一种基于H/α参数变化规律的多时相PolSAR农作物监督分类算法的制作方法
本发明属于微波遥感数据处理及应用技术领域,特别涉及雷达遥感领域中的一种极化合成孔径雷达(Polarimetric Synthetic Aperture Radar,PolSAR)的农作物分类处理,具体为一种基于H/α参数变化规律的多时相PolSAR农作物监督分类算法。
背景技术:
农作物分类是极化SAR的主要应用之一。PolSAR作为一种遥感手段,能够提供高分辨对地观测信息,目前大量的研究工作集中在单幅图像上。随着发展的星载系统的运行,而且星载系统运行为多时相分析提供了可能。作物分类信息在作物库存研究领域中具有极其重要的意义,比如作物长势监测、生物量估测、作物产量预测及其他相关应用。近几十年来,作物分类已成为空间遥感领域的研究热点之一。
如今,对于PolSAR数据已经开发了很多的分类算法,大体可以分为三类,基于统计模型的算法,基于电磁波散射机制的算法,基于先验知识的算法,这些方法有监督型和非监督型,但这些算法存在一定的缺点,首先这些算法大多数集中在单时相PolSAR数据的分析,从而对目标进行分类,但因为不同类型的农作物在不同的生长周期具有不同的散射特性,所以单时相的数据并不能在农作物分类的过程中提供足够多的信息,因此数据采集的时间是一个关键因素,但其分类精度不能达到所需要求。为此,有必要采用多时相PolSAR数据实现对不同农作物分类的更高的精度。
Cloude和Pottier在文献“An Entropy Based Classification Scheme for Land Applications of Polarimetric SAR”(IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING,VOL.35,NO.1,JANUARY 1997)中提出了一种极化合成孔径雷达数据处理中的非监督分类方法,该方法的基本原理为:将极化相干矩阵分解为极化熵H和平均散射角α,其中极化熵和散射角能够很好地描述目标的极化散射特性,可将目标的极化散射特性用由目标熵和散射角组成的分类平面(H-α分类平面)上的某一点位置来描述,H-α分类平面被分成了9个基本区域,代表9类不同的散射机理,从而达到分类的效果。
Jong-Son Lee在文献“Classification of Multi-Look Polarimetric SAR Data Based on Complex Wishart Distribution”(Int.J.Remote Sensing,VOL.15,NO.11,JULY 1994)中提出了一种合成孔径雷达数据处理中监督分类方法,该方法是通过描述多视全极化SAR图像协方差矩阵的统计特性,直接利用该分布进行分割可充分利用全极化SAR数据的统计先验知识,并可避免拆分协方差矩阵导致的信息损失,可达到一定程度的分类效果。
上述两种极化合成孔径雷达PolSAR数据处理的分类方法的核心,前者是利用H/α平面进行分类,(1)但是对于农作物而言,随着生长的变化,它的H,α参数也会发生变化,所以在不同时期,H/α平面上分布不同,从一个区域移动到另一区域;(2)在特定的生长周期时,会有大量样本分布在边界区域,导致分类误差较大,甚至完全分错;(3)属于非监督分类。后者是从散射矩阵分布出发,虽然对于多时相分类用到了单个时相的数据,但是只是从协方差矩阵出发,并未利用具体的散射特性,导致分类精度不能满足实际应用要求。
技术实现要素:
为了克服上述现有技术的缺点,本发明的目的在于提供一种基于H/α参数变化规律的多时相PolSAR农作物监督分类算法,可用于PolSAR图像分类处理,通过新定义参数θ的计算,构建分类函数f(θi),计算各个像素点在各类的θi处的函数值,通过比较该值的大小对该像素点进行分类,从而当现有复Wishart分类算法对图像处理的分类精度不能满足所需要求时,在极化合成孔径雷达数据处理过程中,本发明对PolSAR图像的农作物分类精度有一定的提高。
为了实现上述目的,本发明采用的技术方案是:
(1)输入n个多时相的全极化SAR图像数据;
(2)完成多时相全极化SAR图像的精准配;
(3)将每个单时相的全极化SAR数据进行H/α分解,然后将所得每个像素点处的H、α参数值保存到对应的矩阵中,其中矩阵每层的数据对应着多时相SAR数据的每个时相的H、α数据;
(4)建立地面真值分布:
(4a)在地表真实分布选择各类农作物的训练样本,然后将选中区域的像素点的H和α以复数的形式,分别对应存在各类样本矩阵中;
(4b)将(3)中保存的全极化SAR数据,同样以复数的形式存在目标矩阵中;
(5)计算夹角,并构建分类函数:
(5a)确定原点,将步骤(4a)获取的训练样本矩阵中的复数在H-α平面上与该点相连,并将步骤(4b)所得矩阵中所有全极化SAR像素点对应的复数与该点相连,再分别保存在训练样本矩阵和整体全极化SAR数据矩阵中;
(5b)利用步骤(5a)所得各类训练样本的复数矩阵,在H-α平面计算训练样本在H-α分布区域的夹角;
(5c)构建分类函数。
(5d)将步骤(5a)中保存的全极化SAR图像的各个像素点的参数,代入所构建分类函数f(θi),并得到对应的结果;
(6)利用步骤(5d)中的结果,对该点进行分类判别。
(7)输出分类后的农作物分布图。
与现有技术相比,本发明的有益效果是:
本发明提出了一个新的参数来测量H/α分布变化的特征,并且根据该新定义的参数提出了一种监督分类方法,与现有经典的复Wishart分布分类方法相比,输入相同的PolSAR图像,不仅它的整体分类精度有了一定的提高,而且分类过程中的运算量大大减少,使得分类效率提高。
附图说明
图1为本发明的流程图;
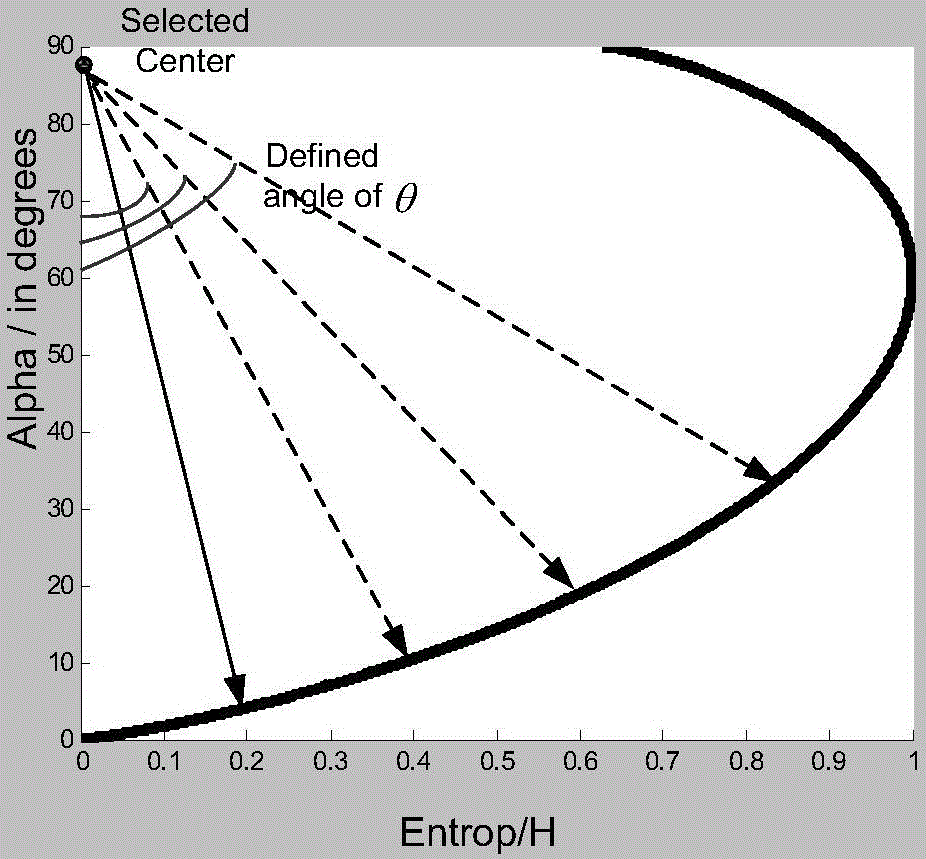
图2为本发明所述在H-α平面上的定义参数示意图;
图3为分6类农作物时,现有方法和本发明所述方法的整体分类结果和整体分类误差对比。
图4为分四类农作物时,现有方法和本发明的所述方法整体分类结果和整体分类误差对比。
具体实施方式
下面结合附图对本发明做进一步的描述。
参照附图1,本发明的具体实施步骤如下:
以输入AGRISAR_2009\Simulated_QuadPol_GTC_Products\Indian_Head_SK ASC_FQ02数据包为例,其中包含7个时相的全极化PolSAR数据。
步骤1,输入SAR图像数据。
先将每个时相的SAR数据读入,生成一个行向量。该行向量中共有N1×N2×M个元素。
其中,N1和N2表示该图像在二维平面上纵向和横向的像素点个数,M表示该SAR图像数据的层数。
第二步,将读取进来的SAR数据进行维数的变化,使其变为M×N2行,N1列,然后通过矩阵转置,使读取的数据变为N1行,M×N2列。
其中,N1,N2,M与第一步代表意义相同。
第三步,通过循环语句,将转置后的二维矩阵中的SAR数据,存入定义的三维矩阵中,该三维矩阵具有和该SAR图像在二维平面上纵向和横向的像素点个数相同的列数和行数,层数与SAR图像的层数相同,在这样的矩阵中,在行数和列数相等的情况下,每层的数据都对应着SAR图像中同一个像素点,为方便描述将该矩阵定为S阵,其大致形式如下:
S矩阵是一个三维矩阵,矩阵中的行数和列数对应着多时相全极化SAR图像中像素点的位置,层数与多时相全极化SAR图像的层数相同,以保证SAR数据全部读入。
步骤2,对图像进行精配准。
完成多时相全极化SAR图像的精准配。具体通过辐射校正,辐射地形校正,归一化,滤波,几何地形校正等这一系列的数据预处理工作完成精配准。
步骤3,H/α分解处理。
将每个时相的SAR数据进行H/α分解,然后将所得每个像素点处的H、α值保存在对应的矩阵中,为方便描述,将保存的矩阵,分别定为H阵和α阵,并且H阵和α阵中每层的数据分别对应着多时相SAR数据的各个时相的各个像素点处H、α参数值,在行数和列数相同的情况下,每一层都对应着同一个像素点的参数值,不同的层代表不同的时相;
比如下矩阵,它的行数和列数对应着像素点的位置,各个层对应着各个时相。
步骤4,建立地面真值分布
在地表真实分布选择各类农作物样本,然后将选中区域的像素点的H和α以复数的形式,分别对应存在各类样本矩阵中。将步骤3中所保存的整个SAR图像的数据以同样的方法保存,通过下式实现:
Tm=Hm+i·αm
其中,Hm表示样本中第m类作物的H值,i表示虚数单位,αm表示第m类作物的α值,整个矩阵Tm共有7列,每列分别存储该类样本像素点对应的7个时相数据。
对于步骤3中所保存的SAR图像的数据,它将图像中所有点的H和α以同样的方法,即Ampn=Hmpn+i·αmpn的方法存储,其中下标m代表行,p代表列,n代表层,即所有相同位置处的H和α的复数组合存储在A矩阵中,该矩阵共有7层,每层的数据与该图像每个时相的各个像素点一一对应,并且A矩阵中,不同层数的对应相同的行数和列数的7个数据,对应着7个时相中的同一个像素点处的像素信息。
形式如下,行数和列数对应着像素点的位置,每一层对应着每一个时相,矩阵中每一处存放着对应像素点在对应时相处的H、α以复数形式表现的参数值。
步骤5,计算夹角,并构建分类函数
首先在H-α平面上确定一个原点,具体实现利用下式:
C=i·b+a;
其中,i表示虚数单位,b表示在H-α平面上的纵坐标,a表示横坐标,选择适当的数据,使得分类精度达到最佳。
然后将该原点与H-α平面上的样本点,即步骤4中所存的样本点相连,通过复数的相减运算得到以新的以原点C为顶点,样本点为终点的新的矢量,即新的复数,并再次存在对应的矩阵Tm中,为下步矢量间的夹角做好准备,对于步骤4中所存储好的所有多时相全极化SAR数据同样进行与该原点相连,即通过复数的相减运算得到以新的以原点C为顶点,原始点为终点的新的矢量,表现为复数的形式并保存在A阵中。
再根据所形成新的矢量,对各类样本取共轭矩阵进行相角求差计算,具体实现利用下式:
其中,Tmj表示步骤5中样本数据在复平面上与原点相连后的样本数据矩阵,角标表示第m类样本作物的第j个时相的样本点的数据,V中存储样本农作物的复数信息,每一行对应着同一类训练样本的各个时相与第一时相的夹角。该复数表现为指数形式,模为1,辅角表示第m类农作物样本的第j个时相在H-α平面上的主要分布区域边界,与该类农作物的第1时相在H-α平面上主要分布区域边界的夹角,从而得到已知农作物类别的散射规律信息,i为虚数单位,exp(·)表示常数e的指数操作,(·)*表示取共轭操作,arg(·)表示取相角操作。
最后,构建分类函数,该函数中的输入为θi,即为经过计算已经得到的单位向量V的辅角.
首先,从步骤5中所得到的整体全极化SAR数据复数矩阵,即经过与训练样本相同处理后的矩阵A中每个像素点的7个时相的数据进行提取,提取方式为将行数和列数相等点的所有层的数据提取,即每个像素点处的7个时相的数据,并存放以列向量的形式存储。为方便描述假设提取后存在W中。将步骤5中所得的训练样本数据,即对V矩阵进行矩阵的行提取,然后变为列向量,最后将数据存在Q中,即样本列向量。
最后,将所提取的样本数据取共轭复数,并且将它的7个数据对应与所提取像素点的7个时相的数据进行复数相乘运算,求和,再取模。具体实现利用下式:
式中,d为一个行向量,将所提取像素点数据,与所得V矩阵中每一行,即每一类训练样本数据进行上式的运算,并且将得到的结果存入d(m),m表示被分类点与第m类样本进行运算后,存放在d中的第m个位置。(·)*表示共轭操作,|·|表示取向量的模操作。
步骤6,对各个像素点进行分类判别
对农作物进行最后的判别的是利用对d中信息的判断,d为步骤5计算得到的一个行向量,找出d中最大值的位置信息,即对应为该像素点处农作物的类别信息。
步骤7,输出分类后的农作物分布图。
6类农作物中,有部分作物外观类似,所以将外观类似农作物合并,即Flax,Lentil,Spring Wheat三类合并为Spring Wheat,其他类别保持不变,结果变为4类作物,然后将4类农作物经过上述同样的步骤,重新进行分类,并输出对应的农作物分布图。
图2为本发明在H-α平面上定义参数的示意图,由图2可知,根据该参数的大小可以说明H-α平面上的H-α点的分布情况,即达到最终的农作物分类目的。
图3中,分6类农作物时,现有方法和本发明所述方法的整体分类结果和整体分类误差对比。(a)地面真实的农作物分类图。(b)为通过现有方法复Wishart分类方法得到的农作物分类结果图和它对应的分类误差图,它的分类精度为70.14%,Kappa系数为59.72%。(c)通过本发明所述方法得到的农作物分类结果图和它对应的分类误差图,它的分类精度为72.58%,Kappa系数为61.61%。其中分类误差图为灰度图,只有0和1,白色区域为分类出错部分,黑色区域为分类正确部分。
图4中,分4类农作物时,现有方法和本发明所述方法的整体分类结果和整体分类误差对比。(a)地面真实的农作物分类图。(b)为通过现有方法复Wishart分类方法得到的农作物分类结果图和它对应的分类误差图,它的分类精度为83.79%,Kappa系数为71.25%。(c)通过本发明所述方法得到的农作物分类结果图和它对应的分类误差图,它的分类精度为89.08%,Kappa系数为79.14%。其中分类误差图为灰度图,只有0和1,白色区域为分类出错部分,黑色区域为分类正确部分。
表1和表2为分6类农作物时,现有方法和本发明所述方法的各类农作物分类的百分比(表中对角线部分),整体分类精度,Kappa系数,其中表1为现有方法,表2为本发明所述方法,表中类别对应图3中注释顺序由上到下。
表1
表2
表3和表4为分4类农作物时,现有方法和本发明所述方法的各类农作物分类的百分比(表中对角线部分),整体分类精度,Kappa系数,其中表3为现有方法,表4为本发明所述方法,表中类别对应图4中注释顺序由上到下。
表3
表4
通过图3,图4的处理结果,并参考表1、表2和表3、表4中的混淆矩阵的结果对比可知,PolSAR图像的整体分类结果,经过本发明所述的农作物分类方法处理后,它的分类精度能达到更进一步的提高。
- 还没有人留言评论。精彩留言会获得点赞!