一种HadoopMapReduce的优化方法与流程
本发明属于计算机应用领域,涉及一种Hadoop MapReduce的优化方法。
背景技术:
Hadoop是一个由Apache基金会开发的分布式系统基础架构,用户可以在不了解分布式底层细节的情况下,开发分布式程序。
Hadoop MapReduce并行计算框架构建于Hadoop分布式文件系统(HDFS)之上,包含一个主节点和若干从节点,核心节点是JobTracker,功能是负责任务调度,管理作业,TaskTracker是任务节点,负责执行JobTracker分发过来的任务。
作业和任务是并行计算框架的两个重要概念,下面先介绍一下作业执行的状态转换过程以及任务的时序流程。
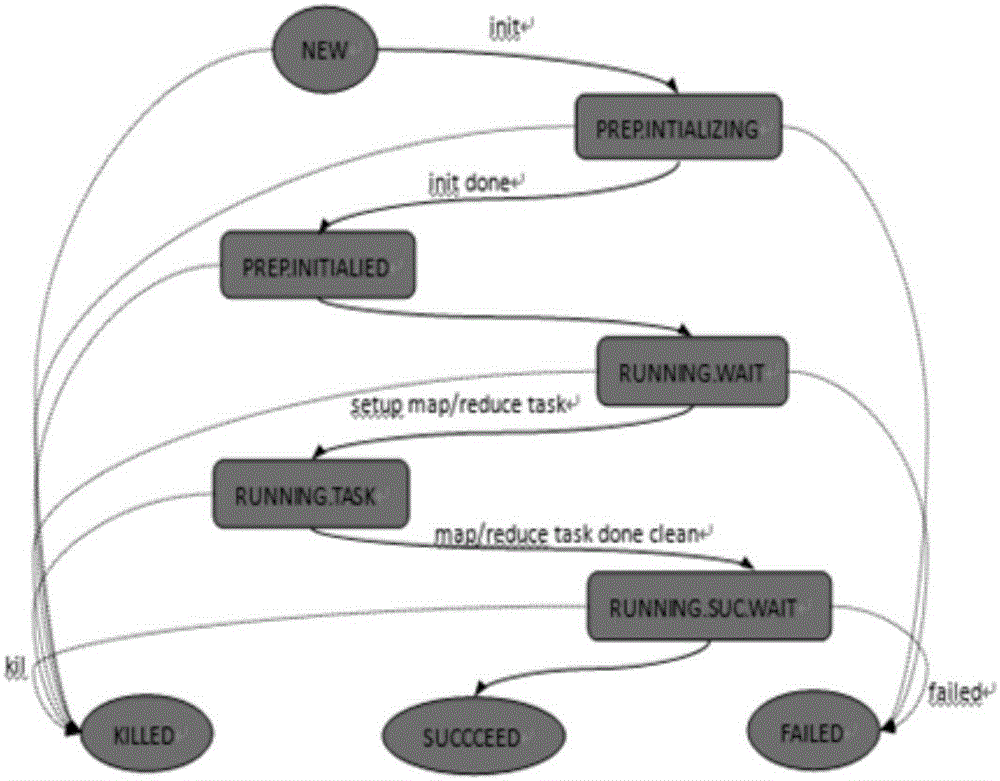
在目前的Hadoop MapReduce执行框架中,作业初始状态从NEW开始,继而进入PREP.INTIALIZIN状态进行初始化,目的是为了读取输入数据的数据块描述信息,并创建所有的map和reduce任务,初始化成功后,进入PREP.INTIALIZED状态,此时,一个特殊的setup任务启动,此任务的作用是创建作业的运行环境,然后作业进入RUNNING阶段,在此阶段,作业不会立即被处理,而是处在RUNNING.WAIT状态等待被调度,被调度后,任务才开始执行,此时作业进入RUNNING.TASK状态,真正的进行任务处理,当所有的map和reduce任务完成以后,作业进入RUNNING.SUC.WAIT状态,此时,另一个特殊的cleanup任务启动,此任务的目的是清理作业的运行环境,然后作业进入结束阶段,下图是作业的状态转换图,图中的每个状态下,作业都有可能被用户主动杀死,进入KILLED状态,也有可能在执行任务的过程中因为种种原因失败,进入FAILED状态。
任务(Task)是Hadoop MapReduce框架进行并行化计算的基本单位,Task的整个生存周期是我们所要分析的重要对象,在框架的实现中,两端分别对应TaskInProgress和TaskTracker.TaskInProgress两个对象,当一个作业被提交到Hadoop系统的时,JobTracker对作业进行初始化,此时作业内的任务被全部创建好,等待TaskTracker来请求任务,我们可以简单分析一下task的生命周期。
JobTracker接受任务时,创建TaskInProgress,此时Task处于UNASSIGNED状态,TaskTracker经过一个心跳周期后请求分配任务,待JobTracker收到请求后分配一个TaskInProgress任务给TaskTracker,这是第一次心跳通信。
TaskTracker收到任务后创建TaskTracker.TaskInProgress对象,并启动Chi ld进程来执行任务,此时TaskTracker将任务状态更新为RUNNING。
再过一个心跳周期,Task向JobTracker报告Task状态的改变,JobTracker也将状态更新为RUNNING,此为第二次心跳周期,任务执行期间TaskTracker还会周期性的向JobTracker发送心跳信息,在任务执行完之后,TaskTracker会将状态变为CMMIT_PENDING,发送给JobTracker。
JobTracker收到消息后,会返回确认消息,表示允许提交,此时TaskTracker会将结果提交,并把任务装态更新为SUCCEEDED,再过一个周期,TaskTracker再次发送心跳消息,JobTracker也将任务状态更新为SUCCEEDED,至此,一个任务的生命周期结束。
分析作业的状态转换过程,我们可以看出一个作业的生命周期中,有三个任务,在执行所有的常规任务之前,会先执行一个setup任务,之后执行正常的MapReduce任务,在所有的任务执行完成之后,会执行一个cleanup任务。根据任务的生命周期我们可以知道setup任务的执行必须经过分配任务和报告完成任务至少两个心跳周期,同样的,cleanup任务至少也会消耗两个心跳周期,这就大大增加了系统的运行时间,setup任务和cleanup任务消耗的心跳周期会直接影响整个系统的性能。
技术实现要素:
有鉴于此,本发明的目的在于提供一种Hadoop MapReduce的优化方法,将setup任务和cleanup任务合并MapReduce任务中,至少减少四个心跳周期,从而提高执行效率。
为达到上述目的,本发明提供如下技术方案:
一种Hadoop MapReduce的优化方法,一个作业的生命周期中有三个任务,包括setup任务、MapReduce任务和cleanup任务,将setup任务与clean任务合并进MapReduce任务,在一个作业在完成初始化时,直接启动MapReduce任务;即在map端首先执行setup任务,进行作业环境的创建,在reduce端最后执行clean任务,清理临时目录;然后作业结束,实现作业状态的优化。
进一步的,所述在在map端首先执行setup任务,在reduce端最后执行clean任务的实现方法为:在MapTask类中添加一个“setupJob()”方法,在ReduceTask类中添加一个“cleanJob()”方法,在Map任务的最开始阶段调用Task类的“runJobSetupTask()”方法,在reduce任务的最后阶段调用Task类的“runJobCleanupTask()”方法。
本发明的有益效果在于:通过分析MapReduce框架内部的作业执行过程,对执行过程中的环境准备和清理做了优化,合并setup任务与cleanup任务,有效的节约了至少4个心跳周期的时间,实现了MapReduce作业执行性能的优化。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为优化前的作业状态转化图;
图2为优化后的作业状态转化图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
参照图1优化前的作业状态图,一个作业的生命周期中有三个任务,包括setup任务、MapReduce任务和cleanup任务,根据任务的生命周期我们可以知道setup任务的执行必须经过一下两个步骤:
分配setup任务,经过一个心跳周期,待JobTracker收到TaskTracker的任务请求,则将setup任务分发给TaskTracker
Setup任务完成,TaskTracker执行完setup任务后,通过心跳信息向JobTracker报告完成信息,这是第二次心跳通信
补充一点,在任务执行过程中,TaskTracker还会周期性的向JobTracker发送心跳信息,但是以上两个心跳信息不可避免,是一定存在的。
同样的,cleanup任务至少也会消耗两个心跳周期,心跳消息除了包含有任务请求信息只玩,还包含任务执行状态,节点信息等内容。在标准的Hadoop系统中,少于100个节点的心跳周期为3s,当集群大于100个节点后,每多100个节点,心跳周期增加1s。由此可以计算出,setup任务与cleanup任务至少花费了12s的时间,虽然12s时间不算长,但如果对于一个执行时间为1min的段作业而言,整个作业环境的创建与清理就花销了20%左右的比例,这对系统的性能还是有相当大的影响。
通过分析Hadoop的源码,我们发现setup的主要任务是创建一个临时的输出目录,而cleanup任务是为了删除该目录。这两项任务本身的耗时并不长,真正消耗时间的是JobTracker与TaskTracker之间的心跳等待中,因此,我们从如下角度考虑优化策略。
将setup与clean任务合并进MapReduce任务,也就是说,当一个作业在完成初始化时,我们直接启动MapReduce任务,在map端做的第一件事,就是setup,进行作业环境的创建,在reduce端做的最后一件事就是clean,清理临时目录。为此,我们可以在MapTask类中添加一个“setupJob()”方法,在ReduceTask类中添加一个“cleanJob()”方法,在Map任务的最开始阶段调用Task类的“runJobSetupTask()”方法,在reduce任务的最后阶段调用Task类的“runJobCleanupTask()”方法,然后作业结束,优化后的作业状态转换图如图2所示,优化后的流程图中没有了PREP.SETUP状态,被合并进了RUNNING.WAIT状态,也没有了CLEANUP状态,被合并进了RUNNING.SUC.WAIT状态。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!