实体热门度的计算方法及装置、应用方法及装置与流程
本发明涉及人工智能对话系统,尤其涉及知识图谱中实体热门度的计算方法及装置、知识图谱中实体热门度在人机对话中的应用方法及装置。
背景技术:
含知识图谱的人工智能对话系统,比传统语料检索的对话系统的优势在于其多具备了知识和常识方面的回答能力,人在与这类人工智能对话系统聊天时能感受到机器人和人一样能记忆知识,懂知识,聊知识。含知识图谱的人工智能对话系统的结构流程通常是用户输入句,闲聊类回答与基于知识图谱的知识类回答作为并行处理(各自给出候选回答并给一个自信分数,分数越高越希望出此结果),最后由一个最终排序器从所有候选回答中挑选最合适的回送给用户。
当知识图谱的实体(词条)数量达到百万千万甚至上亿的数量级的时候,实体(词条)会大量涉及日常用语,例如:我是谁(电影名),你好(歌曲名)等等。因此基于知识图谱的知识类回答需要做到:判别用户输入句的意图是否想问知识;所问词条是否属于日常用语;触发知识类回答是否会抢答闲聊类的回答模块;如何设置回答自信分数等问题。不能解决这类问题就会造成知识类回答抢答了原本应该触发的闲聊;另外,同名实体触发的优先级问题也是需要解决的。
技术实现要素:
本发明的目的是提供知识图谱中实体热门度的计算方法及装置、知识图谱中实体热门度在人机对话中的应用方法及装置,旨在解决现有的人工智能对话系统在人机对话过程中遇到同名实体时,无法根据用户输入句的意图确定应该触发知识类回答还是闲聊类回答,以及同名实体触发的优先级无法确定的问题。
本发明解决其技术问题所采用的技术方案是:
一种知识图谱中实体热门度的计算方法,包括:
抓取知识图谱中实体的百科页面,对所述实体的百科页面的基础属性进行统计,获取基础属性的统计结果;所述基础属性包括属性数量、链接数量、页面篇幅、出品日期/上映时间、百科页面浏览次数统计、百科页面最近更新统计、日常用语的实体出现频率中的一种或多种;
根据所述基础属性的统计结果,设置各基础属性的初始热门度;
对各基础属性的初始热门度进行归一化处理,获取各基础属性的归一化热门度;
获取各基础属性的加权系数;
根据各基础属性的加权系数,对各基础属性的归一化热门度进行加权求和,获取实体热门度。
在上述实施例的基础上,进一步地,还包括:
定期更新实体热门度。
在上述实施例的基础上,进一步地,所述定期更新实体热门度的步骤,具体为:
对各基础属性的初始热门度进行更新;
根据更新后的各基础属性的初始热门度,对各基础属性的归一化热门度进行更新;
根据更新后的各基础属性的归一化热门度,对实体热门度进行更新;或者,
根据搜索网站的热搜榜单、排名及排名变化,获取热搜数据;
对社区网站的短评与长评按时间序列进行计数,获取社区数据;
对人机对话记录中的实体按时间序列进行计数,获取对话数据;
将所述热搜数据、所述社区数据、所述对话数据作为标定数据集,根据所述标定数据集,对各基础属性的加权系数进行更新;
根据更新后的各基础属性的加权系数,对实体热门度进行更新。
在上述任意实施例的基础上,进一步地,还包括:
对知识图谱中相邻实体的实体热门度进行修正。
一种知识图谱中实体热门度在人机对话中的应用方法,包括:
根据用户输入的信息,获取知识类回答和闲聊类回答;所述知识类回答中包括实体;
上述任一项实施例中的知识图谱中实体热门度的计算方法;
根据实体热门度,获取知识类回答分数;
获取闲聊类回答分数;
根据所述知识类回答分数、所述闲聊类回答分数,对知识类回答和闲聊类回答进行排序,获取排序结果;
根据所述排序结果,对用户进行回应。
一种知识图谱中实体热门度的计算装置,包括:
统计模块,用于抓取知识图谱中实体的百科页面,对所述实体的百科页面的基础属性进行统计,获取基础属性的统计结果;所述基础属性包括属性数量、链接数量、页面篇幅、出品日期/上映时间、百科页面浏览次数统计、百科页面最近更新统计、日常用语的实体出现频率中的一种或多种;
设置模块,用于根据所述基础属性的统计结果,设置各基础属性的初始热门度;
归一化模块,用于对各基础属性的初始热门度进行归一化处理,获取各基础属性的归一化热门度;
系数获取模块,用于获取各基础属性的加权系数;
计算模块,用于根据各基础属性的加权系数,对各基础属性的归一化热门度进行加权求和,获取实体热门度。
在上述实施例的基础上,进一步地,还包括:
更新模块,用于定期更新实体热门度。
在上述实施例的基础上,进一步地,所述更新模块用于:
对各基础属性的初始热门度进行更新;
根据更新后的各基础属性的初始热门度,对各基础属性的归一化热门度进行更新;
根据更新后的各基础属性的归一化热门度,对实体热门度进行更新;或者,
根据搜索网站的热搜榜单、排名及排名变化,获取热搜数据;
对社区网站的短评与长评按时间序列进行计数,获取社区数据;
对人机对话记录中的实体按时间序列进行计数,获取对话数据;
将所述热搜数据、所述社区数据、所述对话数据作为标定数据集,根据所述标定数据集,对各基础属性的加权系数进行更新;
根据更新后的各基础属性的加权系数,对实体热门度进行更新。
在上述任意实施例的基础上,进一步地,还包括:
修正模块,用于对知识图谱中相邻实体的实体热门度进行修正。
一种知识图谱中实体热门度在人机对话中的应用装置,包括:
回答获取模块,用于根据用户输入的信息,获取知识类回答和闲聊类回答;所述知识类回答中包括实体;
上述任一项实施例中的知识图谱中实体热门度的计算装置;
第一分数模块,用于根据实体热门度,获取知识类回答分数;
第二分数模块,用于获取闲聊类回答分数;
排序模块,用于根据所述知识类回答分数、所述闲聊类回答分数,对知识类回答和闲聊类回答进行排序,获取排序结果;
回应模块,用于根据所述排序结果,对用户进行回应。
本发明的有益效果是:
本发明提供了知识图谱中实体热门度的计算方法及装置、知识图谱中实体热门度在人机对话中的应用方法及装置,通过对知识图谱中实体热门度的计算,将其应用在人机对话过程中,使知识类的问答的给分能有效得到定量化。本发明实现了知识类回答的自信分数设定,减少日常用语抢答闲聊类的回答;实现了在人与情感聊天机器人对话中的话题延伸,比如对话中聊到某一话题,机器人可以主动发问相关热门词条的应用;实现了知识类回答中对于实体多义词的处理,在对话上下文没出现其他线索时输出默认(热门度最高)实体词条的回答。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1示出了本发明实施例提供的知识图谱中实体热门度的计算方法的流程图;
图2示出了本发明实施例提供的知识图谱中实体热门度的计算装置的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不限定本发明。
具体实施例一
如图1所示,本发明实施例提供了一种知识图谱中实体热门度的计算方法,包括以下步骤。
步骤S101,抓取知识图谱中实体的百科页面,对所述实体的百科页面的基础属性进行统计,获取基础属性的统计结果;本发明实施例对基础属性不做限定,所述基础属性可以包括属性数量、链接数量、页面篇幅、出品日期/上映时间、百科页面浏览次数统计、百科页面最近更新统计、日常用语的实体出现频率中的一种或多种。
步骤S102,根据所述基础属性的统计结果,设置各基础属性的初始热门度。
步骤S103,对各基础属性的初始热门度进行归一化处理,获取各基础属性的归一化热门度。
步骤S104,获取各基础属性的加权系数。
步骤S105,根据各基础属性的加权系数,对各基础属性的归一化热门度进行加权求和,获取实体热门度。
本发明实施例对步骤S104中获取各基础属性的加权系数的方式不做限定,优选的,可以抽取多个实体作为样本,并将样本人工标注成热门样本或冷门样本,再针对被标注的热门样本和冷门样本,利用机器学习中的逻辑回归算法,训练出各基础属性的加权系数。
本发明实施例通过对知识图谱中实体热门度的计算,将其应用在人机对话过程中,使知识类的问答的给分能有效得到定量化。
本发明实施例中,属性数量指的是基础属性的数量,一般的百科页面,社区类词条页面,都会有此词条的一些基础属性,例如如果是电影的话,属性可以包含:中文名,英文名,发行时间,导演,演员,评分。属性数量的多少与实体词条热门度的大小由发现得出是正相关的。
本发明实施例中,链接数量指的是链接到其他实体词条页面的链接数的统计,例如在实体词条页面中的介绍性内容中包含其他的实体词条时,会有链接到其他实体词条的页面,链接数量就是对此类链接数的统计。链接数量的多少与实体词条热门度的大小由发现得出是正相关的。
本发明实施例中,页面篇幅指的是实体词条页面中的字数,字数统计包括简介,特有类别介绍,比如:电影词条会有剧情梗概,影评,人物介绍;人物词条会有成长经历,第一桶金;工具类词条会有应用范围,原理。页面篇幅的长短与实体词条热门度的大小由发现得出是正相关的。
本发明实施例中,出品日期/上映时间的统计大多针对影视作品,书刊杂志。在其他基本信息统计相同时,离当前时间上越接近的热门度越高。
本发明实施例中,百科页面浏览次数统计指的是页面真实被访问次数的统计。页面浏览次数的多少与实体词条热门度的大小由发现得出是正相关的。
本发明实施例中,百科页面最近更新统计指的是实体词条页面最近一次被更新的时间。在其他基础信息统计相同时,越最近被更新的越可能是热门词条,即实体热门度越高。
本发明实施例中,日常用语的实体出现频率指的是实体在日常用语里的出现频率。一类直接用法是如果频率高就给热门度减分;另一类用法是人机对话中应用时,结合热门度对机器人回答的分数进行分数调整。假设有两个相同热门度的词条,比如:天黑请闭眼(一类社交游戏)和你好(即是日常用语,也是耀乐团的演唱歌曲,李国祥演唱歌曲,艾梦萌演唱歌曲,综艺节目名),显然“你好”这个词在日常用语里的出现频率更高,更被人当成日常用语。
举例来说,实体词条“姚明”,在某百科页面中,名字是“姚明”的存在多种多义词义项:(一)姚明(中职联董事长兼总经理),初始热门度计算中:属性数量=29;链接数量=50;页面篇幅=5533;百科编辑次数=984;页面浏览次数=1亿6千万等等;定期更新机制下,此姚明词条处于热搜榜的人物风云榜中等等;知识图谱中的关系中,妻子“叶莉”,队友“易建联”等也均为热门度较高的实体。(二)姚明(中国一级作曲家),初始热门度计算中:属性数量=11;链接数量=53;页面篇幅=999;百科编辑次数=35;页面浏览次数=6百多万;定期更新机制下,此姚明词条并不处于任何热搜榜中;知识图谱中其有关系的实体也不是热门度高的实体。
由此得到的(一)姚明(中职联董事长兼总经理)的热门度较高,假设定分为0至1分的话,为0.98;(二)姚明(中国一级作曲家)的热门度定分为0.45分。
优选的,本发明实施例还可以包括:步骤S106,定期更新实体热门度。
本发明实施例对实体热门度的更新方式不做限定,优选的,所述定期更新实体热门度的步骤,可以具体为:对各基础属性的初始热门度进行更新;根据更新后的各基础属性的初始热门度,对各基础属性的归一化热门度进行更新;根据更新后的各基础属性的归一化热门度,对实体热门度进行更新;或者,根据搜索网站的热搜榜单、排名及排名变化,获取热搜数据;对社区网站的短评与长评按时间序列进行计数,获取社区数据;对人机对话记录中的实体按时间序列进行计数,获取对话数据;将所述热搜数据、所述社区数据、所述对话数据作为标定数据集,根据所述标定数据集,对各基础属性的加权系数进行更新;根据更新后的各基础属性的加权系数,对实体热门度进行更新。本发明实施例对加权系数的更新算法不做限定,优选的,其可以为基于机器学习重排序的算法。
本发明实施例对热搜数据中排名变化的利用方法不做限定,优选的,可以根据热搜数据对初始热门度进行加分或者减分,例如热搜数据中排名上升为加分;下降为减分;按变化程度动态调分大小。
本发明实施例中,社区数据主要针对影视作品和书刊,此类在社区类网站会有评论,对评论按时间求和计数,且区分评论的长短和质量,按照评论的时间作为加权求和系数的参考,具体的,可以是离现在越近的系数越大。例如1年前的10条评论会区别于昨天晚上的10条评论;而昨天晚上的10条短评也会区别于昨天晚上的10条长评;昨天晚上的10条3星短评也会区别于昨天晚上的10条5星长评。计数结果的用法可以为:一直接加分;二做标定数据集的参考,引入机器学习重排序。
本发明实施例中,对话数据的获取类似社区数据,只是要更换数据源,可以做成所有用户通用的计数;也可以做成对每个用户根据喜好习惯客制化的计数。热门度计算可以是对所有用户通用的一套体系分值;也可以是对每个用户客制化的体系分值。
优选的,本发明实施例的计算方法还可以包括:步骤S107,对知识图谱中相邻实体的实体热门度进行修正。在知识图谱中,一个节点是一个词条实体,储存了实体的所有属性。两个节点的关系储存了两个节点所代表的两个实体的关系和关系的所有属性。举个例子,比如实体A“姚明”,实体B“叶莉”,他们在只是图谱中分别是以两个节点的形式存在的,各自的属性存于各自的节点中(比如身高,简介,主要荣誉)。他们的关系(具有方向性)为A用关系R1“妻子”指向B;B用关系R2“丈夫”指向A。通俗的语言描述A—R1—>B是“姚明(A)的妻子(R1)是叶莉(B)”;A<—R2—B是“叶莉(B)的丈夫(R2)是姚明(A)”。当然,关系不一定只限于人和人的,是可以多样的,比如“刘德华(A)的代表作品(R)有无间道(B)”,“无间道(B)的主演(R)有刘德华(A)”,还可以是:“白色(A)属于(R)颜色(B)”。这里对有关系的相邻实体的热门度修正的目的是在得到各个实体的热门度时,由于有关系的实体间存在相互内在影响,比如实体“姚明”的热门度高了,连带把关系“妻子”的实体“叶莉”;关系“女儿”的实体“姚沁蕾”的热门度也带高了。这类实体热门度排序问题类似于PageRank的网页排序问题:实体的热门度相当于网页的排名;实体间的关系相当于网页间的链接跳转(即实体A到实体B的关系相当于页面A到页面B的跳转)如此可以把问题转化为利用PageRank类似的衍生算法对知识图谱中的所有实体的热门度进行再一次的数值修正和排序。实验发现通过调整关系传递热门度的百分比能达到很好的收敛效果。
在上述的具体实施例一中,提供了知识图谱中实体热门度的计算方法,与之相对应的,本申请还提供知识图谱中实体热门度的计算装置。由于装置实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的装置实施例仅仅是示意性的。
具体实施例二
本发明实施例提供了一种知识图谱中实体热门度在人机对话中的应用方法,包括:根据用户输入的信息,获取知识类回答和闲聊类回答;所述知识类回答中包括实体;具体实施例一中任一项实施例中的知识图谱中实体热门度的计算方法,用于计算得到实体热门度;根据实体热门度,获取知识类回答分数;获取闲聊类回答分数;根据所述知识类回答分数、所述闲聊类回答分数,对知识类回答和闲聊类回答进行排序,获取排序结果;根据所述排序结果,对用户进行回应。
本发明实施例实现了知识类回答的自信分数设定,减少日常用语抢答闲聊类的回答;实现了在人与情感聊天机器人对话中的话题延伸,比如对话中聊到某一话题,机器人可以主动发问相关热门词条的应用;实现了知识类回答中对于实体多义词的处理,在对话上下文没出现其他线索时输出默认实体词条的回答。默认实体词条可以为实体热门度最高的实体词条。
当用户与机器人聊天过程中,知识类的回答根据第一部分的实体热门度,给予回答的分数,而最终排序器会根据所有模块(包括知识类的,闲聊类的)给的回答和分数,做选择最后真正恢复给用户。因此,热门度越高的词条的知识类答案,分数也越高,是正相关。
从实体词条的热门度(包含另一维度:实体词条在日常用于中的词频)对于知识类的回答的定分机制有以下类别:
(i)用户的一句话就是一个实体词条或者此实体词条的同义词。比如:用户问:“周杰伦”或者“周董”。此类会根据上下文做判定:
(i.a)如果上一轮的历史人机对话记录为,机器人发问,此轮用户是在回答,比如机器人:“你最喜欢的歌手是谁”,用户:“周杰伦”;此时分数要在热门度的基础上调低,防止出知识类的回答而显得不合适。
(i.b)如果上一轮的历史人机对话记录判定此时用户是在发起一个话题,相当于用户想机器人回答此实体词条“周杰伦”的介绍。此时分数要在热门度的基础上调高,知识类的介绍类回答或根据知识推理的回答需要变成高分出结果。
(i.c)如果上一轮的历史人机对话记录没有足够信心判断,就根据实体词条的热门度给分,由于冷门词条的热门度低,因此此时知识类回答的分数也低,也一定程度上防止了冷门词条(或日常用语里词频高的词条)的不合适的抢答。
(ii)用户问一句意图是介绍实体词条知识的句子或者是问实体词条的属性或者是问实体词条的关系时的句子,比如“你知道周杰伦是谁吗”或者“你知道周杰伦的代表作品吗”或者“周杰伦的妻子是谁”,这类按照问知识的意图分类器的信心值以及词条热度结合打分。
(iii)用户问多个实体词条时,比如“周杰伦和昆凌是什么关系”等。此时回答分数根据问知识的意图分类器的信心值和句子中词条的热门度的组合打分。
具体实施例一中实体“姚明”的例子,在人机对话中的体现大致为:
(1)知识类回答的自信分数设定,对2个姚明的问答按照热门度给回答定分,获取知识类回答分数。
(2)在人机对话中的话题延伸,比如对话中聊到某一话题,机器人可以主动发问相关热门词条等应用。例如用户问到“姚明”,机器人可以根据其相关相邻热门实体进行附加回答,例如说“他最近有XX的新闻哦”再附加一句“对了,他的好朋友易建联最近去湖人打球了。”
(3)知识类回答中对于实体多义词的处理,在对话上下文没出现其他线索时输出默认(热门度最高)实体词条的回答,例如用户问:“你知道姚明吗”,给出的就是姚明(中职联董事长兼总经理)这个姚明的介绍或者相关的知识推理回答。
应用本发明后,在人机对话中,知识类的问答的给分能有效得到定量化。能解决下列问题:
(1)知识类回答的自信分数设定,减少日常用语抢答闲聊类的回答。例如对于冷门词条电影《我是谁》,用户问:“我是谁”,知识类按照词条的热门度并根据上述(i)的规则打分偏低,使得闲聊类回答能出结果;用户问:“你知道我是谁这本电影吗”,知识类回答按照词条的热门度并根据上述(ii)的规则打分偏高,闲聊类不回答,知识类回答。
(2)在人与情感聊天机器人对话中的话题延伸,比如对话中聊到某一话题,机器人可以主动发问相关热门词条等应用。例如用户问:“今天NBA(美职篮)有湖人队比赛吗”,而词条“易建联”去了“湖人队”打球最近热门度较高,因此机器人可以根据“易建联”和“湖人队”在知识图谱中所存的三元组(实体A,关系R,实体B)=(易建联,现在效力于,湖人队)来回答“今天湖人队没比赛,明天XX时会打XX队。对了,易建联在湖人打球了你知道吗”。
(3)知识类回答中对于实体多义词的处理,在对话上下文没出现其他线索时输出默认(热门度最高)实体词条的回答,例如用户问:“你知道姚明吗”,返回的热门度最高的词条为前篮球运动员姚明的知识类回答。(当然有上下文线索的时候,根据线索回答实体词条,例如“你知道作曲家姚明吗”,回答就是中国一级作曲家姚明的知识类回答)。
在上述的具体实施例二中,提供了知识图谱中实体热门度在人机对话中的应用方法,与之相对应的,本申请还提供知识图谱中实体热门度在人机对话中的应用装置。由于装置实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的装置实施例仅仅是示意性的。
具体实施例三
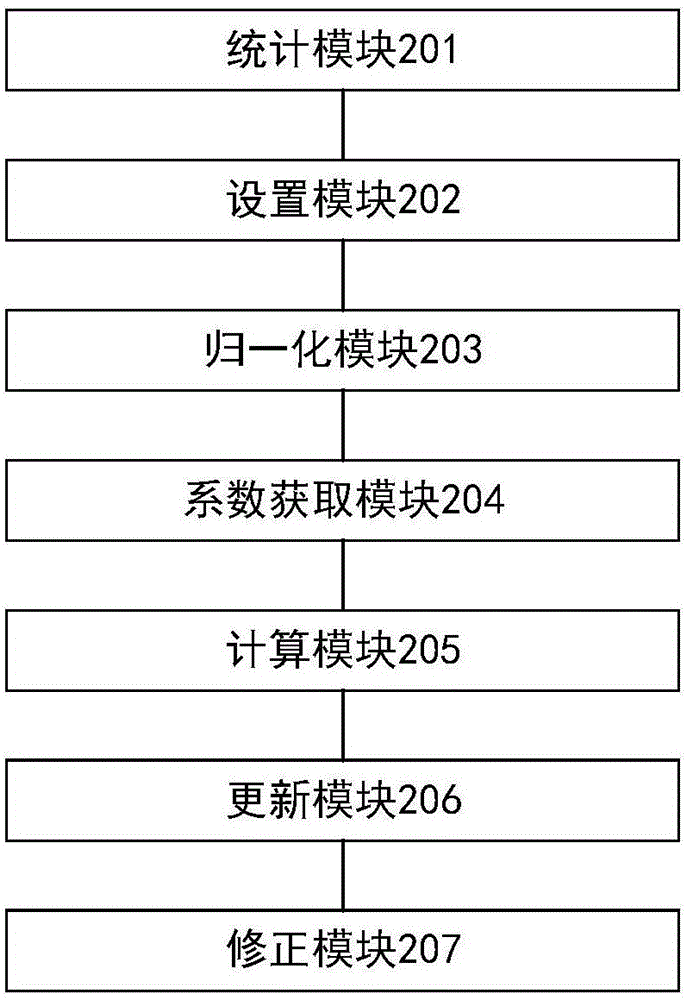
如图2所示,本发明实施例提供了一种知识图谱中实体热门度的计算装置,包括以下模块。
统计模块201,用于抓取知识图谱中实体的百科页面,对所述实体的百科页面的基础属性进行统计,获取基础属性的统计结果;所述基础属性包括属性数量、链接数量、页面篇幅、出品日期/上映时间、百科页面浏览次数统计、百科页面最近更新统计、日常用语的实体出现频率中的一种或多种。
设置模块202,用于根据所述基础属性的统计结果,设置各基础属性的初始热门度。
归一化模块203,用于对各基础属性的初始热门度进行归一化处理,获取各基础属性的归一化热门度。
系数获取模块204,用于获取各基础属性的加权系数。
计算模块205,用于根据各基础属性的加权系数,对各基础属性的归一化热门度进行加权求和,获取实体热门度。
本发明对系数获取模块204获取各基础属性的加权系数的方式不做限定,优选的,系数获取模块204可以用于抽取多个实体作为样本,并将样本人工标注成热门样本或冷门样本,再针对被标注的热门样本和冷门样本,利用机器学习中的逻辑回归算法,训练出各基础属性的加权系数。
本发明实施例通过对知识图谱中实体热门度的计算,将其应用在人机对话过程中,使知识类的问答的给分能有效得到定量化。
优选的,本发明实施例还可以包括:更新模块206,用于定期更新实体热门度。
本发明实施例对更新模块不做限定,优选的,所述更新模块可以用于:对各基础属性的初始热门度进行更新;根据更新后的各基础属性的初始热门度,对各基础属性的归一化热门度进行更新;根据更新后的各基础属性的归一化热门度,对实体热门度进行更新;或者,根据搜索网站的热搜榜单、排名及排名变化,获取热搜数据;对社区网站的短评与长评按时间序列进行计数,获取社区数据;对人机对话记录中的实体按时间序列进行计数,获取对话数据;将所述热搜数据、所述社区数据、所述对话数据作为标定数据集,根据所述标定数据集,对各基础属性的加权系数进行更新;根据更新后的各基础属性的加权系数,对实体热门度进行更新。
优选的,本发明实施例还可以包括修正模块207,用于对知识图谱中相邻实体的实体热门度进行修正。
具体实施例四
本发明实施例提供了一种知识图谱中实体热门度在人机对话中的应用装置,包括:回答获取模块,用于根据用户输入的信息,获取知识类回答和闲聊类回答;所述知识类回答中包括实体;上述任一项实施例中的知识图谱中实体热门度的计算装置;第一分数模块,用于根据实体热门度,获取知识类回答分数;第二分数模块,用于获取闲聊类回答分数;排序模块,用于根据所述知识类回答分数、所述闲聊类回答分数,对知识类回答和闲聊类回答进行排序,获取排序结果;回应模块,用于根据所述排序结果,对用户进行回应。
本发明实施例实现了知识类回答的自信分数设定,减少日常用语抢答闲聊类的回答;实现了在人与情感聊天机器人对话中的话题延伸,比如对话中聊到某一话题,机器人可以主动发问相关热门词条的应用;实现了知识类回答中对于实体多义词的处理,在对话上下文没出现其他线索时输出默认实体词条的回答。默认实体词条可以为实体热门度最高的实体词条。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。尽管本发明已进行了一定程度的描述,明显地,在不脱离本发明的精神和范围的条件下,可进行各个条件的适当变化。可以理解,本发明不限于所述实施方案,而归于权利要求的范围,其包括所述每个因素的等同替换。
- 还没有人留言评论。精彩留言会获得点赞!