基于眼动追踪的文本推荐方法与流程
本发明涉及文本推荐领域,特别是用户兴趣建模的方法。
背景技术:
文本推荐(Text Recommendation)作为典型的推荐服务,在发展迅速、巨大又无序的互联网信息空间中扮演着越来越重要的角色。文本推荐旨在帮助用户从海量的数据中找到自己感兴趣的内容,因而为了能够向用户提供更好的推荐服务,挖掘用户的偏好信息成为广大学者重点关注的问题。
基于内容的推荐(Content-based Recommendations)是当前研究最多的推荐方法之一。它根据历史信息(如评价、分享、收藏过的文档)构造用户偏好文档,计算推荐项目与用户偏好文档的相似度,将最相似的项目推荐给用户。其中两个重要的部分是分析文本的特征及用户偏好数据。近几年,在文本特征分析的研究中,Latent Dirichlet Allocation(LDA)作为一种语义挖掘方法被深入研究。LDA是文本挖掘领域中广泛使用的一种非监督机器学习技术,可以用来识别大规模文档集或语料库中潜藏的主题信息。David Newman等人于2006年最早提出了将主题模型用于语料分析的过程。该项研究通过LDA算法提取文档的主题模型,并依此为依据建立文档之间的相关性,生成文档的关系图谱。用户行为数据反馈包括显示反馈和隐式反馈。显示反馈需要用户对推荐的内容给出明确的评分或者以调查问卷的方式提前向系统提供自己的阅读偏好信息。虽然用户偏好提取能够更加精准,但是有研究表明,这种需要额外操作的反馈方式,对用户很不友好,并且由于隐私问题往往不能收集到足够的数据。相较而言,隐式反馈将用户在阅读过程中产生的行为、阅读的内容等作为反馈信息,交由系统后台进行处理、分析,提取用户的阅读偏好,不需要用户有额外的反馈操作,获取用户反馈的过程几乎不会被察觉,因而更容易被用户接受。Claypool等研究者针对隐式反馈的可靠性进行实验,发现“用户的阅读时间”、“滚轮在页面的滚动次数”与“用户是否喜欢该文章”存在着正向关系。然而简单的隐式相关反馈中,用户的阅读时间等行为只能反映用户对当前整篇文本的兴趣,而每篇文本本身包含了多个主题,传统的隐式反馈模糊了用户对每篇文本包含的多个主题空间的不同兴趣度,所以反馈信息会出现误差。另一方面,随着科技的发展,眼动追踪以精确的视觉捕捉技术成为学者研究的热门课题。在文本阅读过程中,它能将用户视觉获取信息的行为显性化,让我们有机会有数据基础去分析用户阅读过程中更加细节的主观认知情况。Chen等引入眼动追踪进行文本之间相似度比较时,研究用户阅读规律与习惯的研究时,发现对于不同文本形式以及文本内容,用户会选择不同的浏览轨迹和专注于某些特定词的阅读习惯。可见,眼动追踪技术能更精准的观察用户在阅读过程中的重点关注点,提高兴趣挖掘的准确性。
现阶段,LDA的研究大部分集中于本身对于文本内容的主题抽象过程,即客观因素,而眼动仪的应用专注于提供用户阅读规律、阅读偏好的数据,以进行探索或发现,即提供主观性质的结果模式。French等是利用眼动仪和LDA对儿童行为进行成功或失败预测,Ali等利用眼动仪与LDA进行需求追踪,这一类大多具体应用于某一类应用背景,并且多数是眼动仪与LDA分开使用,彼此之间没有联系,仅作为工具。而将LDA真正与眼动仪结合起来的研究,非常少。因此,在现有的研究基础上,本发明从眼动追踪的显性化数据中分析用户更为细致的主观认知情况,并且将用户的主观认知结合到客观数据中,得到更加个性化更有价值的用户的偏好信息,从而提高文本推荐的满意度。
技术实现要素:
本发明的目的主要是,根据用户的主观认知数据对用户做更准确的兴趣建模,提供一种更能让用户满意的文本推荐方法。
本发明的目的可以通过以下技术方案来实现:
一种基于眼动追踪的文本推荐方法,包括以下步骤:
1)根据已知语料库采用基于Gibbs Sampling的求解方法训练LDA主题模型,获得模型的参数矩阵。再根据训练好的LDA主题模型,计算新文本的主题分布和用户的历史阅读文本中词在主题中的客观分布情况。
2)采集眼动追踪的用户在阅读时的主观行为数据,转换数据格式,选取合适的行为特征计算用户阅读过程中对文本中各个词的关注度。
3)结合1)文本中词在主题中的客观分布情况和2)用户在阅读过程中对文本中各个词的关注度,计算用户在历史阅读文本中的兴趣主题分布。
4)根据1)中得到的新文本的主题分布和3)中得到的用户在历史阅读文本中的兴趣主题分布,计算JS相似度。并根据用户在上一次的选项排序,反馈出用户的兴趣变化情况,再动态调节推荐列表。
所述的步骤1)具体包括以下步骤:
11)假设语料库中共有D篇文本,dk表示第k篇文本,共有T个主题,tj表示第j个主题,共有W个单词(每篇文本的单词量<=W),wi表示第i个单词。Gibbs Sampling公式:
其中,表示单词wi属于文本dk的主题tj时的概率,表示除了单词wi外的其他词的主题归属向量,表示单词向量,表示主题tj在文本dk中的概率,表示单词wi在主题tj中的概率,表示属于主题tj的词被分配到文档dk中的次数,表示单词wi被分配到主题tj的次数,αj和βi是两个Dirichlet分布的参数。
根据已知语料库采用Gibbs Sampling公式训练LDA主题模型的流程如下:
随机初始化:对语料中每篇文本中的每个词w,随机的赋一个主题t;
重新扫描语料库,对每个词w,按照Gibbs Sampling公式重新采样它的主题,在语料中进行更新;
重复以上语料库的重新采样过程直到Gibbs Sampling收敛;
统计语料库的topic-word共现频率矩阵,该矩阵就是LDA的模型。
由topic-word共现频率矩阵计算每个单词在各个主题中的概率,即可得到模型的参数矩阵(表示各个主题在单词维度上的概率分布)。
12)根据训练好的LDA主题模型,计算新文本的主题分布(表示一篇文本在主题维度上的概率分布)的流程如下:
随机初始化:对当前文本中的每个词w,随机的赋一个主题t;
重新扫描当前文本,按照Gibbs Sampling公式(我们认为推导过程的是不变的,是由11)中训练的LDA模型提供的),对每个词w,重新采样它的主题;
重复以上过程直到Gibbs Sampling收敛;
统计文本中的主题分布,该分布就是
13)根据训练好的LDA主题模型,用户的历史阅读文本对语料库仍然是新文本,计算每一篇阅读文本中词在主题中的客观分布情况(tj,wi)(表示单词wi属于主题tj)的流程如下:
随机初始化:对当前文本中的每个词w,随机的赋一个主题t;
重新扫描当前文档,按照Gibbs Sampling公式(我们认为推导过程的是不变的,是由11)中训练的LDA模型提供的),对每个词w,重新采样它的主题;
重复以上过程直到Gibbs Sampling收敛;
提取文本中各个词的归属主题,即文本中词在主题中的客观分布情况(tj,wi)。
所述的步骤2)具体包括以下步骤:
21)在用户阅读文本的过程中,利用眼动仪采集用户阅读过程中的注视点,眼跳,回视,瞳孔变化等主观行为数据,并将其转换为后续计算所需要的数据格式;
22)在这里,我们选取用户阅读过程对单词wi的注视时间和瞳孔面积来计算用户阅读过程中对文本中各个词的关注度Ψ(wi):
其中系数μ+v=1,表示注视时间和瞳孔面积对关注度的影响系数。
所述的步骤3)具体包括以下步骤:
31)结合13)得到的每一篇阅读文本中词在主题中的客观分布情况(tj,wi)和22)得到的用户在阅读过程中对文本中各个词的关注度Ψ(wi),计算用户在历史阅读文本中的兴趣主题分布在主题tj的分量
其中αj是LDA训练过程得到的模型参数。
所述的步骤4)具体包括以下步骤:
41)根据12)得到的新文本的主题分布和31)得到的用户在历史阅读文本中的兴趣主题分布计算JS散度表示两者之间的相似度DJS(θ,θ′):
其中需要注意的是,JS散度值越小,相似度越高。
42)假设推荐列表长度为n,用户在上一次的选项排序为r,根据用户的选项反馈出用户的兴趣变化情况,计算综合历史阅读数据和当前阅读数据的JS散度Dall:
Dall=δ·Dh+τ·Dc
其中系数δ+τ=1,(n+2是为了避开0和1),Dh表示新文本与历史阅读数据的JS散度,Dc表示新文本与当前阅读数据的JS散度。如果用户的选项越靠前,说明用户选择的这篇文本非常符合用户的需求喜好,致使δ越小,τ越大,计算结果Dall越接近于新文本与当前这篇阅读文本的相似度Dc。根据Dall由小到大给新文本排序,选取前n项作为用户的推荐项。
与现有技术相比,本发明具有以下优点:
一、在用户阅读过程中,采用眼动仪采集更为准确的主观行为数据,进而更好的分析用户阅读习惯及阅读喜好。
二、结合LDA主题建模的客观数据与眼动追踪的主观行为数据,挖掘用户的阅读习惯及阅读喜好,达到更好的推荐效果。
附图说明
图1为用户阅读一篇文本的眼动追踪数据分析图
图2为基于眼动追踪的文本推荐方法构建模块图
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。
实施例:
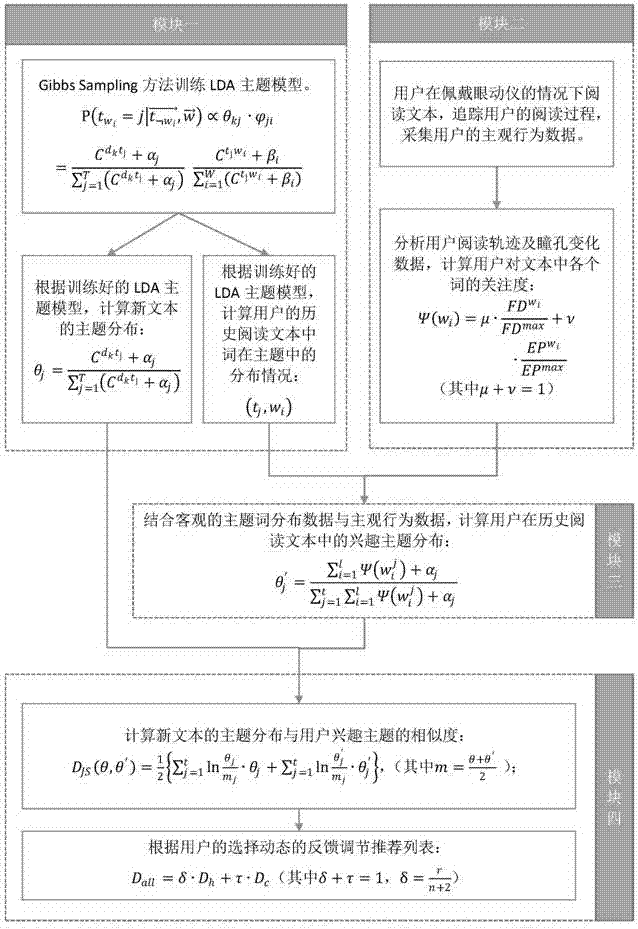
如图2所示,一种基于眼动追踪的文本推荐方法,共包括四个模块。在具体实施过程中,各个模块的协调工作及计算如下:
1)对应于模块一。根据已知语料库采用基于Gibbs Sampling的求解方法训练LDA主题模型,获得模型的参数矩阵。再根据训练好的LDA主题模型,计算新文本的主题分布和用户的历史阅读文本中词在主题中的客观分布情况。具体包括以下三个步骤,对应于模块一内的三个部分:
11)假设语料库中共有D篇文本,dk表示第k篇文本,共有T个主题,tj表示第j个主题,共有W个单词(每篇文本的单词量<=W),wi表示第i个单词。Gibbs Sampling公式:
其中,表示单词wi属于文本dk的主题tj时的概率,表示除了单词wi外的其他词的主题归属向量,表示单词向量,表示主题tj在文本dk中的概率,表示单词wi在主题tj中的概率,表示属于主题tj的词被分配到文档dk中的次数,表示单词wi被分配到主题tj的次数,αj和βi是两个Dirichlet分布的参数。
根据已知语料库采用Gibbs Sampling公式训练LDA主题模型的流程如下:
随机初始化:对语料中每篇文本中的每个词w,随机的赋一个主题t;
重新扫描语料库,对每个词w,按照Gibbs Sampling公式重新采样它的主题,在语料中进行更新;
重复以上语料库的重新采样过程直到Gibbs Sampling收敛;
统计语料库的topic-word共现频率矩阵,该矩阵就是LDA的模型。
由topic-word共现频率矩阵计算每个单词在各个主题中的概率,即可得到模型的参数矩阵(表示各个主题在单词维度上的概率分布)。
12)根据训练好的LDA主题模型,计算新文本的主题分布(表示一篇文本在主题维度上的概率分布)的流程如下:
随机初始化:对当前文本中的每个词w,随机的赋一个主题t;
重新扫描当前文本,按照Gibbs Sampling公式(我们认为推导过程的是不变的,是由11)中训练的LDA模型提供的),对每个词w,重新采样它的主题;
重复以上过程直到Gibbs Sampling收敛;
统计文本中的主题分布,该分布就是
13)根据训练好的LDA主题模型,用户的历史阅读文本对语料库仍然是新文本,计算每一篇阅读文本中词在主题中的客观分布情况(tj,wi)(表示单词wi属于主题tj)的流程如下:
随机初始化:对当前文本中的每个词w,随机的赋一个主题t;
重新扫描当前文档,按照Gibbs Sampling公式(我们认为推导过程的是不变的,是由11)中训练的LDA模型提供的),对每个词w,重新采样它的主题;
重复以上过程直到Gibbs Sampling收敛;
提取文本中各个词的归属主题,即文本中词在主题中的客观分布情况(tj,wi)。
2)对应于模块二。采集眼动追踪的用户在阅读时的主观行为数据(如图1),转换数据格式,选取合适的行为特征计算用户阅读过程中对文本中各个词的关注度。具体包括两个步骤,对应于模块二的两个部分:
21)在用户阅读文本的过程中,利用眼动仪采集用户阅读过程中的注视点,眼跳,回视,瞳孔变化等主观行为数据,并将其转换为后续计算所需要的数据格式;
22)在这里,我们选取用户阅读过程对单词wi的注视时间和瞳孔面积来计算用户阅读过程中对文本中各个词的关注度Ψ(wi):
其中系数μ+v=1,表示注视时间和瞳孔面积对关注度的影响系数,FDmax表示最长的注视时间,EPmax表示最大的瞳孔面积。
3)对应于模块三。结合1)文本中词在主题中的客观分布情况和2)用户在阅读过程中对文本中各个词的关注度,计算用户在历史阅读文本中的兴趣主题分布。具体包括以下一个步骤,对应于模块三的内容:
31)结合13)得到的每一篇阅读文本中词在主题中的客观分布情况(tj,wi)和22)得到的用户在阅读过程中对文本中各个词的关注度Ψ(wi),计算用户在历史阅读文本中的兴趣主题分布在主题tj的分量
其中αj是LDA训练过程得到的模型参数。
4)对应于模块四。根据1)中得到的新文本的主题分布和3)中得到的用户在历史阅读文本中的兴趣主题分布,计算JS相似度。并根据用户在上一次的选项排序,反馈出用户的兴趣变化情况,再动态调节推荐列表。具体包括以下两个步骤,对应于模块四的两个部分:
41)根据12)得到的新文本的主题分布和31)得到的用户在历史阅读文本中的兴趣主题分布计算JS散度表示两者之间的相似度DJS(θ,θ′):
其中需要注意的是,JS散度值越小,相似度越高。
42)假设推荐列表长度为n,用户在上一次的选项排序为r,根据用户的选项反馈出用户的兴趣变化情况,计算综合历史阅读数据和当前阅读数据的JS散度Dall:
Dall=δ·Dh+τ·Dc
其中系数δ+τ=1,(n+2是为了避开0和1),Dh表示新文本与历史阅读数据的JS散度,Dc表示新文本与当前阅读数据的JS散度。如果用户的选项越靠前,说明用户选择的这篇文本非常符合用户的需求喜好,致使δ越小,τ越大,计算结果Dall越接近于新文本与当前这篇阅读文本的相似度Dc。根据Dall由小到大给新文本排序,选取前n项作为用户的推荐项。
- 还没有人留言评论。精彩留言会获得点赞!