一种基于変分编码器中国手语识别方法与流程
本发明中国手语识别领域,特别是一种基于変分编码器中国手语识别方法。
背景技术:
手语识别是一种能够将手语信息转化成语音、文字并进行朗读或显示的技术。在手语识别领域,由于连续手语识别是手语识别的关键问题,因此,如何提高手语识别的效果关键在于如何提高连续手语识别的准确性。
现有技术中,连续手语识别的方法主要有以下几种:
第一种,连续手语识别通常采用HMM(Hidden Markov Model,隐马尔科夫),这种方法在模型中引入了前一状态对当前状态的影响,通过计算输出概率最大化来实现手语的识别;
第二种,连续手语识别也可采用CRF(Conditional Random Field,条件随机场),这种方法在模型中引入上下文信息,需要对训练特征进行左右扩展,并引入人工特征模板进行训练。传统方法中首先分别训练得到手语模型,然后采用逐级预测的方式对待识别手语进行识别。
第三种,采用机器学习算法如SVM、BP神经网络搭建语言模型进行识别。这种需要事先人工采集并标注好数据,进行监督式学习。
但是,上述三种方法主要存在以下问题:
虽然采用左右扩展的方式能在一定程度引入前后状态的关联,但是为了减小模型规模和复杂度,扩展大小十分有限,因此链接前后的距离不能太远,造成当前时刻对前面状态感知能力的下降;
采用监督式学习,需要人工进行标注数据,数据采集工作繁琐,工作量大。
并未考虑非线性扰动对识别结果的影响,当数据有小的扰动的时候,识别算法健壮性不强。
技术实现要素:
本发明的目的在于提供一种基于変分编码器中国手语识别方法,该方法能够减小非线性扰动信号的干扰,实现无监督学习,将时间序列识别网络化繁为简,且提高了对中国连续手语识别的准确率。
为实现上述目的,本发明的技术方案是:一种基于変分编码器中国手语识别方法,包括如下步骤,
S1:采集中国手语的时间序列数据,对该些数据采用编码器进行重构;
S2:对步骤S1重构后的数据进行反向解码,获得反向解码的重构数据;
S3:计算输入数据与解码后的重构数据之间的交叉熵,从而得到整个结构的损失函数,将误差回传,不断更新编码器、解码器参数,极小化损失函数,从而得到最终的编解码模型,用于手语的识别,交叉熵计算公式如下:
其中,xi为模型输入数据,yi为在重构后的输出序列。
在本发明一实施例中,所述步骤S1具体实现方式为:采用数据手套获取手语特征,获取中国手语的时间序列数据,而后对采集到的时间序列数据采用编码器进行重构,获得手语时间序列的特征向量;所述数据手套包括弯曲度传感器、九轴传感器以及用于数据处理、存储、发送的微型处理器。
在本发明一实施例中,所述编码器输入为时间序列数据,中间输出由期望与方差向量组成,通过样本均值、方差及随机采样消除非线性扰动后构成编码器,从输入到中间输出采用LSTM型RNN实现,同时采用相对熵来衡量编码器的性能。
在本发明一实施例中,所述相对熵即KL散度,通过统计方法计算可得两个分布N(u,Σ)与N(0,I)之间的散度,计算公式为
其中,Σi、ui为采集到的时间序列数据的方差与均值。
在本发明一实施例中,所述步骤S2具体实现方式为:将编码器所重构的数据通过解码器再次重构,获得的解码结果将用于梯度下降来逼近真实系统。
在本发明一实施例中,所述解码器输入为编码器重构后的特征向量,输出为再重构后的时间序列,解码器采用LSTM型RNN实现。
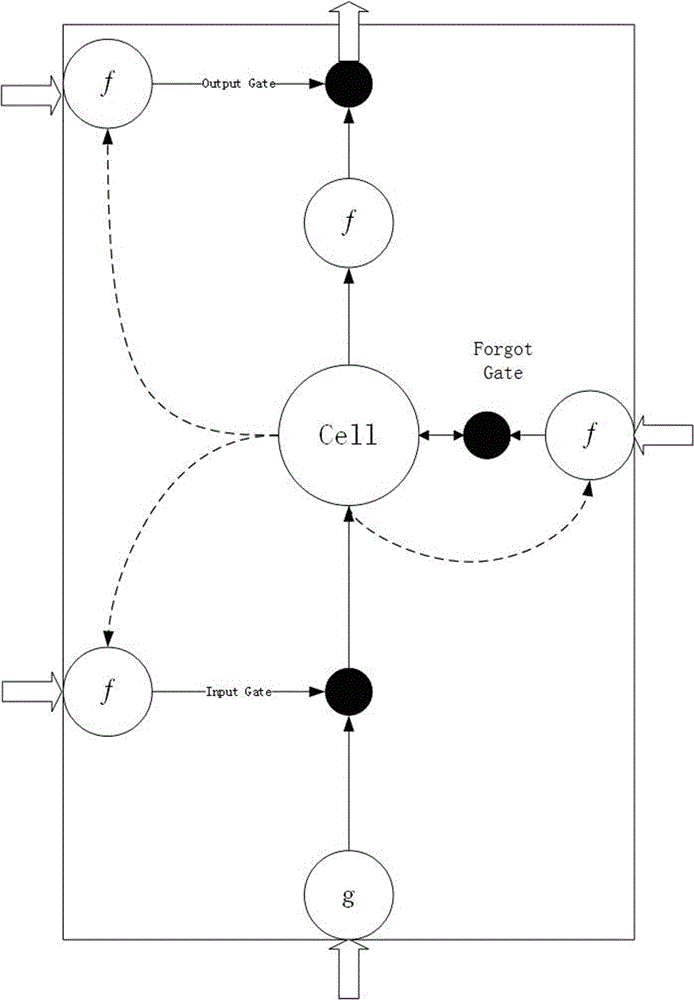
在本发明一实施例中,所述LSTM型RNN采用下式控制信息的流动:
It=σ(WixIt+Wimmt-1+Wicct-1+bi)
Ft=σ(WFxIt+WFmmt-1+WFcct-1+bF)
ct=Ft⊙ct-1+It⊙g(WcxIt+Wcmmt-1+bc)
Ot=σ(WOxIt+WOmmt-1+WOcct-1+bO)
mt=Ot⊙h(ct)
其中,给定输入序列I=(I1,I2...IT),T为输入序列的长度,It为t时刻的输入,W为权重矩阵,b为偏置矩阵,I、F、c、O、m分别代表输入门、遗忘门、状态单元、输出门以及LSTM结构的输出;
其中,σ为三个控制门的激励函数,公式为:
其中,h为状态的激励函数,公式为:
相较于现有技术,本发明具有以下有益效果:本发明通过自编码解码器的设计实现了手语时间序列数据的无监督训练,同时通过随机采样和LSTM型RNN网络相结合的优点,消除传感器采集数据中非线性扰动对识别结果的影响,提高了手语识别数据采集工作的效率、简化了识别网络的搭建并提高了识别的准确率。
附图说明
图1为本发明方法模型框架图。
图2为本发明实施例LSTM型RNN基本原理示意图。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
本发明的一种基于変分编码器中国手语识别方法,包括如下步骤,
S1:采集中国手语的时间序列数据,对该些数据采用编码器进行重构;具体即,
S2:对步骤S1重构后的数据进行反向解码,获得反向解码的重构数据;
S3:计算输入数据与解码后的重构数据之间的交叉熵,从而得到整个结构的损失函数,将误差回传,不断更新编码器、解码器参数,极小化损失函数,从而得到最终的编解码模型,用于手语的识别,交叉熵计算公式为
其中,xi为模型输入数据,yi为在重构后的输出序列。
所述步骤S1具体实现方式为:采用数据手套获取手语特征,获取中国手语的时间序列数据,而后对采集到的时间序列数据采用编码器进行重构,获得手语时间序列的特征向量;所述数据手套包括弯曲度传感器、九轴传感器以及用于数据处理、存储、发送的微型处理器。所述编码器输入为时间序列数据,中间输出由期望与方差向量组成,通过样本均值、方差及随机采样消除非线性扰动后构成编码器,从输入到中间输出采用LSTM型RNN实现,同时采用相对熵来衡量编码器的性能。所述相对熵即KL散度,通过统计方法计算可得两个分布N(u,Σ)与N(0,I)之间的散度,计算公式为
其中,Σi、ui为采集到的时间序列数据的方差与均值。
所述步骤S2具体实现方式为:将编码器所重构的数据通过解码器再次重构,获得的解码结果将用于梯度下降来逼近真实系统。所述解码器输入为编码器重构后的特征向量,输出为再重构后的时间序列,解码器采用LSTM型RNN实现。
所述LSTM型RNN采用下式控制信息的流动:
It=σ(WixIt+Wimmt-1+Wicct-1+bi)
Ft=σ(WFxIt+WFmmt-1+WFcct-1+bF)
ct=Ft⊙ct-1+It⊙g(WcxIt+Wcmmt-1+bc)
Ot=σ(WOxIt+WOmmt-1+WOcct-1+bO)
mt=Ot⊙h(ct)
其中,给定输入序列I=(I1,I2...IT),T为输入序列的长度,It为t时刻的输入,W为权重矩阵,b为偏置矩阵,I、F、c、O、m分别代表输入门、遗忘门、状态单元、输出门以及LSTM结构的输出;
其中,σ为三个控制门的激励函数,公式为:
其中,h为状态的激励函数,公式为:
实施例1:
如图1所示,本实施例提供了一种基于変分自编码器中国手语识别方法,其架构包括编码器和解码器两大模块。
在本实施例中,所述编码器包含输入、编码模块、KL散度计算模块和采样模块。具体实现步骤如下:
步骤S1:采集中国手语的时间序列数据,其中5000组无标注数据用于训练无监督模型,500组用于微调无监督模型,500组数据作为测试数据;
步骤S2:对5000组无标注数据进行编码,拟合出概率解释型神经网络,将输入数据通过变分推理网络映射为潜状态,从而获得潜状态的分布。
步骤S3:编码后,潜状态是一个分布而不是单一值,为了重新映射回相应的数据需要进行采样。因此,为了使之可微,将分布的方差和期望当做传统网络参数并加入噪声增加随机性。
步骤S4:将采样后的潜状态输入到解码器输入端,通过解码器将潜状态映射回相应的数据,得到的数据与数据分布之间计算KL散度,得到整个网络的损失函数,将误差回传,将梯度回传给编码器的参数,并通过梯度下降训练整个网络。
在本实施例中,所述步骤S1中,中国手语的时间序列数据通过数据手套获得,所得的数据包括了5个手指的弯曲、加速度传感器x,y,z三轴数据、重力传感器x,y,z三轴数据、姿态解算数据yaw,roll,即13维数据;
可选的,编码器可采用LSTM型RNN实现,其结构如图所示,其数据流动方向如以下式子所示:
It=σ(WixIt+Wimmt-1+Wicct-1+bi)
Ft=σ(WFxIt+WFmmt-1+WFcct-1+bF)
ct=Ft⊙ct-1+It⊙g(WcxIt+Wcmmt-1+bc)
Ot=σ(WOxIt+WOmmt-1+WOcct-1+bO)
mt=Ot⊙h(ct)
其中,给定输入序列I=(I1,I2...IT),T为输入序列的长度,It为t时刻的输入,W为权重矩阵,b为偏置矩阵,I、F、c、O、m分别代表输入门、遗忘门、状态单元、输出门以及LSTM结构的输出;
其中,σ为三个控制门的激励函数,公式为:
其中,h为状态的激励函数,公式为:
在本实施例中,所述步骤S3中,通过编码器的映射生成的数据满足均值为u(DX)、方差为∑(DX)的分布,采样的公式如下式所示,
ε为噪声采样以此来增加随机性。
在本实施例中,所述步骤S4中,K散度计算公式为:
其中Σi、ui为采集数据的方差与均值。
在本实施例中,所述KL散度将作为网络的损失函数的一部分,并计算交叉熵计算方法为:
其中,xi为模型输入数据,yi为在重构后的输出序列,误差将回传,使用梯度下降更新网络参数。
通过结构和计算公式可以看出变分自编码器具有非监督学习的优点,能够提高数据采集工具的效率,采用LSTM型RNN具有缓存历史的状态信息的作用,并且通过门结构对历史信息进行维护,从而扩展了大范围上下文信息对当前信息的影响,同时配合随机采样的方式、KL散度思想能最大化逼近识别网络、消除非线性扰动,提升了连续手语识别的准确率,并简化了识别模型的复杂度。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!