一种基于音频指纹的分片音频检索方法与流程
本发明涉及音频检索方法,更具体的是基于音频指纹的分片音频检索方法,属于音频检索技术领域。
背景技术:
随着网络的发展,音频呈海量增长之势,如何高效且有效地检索或监管音频内容成为一个重要的问题。传统的音频信息检索技术主要是基于文本的,然而传统的基于文本的音频信息检索无法满足人们对音频检索的需求。也就是说,如果用户听到一段很熟悉的音频,想通过录制几秒钟的片断来查询整段音频的信息,目前在技术上仍然存在较大的实现难度。
目前音频检索主要可以分为两大类:一类是基于内容的,它是指利用音频的高层语义信息对音频进行分类和识别,例如音频分类、音频索引、关键词检索等;另一类是固定音频检索,又称为基于特征相似度的音频检索,它是指给定一个查询音频段,然后根据音频的声学特征,在待检音频库(或音频流)中检索与其同源(即内容相同或相近)的音频文件。
比较经典的音频检索方法主要有两类:基于局部特征点或者全局结构信息的音频检索方法。
基于局部特征点的方法,一般是从频谱中寻找一些典型的特征点,例如英国的Shazam公司,提取频谱峰值信息,然后将特征点组成特征点对,把特征点对作为该片段的声纹;搜索时候建立哈希索引实现快速搜索。此方法的特点是不需要保留频谱的全局信息,特征具有代表性,抗造性能强,缺点是信息量少,声纹构建索引时碰撞比较严重。
基于全局结构信息的方法,是保留整个频谱的全局信息,信息量大,但是抗噪性能不强,信息代表性差,例如荷兰的Philips研究所提出的方法,把300--2000Hz之间的频谱分成33个非重叠的子频带,最终子频带由0或者1来表示,这些0、1序列组成声纹;搜索时候也使用声纹构建哈希表来加快搜索速度。
技术实现要素:
本发明的目的在于提出一种基于音频指纹的分片音频检索方法,能够大幅度提高音频检索的准确率和效率。
为达此目的,本发明采用以下技术方案:
一种基于音频指纹的音频指纹检索方法,包括以下步骤:
A.检测待检音频片段长度并判断此长度是否大于设定的值N秒,根据N秒分成两片;
B.对音频片段进行数字化、预处理;
C.预处理后对音频片段进行音频指纹特征的提取;
D.提取的音频指纹与音频指纹库匹配;
E.判断最大匹配率是否达到设定的阈值,若达到,返回原始音频信息,检索结束。否则,判断步骤A中是否有分片,如果没有,返回“没有匹配的音频”的结果,检索结束。如果有,判断剩余的音频片段长度是否大于N秒,否,执行步骤B和步骤C,是,对剩余的音频片段进行分片,然后执行步骤B和步骤C;
F.将所有步骤E中提取的音频指纹从前到后附加到步骤C中提取的音频指纹之后,一同与音频指纹库进行特征匹配;
G.执行步骤E和步骤F,依此类推,形成循环操作。
步骤A中,检测待检音频片段音频长度并判断此长度是否大于设定的值N,比如设定这个值为3秒,如果待检音频片段不大于3秒则不用分片,否则需要分片,分成3秒的片段以及剩余长度的音频片段。
步骤B中,音频片段为3秒的音频分片或者不大于3秒的音频片段,然后对此音频片段进行数字化、预处理,主要包括预滤波、采样、预加重、加窗分帧。
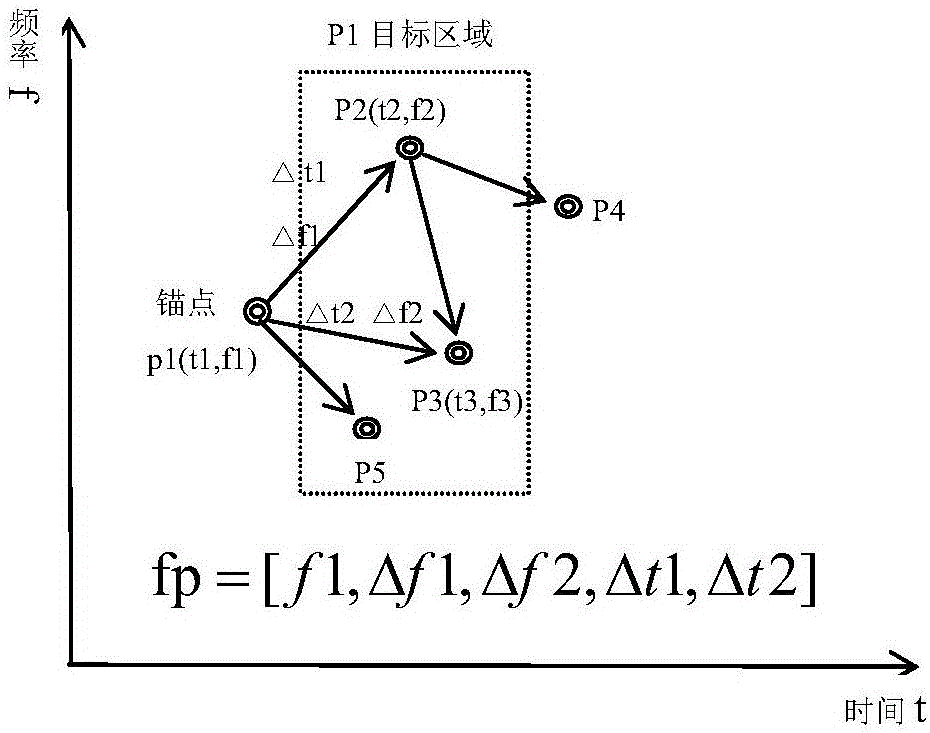
步骤C中,对音频片段逐帧进行FFT变换得到频谱图,根据频谱图找到频谱极大值,每一帧提取n个频谱极大值点,然后以一个极大值点为锚点,并以后面的m个极值点为目标区域,在目标区域里选取两个极值点与锚点形成极值点三角形,假定锚点的坐标为(t1,f1),另外两点为(t2,f2),(t3,f3),则音频指纹可以用向量fp表示:
fp=[f1,Δf1,Δf2,Δt1,Δt2]
式中,Δf1=f2-f1,Δf2=f3-f1,Δt1=t2-t1,Δt2=t3-t1;
步骤E中,判断最大匹配率是否达到设定的阈值,若达到,返回原始音频信息,检索结束。否则,判断步骤A中是否有分片,如果没有,返回“没有匹配的音频”的结果,检索结束。如果有,判断剩余的音频片段长度是否大于N秒,否,执行步骤B和步骤C,是,对剩余的音频片段进行分片,然后执行步骤B和步骤C。
步骤F中,将前面所有音频分片所得的音频指纹按照时间上的从前往后的顺序连在一起与音频指纹库进行匹配。
判断匹配率是否达到设定的阈值,形成循环操作。
本发明采用先对待检音频片段进行分片,并逐片进行特征提取和特征匹配,并对音频指纹特征进行优化的方法,可以大幅度提高音频检索的准确率和效率。
附图说明
图1是本发明基于音频指纹的分片音频检索方法具体实施例的流程图
图2是本发明音频指纹特征提取的示意图
具体实施方式
下面结合附图并通过具体实施方式来进一步说明本发明的方案。
图1是本发明具体实现方式中的一种基于音频指纹的分片音频检索流程示意图。如图1所示,该音频检索流程步骤如下:
第一阶段是建立原始音频指纹库。即将庞大的原始音频提取为一系列的音频指纹并建立音频指纹库,使用哈希算法,对音频指纹库建立哈希索引表。具体步骤包括:
首先,将库音频进行数字化、预处理,主要包括预滤波、采样、预加重、加窗分帧。预滤波的目的是抑制输入信号各频域分量中频率超过采样频率一半的所有分量,以防止混叠;另外,预滤波还有一个用处,就是抑制50HZ的电源工频干扰。然后经过采样数字化后,对数字化的语音信号进行预处理。预加重的目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱,以便于频谱分析。由于音频的短时平稳性,所以在分析音频时,需要对语音信号进行加窗分帧。
然后,进行音频指纹提取,如图2。将数字化、预处理后的音频信号逐帧进行FFT变换得到频谱图,根据频谱图找到频谱极大值,每一帧提取n个频谱极大值点,然后以一个极大值点为锚点,并以后面的m个极值点为目标区域,在目标区域里选取两个极值点与锚点形成极值点三角形,假定锚点的坐标为p1(t1,f1),另外两点为p2(t2,f2),p3(t3,f3),则音频指纹可以用向量fp表示:
fp=[f1,Δf1,Δf2,Δt1,Δt2]
式中,Δf1=f2-f1,Δf2=f3-f1,Δt1=t2-t1,Δt2=t3-t1;
目标区域的选取取决于锚点后按时间排序的m个频谱极值点,假定m设置为3,如图2,p1为锚点,则p1的目标区域包括p2,p3,p5,p4则不在p1的目标区域中。而且锚点和其目标区域中的任两点组成的极值点三角形中,目标区域的两点也是按时间的先后顺序与锚点组成音频指纹,如图2,Δf1是时间上早于p3的p2的频率与锚点的频率差,指纹的其他元素同理。
最后,将提取的音频指纹通过哈希算法转化成哈希索引表,构建音频指纹库。
第二阶段对待检音频片段提取音频指纹,并进行指纹匹配。具体步骤包括:
步骤1,判断待检音频片段的长度是否大于3秒,否,对待检音频片段进行数字化、预处理以及指纹提取,过程同第一阶段。
步骤2,是,对待检音频片段进行分片,分成3秒的音频长度片段和剩余音频长度片段,然后对3秒音频片段执行数字化、预处理以及指纹提取,过程同第一阶段。
步骤3,将提取的指纹同指纹数据库中的指纹进行匹配,统计匹配率,判断最大匹配率是否大于阈值,是,返回指纹对应的原始音频信息,检索结束。
步骤4,否,判断是否还有分片,否,返回“没有匹配的音频”的结果,检索结束。
步骤5,是,判断该分片是否大于3秒,否,对该分片进行数字化、预处理以及指纹提取,过程同第一阶段。
步骤6,是,对待检音频片段进行分片,分成3秒的音频长度片段和剩余音频长度片段,然后对3秒音频片段执行数字化、预处理以及指纹提取,过程同第一阶段。
步骤7,将按照以上步骤提取的指纹根据分片的顺序排列,一同与指纹数据库进行匹配。
步骤8,之后在步骤3到步骤7之间循环操作,直到检索结束。
应说明的是,以上所述的实施例仅用于说明本发明的技术思想及特点,其目的在使本领域内的技术人员能够了解本发明的内容并据以实施,当不能仅以本实施例来限定本发明的专利范围,即凡依本发明所揭示的精神所作的同等变化或修饰,仍落在本发明的专利范围内。
- 还没有人留言评论。精彩留言会获得点赞!