算如下:
IR=扫描H1中的F1”的强度/来自H的F1的强度,
其相对于相同的两个扫描H和H1,在某个指定的容差内匹配PCC强度的AR2值。作为第二实施例,可以使用F1的AR1值来获得碎片离子诸如来自库的F1的预测强度。具体地讲,可以针对匹配的PCC获得F1的估计强度,由此来自库的AR1值可以乘以扫描HI中PCC的强度。类似地,从库获得的任何碎片离子的AR1值可以用于确定洗脱峰的任何扫描中PCC的强度。如本文其他地方所述,AR1=产物离子的强度/前体离子或PCC的强度。因此,给定PCC强度,通过将碎片离子的AR1 * PCC强度相乘来得到碎片离子的强度。
在PCC的峰中每个扫描时间的碎片离子组的验证处理可以如本文其他地方所述的那样用非监督聚类来执行,以确定PCC的库中的碎片离子与包括在PCC峰的那些扫描时间的EE扫描数据中的碎片离子之间的匹配。例如,如上所述,处理可以根据这样的AR2值来确定用于扫描H1和H2的库中的匹配碎片F1至F15的数量。然后对为扫描H1确定的第一组匹配碎片和为扫描H2确定的第二组匹配碎片执行验证处理。这样的验证处理可以包括使用本文其他地方结合非监督聚类所述的一个或多个验证标准。与非监督聚类的情况一样,这样的验证处理可以包括使用AR1值验证AR2值并确定关系R1是否为真(即,碎片离子的强度不得大于其PCC的强度)。可以在监督聚类中确定AR1度量,如本文其他地方针对非监督聚类所述的。验证处理可以比较在库中表示的碎片离子F1在PCC峰中的扫描的AR1值。如果PCC峰中的所有扫描的所有这些AR1值(如使用实验数据确定的)与来自库的F1的AR1值在一定的容差内不匹配,则碎片F1与强度用于计算AR1和AR2值的PCC不匹配。
这样的验证处理可以包括确定H1的第一匹配集合和H2的第二匹配集合的每个中的匹配碎片的数量是否至少是指定的最小数量(例如,诸如可以使用本文其他地方所述的图8的表格)。针对监督聚类执行的此类处理类似于上文针对非监督聚类相对于AR2值以及验证标准所述的处理,验证标准是每个扫描是否具有满足最小数量的相关数量的匹配碎片。例如,可以执行处理以遍历PCC峰的扫描H1和H2之间的扫描点,并且确定从H1到H2的每个扫描点是否至少具有最小阈值数量的匹配来自库的PCC的已知碎片的碎片。
确定PCC峰中所有扫描点的匹配碎片离子组可以采用与本文其他地方针对非监督聚类所述的方式类似的方式来执行。
应该指出的是,上述过程是查询目标库以返回指定PCC的一组碎片离子诸如F1至15,然后执行处理以确定PCC峰中的扫描的匹配碎片离子组,以及每个这样的扫描是否具有至少所需最小数量的碎片离子匹配(在来自库的F1至F15的每个EE扫描数据中的碎片离子之间)。对于检测PCC的峰中的每个扫描点,可以应用如本文所述的标准(例如,使用各种比率或AR值,碎片离子匹配的最小阈值数量等),并且如果某个扫描点满足这样的标准,那么该扫描的SSPPIS被认为与目标库中的目标PCC匹配。在一些情况下,可以仅通过单次扫描匹配来确定实验数据中的检测PCC与所考虑的库的目标PCC相匹配(例如,如利用DDA获得的实验数据)。对于检测的PCC,可以如本文所述计算AR3值。同样如本文结合非监督聚类所述的,可以执行处理以将与相同洗脱分子相关的多个匹配SSPPIS组合在一起。与AR1值一样,AR3值必须在所有SSPPIS中保持一致(在指定的容差内)。
在一个实施例中,可以使用理论数据诸如使用模拟器生成的数据来填充目标库。一旦确定再库中的目标PCC和样品实验数据集合中的PCC之间存在匹配,则可以使用按照本文所述的处理从PCC的实验数据集合获得的信息来替换或补充库中的目标PCC的信息。例如,根据实验数据确定的用于PCC的SSPPIS的信息可以替换库中目标PCC的理论上生成的信息(例如,保留时间)。
如本文其他地方更详细描述的,监督聚类可以结合许多不同的应用和工作流程过程来使用。例如,可以对照从一组实验数据获得的所有SSPPIS来查询来自目标库的特定碎片离子组,以查找目标分子的任何修改或变体。输入碎片离子组显然与给定的PCC匹配。分子的任何变体都将产生与修改之前的无变体形式的碎片化谱相似的碎片化谱(碎片离子列表)。作为响应于定位这样的匹配碎片离子组的输出,可以返回与匹配碎片离子组相关的PCC。前述内容是监督聚类可以与目标库一起使用的另一种方式。因此,在受监督的SSPPIS识别和随后的CPPIS形成中,PCC在SSPPIS中的存在不是必需的。虽然目标肽的有效识别要求其PCC存在,但受监督的过程提供了根据本文的技术操作的实施例,其能够识别目标肽的任何修改(序列、化学、转换后)、变体(点突变)或遗漏的裂解形式,前提是有统计学显著数目的产物离子匹配。如果有统计显著数目的产物离子匹配,则可以计算目标前兆m/z以及所有匹配SSPPIS中存在的前体的该值之间的Δm/z。可以将这一Δm/z与已知Δm/z值的查找表进行比较来尝试识别修改的来源。结合本文其他处理对此进行更详细地描述。类似地,如果匹配产物离子只反映指示遗漏的裂解的单个碎片化路径(y”或b碎片离子),则可通过对照近邻肽的碎片化模式查询来自每个匹SSPPIS的残余(未匹配)产物离子,来检索该近邻肽序列以进行构象。这在本文其他地方结合前体的变体或修改更详细地描述。
因此,作为确定样品包括具有目标库中的指纹信息的特定已知分子的一部分,可相对于针对样品获得的实验扫描数据集合执行监督聚类。例如,如果从实验扫描数据获得的所有SSPPIS都与目标库中已知分子的SSPPIS信息相匹配,则样品的所得CPPIS已被确认为仅包含如目标库中确定的已知分子。然而,作为另外一种选择,样品的监督聚类可能不能匹配在实验扫描数据集合中识别的一些PCC和一些碎片离子,这些PCC和碎片离子也可以被称为残余、遗留或不匹配的PCC和碎片离子。例如,图3的元素354表示这样的一个残余组的不匹配离子。在这种情况下,样品的CPPIS包括如包括在目标库中的已知或目标分子的匹配PCC何碎片离子。未包括在样品的已识别CPPIS中的残余组未匹配PCC和碎片离子可以表示一些未包括在该库中的变体、未知或未识别的分子等。如本文其他地方所述,可以进一步处理或分析该残余组。
如上所述,监督聚类执行与非监督聚类相同的处理,具有如本文所指出的不同之处,由此在非监督聚类中用于比较的目标或基准是扫描H,其表示扫描中的跟踪PCC的洗脱峰的顶点。相比之下,在监督聚类中,目标被指定为具有来自库的已知模式或指纹(例如,SSPPIS或CPPIS)的已知组分或分子。在至少一个实施例中,在监督聚类中使用的目标库最初可以由模拟器生成,因此该库包含理论数据。
如本文所述的监督聚类可以使用同样的AR(面积比率或强度比率)度量,其具有针对不同目标而考虑的变化(例如,非监督聚类使用来自洗脱PCC峰的扫描的信息,而监督聚类使用来自库的信息)。
通常,可以采用任何合适的方式来生成或更一般地说获得目标,诸如可以结合监督聚类使用的目标库。例如,可以从包括已知分子或化合物(诸如肽)的信息的库获得目标,该库是从任何先前的实验、模拟、非监督聚类等生成的。
监督聚类具有许多不同的应用和用途,其中一些在本文中有所描述。例如,监督聚类可以与本文所述的已知分子的目标库一起使用确定样品是否包含该库中包括的具有相关指纹的已知分子。因此,可以使用监督聚类来确认被测样品中是否存在已知分子。另外,监督聚类也可以用于确定被测样品是否包含任何残余或不匹配PCC和/或碎片离子,由此可以表示样品可以包含一种或多种未识别的分子、变体等。
参见图14,示出了可在根据本文技术的一个实施例中执行的处理的流程图1100。样品可以包含已知的第一分子,以及已知的或未知的附加的变体、异常、附加的第二分子等。这时,假设有一个目标库或数据库已经被验证,诸如上文所述,它包括表示第一分子的一致的指纹数据。使用这样的库或数据库,可以执行流程图1100的处理。在步骤1102中,使用包括第一已知分子和附加的变体、异常或第二分子的样品来进行实验。在步骤1104中,可以使用经验证的库或数据库以及从步骤1104获得的样品实验数据来执行监督聚类。作为监督聚类的结果,实验数据的第一部分离子被聚类成也与库的目标SSPPIS匹配的SSPPIS。同样作为步骤1104的结果,实验数据的剩余第二部分离子不与库或数据库匹配。实验数据的剩余第二部分是实验数据中未被聚类成一个或多个SSPPIS(例如,PCC和关联碎片的一个或多个实例)的遗留或不匹配离子的剩余组,因此不匹配由该库或数据库表示的SSPPIS。因此,剩余第二部分离子包括表征已知附加的变体、异常或附加的第二分子的离子。在步骤1106中,剩余组不匹配离子的未监督聚类产生表示该变体、异常、附加分子等的SSPPIS结果组。因此,步骤1106中非监督聚类生成的SSPPIS结果组可以用作表示该变体、异常、附加分子等的指纹,并且可以用于构建第二数据库或库(例如,诸如使用上文结合图13所述的处理)。一个实施例可以重复执行流程图1100的处理,使用包括相同化合物或分子的相同样品或多个样品进行多次实验。可以使用这样的重复处理来获得表示该附加变体、异常、附加分子等的指纹的多组SSPIS。步骤1106中多个实验产生的多组SSPPIS可如本文所述进行组合以形成该附加变体、异常、附加分子等的指纹的综合数据。
现在将描述使用目标库的监督聚类技术的一个附加实施例或变型。
参见图14A,示出了流程图1700,其包括可在根据本文技术的一个实施例中执行的用于监督聚类的处理步骤。处理可以包括执行步骤1202、1204和1205,如本文其他地方结合图9所述。在步骤1702中,可变的当前PCC可以被分配要被处理的下一个PCC。在步骤1704中,确定当前一组实验数据中的所有PCC是否已经都被处理。如果步骤1704评估为是,则控制前进到步骤1712。步骤1712的处理可以包括执行步骤1210和1212,如本文其他地方所述,以及任选的附加处理。步骤1712的附加处理可以包括例如用从实验数据的当前处理获得的信息来替换现有库信息(例如,关于PCC和相关碎片)。例如,如果库包含如使用模拟器获得的理论上生成的信息,则可以更新该库以使用作为流程图1700处理的结果从实验数据获得的PCC或前体及相关碎片离子信息来替换这种现有信息。
如果步骤1704评估为否,则控制继续进行以处理当前PCC。在步骤1706中,确定在当前PCC的库中是否找到匹配的PCC。如本文其他地方所述,这样的匹配PCC可以基于(在某个指定的容差内)匹配的m/z,m/z和保留时间,m/z、保留和漂移时间,或者更一般地说,离子检测前分离方法的任何组合。如果步骤1706评估为否,则控制前进到步骤1702。如果步骤1706评估为是,则控制前进到步骤1708,以从库中检索匹配的PCC的碎片离子信息(对于一个或多个碎片离子)。在步骤1710中,可以对PCC的H扫描或顶点扫描的实验数据的HE扫描数据进行筛选,以仅包括从库中获得的与PCC的碎片离子匹配的那些碎片离子。例如,假设PCC的扫描H或顶点扫描的HE扫描数据包括表示为F1至F15的15个碎片离子,并且对于同一PCC,库包括5个碎片离子F1至F5。步骤1710中的这种筛选对HE扫描数据进行筛选,以确定仅包括碎片离子F1至F5的信息的第一过滤碎片离子组。第一过滤碎片离子组的信息将在随后的处理中使用,并且扫描H或顶点扫描的HE扫描数据中碎片F6至F15的剩余碎片离子信息可能不会被进一步用于随后的处理步骤中。处理前进到步骤1206以执行如本文其他地方(诸如结合图9)所述的处理。在这种情况下,用于PCC的顶点或H扫描的碎片离子信息限于在实验数据的HE扫描数据中仅针对第一过滤碎片离子组中的那些碎片离子的碎片离子信息。处理从步骤1206前进到步骤1702。
不同于在解离过程中产生许多产物离子的肽或其他复杂分子,小分子通常只产生少量产物离子。另外,小分子通常带有单电荷,它们的碎片也如此。当与来自肽的碎片离子比较时,它们的强度比率(AR1)通常非常低。具有单电荷和较低的强度不会形成许多同位素。在此,仅使用前体产物离子面积关系来识别和验证哪些产物离子与哪个前体相关将需要比较大量的类似实验。然而,根据本文技术的一个实施例可以利用许多小分子实验室采用的50%幸存者产率策略(例如,50% PCC产率规则),前提是仪器控制软件可以逐个扫描地改变碰撞能量。这导致碎片化模式在分子的整个洗脱过程中的变化,为对齐的识别和验证提供了额外的正交性。共洗脱小分子的产物离子在给定的碰撞能量下将具有不同的50%幸存者产率,从而将它们与“真正的”母体前体产生的产物离子分离。如以下段落中更详细描述的,根据本文技术的一个实施例可将前述内容并入为小分子应用执行的实验和数据分析中。
对于小分子而言,根据本文技术的一个实施例可以通过在整个洗脱峰中改变碰撞能量,来逐个扫描地改变洗脱峰上的碎片化模式。如本文其他地方所述,碎片化模式可表征为产物离子与其母体前体(诸如其相关PCC)之间的强度关系。碎片化模式使得在整个色谱洗脱过程中,上述两者之间的面积比率或强度必须(在某个实验方差内)一致,前提是分子洗脱碎片化模式上的多个循环可以在碰撞能量循环之内和之间进行比较。本文中的技术利用母体离子(诸如PCC)与其碎片之间的这样的原理和关系。详细地说,前体的碎片化模式在其洗脱过程中是一致的。为此,在相同碰撞能量循环以及不同的碰撞能量循环中的相同能量下,前体离子与其成分产物离子之间的强度关系在不存在干扰的情况下应保持恒定。前体离子或PCC在碎片化过程中将产生的产物离子的数量是其长度/质量和浓度的函数。当PCC的强度在检测峰上变化(例如,增大和/或减小)时,其产物离子的强度也同样地变化。
根据本文的技术,一个实施例可以在对含有小分子的样品执行的实验中逐个扫描地改变碰撞能量。假定已经对含有小分子的样品执行了实验,导致获得LE扫描数据和EE扫描数据。如本文所述的LE扫描数据主要包括前体或PCC扫描数据,并且EE扫描数据主要包括碎片离子扫描数据。可以检查这样的LE和EE扫描数据集合,以针对特定的PCC或前体离子确定导致在EE扫描数据中出现的PCC或前体离子的碰撞能量(CE)近似于在LE扫描数据中PCC或前体离子的强度的½或50%(例如在某个指定的容差内)。如本文其他地方所述,基于不同组扫描数据中的匹配m/z,同一种离子可位于不同组的扫描数据中,诸如LE扫描数据和EE扫描数据。
作为第一步,可以检查LE扫描数据以获得PCC或母体前体离子的强度。例如,假设扫描S1中的LE扫描数据中PCC或母体前体离子的强度是10e6。作为第二步,检查EE扫描数据,以在扫描S1处定位EE扫描数据中的PCC,并获得当该PCC在扫描S1处出现在EE扫描数据中时的PCC强度。例如,假设LE扫描数据的扫描S1中PCC或母体前体离子的强度是10e3,从而表示50%的PCC没有被碎片化,并且50%的PCC已经被碎片化。作为第三步,可以确定LE扫描的扫描S1中和EE扫描的扫描S1中PCC或前体离子的强度之间的差异。前述差异表示从扫描S1中的PCC或前体离子产生的任何碎片离子的预期总强度的最大值或上限。继续讨论前面给出的例子,这意味着10e6 - 10e3 = 10e3表示从扫描S1中的PCC或前体离子产生的任何碎片离子的预期总强度的最大值或上限。另外,如在扫描S1的LE扫描数据中那样,差值10e3也等于10e6的PCC或前体离子强度的50%。因此,根据本文技术的一个实施例可以记录与扫描S1中PCC或前体离子的碎片化结合使用的特定CE,其中这样的CE导致大约50%的PCC或前体离子被碎片化。在本文的描述中,前述内容也可以被称为50% PCC产率规则。
根据本文技术的一个实施例可以执行这样的实验,其中针对每次扫描改变CE能量,并且CE能量随时间变化以在形成循环或周期的后续扫描中循环经历一系列CE值。CE循环或周期在后续扫描的第一部分中从最小CE值开始增大CE,诸如在步骤的CE间隔中,直到CE达到最大值或顶点值,然后CE随后在CE间隔或步骤中减小,直到达到最小CE值,然后重复CE循环或周期。
参照图15,示出了例子1400,它以图形方式示出了CE如何可以根据每次扫描来变化,使得CE值形成包括CE循环或周期的峰。点A、C、E和G可以表示CE循环或周期中的CE最小值,点B、D和F可以表示CE循环或周期中的CE最大值。可以在两个连续CE周期或循环中的相同CE值对之间表示单个CE循环或周期。例如,可以在点A和C之间表示单个CE循环或周期,由此CE在从点A到点C的每次扫描中被设置为不同的CE值,这开始了一个新的CE循环或周期。一个实施例可以在每次扫描中将CE值在CE循环或峰的上坡上从CE最小值递增到最大CE值,并且还在每次扫描中将CE值在CE周期或峰的下坡上从最大CE值递减到最小CE值,递增量为针对每个扫描的预定量。可以使用任何合适的技术,诸如根据控制CE设置的数学函数或使用软件和/或硬件在每次扫描时进行选择,来确定每次扫描的这些CE值。
在本文所述的一个实施例中,诸如图15等所示,CE循环可被表征为高斯峰或曲线,使得在同一CE循环的下斜坡上以相反的顺序重复上坡的CE。例如,L1、L2和L3表示CE循环1510a的上坡上点,点L6、L5和L4表示CE循环1510a的下坡上的点,其中点或扫描L1和L6具有相同的CE,点或扫描L2或L5具有相同的点CE,并且点或扫描L3和L4具有相同的CE。以类似的方式,重复每个循环的CE,使得例如L7表示CE循环1510b中的具有与L3和L4相同的CE的点或扫描,L8表示CE循环1510b中的具有与L5相同的CE的点或扫描,并且L11表示CE循环1510b中的具有与点L2、L5和L8相同的CE的扫描。类似地,L9表示CE循环1510c中的具有与L3、L4和L7相同的CE的点或扫描,L10表示CE循环1510b中的具有与L5和L8相同的CE的点或扫描。因此,使用由形成高斯型峰或曲线的CE值组成的CE循环使得除了顶点或峰CE值之外的每个CE值在每个CE曲线内出现两次。此外,如果在一个色谱峰中存在“n”个CE循环,如下面更详细描述的那样,那么在该单个色谱峰中,每个这样的CE值(除了峰CE值)出现2n次。
应该指出的是,CE变化期间的每个CE循环或周期中的扫描或扫描实例的数量为至少中值或均值色谱峰宽除以二(2)。更正式地说,假设每次扫描中CE都是变化的,那么表示CE循环中的扫描次数的CE循环周期T可以表示为:
T ≤洗脱峰或色谱峰的FWHM CE循环公式
其中
T是CE循环的周期,表示单个CE循环中的扫描的整数数量,其中CE在每个扫描处变化;并且
洗脱峰或色谱峰的FWHM表示与样品中洗脱组分或分子相关的中值或均值洗脱峰或色谱峰的FWHM(例如,FWHM=均值或中值洗脱峰或色谱峰宽/2)。
通常,CE循环公式更正式地表达了执行下述实验的希望:其中对于与单个分子相关的任何洗脱峰中的扫描,出现至少一个CE循环(例如,单个分子或组分的任何洗脱峰将经历至少一个CE循环或经历CE循环中的每个CE至少一次)。
当改变单个PCC的单个洗脱峰的CE能量时,可以检查LE扫描数据和EE扫描数据来确定50%
PCC产率规则适用的扫描(例如,其中PCC或前体离子在EE扫描数据中的强度为来自LE扫描数据的强度的约50%的扫描)。
应该指出的是,可以跨不同的扫描来跟踪特定PCC,以基于在连续的后续扫描中LE扫描数据中该PCC的匹配m/z来确定其相关洗脱峰,如本文其他地方所述。此外,与检测峰的每个扫描的EE扫描数据中的该PCC相关的强度应遵循根据变化的CE的扫描之间的预期相对强度模式。例如,随着CE从扫描N增加到N+1,预期PCC或前体离子经历的碎片化也从扫描N增加到N+1。因此,从扫描N到N+1,EE扫描中PCC的强度降低,这是因为EE扫描数据中表示的与PCC碎片化所产生的碎片离子相关的强度增大。换句话说,如果扫描N中的CE<扫描N+1中的CE,则EE扫描数据中扫描N的PCC的强度>EE扫描数据中扫描N+1的PCC的强度(因为由扫描N中的PCC碎片化产生的碎片离子的强度<由扫描N+1中的PCC碎片化产生的碎片离子的强度)。
以类似的方式,对于PCC的检测峰中的扫描,预期EE扫描数据中扫描之间的PCC的强度遵循扫描之间的相对强度模式,其根据随着CE从顶点处的CE最大值减小到CE最小值而使CE变化。例如,随着CE从扫描N减小到N+1,预期PCC或前体离子经历的碎片化也从扫描N减小到N+1。因此,从扫描N到N+1,EE扫描中PCC的强度增大,这是因为EE扫描数据中表示的与PCC碎片化所产生的碎片离子相关的强度减小。换句话说,如果扫描N中的CE>扫描N+1中的CE,则EE扫描数据中扫描N的PCC的强度<EE扫描数据中扫描N+1的PCC的强度。前述预期的扫描之间的相对强度模式可以与PCC的匹配m/z结合使用,以确定PCC的峰并在扫描之间跟踪PCC。
在50% PCC产率规则适用的PCC的洗脱峰的扫描中,可以在跟踪的洗脱峰的每次扫描中为PCC确定AR2比率,并且采用与本文其他地方所述类似的方式将其进行比较,作为进一步验证标准(除了在峰的扫描之间的匹配m/z和预期相对强度模式之外),以确保洗脱峰是针对该特定的PCC(在峰的扫描之间具有匹配的m/z和预期的相对强度模式)。在这种情况下确定的AR2比率类似于本文其他地方所述的AR2比率,诸如结合用于AR2的公式所述的,不同之处在于该AR2比率不是基于LE扫描数据中该PCC的强度而使用在洗脱峰顶点或PP扫描中该PCC的强度,而是使用如在EE扫描数据中50% PCC产率规则适用的扫描M的PCC的强度。应该指出的是,在任何两个相邻的扫描之间改变碰撞能量将影响碎片化模式。因此,扫描之间的AR2比率(其不同于之前描述AR2比率)在离子类型之间将不一致,但在相同的碰撞能量下采集的扫描之间将可重现。对于具有相同或相似碰撞能量的扫描或点,可以在色谱洗脱中对碎片化模式的相似性进行比较。使用该特定版本的AR2比率可以执行的操作是,跟踪残余的未碎片化PCC或前体离子的强度,因为它随着CE变化而出现在EE扫描数据中的不同扫描中,诸如PCC的洗脱峰的不同扫描中。
参见图16,示出了例子1500,它以图形化方式示出了PCC的洗脱峰1512,如可以基于不同扫描的LE扫描数据中该PCC强度来确定的。在该例子1500中,PCC的单个洗脱峰1512中有3个CE周期1510。因此,在单个洗脱峰1512期间,CE改变或循环经历CE的周期3次。为了在下面的段落中进行说明和描述,3个CE周期的1510的峰或曲线叠加在该图上,具有单个洗脱峰。
作为第一步,可以确定洗脱峰中50% PCC产率规则适用的一个或多个扫描。在这个例子中,点X1、X2和X3可以表示对于具有峰1512的已跟踪PCC,50% PCC产率规则适用的这些点或扫描。如上所述,点X1、X2和X3中的每一个表示这样的扫描,其中EE扫描数据中该PCC的强度大约是同一扫描的LE扫描数据中该PCC的强度的50%(例如,在同样由点X1、X2和X3中的每一个表示的特定CE下,PCC的碎片化效率大约为50%)。
作为第二步,可以确定包括点X1、X2和X3中的每一个的单个CE周期的相关CE峰或曲线。现在将要描述的是可以相对于单个CE峰或曲线执行的处理,以及在CE峰中但是可以相对于表示单个CE周期的每个这样的CE峰或曲线重复的扫描。例如,点X1表示与在例子1500中由点A、B和C形成的曲线所示的第一CE周期1510a相关的扫描中包括的扫描。使用点X1(表示EE扫描数据中PCC的强度大约为LE扫描数据中PCC强度的50%的扫描)作为H扫描(例如,顶点或PP扫描),可将一系列AR2比率进行比较,并将其用作CE周期内和之间的验证标准,如现在将描述的。换句话讲,如本文其他地方所述,诸如对于非监督聚类和监督聚类的情况,使用AR1和AR2值来确定使用PCC的洗脱峰(例如1512)的顶点作为H扫描,将哪些产物离子与PCC对齐。不同于将PCC洗脱峰的顶点作为计算AR1和AR2值时的PP,扫描X1可以用作PP,其中点H1和H2(分别表示上坡和下坡上的FWHM点)是相对于现在用作PP的扫描X来确定的。鉴于碎片化是碰撞能量的函数,并且在所述的实施例中,碰撞能量在扫描之间发生变化,因此可以在同一CE循环中出现的具有相似(或者在指定容差内大致相同)碰撞能量的扫描之间以及在具有相同CE的扫描之间(并且这样的扫描处于不同的碰撞能量循环中)进行AR1和AR2的比较,其中(例如,同样地,在根据本文技术的一个实施例中,每个中值色谱峰宽度(FWHM)最少需要两个循环)。
例如,典型的小分子具有3秒宽的色谱峰宽(FWHM),采集速度为100毫秒,即3000毫秒/100毫秒或30次扫描。需要至少两个碰撞能量循环将允许10个不同的碰撞能量,应用5个不同的碰撞能量将允许6个碰撞能量循环。碰撞能量循环的个数由采集速度中值色谱峰宽(FWHM)决定。
因此,可以为碰撞能量循环内的每个扫描点确定AR1和AR2比率,其中:
AR1 = Int (F1…Fn) / Int (S1, PCC)
其中
n等于扫描S1的EE扫描数据中碎片离子的数量;
Int (F1…Fn)表示扫描S1的EE扫描数据中的任何一个“n”碎片离子的强度;并且
Int (扫描S1, PCC)是扫描S1的LE扫描数据中F1至Fn起源的PCC或前体离子的强度(例如,可以基于n个碎片即F1至Fn中的每一个与其母体前体离子或PCC的比率,为这些碎片确定不同的AR1值);并且
AR2 = Int (扫描S1, PCC)/Int (扫描M, PCC) PCC的AR2的V3公式,其中
Int (扫描M, PCC)是PCC的CE周期的扫描M的EE扫描数据中该PCC或前体离子的强度,其中50% PCC产率规则适用于该PCC的强度;并且
Int (扫描S1, PCC)是某个扫描S1的EE扫描数据中该PCC或前体离子的强度,扫描S1表示除扫描M之外的PCC的CE周期的另一次扫描。
类似地,我们可以根据V3公式确定碎片离子的AR2值:
AR2 = Int (扫描S1, F1)/Int (扫描M, F1)碎片离子的AR2的V3公式
其中
Int (扫描M, F1)是PCC的CE周期的扫描M的EE扫描数据中碎片离子F1的强度,其中50% PCC产率规则适用于该PCC的强度;并且
Int (扫描S1, F1)是某个扫描S1的EE扫描数据中F1的强度,扫描S1表示除扫描M之外的该碎片离子F1的CE周期的另一次扫描。
另外,AR2可以基于上述公式来定义,但是相对于在两个不同CE循环中的对应点处的两个扫描(例如,在这两个扫描中应用相同CE1,诸如在两个不同CE循环1510a和1510b中的L2和L11,并且在CE循环1510a、1510b和1510c中分别在扫描L3、L7和L9中应用相同的CE2),其中
Int (扫描M, PCC)是PCC的CE周期的任何扫描M的EE扫描数据中PCC或前体离子的强度;并且
Int (扫描S1, PCC)是在每个后续碰撞能量循环中扫描M的伴随或对应位置的EE扫描数据中PCC或前体离子的强度(例如,S1和M是在应用相同CE的后续CE循环中对应点处的对应扫描);并且
Int (扫描M, F1)是CE周期的任何扫描M的EE扫描数据中碎片离子F1的强度;并且
Int (扫描S1, F1)是在表示每个后续CE循环中M的对应或伴随扫描的某个扫描S1的EE扫描数据中F1的强度(例如,S1和M1是在应用相同CE的不同CE循环中的对应扫描)。
为了参照图15来进一步说明,如果在S1和S2两者中使用近似相同的CE,则为碎片F1确定的AR1值预期在相同CE循环的扫描S1和S2中是相同的(例如,预期AR1对于扫描对L3和L4中的F1是相同的。预期AR1对于扫描对L2和L5中的F1是相同的)。预期F1的AR1值在三个不同CE循环的对应扫描L3、L4、L7和L9中是相同的,其中在多个CE循环中的所有L3、L4、L7和L9中使用相同的CE。预期在应用相同CE的相同CE循环的扫描L3、L4中,使用以上V3公式针对PCC或前体离子确定的AR2值是相同的。另外,预期在应用相同CE的CE循环内和跨越这些CE循环的扫描L3、L4、L7和L9中,使用V3公式的相同PCC的AR2值是相同的。
而且,在扫描L3中使用上面的V3公式针对碎片F1确定的第一AR2值预期与针对使用上面的V3公式在扫描L3中从其生成F1的PCC确定的第二AR2值相同。此外,在扫描L4、L7和L9中,也预期前述第一和第二AR2值与使用以上V3公式的来源PCC和F1的AR2值相同。更进一步地,在扫描L4、L7和L9中,也预期前述第一和第二AR2值(对于扫描L3中的PCC和F1)与针对使用以上V3公式的源自与F1相同的PCC的另一碎片F2确定的AR2值相同。
因此,可以跟踪AR1和AR2比率,并且预期它们在CE变化的CE周期的类似扫描(具有大约相同的CE)中在某个指定的容差内大致相同。如本文其他地方所述,其中相对于PCC洗脱峰的点H1和H2(如基于扫描上的LE扫描数据所跟踪的)确定和比较AR2比率,可以针对点H1和H2确定相似的AR2比率,这两个点是相对于CE周期的峰而不是PCC洗脱峰确定的FWHM点。例如,包括X1的第一CE周期1510a是在点A、B和C之间形成的第一峰或曲线。可以相对于使用扫描X1作为第一CE周期1510a的PP(诸如图16所示)来确定第一CE周期1510a的FWHM点。这些比率也可以用作验证碎片离子的对齐的度量。
例如,可以使用第一碰撞能量CE1来确定在第一CE循环1510a中的第一扫描S1处,碎片离子F1相对于其母体前体离子或PCC的第一AR1值。可以在第二CE循环1510b的对应扫描S2中确定F1相对于其母体离子或PCC的第二AR1值,其中扫描S2使用与扫描1中相同的碰撞能量CE1。预期F1的两个上述AR1值应是近似的。
一般来讲,CE循环的周期≤ PCC洗脱峰的FWHM。在根据本文技术的一个实施例中,可以基于以下间隔来计算用于确定AR2比率的H1和H2扫描点:
CE周期中的CE或扫描数/3 =间隔 间隔公式
其中
“CE周期中的CE或扫描数”是在单个CE循环或周期中的CE或EE扫描的数量。
例如,假定扫描X1是扫描5,并且在每个CE周期中有10个CE或10次EE扫描(例如,1510a、1510b和1510c中的每一个中有10个CE或扫描)。基于以上间隔公式,确定的间隔为3 1/3,可以四舍五入成整数3。在这种情况下,使用扫描5作为PP,用于计算AR2值的H1和H2点可以是PP+3扫描(例如,5+3表示扫描8作为点H2)以及PP-3扫描(例如,5-3=2表示扫描2作为点H1)。
在本文所述的一个实施例中,AR2值可以首先在两个不同CE循环的对应扫描(例如,来自不同的碰撞能量循环但都具有相同的碰撞能量的扫描)之间以及对于该CE循环的扫描H1和H2中的FWHM点如下确定:
AR2 =上坡比率U =下坡比率D 公式B1
=Int (H1,前体)/Int (H,前体) = Int (H2,前体)/Int (H,前体)
其中
Int (H,前体)是扫描M的EE扫描数据中PCC的强度,其中PCC 50%产率规则在CE峰中适用;
Int (H1,前体)是CE峰的上坡或LHS上的扫描H1的EE扫描数据中PCC的强度;并且
Int (H2,前体)是CE峰的下坡或RHS上的扫描H2的EE扫描数据中PCC的强度。应该指出的是,在同一CE循环中的两次扫描H1和H2中,CE大致相同。
如本文其他地方所述,处理然后可以检查扫描H=M (在该实例中=X1)的产物或碎片离子扫描数据,以及相对于M确定的H1和H2。这样的处理包括在具有类似碰撞能量的循环之间匹配碎片离子,以及按照m/z和强度比率来比较碰撞能量。
可以确定扫描H和H1之间的第一组匹配碎片离子,并且可以确定扫描H和H2之间的第二组匹配碎片离子。例如,如果满足以下条件,则扫描H中的碎片离子F1被确定为与扫描H1中的碎片离子F1”匹配:
F1的m/z与F1”的m/z在某个指定的容差内匹配;并且强度比率IR计算如下:
IR=扫描H1中F1”的强度/扫描H中F1的强度,其与在下一个碰撞能量循环中其伴随物的AR2在某个指定容差内匹配(例如,匹配使用V3公式针对碎片F1或其起源PCC所确定的AR2,该起源PCC是相对于对应于H和H1的下一个CE循环的扫描而确定的(其中在下一个CE循环中,对应的扫描H”具有与扫描H相同的CE,并且在下一个CE循环中,对应的扫描H1”具有与扫描H1相同的CE)。应该指出的是,前述IR是AR2值的另一种表示,并且也预期与使用V3公式针对来自PCC的碎片FU、相对于扫描H和H1所确定的AR2值相同。
以类似的方式,可以如本文其他地方所述执行处理,以确定针对每个CE循环的曲线或峰的不同扫描点的不同AR2值,其中使用50% PCC产率规则适用的扫描作为PP。另外,使用50% PCC产率规则适用的扫描作为PP,可以确定本文所述的任何其他比率,诸如AR1和AR3比率。
前述附加的AR1、AR2和/或AR3值可以用作附加的验证标准,将其连同本文所述的其他验证标准一起使用以验证洗脱PCC峰,并且还用作验证标准来筛选或验证与也如本文所述的特定PCC相关的碎片离子。
作为使用50% PCC产率规则适用的扫描M作为用于确定各种比率(诸如AR1和AR2值)的PP或H扫描的变型,一个实施例也可以使用CE循环或峰的某个扫描,其中EE扫描数据中的PCC的强度处于其最小值(相对于诸如1510a的单个CE周期中的所有扫描的所有EE扫描数据集合),由此表示该PCC的碎片化为最大程度的扫描。
作为使用50% PCC产率规则适用的扫描M作为用于确定AR2值的PP或H扫描的另一个变型,一个实施例可以更一般地使用CE循环或峰的某个扫描,其中EE扫描数据中的PCC的强度大致为50%或更小(相对于诸如1510a的单个CE周期中的所有扫描的所有EE扫描数据集合)。更一般地,一个实施例可以选择某个阈值百分比,该阈值百分比可以是大约50%或更小,从而表示选择在计算各种比率(例如,本文所述的AR1、AR2等)中用作H扫描或PP的扫描,其中EE扫描数据中该PCC的强度近似为该阈值百分比或更小(例如,不超过指定的阈值百分比,从而表示PCC的阈值程度或最小程度的碎片化)。
根据本文技术的一个实施例也可以确定具有洗脱峰1512的特定分子的理想CE。这样的理想的CE可以用于建立用于其他实验的CE,诸如用于目标数据采集以确定样品是否包含具有洗脱峰1512的特定分子。50% PCC产率规则适用的以下CE可以用作具有洗脱峰1512的特定PCC的理想CE。可以使用非监督聚类和/或监督聚类确定并存储理想CE来作为跨多个实验的平均值。类似地,可以针对理想CE来跟踪误差指示器诸如CV、标准偏差等。
前述内容可以被表征为对小分子特别有用的技术。然而,如本领域技术人员将会理解的,这样的技术不限于用于小分子,而是通常可以用于任何合适尺寸的任何分子。
参见图17,示出了汇总上述处理的流程图1600,其可以在根据本文技术的一个实施例中执行。在步骤1601中,可以使用CE循环公式来确定单个CE循环或周期中的扫描次数,诸如本文其他地方所述。另外,可以确定单个CE循环中的每个扫描的特定CE值或设置,其中对于该单个CE循环中的每个扫描,CE可以改变。可以采用任何合适的方式(本文描述了其中的一些)来确定包括在单个CE循环或周期中的特定CE。例如,一个实施例可以使用数学函数来确定单个CE周期或循环的扫描中的连续CE值。例如,这样的CE值可以形成表示循环经历多个CE周期或周期的不同CE值的波或系列峰。在步骤1602中,可以使用样品来执行实验以获得HE和LE扫描数据,其中基于CE循环和每个CE循环中的CE来改变每个连续扫描中的CE。然后可以在步骤1204中执行处理以确定LE扫描数据中的离子的PCC,并且在步骤1205中为每个PCC执行峰检测。图17的步骤1204和1205类似于结合图9所述的用于无监督聚类的步骤。
在步骤1606中,可以执行处理以根据包括AR1值、AR2值和其他标准的验证标准来确定与PCC中的每一个关联(例如匹配)的一组碎片离子。验证标准可用于筛选或完善初始碎片离子组并确定每个PCC的修正碎片离子组。步骤1606的处理类似于结合图9、10和11所述的步骤1206的处理,区别在于步骤1206中的这种处理可以相对于每个CE扫描循环(而不是PCC洗脱峰)来执行。此外,H扫描或PP扫描可以不同,并且不是使用PCC洗脱峰强度顶点作为H扫描或PP(如在步骤1206中),步骤1606可以使用在单个CE循环或周期中50% PCC产率规则适用(或更一般地说,在PCC碎片化处于其最大水平的情况下)的扫描来作为计算AR2和AR1值时的替补H扫描或PP。同样如本文所描述,50% PCC产率规则使用50%的阈值水平,并且步骤1606可以更一般地使用任何合适的阈值水平或阈值百分比来执行。随后可以执行步骤1208、1210和1212,并且这些步骤与在本文其他地方诸如结合图9所述的步骤类似。
单克隆抗体是识别体内外来入侵者诸如细菌的蛋白质。这样的单克隆抗体可以被注入到身体中,例如用于各种治疗和药用目的,诸如使身体的免疫系统瞄准特定疾病。
源或宿主可以制造或产生将识别此类外来入侵者的单克隆抗体。例如,源或宿主可以是用于产生期望的单克隆抗体的动物,诸如大鼠、牛等。可以执行处理以分离或纯化单克隆抗体,并确定纯化的抗体(PA)的指纹(例如,前体离子或PCC以及各自的相关碎片离子)。可以执行处理以验证或确保由来源或宿主产生的PA是“纯的”并且不包括除PA以外的任何其他蛋白质(例如来自源或宿主的)、组分或化合物。可以执行这样的处理来确定PA中是否存在任何宿主蛋白质。如本领域所知,FDA例如对PA具有限制和要求,因为PA是“纯的”并且已经被验证或检验为仅包括PA并且不包括任何宿主细胞蛋白质或其他污染物。
应该指出的是,任何污染物(例如宿主细胞蛋白质)的任何量或浓度可能非常小,因此所使用的技术应能够检测到如此低的浓度水平,诸如浓度在0.1%的污染物蛋白质或PA以外的其他分子。
PA可以是已知的蛋白质,可以为其确定肽、相关碎片离子和相关前体的目标库,以及碎片离子信息。在一个实施例中,模拟器或建模软件可以用于为蛋白质的特定肽预测所有的前体离子,以及为每个前体离子预测通过碎片化每个这样的前体离子而产生的相关碎片离子。前述内容是可以用来产生诸如PA的蛋白质的目标库的一种方法。更一般地说,根据本文技术的一个实施例可以使用任何合适的技术来获得用于填充用于PA的目标库的信息。根据本文的技术,一个实施例可以使用模拟器来预测并生成用作受监督聚类的目标的PA的CCPIS。
例如,如图18所示,所示的是可以包括在单个PA的库中的信息的示例性表示,其可以包括例如对于表示为肽1至肽M的数百个或更多个肽的信息。对于每个肽,该库可以识别一组前体离子和相关碎片离子。例如,对于肽1,前体离子1至N可由于前体离子化而产生。另外,该库可以针对每个这样的前体离子识别由于这种前体离子的碎片化而产生的碎片离子。例如,前体离子1在碎片化时产生一组相关碎片离子。应该指出的是,如本文所述,库中的每个前体离子可对应于单个PCC,或者可以其他方式将单个前体的信息表示为一个或多个PCC的组合集合,所述一个或多个PCC表示相同前体离子的不同电荷态。另外,库可包括前体离子和产物离子的离子信息,例如每种离子的m/z、保留时间、离子的不同强度比或面积比(例如,AR1和AR3度量的值)等等。
参考图19,示出了可在根据本文技术的一个实施例中执行的示例性工作流程。可对包括PA的样品1852进行实验1854以确定PA是否是“纯的”并且是否仅包括PA。这种处理可确定被分析的样品是否包含任何宿主细胞蛋白质污染物或其他污染物。如本文所述和本领域已知的,实验1854可包括进行蛋白质消化和LC/MS或LC/IMS/MS分析。可获得该实验的LE和HE扫描数据1855,所述数据可使用本文所述的监督聚类技术1856进一步处理,其中PA蛋白的库1857用作监督聚类目标库。例如,可使用如图14A中所述的监督聚类来执行由1856表示的这种处理,其中根据进一步的考虑数字地去除了匹配的离子。
由1856表示的这种处理可包括执行监督聚类并且生成残余或剩余的不匹配离子集合1858。如本文其他地方所述,残余或剩余的不匹配离子集合1858可包括不匹配的前体离子或PCC和不匹配的碎片离子,其被确定为与PA库1857中的信息不匹配。
此时,后续处理可使用两种替代工作流程中的一种。第一后续处理工作流程包括下面更详细描述的由1860、1862、1864和1866表示的处理。第二后续处理工作流程包括由1870、1872和1874表示的处理。
结合第一后续处理工作流程,可输入残余或剩余的不匹配离子集合1858以供非监督聚类1860处理。作为输出,非监督聚类1860可确定包括PCC或前体离子和相关联碎片离子的匹配离子集合的输出1862。对于1858中的每个PCC,非监督聚类1860可确定如包括在输出1862中的一个或多个相关联或匹配碎片离子的集合。然后可针对宿主细胞蛋白质污染物的第三方DB或库1864查询匹配的离子集合1862(例如,搜索匹配的离子集合1862以确定前体离子和相关联碎片离子的任何匹配集合是否匹配DB或库1864中前体离子和相关联碎片离子的任何匹配集合,从而识别出匹配的离子集合1862包含宿主细胞蛋白质污染物。
结合第二后续处理工作流程,宿主细胞蛋白质组1868可以如本文其他地方所述的方式输入到建模软件1870,以生成宿主细胞蛋白质污染物1874的DB或库(例如,包括诸如图18、图12等中的信息)。残余或剩余的不匹配离子集合1858可被输入以供监督聚类1872使用宿主细胞蛋白质污染物的DB或库作为目标库进行处理。以这种方式,可使用监督聚类1872以识别出是否在残余集合1858的不匹配离子与宿主细胞蛋白质污染物的DB或库之间进行了足够数量的匹配,以识别出或确认残余集合1858识别任何宿主细胞蛋白质污染物。
参见图20,示出了可在根据本文技术的一个实施例中执行的处理步骤的流程图。流程图1900总结了如上所述并结合图19的处理。在步骤1902中,可对包括PA的样品进行实验,以获得该实验的LE扫描数据和HE扫描数据。在步骤1904中,可使用实验数据并使用PA蛋白库作为目标库来执行监督聚类。与本文其他地方的描述一致,可针对目标库中的每个前体离子或PCC执行步骤1904中的监督聚类,以确定在LE扫描数据中是否存在匹配,并且对于每个这样的匹配PCC,HE扫描数据是否包括如在目标库中识别的PCC的任何碎片离子。
因此,库的PA的适当数量的前体离子或PCC和相关联碎片离子应与如在该实验的LE和HE扫描数据中包括的离子信息匹配。在步骤1906中,可进行处理以确定不匹配前体离子或PCC和不匹配碎片离子的残余或剩余集合,因为实验数据中的这些离子在步骤1904中未相对于PA库确定匹配。根据步骤1906,实施例可替代地进行到执行形成第一后续工作流程的步骤1908和1910,或者可进行到执行形成第二后续工作流程的步骤1912和1914。
作为第一替代方案,处理可从步骤1906进行到步骤1908,以对来自步骤1906的残余或剩余的不匹配离子执行非监督聚类,从而生成SSPPIS或匹配PCC和相关联碎片离子的集合。处理进行到步骤1910以搜索宿主细胞蛋白质污染物的DB或库,寻找库与PCC和相关联碎片离子的匹配集合之间的匹配(如由步骤1908处理所确定的)。在步骤1910中使用的DB或库可以是例如第三方提供的库。
作为第二替代方案,处理可从步骤1906进行到步骤1912。在步骤1912中,可进行处理以诸如使用如本文所述的建模软件生成宿主细胞蛋白质污染物的DB或库。在步骤1914中,随后可执行监督聚类以搜索SSPPIS或残余集合(在步骤1906中生成)中的DB或库(在步骤1912中生成)的匹配PCC和相关联碎片离子的集合。
参见图21,示出了可在根据本文技术的一个实施例中进行的处理的例子2101,以针对特定的纯化抗体(PA)生成目标库。PA库2117可结合本文所述的其他技术使用,例如结合验证样品中是否存在特定的蛋白质或分子。PA库2117还可结合检测和/或识别样品中的变体、异常、污染物等来使用。例如,如本文所述,PA库可与样品分析结合用于检测前体变体或修饰、二硫键合肽、抗体偶联药物(ADC)和宿主细胞蛋白质污染物中的任一者。因此,图21示出了可生成PA库以供随后作为目标库与根据本文的技术在一个实施例中执行监督聚类结合使用的一种方式。
作为处理的第一部分,PA库2117可初始填充理论数据。在一个实施例中,诸如本文其他地方提及的模拟器或模拟软件的建模软件2021可提供有PA蛋白质组2020作为输入。作为输出,建模软件2021生成PA的理论肽图。肽图可包括PA的肽和相关联离子。例如,肽图可包括前体离子或PCC,以及对于每个这样的PCC,通过PCC的碎片化生成的相关联碎片离子等。由建模软件2021产生的理论上生成的肽图可用于初始用PA的肽和碎片离子信息填充PA库2117。应该指出的是,用于填充PA库2117的肽图包括其中所有半胱氨酸均被修饰使得不存在二硫化物的PA的离子信息。目标PA库包含所有目标肽的所有理论“计算机”CPPIS。
在初始用理论肽图填充库2117之后,可在已知包括PA的样品2112上进行实验2114。如本文所述和本领域已知的,实验2114可包括进行蛋白质消化和LC/MS或LC/IMS/MS分析。在该实验中,样品准备包括进行还原和烷基化,由此样品中的所有半胱氨酸均被修饰使得不存在二硫化物(例如,仅胰蛋白酶肽)。可获得实验2114的LE和HE扫描数据2115。LE和HE扫描数据2115可使用本文所述的监督聚类技术2116进一步处理,其中PA蛋白的库2117用作监督聚类目标库。例如,可使用如图14A中所述的监督聚类来执行由2106表示的这种处理。如上所述,库2117中的信息包括其中所有半胱氨酸均被修饰使得不存在二硫化物的PA的离子信息。如果如2114中所述准备样品使得半胱氨酸被修饰并且在分析的样品中不存在二硫化物,则库2117中的所有肽(包括含有半胱氨酸的那些)应与实验数据集合2115中的对应离子信息匹配。作为输出,监督聚类2116可生成可用于更新PA库2117的匹配离子信息2122。如本文所述,监督聚类2116在2115的LE扫描数据中查找目标PA库2117的每个目标前体离子或PCC的存在。对于每个这样的匹配目标前体离子或PCC,随后从库2117中检索匹配的目标前体的相关联目标碎片离子,并与进一步处理结合使用以确定该前体的哪个目标碎片离子存在于实验数据中。因此,在监督聚类2116结束时,匹配的离子信息2112可识别在实验数据集合2115的LE扫描数据中匹配的库2117的每个目标PCC或前体离子,以及对于每个这样的匹配PCC或前体离子,产生自匹配的PCC或前体离子的碎片离子的相关联碎片离子集合。应该指出的是,作为监督聚类的结果而生成的相关联碎片离子集合识别由监督聚类2116确定的PA库2117的那些碎片离子与实验数据集合2115中的匹配的PCC或前体离子相关联。例如,库2117可包括匹配的目标PCC或前体离子的15个碎片离子。然而,监督聚类可确定这15个碎片离子中只有10个与实际实验数据集合2115中匹配的目标PCC或前体离子相关联。
因此,在完成监督聚类2116之后,匹配的离子信息2112可用于更新或重新填充PA库2117(例如,由此基于实际的实测实验数据2115用匹配的离子信息2112替换2117的理论或模拟离子信息)。例如,再次参考图14A和本文的相关描述,其中PA库2117可初始填充理论数据并且与监督聚类2116结合使用。对于实验数据集合2115中与库2117中的PCC或前体离子匹配的每个PCC或前体离子,库2117中用于PCC及其相关联碎片离子的理论离子信息可被替换为或更新为包括如从实验数据集合中获得的离子信息。另外,对于现在正在描述的处理,实施例可使用如包括在用于匹配的PCC或前体和相关联碎片离子的实验数据集合中的离子信息。
现在将描述的是可结合前体变体或修饰的识别来执行的技术。
在此描述的上下文中,“变体”可被认为是与纯化抗体或治疗剂相关联的肽的单点突变。从更广泛的意义上讲,本文的技术可以更普遍地应用并使用于“变体”,其为肽的任何修饰形式。常见的修饰包括但不限于氧化(M,W)、甲基化(K,R)、乙酰化(K,R)、标签(SILAC)、接头、与细胞毒性剂(例如,ADC)的连接剂、聚糖、磷酸盐等等。保持前体与其产物离子之间的关系,直到变体/修饰点之前,肽的碎片化模式几乎相同。变体/修饰对保留时间的物理化学属性有影响,并且如果使用IMS,则漂移时间或横截面积(CCSA2)是肽长度的函数。但有一些化学修饰是例外。例如,结合ADC,接头及其细胞毒性剂非常疏水并且对肽的保留时间具有显著影响。
如果在初始验证或筛选中存在统计学显著数目的匹配产物离子(前体离子匹配的存在不是必需的),则可准确识别肽的修饰/变体形式。如本文在下文中更详细描述的处理识别到匹配的SSPPIS中不存在前体离子并触发另外的处理,由此计算在匹配的SSPPIS中的前体离子(只有一个)和目标m/z之间的Δ m/z并且与已知变体/修饰的查找表进行比较。如果发现匹配,则生成修饰/变体的产物离子谱,并将其与前体的峰值包络内的所有SSPPIS进行比较,以验证在创建新CPPIS(变体)中的识别和包含。这种方法的成功率是修饰/变体在肽的线性氨基酸链中的位置及其碎片化模式的函数。为了清楚起见,如果Δ m/z是脱离C-端的第二个氨基酸残基的修饰或点突变(变体),并且通过碎片化(例如,碰撞解离)生成的90%的产物离子是y”离子,则从修饰/变体的y”2至y”max的所有y”离子将携带Δ m/z。因此这些产物离子在验证处理中不能匹配。另一方面,如果在碎片化期间生成了足够数目的b离子,并且统计学显著数目的它们匹配,则已识别出肽的修饰/变体形式。
如果在第一遍中基于相对于前体离子的Δ m/z没有识别出变体,则可使用反映了所有可能氨基酸互换(单点突变)的确切质量差的Δ m/z值的查找表来进一步执行处理。Δ m/z、Δ时间和Δ漂移时间(如果使用IMS)可被添加到提取的产物离子。然后在用户定义的m/z、保留时间和漂移时间的匹配容差内,对所有SSPPIS筛选这些产物离子。如果前体的Δ m/z与产物离子的Δ m/z一致,则发现匹配,并且创建变体CPPIS。当发现变体时,所识别的产物离子可提供对序列中修饰/变体的位置的了解。如上所述,直到修饰点之前,产物离子m/z值是一致的。示出Δ m/z的第一次结合的产物离子m/z值指出变体氨基酸的一般位置的算法。一旦做出初步识别,就会针对变体的所有可能位点生成产物离子,并将其与存在于匹配的SSPPIS中的其他产物离子进行比较。此时,处理可尝试识别修饰或变体的确切位置。类似于之前描述的位置限制,Na+和K+加合物显著地改变常见碎片离子类型(b, y”)中的一者或两者的m/z值。如果钠离子化或钾离子化的电荷位于C-端,则碎片化产生的y”离子将包括钠离子化或钾离子化的Δ m/z(限制它们与未修饰的肽匹配)。对于N-端也是如此,用它们的补充b离子代替y”离子。Na+和K+加合物形成发生在气相中。因此,肽的Na+和K+加合物将具有相同的保留时间和漂移时间。在这种情况下,处理搜索Na+和K+加合物,可将Δ m/z添加到前面提到的查找表中,使得这种修饰可被识别为目标肽的修饰/变体形式之一。根据本文技术的一个实施例可报告任何可能的变体,而不管是否有令人信服的产物离子数据来支持其识别。
本文技术的明显优势是不用管筛选的SSPPIS中PCC的存在。虽然通过其母体分子的存在加强了对初级肽的识别,但并不是必需的。本文所述的处理可用于识别仅在匹配统计学显著数目的产物离子(包括具有其目标CPPIS的其同位素)时预测的前体的修饰/变体形式。
作为与本文用于检测和/或识别前体变体或修饰的技术结合的处理的第一部分,可执行步骤以首先验证样品中PA的存在。参考图22,示出了可在根据本文技术的一个实施例中执行的示例性工作流程。可对包括PA的样品2102进行实验2104以确定样品2102是否确实包括PA。如本文所述和本领域已知的,实验2104可包括进行蛋白质消化和LC/MS或LC/IMS/MS分析。在该实验中,样品准备包括进行还原和烷基化,由此样品中的所有半胱氨酸均被修饰使得不存在二硫化物(例如,仅胰蛋白酶肽)。可获得实验2104的LE和HE扫描数据2105。LE和HE扫描数据2105可使用本文所述的监督聚类技术2106进一步处理,其中PA蛋白的库2107用作监督聚类目标库。例如,可使用如图14A中所述的监督聚类来执行由2106表示的这种处理。如本文所述,PA库2107可使用任何合适的技术生成,并且包括前体离子或PCC,以及对于每个这样的PCC,通过PCC的碎片化生成的相关联碎片离子(例如,PA库2107包括PA的前体和相关产物离子的CPPIS)。例如,PA库2107可被生成为包括如结合图21的处理所述的信息。库2107中的信息包括PA的离子信息。如果如2104中所述准备样品,则库2107中的所有肽应与实验数据集合2105中的对应离子信息匹配。因此,在一个实施例中,样品2102中PA的存在可通过将库2107中的所有肽与实验数据集合中的离子信息匹配作为执行监督聚类2106的结果来验证。作为替代,样品2102中PA的存在可通过将库2107中的至少指定数目的肽与实验数据集合中的离子信息匹配作为执行监督聚类2106的结果来验证。处理的前述第一部分也可称为肽图分析,其是对蛋白质的鉴别测试,包括蛋白质的化学或酶促处理,导致形成肽碎片,然后以可重现的方式分离和识别碎片。
作为在2106中执行监督聚类的结果,可获得第一信息集合2106a,其识别与实验数据集合2105中的对应离子信息匹配的库2107的那些前体离子或PCC和相关联碎片离子(例如,CPPIS)。另外,作为2106处理的结果,可获得表示不匹配离子(例如,不匹配的PCC和不匹配的碎片离子)的残余或剩余集合的第二组信息2106b。不匹配离子2106b的残余或剩余集合可包括每次扫描中与库的PCC或前体不匹配的离子集合。
因此,元素2106a表示被识别或与实验数据集合中的对应离子信息匹配的PA的那些肽(例如,元素2106a表示PA库的匹配目标(例如,与实验数据集合中的离子信息匹配的库的那些PCC或前体离子))。根据如在2106a中识别的PA库的匹配的PCC或前体目标,我们现在具有每个这种匹配的PCC或前体离子的产物离子谱(例如,CPPIS),其中产物离子谱表示源自相关联PCC或前体离子的碎片离子。另外,用于在2106a中匹配的PCC和相关联碎片离子的离子信息(诸如AR1值、AR2值等)可如同包括在实验数据集合2105中一样。
此时,可以执行处理以在不匹配离子2106b的残余或剩余集合中搜索2106a的匹配的PCC或前体离子目标的碎片离子。匹配的碎片离子的碎片离子信息可如同包括在实验数据中一样。例如,库2107可包括PCC或前体离子P1,并且指示存在与PI相关联(例如,通过PI的碎片化生成)的20个碎片离子。当执行监督聚类2106时,库的目标P1可与实验数据集合中的对应P1匹配。
另外,实验数据集合2105可以仅包括与P1相关联的5个碎片。在根据本文使用监督聚类的技术的一个实施例中,库2107可被更新以用实验数据集合的5个碎片离子和对应的碎片离子信息替代20个碎片离子。另外,用于P1的匹配离子信息2106a中的信息可以包括如实验数据集合中的5个碎片离子的碎片离子集合和相关联离子信息。
参考图22,在匹配离子集合2106a中包括多行离子信息。2106a的每一行可识别在监督聚类2106中与库2107的对应PCC或前体离子匹配的匹配PCC或前体离子。2106a的每一行可包括在实验数据集合中被识别为与包括在同一行中的匹配PCC或前体离子相关联的碎片离子的碎片离子集合。与本文的这个例子和其他例子一致,PCC或前体离子可表示为Pi,其中“i”是整数,并且产物或碎片离子可表示为Fi。例如,2106a包括具有P1的第一行,其与库2107的对应PCC或前体离子匹配。在实验数据集合2105中,已经(通过监督聚类2106)确定P1与碎片离子集合2110a相关联。2106a包括具有P2的第二行,其与库2107的对应PCC或前体离子匹配。在实验数据集合2105中,已经(通过监督聚类2106)确定P2与碎片离子集合2110b相关联。
对于匹配离子信息2106a中的碎片离子集合而言,该碎片离子集合表示已被确定为全部源自相同前体离子或PCC的相关联或相关碎片离子的集合,其中PCC或前体离子已经与库2107的对应PCC或前体离子匹配。
在例子2100中,离子2106b的残余或剩余集合可以包括作为监督聚类2106的一部分的在每次扫描中不与库2107的目标匹配的离子的行。例如,2106b包括来自扫描X的包括P3和F1-3的离子的第一行,来自扫描Y的包括P4和F8-12的离子的第二行,来自扫描Z的包括P6和F10-11的离子的第三行,以及来自扫描XX的包括P5和F5-7的离子的第四行。在根据本文技术的一个实施例中,2106b的每行可对应于由监督聚类生成的SSPPIS,但是其尚未与库2107的对应PCC或前体离子匹配。
一个实施例可进一步过滤2106a的碎片离子集合2110a-b。例如,在每个碎片离子集合2110a-b中,处理可过滤碎片离子以仅利用那些满足最小强度阈值的碎片离子。在一个实施例中,对于每个碎片离子集合2110a-b,表示最小强度的阈值可以是集合中具有最大强度的碎片离子的强度的1/3。例如,假设2110a的F4具有2110a中所有碎片离子的最大强度MX。在这种情况下,2110a的碎片离子可被过滤从而不必进一步处理2110a中不具有至少MX/3的强度的任何碎片离子。
可针对2106a的每个碎片离子集合执行类似的过滤。在该例子中,假定基于相对于每个碎片离子集合中的最大碎片离子强度确定的最小阈值强度,2110a和2110b中所有示出的碎片离子满足这种过滤标准。
可以执行处理以搜索残余集合2106b的碎片离子集合2112a-d,以确定残余集合2106b的任何碎片离子集合是否包括与2106a的碎片离子集合2110a-b中的一个匹配的阈值数目的碎片离子。通常,匹配离子信息2106a与残余集合2106b的碎片离子集合之间的这种匹配可以使用包括匹配碎片m/z(在指定容差内)、匹配碎片离子强度比的匹配标准来进行,并且确定碎片离子匹配的最小阈值数目满足匹配m/z和匹配碎片离子强度比标准。这在下文中更详细地解释。
例如,匹配离子信息2106a的第一碎片离子集合2110a被检索并且与残余2106b的每个碎片离子集合2112a-d进行比较,以确定其间是否存在满足匹配m/z和匹配碎片离子强度比标准的至少阈值数目的匹配碎片。将第一碎片离子集合2110a与碎片离子集合2112a进行比较,以确定两个集合之间的匹配碎片的数目。这种匹配可寻找在某个指定的容差内具有相同m/z的匹配碎片。在关于2110a和2112a的这个例子中,假定两个集合中的F1-F3均具有匹配的m/z值。
另外,在集合2110a和2112a之间必须满足碎片离子强度比标准。对于诸如2110a的碎片离子集合,可相对于相同碎片离子集合中的任何碎片的最大强度确定其每个碎片离子Fn的碎片离子强度比(FII)。形式上,这可以表示为:
FII Fn =强度(Fn)/ MAX碎片强度
其中
Fn表示正在确定其FII的碎片离子集合的碎片离子;并且
MAX碎片强度表示在作为Fn的相同碎片离子集合(例如,其中碎片离子集合来自2106a或2106b)中的所有碎片离子的最大碎片离子强度。
为了进一步说明,考虑碎片离子集合2110a,其中到目前为止已确定2110a的F1-F3具有用于2112a的F1-F3的匹配m/z值,由此到目前为止所得的碎片离子集合包括F1-F3,其中F3具有F1-F3的最大强度。与本文其他地方的描述一致,可以执行处理以确定2110a中F1的第一FII和2112b中F1的第二FII,然后比较上述第一FII和第二FII以确定在某个指定的容差内上述第一FII和第二FE的匹配。如果不是,则从所得的离子碎片集合中去除碎片离子F1,并且处理可以继续。上述确定和比较FII的处理可以针对所得的碎片离子集合中的每个Fi重复。
在处理中的这一时刻,假定所得的碎片离子集合包括F1-F3,其中已确定在2110a和2112a中的F1-F3已满足匹配m/z和匹配碎片离子强度比标准。现在可以执行处理以确定所得的碎片离子集合是否包括至少最小阈值数目的碎片离子。例如,在一个实施例中,碎片离子的最小阈值数目可表示为N/2,向上舍入到下一个整数值,其中N可以是集合2110a中碎片离子的数目。如果所得的碎片离子集合确实包括最小阈值数目的碎片离子,则处理可确定所有匹配标准均被满足,由此2110a和2112a被确定为根据匹配标准的匹配碎片离子集合。此外,所得的碎片离子集合识别碎片离子集合2110a中匹配来自2112a的碎片离子的部分。否则,如果所得的碎片离子集合不包括最小阈值数目的碎片离子,则处理可以确定2110a和2112a不是匹配的碎片离子集合。
继续讨论上面的例子,可以确定F1、F2和F3形成表示与2110a的碎片离子匹配的2112a的碎片离子的所得匹配碎片离子集合。应该指出的是,如果2110a和2112a之间的比较没有得到满足匹配m/z和匹配碎片离子强度比的匹配标准的匹配阈值数目的碎片离子,则处理可通过如下方式继续:比较2110a与2112b、2110a与2112c以及2110a与2112d的碎片离子以确定2212b-d中的任一个是否为2110a的匹配。对于2106a的碎片离子的每个集合也可以执行类似的处理(例如,将2110b与2112a、2112b、2112c和2112d中的每一个进行比较)。
继续讨论上面的例子,已经确定F1、F2和F3形成识别与2110a的碎片离子匹配的2112a的碎片离子的所得匹配碎片离子集合。基于这样的匹配,处理确定已存在修饰或变体。现在可以执行处理以确定原始分子(例如,原始PCC或前体)的特定修饰或变体。此时,可以执行处理以通过计算与2110a和2112a相关联的两个PCC或前体离子的m/z值之间的差异来确定前体或PCC修饰的Δ质量。关于2112a,应该指出的是,在该例子中,P3可以出现在与碎片离子集合2112a相同的扫描X中,其中LE和HE扫描数据可例如使用Bateman技术和高-低规程(在本文其他地方描述)生成。更一般地,取决于获得LE和HE扫描数据的方式,前体P3可以是在由扫描X表示的扫描中具有其相关联的碎片离子的前体离子。还应该指出的是,虽然只有单个前体离子P3被示出为不匹配并且在扫描X中也具有其碎片离子,但是不止一个前体离子可能与单次扫描X如此相关联(例如,多个前体离子可在扫描X中具有其碎片离子)。
在该例子中,Δ质量被确定为P1的第一m/z(在2110a中)与P3的第二m/z(在2112a中)之间的差的绝对值。更一般地,第一离子IX和第二离子IY之间的质量差MD可表示为:
MD = ABS (IX m/z - Iy m/z)
其中
Ix m/z表示Ix的m/z;
Iy m/z表示Iy的m/z;并且
ABS表示差的数学绝对值。
可关于两个前体离子或PCC诸如在该例子中的P1和P3(P1 = Ix并且P3 = Iy)确定MD,其表示对分子或前体的修饰的m/z差。根据本文技术的一个实施例可利用查找表或按MD的不同值索引的结构,每个值表示如表所示的不同前体修饰。例如,一个实施例可使用分子已知的修饰或变体的表,例如通过Unimod.org可获得的。
现在参考图23以进一步示出可在根据本文技术的一个实施例中使用的表2210的例子。表2210是前体Δ质量修饰表的例子,其中列2212包括可受关注的已知修饰的m/z差。通过在列2212中搜索匹配值(在指定容差内匹配),可确定用于MD的值并将其用作表2210中的索引。如果计算的MD值与列2212中的值匹配,则可检索表2210的行以获得关于对应的前体修饰的信息。元素2220可表示用于确定表2210的最后一列中的m/z差的单一同位素质量。
应该指出的是,前体修饰或变体的表2210可在根据本文技术的特定实施例中随所关注的那些修饰或变体而变化。
如果发现计算的MD值和表中的条目匹配,则确定已经存在由匹配的表条目表示的前体的修饰或变体。
可以执行处理以确定与由2210的匹配表条目表示的前体修饰或变体对应的经修饰前体的碎片的m/z值。一个实施例可使用例如模拟器来计算由表的匹配条目建议(例如,由Δ质量或MD匹配建议)的修饰的碎片质量或m/z值。
例如,再次参考图22和上面的例子,假定如上所述在2112a和2110a之间进行匹配,并且针对这样的匹配碎片离子集合计算的MD匹配表2210中的条目,则表示MD对应于前体修饰或变体。如上所述,匹配的离子信息2106a指示P1是与库2107中的对应前体或PCC匹配的PCC或前体离子。在该例子中,P1可被确定为经修饰的原始PCC或前体离子,并且P1的特定前体修饰或变体可由P3来表示(例如,P3是由2210的匹配表条目基于关于P3和P1计算的MD表示的P1的经修饰型式或变体)。
此时,模拟器或建模软件可用于确定或理论上计算由匹配表条目建议的特定前体修饰或变体的预期碎片离子和相关联碎片离子m/z值。假定模拟器确定用于如由匹配表条目或者基于计算的MD值所表示的对P1的修饰的碎片离子集合是F1 F2” F3” F4(其中模拟器针对碎片离子F1 F2” F3”和F4中的每一个确定m/z值以及可能的其他信息)。为了在下面的段落中进行说明,让F1 F2” F3”和F4形成前体修饰或变体的计算的碎片离子集合。
现在可以进行处理以验证由计算的MD值或质量差所建议的前体修饰或变体。这种处理可包括在残余集合2106b中搜索前体变体的一个或多个碎片离子。更具体地讲,这种处理可以在前体变体P3的PCC的洗脱峰的扫描中搜索前体修饰的计算的碎片离子集合的一个或多个经修饰碎片(例如,F2” F3” F4”)(例如,图7示出了PCC的洗脱峰的扫描)。
例如,再次参考图22,假定残余集合2106b还包括用于扫描YY的另一行,如下:
扫描YY P3 F1 F2” F3”
表示另一个扫描YY,其中前体离子或PCC P3出现,其具有相关联碎片F1 F2”和F3”的不同集合。用于验证前体修饰或变体的这种处理可在除了扫描X之外的另一个扫描中搜索残余集合2106b,其中由P3表示的经修饰前体离子或PCC出现。在这种情况下,P3出现在额外扫描YY中,其中扫描YY可表示P3的洗脱峰的扫描。对于出现P3的匹配扫描YY,确定是否还出现一个或多个经修饰碎片F2” F3”或F4”。如果是,则处理确认前体修饰或变体的存在,否则验证不能确认前体修饰或变体的存在。继续讨论该例子,经修饰碎片F2”和F3”两者都出现在扫描YY中,从而确认或验证P3为特定的前体修饰或变体,如上述计算的MD所表示的(例如,表中具有在2212中的值与计算的MD匹配的条目)。
根据本文的技术,实施例可以进一步利用其他验证标准来进一步验证特定修饰,例如使用如本文其他地方所述的AR1和AR2的值。例如,使用残余集合2106b中的离子信息,可在诸如本文所述的并且结合图7所示的扫描中跟踪P3,并且也可如本文所述的那样执行处理,以使用验证标准诸如AR1值和AR2值确定P3的相关或相关联的碎片离子的集合。在这种情况下,与P3相关联的碎片离子集合应包括一个或多个经修饰碎片F2”和F3”。此外,与本文其他地方的讨论一致,使用诸如AR1的验证标准,如针对F2”所确定的AR1在P3的洗脱峰的扫描中应当相同,并且如针对F3”所确定的AR1在P3的洗脱峰的扫描中应当相同。针对P3及其碎片诸如F2”和F3”确定的AR2值在P3的洗脱峰的扫描中应当相同。例如,对于P3的洗脱峰的扫描H和M,以下应该成立(在某个指定的容差内):
扫描H中P3的强度/扫描M中P3的强度=
扫描H中F2”的强度/扫描M中F2”的强度=
扫描H中F3”的强度/扫描M中F3”的强度。
以上描述了响应于确定在碎片离子集合2110a和2112a之间对于至少阈值数目的碎片离子的匹配而执行的处理。作为替代,现在考虑这样的情况,其中处理没有在2110a和2112a之间找出或确定出对于至少阈值数目的碎片离子的匹配。在这种情况下,如果2110a中的碎片离子的数目至少是最小数目诸如四(4),则可执行替代处理。这种替代处理可包括确定MD值(如本文其他地方所述),其不同之处在于该MD值表示关于2110a中的一对“相邻”碎片离子的质量或m/z差。可针对基于一对“相邻”碎片离子(例如,2110a的F1和F2)的MD值重复如上所述的关于两个前体离子或PCC的MD的这种处理。在相对于诸如与特定PCC或前体离子诸如PI相关联的碎片离子集合诸如2110a确定一对相邻碎片离子时,集合2110a中的碎片可根据碎片的增加或减小的m/z值排序。如果两个碎片离子F1和F2在按m/z排名的排序位置上彼此相邻,则在这种情况下F1和F2可为相邻的。
应该指出的是,如果如上所述针对前体确定的MD或者针对一对碎片离子确定的MD不匹配表2110的质量Δ或不同条目,则这种不匹配的MD可表示新的或额外的类型或未纳入表中的前体修饰。
参见图24,示出了可在根据本文技术的一个实施例中执行的处理步骤的流程图2300。流程图2300总结了如上所述的处理。在步骤2302中,可获得基于质量或m/z差的前体修饰或变体的表。表2210是可包括在这样的表中的信息的例子。在步骤2304,对经处理的样品进行实验,并且可获得实验数据。也可以在步骤2304中执行监督聚类,以获得匹配离子信息的集合2106a(例如,与库中的目标匹配的实验数据)以及离子信息的残余或剩余集合2106b。处理从步骤2306开始以遍历与PCC或前体离子相关联的2106a的每个碎片离子集合,所述PCC或前体离子与库2107的对应PCC或前体离子匹配。在步骤2306,可为当前碎片离子集合分配匹配离子信息2106a的下一个碎片离子集合。在步骤2308,确定是否匹配离子信息2106a的所有碎片离子集合均已被处理。如果是,则处理停止。否则,如果步骤2308评估为是,则控制进行到步骤2310,以在离子的残余集合2106b中搜索当前碎片离子集合与残余集合的同一扫描中第二碎片离子集合之间的匹配。例如,参考图22,步骤2310的处理可导致如上所述确定2110a和2112a之间的匹配。在步骤2312,确定是否在残余集合2106b和匹配离子信息2106a中找到了匹配的碎片离子集合。如果步骤2312评估为否,则控制进行到步骤2306。如果步骤2312评估为是,则控制进行到步骤2314以确定关于匹配碎片离子集合的PCC或前体离子的MD值。步骤2314例如可确定关于图22的P1和P3的MD值。在步骤2316,确定MD值的匹配条目是否位于前体或修饰变体的表中。如果步骤2316评估为是,则控制进行到步骤2320。在步骤2320,可例如使用如本文其他地方所述的模拟器来确定在步骤2316中匹配的前体变体或修饰的碎片离子集合。在步骤2322,可执行验证处理以验证或确认前体变体或修饰的存在。例如,如本文所述,这样的验证处理可使用前体修饰或变体的模拟碎片离子集合(如在步骤2320中生成的),并且还使用残余集合2106b来确认P3是前体修饰还是变体。参考图22和上面的例子,这样的验证处理可在残余集合2106b中搜索经修饰碎片(诸如F2”或F3”)的存在。这样的验证处理可使用例如离子P3和相关碎片离子F1、F2”和F3”的AR1值和AR2值。处理从步骤2322起进行到步骤2306。
如果步骤2316评估为否,则可执行替代处理。如本文所述,这种处理可包括针对2106a中的匹配前体离子或PCC P1确定关于包括在2110a中的相邻碎片离子的MD值。
可使用本文的技术识别并验证二硫键合肽。在讨论这样的技术之前,首先参考图25,其示出了如可以在根据本文技术的一个实施例中使用的蛋白质的例子。该蛋白质可包括各种氨基酸,诸如半胱氨酸(由Cs表示)、赖氨酸(由Ks表示)和精氨酸(由Rs表示)。二硫键连接在半胱氨酸上,如元素2002所示。作为实验的样品准备和处理的一部分,可使样品中的蛋白质经受各种酶消化(例如,胰蛋白酶)和其他可能导致肽切割的处理。典型的肽切割位点可包括例如精氨酸位点和赖氨酸位点。
例如,在蛋白质组学分析过程中,凝胶内消化可作为样品准备的一部分进行蛋白质的质谱鉴定。凝胶内消化可包括例如蛋白质中半胱氨酸的脱色、还原和烷基化(R和A)、蛋白质的蛋白酶切割和所生成的肽的提取。蛋白质中可能包含的胱氨酸或半胱氨酸的还原和烷基化(R和A),如通常可作为样品准备处理的一部分进行的,导致蛋白质的二硫键(例如,如2002所示)不可逆地被破坏,并且可获得蛋白质的三级结构充分展开为线性氨基酸链。进行这样的样品准备可例如结合本文所述的各种工作流程(例如结合图21)来进行。
根据本文技术的一个实施例可进行如本文所述的处理作为PA蛋白质结构验证的一部分,以识别其中半胱氨酸不参与二硫键的含半胱氨酸的肽。结合如下文更详细描述的这种处理,可例如使用凝胶内消化来准备被分析的样品,由此样品准备省略了还原和烷基化(R和A)。以这种方式,样品中的任何半胱氨酸或半胱氨酸保持完整,以供使用本文所述的技术进行后续检测。例如,使用如结合图21所述生成的目标PA库的监督聚类技术可用于找到具有半胱氨酸(其可用作二硫键锚点)的所有肽,其中这样的半胱氨酸也不参与二硫键。
根据本文技术的一个实施例可执行处理以识别样品中的任何二硫键合肽。如下面更详细描述的,目标肽中半胱氨酸残基的存在可导致执行这样的处理。二硫键定位可使用如本文所述的监督聚类并使用包括所有含半胱氨酸的肽的线性序列的目标库或数据库(如结合图21所述)进行。本文所述的用于二硫键合肽检测和/或验证的处理可包括查询目标库或数据库并提取所有含半胱氨酸的肽的CPPIS。每个含半胱氨酸的CPPIS的产物离子谱可以与其他肽类似的方式针对生成的所有SSPPIS产物离子谱进行筛选。如果确定了跨越可接受的色谱峰宽的适当数量的SSPPIS,则创建CPPIS。正确识别的SSPPIS从时间或扫描数上反映了洗脱肽与其匹配的产物离子及其强度/区域,示出了在整个跨度上合适的强度分布(增加/减少)。如果没有找到匹配,则处理移至下一个含半胱氨酸的CPPIS,并重复该过程。如果有统计学显著数目的产物离子(例如,指定的阈值数目)匹配,则算法接下来使用任何用户定义数目的可能的二硫键合肽之间的Δ m/z值的矩阵或表执行处理。接下来,计算匹配的肽和前体离子的m/z之间的Am/z并与矩阵的Am/z值比较。如果发现匹配,则处理随后继续比较伴侣肽的产物离子以用于验证和键定位。如果统计学显著数目的产物离子与两种肽匹配,并且它们的AR1比和AR2比在所有匹配的SSPPIS中重复,则可形成二硫键合的CPPIS。
根据本文技术的一个实施例可使用二硫键合肽的附加验证标准。结合在二硫键中的每个线性序列将在保留时间处存在,并且如果使用IMS,漂移时间与其实验值不一致。在实验中,治疗剂被还原和烷基化,确保没有形成半胱氨酸键。一致的产物离子的集合在时间上的移动显著地将识别限制为随机事件。在以下段落中更详细地描述了可在根据用于二硫键合肽识别和/或验证的技术的实施例中执行的处理。
作为与本文用于检测和/或识别二硫键合肽的技术结合的处理的第一部分,可执行步骤以首先验证样品中PA的存在。
参考图26,示出了可在根据本文技术的一个实施例中执行的示例性工作流程。由2420示出的第一部分可包括执行与本文中结合图21在别处描述的步骤类似的步骤。实验2404a可为关于PA样品2402执行的第一个这样的实验。实验2404a可包括为蛋白质消化和LC/MS或LC/IMS/MS分析进行的样品准备处理。在第一实验2404a中,样品准备包括进行还原和烷基化,由此样品中的所有半胱氨酸被修饰,使得不存在二硫化物(例如,仅胰蛋白酶肽)。可获得实验2404a的LE和HE扫描数据2405a。LE和HE扫描数据2405a可使用本文所述的监督聚类技术2406进一步处理,其中PA蛋白的库2407用作监督聚类目标库。
如果如2404a中所述制备样品,则PA库2407中的所有肽应与实验数据集合2405a中的相应离子信息匹配。因此,在一个实施例中,样品2402中PA的存在可通过将库2107中的所有肽与实验数据集合中的离子信息匹配作为执行监督聚类2406的结果来验证。作为替代,样品2402中PA的存在可通过将库2407中的至少指定数目的肽与实验数据集合2405a中的离子信息匹配作为执行监督聚类2406的结果来验证。处理的前述第一部分也可称为肽图分析,其是对蛋白质的鉴别测试,包括蛋白质的化学或酶促处理,导致形成肽碎片,然后以可重现的方式分离和识别碎片。
在执行由2420表示的前述操作之后,可以在第二实验2404b中对同一PA样品2402的另一部分进行处理。包括样品准备的实验2404b可以与实验2404a相同,不同之处在于实验2404b包括样品准备并且省略了进行还原和烷基化。以这种方式,样品处理省略了还原和烷基化步骤,从而在通过2404b分析样品的过程中不会破坏存在的任何二硫键。因此,如果样品中存在二硫键,则这样的二硫键保持完整并且在样品处理中不被破坏。
可获得第二实验2404b的LE和HE扫描数据2405b。LE和HE扫描数据2405b可使用本文所述的监督聚类技术2409(例如,在图14A中)进一步处理,其中PA蛋白的库2407用作监督聚类目标库。应该指出的是,作为执行2420的工作流程的结果,可生成PA库2407。
作为在2409中执行监督聚类的结果,可获得第一信息集合2406a,其识别与实验数据集合2405b中的对应离子信息不匹配的库2107的那些肽或前体离子(或PCC)和相关联碎片离子(例如,CPPIS),并且其中这样的肽或前体也含有半胱氨酸。另外,作为2409处理的结果,可获得表示实验数据集合2405b的不匹配离子(例如,不匹配的PCC和不匹配的碎片离子)的残余或剩余集合的第二组信息2406b。不匹配离子2406b的残余或剩余集合可包括实验数据集合B 2405b的每次扫描中与库的肽(例如,PCC或前体)不匹配的离子集合。
因此,元素2406a表示未被识别或不与实验数据集合2405b中的对应离子信息匹配并且还包含形成二硫键所需的半胱氨酸氨基酸的PA的那些肽或前体(例如,元素2406a表示PA库的不匹配目标(例如,包含半胱氨酸并且与实验数据集合B 2405b中的离子信息也不匹配的库2407的那些PCC、肽或前体离子))。根据如在2406a中识别的PA库的不匹配的含半胱氨酸的肽或前体目标,我们现在具有每个这样不匹配的含半胱氨酸的肽或前体离子的产物离子谱(例如,CPPIS),其中产物离子谱表示预计源自相关联肽或前体离子碎片化的碎片离子。在该例子中,2406a表示库2407包括未通过监督聚类2409与实验数据集合B 2405b中的对应前体和碎片离子信息匹配的前体或肽P1和P2。另外,2406a指示库还包括用于库的目标前体P1的目标碎片离子集合2410a,并且库还包括用于库的目标前体P2的目标碎片离子集合2410a。
根据本文的技术,可执行处理以识别与2405b相比在2405a中各自具有不同保留时间的2406a的那些前体或肽。例如,可执行处理以跟踪在如本文所述的不同扫描中的前体或肽的PCC,以确定在不同扫描(例如在图7中所示)中的洗脱峰或轮廓,由此可将其中所跟踪前体具有最大强度的顶点或扫描确定为其近似的保留时间。如果在第二实验中前体不是二硫键合肽,则预计两个相同的所跟踪前体或肽在2405a和2405b中将具有相同的保留时间。因此,如果前体P1包含在二硫键合肽中,则预计P1在2405a和2405b中具有不同的保留时间。类似地,如果前体P2包含在二硫键合肽中,则预计P2在2405a和2405b中具有不同的保留时间。应该指出的是,如果在实验2404a、2404b中使用IMS,则如果在第二实验2404b中前体诸如P1或P2包含在二硫键合肽中,那么预计该前体在2405a和2405b中也具有不同的漂移时间或不同的碰撞横截面积(CCSA2)。
对于这个例子,假定P1和P2都是库2407的不匹配的含半胱氨酸的目标肽或前体,其在2405a和2405b中均具有这样的不同保留时间和漂移时间。可执行处理以搜索残余集合2406b,从而确定在残余集合中,与P1和P2的组合相关联的阈值数目的碎片离子是否出现在同一扫描中。例如,可执行处理以形成碎片离子集合2410a和2410b的集合并集,其在该例子中是组合碎片离子集合(CFIS)= {F1, F2 F3 F4 F5},然后搜索残余集合2406b以得到在同一扫描中与CFIS的至少阈值数目的碎片的匹配。为了在该例子中进行说明,可确定扫描T包括基于2410a和2410b的CFIS的所有碎片离子,从而表示在残余集合2406b中,在同一扫描T中出现的含半胱氨酸的两种肽P1和P2。
可执行处理以确定新分子的理论质量Mnew,包括P1和P2之间的二硫键,其可以如下表示:
Mnew = M1 + M2 -(c *氢的质量)
其中
M1是P1的质量(例如,可以是P1的单一同位素质量);
M2是P2的质量(例如,可以是P2的单一同位素质量);
c是大于0的整数,表示P1和P2之间的半胱氨酸键或锚点的数目;并且
氢的质量表示氢的原子质量,其为大约1.007原子质量单位或amu。
模拟器或建模软件2021可用于确定Mnew的理论上可能的m/z。例如,Mnew可具有模拟器可确定的多个电荷态,诸如+3、+5和+7。然后,模拟器可确定在实验数据集合诸如2405b中可出现Mnew的这样的多个电荷态的理论m/z值。每个这样的m/z值因此对应于Mnew的PCC的m/z。
现在可通过在2405b的LE扫描数据中搜索与Mnew的m/z值(如由模拟器确定的)中的一个匹配的m/z来继续处理。例如,假定模拟器确定与2405b的LE扫描数据中的对应m/z值匹配的Mnew的第一m/z值。假定第一m/z值表示Mnew的PCC +3的m/z。搜索2405b的LE扫描数据,以确定包括Mnew的PCC +3的m/z的所有扫描。如果Mnew的PCC +3的第一m/z值出现在2405b的LE扫描数据的任何扫描中,则可确认二硫键合肽Mnew的存在或验证。
现在可执行处理以确定与Mnew相关联或源自Mnew的2405b的碎片离子。模拟器可用于计算分子Mnew的所有理论碎片离子,所述分子Mnew为二硫键合肽对P1和P2的分子。分子Mnew的这种理论碎片离子可被包括在用作关于实验数据集合B 2405b执行的监督聚类的目标库的新库L1中。与本文其他地方的描述一致,这样的监督聚类导致生成Mnew的CPPIS、包括P1和P2的二硫键合分子或肽Mnew。
应该指出的是,上述例子示出了分子Mnew的检测和识别,所述分子Mnew是包含二硫键合对P1和P2的肽,其中P1和P2表示目标库2407的目标肽或前体离子,其通过监督聚类2409与实验数据集合B 2405b中的对应前体和碎片离子信息不匹配。因此,P1和P2可表示可作为二硫键合肽对包括的肽或前体候选物。作为二硫键合肽对的候选物的肽或前体还可包括库2407的“匹配的”目标肽或前体(例如,2407中通过监督聚类与实验数据集合B 2405b中对应的前体和碎片离子信息匹配的肽或前体),其中这种匹配的目标肽或前体却在符合在二硫键合对中包含此类匹配的目标肽时表现出其他异常或非预期的行为。例如,假定P3表示库2407的匹配的目标前体或肽。P3可表现出在2405a和2405b中不同的强度行为。回想一下,实验2404a和2404b可被认为是重复实验,不同的是如上所述的样品处理中的差异(其中2404a包括用于破坏2402中的任何二硫键合对的样品处理,而2404b省略了这种样品处理从而保留了2402中存在的任何二硫键合对)。因此,相同的肽、前体或PCC应在2405a和2405b两者中均表现出类似的行为。例如,如果P3不参与二硫键合对,则预计P3在两个实验中在大致相同的扫描和大致相同的漂移时间下具有其最大强度。在两个实验中,P3在相同的扫描中也应表现出类似的强度。例如,对于2405a和2405b中的相同扫描S1,P3在两个实验中应具有大致相同的强度(在某个容差内)。类似地,在两个实验中,源自P3的碎片离子在相同的扫描中也应具有类似的强度。此外,P3及其碎片的AR2值在2405a和2405b中应一致。例如,可相对于实验数据集合A 2405a的LE扫描数据的两个扫描S1和S2中P3的强度计算P3的第一AR2值,并且可相对于实验数据集合B 2405b的LE扫描数据的相同的两个扫描S1和S2中P3的强度计算P3的第二AR2值,由此如果在具有数据集合B 2405b的第二实验中P3不包含在二硫键中,则预计第一AR2值和第二AR2值大致相同。以类似的方式,如果在具有数据集合B 2405b的第二实验中P3不包含在二硫键中,则预计P3的碎片离子的AR2值也大致相同。因此,可使用这种强度和/或强度比的比较来检测匹配的目标肽或前体P3的不一致或异常行为,从而表明P3也是将与2406a的不匹配的目标肽或前体一起考虑的候选肽或前体。
参见图27,示出了可在根据本文技术的一个实施例中执行的处理的流程图,以检测样品中二硫键合对的存在。流程图2500总结了如上所述的处理。
在步骤2502中,可使用包括进行还原和烷基化从而破坏存在的任何二硫键的准备处理并利用包括PA的样品来进行第一实验。可获得针对第一实验的第一实验数据集合A,并且可执行监督聚类。在监督聚类中使用的PA的目标库可例如使用本文其他地方提及的模拟器或建模软件,初始填充理论碎片离子信息。这样的监督聚类可导致验证包括PA的样品并且还导致用来自数据集合A的实测实验数据来更新目标库。
在步骤2504中,可使用相同的样品进行第二实验,并进行与步骤2502中相同的实验,不同之处在于省略了进行还原和烷基化从而使任何现有的二硫键保持完整的准备处理。可获得针对第二实验的第二实验数据集合B,并且可执行监督聚类。监督聚类中使用的目标库可以是在步骤2502中监督聚类更新的PA的更新目标库。作为步骤2504中的监督聚类的结果,目标PA库的不匹配的目标前体或肽的集合2406a可连同包括不与监督聚类中的目标PA库匹配的离子的扫描的残余或剩余集合2406b一起确定。
在步骤2506中,可确定满足指定标准的一对候选肽或前体P1和P2。如上所述,这样的标准可包括确定每个候选物包含至少一个半胱氨酸,确定在第二实验数据集合B的残余集合中该对的阈值数目的碎片离子出现在单次扫描中,确定每个候选物在实验数据集合A和B中具有不同的保留时间(并且如果执行IMS,则具有不同的漂移时间)(例如,在实验数据集合A和B的不同扫描中的相关联最大强度),每个候选者或者处于不匹配的目标前体或肽集合2406a中,或者以其他方式与库的目标前体匹配并且还表现出异常或不一致的行为。前体或肽候选物的这种不一致行为与候选物不包含在样品的二硫键中不一致。
在步骤2508中,可计算包括P1和P2作为二硫键合对的分子的Mnew。在步骤2510中,可使用模拟器或建模软件来确定可存在Mnew的PCC的各种电荷态。对于具有不同电荷态的每个这样的PCC,可确定对应的m/z值。在步骤2512中,可以搜索第二实验数据集合B的LE扫描数据,以定位LE扫描数据中与Mnew的一个PCC的m/z值匹配的m/z。在步骤2514中,确定在第二实验数据集合B的LE扫描数据中是否已定位到这样的匹配m/z。如果步骤2514评估为否,则控制进行到步骤2516,在该步骤中确定,P1和P2没有在第一和第二实验所分析的样品的分子或肽中形成二硫键合对。如果步骤2514评估为是,则控制进行到步骤2518,在该步骤中确定,P1和P2在第一和第二实验所分析的样品的分子或肽Mnew中确实形成了二硫键合对。控制进行到步骤2520以例如使用模拟器或建模软件计算Mnew的理论碎片离子集合,并且用这样的信息初始填充Mnew的目标库。Mnew目标库可用作关于第二实验数据集合B执行的监督聚类中的目标库以确定Mnew的CPPIS。因此,可以用这样的CPPIS信息更新Mnew目标库。
应该指出的是,在流程图2500中示出了关于单对候选肽或前体的从步骤2506开始的步骤。可对每个这样的候选物对重复这种处理。
根据本文技术的一个实施例还可执行处理以检测并识别样品是否包含任何抗体偶联药物(ADC)。这种技术可包括执行与本文所述用于所识别的二硫键合对的处理类似的处理。如本领域已知的,ADC可以被表征为一类被设计用于治疗癌症患者的靶向疗法的高效的生物药物。ADC是复杂的分子,包括通过具有不稳定键的稳定化学接头连接到生物活性细胞毒性(抗癌)有效负载或药物(在本文中也被称为细胞毒性剂或偶联物)的抗体。因此,细胞毒性剂或偶联物可在抗体的肽的特定氨基酸(例如,半胱氨酸或其他氨基酸)处连接至抗体。
在开发ADC时,抗癌药物(例如,细胞毒素)偶联于特异性靶向某种肿瘤标志物(例如,理想地仅在肿瘤细胞中或上发现的蛋白质)的抗体。抗体在体内跟踪这些蛋白质并将其自身连接至癌细胞的表面。抗体与靶蛋白(抗原)之间的生物化学反应在肿瘤细胞中触发信号,然后将抗体与细胞毒性剂一起吸收或内化。在ADC被内化后,细胞毒性剂被释放并杀死癌细胞。由于这种靶向作用,理想的是该药物具有较低的副作用并且比其他化学治疗剂具有更宽的治疗窗口。
参见图28,示出了可在根据本文技术的一个实施例中执行的处理的流程图2600,以检测样品中ADC的存在。对于在2600中执行处理以确定ADC是否存在于样品中的特定ADC,可以提供输入,包括识别细胞毒性剂连接至抗体的点的目标氨基酸、接头的质量以及细胞毒性剂或偶联物的质量。结合诸如后续步骤中所述的处理,偶联物或细胞毒性剂可连接至半胱氨酸氨基酸。然而,更一般地,偶联物或细胞毒性剂可连接至抗体的肽的任何氨基酸。
应该指出的是,步骤2602、2604、2606、2608、2610、2612、2614、2616、2618和2620分别类似于图27的步骤2502、2504、2506、2508、2510、2512、2514、2516、2518和2520。
在步骤2602中,可用包括PA的样品来进行第一实验。例如,可通过进行本领域已知的蛋白质消化技术来处理样品。例如,这样的样品准备过程可包括进行还原和烷基化。然后可通过进行包括色谱分离、质谱、IMS等的实验来分析所准备的样品。可获得针对第一实验的第一实验数据集合A,并且可执行监督聚类。在监督聚类中使用的PA的目标库可例如使用本文其他地方提及的模拟器或建模软件,初始填充理论碎片离子信息。这样的监督聚类可导致验证包括PA的样品并且还导致用来自数据集合A的实测实验数据来更新目标库。
在步骤2604中,可使用相同的样品进行第二实验,并进行与步骤2602中相同的实验和相同的样品处理。可获得针对第二实验的第二实验数据集合B,并且可执行监督聚类。监督聚类中使用的目标库可以是在步骤2602中监督聚类更新的PA的更新目标库。作为步骤2604中的监督聚类的结果,目标PA库的不匹配的目标前体或肽的集合(例如,2406a)可连同包括不与监督聚类中的目标PA库匹配的离子的扫描的残余或剩余集合(例如,2406b)一起确定。
在步骤2606中,可确定满足指定标准的候选肽或前体P1。应该指出的是,步骤2506确定一对候选物,而步骤2606确定单个候选物。对于ADC,这样的标准可包括确定候选物包含细胞毒性剂所连接至的至少一个半胱氨酸或其他目标氨基酸。这是作为被检测或识别的特定ADC的输入而提供的目标氨基酸。这样的标准可包括确定在第二实验数据集合B的残余集合中候选物P1的阈值数目的碎片离子(其中在PA的目标库中指定这样的碎片离子)出现在单次扫描中。这样的标准可包括确定候选物P1在实验数据集合A和B中具有不同的保留时间(并且如果执行IMS,则具有不同的漂移时间)(例如,在实验数据集合A和B的不同扫描中的相关联最大强度)。这样的标准可包括确定候选物P1或者处于不匹配的目标前体或肽集合2406a中,或者以其他方式与库的目标前体匹配并且还表现出异常或不一致的行为。前体或肽候选物的这种不一致行为与候选物不包含在样品的ADC中不一致。这种不一致结合二硫键检测和识别进行了描述,并且也可结合本文所述的处理用于确定候选物P1,该候选物可以是表现出异常或不一致行为(例如,关于第一实验和第二实验之间的差异)的库的匹配的目标前体或肽。
在步骤2608中,可计算Mx,其表示包括P1、指定的接头和指定的细胞毒性剂或偶联物的ADC的质量。Mx可计算为上述各项的质量的总和。
在步骤2610中,可使用模拟器或建模软件来确定可存在Mx、ADC的PCC的各种电荷态。对于具有不同电荷态的每个这样的PCC,可确定对应的m/z值。在步骤2612中,可搜索第二实验数据集合B的LE扫描数据,以定位LE扫描数据中与Mx的一个PCC的m/z值匹配的m/z。在步骤2614中,确定在第二实验数据集合B的LE扫描数据中是否已定位到这样的匹配m/z。如果步骤2614评估为否,则控制进行到步骤2516,在该步骤中确定,P1不包括在第一和第二实验所分析的样品的ADC中。
如果步骤2614评估为是,则控制进行到步骤2618,其中确定P1包括在ADC中,并且ADC包括在第一和第二实验所分析的样品中。控制进行到步骤2620以(例如,使用模拟器或建模软件)计算具有相关联质量Mx的ADC的理论碎片离子集合。ADC的理论碎片离子集合可用于初始填充ADC的目标库。ADC目标库可用作关于第二实验数据集合B执行的监督聚类中的目标库以确定ADC的CPPIS。因此,可以用这样的CPPIS信息更新ADC目标库。
应该指出的是,在流程图2600中示出了关于单个肽或前体候选物P1的从步骤2606开始的步骤。可对其他候选物重复这种处理。
现在将描述的是本文称为多模式采集(MMA)的技术。在一个方面,MMA可被表征为包括DDA和Bateman技术的组合或本文其他地方所述的高-低规程数据采集技术。MMA可包括结合用于一个或多个分离的附加维度的处理来进行质谱分析。例如,MMA可包括LC/MS分析,并且还可包括执行IMS。如在以下段落中更详细描述的,MMA提供可变尺寸的质量隔离窗口(MIW)的顺序隔离,由此在整个洗脱时间内调节MIW的宽度(例如,执行质量过滤或选择的MS的四极杆)。在一个实施例中,洗脱时间范围可被分成相等的部分,在本文中被称为时段或区段。在宽度是特定时段或区段中前体离子的数目的函数的情况下,MIW的宽度可以变化。换句话说,根据本文所述的MMA技术的实施例可例如改变整个时间内的MIW宽度,以便保持进入第一过滤四极杆的前体离子的数目,这样随后才能碎片化成几乎一样。前述的目标是,在单个循环内,使利用每个不同的顺序MIW碎片化的前体离子具有大约相同的数目。
使用MMA时,可以指定从最小m/z值到最大m/z值的m/z值的总范围。m/z值的总范围可被分成多个m/z间隔。每个m/z间隔在m/z值的总范围内具有上限和下限。在诸如以下段落中所述的一些实施例中,m/z间隔可在m/z范围上有重叠。结合MMA技术针对每个不同的m/z间隔执行的处理在本文中可被称为不同的循环。例如,可将值的总m/z范围分成“n”个m/z间隔,由此结合MMA针对m/z间隔“i”执行的处理,1 ≤ i ≤ n可被称为循环i。
所考虑的m/z值的总范围的特定最小m/z值和最大m/z值可随着一个或多个因素而变化,所述因素例如特定样品(例如,样品是小分子、单个蛋白质或抗体,还是多种未知蛋白质的复杂混合物)、执行的特定样品处理(例如,使用什么特定的酶)等。例如,发明人已经对样品的典型胰蛋白酶分析的实验进行了模拟,并且已大致确定,模拟实验中所有离子的大约50%具有如下m/z值的离子,所述m/z值落入针对典型胰蛋白酶分析的从大约350至1350的总m/z范围内。应该指出的是,总m/z范围可随着特定分析和被分析的所关注样品而变化。因此,基于可随着样品、实验、样品处理等而变化的这样的一个或多个因素,可指定m/z值的总范围用于以下段落中描述的MMA技术。
参见图29,示出了说明与在洗脱时间内的前体离子数目有关的频率或计数的分布的例子。在Y轴上是m/z,在X轴上是保留时间(RT)。图上的矩形或斑点的厚度表示在具有特定m/z值的特定RT区段或范围中的前体离子的频率或数目。图上某一点上的矩形或斑点越大,与图上该点处的特定m/z值和RT相关联的离子的数目或频率就越大。例如,虚线Q和Q'之间的框或矩形表示大约50%的前体离子落在从约350至1350的总m/z范围内。图上各个矩形之间的白色平分线表示每个RT区段中的中值。元素2802标识出3条这样的线,每条线表示RT区段中的一个的中值。
应该指出的是,可以任何合适的方式获得如以下段落中所述的最小和最大m/z值的总范围、关于具有不同m/z值的离子的频率的分布等。例如,一个实施例可通过对各种样品进行实际的实验、通过模拟等获得此类信息。例如,图29所示的关于前体离子的m/z值的频率随洗脱时间的分布信息可使用模拟器或诸如本文其他地方所讨论的建模软件来获得。
出于说明目的,可将被划分成“n”个m/z间隔或分区的350-1350的总m/z范围与随后的示例和说明结合使用来说明MMA技术的用途。然而,应该指出的是,总m/z范围通常可以是所需的任何m/z值范围。
MMA技术可使用关于具有各种m/z值的前体离子的频率或数目的分布的信息来改变MIW的宽度或尺寸。如在以下段落中所述,可选择MIW的尺寸或宽度,使得所选择和允许通过以用于随后碎片化的前体离子的数量在循环的洗脱时间或RT区间内大致相同。
在图29中示出了在图上表示为循环A、B和C的“n”个m/z间隔中的3个。循环A可具有350-550的m/z间隔。循环B可具有475-700的m/z间隔。循环C可具有525-750的m/z间隔。因此,在所示示例中,不同m/z间隔或循环的m/z范围重叠。
应该指出的是,如果有的话,关于本文所述的处理,m/z间隔之间的特定重叠量可被指定作为输入。例如,作为第一选择,一个实施例可指示在与n个循环相关联的m/z间隔之间不存在重叠。作为第二选择,一个实施例可指示在每两个连续循环之间发生固定量的重叠。例如,可通过指示m/z值(例如,25)的绝对量或次数来指示此类重叠。作为另一种选择,一个实施例可诸如基于函数、公式等来改变两个连续循环之间的重叠量。
参见图30,所示出的是更详细地示出了可在根据本文技术的一个实施例中的循环A、B和C中使用的MIW的一个示例。
在示例2700中,大致示出了每个循环A、B和C中的不同MIW。该示例中的每个循环包括10次扫描- 1次低能量/探测扫描、如2711所示的1次覆盖初始MIW的高能量扫描和根据为该循环预定的MIW的变化尺寸(例如,诸如按照图31的2930)的8次升高能量扫描。根据本文技术的一个实施例可使用Bateman技术或本文其他地方所述的高-低规程数据采集技术进行每个循环的第1次和第2次扫描,以获得每个循环的初始MIW的前体和相关联的碎片数据(例如,初始MIW是循环的整个m/z间隔)。每个随后的扫描(3-10)仅反映当个循环的当次扫描的预定MIW窗口内的那些前体离子的产物离子谱。
参考循环1或A,在2710中示出的是两条时间线LE和EE,其表示在改变MIW宽度并且对于每个MIW宽度还改变循环A中相关联的m/z范围的情况下,在洗脱时间内执行的四极杆前体离子MIW (LE)和升高能量(EE)或高能量(HE)中的变化。以类似的方式,参考循环B,在2720中示出的是两条时间线LE和EE,其表示在改变MIW宽度并且对于每个MIW宽度还改变循环B中相关联的m/z范围的情况下,在洗脱时间内执行的四极杆前体离子MIW (LE)和升高能量中的变化。另外,参考循环C,在2720中示出的是两条时间线LE和EE,其表示在改变MIW宽度并且对于每个MIW宽度还改变循环C中相关联的m/z范围的情况下,在洗脱时间内执行的四极杆前体离子MIW (LE)和升高能量中的变化。
在该示例中,对于每个循环,第一扫描(表示扫描1)使用对应于与该循环相关联的整个m/z间隔的MIW。例如,对于循环A,元素2710识别10次扫描,其中扫描1表示与循环A相关联的m/z间隔的整个m/z范围350-550。扫描2反映初始MIW (m/z=350-550)的产物离子谱,剩余的编号为3-10的8次扫描分别反映了在该扫描的预定MIW窗口内从前体离子发出的一组碎片离子,如2930所示。
以类似于针对循环A所述方式的方式,对于循环B,元素2720识别10次扫描,其中扫描1表示整个m/z范围475-700,扫描2反映了来自与循环B相关联的m/z间隔的初始MIW中的碎片离子。剩余的8次扫描3-10反映了在预定MIW内的那些前体离子的产物离子谱,该预定MIW具有均在随后的或顺序扫描中变化的宽度和相关联的m/z范围或窗口。
以类似于针对循环B所述方式的方式,对于循环C,元素2730识别10次扫描,其中扫描1表示整个m/z范围525-750,扫描2反映了来自与循环C相关联的m/z间隔的初始MIW中的碎片离子。剩余的8次扫描3-10反映了预定MIW内的那些前体离子的产物离子谱,该预定MIW具有均在随后的或顺序扫描中变化的宽度和相关联的m/z范围或窗口。
在根据本文技术的一个实施例中,对于循环A的扫描1,可在m/z范围350-550内获取LE扫描数据,并且可在m/z范围50amu至最大m/z内获取HE扫描数据,其中最大m/z是最高m/z和当时该MIW的z以及(如果采用了IMS)漂移时间的函数。对于循环A的扫描3-10,没有获取LE扫描数据。相反,改变四极杆以仅传输每个此类扫描的预定MIW。在每次扫描3-10中,MIW可被指定为更窄或更宽,这取决于正在采样该循环的初始MIW的哪个部分,如2930所示。下文更详细地描述了改变MIW宽度。对于循环A的扫描3-10,使用该特定扫描的特定变化MIW宽度来获取HE扫描数据。
在以下段落中更详细地描述了可用于确定与循环A、B和C的此类扫描3-10中的每个MIW相关联的变化MIW宽度和变化m/z范围的技术。应该指出的是,在一个实施例中,可通过类似于DDA如何创建切换列表的方式来设置MIW的宽度。或者,可诸如使用模拟器或控制仪器的其他软件对MIW的宽度进行预编程。此外,与每个MIW相关联的m/z值的范围或窗口可被编程为随每次扫描而改变。
因此,参考图30,循环中的每个矩形或条表示可在根据本文的技术的实施例中进行的数据采集。例如,在循环A中,元素2711表示在循环A的单次执行中采集的各种LE和HE数据集。元素2711包括可在循环A的单次执行中采集的扫描1的单个LE扫描数据集和扫描2-10的9个HE数据集。在循环B中,元素2721表示在循环B的单次执行中采集的各种LE和HE数据集。元素2721包括可在循环B的单次执行中获取的扫描1的单个LE扫描数据集和扫描2-10的9个HE数据集。在循环C中,元素2731表示在循环C的单次执行中采集的各种LE和HE数据集。元素2731包括可在循环C的单次执行中采集的扫描1的单个LE扫描数据集和扫描2-10的9个HE数据集。
在根据本文的技术的实施例中,在继续使用下一个循环处理之前,与单个循环相关联的处理可重复一段时间。例如,考虑以下内容。实验具有100分钟的总洗脱时间或实验运行的总时间量。指定的m/z间隔的数量“n”可以是20,由此每个m/z间隔或循环可被执行5分钟(例如,100/20=5)。MS扫描速率可以是10次扫描/秒或600次扫描/分钟。因此,对于每个循环可在5分钟内获取3000次扫描的数据。在该示例中,与循环A相关联的处理可重复5分钟。一旦循环A已运行了5分钟的时间段,可执行下一个循环5分钟,依此类推,直到所有的20=n个循环都已执行了其相关的处理。
通常,如将在以下段落中更详细描述的,随着m/z间隔内的离子数量的频率或计数增加,MIW的宽度减小,目的是选择或允许近似相同数量的离子随时间通过质量过滤器用于随后的碎片化。因此,在每次扫描中,MIW的宽度和m/z窗口或范围的属性可表征为不同m/z值处的前体离子的频率分布的函数。
参考图31,所示出的是示出可在根据本文技术的一个实施例中使用的循环A的m/z值的频率分布的示例。示例2900以图形方式示出了具有350-550的关联m/z间隔的循环A的分布。如本文其他地方所述,可以任何合适的方式获得2900的分布。例如,该分布可使用模拟器或者建模软件来模拟或者理论上确定,可作为运行真实实验的结果来获得,等等。
示例2900示出了8个m/z区段或条框,其中每个m/z区段为25m/z单位。应该指出的是,循环A的m/z间隔为350-550,由此在该示例中m/z间隔包括350,但不包括端点550(例如,表示m/z间隔350≤m/z≤550)。图31指定了所表示的每个m/z区段的包含性m/z值。例如,第一区段具有350-374的包含性m/z范围,其中5个前体离子的频率落入该m/z范围。第二区段具有375-399的包含性m/z范围,其中15个前体离子的频率落入该m/z范围。具有包含性m/z范围425-449的第四区段具有全部所示的m/z区段的60个的最高频率。随着表示m/z区间或区间中的前体离子的数量的频率或计数增加,MIW的宽度减小。
元素2920列出了与具有350-550的m/z间隔的循环A的分布相关联的一些属性。在该示例中,m/z间隔350-550具有160的总离子数(例如,2900中的所有频率之和)。如果MIW随扫描变化的次数=8(例如,如图30中的扫描3-10),那么在每次扫描中过滤或允许通过的前体离子的平均数量应当是约20。基于此,可执行代码以确定循环A中的每次扫描的变化MIW宽度及其相关联的m/z窗口或范围。在该示例中,循环A的扫描可具有这样的MIW,该MIW具有不与相同循环A中的先前扫描的m/z窗口重叠的相关联的m/z窗口。所有扫描3-10中的所有MIW的m/z窗口可覆盖整个m/z间隔。下一次扫描针对其MIW具有在前一次扫描的m/z窗口结束处起始的相关联的m/z窗口(例如,扫描4针对其MIW具有以m/z=400起始的相关联的m/z窗口,而扫描3具有的相关联的m/z窗口以m/z=399结束)。因此,在一个循环(诸如A)内,处理可将MIW设置为具有递增地遍历该循环A的整个m/z间隔的相关联的m/z窗口。
元素2930列出了每个扫描编号3-10的可在循环A的单次执行的处理中确定和使用的变化宽度和m/z窗口。
参考图32,示出了可用于在根据本文技术的一个实施例中针对循环A的单次执行的各种扫描中的变化MIW宽度和m/z窗口的进一步说明。示例3000包括来自表2930的为便于检查而转载的信息。另外,示例3000包括针对循环A的单次执行中的每次扫描识别相关联的MIW m/z窗口和MIW宽度的表3010。行3012表示每次扫描的不同MIW m/z窗口。行3014表示每次扫描的不同MIW宽度。行3016表示以数字示出的特定扫描以及对于其是低能量扫描还是高能量扫描的指示。
如本文其他地方所述,循环A包括10次扫描组,每组对应于行3016中的一个单元。对于扫描“X”,其中X是从1到10的包含性范围中的整数,指定“XLE”表示扫描X为LE扫描,并且指定“XHE”表示扫描X为HE扫描。因此,行3016中的每个单元可表示单次低能量扫描或单次高能量扫描。
如上文和本文其他地方所述,在扫描1 3016a(表示为1LE)中,使用作为该循环的整个m/z间隔的MIW来采集LE“探测”扫描的数据集。扫描2 3016b(表示为2HE)是包括使用来自扫描1的MIW的前体离子产生的碎片离子的高能量扫描。在扫描3-10中,可执行处理以设置和使用指定的MIW(针对每个此类扫描具有如行3012和3014所示的宽度和m/z窗口),然后在该扫描的指定MIW内执行前体离子的HE扫描数据采集(如由3HE至10HE所示)。例如,元素3016a是表3010的表示第一次扫描的单个单元,其中针对MIW获取了一组LE扫描数据,该MIW被设置为具有200的MIW宽度的350-549(包含性)的整个m/z间隔。单元3016b表示第二次扫描,其中通过前体离子的碎片化采集了一组HE扫描数据,该前体离子具有在指定MIW宽度为200的m/z窗口350-549(包含性)内的m/z值。类似地,单元3016c-3016j表示针对剩余的扫描3-10将MIW宽度和m/z窗口设置为行3012和3014中指示的特定设置(例如,在每个扫描3-10中,为前体离子产生的碎片离子执行HE数据采集,该前体离子具有落入为该扫描指定的特定MIW的m/z窗口中的m/z)。
基于图31中的分布,使用如图32的表3010中的MIW宽度和m/z窗口产生变化的MIW宽度和m/z窗口,使得大致相同数量的20个前体离子被过滤或选择以及被允许通过以用于随后的碎片化。
应该指出的是,结合图31和图32的前述示例示出了作为m/z值的函数的频率分布诸如在LC/MS实验中的用途。一个实验也可结合LC/MS使用IMS,从而增加另一分离维度,即漂移时间或碰撞截面积(CCSA2)。因此,在还使用IMS的此类实施例中,如图31所示的X轴上的条框或区段可以是m/z和漂移时间或CCSA2。
另外,根据本文技术的实施例还可在每次扫描中选择可随特定MIW m/z窗口、保留时间(RT)和/或漂移时间或CCSA2中的一者或多者而变化的碰撞能量。例如,参考图33,其中示出了可在根据本文技术的实施例中使用的3100表。
表3100可以是预先确定的碰撞能量值的查找表。表3100可通过如列3110所示的m/z、RT和漂移时间或CCSA2中的任何一者或多者进行索引。列3112可提供用于m/z、RT和漂移时间或CCSA2的不同值的不同碰撞能量。对于为m/z、RT和漂移时间或CCSA2指定的特定的一组一个或多个值,表格3100的每行可识别推荐使用的相应碰撞能量值或值的范围。因此,根据本文技术的实施例可使用表3100基于与特定HE扫描相关联的特定MIW m/z窗来改变或选择每个HE扫描中的碰撞能量。例如,对于m/z窗口425-432的扫描5,再次参考图32的元素3020。对于循环A处理的特定执行,可确定RT或洗脱时间和漂移时间,并与m/z窗口425-432一起使用以选择3110的匹配条目。从包括匹配条目3110的表3100的行开始,可从列3112中检索碰撞能量值,并将其用作前体碎片化或HE扫描5HE的选定碰撞能量。因此,在循环A处理的执行期间,可将循环5HE中的碰撞能量设置为检索到的碰撞能量值。
在根据本文技术的一个实施例中,如上所述,可使用模拟器或建模软件来确定用于确定各种循环的MIW宽度和m/z范围的理论分布。在此类实施例中,软件可提供一组输入。此类输入可包括总洗脱时间、m/z间隔的数量、表征样品和样品准备的一个或多个参数、采集时间(例如,单次扫描的时间长度)、表征m/z间隔间的重叠的一个或多个参数、是否执行IMS、是否使用恒定的碰撞能量以及是否诸如结合图33所述的(例如,根据m/z、RT和/或漂移时间或CCSA2)使用查找表来改变或设置HE扫描中的碰撞能量。在本文其他地方更详细地描述了上述输入。基于该输入,模拟器或建模软件可确定如上所述用于各种循环的具有不同宽度和m/z窗口的MIW。
如本文所述,“SSPPIS”是包括来自LE扫描及其对应的HE扫描的数据的单扫描前体-产物离子谱。如本文所述,可结合各种采集方法(其中一些在本文中有所描述)来获得此类LE和HE扫描数据集。例如,可使用Bateman技术或高-低规程技术。另外,如上所述,一个实施例可使用其他采集技术,诸如DDA和MMA。对于DDA和MMA采集,可在每次探测扫描的选定前体离子的质量隔离窗口内的每个PCC上构建SSPPIS。关于MMA,“探测扫描”可以是每个循环的第一次扫描,其中质量或m/z滤波选择循环的m/z间隔中的所有m/z(例如,参见图32的3016a)从而允许所有具有此类m/z的前体离子通过以用于碎片化。
无论采集方法如何,可为每个单独的PCC初始分配其伴随产物离子谱。这包括诸如在MMA或DDA采集中的MIW内或诸如在Bateman技术或高-低规程技术中的LE扫描内的所有前体离子。如果数据是在IMS激活的情况下获取的,则可通过在限定的容差内匹配漂移时间来完成初始前体和产物离子的对准。
参考图33B,示出了可在根据MMA技术的一个实施例中执行的处理步骤的流程图。流程图3150总结了如上所述的处理。在步骤3152中,确定对于一个指定的总m/z范围的m/z值的频率的分布。在步骤3154中,确定实验的多个循环,并且对于每个循环确定对应的m/z间隔范围。在步骤3156中,可为当前循环分配在后续步骤中执行处理的下一个循环。在步骤3158中,确定处理是否已完成了所有“n”个循环。如果是,则控制进行到步骤3160,在该步骤中可使用针对“n”个循环的扫描确定的各种MIW来执行实验。如果步骤3158评估为否,则控制进行到步骤3162。对于当前循环,确定当前循环的m/z间隔的m/z值的频率分布。例如,图31示出了可结合针对当前循环的步骤3158执行的此类处理。在步骤3164中,对当前循环的除前两次扫描之外的每次扫描执行处理。对于除前两次扫描之外的每次此类扫描,确定MIW宽度和相关联的m/z窗口,由此在每次扫描(除前两次扫描之外)中选择或允许通过大致相同数量的前体离子。例如,步骤3164确定如图32的表2930所示的信息。在步骤3166中,可任选地执行处理,以根据与HE扫描相关联的MIW的m/z窗口以及与该特定的HE扫描相关联的RT和/或漂移时间来选择执行每个HE扫描时使用的碰撞能量。控制进行到步骤3156。
因此,流程图3150执行处理以确定针对“n”个扫描的特定MIW宽度和相关联的m/z窗口的调度以及任何任选地在步骤3166中确定的碰撞能量,然后使用前述方法结合步骤3160继续执行数据采集。
参考图34,描述了可在根据本文技术的一个实施例中执行处理以确定MMA或DDA采集中的PCC的强度。对于具有关联m/z的特定PCC,可跟踪各种扫描中的PCC的强度。对于DDA,此类扫描可包括探测扫描。对于MMA,此类扫描可包括循环中的第一次扫描(例如,图32的元素3016a)。考虑到PCC或前体离子的强度在探测扫描中是已知的以及MS/MS采集在时间上是连续的事实,在探测扫描和碎片化中前体离子的强度将是不同的。AR1是碎片化时产物离子与母体前体的比率。如果MIW内有五个前体离子或PCC,则每个前体离子都会产生自己的产物离子或MS/MS谱图。MS/MS谱图中的产物离子代表来自所有前体的复合谱图。在这种情况下,按m/z和区域或强度进行过滤,复合产物离子与所有五种前体共享图谱。产物离子的m/z或强度不能大于前体,并且最小强度不能大于其前体的最小强度的1/250。根据本文的技术,可执行处理以确定碎片化时的PCC强度。图34示出了可完成该步骤的方法。在每次探测扫描中,可记录PCC的强度值,并且可执行线性回归或插值以确定探测扫描之间的任何所需的强度值。在图34中示出了对应于10次扫描的10个点,在这些点处,相同PCC的强度是已知的并且在形成所示曲线的时间内对其进行追踪。例如,这样的10个点可对应于10次探测扫描或PCC的m/z被选择的次数。PCC的碎片化可发生在例如可处于两次探测扫描之间的点P1处。点P1处的PCC的强度可使用线性内插或本领域中已知的任何其他合适的技术来确定。
在蛋白质组学研究中,普遍认为DDA采集中的覆盖深度和动态范围是有限的。该方法的连续性质限制了灵敏度和可被采样的前体离子的数量。为此,已引入了大量的非数据依赖型采集(DIA)策略(其中一些在本文中有所描述),其中这些方法大部分不受采样问题的影响,有一些方法在灵敏度方面有一些限制。DIA方法的一个主要限制是干扰,即MS/MS图谱是高度嵌合的并且常常不能用常规的数据库搜索引擎来识别。在本文技术的在离子检测之前利用每个可用的分离维度至少一个实施例中,可利用在以下段落中描述的MMA策略的特定实现方式和工作流程。可在一个实施例中使用的以下段落中的MMA策略和工作流程包括在单个分析工作流程中多路复用的窄带和宽带DIA。本文技术的一些实施例可执行具有迭代性质的MMA,由此MMA工作流程以最小的灵敏度损失来限制干扰的不利影响。可通过选择离子色谱图(SIC)或常规的数据库搜索策略来执行定性识别。
高分辨率DIA采集策略作为新兴技术被重点提出,从而显现出在定性和定量“靶向分析”领域的日益普及。也日渐地广泛认为,更高分辨率的Q-Tof和Orbitrap质量分析器在复杂基质中的靶向定量领域“已经成熟”。更高分辨率的质量分析器通过消除研究人员预先确定每种肽的最佳通道的必要性来减少测定开发时间。精准定量复杂混合物中肽的能力可基于所应用的分析工作流程在不受周围基质的影响下测量每种离子的物理化学属性的能力来预测。就m/z、色谱和漂移峰宽度而言,更高的分辨力在减少离子干扰的不利影响方面是最重要的。数据处理工具(诸如可与本文技术结合使用)可计算离子纯度计分(IPS),该指标反映了已被测量的每种离子的面积的情况。通过将半高、m/z、时间和漂移与其相应的实验方法进行比较来计算IPS。为了评估所测量的m/z,使用锁定质量通道的分辨率进行比较,因此对于ICR,质量分辨率是瞬态测量时间和m/z的函数。已知测量瞬态时间和m/z提供了计算用于比较的理论质量分辨率的方法。至于色谱和漂移峰宽度,对于每一者将各自相应的宽度与整个梯度洗脱中所有计算值的中值进行比较。
在任何一个所采用的分离空间中,分辨率的提高都伴随一定的后果。结合分析技术,选择性和分辨率之间的关系遵循标准的S曲线。超过拐点的分辨率设置通常会对实验的其他方面产生有害影响,例如灵敏度的降低。灵敏度是离子通量(离子/单位时间)的函数。较窄的色谱峰导致较高的离子通量。较窄的色谱峰需要更快的扫描时间来维持占空比。如果扫描速度的增加不会导致每单位时间产品离子谱数量的同时增加,则在占空比或灵敏度上都不会有净增益。离子通量通常可定义为每单位时间离子从MS检测器输出的速率(例如,离子数/时间单位以及它们在m/z范围内的分布情况)。离子通量与诸如本文其他地方所述的不同m/z值随时间的频率分布类似(例如,图31利用MMA结合有关MIW选择尺寸和范围的描述)。
富集仪器中质量分辨率是m/z和瞬态测量时间的函数,其中窄峰需要更快的采样速度,瞬态测量时间的同时增加会按比例降低实验质量分辨率。对于Q-Tof几何结构,分辨率与测量时间无关,灵敏度由飞行时间分析器的占空比和传输率控制。通过增加正交分离的次数,可减轻质量和色谱分辨率上的压力,使得每一者都能够在它们各自的拐点之下操作。所应用的分析工作流程在最宽的动态范围内以最高的准确度和精确度精确识别和定量复杂混合物中肽的最大数量的这种能力可表征为在离子检测之前所采用的所有分离技术的直接结果数量和分辨能力。
该MSE DIA工作流程以交替方式采集MS全扫描数据,其中碰撞移动室处于低能量状态和升高能量状态之间。如本领域所知和本文其他地方所述,MSE(在本文中也被称为Bateman技术或高-低规程)是指使用交替的低能量碰撞诱导解离和高能量碰撞诱导解离的串联质谱数据采集方法,其中前者用于获得前体离子精确质量和强度数据进行定量,后者用于获得产物离子精确质量。利用MSE(例如,Bateman技术或高-低规程)不进行前体离子选择,所有前体离子同时碎片化。在此类实施例中,碰撞能量可在升高能量采集时间内从低能量状态渐变到升高能量状态,以在所有电荷态中提供更完整的碎片化。通过峰形和顶点保留时间(在本文中有时也称为RT或tr)的相似性将产物离子与其母体前体对准。覆盖深度、肽识别的数量可与当时比较传统的DDA采集策略相当。然而,在这些高度嵌合的产物离子谱中的识别需要专门的数据库搜索引擎。使用商业和开源数据处理和搜索工具无法处理和搜索MSE DIA数据一直是一个限制。例如,通过引入行波离子淌度质谱(TWEMS)提高了该方法的选择性。在检测之前TWIMS几何结构以二维形式(IMS漂移m/z)将离子分开。IMS的加入增加了峰容量并降低了嵌合度,而几乎没有降低灵敏度。对于IMS增强型数据集,前体和产物离子通过其各自的峰形以及顶点保留时间和漂移时间(td在本文中也用来指漂移时间或漂移时间区段)对准。这些高清MSE (HDMSE) IM(离子淌度)-DIA前体和产物离子谱反映了更高的选择性,从而允许更大的覆盖深度和动态范围。虽然选择性增加并且因此产品离子谱质量改善,但HDMSE IM-DIA产物离子谱仍然是高度嵌合的,并且在很大程度上仍需要专门的DIA数据处理工具。尽管选择性有所提高,但与更近期的较高扫描速率相比,DDA仪器在识别相似数量的肽的能力上仍具挑战性。
最好通过使用选择离子色谱图(SIC)对照谱库来筛选产品离子谱完成定性识别,基于这一推理,有人提出,DIA产物离子谱可能过于复杂,无法使用常规的数据库搜索工具进行识别。为此,已利用SIC方法(例如,包括:FT-ARM、SWATH(所有理论质谱的顺序窗口采集)和MSX(多路DIA)采集)引入了多种替代的DIA策略。虽然类似于不进行前体离子选择的MSe DIA,但使用用户定义的m/z间隔在m/z范围内进行连续采样。m/z范围的缩小限制了产物离子谱中嵌合降低的共碎片化肽的数量。在这些DIA工作流程中,用户定义的质量隔离宽度可遍历预先确定的质量范围(SWATH)或随机定位在其中(MSX)。例如,采用MSX方法,在500-900m/z的预定质量范围内对一系列4-Th宽质量隔离窗口进行随机采样。与以下段落和本文其他地方关于建模和模拟的讨论相一致,m/z域(例如,500-900m/z)的这一部分反映了整个时间域上的最大密度的前体离子通量。假定由较窄(但仍比DDA宽)的质量隔离窗口产生的产物离子谱将发生更少的嵌合,并且更易于通过SIC方法识别。还可通过解复用重叠的产物离子谱并将产物离子分组来增强该方法并减少嵌合。将匹配的产物离子分配到重叠区域,使那些独特的产物离子各自留在其相应的m/z区段中。考虑到选定的m/z窗口(500-900Th)的离子密度和较高扫描速率MS2(例如,MS/MS)采集的较低质量分辨能力,两种或更多种共碎片化前体在质量分辨率内产生相似m/z的产物离子的能力是高的。耗尽这些离子可能会限制选择性而不是增加选择性。
DIA模式本身并不能克服DDA的现有限制。占空比仍是扫描速度的函数,而更高的扫描速度对灵敏度是不利的。为了通过SWATH或MSX保持占空比一定的相似性,需要减小m/z域的宽度以便在不会完全牺牲灵敏度的情况下设置采集时间。尽管对所有洗脱肽都能采集到产物离子谱,但对m/z空间的高度受限采样意味着很大区域的m/z未被采样。将需要对整个m/z范围进行采样;甚至需要更快的扫描速度、更宽的m/z隔离窗口或多次进样。必须采集多次进样不会增加占空比,也不会对实验峰容量或离子干扰产生任何影响。
使用本文所述技术的一个实施例可被表征为利用DIA技术在不损失灵敏度的情况下具有改善的选择性。为此,在以下段落中描述了根据本文技术的利用MMA采集策略的一个实施例,该策略利用离子通量、m/z和漂移来设置每个DIA采集的MIW宽度。在此类实施例中,洗脱时间可分碎到扫描循环中,并且扫描循环的次数可以是所有洗脱组分的平均色谱(FWHM)的函数。考虑到精确的AUC(曲线下面积)定量需要色谱图峰的FWHM上的最少五个数据点,因此可强制执行下限五个扫描循环。在如下所述的至少一个实施例中,每个扫描循环可包括17个单独的DIA采集-一个低能量、两个宽带(50Th<MIW<500Th)和14个窄带(1Th<MIW<50Th) HDMSe IM-DIA(高清MSe离子淌度)采集(例如,HDMSe表示与Bateman技术或高-低规程的MSe结合执行IMS以用于数据采集)。如下所述并且与本文的其他说明一致,宽带和窄带采集中的每一者可使用具有可随每个扫描循环而变化的尺寸或宽度以及关联的m/z范围的MIW。每个MIW可指定一个m/z范围,其表示允许通过低能量扫描以用于随后的碎片化的m/z值的范围。因此,使用具有某个m/z范围的MIW提供了在低能量扫描中选择性地允许具有在该m/z范围内的m/z的前体离子或离子进行碎片化,以限制源自一种前体离子所产生的碎片离子的量。除了重复的低能量HDMSE IM-DIA全扫描采集之外,在至少一个实施例中,每个宽带和窄带HDMSE IM-DIA采集的中心m/z值随扫描循环而变化。在至少一个实施例中,可执行处理以选择宽带和窄带MIW中的MIW窗口以遍历整个m/z范围,同时也允许后续扫描中的MIW间的重叠。扫描循环之间的中心m/z的动态运动允许对每个前体进行多次采样,作为不同MIW的一个组成部分。使用解复用架构,本文描述的技术在几乎不损害灵敏度的情况下产生高度区分的产物离子谱。
可使用常规的数据库搜索引擎来搜索或使用已知的SIC技术来匹配高度选择性的产物离子谱。已识别的图谱可存入分子离子库(MIR)的推定部分中。对于洗脱分子或组分,可推定或认为这种推定识别(例如,前体以及对于每种前体,其相关的碎片离子)是正确的但还未经验证。在至少一个实施例中,一旦至少存储了五十个推定识别,MIR内部的验证算法就被激活。在后台操作中,验证算法可连续选择30个推定识别的产物离子谱的随机采样,并执行处理以确定这些谱之间的相关性和统计显著性。例如,一个实施例可应用本领域已知的点积光谱相关性和皮尔逊积矩相关系数来确定显著性。例如,点积光谱相关性在Toprak、U. H.、Gillet、L. C.、Maiolica、A.、Navarro、P.、Leitner、A.和Aebersold、R. (2014),“Conserved peptide fragmentation as a benchmarking tool for mass spectrometers and a discriminating feature for targeted proteomics”,Molecular & Cellular Proteomics, 13(8), 2056-2071中有所描述,该文献以引用方式并入本文,而皮尔逊积矩相关系数在Morreel、K.、Saeys、Y.、Dima、O.、Lu、F.、Van de Peer、Y.、Vanholme、R. … Boerjan、W. (2014),“Systematic structural characterization of metabolites in Arabidopsis via candidate substrate-product pair networks”,The Plant Cell,26(3), 929-945中有所描述,该文献以引用方式并入本文。如果发现正相关性,则产生复合产物离子谱(在本文其他地方描述),并且该肽的分子离子特征可存储在MIR中。
现在将描述的是在以下段落中描述的使用本文技术的一个实施例中使用的材料和方法。
在样品准备中,使酵母菌株W303 MATα (ATCC:24657) (Blue Sky BioServices, Worcester, MA)在YPD培养基中生长直至早期至中期对数期。通过在4℃下以4,000g离心5分钟收获细胞。将沉淀悬浮于含100mM二硫苏糖醇(DTT)和5%十二烷基硫酸钠(SDS)的100mM Tris pH 7.6中。除非另有说明,否则所有化学品均购自Sigma- Aldrich (St. Louis, MO)。将得到的裂解物加热至95℃持续5分钟,然后使用Bioruptor超声仪(Diagenode, Liège, Belgium)在20kHz、320W、60s循环下超声处理30分钟。完全裂解后,将上清液以16,000g离心5分钟以澄清蛋白质提取物。
进一步关于样品准备,将约50µg的每种样品冻干,并溶解于含0.05% (w/v) RapiGest (Waters Corporation, Milford, USA)的50mM碳酸氢铵中。将样品在10mM DTT存在下于60℃还原30分钟,然后在50mM碘乙酰胺(IAA)存在下于环境温度中在无光条件下进一步烷基化30分钟。通过以1:10 (w/w)的比率加入测序级经TMPK处理的胰蛋白酶(Promega, Madison, MI)启动蛋白水解消化,并在37℃下温育过夜。加入TFA至最终浓度为0.5% (v/v)以水解RapiGest,并将溶液在37℃下温育20分钟,然后涡旋并以13,000rpm离心30分钟。样品分析前将浓缩的原液稀释至100ng/µL。
将要描述的是可用于分析上述样品的LC-MS配置。使用配备有BEH C18 1.7µm, 20cm×75µm分析RP柱(Waters Corporation)的nanoAcquity系统(Waters Corporation)进行胰蛋白酶肽的ID纳升级LC分离。将1微升样品加载到柱上。流动相A为含0.1% (v/v)甲酸的水,流动相B为含0.1% (v/v)甲酸的乙腈。将肽从分析柱中洗脱,并用90分钟内流动相B由5%升至35%的梯度和300nl/min的流速对其进行分离,随后用90%流动相B进行10分钟的柱冲洗。在初始条件下重新平衡该柱20分钟。柱温保持在35℃。通过LC系统的辅助泵以250nl/min的速度将锁定质量化合物[Glu1]-纤维蛋白肽B (50nM)输送到质谱仪的NanoLockSpray源的参比喷雾器。
使用质谱仪(Waters Corporation, Wilmslow, United Kingdom)的Synapt G2-S1和Xevo G2-XS QT执行胰蛋白酶肽的质谱分析。两种仪器均在分辨率模式下运行,其中标称质量分辨率设置分别为20,000和25,000。所有实验均以电喷雾正离子模式进行,离子源模块温度和毛细管电压分别设定为80℃和2.5kV。用NaCS1混合物将飞行时间分析器(ToF)的m/z从50外部校准至1990。使用[Glu1]-纤维蛋白肽B的双电荷单同位素离子对数据进行锁定质量校正后的采集。参比喷雾器以30s的频率进行采样。在Synapt G2-S1上以非数据依赖型(HDMSE IM-DIA)采集模式以及在Xevo G2-XS QTof上以非数据依赖型(MSEDIA)采集模式收集精准的质量LC-MS数据。所有采集都是在0.1秒内采集的,其中扫描间延迟为0.025秒。在低能量MS模式下,以每单位电荷4eV的恒定碰撞能量收集数据。在升高能量模式下,使用类似于DDA采集中使用的查找表,将碰撞能量从初始值渐变到最终值。
参考图35,所示出的是示出了可在根据本文技术的一个实施例中执行的工作流程的示例3500。工作流程3500可结合上述进行实验的样品来执行。
元素3502表示包括目标3502a、模拟器3502b、建模参数3502c和校准公式3502d的工作流程建模阶段。元素3504表示包括调度器3504b、调度参数3504a以及用于执行实验的仪器和设备3503的工作流程采集阶段。在至少一个实施例中,元素3503通常可表示执行用于样品分析(诸如用于分析上述制备的酵母样品)的色谱(例如,LC)、质谱和(任选的)离子淌度质谱的科学仪器系统。在至少一个实施例中,调度器可确定在执行用于实验和样品分析的数据采集时用于控制质谱仪的调度。与本文其他地方的讨论一致,除了质谱仪之外,还可结合使用除质谱仪之外的一个或多个附加仪器来执行样品分析,尽管如本文所述的调度器的实施例可仅影响由质谱仪执行的处理。元素3506表示包括原始文件3506a、数据处理3506b、对准图谱处理3506c、解复用3506d和数据库搜索3506e的通用工作流程数据处理或数据分析阶段。元素3508表示包括MIR 3508a、验证处理3508b和推定产品离子谱库3508c的存储工作流程阶段。元素3505表示产生关于离子通量3505a、m/z与tr的关系3505b、m/z与td的关系3505c以及tr与td的关系3505d的输出的空间映射阶段。
通常,工作流程3500示出了两个主要工作流程路径,其中第一路径由固体连接器和箭头限定,第二路径由虚线箭头和连接器限定。第一路径表示使用模拟器的流程。可以迭代方式使用由第二路径表示的流程,例如对于所执行的每次运行或进样以及在如本文其他地方所述的多次运行或进样中迭代地使用。
将表示模拟或建模目标3502a的文件输入到模拟器3502b中。结合上述酵母样品,目标3502a可包括在测试和分析下可存在于样品中的可能的肽、蛋白质或完整的蛋白质组。通常,目标3502a识别待由模拟器3502b模拟的一组分子。因此,目标3502a可随待分析的特定样品而变化。例如,如果样品包括小分子、农药等,那么目标3502a将使用工作流程3500来识别在分析时可出现在样品中的此类分子。模拟器3502b模拟在目标3502a中识别的分子的属性或生理化学性质。例如,模拟器3502b针对目标分子3502a确定的建模属性可包括保留时间、漂移时间、碎片化模式信息(例如前体和由于前体离子碎片化而产生的相关碎片离子)、前体和碎片离子的m/z的预期、建模或模拟的属性值等。建模的属性通常可包括本文所述以及本领域中已知的任何属性的建模值。
将建模或模拟的属性(例如,3502a的目标分子的建模的物理和化学属性)输入到调度器3504a,该调度器使用该建模的输入来设置/确定MMA调度。数据采集参数3540a在本文其他地方有更详细地描述,并且通常随所执行的特定实验和数据分析而变化。例如,调度器3504b能够例如基于模拟的保留时间来确定洗脱分子或组分的预期采集顺序。调度器3504b设置影响采集时间线的参数3504a,该采集时间线例如扫描循环/色谱FWHM的数量、扫描时间、宽带和窄带m/z隔离宽度(MIW)以及碰撞能量表。参数3504a还可包括用户定义的信息,诸如任何用户定义的最小值或匹配容差。
样品分析由包括根据MMA设置或调度器3504b生成的调度进行操作的质谱仪的仪器3503执行。作为实验运行或进样的结果,产生原始数据3506a,然后在数据处理3506b中处理该原始数据。数据处理3506b包括如下文和本文其他地方所述的数据处理。例如,数据处理3506b可包括单个扫描处理、构建电荷簇组或PCC的处理以及确定PCC的电荷态或潜在/候选电荷态的处理。对准处理3506c可包括在每次扫描中使前体和产物或碎片离子对准(例如,形成单次扫描的SSPPIS),并且还按m/z在时间上组合PCC(例如,以形成表示随时间洗脱的离子或PCC的曲线)。因此,对准处理3506c可包括形成单个扫描的SSPPIS并且随时间对于相同PCC的组合SSPPIS(例如,随时间洗脱的相同PCC的轮廓或包络)。然后将对准的产物和前体或SSPPIS输入到解复用3506d。
通常,解复用3506d可表征为与特定前体离子或PCC相关联的特定产物离子的进一步细化(例如,以选择性地细化、过滤或限制实验数据中的产物离子,该实验数据被确定为通过碎片化PCC或前体离子产生的实验数据)。例如,解复用可包括使用如本文所述的各种标准来进一步过滤、排除或移除与PCC相关联的碎片离子(例如,标准可使用AR1和AR2值以及本文所述的其他值)以确定最佳识别每种洗脱组分的产物离子谱(例如,确定CPPIS中所包含的洗脱组分的最佳碎片离子,其中碎片离子可用于识别洗脱组分的前体离子)。
在解复用结束时,可例如结合无监督聚类或非监督聚类为洗脱组分或分子构建CPPIS(例如,对于相同的洗脱组分或分子组合SSPPIS)。在无监督聚类的情况下,处理3506e可包括将CPPIS添加到推定的储存库3508c以在3508b中进一步验证。一旦经验证,CPPIS可包含在MIR 3508a中。
在监督聚类的情况下,步骤3506e可包括从储存库3508c中提取目标CPPIS,并且在来自实验数据的SSPPIS的时间线中查询(例如,基于m/z、保留时间和漂移时间(如果使用IMS))。在实验数据中匹配(例如,匹配前体或PCC m/z)目标CPPIS的SSPPIS可被组合成实验CPPIS,然后被添加到储存库3508c中。随后的验证3508b可执行处理以进一步验证实验CPPIS,该实验CPPIS可替换或补充MIR 3508a中的洗脱组分或分子的现有CPPIS。
所执行的实验产生的结果可以空间映射3505的形式(例如,经由从3506c到3505a, 3505b, 3505c, 3505d,然后到调度器3504b的流程路径)从3506c传输回调度器3504b。基于通过3506c反馈到3504b的实验数据,调度器3504b可修改或修订调度或MMA设置,并且还进一步修订参数(例如,可修订碰撞电压或能量、改变MIW等)。在至少一个实施例中,可修订MMA调度和参数以现在识别或旨在在下一次样品进样或运行中产生实验数据的那些先前未被识别的分子(例如,在先前的进样运行或实验中尚未获得实验数据的那些分子)。例如,在第一次运行中,调度器3504b可基于模拟信息(诸如目标3502a中的分子的模拟属性或性质)来确定采集调度和相关联的参数3504a。在第一次运行之后,可获得3502a中的一些第一部分分子的实验数据。在第二次运行中,调度器可选择采集调度和参数3504a,目的是获得不在第一部分中的3502a中的其他分子的实验数据。
数据库搜索3506e可包括如本文所述的监督聚类,其中可从3508c中选择目标洗脱组分的CPPIS以确定目标洗脱组分的CPPIS是否与实验数据的SSPPIS匹配。如果是,则可从储存库3508c获得关于匹配的目标洗脱组分的附加属性,并以校准公式和/或建模参数3502d的形式将其作为输入提供给模拟器3502b(例如,应使用何种碰撞能量、洗脱组分的保留时间是多少、该洗脱组分的不同PCC或前体的漂移时间是多少、该洗脱组分的碎片化模式(前体以及对于每种前体其相关联的碎片离子)是什么)。
在一个实施例中,模拟器3502b可最初用于预测、模拟或建模目标3502a中所有分子的物理和化学性质,诸如通过对所有目标3502a生成模拟的理论碎片模式(例如,每种前体和经由碎片化源自每种前体的相关联的碎片离子)。例如,假定目标3502a具有1000个分子。模拟器3502b最初可产生用于1000个分子的此类模拟属性信息,以确定执行第一次实验运行时所使用的初始MMA调度和参数3504a。现在,第一次实验基于初始MMA调度和参数进行,以采集包括200个这些洗脱分子的属性或性质的实验数据。然后通过第一次实验运行获得的该200个分子的属性可形成现在输入到模拟器中的反馈。然而,模拟器3502b可继续模拟目标组中尚未获得实验数据的剩余800个分子的信息。以类似的方式,模拟器3502b还可利用来自MIR 3508a(3508a至3502a的箭头)的信息进行更新,其中模拟器3502b可使用来自MIR 3508a的输入并且模拟剩余洗脱分子的信息。例如,对于第一洗脱分子,MIR包括属性/物理性质,诸如RT、漂移时间、该洗脱分子的前体谱图和前体的产物离子谱等。然而,对于第二洗脱分子,MIR可不包括任何信息。因此,模拟器可使用并输出来自MIR的第一洗脱分子的信息。然而,随着继续进行第二次洗脱,模拟器将继续输出并使用模拟的属性信息(例如,表示哪种前体预期产生什么产物离子的第二洗脱分子的理论碎片化模式)。在至少一个实施例中,可修订MMA调度(在本文中也称为计划或采集计划)和参数以现在通过下一次样品进样或运行识别目标3502a中之前未被识别的那些分子(例如,修改MMA设置或调度3504b和参数3504a以获得3502a中模拟器仍为其生成模拟属性信息的分子的真实实验数据)。
在以下段落和附图中提供了关于3500中的各种条目和处理步骤的进一步细节。
关于建模3502,精确建模和模拟压力对生物系统的微扰影响的能力需要对所模拟的一个或多个系统有充分的认识和了解。肽的氨基酸的元素组成和线性序列都是已知的,因此可计算出该肽的所有可能的前体和产物离子的m/z和z。这是所有开源和市售肽数据库搜索引擎的一般操作手法。前体可产生的同位素的数量与其元素组成和浓度直接相关。以下段落进一步描述了建模阶段或过程3502的单个组件。
关于有关上述酵母样品的特定实验,可提供目标文件3502a。为了正确地模拟细胞裂解液中的离子在LC-MS工作流程中的反映给定的峰容量的分布情况,输入蛋白质列表必须尽可能按浓度排序。为了实现该目标,例如从诸如互联网上公开可用的来源获得超过100个原始和经处理的酵母细胞裂解物数据集。使用本领域已知并且还在例如Cox、J.和Mann、M. (2008),“MaxQuant enables high peptide identification rates, individualized ppb-range mass accuracies and proteome-wide protein quantification”,Nature biotechnology, 26(12), 1367-1372中所述的Mascot Distiller和MaxQuant处理原始数据文件,该文献以引用方式并入本文。所有的产物离子谱都是按照UniProt酿酒酵母(S. cerevisiae)(2014年7月3日,第6752条)fasta数据库使用如例如在Cox、J.、Neuhauser、N.、Michalski、A.、Scheltema、R. A.、Olsen、J. V.和Mann、M. (2011),“Andromeda: a peptide search engine integrated into the MaxQuant environment”,Journal of proteome research, 10(4), 1794- 1805中所述的本领域已知的Mascot、X! Tandem和Andromeda进行搜索,该文献以引用方式并入本文。对于每个搜索结果,通过将每个评分除以所有评分的总和对蛋白质评分进行归一化。假设蛋白质的浓度是其归一化评分的直接结果,则将结果合并、重新归一化并按降序排列。这构成了有序数据库的构造方式。将酵母有序数据库用作输入(例如,目标3502a),输入到模拟器3502b中。除了有序数据库之外,用户还输入用于柱上载样量的建模参数3502c和校准公式3502d、梯度和IMS校准文件以及用于漂移、色谱和m/z的分辨率。使用Hi3定量策略,柱上载样量分布在模拟蛋白质中,从而建立每个蛋白质的摩尔浓度。Hi3定量策略在本领域中是已知的,诸如在例如Silva、J. C.、Gorenstein、Μ. V.、Li、G. Z.、Vissers、J. P.和Geromanos、S. J. (2006),“Absolute quantification of proteins by LCMSE a virtue of parallel MS acquisition”,Molecular & Cellular Proteomics, 5(1), 144-156中所述,该文献以引用方式并入本文。
参考图36A和图36B,所示出的是进一步示出了可提供给模拟器3502b的不同输入的示例3600和3601。综上所述,元素3600和3601可表示包括在建模参数3502c和校准公式3502d中的采样信息。特别地,表和模型3600和3601示出了模拟器用来估计来自肽、蛋白质或整个蛋白质组的一组输入的前体和产物离子通量的采样表和模型。图A 3606反映了基于肽序列长度的z的分布。图B 3602描绘了考虑到可带电残基(K、R、H)相对于n和c端的定位而应用的调整(%)的表。图C 3604按m/z确定电离顺序(从最高到最低)。每种肽的每种电荷态的m/z被设置在具有限定电离顺序的y轴截距的曲线上。图D 3614中的曲线限定了将多少百分比的肽区域分配给每个z。图E 3616和表1 3608分别示出了每种氨基酸的CCSA和疏水性值。模拟器利用这些值来计算每种肽的保留时间和每种电荷态的CCSA。表2 3612反映了每种二肽键的频率值。将被定义为低能量中的前体离子强度与升高能量中的残余强度之差的残余差异乘以计算值来设定碎片离子强度。分配强度(乘以1000)在同位素上分布。
当被电喷雾进质量分析器时,肽可呈现多种电荷态。图A 3606和图B 3602分别反映了作为肽长度和某些可带电残基的位置的函数的z的分布。就氨基酸组成而言,蛋白质非常相似。图C 3604中反映的曲线分配电离顺序。基于每种肽可呈现的理论充电状态的数量,为其分配一个m/z值或一系列m/z值。每个m/z值落在曲线上的位置反映在其从0到1的等级中,其存在最佳电离。考虑到组成的相似性,每种蛋白质的最佳至最少电离肽的数量是长度的直接函数。图D 3614示出了这些肽的分布情况。假设在组成上相似,占据3614中每个区段的肽的数量也是长度的函数。在这种情况下,蛋白质的肽分布在3614的十个区段中。哪种肽位于哪个区段是其m/z值在图C 3604所示的曲线上所处的位置的函数。简而言之,10kDa(道尔顿)蛋白质将导致每区段有一个肽,由此100kDa蛋白质将导致每区段有十个肽。一旦限定了顺序,为最佳电离肽的强度分配给定的蛋白质摩尔量和所计算或定义的响应因子(cts/mole),而所有其他肽都是通过将最佳电离肽的强度乘以它们位于曲线上的位置来分配。一旦每种前体m/z接收到其强度,则使用同位素建模算法对其进行分布。
物理化学属性、保留时间、漂移时间和碰撞截面积的建模算法在本领域是已知的,例如在Krokhin、Oleg V.和Vic Spicer,“Predicting peptide retention times for proteomics”Current Protocols in Bioinformatics (2010): 13-14;Petritis、Konstantinos等人,“Improved peptide elution time prediction for reversed-phase liquid chromatography-MS by incorporating peptide sequence information”,Analytical chemistry 78.14 (2006): 5026-5039;以及Meek、James L.,“Prediction of peptide retention times in high-pressure liquid chromatography on the basis of amino acid composition”,Proceedings of the National Academy of Sciences 77.3 (1980): 1632-1636;Moruz、Luminita等人,“Chromatographic retention time prediction for post-translationally modified peptides”,Proteomics 12.8 (2012): 1151-1159;Valentine、Stephen J.等人,“Using ion mobility data to improve peptide identification: intrinsic amino acid size parameters”,Journal of proteome research 10.5 (2011): 2318- 2329;以及Knapman、Tom W.等人,“Considerations in experimental and theoretical collision cross-section measurements of small molecules using travelling wave ion mobility spectrometry-mass spectrometry”,International Journal of Mass Spectrometry 298.1 (2010): 17-23,其全部以引用方式并入本文。
图E 3616和表1 3608分别示出了每种氨基酸的碰撞截面积和疏水性指数(HI)值。已知元素组成、线性序列、长度和z,可预测给定柱类型、梯度分布、流速、柱温、气体密度和场强的洗脱时间和漂移时间。模拟器3502b利用这些值并估计建模肽及其各自电荷簇组的洗脱和漂移顺序。实验值和预测值之间的可变性是每个可测量属性的模型被限定程度的函数。
肽碎片化与所提供的仪器平台/几何结构无关。类似的碎片化方法(例如,低能量CID/碰撞室)和仪器在类似的气体压力和碰撞能量下运行。表2 3612示出了模拟器所使用的三个碎片化表中的一者的一部分。每个表反映了氨基酸所有可能的二元对(AA、AC、AD等)的矩阵。类似于有序输入fasta数据库的构建,将每个匹配的产物离子强度归一化为该肽的所有匹配的产物离子的总强度。第一表格反映了400个可能的二元对中的每一者的归一化强度。第二表格反映了每个可能的二元对(序列)的归一化频率,第三表格表示所识别的对的频率。对于每个二元对,在识别出对的频率之间计算比率频率。接下来,将归一化强度比率值除以归一化频率(存在的/检测到的),其结果归一化为所有二元对的总和。使用这三个模型为每种理论产物离子分配一个分数值。通过将其分数值乘以肽的电荷簇组的强度值来计算产物离子强度。然后将分配到的强度分布到适当数量的同位素中。碎片化建模过程更详细的说明可见于例如“Conserved peptide fragmentation as a benchmarking tool for mass spectrometers and a discriminating feature for targeted proteomics”,Molecular & Cellular Proteomics, 13(8), 2056-2071中,该文献以引用方式并入本文。
在至少一个实施例中,MMA整体工作流程3500可完全处于用户控制之下或作为自动化过程运行。示意性工作流程3500可应用于单个样品或迭代地被执行用于技术或生物重复样的递归和/或详尽分析。如上所述,实线箭头和连接器形成了第一路径,其示出了模拟离子通量在构建初始MMA调度设置和参数方面的用途,而形成第二路径的虚线箭头和连接器反映了迭代工作流程,其中预定采集(由调度器3504b生成)的采集时间线是基于前一个进样的离子通量。
在批量分析模式下,采集后处理可使用最高得分肽作为最小二乘方拟合的分子标记来校正进样之间的保留时间和/或漂移时间的任何变化。另外,关于调度器3504b和MMA调度,在一个实施例中,每个窄带和宽带采集的中心m/z在同一个循环中被排除在下一次扫描之外。排除列表是累积性的,从而不断限制每单位时间要缩小对m/z范围的哪些部分的采样。中心m/z的不断变化确保对产物离子谱的差分采集,这在通过解复用算法进行处理时产生选择性不断增加的产物离子谱。一旦低能量扫描的整个m/z域已在多个隔离窗口内被多次采样,重复该过程直到一群生物样品的单一混合物、重复样或成员的所有进样已被耗尽。下文更详细讨论的示例3700中的灰点边界线D1示出了对相同m/z空间的多次采样。这种迭代方法允许为每种洗脱肽产生高度特异性的产物离子谱。包括所有进样中的每个图谱的每种离子的所有测量的物理化学属性。MMA策略在几乎不影响灵敏度的情况下显著增加了产物离子谱的数量和选择性。由此产生的每种产物离子谱的洁净度使得该工作流程成为传统数据库搜索和SIC靶向的理想选择。
关于由调度器3504b确定的循环时间,参考图37。为了保持对无标记、同量异位和同位素标记的样品进行高度精确的AUC定量的能力,在洗脱肽的峰的FWHM上需要至少五个数据点(例如,需要色谱峰的两个半高点之间(诸如图7中的点H1和H2之间)的5个数据点/5个谱图)。为此,用于确定适当的扫描循环时间、采集速度和每个扫描循环的采集次数的起始指标为中值色谱FWHM。调度器3504b可使用构建MMA时间线的算法来执行处理,该算法使用诸如动态范围(例如,表示检测到的离子的信号强度的计数的范围)、检测器的检测范围的测量、仪器响应因子(以计数/摩尔进样)和LOD的输入。响应因子可以是用户定义的或实验确定的,诸如在例如Silva、J. C.、Gorenstein、Μ. V.、Li、G. Z.、Vissers、J. P.和Geromanos、S. J. (2006),“Absolute quantification of proteins by LCMSE a virtue of parallel MS acquisition”,Molecular & Cellular Proteomics, 5(1), 144- 156中所述的,该文献以引用方式并入本文。
在一个示例性实施例中,元素3710总结了用于确定扫描循环时间的信息。采集速度是LOD(将在最低期望离子上生成可用信号的MS累积时间)的5倍,但勿超过最快扫描速率(50ms)。在手动模式下,包括扫描速度、采集时间、响应因子和动态范围的所有参数都可由用户定义。每个扫描循环的采集次数使用计算的采集速度、仪器扫描间的延迟时间和参考(锁定)质量的采集频率来确定。关于确定扫描循环时间,从实验运行中已知中值峰宽以及因此中值FWHM。在该示例3710中,假定FWHM为0.18分钟或10.8秒。在如本文所述的至少一个实施例中,希望在10.8秒间隔内有最少5个点并且因此5个谱图或扫描。因此,可使用2.16秒/扫描循环的最大扫描循环时间来确保最小值5。在该特定示例中,具有约6个循环/FWMH的MM工作流程3500(例如,10.8/6=1.8秒)使用1.86秒的循环时间。
参考3720,对于1.86秒的第一扫描循环,一个实施例可执行17次数据采集或实验,并且因此在不损失灵敏度的情况下(具有100毫秒采集时间)在单个峰值上执行17*6=102次实验或采集。17次数据采集包括1次低能量扫描A1、2次宽带扫描B1和14次窄带扫描C1。元素A1表示单次低能量(LE)扫描,其中允许在300-1950 m/z范围内的所有前体离子通过。就宽带MIW B1和窄带MIW C1而言,可利用不同的MIW来选择前体离子的碎片化。可选择两个宽带MIW BI,每个具有在50和500m/z之间的范围或宽度。可选择十四个窄带MIW C1,每个具有在1和50m/z之间的范围或宽度。通常,可根据在特定的m/z范围内的前体离子数量的密度来选择不同的MIW-中等宽度或窄宽度。例如,在具有较低离子通量的m/z范围A1的区域中,可使用中等MIW。在具有较高/最高离子通量的m/z范围A1的区域中,可使用窄带MIW。因此,较窄的MIW可用在具有较高/最高离子通量的m/z范围的部分中以使离子干扰最小化,并且在空间上分辨或分离具有较高/最高离子通量的此类区域中的离子(例如,从前体生成的片段)。在一个实施例中,在随后的扫描循环中,可选择2个宽的MIW和14个窄的MIW,每个具有与先前扫描循环不同的中心点,以便移位随后扫描中的与每个MIW相关联的m/z子范围。可基于对应于一些连续数值的m/z值的任何限定的m/z区间内的所需最大数量的前体离子(例如,每m/z区间不超过10个前体离子)来确定每个MIW的尺寸。这在下文参考图38进一步进行了更详细地描述,该图示出了来自前一个进样的各种分布。
关于确定MIW,在任何产物离子谱中可被占据的m/z足够空间的量是有限的。因此,能够以最小嵌合干扰填充该空间的产物离子的数量是每单位时间碰撞室中存在的前体种群及其聚集产物离子的函数。在图38的示例3750中,所示出的是示出了空间映射3505的一个示例,该空间映射可由实验数据生成并用于向MMA调度器3504b提供输入,以便确定在根据本文技术的一个实施例中的循环时间的特定扫描中使用的MIW。图A 3752表示离子通量热图,其示出了以二维m/z与tr区段方式分组的前体离子。每个m/z与tr区段为10Th宽和0.2min宽。图B 3754反映了m/z相对于保留时间的分布。图C 3756反映了m/z相对于漂移时间的分布。图D 3758反映了保留时间tr相对于漂移时间td的分布。3752中的具有最高离子通量的m/z范围的密集填充部分以及3754和3756中的边界线β和β'之间的密集填充m/z范围由“*”表示。因此,例如,3754和3756中的边界线β和β'之间的m/z范围可表示其中使用窄的MIW的m/z范围,而在边界线β'上方和β'下方(以边界线β和β'为界的区域之外)的m/z范围中使用宽的MIW。
如3710所示,在100毫秒的扫描速度、10毫秒的扫描间延迟时间的情况下,每个扫描循环可包含大约108个图谱,每个图谱被视为单独的实验。在图37的3720中示出了这些图谱在1.86秒的中值色谱FWHM上的分布情况的一个示例。在3720中,每个扫描循环的第一次采集是低能量前体离子扫描,随后是在上下边界线β和β'之外的具有关联m/z范围的两个宽带高能量扫描BI(如图B 3754所反映)。宽带MIW采集的宽度可由每个漂移区段限制十个前体离子来限定。作为关于窄带MIW的第一种情况,调度器对于每个扫描循环选择前体离子的计算数量,从而反映边界线β和β'内的最高归一化强度。此类前体离子的m/z值可用于确定窄带MIW的起始m/z范围。使用选定的m/z值,每个窄带采集的宽度可类似地用每个漂移区段最多10个前体离子来计算。以这种方式,如本文其他地方所述,与每个MIW相关联的m/z范围和宽度可随目标而变化,该目标为基于每个漂移时间区段包含最多10个前体离子来调整MIW宽度。作为变型,与宽带和/或窄带MIW相关联的质量隔离宽度也可以是用户定义的。只要MIW的中心前体m/z是唯一的,就可在相同的扫描周期内重新采样在时间、漂移和m/z方面都相同的部分。通过用中值色谱FWHM来限定扫描循环数,在单次扫描循环中每个前体就有机会在其洗脱过程中被多次取样。重复该过程,直到在当前扫描循环中所有前体离子已在窄带或宽带MIW中被采样。调度器保持追踪多维空间的哪些区域尚未被精确地采样。在批量采集模式下运行,中心m/z值的累计排除确保了在图B 3754、图C 3756和图D 3758所示的边界线β和β'内的m/z、时间和漂移空间在该过程重复之前可被完全采样(例如,获得整个有界多维空间的升高能量扫描数据)。
上述确保在再次对多维有界区域的限定范围(例如,由图B 3754、图C 3756和图D 3758中的边界线β和β'表示)重复采样之前已对所限定的范围进行了采样的处理通常可发生在一次进样或运行中,或者可跨越多次进样或运行。在跨越多次进样的情况下,可在每次进样或运行中使用相同的样品或不同的样品,只要使用的样品包括用于进行分析的相同或共同的一组分子(例如,所有样品包括如在目标3502a中定义的分子)。当跨越多次进样时,调度器可使用与第一个进样或运行有关的信息(诸如实验数据(例如,离子通量、被覆盖或被采样的m/z范围等))来自动确定下一个第二进样或运行的调度(例如,下一个第二进样和运行的每个扫描和扫描循环的宽和/或窄MIW的m/z范围)以确保对整个多维有界区域的完整采样。更一般地,前文示出了可跨域多个进样、同一进样的循环和扫描循环等的工作流程处理的迭代性质和反馈。通常向调度器3504b提供关于多维有界区域的哪些(多个)部分在当前时间点已被采样的信息,使得调度器可执行处理以对多维有界区域的尚未被采样的剩余部分进行采样(例如,在当前时间点之后确定质谱仪和/或离子淌度谱仪的采样和操作的调度,以确保在对多维有界区域可能的重复采样之前整个多维有界区域已被采样)。如本文所述,在进样之间向调度器提供上文所述的反馈的信息可包括实验数据(诸如离子通量)和其他数据(例如,参见图38的示例3750)。
通常,宽带和窄带MIW的宽度可通过算法确定,或者可以是用户定义的,如上所述。在了解先前采集的时间线的情况下,调度器设置新的采集时间线,以便排除每个宽带和窄带采集的中心m/z。可利用用户定义的色谱FWHM或先前实验的中值来执行MMA时间线的构建,其中在该示例中,调度器将扫描循环的次数设为6。在本示例中的自动模式下,采集顺序被设置为执行一次低能量全扫描、两次宽带(50Th<MIW<500Th)扫描和n次窄带(1Th<MIW<50Th)扫描,其中n是用户定义或算法确定的LOD(摩尔)的函数。调度器需要扫描间延迟时间和响应因子(cts/mole)作为最小输入。响应因子(RF)可从参考质量或用户定义的质量来计算。除了扫描间延迟时间之外,LOD/RF算法还确定采集时间。将扫描循环时间除以采集时间设置采集次数,其中窄带采集的次数(n)等于循环中扫描的总次数减三。
在自动模式下操作时,除了设置循环时间、采集速度、采集次数和MIW宽度之外,调度器3504b还监测并且(如果需要)可调整对每个MIW所应用的碰撞能量。与MMA工作流程中的许多参数3504a一样,碰撞能量表可以是用户定义的,或者可使用来自前一个进样的碎片化效率数据来优化残余的表。如本文其他地方关于数据处理3506b所述,可为每种洗脱肽计算碎片化效率。在二维数据(时间和m/z)中,无论z如何,来自相同肽的前体离子同时碎片化。为了有效地碎片化,对于每个z,碰撞能量在采集时间内在最佳值之间切换。在三维数据中,前体离子被m/z和z分离,由此应用高效碎片化的最佳碰撞能量作为漂移时间的函数。调度器计算来自输入数据的一系列碎片化曲线(m/z相对于z)以优化残余的碰撞能量表。类似于前体离子和质量隔离窗口的动态选择和排除,在批量分析模式下,该过程的迭代性质提供了对碰撞能量表的不断优化。
现在将更详细地描述数据处理和分析阶段3506。与本文的讨论一致,执行单次扫描处理。考虑到3700中举例说明的示例MMA情境(例如色谱分离空间为60min,循环时间为1.86s,采集时间为100ms,并且扫描延迟时间为10ms),采集了约2,000个低能量HDMSe IM-DIA所有离子扫描或光谱,采集了约4,000个不同的质量隔离宽度宽带(50 Th < MIW < 500 Th)扫描或光谱,并且收集了约24,000个窄带(1 Th < MIW < 50 Th)扫描或光谱。3506的MMA数据处理算法将每次扫描视为其自身的独立实验。处理从访问来自参比(锁定)质量通道的信息开始。对该通道的分析提供了两个重要的信息;也就是oa-TOF分析仪的质量分离度,以及完整洗脱时间上m/z校准的稳定性。按时间顺序对采集通道逐扫描进行处理。对于每次扫描,使用单次扫描中心化算法将m/z (2D)向量和m/z漂移(3D)向量中心化。在中心化过程中,针对每个离子在所有维度(tr、td和m/z)上计算FWHM。这些值与参比质量数据一起用于计算纯度分数,该纯度分数是用来确定离子面积是唯一的、还是由于干扰(例如,其离子信号或面积受到另一个干扰离子的影响)是复合面积的度量。
数据处理3506b可以包括使用与在同一次扫描中形成离子的候选同位素簇(例如由此形成PCC)相关的信息(诸如包括下面描述的图39和图40的信息)来执行处理、将电荷z分配给PCC,以及校正离子干扰。可以结合本文所述的其他处理来执行用于形成PCC并如下所述为其分配电荷态的此类技术。例如,形成PCC并为其分配电荷态可以结合本文别处描述的无监督/非监督聚类来执行。在至少一个实施例中,一旦已经计算了前体离子的离子纯度分数以及中心化的m/z值、漂移值和面积值,每个前体离子的m/z值就被分解成两个不同的值,即标称整数m/z和分数m/z。例如,对于m/z为680.33的单次扫描中的前体离子,标称m/z=680,并且分数m/z=0.33。
参考图39,示出了举例说明不同离子电荷态的标称m/z值相对于分数m/z值的图的例子。在该例子3850中,基于特定仪器的分离能力,可能最多有6种可能的电荷态,并且3850中的图形举例说明了离子的标称m/z相对于分数m/z的分布。用于填充3850的信息可以使用以任何合适的方式确定的已知离子数据来构造。如通过例子3850所见,形成了电荷向量,其包括对于特定电荷态唯一的向量以及其中相同的m/z可以取多个z值的向量。例如,以下可以是对于特定电荷态唯一的电荷态向量:在线L1和线L2之间主要包括3+(例如,z=3)电荷态离子,在线L2和线L3之间主要包括4+电荷态离子,在线L3和线L4之间主要包括5+电荷态离子,在线L5和线L6之间主要包括1+电荷态离子,在线L6和线L7之间主要包括4+电荷态离子,在线L7和线L8之间主要包括3+电荷态离子,在线L10和线L11之间主要包括5+电荷态离子,在线L11和线L12之间主要包括3+电荷态离子,并且在线L12和线L13之间主要包括4+电荷态离子。以下可以表征为包括下述线之间的多个电荷态的多线道电荷态向量:线L4和线L5之间(例如,包括多个电荷态离子,诸如1+、2+、3+和4+),以及线L9和线L10之间(例如,包括多个电荷态离子诸如2+和4+)。在额外的IMS漂移时间维度可用的情况下,可以类似地形成漂移时间相对于分数m/z部分的图,其中该图举例说明了唯一的电荷态向量和多线道电荷态向量两者。
以上是可以包括在分数m/z空间内提供不同分离视图的唯一电荷态向量和多线道电荷态向量两者的分布的例子。由于m/z的模态涉及电荷z,故可以观察到m/z的模态,由此分数m/z的分布可以被表征为关于某些电荷态的多模态。例如,z = 4的离子可以与z = 2的离子相互交错,而z = 6的离子可以与z = 3的离子相互交错。然而,一些分数m/z值对于给定的电荷态是唯一的。电荷态z = 4的离子有一些分数m/z值对于电荷态z = 2的离子是无法存在/不存在的。关于电荷态z = 6和z = 3也是如此。此外,某些成对电荷态如2+和4+、或3+和6+都是多模态的,并且还反映了谐波级数的特性。以z = 3为例,同位素之间的预期分数m/z差将等于0/3、1/3和2/3。谐波电荷态如2+和4+、或3+和6+的分数m/z总会存在相互交错。然而,两个2+同位素系列不能相互交错以模拟4+系列的同位素分布。两个3+同位素系列也不能模拟6+系列的同位素分布。将z正确地分配给映射到多线道电荷态向量之一的离子可以被确定为模运算的函数,其中z=模量。在至少一个实施例中,信息诸如基于分数m/z的一个或多个分布图可以提供电荷态分离的一些指示,由此与一个电荷态唯一地相关联的电荷态向量连同与多个电荷态相关联的多线道电荷态向量。此类图(例如,诸如图39中所示)可以用于对每个离子执行初始或候选电荷态分配。在一些情况下,初始电荷态分配可以是包括多个可能的电荷态的组。应该指出的是,可以使用添加额外的IMS漂移时间维度来获得例如漂移时间相对于分数m/z的附加图,从而允许改善离子分离成不同的电荷态分组。如果可能,继这样的初始电荷态分配之后,可以使用如下所述的链接操作执行额外的处理,以形成候选同位素簇或PCC。
为了进一步举例说明,现在参考图40,其包括可以在根据本文技术的一个实施例中使用的表。表3800反映了模运算,其中模量等于z,并且模数等于分数m/z在零处转折并且重新开始之前一系列同位素的最大数量。每个单元格中表示的分数值反映理论同位素/z或模量的比率。表3800中的信息可以用于将同位素链接在一起形成PCC,如现在将要描述的那样。表3800包括针对每种可能的电荷态的行和针对每种可能的同位素的列。在该例子中存在6个可能的电荷态,其中模量为z,如3804中的行值1至6所表示。此外,取决于电荷态,可以包括多达6个同位素。每个列对应于可能的同位素A0至A5中特定的一个同位素,其中“An”更一般地表示特定的同位素,“n”为非负整数,并且特定同位素的“n”表示表3800中与该特定同位素相关联的列。对应于不同同位素的“n”的值表示模数3802。表中的条目表示关于特定同位素A1至A5在单次扫描内相对于同位素A0的m/z的步长或Δ距离。表中的每个条目可以由一对值(X,Y)标识,其中X表示行标识符“z”或模量,而Y表示与特定An同位素相关联的列标识符“n”。表中条目的值等于该条目的同位素数量“n”(例如,Y)除以该条目的电荷态(例如,X)。更一般地讲,表中每个条目的值=Y/X,其中条目由刚描述过的(X,Y)标识。
参考行3804d,使用z= 3,同位素之间的预期分数m/z差等于0/3、1/3或0.33,以及2/3或0.67。参考行3804a,使用z= 6,同位素之间的预期分数m/z差等于0/6、1/6或0.167、2/6或0.33、3/6或0.5、4/6或0.667,以及5/6或0.833。因此,谐波电荷态如3+和6+的分数m/z存在相互交错,原因在于电荷态3的两个连续同位素之间的Δm/z是电荷态6的两个连续同位素之间的Δm/z的倍数(例如,电荷态3的任何两个连续同位素诸如A0和A1、或A1和A2之间的Δm/z 0.333是电荷态6的任何两个连续同位素诸如A0和A1之间的Δm/z 0.167的倍数(两倍)。然而,表中存在不发生这种相互交错的特定条目,由此与A0同位素(例如,存储在表条目中的值)的特定Δm/z距离仅出现在该表的单个条目中。例如,表3800中由3803a至3803e表示的条目是该表中的唯一条目,因此表示当电荷z可以被分配给离子时的情况。
另外,表3800可以用于将同一次扫描中的不同同位素链接或连接到一起以形成候选PCC,如现在将要描述的那样。处理开始于在低能量扫描中选择最低m/z离子(例如,扫描中的最低m/z前体离子)以确保初始关联为A0同位素。在知道所有可能的电荷态的情况下,处理于是开始于最高理论电荷态,以处理2+离子和4+离子、或3+离子和6+离子的谐波模态效应。例如,处理从列1 3802a开始,并且按照从最高电荷态z=6(行1)到最低电荷态z=1(行6)的先后顺序向下遍历该列。对于该列中具有值D(表示Δm/z)的每个条目,查询扫描中的m/z值以确定该扫描中是否存在等于A0的m/z + D的总和的m/z。例如,假定扫描S1中的A0具有为600.0的m/z。对于条目3803a=0.167,扫描S1中是否存在等于600.167(例如,600.0 + 0.167)的m/z如果存在,则该匹配的m/z被假定为A1同位素。如本文别处所述,此类m/z匹配可以在某个指定水平的容差或可接受误差内进行。然后使用为0.167的相同Δm/z继续进行同位素链接,以将其他同位素链接在一起。搜索扫描S1继续定位同一PCC的剩余同位素,其中定位的每个连续对的离子/同位素之间的距离具有为0.167的m/z差或距离。继续讨论上面的例子,在扫描S1中,处理可以定位具有600.333、600.50、600.667和600.833的m/z值的4个额外的m/z匹配离子。结合上述例子,由于推定的A1同位素的m/z定位在与A0的m/z相距0.167的m/z距离(例如,对于电荷态6,0.167定位在行1中),所以将6个离子确定为具有6+电荷态的候选PCC。当扫描中没有另外的离子定位在与最近的匹配同位素的m/z相距0.167的m/z距离时,对当前PCC的链接停止。例如,没有离子定位在m/z为601的扫描S1中。
作为上述的变型形式,假定扫描S1中不存在等于600.167的m/z。在这种情况下,继续向下处理列3802a,以使用如针对下一个最高电荷态5的行3804b中所指定的Δm/z=0.200。进行相同的查询,以确定扫描中是否存在等于600.200(即A0的m/z 600加上0.200的总和)的m/z。如果存在,则推定匹配的m/z是A1同位素的匹配m/z,并且进一步使用为0.200的Δm/z来链接到如上所述同一PCC的其他后续同位素,其中定位的每个连续对的离子/同位素之间的距离具有为0.200的m/z差或距离。在这种情况下,推定PCC具有为5的电荷态,并且继续链接以定位额外的离子,直到扫描中没有另外的离子定位于在与最近的匹配同位素的m/z相距0.200的m/z距离。如果扫描S1中不存在等于600.20的m/z,则处理进一步继续以循序遍历列3803a,并且对行3804c中的下一个最高电荷态4使用下一个Δm/z值=0.250。
前述向下遍历列3803(从最高到最低电荷态)继续进行,直到:1)定位m/z等于600加上列3803a中的Δm/z值之一的匹配离子,或者2)该列中的所有条目都已经被处理并且没有定位到匹配离子。一旦3802a中的所有条目都已经在考虑m/z为600的候选A0时得到处理,则低能量扫描中的下一个最低m/z也可以被相似地处理。例如,假定扫描S1中的下一个最低m/z为602.5,则可以采用类似于如上文针对m/z=600所述的方式,基于推定m/z=602.5的离子为A0同位素,针对m/z=602.5的该离子执行处理,以试图形成同位素簇或PCC。
参见图41,示出了根据本文的技术可以在一个实施例中执行的处理步骤的流程图。流程图3800总结了根据本文的技术在一个实施例中结合使用表3800执行链接以形成同位素的候选PCC的上述处理。在步骤3902中,选择当前扫描中的离子,其中所选择的离子在该扫描中具有最低的m/z。该扫描为前体离子的低能量扫描。所选择的离子为用于链接到其他离子以形成PCC的候选A0同位素。令X1等于在该扫描的所有离子中具有最低m/z的所选择离子的m/z。在步骤3904中,向MAX分配最大可能电荷态,诸如6。在步骤3906中,向MAX分配当前电荷态。在步骤3908中,Δ与当前电荷态的A0和A1之间的理论m/z距离相关联。更一般地讲,如上所述,Δ表示同位素簇中具有等于当前电荷态的电荷态的每对连续同位素之间的m/z距离。Δ表示表3800的条目的值。例如,在当前电荷态=6时,基于条目3803a的Δ被设定为0.167。从步骤3908开始,对循环中的当前Δ执行处理。
在步骤3910中,确定在当前扫描中是否存在等于X1 + Δ的m/z。如果步骤3910评估为是,则控制前进到步骤3912,其中匹配的m/z被推定为链中下一个同位素的m/z。步骤3912包括对扫描中的任何后续离子执行链接,其中每个这样的后续离子都具有与先前匹配的m/z相差另一个Δ的m/z。如果没有定位到m/z超过最后一个匹配的m/z Δ的离子,则链接停止。经由链接形成的PCC或同位素簇被分配等于当前电荷态的电荷态。如果步骤3910评估为否,则控制前进到步骤3914,其中确定是否已针对所有电荷态完成处理。如果是,则处理停止。否则,如果步骤3914评估为否,则控制前进到步骤3916,其中当前电荷态递减1,并且处理以步骤3908使用表3800中的下一个条目(诸如列3802a中的下一个条目)继续进行。
应该指出的是,用于形成候选PCC并且为其分配电荷态的上述处理可以针对所选择的电荷态执行关于Δm/z值的处理。例如,在执行流程图3900的处理之前,可能已经为步骤3902中选择的候选A0离子确定了一个或多个可能的电荷态的子集。例如,使用其他手段诸如图39的图形3850和/或其他信息,可以进一步减少6个可能电荷态的数量。例如,候选A0离子可以具有将其置于线L9和线L10之间的多线道电荷向量之一中的m/z,并且可以被分配为2+或4+的可能电荷态。在这种情况下,可以减少流程图3900的处理,由此仅需要评估这些电荷态的0.250和0.50的Δm/z值。
在已经构造好候选PCC之后,可以执行处理来验证该PCC。例如,该PCC中的每个同位素的面积或离子信号强度由同位素模型来验证和/或调整。同位素模型使用平均值(averagine)的元素组成来计算理论同位素分布(例如,离子信号面积、强度或计数的分布)和高于理论肽的m/z和z的LOD的预测同位素数量两者。产生平均值的同位素模型在本领域中是已知的,并且描述于例如Valkenborg, D.、Jansen, I.、和Burzykowski, T. (2008),“A model-based method for the prediction of the isotopic distribution of peptides”,Journal of the American Society for Mass Spectrometry,19(5), 703-712中,该文献以引用方式并入本文。
为了进一步举例说明,参考图42。每个离子可以被分配一系列测量或计算的属性。在至少一个实施例中,这些属性可以包括:m/z、面积(例如,离子强度的度量)、一种或多种理论电荷态以及在三维数据m/z和漂移的情况下,m/z的一个或多个纯度分数。参见例子4000,可以如上文结合图40和图41描述的那样执行处理,其中链接处理以从二维扫描中选择最低m/z离子开始,从而确保初始关联为A0。4010中具有最低m/z的离子为548.9784。例如,前一次处理可能已经为离子初始分配可能的3+或6+电荷态。从最高电荷态6+开始,将0.1667 Th (1/z)(例如,表条目3803a)添加到最低m/z 548.9784,由此针对该扫描的完整离子列表查询上述总和以进行匹配。在该例子中,在4010举例说明的扫描中未找到匹配,因而确定不存在6+伴侣Ai离子。处理然后考虑下一个理论电荷态3+,其中将0.333 Th (Mz)(例如,来自条目3805)添加到最低m/z 548.9784,由此针对该扫描的完整离子列表查询上述总和以进行匹配。在这种情况下,在549.3058处发现了匹配的m/z离子,其中前述549.3058处的m/z为候选的Ai同位素。在至少一个实施例中,质量匹配容差(用于确定匹配的m/z值)可以根据之前的参比质量校准被自动设定为所测得的质量精度的±3倍。
在该例子中,m/z=549.3058的A1同位素可以具有比预期低的离子纯度分数(例如,相对于其他分数或阈值水平可能更低)。此外,可能存在质量误差。质量误差在本文以下段落中进行描述。上述质量误差可以被解释为提示存在比A1同位素的预测值549.3117 Th稍低的m/z的干扰离子(为所测得的质量精度的±3倍)。重复对额外同位素A2和A3的搜索,同位素关系的数量扩大到总共四个(例如,A0 m/z= 548.9784,A1 m/z=549,3058,A2 m/z=550.0,A4 m/z=5503090)。由于关联2和关联3之间、以及关联3和关联4之间的质量误差与之前的校准的质量误差成比例,所以怀疑的干扰可以得到证实或验证。
图42的4010中的虚线曲线4012举例说明了3+电荷簇的预测同位素分布。计算的同位素模型与4010的实验数据相匹配。被链接离子的强度反映了唯一的z或验证的z分配和高纯度分数,故可以用作锚点以校正与A1同位素类似的复合离子面积。例如,如果被链接离子之一(表示刚形成的候选PCC的同位素)具有高纯度分数并且被包括在将该离子映射到单一电荷态的唯一电荷态向量中,则该离子的性质(例如,强度、质量、电荷态)可以用作同位素建模的锚点,以对PCC的其他同位素进行确定、预测或建模,并且还对PC中的此类其他同位素的属性进行建模。例如,m/z=549.646的A2离子可以是这样的锚点离子,由此可以使用A2的属性(例如,m/z、强度或面积、保留时间、漂移时间(如果有))来对关于同一PCC的A1离子的预期理论属性(例如,信号强度或面积)进行建模。m/z=549.3058的实验A1离子的此类建模属性可以与所述建模属性进行比较以对实验数据进行校正或调整,也可以用来检测离子干扰。例如,可以使用A1离子的建模强度来将A1的实验数据强度从4010中举例说明的值校正或调整为4020中举例说明的结果。此外,由4012举例说明的模型同位素分布指出A1离子处的干扰,并且可以相对于实验数据采取进一步的校正措施。为了克服真实元素组成与用于对同位素分布进行建模的平均值的元素组成之间的任何变化,在执行任何校正措施诸如创建“虚拟离子”之前,可以允许处理存在20%的变化。虚拟离子可以被分配剩余离子面积,以及在实验数据扫描中被分配给相关联母体离子的所有其他属性。例如,如4020中举例说明,可以为m/z=549.3058的A1离子创建具有经校正的离子面积的虚拟离子,从而允许m/z=549.3058的相同离子被准确地分配为在考虑中的当前PCC的3+ A1同位素,并且还与电荷态=4+且具有m/z =549.0398的A0离子的另一个第二PCC相关联。因此,元素4010和4020举例说明了如何校正m/z=549.3058的非相容(例如,低IPS、高面积)Al同位素的面积并且创建“虚拟”离子。虚拟离子可以结合后续链接处理使用,执行后续链接处理是为了创建其他候选PCC,诸如如上所述使用m/z=549.3058作为A0离子且具有电荷态4的另一个PCC。
在如上所述处理低能量前体离子扫描以形成具有分配的电荷态的PCC之后,可以基于这些PCC的m/z值、三维数据(例如,包括IMS)、漂移时间,跨时间将这些PCC加以组合。一般来说,这可以被表征为以比如上所述形成各个PCC更高的级别执行的另一种类型的链接或关联。现在,执行处理以组合各自在不同扫描中的各个PCC,以形成色谱峰,也称为单个PCC的洗脱轮廓或包络(例如,形成同一PCC随时间推移的峰或包络,诸如图7中举例说明)。
为了进一步举例说明,现在参考图43,其中小图片A 4110和C 4120举例说明了执行处理以通过PCC的m/z值跨时间组合PCC,因此在不同的时间点跟踪同一PCC以形成该PCC的洗脱轮廓或包络。在至少一个实施例中,用于每个PCC的m/z可以是A0同位素的m/z。小图片A 4110举例说明了在实验数据中的不同扫描时间处具有第一m/z的第一PCC的绘图,而小图片C 4120举例说明了在实验数据中的不同扫描时间处具有第二m/z的第二不同PCC的绘图。小图片A 4110和C 4120是每个PCC的强度相对于扫描时间的图形显示。在4110中,对于第一个被跟踪的PCC,元素4111a E1表示顶点(例如,图7的点H),元素4111b-c E2和E3表示峰半高点(例如,图7的H1和H2),并且元素4111d-e E4和E5表示峰基线点(例如,在PCC的峰轮廓被确定为开始和结束的位置)。在4120中,对于第二个被跟踪的PCC,元素4121a F1表示顶点(例如,图7的点H),元素4121b-c F2和F3表示峰半高点(例如,图7的H1和H2),并且元素4121d-e F4和F5表示峰基线点(例如,在PCC的峰轮廓被确定为开始和结束的位置)。
另外,对于4110和4120的两个被跟踪的PCC,可以确定相关联的误差图。元素4130举例说明了4110中跨时间跟踪或链接的第一PCC的第一误差图。元素4140举例说明了4120中跨时间跟踪或链接的第二PCC的第二误差图。在4130和4140中,误差是以百万分率(ppm)计的m/z误差。该m/z (ppm)误差可以通过将之前的A0m/z值与链中的下一个关联PCC的值进行比较来计算。因此,对于图4110中的第一个点Pn和第二个点Pn+1,Pn+1的质量误差或m/z误差表示点Pn和Pn+1之间的m/z值增量或差值,其中Pn是用于形成紧靠Pn+1之前的峰的点(例如,质量误差Pn+1 = m/z Pn+1 - m/z Pn)。在4130和4140中,下边界线α和上边界线α’反映来自前一次锁定质量校准的计算的质量精度,其在该例子中为+/-3ppm(例如,α在- 3ppm处,而α’在+ 3ppm处)。在4130中,G1 4131a表示峰或顶点E1 4111a的质量误差,G2 4131b表示半高点E2 4111b的质量误差,并且G3 4131c表示半高点E3 4111c的质量误差。在4140中,K1 4141a表示峰或顶点F1 4121a的质量误差,K2 4141b表示半高点F2 4121b的质量误差,并且K3 4141c表示半高点F3 4121c的质量误差。
4110和4120之间的FWHM的视觉比较示出,4120中的点的曲线或轮廓比4110的点所形成的曲线或轮廓宽得多,这表明4120中可能存在干涉。通过分析,可以基于小图片D 4140中的点K1 4141b和K2 4141a之间的质量误差的信息来验证4120中的干涉。具体而言,在第一时间点处的点K2 4141b表示测得的质量误差与可接受的质量误差范围(由边界α和α’表示)的显著偏差,从而表示干扰。后续的时间点诸如K1 4141a和K3 4141c表示在可接受的质量误差范围内的质量误差,从而表明一个或多个干扰离子的干扰继续存在。所以,K2 4141b之后的每个点或扫描可以被确定为具有干扰。因此,洗脱峰4120实际上是多个不同PCC(例如,重叠产生4120的组合洗脱轮廓的两个或更多个前体离子)的离子强度的复合峰或集合峰,由此这样的干扰开始于F2 4121b,并且在4120中的后续点处在扫描的剩余部分继续存在。如果情况是从扫描时间诸如65.4开始不再发生干扰,那么在扫描时间65.4处将检测到对应的负质量误差,其可以表征为由K2 4141b表示的+12ppm质量误差的互补误差或反向误差。换句话说,如果从扫描时间65.4向前不再发生干扰,则在扫描时间65.4处,将存在大约-12ppm的质量误差值。
应该指出的是,对于41110中的点的任何扫描或光谱可能都无法确定干扰,原因在于此类扫描或光谱的质量误差都不超过可接受的质量误差范围。
作为与干扰有关的另一个例子,参考图44的4200。例子4200包括元素4202,该元素示出了彼此干扰的两个不同PCC的两个色谱峰C1 4210和C2 4220。元素4202示出了强度相对于扫描时间的关系。实际看到的复合峰或结果峰C3 4222可能是4210和4220的总和组合。一个目标是检测观察到的复合峰C3 4222实际上是由多个离子诸如4210和4220贡献而成的这一事实,然后试图将复合峰C3去卷积或分解成其组分诸如4210和4220。在第一点或扫描时间PI处,可以确定在可接受的质量误差范围之外的第一质量误差,从而表示对干扰的扫描开始。以类似的方式,后续可以在第二时间点P2处获得下一次出现的第二质量误差,其中第二质量误差在可接受的质量误差范围之外,从而表示在第一点P1处检测到的干扰结束。上述第一点P1和第二点P2之间的点的质量误差可以在可接受的质量误差范围内。元素4204示出了质量误差相对于扫描时间的关系,其表示可以针对4202中不同点处的对应扫描获得的质量误差值。具体而言,X1 4204a和X2 4204b可以分别表示在点P1和P2处超过可接受的质量误差范围的质量误差。4204的剩余误差值都可以在可接受的质量误差范围内。以这种方式,X1和X2可以被用作表示可能的干扰边界的点。在怀疑有干扰的时间处进行的扫描可能被排除在与为被跟踪的前体离子或PCC形成CPPIS相关的考虑之外。作为替代,可以采取措施来校正或进一步完善从干扰扫描的实验数据提取的信息,如下文更详细地描述。
在该例子4200中,一旦检测到超过可接受的质量误差范围的质量误差X1和X2,就可以执行进一步的处理。由于X1处的质量误差为10ppm并且X2处的质量误差为-10ppm,所以可以确定干扰在扫描时间P1处开始并且在扫描时间P2处结束。当选择用于包含在CPPIS中的扫描或光谱时,一个实施例可以选择排除干扰扫描。作为替代,一个实施例可以采取另一种措施,诸如通过检查碎片化模式。具体而言,在从P1到P2发生干扰时的扫描中的碎片离子可能源自多个干扰离子中的任一个。然而,在P1之前或在P2之后的扫描中出现、但不在从P1到P2(包括端点)的扫描中出现的碎片离子frag1可以被确定为源自被跟踪的前体离子或PCC。以类似的方式,对于从P1到P2(包括端点)的干扰扫描是唯一的碎片离子frag2(例如,frag2出现在从P1到P2(包括端点),而不是在P1之前也不是在P2之后的一次或多次扫描中)可以被确定为源自干扰前体离子,而不是源自被跟踪的前体离子或PCC。
一个实施例可以进一步排除与CPPIS形成结合使用的扫描或光谱,以及基于检测到的平均离子峰宽W1的进一步分析。例如,一个实施例可以排除包括在检测到的峰的拖尾左端和右端中的扫描。在至少一个实施例中,只有在平均峰宽W1+/-两个标准偏差内的扫描才可以用于CPPIS形成。
在至少一个实施例中,峰的左右两个半高点之间的至少两次扫描或两个光谱可以用于形成被跟踪的PCC或前体离子的CPPIS。在一个替代实施例中,可以仅选择左右两个半高点之间的单次扫描或单个光谱。所选择的一次或多次特定扫描(以及因此用于形成相关联前体离子的CPPIS的此类一次或多次所选择扫描的特定碎片离子或产物离子)可以根据如本文所述用于排除和/或完善基于实验数据的信息的一个或多个标准。例如,一个实施例可以选择排除怀疑有干扰的任何扫描,其中这种干扰可以使用超出可接受的质量误差范围的一个或多个质量误差来确定。一个实施例可以选择用于形成CPPIS的扫描,其中该扫描位于左右两个半高点之间,并且其中被跟踪的PCC或前体离子在此类点之间具有所有扫描的最大强度。一个实施例可以选择用于形成CPPIS的扫描,其中该扫描位于左右两个半高点之间,并且其中被跟踪的PCC或前体离子在此类点之间具有所有扫描的最大离子电流。扫描中离子的离子电流可以定义为该离子相对于该扫描中所有离子的强度总和的相对强度。因此,其中前体离子具有最大离子电流的扫描是其中前体离子相对于该扫描中所有离子的总强度具有最大强度的扫描。例如,在扫描S1中,前体离子prec1可以具有强度10,并且该扫描中所有离子的总强度可以为20,因此prec1在S1中具有10/20= 50%的离子电流。在扫描S2中,前体离子prec1可以具有强度10,并且该扫描中所有离子的总强度可以为200,因此prec1在S2中具有10/200= 5%的离子电流。在这种情况下,由于prec1在S2中具有其最大离子强度,所以可以选择S2来表征prec1,并且S1可以被排除。
在没有干扰的情况下,至少一个实施例可以在峰中的两个半高点之间选择一次或两次扫描,其中所选择的一次或两次扫描具有可能被选择的所有候选扫描的最大离子电流。应该指出的是,具有所有候选扫描的最大离子电流的扫描可能不是具有所有这些候选扫描的最高或最大强度的扫描。通过选择具有所有这些扫描的最高离子电流的扫描,所选择的扫描
在存在可疑或检测到的干扰(诸如基于超过可接受的质量误差范围的一个或多个质量误差)的情况下,一个实施例可以选择排除任何具有干扰的扫描。作为替代,一个实施例可以选择干扰扫描和非干扰扫描的组合,诸如以进一步完善被确定为源自被跟踪的PCC或前体离子的特定碎片离子(例如,从而完善包括在CPPIS中的碎片离子以及对前体离子的推定识别)。例如,可以选择第一干扰扫描S1并且可以选择第二非干扰扫描S2。可以确定S2(在S2中而不是在S1中)独有的第一组R1碎片离子,其中R1中的此类碎片离子被确定为源自被跟踪的PCC或前体离子,并且S2中的剩余碎片离子可以被忽略/不用于识别前体离子。可以确定S1和S2两者所共有的第二组R2碎片离子,其中R2中的此类碎片离子被确定为并非源自被跟踪的PCC或前体离子,而是被确定为源自干扰离子。
参见图46A和图46B,示出了可以在根据本文技术的一个实施例中执行的流程图4400和4401。流程图4400和4401总结了可以基于如图35所示的一个特定工作流程执行的处理。在步骤4402中,可以使用模拟器来提供模拟属性,这些模拟属性用于对如图35的目标3502a中所识别的洗脱分子或组分进行建模。在步骤4404中,调度的MMA可以执行处理以确定调度的MMA采集和参数。在步骤4406中,可以使用包括MS和/或MS和IMS的仪器系统来执行样品分析。样品分析可以通过数据采集技术以及按照MMA调度和参数进行调度来执行。步骤4406可以包括根据MMA调度在多个扫描循环中迭代选择不同的MIW。在步骤4408中,可以由样品分析生成实验数据。后续步骤概述了可以使用在步骤4408中获得的实验数据执行的不同的数据处理步骤。应该指出的是,与本文的其他讨论一致,一个实施例可以执行比包括在流程图4400和4401中的步骤更多的步骤。在步骤4410中,可以从实验数据中为每个离子确定初始的一组属性。此类属性可以包括例如m/z、保留时间、漂移时间、纯度分数、FWMH、一个或多个维度上的面积或信号强度,等等。在步骤4412中,可以对低能量扫描中的一个或多个前体离子进行一种或多种电荷态的初始分配。步骤4412可以包括使用诸如本文结合图39所描述的信息来执行处理。在步骤4414中,可以构造PCC并且为每个PCC分配电荷态。可以例如根据包括前体离子的同位素模型的输入,并且还使用图40的表3800,通过将同一前体离子的同位素变型链接在一起来构造PCC。为PCC分配与表3800中被选择用于链接的条目相关联的电荷态。该条目表示用于将簇的同位素链接在一起的特定Δm/z。特定的Δm/z是链接在一起形成PCC的连续同位素之间的差值。在步骤4416中,确定前体离子的峰洗脱轮廓或包络(例如色谱峰)。步骤4416可以包括跨时间将同一PCC组合或链接在一起(例如,基于匹配的A0 m/z)。可以各自使用最小数量的点或扫描来确定峰轮廓。在步骤4418中,可以执行处理以将每个前体离子与源自该前体离子的碎片离子对齐。步骤4418可以包括例如执行处理以基于质量误差检测并处理扫描中的干扰。在步骤4420中,可以针对每个前体离子执行处理以选择一次或多次扫描及其中的碎片离子,从而形成CPPIS或复合前体产物离子谱。在步骤4422中,可以根据实验数据更新模拟器、MMA调度和参数。尽管没有示出,但所述处理还可以包括将推定的CPPIS存储在诸如与无监督/非监督聚类有关的储存库3508c中。
考虑到每次扫描都被视为其自身的独立实验,则所有产物离子可以被初始地分配给窄带的MS质量隔离窗口内的每个前体离子。通过将每个前体的强度与产物离子谱中发现的任何残余(剩余)强度进行比较,来计算每个前体的碎片化效率。在碎片化时刻,前体离子的强度是其采集时间相对于电荷簇链中的初始关联的采集时间的函数。元素4110示出了任何两个扫描循环之间的前体离子强度的变化。星号示出了选择前体离子进行碎片化的时间。对齐处理可以使用线性回归来内插预碎片化强度,如4115中所表示,从而连接界定所选择前体的两个关联。向上的箭头表示相交。
碎片化效率与前体离子可以生成的产物离子的数量和动态范围之间存在直接关系。一个恰当碎片化的前体将相对于其长度产生比过度碎片化或碎片化不足的前体更多的产物离子。产物离子相对母体前体的动态范围与母体的碎片化效率成反比。过度碎片化的前体和碎片化不足的前体通常相对于其前体长度产生较少数量的产物离子,尽管它们通常反映更宽的动态范围。在迭代批处理中,使用这些效率来优化进样之间的碰撞能量表。图44示出了定义产物离子面积的动态范围的两条线性回归线,表示为母体前体离子强度的百分比相对于碎片化效率的关系。产物离子分配不仅受动态范围的限制,还受m/z和z的限制。考虑到离子的分子质量是其元素组成的直接反映,则标称整数质量对分数m/z图也可以用于确定产物离子的电荷。对于采用碰撞诱导解离(CID)作为碎片化机理的仪器,具有电荷z的前体离子只能产生反映最大电荷z-1的产物离子。该规则唯一的例外出现于z = 1的前体离子。单电荷前体离子只能够产生单电荷产物离子。为此,任何产物离子或产物离子的不存在于与其母体前体离子的z相称的电荷向量中的链接同位素立即从产物离子谱中消除。类似地,为了减少分心,用户可以选择将z > 1的产物离子与z > 2的前体离子对齐。
通过前体离子链接处理(例如,如结合图43所描述,用于产生前体离子的色谱峰或洗脱轮廓),解复用处理可以确定何时、以及在哪些扫描中,前体离子已经历了碎片化。通过控制扫描循环内和跨扫描循环如上文结合MMA所述的每个宽带和窄带采集的MIW的中心,以及累积地排除用于在任何随后进样中进行后续选择的那些m/z值,解复用处理被提供了不断增大任何产物离子谱的选择性的机会。每次迭代后,采集后处理都会校正任何两次进样之间的保留时间或漂移时间的任何变化。不断完善进样之间的保留时间和漂移时间的相对定位允许解复用算法访问附加的重叠产物离子谱。
此外,解复用处理还访问所有元数据,诸如实际或内插的前体离子强度、质量校准误差、实际或校正的产物离子强度,以及与每一次扫描中的每个离子相关的纯度分数。利用该元数据,解复用算法通过将产物离子仅限制于具有在定义的质量误差内的相同m/z,并且表现出与其推定前体的丰度成比例的相对丰度变化的那些,而显著降低了较宽的质量隔离窗口的嵌合效应。m/z和强度比率匹配容差可以采用算法,基于前一次参比质量校准通过离子纯度分数确定,或者可以由用户定义。一般来说,允许的面积比率容差比实际的m/z宽得多。换句话说,在前体离子强度较大的情况下匹配的产物离子强度必须更大,而在前体离子强度较小的情况下,匹配的产物离子强度必须更小。在至少一个实施例中的所有过滤结束时,每个产物离子谱都可以按照行业标准mzML或mgf文件格式编写,以用于后续的数据库搜索。也可以通过从MIR查询模拟产物离子谱或复合产物离子谱,诸如本文结合监督聚类所述的那样进行识别。
重新参见图35,肽的反映超过搜索引擎计算的95%置信区间的分数的产物离子谱可以作为推定识别被存储到3508c中。为了创建唯一或全局的肽识别符,肽序列可以与其m/z连结,并且如果该序列含有修饰,则修饰相对于N-端的位置也包括在内。可以用于识别此类修饰的技术在本文别处描述。除了已识别的肽之外,还存储了不匹配的产物离子谱,尽管它们被分配了全局识别符来替代肽的唯一识别符。全局识别符的使用类似于UPC(通用产品代码),因为它由连结到计算的CCSA(在本文中有时也称为碰撞横截面积的CCS (Å2))的四舍五入的(小数点后1位)前体离子m/z组成。一旦最小数量(例如50)的推定识别(例如,肽序列或全局识别符)已经被存储到3508c中,验证处理3508b就可以在后台中执行操作。3508b的验证算法可以通过随机选择匹配或识别的产物离子谱中的最少三十个来持续尝试创建CPPIS。可以使用验证处理,例如点积谱间相关性和皮尔逊积矩相关系数(r)来首先确定显著性。对于用皮尔逊积矩相关系数r来反映正相关,需要一组零相关来进行比较。这些零相关是由具有相似的m/z和z、但线性序列不同的肽产生的。一般来讲,如果r >= 0.75,则相关性可以被认为有效。
总的来说,DDA可能被认为缺乏跨最宽的实验动态范围最大化定性覆盖深度和定量准确度所必需的速度和灵敏度。已经开发出DIA策略如MSX和SWATH来解决系列DDA分析的采样限制,但是这些DIA方法的灵敏度可能仍然存在缺陷或缺点。其他DIA方法如Bateman技术或高-低数据采集规程不受灵敏度限制,而是产生高度嵌合的产物离子谱。固定量的足够的质量空间可能占据在MS/MS光谱中。在分离能力更高的质量分析仪中,产物离子谱中的可访问m/z空间受到其中所含产物离子的数量、元素组成和浓度的限制。尽管MIW内包含的肽的线性序列是不同的,但它们都采样了蛋白质组的相同氨基酸分布。当在质量隔离窗口内采集产物离子谱时,隔离窗口本身确保所有的共碎片化前体都具有相似的m/z。关于将同位素的数量和面积分布集中到产物离子,是其元素组成和浓度的直接函数。如电荷向量(例如,图39)所示,来自不同产物离子的不同同位素可以共享相同的m/z。假设MIW内的肽动态范围为两个数量级,则来自一种产物离子的一种同位素极有可能干扰来自第二种产物离子的另一种同位素。
为了最大化前体离子采样、保持灵敏度并且限制产物离子干扰,可以使用如本文所述的最佳采集方法来控制每次MS/MS采集进入碰撞室的前体离子的数量。前体离子的数量是在离子检测之前采用的所有在线正交分离技术的复合分离能力的函数。关于可以在单个实验中进行的准确肽识别的数量的选择性不是扫描速度和/或MIW的函数。相反,选择性是干扰的函数。即便在最复杂的混合物中,如果应用的分析工作流程采用足够大的正交性(即IMS)、更高的质量分离能力、窄色谱峰、变化的MIW窗口、建模和多重累积来独立于周围基质测量每个离子的属性,则可以实现测量规模较大的互补前体离子和产物离子的物理化学属性的能力。
无论是关于同位素标记的肽还是同量异位素标记的肽,定量准确性还是干扰的结果。就iTRAQ和TMT标记而言,如果在解离过程中碰撞室内存在多于一种肽,则每个报告的离子面积都会受到连累。就通过AUC分析进行非标记或绝对定量而言,如果任一面积为复合面积,则计算的相对或绝对丰度将受到连累。由于离子检测前分离技术为数不多,所以分析工作流程很贫乏,这些工作流程一般依赖非常窄的质量隔离宽度和质量分离度来试图使嵌合最小化。虽然将MIW变狭到<1 Th减少了共碎片化的可能性,但并不能将之消除。由于需要非常快的扫描速度来确保足够的采样率,所以窄质量隔离宽度不可避免地会累及占空比。考虑到从MS到MS/MS的强度切换通常被设定为所关注的最低强度离子的顶点强度,灵敏度进一步受到连累。将强度切换设定在这样的水平几乎确保前体从不在其顶点强度处采样。对于依赖窄MIW的工作流程,有必要采用更高的采集速度来维持占空比;然而,更高的扫描速度对质量分离度产生不利影响,特别是在MS/MS采集中。
为了提高采样率而不招致嵌合产物离子谱的有害影响,需要能够以智能的方式处理样品复杂性的分析工作流程,诸如图35的MMA工作流程。要获得最大峰容量的好处,需要透彻了解可用的分离空间、分离能力(在m/z、色谱和漂移这些维度上)、可访问的动态范围;最重要的是透彻了解所研究的样品的复杂性。包括在根据本文的技术的一个实施例中的采集调度器3504b可以利用该信息并且创建“复合分离度”。一般来说,分离度与m/z有关,然而,当在多维空间中采集数据时,分离度/峰容量是一个复合数据。在MMA工作流程中,实验分离度/峰容量是倍增的,因为它是所采用的离子检测前分离技术中的每一种的分离能力的乘积。在本文描述的一个例子中,如图38的3756中所示的m/z按漂移的分布惊人地类似于图38的3754中m/z按时间的分布,原因是所有离子的约50%在整个漂移空间的狭窄30漂移区段部分内。本文描述的数据处理算法的一个实施例在逐扫描的基础上将m/z和漂移中心化,得到±1漂移区段的漂移分辨率;因此,在启用IMS的情况下,任何单次扫描的峰容量都增大到10倍左右。另外,如图43所示,前体离子链接允许以解复用算法执行面积比率过滤器服务。在MMA工作流程内,调度器可以在由高度准确的模型或之前处理的数据获得的先验知识指导下,智能地管理穿过碰撞池的离子通量。
图38的图3752中所示的数据反映了10Th×0.2分钟区段中的离子密度。在至少一个实施例中,当MMA以固定MIW模式操作时,这些可以是缺省设置。MIW可能是用户可定义的。在自动模式下,调度器可以将MIW设定为由算法确定的最大值。例如,对于二维采集,MIW可以被设定为将前体离子的数量限制为十个。在三维数据中,MIW可以被设定为使得每个漂移区段的最大前体离子数量小于十个。关于三维采集,m/z作为漂移函数的分布定义了每次采集中共碎片化前体的最大数量。图38的元素3754示出了所有前体离子的约50%存在于250Th (± 50Th) MIW内,且中值m/z随时间推移稳步增大。第二个和第三个四分位数随时间推移以两条线性回归线β和β’为边界。β和β’是发散的,说明m/z随时间推移而变宽。图38的元素3756示出了反映m/z对漂移的类似模式。这使得MMA工作流程能够在边界线β和β’上下方的m/z区域中将MIW从窄带采集增大到宽带采集。为了使用AUC定量准确地确定肽的浓度或相对丰度,必须跨其峰FWHM采集最少五个数据点。例如,图37所示的数据举例说明了可以如何基于平均色谱峰宽计算扫描循环数、窄带采集数和宽带采集数,以及扫描时间。
在根据本文技术的至少一个实施例中,解复用处理可以包括比较来自其中定义的m/z范围被采样的所有窄带采集的产物离子谱。产物离子可以使用±3×之前的参比质量精度(ppm)、±1漂移区段以及±2.5×为驻留在定义的m/z范围内的每种A0同位素计算的面积比率这些匹配容差,利用m/z、漂移和面积比率进行匹配。在存在多于一种前体离子的情况下,可以利用前体离子的z及其计算的碎片化效率(例如,图40和图45)来进一步过滤产物离子谱。宽带产物离子谱可以被类似地处理。在根据本文技术的实施例中,诸如实现图35的工作流程,自动化工作流程的迭代性质是:所有窄带采集和宽带采集的中心m/z的持续移动为解复用算法和验证算法提供了不断提高产物离子谱的选择性的机会。
在使用本文技术的至少一个实施例中,可以将已识别的超过95%置信度的产物离子谱连同所有其他不匹配的产物离子谱一起存储到MIR的推定部分3508c中。与每个离子谱相关联的是所有离子(既有前体离子,又有产物离子)的所有元数据。在这样一个实施例中,一旦已经存储了最少50个推定的肽识别或匹配的全局识别符,验证算法3508b就尝试为每个识别创建CCPIS。验证算法可以利用例如皮尔逊积矩相关性和ANOVA来检测显著性。假如存在有效的相关性,则产生包括反映每个产物离子的归一化强度的可接受变化的误差条的CPPIS,并将其移动到MIR 3508a的经验证部分中。
由于清晰度和覆盖深度与复杂蛋白质组学样品的准确定性和定量分析相关,所以是峰容量的直接函数。任何分析工作流程的峰容量都可以定义为来自在离子检测之前应用的每种正交分离技术的所有分离能力的乘积。与所有的分析技术一样,选择性随特异性增大的程度遵循标准的s曲线。变化率最初很浅,接着迁移到线性区域中,达到拐点后迅速接近渐近极限。越过渐近线的任何增加都会对数据质量产生不利影响。很明显,在离子检测之前采用附加的正交分离(不论是在线还是离线),将对最大化峰容量产生积极影响。随着添加更多的分离维度,施加于每个维度的应力得到缓解,从而允许每个维度在其拐点处或附近发挥作用。可以在MMA中采用的正交分离技术在一个实施例中可以包括但不限于1D和2D UPLC、质量分离度、IMS、多重累积、面积比率和分数m/z。
通过最大化峰容量,如本文所述的数据处理能够校正与复杂混合物的DIA分析相关联的许多离子干扰。使用每种离子测得的FWHM(m/z、tr、td)分配纯度分数,从而反映其面积已经得到测量的程度有多大。使用电荷向量、同位素建模和离子链接准确地识别每种电荷态的肽及其相关联产物的A0同位素。将同位素聚类为电荷群,并且验证或校正每个电荷群的数量和面积分布。如果已经确定干扰,则创建虚拟离子并使其可用于后续的聚类。逐扫描分析数据为数据处理和解复用算法提供了比较以下各项的手段:m/z、面积变化率,以及进样内和进样之间的相似产物离子谱之间的连续性。利用前一次进样的经处理数据来定义当前的MMA工作流程,使该方法能够询问之前没有被采样为窄带DIA采集的m/z区域。
通过不断调整每个宽带采集和窄带采集的中心m/z值,可以使用来自前一个扫描循环或进样的产物离子谱来过滤另一个产物离子谱。将包括母体前体的产物离子谱在内的所有产物离子谱的所得到的元数据存储到MIR的推定部分中允许比较产物离子谱,而不管识别状态是怎样的。由点积谱间相关性和皮尔逊积矩相关性创建复合产物离子谱。然后可以比照经处理的非聚类离子检测查询这些复合产物离子谱。
在不脱离要求权利的本发明的实质和范围的情况下,本领域的普通技术人员将会想到本文所描述内容的变型、修改和其他具体实施。因此,本发明将不由前面的说明性描述来定义,而是由以下权利要求书的实质和范围来定义。
- 还没有人留言评论。精彩留言会获得点赞!