基于粒子群优化算法的视频流特征选择与分类方法与流程
本发明属于模式识别与分类技术领域,特别涉及一种基于粒子群优化算法的视频流特征选择与分类方法。
背景技术:
随着互联网和流媒体技术的迅速发展,网络中的视频业务的增长尤为迅速。与此同时,网络中新的应用和协议的不断快速出现,使得网络环境更加复杂。各种类型的网络应用和网络流量的急速增加,给网络服务提供商带来了极大的挑战。如何有效地进行网络管理、保证不同业务的服务质量和用户的信息安全已成为迫切需要解决的问题。对于网络服务提供商和网络环境管理者来说,快速准确地识别出网络中的不同业务流是一种行之有效的解决方案。
传统的网络流量识别和分类方法主要有基于端口的方法、基于深度包检测的方法。基于端口的识别方法是根据国际互联网代理成员管理局建议的端口号来区分不同的网络应用,随着动态端口号的广泛应用,使得这种方法的识别效率和分类准确度不高。基于深度包检测的方法的原理是通过解析数据包的载荷,与已知协议中特定的签名进行比较,从而区分不同的业务。但是随着网络数据加密的普及和用户隐私保护等问题,导致基于深度包检测的网络流量分类方法不再适用。基于统计特征的方法通过提取数据流的统计特征对数据流进行分类。这种方法既可以克服传统方法的缺点,又具有较高的准确性和稳定性。因此,基于网络流统计特征结合机器学习方法被广泛地应用到网络业务流识别领域。
从网络业务流可以提取大量的统计特征,如何选择合理的特征组合是提高分类精度的关键所在。许多研究表明,特征之间的不相关或冗余的特征会引发过拟合问题,进而严重影响分类结果的准确性。同时,高维的特征集合还会给分类器带来大量的计算开销和时延。因此,选取简单、容易获取的特征组合对分类器性能的提高有着重要的作用。
技术实现要素:
本发明的目的在于针对网络视频业务流的统计特征选择以及识别分类问题,提出了一种基于粒子群优化算法的视频流特征选择与分类方法,该方法针对在线标清视频(非直播)、在线高清视频(非直播)、在线超清视频(非直播)、在线直播视频、HTTP 下载、即时通信类视频、P2P类视频七种业务进行分析和研究,提出一种基于粒子群优化算法的视频流特征选择方法,经过三层SVM级联分类器对原始的视频业务流进行分类。实验结果表明,本发明方法能够比现有同类方法获得更高的分类准确率。
为实现上述目的,本发明提出的技术方案是一种基于粒子群优化算法的视频流特征选择与分类方法,包括以下步骤:
步骤1:在开放的互联网环境中使用网络封包分析软件获取所需的实验数据,然后对数据包进行过滤,最后对这些网络视频业务流进行基本的统计特征计算;
步骤2:对上述计算得出的视频业务流的统计特征进行分析,选择出能有效区分业务流的特征组合;
步骤3:根据设计的三层SVM级联分类器对原始的视频业务流进行分类实验,得到最终的分类结果。
进一步,上述步骤1又具体包括:
步骤1-1:在开放的互联网环境中,通过网络封包分析软件抓取所需的视频业务流数据,然后对原始的数据进行简单预处理,转换成标准的五元组文本格式,即数据包到达的时间、源IP地址、目的IP地址、协议、数据包分组大小;
步骤1-2:对数据包过滤是指滤除不感兴趣或者不会对分类结果产生影响的数据包;
步骤1-3:对原始视频流的标准五元组文件进行基本的统计特征计算,这些特征包括:包大小、包大小的均值与方差、包大小信息熵、包间隔的均值与方差、字节速率、分组速率、上下行字节数之比、上下行包大小之比。
上述步骤2还具体包括:
步骤2-1:对所有视频业务流的统计特征进行离散化操作,降低特征选择过程中的计算开销;
步骤2-2:利用特征权重算法计算每个统计特征的权重;
步骤2-3:根据特征权重的排名,去掉部分与类别关联较小的特征,选取权重最大的N个特征,降低原始特征空间的维数,减少后续操作的计算复杂度;
步骤2-3:在上一步选取的N个特征子集中,选取特征权重排名靠前的M个特征作为先验知识,指导粒子群优化算法的种群初始化,将每个粒子的初始位置设为最优位置;迭代次数设为1;
步骤2-4:将不一致率作为粒子群优化算法的适应度函数,利用适应度函数计算粒子的整体适应度,将样本实例中的一个特征组合称为一个模式,特征子集的所有模式的不一致数,就等于该模式出现的样本总数减去出现次数最多的某一类标签的样本数,不一致率就等于不一致数除以样本总数;
步骤2-5:如果当前粒子的适应度小于粒子自身最优位置的适应度,将粒子自身最优位置更新为当前位置;如果粒子自身最优位置的整体适应度小于种群的最优位置的适应度,将种群的最优位置更新为粒子自身最优位置;
步骤2-6:根据当前粒子的位置和速度信息更新粒子群的位置和速度;
步骤2-7:若满足最大迭代次数或不一致率在迭代过程中持续不变,则输出最优解;否则,重复步骤2-5到步骤2-6。
更进一步,上述步骤2-3中的N优选为10,M优选为2。
上述步骤3可以具体包括:
步骤3-1:利用特征选择方法对原始视频业务流特征进行选择,并进行第一层SVM分类,得到分类结果C1,C2,C3,C4;其中,C1为即时通信类视频,C2为P2P类视频,C3为http下载,C4为在线视频,包含直播和非直播两类;
步骤3-2:对上一层分类结果C4的数据流特征再次使用特征选择方法进行特征选择,并进行第二层SVM分类,得到分类结果C41,C4;其中,C41为在线直播视频,C42为在线非直播视频;
步骤3-3:对上一层分类结果C42的数据流特征再次使用特征选择方法进行特征选择,并进行第三层SVM分类,得到分类结果C421,C422,C433;其中,C421为标清视频,C422为高清视频,C423为超清视频;
步骤3-4:统计分类输出结果。
与现有技术相比,本发明的有益结果:
1、本发明提出的基于粒子群优化算法的视频流特征选择方法相较于其他的基于粒子群优化算法的特征选择方法具有更低的计算复杂度,能够有效的降低特征选择过程中的时间和空间开销,提高特征选择的效率。
2、本发明对视频业务采用多层分类的方法,设计了一种三层SVM级联分类器,配合本发明提出的特征选择方法选择的特征组合,能够取得较好的分类结果。
附图说明
图1为本发明基于粒子群优化算法的视频流特征选择与分类方法的流程框图。
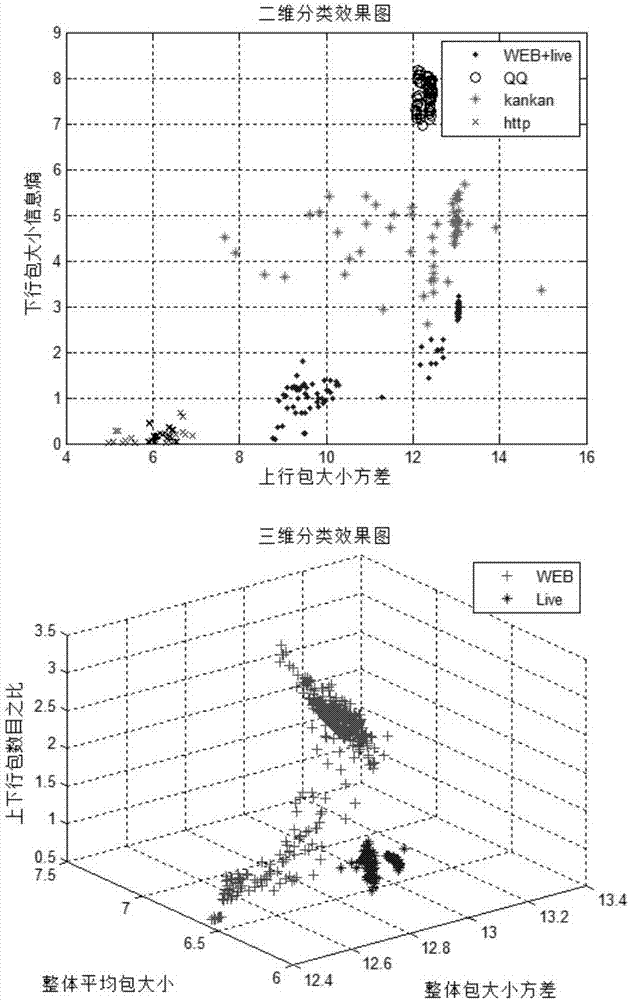
图2为本发明提出的特征选择方法所选取的特征组合的有效验证图。
具体实施方式
以下结合说明书附图对本发明创造作进一步的详细说明。本发明可以对视频流业务选择出简单、有效的特征组合,并利用三层SVM级联分类器对原始的视频业务流进行分类。方法流程分为以下步骤:
步骤1:在开放的互联网环境中使用网络封包分析软件获取所需的实验数据,然后对数据包进行过滤,最后对这些网络视频业务流进行基本的统计特征计算,具体步骤为:
步骤1-1:在开放的互联网环境中,通过网络封包分析软件抓取所需的视频业务流数据,然后对原始的数据进行简单预处理,转换成标准的五元组文本格式,即数据包到达的时间、源IP地址、目的IP地址、协议、数据包分组大小;
步骤1-2:对数据包过滤是指滤除不感兴趣或者不会对分类结果产生影响的数据包;
步骤1-3:对原始视频流的标准五元组文件进行基本的统计特征计算,这些特征包括:包大小、包大小的均值与方差、包大小信息熵、包间隔的均值与方差、字节速率、分组速率、上下行字节数之比、上下行包大小之比。
步骤2:对视频业务流的统计特征进行分析,选择出能有效区分业务流的特征组合,具体步骤为:
步骤2-1:对所有视频业务流的统计特征进行离散化操作,降低特征选择过程中的计算开销;
步骤2-2:利用特征权重算法计算每个统计特征的权重;
步骤2-3:根据特征权重的排名,去掉部分与类别关联较小的特征,选取权重最大的N个特征,降低原始特征空间的维数,减少后续操作的计算复杂度;
步骤2-4:在上一步选取的N个特征子集中,选取特征权重排名靠前的M个特征作为先验知识,指导粒子群优化算法的种群初始化,将每个粒子的初始位置设为最优位置;迭代次数设为1;
步骤2-5:将不一致率作为粒子群优化算法的适应度函数,利用适应度函数计算粒子的整体适应度,将样本实例中的一个特征组合称为一个模式,特征子集的所有模式的不一致数,就等于该模式出现的样本总数减去出现次数最多的某一类标签的样本数,不一致率就等于不一致数除以样本总数;
步骤2-5:如果当前粒子的适应度小于粒子自身最优位置的适应度,将粒子自身最优位置更新为当前位置;如果粒子自身最优位置的整体适应度小于种群的最优位置的适应度,将种群的最优位置更新为粒子自身最优位置;
步骤2-6:根据当前粒子的位置和速度信息更新粒子群的位置和速度;
步骤2-7:若满足最大迭代次数或不一致率在迭代过程中持续不变,则输出最优解;否则,重复步骤2-5到步骤2-6。
步骤2-1:对所有视频业务流的统计特征进行离散化操作,降低特征选择过程中的计算开销;
步骤2-2:利用特征权重算法计算每个统计特征的权重;
步骤2-3:根据特征权重的排名,去掉部分与类别关联较小的特征,选取权重最大的10个特征,降低原始特征空间的维数,减少后续操作的计算复杂度;
步骤2-4:在上一步选取的10个特征子集中,选取特征权重排名靠前的2个特征作为先验知识,指导粒子群优化算法的种群初始化,将每个粒子的初始位置设为最优位置;迭代次数设为1;
步骤2-5:将不一致率作为粒子群优化算法的适应度函数,利用适应度函数计算粒子的整体适应度,将样本实例中的一个特征组合称为一个模式,特征子集的所有模式的不一致数,就等于该模式出现的样本总数减去出现次数最多的某一类标签的样本数,不一致率就等于不一致数除以样本总数;
步骤2-5:如果当前粒子的适应度小于粒子自身最优位置的适应度,将粒子自身最优位置更新为当前位置;如果粒子自身最优位置的整体适应度小于种群的最优位置的适应度,将种群的最优位置更新为粒子自身最优位置;
步骤2-6:根据当前粒子的位置和速度信息更新粒子群的位置和速度;
步骤2-7:若满足最大迭代次数或不一致率在迭代过程中持续不变,则输出最优解;否则,重复步骤2-5到步骤2-6。
步骤3:根据设计的三层SVM级联分类器对原始的视频业务流进行分类实验,得到最终的分类结果,具体步骤为:
步骤3-1:利用特征选择方法对原始视频业务流特征进行选择,并进行第一层SVM 分类,得到分类结果C1,C2,C3,C4;其中,C1为即时通信类视频,C2为P2P类视频,C3为http下载,C4为在线视频,包含直播和非直播两类;
步骤3-2:对上一层分类结果C4的数据流特征再次使用特征选择方法进行特征选择,并进行第二层SVM分类,得到分类结果C41,C4;其中,C41为在线直播视频,C42为在线非直播视频;
步骤3-3:对上一层分类结果C42的数据流特征再次使用特征选择方法进行特征选择,并进行第三层SVM分类,得到分类结果C421,C422,C433;其中,C421为标清视频,C422为高清视频,C423为超清视频;
步骤3-4:统计分类输出结果。
现结合附图和实施例对上述步骤做进一步详细的说明。
步骤1,网络视频业务流的获取与统计特征计算:在开放的互联网环境中使用网络封包分析软件获取所需的视频业务流数据,其中包括在线标清视频(以youku标清为例)、在线高清视频(以youku高清为例)、在线超清视频(以youku超清为例)、在线直播视频(以Cbox为例)、HTTP下载、即时通信类视频(以QQ为例)、P2P视频(以迅雷看看为例)七种视频业务。然后将获取的数据流转换成标准的五元组文本格式,即数据包到达的时间、源IP地址、目的IP地址、协议、数据包分组大小。最后对原始视频流的标准五元组文件进行基本的统计特征计算。
步骤2,基于粒子群优化算法的视频流特征选择:首先利用特征权重算法计算每个统计特征的特征权重,然后根据特征的权重大小,滤除部分无关特征,从而达到快速降维的目的。然后选取权重最大的部分特征作为先验知识指导粒子群优化算法的种群初始化,选用不一致率作为适应度函数在剩余的特征子集中选择出最优的特征子集。
在实验中我们设计了三层SVM级联分类器模型,此模型可以在每一级的分类器中使用本发明方法选择的特征组合识别出某些特定类型的应用业务。第一层的SVM分类器主要用来识别出即时通信类视频(QQ)、P2P类视频(Kankan)、http下载和其他类数据(网络在线视频业务和直播业务),最佳的特征组合为上行包大小方差、下行包大小信息熵。为了方便观察,我们对图2第一幅图中上行包大小方差做了取对数操作。从图中可以看出,QQ业务在下行包大小信息熵特征上与其他业务有着明显的区别,http下载业务也在上行包大小方差特征上和其他业务有着明显的区别。在二维空间上使用上行包大小方差和下行包大小信息熵可以将迅雷看看视频业务和在线视频业务(包括直播和非直播)。
第二层的SVM分类器主要用来识别直播和非直播业务。最佳的特征组合:整体包大小方差、整体平均包大小和上下行包数目之比。为了方便观察,我们对图2第二幅图中整体包大小方差和整体平均包大小做了取对数操作。从图2中可以看出,在三维空间里使用整体包大小方差、整体平均包大小和上下行包数目之比可以有效的区分出直播和非直播业务。
第三层的SVM分类器主要用来识别非直播的标清、高清和超清。最佳的特征组合:下行字节速率、下行数据包速率、下行平均包间隔、下行包间隔方差。
步骤3,三层SVM级联分类输出统计结果,其实现方法为:采用上述设计出的三层SVM级联分类器,对原始网络视频业务流,实施多层分类。
本发明的三层SVM级联分类方法包括:
步骤3-1:利用特征选择方法对原始视频业务流特征进行选择,并进行第一层SVM分类,得到分类结果C1,C2,C3,C4;其中,C1为即时通信类视频,C2为P2P类视频,C3为http下载,C4为在线视频,包含直播和非直播两类;
步骤3-2:对上一层分类结果C4的数据流特征再次使用特征选择方法进行特征选择,并进行第二层SVM分类,得到分类结果C41,C4;其中,C41为在线直播视频,C42为在线非直播视频;
步骤3-3:对上一层分类结果C42的数据流特征再次使用特征选择方法进行特征选择,并进行第三层SVM分类,得到分类结果C421,C422,C433;其中,C421为标清视频,C422为高清视频,C423为超清视频;
步骤3-4:统计分类输出结果。
- 还没有人留言评论。精彩留言会获得点赞!