数据处理图编译的制作方法
本申请要求2015年8月11日提交的美国申请序列62/203,547的优先权。
背景技术:
本说明书涉及编译基于图的程序规范的方法。
数据流计算的一种方法使用基于图的表示,其中在该基于图的表示中,与图的节点(顶点)相对应的计算组件通过与该图(称为“数据流图”)的链接(有向边)相对应的数据流而连接。通过数据流链接而连接至上游组件的下游组件接收输入数据元素的有序流,并且按照所接收的顺序来处理输入数据元素,可选地生成输出数据元素的一个或多个相应流。在通过引用而并入于此的标题为“EXECUTING COMPUTATIONS EXPRESSED AS GRAPHS”的在先美国专利5,966,072中描述了用于执行这样的基于图的计算的系统。
数据流图通常被规定为使得存在两个或更多个组件可以并发(即,并行)执行的可能性。用于编译和执行数据流图的许多系统通过编译数据流图以使得数据流图的组件并发执行来在可能的情况下利用这种并发可能性。通过这样做,这些系统集中于以最小的延迟来执行数据流图。
技术实现要素:
在一方面,一般来说,一种方法包括基于数据处理图的一部分的特征而采用两种编译模式其中之一来编译数据处理图的该部分。在第一编译模式下,允许组件的并发执行。在第二编译模式下,不允许组件的并发执行,并且实施组件的串行执行。在一些方面,在数据处理图的一部分的一个或多个组件包括相对于启动“处理任务”(也简称为“任务”)(例如,执行一个或多个组件的操作的处理或线程)所需的时间量而言可能花费长时间量的操作的情况下,使用第一编译模式。在一些方面,在数据处理图的一部分的基本上所有组件包括相对于启动任务所需的时间量而言花费短时间量的操作的情况下,使用第二编译模式。
在另一方面,一般来说,一种用于对基于图的程序规范进行编译以在支持操作的并发执行的计算系统上执行的方法,所述方法包括:接收所述基于图的程序规范,所述基于图的程序规范包括图,所述图包括:多个组件,各组件与至少一个操作相对应;以及多个有向链接,各有向链接将所述多个组件中的上游组件连接至所述多个组件中的下游组件;以及对所述基于图的程序规范进行处理以生成表示一组或多组操作的处理后代码,其中所述处理包括:至少部分基于所述图的拓扑来识别所述操作的第一组中的可能并发级别,使得所述图的拓扑不会阻止所述第一组中的多个操作并发执行;分析所述第一组中的至少一些操作以确定与所分析的操作相关联的运行时特征;以及生成用于执行所述第一组中的操作的处理后代码,其中该处理后代码至少部分基于所确定的运行时特征来实施比所识别的可能并发级别低的所述第一组中的降低并发级别。
各方面可以包括以下特征中的一个或多个特征。
分析所述第一组中的至少一些操作以确定与所分析的操作相关联的运行时特征包括:针对所分析的操作中的各操作,判断所分析的操作是否是潜在地在大于第一阈值的时间段内进行计算或者潜在地在大于所述第一阈值的时间段内等待响应的潜在操作。
分析所述第一组中的至少一些操作以确定与所分析的操作相关联的运行时特征包括:针对所分析的操作中的各操作,判断所分析的操作是否是响应于所述第一组的执行的单次发起而执行多次的一个或多个操作的迭代集的成员。
所述第一阈值被定义为比启动用于执行一个或多个操作的任务所需的第二时间段更长的第一时间段。
在以下条件均不满足的情况下,所述处理后代码实施比所识别的可能并发级别低的所述第一组中的降低并发级别:(1)所述第一组中的不会被所述图的拓扑阻止并发执行的至少两个操作都被判断为潜在操作,和(2)所述第一组中的至少一个操作被判断为一个或多个操作的迭代集的成员。
在以下附加条件也不满足的情况下,所述处理后代码实施比所识别的可能并发级别低的所述第一组中的降低并发级别:(3)所述第一组中的两个或更多个操作的配置表明迭代集的存在。
施比所识别的可能并发级别低的所述第一组中的降低并发级别包括:实施所述第一组中的所有操作的串行执行。
所述有向链接中的一个或多个有向链接指示上游组件和下游组件之间的数据流。
所述有向链接中的一个或多个有向链接指示上游组件和下游组件之间的控制流。
对所述基于图的程序规范进行处理以生成表示一组或多组操作的处理后代码还包括:生成用于至少指定所述操作的第一组中的部分定序的定序信息,其中所述定序信息至少部分基于所述图的拓扑;以及其中,识别所述第一组中的可能并发级别包括:识别所述部分定序所允许的并发级别,以使得所述部分定序不会阻止所述第一组中的多个操作并发执行。
生成所述定序信息包括:对操作的所述第一组进行拓扑排序。
在另一方面,一般来说,在计算机可读介质上采用非暂时形式存储用于编译基于图的程序规范以在支持操作的并发执行的计算系统上执行的软件。所述软件包括用于使所述计算系统进行以下操作的指令:接收所述基于图的程序规范,所述基于图的程序规范包括图,所述图包括:多个组件,各组件与操作相对应;以及多个有向链接,各有向链接将所述多个组件中的上游组件连接至所述多个组件中的下游组件;以及对所述基于图的程序规范进行处理以生成表示一组或多组操作的处理后代码,其中所述处理包括:至少部分基于所述图的拓扑来识别所述操作的第一组中的可能并发级别,使得所述图的拓扑不会阻止所述第一组中的多个操作并发执行;分析所述第一组中的至少一些操作以确定与所分析的操作相关联的运行时特征;以及生成用于执行所述第一组中的操作的处理后代码,其中该处理后代码至少部分基于所确定的运行时特征来实施比所识别的可能并发级别低的所述第一组中的降低并发级别。
在另一方面,一般来说,一种用于对基于图的程序规范进行编译的计算系统,所述计算系统包括:输入装置或端口,其被配置为接收所述基于图的程序规范,所述基于图的程序规范包括图,所述图包括:多个组件,各组件与操作相对应;以及多个有向链接,各有向链接将所述多个组件中的上游组件连接至所述多个组件中的下游组件;以及至少一个处理器,其被配置为对所述基于图的程序规范进行处理以生成表示一组或多组操作的处理后代码,其中所述处理包括:至少部分基于所述图的拓扑来识别所述操作的第一组中的可能并发级别,使得所述图的拓扑不会阻止所述第一组中的多个操作并发执行;分析所述第一组中的至少一些操作以确定与所分析的操作相关联的运行时特征;以及生成用于执行所述第一组中的操作的处理后代码,其中该处理后代码至少部分基于所确定的运行时特征来实施比所识别的可能并发级别低的所述第一组中的降低并发级别。
各方面可以具有以下优点中的一个或多个。
在其它优点中,这些方面编译基于图的程序以实现计算延迟和计算效率之间的折衷。特别地,这些方面有利地将组件分组成能够并发执行的组和不能并发执行的组。根据最优性标准来进行组件的分组,使得基于图的程序的执行得以优化(例如,允许并发执行高延迟操作,而不允许执行低延迟操作)。在一些示例中,最优性标准确保并发仅在其得到提高的计算效率和/或减少的计算延迟的情形下使用。
根据以下描述和权利要求书,本发明的其它特征和优点将变得显而易见。
附图说明
图1是基于任务的计算系统的框图。
图2是包括多个输出标量端口到输入标量端口连接的数据处理图。
图3是包括多个输出集合端口到输入集合端口连接的数据处理图。
图4是包括输出集合端口到输入标量端口连接以及输出标量端口到输入集合端口连接的数据处理图。
图5A是两个组件之间的标量端口到标量端口连接。
图5B是两个组件之间的集合端口到集合端口连接。
图5C是两个组件之间的集合端口到标量端口连接,其包括执行集入口点。
图5D是两个组件之间的标量端口到集合端口连接,其包括执行集出口点。
图6是包括执行集的数据处理图。
图7是图6的执行集中的组件的操作到多个任务的分组。
图8是图6的执行集中的组件的操作到单个任务的分组。
图9A是包括具有不进行任何潜在操作的组件的执行集的数据处理图。
图9B是图9A的执行集中的操作的执行的图。
图9C是图9A的执行集的操作的执行与这些操作的可选执行进行比较的图。
图10A是包括具有进行潜在操作的组件的执行集的数据处理图。
图10B是图10A的执行集中的操作的执行的图。
图10C是图10A的执行集的操作的执行与这些操作的可选执行进行比较的图。
图11是包括具有嵌套执行集的执行集的数据处理图。
图12是包括具有隐式执行集的执行集的数据处理图。
具体实施方式
参考图1,基于任务的计算系统100使用高级程序规范110来控制计算平台150的计算和存储资源以执行程序规范110所指定的计算。编译器/解释器120接收高级程序规范110,并生成采用可以由基于任务的运行时接口/控制器140执行的形式的基于任务的规范130。编译器/解释器120识别可单独地实例化或者作为一个单元实例化的一个或多个“组件”的一个或多个“执行集”,作为要应用至多个数据元素中的各数据元素的细粒度任务。如以下更详细所述,编译或解释处理的一部分涉及识别这些执行集并且准备这些执行集以供执行。应当理解,编译器/解释器120可以使用多种技术,以例如优化在计算平台150上进行的计算的效率。编译器/解释器120所生成的目标程序规范本身可以采用中间形式,其中该中间形式要被系统100的其它部分进一步处理(例如,进一步编译、解释等)以启动基于任务的规范130。以下论述概括了这种变换的一个或多个示例,但是例如如编译器设计领域技术人员将会理解的,当然可以进行其它变换方法。
一般来说,计算平台150由多个计算节点152(例如,提供分布式计算资源和分布式存储资源两者的单个服务器计算机)组成,从而实现高度并行。高级程序规范110中所表示的计算作为相对细粒度的任务在计算平台150上执行,进一步实现指定计算的高效并行执行。
在一些实施例中,高级程序规范110是被称为“数据处理图”的一类基于图的程序规范,其中该“数据处理图”能够执行(如数据流图中的)数据流和控制流这两者。如以下更详细所述,数据处理图还包括用于支持并行的机制,其中这些机制使得编译器/解释器120能够在数据处理图的组件中动态地引入并行。例如,在执行数据处理图的上下文中,数据处理图的组件的实例作为任务(例如,执行一个或多个组件的操作的线程)启动,并且一般在计算平台150的多个计算节点152中执行。一般来说,控制器140提供这些任务的调度和执行轨迹的监管控制方面,以实现系统的例如与计算负载的分配、通信或输入/输出开销的减少、所使用的存储器资源相关的性能目标。
在编译器/解释器120的转译之后,就计算平台150可以执行的目标语言的过程而言,整个计算被表示为基于任务的规范130。这些过程使用诸如“启动”和“等待”等的原语(primitive),并且可以在这些原语中包括或者调用程序员针对高级(例如,基于图的)程序规范110中的组件所指定的工作过程。
在一些情况下,可以将组件的各实例实现为任务,其中一些任务实现单个组件的单个实例,一些任务实现执行集中的多个组件的单个实例,以及一些任务实现组件的连续实例。来自组件及其实例的特定映射依赖于编译器/解释器的特定设计,使得所得到的执行与计算的语义定义保持一致。
一般来说,运行时环境中的任务分层地排列,例如,一个顶级任务启动多个任务,例如,一个顶级任务针对数据处理图中的各顶级组件启动一个任务。同样,执行集的计算可以包括用于处理整个集合的一个任务,其中多个(即,许多)子任务各自用于处理集合的元素。
在一些示例中,各计算节点152具有一个或多个处理引擎154。在至少一些实现中,各处理引擎与在计算节点150上执行的单个操作系统处理相关联。根据计算节点的特征,可以高效地在单个计算节点上执行多个处理引擎。例如,计算节点可以是具有多个单独处理器的服务器计算机,或者该服务器计算机可以包括具有多个处理器核的单个处理器,或者可能存在具有多个核的多个处理器的组合。在任何情况下,执行多个处理引擎可以比在计算节点152上仅使用单个处理引擎更高效。
1数据处理图
在一些实施例中,高级程序规范110是包括“组件”集的、被称为“数据处理图”的一类基于图的程序规范,其中这些“组件”各自指定要对数据进行的整个数据处理计算的一部分。这些组件例如在编程用户界面中和/或在计算的数据表示中被表示为图中的节点。与一些基于图的程序规范(诸如以上在背景技术中所述的数据流图等)不同,该数据处理图可以包括节点之间的、表示数据传送或控制传送中的任一个或两者的链接。一种指示这些链接的特征的方法是在组件上提供不同类型的端口。这些链接是从上游组件的输出端口连接至下游组件的输入端口的有向链接。这些端口具有表示如何相对于链接而写入和读取数据元素以及/或者如何控制组件来处理数据的特征的指示符。
这些端口可以具有多个不同特征。端口的一个特征是其作为输入端口或输出端口的有向性。有向链接表示正从上游组件的输出端口输送至下游组件的输入端口的数据和/或控制。允许开发者将不同类型的端口链接在一起。数据处理图的一些数据处理特征依赖于不同类型的端口如何链接在一起。例如,不同类型的端口之间的链接可能导致提供分层形式的并发的不同执行集中的组件的嵌套子集,如以下更详细所述。端口的类型表明某些数据处理特征。组件可以具有的不同类型的端口包括:
●输入或输出集合端口,其意味着组件的实例将分别读取或写入将经由连接至端口的链接而传递的集合中的所有数据元素。对于在连接端口之间具有单个链接的一对组件,通常允许下游组件在正被上游组件写入时读取数据元素,从而在上游组件和下游组件之间实现管线并行。如以下更详细所述,可以对数据元素进行再定序,从而实现并行化的效率。在一些图形表示中,例如在编程图形界面中,这些集合端口通常由组件处的正方形连接器符号表示。
●输入或输出标量端口,其意味着组件的实例将相对于连接至端口的链接分别读取或写入至多一个数据元素。对于在标量端口之间具有单个链接的一对组件,使用单个数据元素的传送作为控制传送,来实施上游组件完成执行之后的下游组件的串行执行。在一些图形表示中,例如在编程图形界面中,这些标量端口通常由组件处的三角形连接器符号来表示。
●输入或输出控制端口,其与标量输入或输出相同,但是无需发送数据元素,并且用于通信组件之间的控制传送。对于在控制端口之间具有链接的一对组件,(即使在这些组件在集合端口之间也具有链接的情况下也)实施上游组件完成执行之后的下游组件的串行执行。在一些图形表示中,例如在编程图形界面中,这些控制端口通常由组件处的圆形连接器符号表示。
这些不同类型的端口实现数据处理图的灵活设计,从而允许利用端口类型的重叠属性进行数据流和控制流的强大组合。特别地,存在用于采用某种形式来输送数据的两种类型的端口(称为“数据端口”),即集合端口和标量端口;以及存在用于实施串行执行的两种类型的端口(称为“串行端口”),即标量端口和控制端口。数据处理图通常将具有作为没有任何连接的输入数据端口的“源组件”的一个或多个组件、以及作为没有任何连接的输出数据端口的“宿组件”的一个或多个组件。一些组件将具有连接的输入数据端口和输出数据端口这两者。在一些实现中,图不被允许具有循环,因此必须是有向非循环图(DAG)。可以使用该特征来利用DAG的某些特征,如以下更详细所述。
通过以不同方式连接不同类型的端口,开发者能够指定数据处理图的组件的端口之间的不同类型的链接配置。例如,一种类型的链接配置可以对应于特定类型的端口连接至相同类型的端口(例如,标量到标量链接),并且另一种类型的链接配置可以对应于特定类型的端口连接至不同类型的端口(例如,集合到标量链接)。这些不同类型的链接配置既用作开发者在视觉上识别与数据处理图的一部分相关联的预期行为的方式,又用作向编译器/解释器120指示实现该行为所需的相应类型的编译处理的方式。虽然这里所述的示例使用不同类型端口的唯一形状来在视觉上表示不同类型的链接配置,但系统的其它实现可以通过提供不同类型的链接并且向各种类型的链接分配唯一的视觉指示(例如,厚度、线型、颜色等)来区别不同类型的链接配置的行为。然而,为了使用链接类型而非端口类型表示可能具有以上列举的三种类型的端口的相同种类的链接配置,将存在不止三种类型的链接(例如,标量到标量、集合到集合、控制到控制、集合到标量、标量到集合、标量到控制等)。
编译器/解释器120进行用以准备数据处理图以供执行的过程。第一过程是用以识别组件的潜在嵌套执行集的分层的执行集发现预处理过程。第二过程是用以针对各执行集而生成相应控制图的控制图生成过程,其中编译器/解释器120将使用该相应控制图来形成将有效地实现用于控制各执行集内的组件的执行的运行时状态机的控制代码。
具有至少一个输入数据端口的组件指定要对各输入数据元素或集合(或其多个输入端口上的数据元素和/或集合的元组)进行的处理。这种规范的一种形式是作为要对输入数据元素和/或集合中的一个或元组进行的过程。如果组件具有至少一个输出数据端口,则该组件可以产生输出数据元素和/或集合中的相应的一个或元组。这样的过程可以以基于语句的高级语言(例如,使用Java源语句、或者例如如美国专利8,069,129“Editing and Compiling Business Rules”中所使用的针对实例的数据操作语言(DML))指定,或者可以以某种完全或部分编译的形式(例如,如Java字节代码那样)提供。例如,组件可以具有如下的工作过程,其中该工作过程的参数包括其输入数据元素和/或集合以及其输出数据元素和/或集合,或者更一般地,包括对这些数据元素或集合、或者对用于获取输入并提供输出数据元素或集合的过程或数据对象(这里被称为“处置”)的引用。
工作过程可以是各种类型的。在不意图限制可指定的类型的过程的情况下,一种类型的工作过程根据记录格式来指定针对数据元素的离散计算。单个数据元素可以是来自表格(或其它类型的数据集)的记录,并且记录的集合可以是表中的所有记录。例如,针对具有单个输入标量端口和单个输出标量端口的组件的一种类型的工作过程包括接收一个输入记录,对该记录进行计算,并且提供一个输出记录。另一类型的工作过程可以指定如何处理从多个输入标量端口接收到的输入记录的元组以形成在多个输出标量端口发送出的输出记录的元组。
数据处理图所指定的计算的语义定义是固有并行的,因为该语义定义表示针对图所定义的计算的处理的定序和并发的约束和/或缺乏约束。因此,计算的定义不要求结果等同于计算步骤的某一顺序定序。另一方面,计算的定义不提供要求对计算的部分进行排序的某些约束、以及对计算的部分的并行执行的限制。
在数据处理图的论述中,作为运行时系统中的单独“任务”的组件的实例的实现被假定为表示排序和并行化约束的手段。一般来说,在图的执行期间,数据处理图中的各组件将在计算平台中实例化多次。各组件的实例的数量可以依赖于组件要被分配至多个执行集中的哪一个。在对组件的多个实例进行了实例化的情况下,不止一个实例可以并行执行,并且不同实例可以在系统中的不同计算节点中执行。组件所进行的操作以及组件的互连(包括端口的类型)确定指定数据处理图所允许的并行处理的性质。
各种组件上的不同类型的数据端口使得数据能够经由组件之间的链接以不同方式传递,其中这些方式依赖于链接这些组件的输入和输出端口的类型。如上所述,标量端口表示产生(针对输出标量端口)或者消耗(针对输入标量端口)至多单个数据元素(即,0个或1个数据元素)。然而,集合端口表示产生(针对输出集合端口)或消耗(针对输入集合端口)潜在多个数据元素的集合。通过在单个数据处理图中支持这两种类型的数据端口,模型使得开发者能够容易地指示期望的行为。
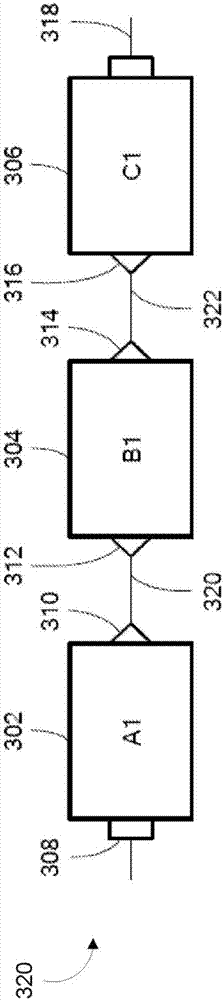
参考图2,数据处理图300包括一系列三个连接组件,即第一组件(A1)302、第二组件(B1)304和第三组件(C1)306。第一组件包括集合类型输入端口308和标量类型输出端口310。第二组件304包括标量类型输入端口312和标量类型输出端口314。第三组件包括标量类型输入端口316和集合类型输出端口318。
将第一组件302的输出标量端口310连接至第二组件304的输入标量端口312的第一链接320既使得数据能够在第一组件302和第二组件304之间传递,同时又能够实施第一组件302和第二组件304的串行执行。同样,将第二组件304的输出标量端口314连接至第三组件306的输入标量端口316的第二链接322既使得数据能够在第二组件304和第三组件306之间传递,同时又能够实施第二组件304和第三组件306的串行执行。
由于图2中的标量端口的互连,因此第二组件304仅在第一组件302完成(并经由第一链接320传递单个数据元素)之后开始执行,并且第三组件306仅在第二组件304完成(并经由第二链接322传递单个数据元素)之后开始执行。即,数据处理图中的三个组件按严格的顺序A1/B1/C1各自运行一次。
在图2的典型数据处理图中,第一组件的输入端口308和第三组件的输出端口318恰好是集合端口,其中这些集合端口对连接第一组件302、第二组件304和第三组件306的标量端口所施加的这些组件的串行执行行为没有影响。
一般来说,集合端口既用于在组件之间传递数据元素的集合、同时又可以向运行时系统赋予用以再定序该集合内的数据元素的许可。由于不依赖于从一个数据元素到另一数据元素的计算状态,因此允许对未定序集合的数据元素的再定序,或者如果存在处理各数据元素时访问的全局状态,则最后状态与处理这些数据元素的顺序无关。这种再定序许可提供了用于延迟与并行化有关的决策直到运行时为止的灵活性。
参考图3,数据处理图324包括一系列三个连接组件,即第一组件(A2)326、第二组件(B2)328和第三组件(C2)330。第一组件326包括集合类型输入端口332和集合类型输出端口334。第二组件328包括集合类型输入端口336和集合类型输出端口338。第三组件330包括集合类型输入端口340和集合类型输出端口342。
三个组件326、328、330各自指定如何处理一个或多个输入元素的集合以生成一个或多个输出元素的集合。特定的输入元素和特定的输出元素之间不必存在一对一的对应关系。例如,第一组件326和第二组件328之间的第一数据元素集合344中的多个数据元素可以与第二组件328和第三组件330之间的第二数据元素集合346中的多个元素不同。对于集合端口之间的连接的唯一约束是:在关于处理三个组件326、328、330的顺序、允许第一组件326和第二组件328以及第二组件328和第三组件330之间的任意再定序的同时,使该集合中的各数据元素从一个集合端口传递至另一集合端口。可选地,在其它示例中,集合端口可以可选地被配置为保存顺序。在该示例中,三个组件326、328、330一起启动并且并发地运行,从而允许管线并行。
关于图1所述的编译器/解释器120被配置为识别集合端口到集合端口的连接,并以适合于正进行的计算的方式将计算转译为可执行代码。集合数据链接的未定序性质向编译器/解释器120赋予如何完成该转译的灵活性。例如,如果恰好是针对第二组件328、基于单个输入元素计算各输出元素(即,在数据元素之间不维持状态)的情况,则编译器/解释器120可以使得运行时系统能够通过针对各数据元素将组件的多达一个实例进行实例化(例如,根据运行时可用的计算资源)来动态地使数据元素的处理并行化。可选地,在特殊情况下,可以在具有输入集合端口的组件中的数据元素之间维持状态。但是在一般情况下,运行时系统可被允许将组件的任务并行化。例如,如果运行时系统检测出没有正在维持全局状态,则该运行时系统可被允许将任务并行化。一些组件还可被配置为支持维持状态,在这种情况下,可能不允许并行化。如果集合是未定序的,则在数据元素之间无需保存顺序这一事实意味着第二组件328的各实例可以在其输出数据元素可用时立即将该输出数据元素提供至第三组件330,并且第三组件330可以在第二组件328的所有实例都完成之前开始处理这些数据元素。
2执行集
在一些示例中,图开发者可以通过将一个组件的集合类型输出端口连接至另一组件的标量类型输入端口来明确地指示可以动态地使数据集合中的数据元素的处理并行化。除了指示这种组件上述内容外,这种指示还要求在集合中的不同元素的处理之间不维持状态。参考图4,数据处理图348包括一系列的三个连接组件,即第一组件(A3)350、第二组件(B3)352和第三组件(C3)354。第一组件350包括集合类型输入端口356和集合类型输出端口358。第二组件包括标量类型输入端口360和标量类型输出端口362。第三组件354包括集合类型输入端口364和集合类型输出端口366。
第一组件的集合类型输出端口358经由第一链接368而连接至第二组件352的标量类型输入端口360,并且第二组件352的标量类型输出端口362经由第二链接370而连接至集合类型输入端口364。如以下更详细所述,从集合类型输出端口到标量类型输入端口的链接表明“执行集”(或“迭代集”)的入口点,并且从标量类型输出端口到集合类型输入端口的链接表明执行集的出口点。一般来说,如以下更详细所述,可以利用运行时控制器来使执行集中所包括的组件动态地并行化以处理来自数据元素集合中的数据元素。
在图4中,第一组件350的集合类型输出端口358和第二组件352的标量类型输入端口360之间的链接368表明执行集的入口点。第二组件352的标量类型输出端口362和第三组件354的集合类型输入端口364之间的链接370表明执行集的出口点。即,第二组件352是执行集中的唯一组件。
由于执行集中包括第二组件352,因此针对从第一组件350的集合类型输出端口358接收到的各数据元素,启动第二组件352的单独实例。至少一些单独实例可以并行运行,这依赖于在运行时之前不能作出的决策。在该示例中,第一组件(350)和第三组件(354)一起启动并且并发运行,而第二组件(352)针对经由链接368所接收到的各数据元素运行一次。如以上关于图1所述,编译器/解释器120对数据处理图进行执行集发现预处理过程,以准备供执行的数据处理图。执行集是可作为单元被调用或者应用至数据的一部分(诸如输出集合端口的数据元素的一部分等)的一个或多个组件的集合。因此,针对各输入元素(或被呈现给集合的多个输入端口的输入元素的元组),执行执行集中的各组件的至多一个实例。在执行集内,通过链接向标量端口和控制端口施加排序约束,其中执行集中的组件的并行执行是可允许的,只要不违反排序约束即可。在存在被允许并行执行的至少一些组件的示例中,执行集可以使用多个任务(例如,针对执行集整体的任务、以及用于一个或多个组件的实例的并发执行的一个或多个子任务)来实现。因此,表示执行集的不同实例的任务本身可以分成例如具有可并发执行的子任务的甚至更细粒度的任务。针对不同执行集的任务通常可以独立且并行地执行。因此例如如果大型数据集具有一百万条记录,则可能存在一百万个独立任务。一些任务可以在计算平台150的不同节点152上执行。任务可以使用轻量级线程来执行,其中这些轻量级线程可以甚至在单个节点152上高效地并发执行。
一般来说,分配算法所识别的执行集(即,除根执行集之外的执行集)通过执行集的边界处的“驱动”标量数据端口来接收数据元素。对于在执行集的驱动输入标量数据端口处接收到的各数据元素,执行集内的各组件(在被启动的情况下)执行一次,或者(在被抑制的情况下)不执行。执行集的多个实例可以实例化并且并行执行以处理来自上游集合端口的可用于该执行集的多个数据元素。针对执行集的并行程度可以在运行时确定(并且包括不使执行集并行化的可能决策),并且仅受到运行时可用的计算资源的限制。在执行集的输出端口处与顺序无关地收集执行集的独立实例的单独输出,并且使这些单独输出可用于下游组件。可选地,在其它实施例中,可以(在一些情况下基于用户数据)识别除根执行集以外的、无需驱动输入标量数据端口的执行集。可以使用这里所述的过程,在适当情况下(例如,针对后述的锁定执行集)在单个实例中或者并行地在多个实例中执行没有驱动输入标量数据端口的这种执行集。例如,可以设置如下的参数,其中该参数用于确定执行集将会执行的次数、以及/或者将会执行的执行集的并行实例的数量。
一般来说,执行集发现过程使用分配算法,其中该分配算法确定数据处理图内的、要作为集合而被应用至数据元素的未定序集合中的输入元素的组件子集。分配算法遍历数据处理图,并基于分配规则将各组件分配给子集。如以下示例中显而易见的,给定数据处理图可以包括嵌套在执行集分层的不同级别的多个执行集。
在这里所述的数据处理图中,存在两种类型的数据端口:标量数据端口和集合数据端口。一般来说,如果一对链接组件(即上游组件和下游组件)经由相同类型的端口之间的链接而连接,则将默认该对链接组件处于相同的执行集中(除非该对链接组件出于其它原因而处于不同的执行集中)。在图5A中,组件A 402具有标量类型的输出端口406,并且组件B 404具有标量类型的输入端口408。由于组件A 402和组件B 404之间的链接410连接两个标量类型端口,因此在该示例中,组件A 402和组件B 404处于相同的执行集中。在图5A中,由于组件A 402和组件B 404之间的链接是标量到标量链接,因此在上游组件A 402和下游组件B 404之间经由链接410来传递0个数据元素或1个数据元素。在完成上游组件A 402的处理时,数据元素经由链接410而传递,除非上游组件A 402被抑制(如上所述),在这种情况下,没有数据元素经由链接410传递。
参考图5B,组件A 402具有集合类型的输出端口412,并且组件B 404具有集合类型的输入端口414。由于组件A 402和组件B 404之间的链接410连接两个集合类型端口,因此在该示例中,组件A 402和组件B 404也处于相同的执行集中。在图5B中,由于组件A 402和组件B 404之间的链接410是集合到集合链接,因此在上游组件和下游组件之间经由链接410来传递数据元素集合。
在链接的任一端上的端口类型之间存在不匹配的情况下,在执行集分层的级别中存在隐式变化。特别地,不匹配的端口表示执行集分层的特定级别中的执行集的入口点或出口点。在一些示例中,执行集入口点被定义为集合类型输出端口和标量类型输入端口之间的链接。在图5C中,在组件A 402和组件B 404之间的链接410处示出执行集入口点424的一个示例,这是因为组件A 402的输出端口416是集合类型端口并且组件B 404的输入端口418是标量类型端口。
在一些示例中,执行集出口点被定义为标量类型输出端口和集合类型输入端口之间的链接。参考图5D,在组件A 402和组件B 404之间的链接410处示出执行集出口点426的一个示例,这是因为组件A 402的输出端口420是标量类型端口并且组件B 404的输入端口422是集合类型端口。
在编译器/解释器120的编译和/或解释之前实现的分配算法使用执行集入口点和执行集出口点来发现数据处理图中存在的执行集。
3执行集编译
参考图6,数据处理图600的一个示例从数据源A 650接收输入数据,使用多个组件来处理该输入数据,并将处理数据的结果存储在第一数据宿H 652和第二数据宿I 654中。数据处理图600的组件包括第一组件B 656、第二组件C 658、第三组件D 660、第四组件E 662、第五组件F 664和第六组件G 666。
第一流651将数据源650的输出集合端口连接至第一组件B 656的输入集合端口。第二流653将第一组件B 656的输出集合端口连接至第二组件C 658的输入标量端口。注意,由于第二流653将输出集合端口连接至输入标量端口,因此第一组件B 656和第二组件C 658之间存在执行集入口点655。
第三流657将第二组件C 658的输出标量端口连接至第三组件D 660和第四组件E 662这两者的输入标量端口。第四流659将第三组件D 660的输出标量端口连接至第五组件F 664的输入集合端口。第五流661将第四组件662的输出标量端口连接至第六组件G 666的输入集合端口。注意,由于第四流659和第五流661将输出标量端口连接至输入集合端口,因此在第三组件D 660和第五组件F 664之间存在第一执行集出口点663,并且在第四组件E 662和第六组件G 666之间存在第二执行集出口点665。
第六流667将第五组件F 664的输出集合端口连接至第一数据宿H 652的输入集合端口。第七流669将第六组件G 666的输出集合端口连接至第二数据宿I 654的输入集合端口。
如上所述,在编译器/解释器120准备供执行的数据处理图600时,该编译器/解释器120首先进行执行集发现预处理过程以识别组件的潜在嵌套执行集的分层。针对图6的典型数据处理图600,执行集发现预处理过程识别如由执行集入口点655、第一执行集出口点663和第二执行集出口点665界定的第一执行集668。如从图中显而易见的,第一执行集668包括第二组件C 658、第三组件D 660和第四组件E 662。
在识别执行集668之后,编译器/解释器120进行控制图生成过程以生成针对第一执行集的控制图,其中编译器/解释器120将使用该控制图来形成将有效地实现用于控制第一执行集内的组件的执行的运行时状态机的控制代码。生成控制图的一个步骤包括将组件分组到任务组。
在一些示例中,编译器/解释器120将数据处理图中的各组件(包括执行集668中的组件)分组到一个或多个任务组。在数据处理图600执行时,针对各任务组启动任务,并且在该任务内进行属于任务组的组件的操作。虽然数据处理图中的所有组件被分组到任务组,但这里所述的方面主要与执行集内的组件到任务组的分组相关。出于该原因,剩余的论述主要与执行集668中的组件到任务组的分组相关。
执行集668中的组件到任务组的多个不同分组都是可能的,其中各不同分组具有相关联的优点和缺点。一般来说,执行集668的组件如何最优地分组到任务组依赖于最优性标准。
3.1针对延迟最小化的编译
例如,如果最优性标准规定执行集668中的组件的最优分组实现最小计算延迟,则这些组件到任务组的一个可能的分组包括将各组件分组到其各自单独的任务组。这样做使得组件的操作(有时称为“工作过程”)在可能的情况下能够并发运行。例如,在执行集668中,第一任务组可分配至第二组件C 658,第二任务组可分配至第三组件D 660,并且第三任务组可分配至第四组件E 662。
参考图7,在数据处理图600的执行集668执行时,启动针对第一任务组的第一任务770,并且在该第一任务770中进行第二组件C 758的操作。在第二组件C 758的操作完成时,第一任务启动针对第二任务组的第二任务722以及针对第三任务组的第三任务774。与正在第三任务774中进行的第四组件E 762的操作并发地在第二任务772中进行第三组件D 760的操作。
有利地,通过与第四组件E 762的操作并发地进行第三组件D 760的操作,计算延迟被最小化,这是因为组件在进行其操作之前无需等待其他组件完成。另一方面,存在与启动多个任务相关联的计算资源和时间这两方面的成本。即,为了最小计算延迟而将执行集668中的组件分组到任务组不是对组件进行分组的最高效方式(其中,效率定义为用于进行给定任务的计算资源量的度量)。
3.2针对效率最大化的编译
可选地,如果最优性标准规定执行集668中的组件的最优分组实现最大效率(如上所述),则执行集668中的组件被分组到单个任务组。这样做要求即使在可以并发的情况下,也在单个任务内串行地进行执行集668中的组件的操作。
例如,针对执行集668,第一任务组可以包括第二组件C 658、第三组件D 660和第四组件E 662。参考图8,在数据处理图600的执行集668执行时,启动针对第一任务组的单个任务876,并且在该单个任务内串行地(即,一次一个地)进行第二组件C 758、第三组件D 760和第四组件E 762的操作。在一些示例中,以拓扑排序的顺序进行第二组件C 758、第三组件D 760和第四组件E 762的操作,以确保保存数据处理图600中指定的操作的顺序。
在单个任务中串行地进行执行集668中的操作的一个优点是,执行操作的效率被最大化。特别地,执行数据处理图所需的计算资源量被最小化,从而避免了与启动多个任务相关联的开销。当然,多个任务的串行执行具有与多个任务的并发执行相比潜在地花费更长时间完成的缺点。
3.3针对延迟和效率折衷的编译
在一些示例中,最优性标准规定执行集668中的组件到任务组的最优分组实现延迟最小化和效率之间的折衷。在以下部分描述了用于实现这种折衷的多个典型方法。
3.3.1潜在操作识别
实现延迟最小化和效率之间的折衷的一种方式包括首先识别数据处理图中的组件所进行的某些操作可能花费相对于启动任务所需的时间而言长的时间。这些操作有时称为“潜在操作”。相对于启动任务所需的时间,某些其它操作可能花费短时间量。
在执行集668中的两个或更多个组件可能并发运行的情形中,编译器/解释器120基于完成执行集668中的组件的操作将会花费的时间的估计,来判断是否要允许执行集668的操作的并发执行。如果在执行集中识别出任何潜在操作,则允许执行集668中的组件并发执行。如果在执行集668中未识别出潜在操作,则不允许执行集668中的组件的并发执行。
在一些示例中,为了确定完成执行集668中的组件的操作将会花费的时长,编译器/解释器120检查与组件相关联的事务代码(例如,如上所述的DML代码)以识别诸如数据库访问、查询文件操作、远程过程呼叫和服务呼叫等的潜在操作。在其它示例中,编译器/解释器120使用运行时仪器来测量在数据处理图600的多次执行期间完成任务所花费的时间。可以基于所测得的完成任务所花费的时间来联机或离线地对数据处理图600进行再编译。
参考图9A,在一个非常简单且说明性的示例中,数据处理图900被配置为使得第一组件B 656从数据源650读取值x并将x发送至第二组件C 658。第二组件C 658通过向x加1来计算值y,并将值y发送至第三组件D 660和第四组件E 662。第三组件D 660通过将y乘以2来计算值z,并将z发送至第五组件F 664。第四组件E 662通过将y除以2来计算值q,并将q发送至第七组件G 666。第五组件F 665将值z写入第一数据宿H 652。第六组件G 666将值q写入第二数据宿I 654。
在编译器/解释器120分析图9A的数据处理图900中的执行集668时,检查第二组件C 658、第三组件D 660和第四组件E 662的事务代码以判断任意组件是否包括潜在操作。在图9A的示例中,由于组件所进行的所有操作是在非常短时间量内完成的简单算术操作,因此未识别出潜在操作。
由于在执行集668中未识别出潜在操作,因此不允许执行集668中的组件并发执行。为了达到该目的,在控制图生成过程期间,第二组件C 658、第三组件D 660和第四组件E 662被分组到单个任务组。在数据处理图执行时,启动针对单个任务组的单个任务,并且在该单个任务中执行针对第二组件C 658、第三组件D 660和第四组件E 662的操作(如图8中那样)。在第一执行集668中的各组件在单个任务中执行的情况下,迫使第三组件D 660和第四组件E 662在第二组件C 658的操作之后串行执行。
参考图9B,在启动单个任务(即,任务1)时(即,在任务1发起处),产生第一开销970,并且第二组件C 658开始执行。在完成第二组件C 658的执行时,第三组件开始执行。在完成第三组件D 660的执行时,第四组件E 662执行,此后单个任务完成。
通过在单个任务(即,任务1)中串行执行三个组件,这三个组件的执行的总时间与允许至少一些组件的并发执行的情况相比更大。然而,在单个任务(或减少数量的任务)中执行导致减少的任务发起相关开销量,这是因为仅产生用于发起单个任务的第一开销970。如上所述,在执行集中不存在潜在操作的情况下,通常期望开销和总执行时间之间的这种折衷。作为比较,图9C示出三个组件的使用第三组件D 660和第四组件E 661之间允许的并发性在第二组件C 658的任务(任务1)之后的单独任务(即,任务2和3)中并发地执行第三组件D 660和第四组件E 661这两个组件的操作所导致的总执行时间980(包括开销)。显而易见的是,在这种情况下,针对减少的并发执行的总执行时间982更短。
参考图10A,在另一简单且说明性的示例中,数据处理图1000被配置为使得第一组件B 656从数据源650读取值x并将x发送至第二组件C 658。第二组件C 658通过向x加1来计算值y,并将值y发送至第三组件D 660和第四组件E 662。第三组件D 660通过将y乘以2来计算值z,并将z发送至第五组件F 664。第四组件E 662通过从数据存储671(例如,查找文件或数据库)读取值m并对m和y求和,来计算值q。第四组件E 662将q发送至第七组件G 666。第五组件F 664将值z写入第一数据宿H 652。第六组件G 666将值q写入第二数据宿I 654。
在编译器/解释器120分析图10A的数据处理图1000中的执行集668时,检查第二组件C 658、第三组件D 660和第四组件E 662的事务代码以判断任意组件是否包括潜在操作。在图10A的示例中,第四组件E 662被识别为包括潜在操作,这是因为该第四组件从数据存储671读取值。
由于在执行集中识别出潜在操作,因此允许数据处理图1000的组件并发执行。为了达到该目的,在控制图生成过程期间,第二组件C 658、第三组件D 660和第四组件E 662各自被分组到不同的任务组(例如,第一任务组、第二任务组和第三任务组)。在数据处理图600执行时,针对各任务组启动不同的任务(例如,针对用于执行第二组件C 658的操作的第一任务组启动第一任务,针对用于执行第三组件D 660的操作的第二任务组启动第二任务,并针对用于执行第四组件E 662的操作的第三任务组启动第三任务)(如图7中那样)。在第一执行集668中的各组件在单独的任务中执行的情况下,第三组件D 660能够与第四组件E 662并发地执行。
参考图10B,在启动第一任务(即,任务1)时(即,在任务1发起处),产生第一开销1070,并且第二组件C 658开始执行。在完成第二组件C 658的执行时,第一任务完成并且第二任务和第三任务并发启动(在任务1完成处),从而分别产生第二开销1072和第三开销1074。第三组件D 660与第三任务中的第四组件E 662的执行并发地在第二任务中执行。由于第四组件E 662是潜在操作并且第三组件D 660不是潜在操作,因此第三组件D 660在第四组件E 662之前完成执行,这导致第二任务完成(即,在任务2完成处)。第四组件E 662继续在第三任务中执行直到完成为止,这导致第三任务完成(即,在任务3完成处)。注意,图10B中的时间线的时间标度与图9B中的时间线的时间标度不同,这表示相对于任务时间而言、开销时间的相同绝对量具有不同的持续时间。
作为比较,图10C示出,在这种情况下,通过在单独的任务(即,任务2和3)中并发执行第三组件D 660和第四组件E 662,三个组件的总执行时间1080小于使用这些组件的减少的并发(在这种情况下为串行)执行的情况下将产生的总执行时间1082。即使通过使三个单独的任务实例化所产生的开销量大于针对减少的并发执行使用单个任务的情况下将产生的开销量,也是如此。如上所述,在执行集中存在潜在操作的情况下,通常期望总执行时间和开销之间的这种折衷。
注意,也可以使用允许并发执行的、组件到任务组(以及最终单独的任务)的其它分组。例如,第二组件C 658和第三组件D 660可被分组到相同的任务组并且最终在单个任务中执行,而不是被分组到单独的任务组。当然,第四组件E 662的操作执行的单个任务仍可以与第二组件C 658和第三组件D 660的操作执行的任务并发地执行,只要满足第二组件C 658和第四组件E 662之间的串行到串行连接所施加的串行约束即可。
3.3.2嵌套执行集识别
实现延迟最小化和效率之间的折衷的另一种方式包括识别执行集中所包括的任意“嵌套”执行集可能花费相对于启动任务所需的时间的长的时间。例如,嵌套执行集可能处理来自上游集合端口的大量数据,包括使数据循环或者启动大量任务以并发地处理数据。
因此,在一些示例中,在第一执行集中的两个或更多个组件可以并发运行的情况下,编译器/解释器120基于第一执行集中所包括的其它嵌套执行集的存在来判断是否允许第一执行集中的操作的并发执行。如果识别出任何嵌套执行集,则允许第一执行集中的组件并发执行。如果在第一执行集中未识别出嵌套执行集,则不允许第一执行集中的组件的并发执行。
参考图11,典型的数据处理图1100从数据源A 1150接收输入数据,使用多个组件来处理输入数据,并且将处理数据的结果存储在第一数据宿H 1152和第二数据宿I 1154中。数据处理图1100的组件包括第一组件B 1156、第二组件C 1158、第三组件D 1160、第四组件E 1162、第五组件J 1172、第六组件F 1164和第七组件G 1166。
第一流1151将数据源1150的输出集合端口连接至第一组件B 1156的输入集合端口。第二流1153将第一组件B 1156的输出集合端口连接至第二组件C 1158的输入标量端口。注意,由于第二流1153将输出集合端口连接至输入标量端口,因此第一组件B 1156和第二组件C 1158之间存在第一执行集入口点1155。
第三流1157将第二组件C 1158的输出集合端口连接至第三组件D 1160的输入集合端口和第四组件E 1162的输入标量端口。注意,由于第三流将第二组件C 1158的输出集合端口连接至第四组件E 1162的输入标量端口,因此在第二组件C 1158和第四组件E 1162之间存在第二执行集入口点1175。
第四流1159将第三组件D 1160的输出标量端口连接至第六组件F 1164的输入集合端口。注意,由于第四流将输出标量端口连接至输入集合端口,因此在第三组件D 1160和第六组件F 1164之间存在第一执行集出口点1163。
第五流1177将第四组件E 1162的输出标量端口连接至第五组件J 1172的输入集合端口。注意,由于第五流1177将输出标量端口连接至输入集合端口,因此在第四组件E 1162和第五组件J 1172之间存在第二执行集出口点1179。
第六流1161将第五组件J 1172的输出标量端口连接至第七组件G 1166的输入集合端口。注意,由于第六流1161将输出标量端口连接至输入集合端口,因此在第五组件J 1172和第七组件G 1166之间存在第三执行集出口点1165。
第七流1167将第六组件F 1164的输出集合端口连接至第一数据宿H 1152的输入集合端口。第八流1169将第七组件G 1166的输出集合端口连接至第二数据宿I 1154的输入集合端口。
在编译器/解释器120准备供执行的数据处理图1100时,该编译器/解释器120首先进行执行集发现预处理过程以识别组件的潜在嵌套执行集的分层。针对图11的典型数据处理图1100,执行集发现预处理过程识别第一执行集1168和嵌套在第一执行集1168内的第二执行集1181。第一执行集1168由第一执行集入口点1155、第一执行集出口点1163和第三执行集出口点1165所界定。第二执行集1181由第二执行集入口点1175和第二执行集出口点1179所界定。如从图中显而易见的,第一执行集1168包括第二组件C 1158、第三组件D 1160、第五组件J 1172、以及包括第四组件E 1162的第二执行集1181。
在图11中,编译器/解释器120判断出第二执行集1181嵌套在第一执行集1168内。由于在第一执行集1168中识别出嵌套执行集,因此允许第一执行集1168中的组件的并发执行。为了达到该目的,在控制图生成过程期间,第二组件C 1158、第三组件D 1160、第四组件E 1162和第五组件J 1172各自被分组到不同的任务组(例如,第一任务组、第二任务组、第三任务组和第四任务组)。在数据处理图1100执行时,针对各任务组启动不同的任务(例如,针对用于执行第二组件C 1158的操作的第一任务组启动第一任务,针对用于执行第三组件D 1160的操作的第二任务组启动第二任务,针对用于执行第四组件E 1162的操作的第三任务组启动第三任务,以及针对用于执行第五组件J1172的操作的第四任务组启动第四任务)。在第一执行集1168中的各组件在单独的任务中执行的情况下,第三组件D 1160能够与第四组件E 1162和第五组件J 1172其中之一或两者并发地执行。
注意,也可以使用允许并发执行的组件到任务组(以及最终单独的任务)的其它分组。例如,第二组件C 1158和第三组件D 1160可被分组到相同的任务组并且最终在单个任务中执行,而不是被分组到单独的任务组。当然,第四组件E 1162和第五组件J 1172的操作执行的单个任务仍可以与第二组件C 1158和第三组件D 1160的操作执行的任务并发地执行。
3.3.3内部执行集并发识别
实现延迟最小化和效率之间的折衷的另一种方式包括判断执行集内是否存在任何可能的并发。例如,执行集1268中可能存在两个组件,其中两个组件中的第一个组件具有经由流而连接至这两个组件中的第二个组件的输入集合端口的输出集合端口(即,集合到集合端口连接)。在这种情况下,这两个组件具有被允许并发执行的可能性,即使它们处于相同的执行集中。
在一些示例中,在第一执行集中的两个或更多个组件可以并发运行的情况下,编译器/解释器120基于数据处理图的拓扑以及某些运行时特征来判断是否允许第一执行集中的操作的并发执行。如果在第一执行集中识别出任何可能的并发,则可以允许第一执行集中的组件并发执行。如果在第一执行集中未识别出可能的并发,则不允许第一执行集中的组件的并发执行。如果存在可能的并发,则可以存在运行时实际使用的不同并发级别。例如,可能的最高并发级别可以允许90%的组件并发执行;并且可以在运行时实际地使用(由所生成的代码实施)并发执行的组件的10%的降低并发级别以基于某些因素来作出折衷。
参考图12,典型的数据处理图1200从数据源A 1250接收输入数据,使用多个组件来处理输入数据,并且将处理数据的结果存储在第一数据宿H 1252和第二数据宿I 1254中。数据处理图1200的组件包括第一组件B 1256、第二组件C 1258、第三组件D 1260、第四组件E 1262、第五组件J 1272、第六组件F 1264和第七组件G 1266。
第一流1251将数据源1250的输出集合端口连接至第一组件B 1256的输入集合端口。第二流1253将第一组件B 1256的输出集合端口连接至第二组件C 1258的输入标量端口。注意,由于第二流1253将输出集合端口连接至输入标量端口,因此第一组件B 1256和第二组件C 1258之间存在第一执行集入口点1255。
第三流1257将第二组件C 1258的输出标量端口连接至第三组件D 1260的输入标量端口和第四组件E 1262的输入标量端口。
第四流1259将第三组件D 1260的输出标量端口连接至第六组件F 1264的输入集合端口。注意,由于第四流将输出标量端口连接至输入集合端口,因此在第三组件D 1260和第六组件F 1264之间存在第一执行集出口点1263。
第五流1277将第四组件E 1262的输出集合端口连接至第五组件J 1272的输入集合端口。
第六流1261将第五组件J 1272的输出标量端口连接至第七组件G 1266的输入集合端口。注意,由于第六流1261将输出标量端口连接至输入集合端口,因此在第五组件J 1272和第七组件G 1266之间存在第三执行集出口点1265。
第七流1267将第六组件F 1264的输出集合端口连接至第一数据宿H 1252的输入集合端口。第八流1269将第七组件G 1266的输出集合端口连接至第二数据宿I 1254的输入集合端口。
在编译器/解释器120准备供执行的数据处理图1200时,该编译器/解释器120首先进行执行集发现预处理过程以识别组件的潜在嵌套执行集的分层。对于图12中的典型数据处理图1200,执行集发现预处理过程识别单个执行集1268。该执行集1268由第一执行集入口点1255、第一执行集出口点1263和第三执行集出口点1265所界定。如从图中显而易见的,执行集1268包括第二组件C 1258、第三组件D 1260、第五组件J 1272、以及第四组件E 1262。
在图12中,编译器/解释器120还通过识别第四组件E 1262和第五组件J 1272之间的连接端口到连接端口的连接、以及执行集1268内的组件的整体拓扑,来识别执行集1268内可能的并发级别。由于在执行集1268中识别出可能的并发,因此允许执行集1268内的至少一些组件的并发执行。为了达到该目的,在控制图生成过程期间,第二组件C 1258、第三组件D 1260、第四组件E 1262和第五组件J 1272各自被分组到不同的任务组(例如,第一任务组、第二任务组、第三任务组和第四任务组)。各任务组包括一个或多个组件的操作,其中整个任务组由运行时将会启动的单个任务(例如,处理或线程)执行。将各组件分配至其自己的任务组实现了运行时的高并发级别。为了实施运行时的降低并发级别,多个组件可被分配至同一任务组,其中相应任务串行地(即,不并发地)执行组件的操作。
在数据处理图1200执行时,针对各任务组启动不同的任务(例如,针对用于执行第二组件C 1258的操作的第一任务组启动第一任务,针对用于执行第三组件D 1260的操作的第二任务组启动第二任务,针对用于执行第四组件E 1262的操作的第三任务组启动第三任务,以及针对用于执行第五组件J 1272的操作的第四任务组启动第四任务)。在执行集1268中的各组件在单独的任务中执行的情况下,第三组件D 1260能够与第四组件E 1262和第五组件J 1272其中之一或两者并发地执行。然而,根据组件的端口(诸如第二组件C 1258和第三组件D 1260之间以及第二组件1258和第四组件E 1262之间的连接串行端口等),可能仍然存在不同任务之间所实施的一些约束。
注意,也可以使用允许不同级别的并发执行的组件到任务组(以及最终单独的任务)的其它分组。例如,第二组件C 1258和第三组件D 1260可被分组到相同的任务组并且最终在单个任务中执行,而不是被分组到单独的任务组。还可以分配第四组件E 1262和第五组件J 1272的操作执行的单个任务组以及最终任务。然后,该单个任务可以与第二组件C 1258和第三组件D 1260的操作执行的任务并发地执行,只要第二组件C 1258在第四组件E 1262开始执行之前完成执行即可。因此,以编译器/解释器120所生成的代码表示的任务组的数量和组成能够实施与执行集中的组件相对应的整个操作组中的不同级别的并发。
4可选例
在一些示例中,如果执行集中的组件仅通过从输出标量端口到输入标量端口的连接(即,标量端口到标量端口的连接)彼此连接,则编译器/解释器120在单个任务组中自动分配执行集中的组件的操作,其中这些组件则被约束为利用单个任务串行执行。
一般来说,允许或不允许执行集内的特定组件之间的并发、改变并发级别的决策仅适用于执行集,而不必适用于组件或嵌套在执行集内(处于执行集分层的较低级别)的执行集。
在一些示例中,在给定执行集中不允许并发的情况下,确定执行集中的组件的拓扑排序顺序,并且以该拓扑排序顺序在单个任务中执行给定执行集中的组件的操作。
在一些示例中,潜在操作被定义为相对于启动任务所需的时间而言花费长时间来完成的操作。在一些示例中,潜在操作被定义为花费比启动任务所需的时间长至少三倍的时间的操作。在一些示例中,潜在操作被定义为花费比启动任务所需的时间长至少十倍的时间的操作。
在一些示例中,用户指定用于定义潜在操作的特征。在一些示例中,用户明确地指定哪些组件包括潜在操作。在一些示例中,用户可以明确地指定针对执行集的编译模式(即,并发或非并发)。
在一些示例中,上述的方法仅在执行集中存在并发执行的可能性的情况下进行。例如,编译器/解释器120可以在进行上述的方法之前游走数据处理图的包括于执行集中的部分,来判断是否可以进行并发执行。在一些示例中,编译器/解释器120确定数据流图的包括于执行集中的部分的最大并发。
上述的各示例突显了一个或多个组件的一个运行时特征,其中该运行时特征可能使执行集中的组件被编译为使得一个或多个组件并发地或顺次地执行。然而,执行集可以包括具有任意数量的这些特征(例如,潜在操作、嵌套执行集和隐式执行集等)的组合的组件。在一些示例中,如果执行集中的一个或多个组件包括表示相对于启动任务所需的时间、组件的操作将会花费长时间来完成的特征,则该执行集被编译为使得允许并发执行。
上述数据处理图编译方法可以例如使用执行适当软件指令的可编程计算系统来实现,或者可以在诸如现场可编程门阵列(FPGA)等的适当硬件中实现、或者以某种混合形式实现。例如,在编程的方法中,该软件可以包括在一个或多个编程或可编程计算系统(可以具有诸如分布式、客户端/服务器或网格式等的各种架构)上执行的一个或多个计算机程序中的过程,其中该一个或多个编程或可编程计算系统各自包括至少一个处理器、至少一个数据存储系统(包括易失性和/或非易失性存储器和/或存储元件)、至少一个用户接口(用于使用至少一个输入装置或端口来接收输入,并且用于使用至少一个输出装置或端口来提供输出)。该软件可以包括例如提供与数据处理图的设计、配置和执行有关的服务的较大程序的一个或多个模块。可以将程序的模块(例如,数据处理图的元素)实现为数据结构或符合数据存储库中所存储的数据模型的其它有组织数据。
软件能够在一段时间(例如,诸如动态RAM等的动态存储器装置的刷新周期之间的时间)内以非暂时性形式(诸如包含在易失性或非易失性存储介质或任何其它非暂时性介质中)、使用介质的物理性质(例如,表面凹区和凸区、磁畴或电荷)存储。在为加载指令所作的准备中,软件可以设置在诸如(利用通用或专用计算机系统或装置可读取的)CD-ROM或其它计算机可读介质等的有形、非暂时性介质上,或者可以经由网络的通信介质(例如,以编码在传播信号中的形式)传递至执行该软件的计算系统的有形、非暂时性介质。可以在专用计算机上、或者使用诸如协处理器或现场可编程门阵列(FPGA)或专用特定用途集成电路(ASIC)等的专用硬件来进行一些处理或所有处理。可以以利用不同的计算元件来进行软件所指定的计算的不同部分的分布式方式来实现该处理。优选将每一个这种计算机程序存储在通用或专用可编程计算机可读取的存储装置的计算机可读存储介质(例如,固态存储器或介质、或者磁性或光学介质)上或者下载至该存储介质,以在利用计算机读取存储装置介质以进行这里所述的处理的情况下配置计算机并使该计算机进行工作。本发明的系统还可被视为作为配置有计算机程序的有形、非暂时性介质来实现,其中如此配置成的介质使计算机以特定的预定义方式进行工作,以进行这里所述的处理步骤中的一个或多个。
已经描述了本发明的许多实施例。然而,应当理解,前述描述旨在示出而不是限制本发明的范围,该范围由以下权利要求书的范围限定。因此,其它实施例也在所附权利要求书的范围内。例如,可以在不偏离本发明的范围的情况下作出各种修改。另外,上述步骤中的一些可以是与顺序无关的,因此可以按照与所描述的顺序不同的顺序进行。
- 还没有人留言评论。精彩留言会获得点赞!