协同过滤推荐系统中基于时序熵的用户相似度计算方法与流程
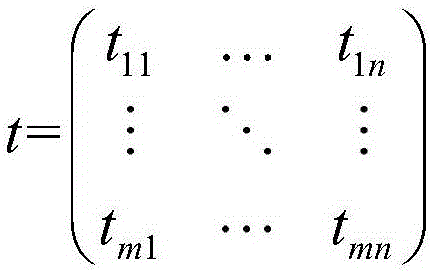
本发明涉及一种协同过滤推荐系统中基于时序熵的用户相似度计算方法。
背景技术:
随着互联网技术和信息技术的迅猛发展,互联网上的信息量急剧上升,用户快速搜到所需要的信息日益困难,人们能够获取更加丰富多样的信息资源的同时,也迫切需要在海量数据中准确快速地提取有用信息,在此背景下,个性化推荐系统应运而生,其应用也日益广泛。个性化推荐系统通过收集分析用户的特征信息和历史行为,推测用户的兴趣、喜好,从而为用户提供更准确的个性化服务,尤其在电子商务系统中个性化推荐系统的应用,能够为消费者智能提供满足其需求的商品同时,也给商家带来了巨大的商业利益,实现了商家与消费者的互利双赢,可以有效地解决互联网发展带来的信息过载的问题。
在众多个性化推荐技术中,协同过滤是目前最成功和应用最多的推荐技术,已广泛应用于电子商务系统中。其核心思想是基于用户-项目评分数据集,筛出与目标用户兴趣相似的用户作为最近邻居集,通过最近邻居对各项目的综合评分信息对目标用户对各项目的喜好程度作出预测,从而为目标用户作出相应的推荐。其优点在于不需要分析项目的各维度特征,可以更加方便地处理非结构化数据。但是,随着电子商务平台用户和商品数量的不断增加,用户评分极端稀疏,计算相似度未考虑各个共同评分项代表用户兴趣的程度不一样,导致传统的相似度计算方法对真实用户相似度评估误差较大,进而影响最近邻居的选取。
技术实现要素:
本发明的目的是提供一种计算精度较高的协同过滤推荐系统中用户相似度计算方法。本发明的计算方法,挖掘用户兴趣与时间的关系,时间越新的评分项,越能代表用户的兴趣变化方向,借鉴信息熵的计算方法,将与时间和项目有关的用户兴趣量化,即越新的评分项携带的用户兴趣信息量越多,则基于这些评分项的用户相似度越高,可解决数据稀疏度带来的相似度计算精准度影响,同时提高对用户兴趣方向的把握。为了达到上述目的,本发明采用如下的技术方案:
一种协同过滤推荐系统中基于时序熵的用户相似度计算方法,包括下列步骤:
(1)构建用户-项目评分矩阵;
(2)计算用户间评分相似度;
(3)计算时序熵相关度,计算某用户和目标用户共同评分项携带关于各自用户的兴趣信息量和各用户的所有评分项携带的兴趣信息量,借鉴信息熵的计算方式,求两用户共同评分项的兴趣信息量和所有评分项携带的兴趣信息量的比,两用户的信息量比值求乘积,得时序熵相关度;
(5)时序熵相似度等于评分相似度和时序熵相关度的乘积。
附图说明
图1是用户-项目评分矩阵。
图2是用户-项目时序矩阵。
图3是时序熵相似度计算流程图。
具体实施方式
本发明的具体实施方式是:
(1)首先采集数据,数据可以从推荐系统的数据库中获取,接着构建如图1所示的用户-项目评分矩阵。设用户总数为m,项目总数为n,Rij为用户i对项目j的评分,评分越高,则表示用户i对项目j的喜好度越大。
(2)计算评分相似度,我们采用经典的皮尔森相似度计算方法,计算方法如下式所示:
其中,a和b代表两个用户,sim(a,b)表示用户a和b之间的传统相似度,Rai表示用户a对项目i的评分,Iab表示两个用户的共同评分项集,表示用户a的评分均值,|Ia|表示用户a评价过的项目个数。
(3)计算时序熵相关度,某用户对某项目的评分时间越短,则该项目携带的用户兴趣信息量越大,共同评分项携带某用户与目标用户的兴趣信息量越多,则用户与目标用户的时序熵相关度越大,时序熵相关度计算方法如下:
其中,tai表示用户a对项目i评分距当前的时长,tbi表示用户b对项i评分距当前的时长,tamax表示用户a所有项评分时长中的最大值,tbmax表示用户b所有项评分时长中的最大值,α为影响系数,最后由实验结果确定其最佳正数值,前项式子中表示共同评分项中第i个项目携带的用户a的兴趣信息量,tai越小,则求得兴趣信息量越大,对Iab求和表示共同评分项携带的用户a的兴趣信息总量,对Ia求和表示用户a所有评分项携带的用户a的兴趣信息总量,相除求比值,后项关于用户b的式子同理。(4)时序熵相似度等于评分相似度和时序熵相关度的乘积,可以表示为:
simH(a,b)=β×sim(a,b)+(1-β)Ht
其中,β是比例系数,取值由实验结果确定。
- 还没有人留言评论。精彩留言会获得点赞!