一种云化架构下的记录数据剔重处理方法及系统与流程
本发明涉及记录数据剔重处理领域。
背景技术:
传统的剔重处理,有基于磁盘文件或基于内存数据库的,基于内存库的剔重是在小机上运行的,数据在只存在一个主机上,内存里只存放一部分索引,如果当前记录对应的业务对应的时间的索引表不在内存中,通过内存换入换出的算法,把一些表的内容落到磁盘,加载对应的表的内存中,从而实现对大量的数据进行剔重处理。例如话单文件的记录,记录间的时间跨度较大,会导致频繁的换入换出,影响性能。内存数据库演进到云化的场景,就变成了分布式内存库,分布式内存库的各个数据节点分布在不同的主机上,不再支持换入换出的功能。例如,由于国际漫游等原因,电信系统的索引一般要保留2-3个月,5000万用户的省份,一个月的索引大致3t,3个月索引大约是9t,在分布式内存库里存放这些信息是比较昂贵的。
技术实现要素:
本发明提供一种云化架构下的记录数据剔重处理方法及系统,目的在于将记录数据按发生时间和接收时间的间隔分类处理,充分利用了分布式内存数据库处理速度快和hbase数据库(一种非关系型数据库)的海量存储空间的优势,实现了云化系统下对记录数据的高速剔重处理和较长时间的保存,提高了系统效率且节省了存储费用。
本发明解决上述技术问题的技术方案如下:
一种云化架构下的记录数据剔重处理方法,包括以下步骤:
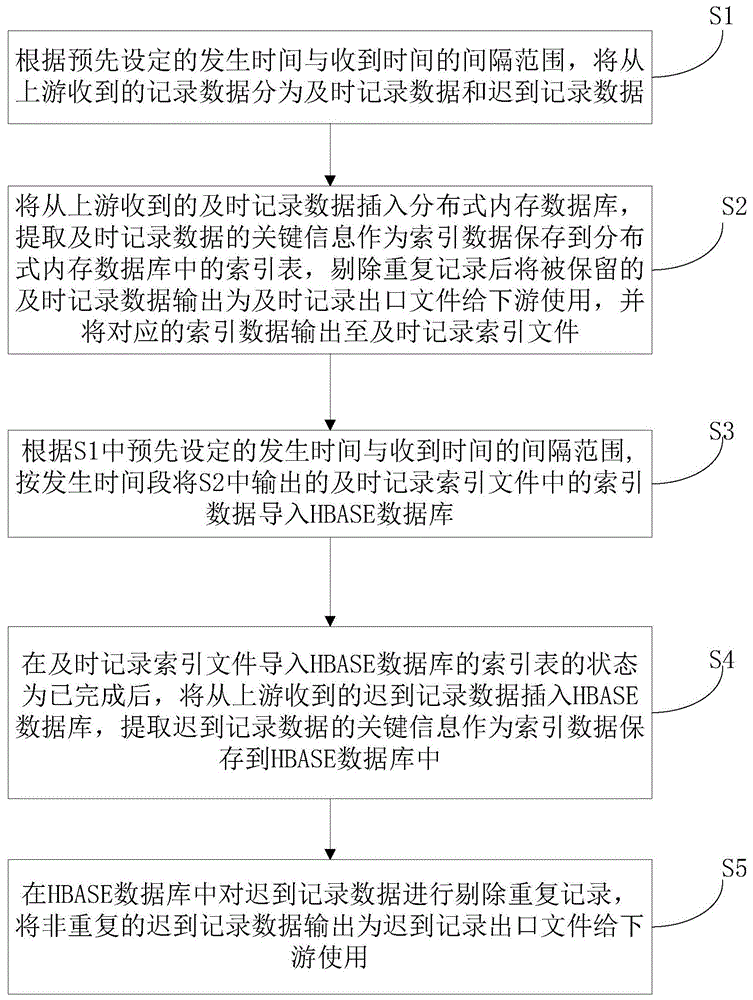
s1,根据预先设定的发生时间与收到时间的间隔范围,将从上游收到的记录数据分为及时记录数据和迟到记录数据;
s2,将从上游收到的及时记录数据插入分布式内存数据库,提取及时记录数据的关键信息作为索引数据保存到分布式内存数据库中的索引表,剔除重复记录后将被保留的及时记录数据输出为及时记录出口文件给下游使用,并将对应的索引数据输出至及时记录索引文件;
s3,根据s1中预先设定的发生时间与收到时间的间隔范围,按发生时间段将s2中输出的及时记录索引文件中的索引数据导入hbase数据库;
s4,在及时记录索引文件导入hbase数据库的状态为已完成后,将从上游收到的迟到记录数据插入hbase数据库,提取迟到记录数据的关键信息作为索引数据保存到hbase数据库中;
s5,在hbase数据库中对迟到记录数据进行剔除重复记录,将非重复的迟到记录数据输出为迟到记录出口文件给下游使用。
本发明的有益效果是:将记录数据按发生时间和接收时间的间隔分类处理,充分利用了分布式内存数据库处理速度快和hbase数据库的海量存储空间的优势,实现了云化系统下对记录数据的高速剔重处理和较长时间的保存,提高了系统效率且节省了存储费用。
在上述技术方案的基础上,本发明还可以做如下改进:
进一步,所述s2中,所述剔除重复记录的过程包括:将所述从上游收到的及时记录数据插入所述分布式内存数据库,根据该次插入操作的返回值判断该及时记录数据是否为重单,若是重单,则将该及时记录数据输出到重单文件,若不是重单,则将该及时记录数据作为被保留的及时记录数据进行后续处理。
采用上述进一步方案的有益效果是:根据插入操作的返回值来判断及时记录数据是否为重单,不占用多余存储空间和系统运行资源,简单高效。
进一步,所述s2中,所述分布式内存数据库的索引表按时间轮流顺序建立多个分索引表,根据所述s1中预先设定的发生时间与收到时间的间隔范围定时将过期的分索引表清空。
采用上述进一步方案的有益效果是:建立分索引表后定时将已过期分索引表数据清空,能及时释放空间,给新的索引数据提供空间,能节约布置系统需要的软硬件资源,提高了系统整体运行效率。
进一步,所述索引数据包括以下内容:索引值、记录数据文件名和记录数据的序号;所述及时记录索引文件中的索引数据采用mapreduce(一种软件架构,用于大规模数据集的并行运算,字面含义为:映射与归纳)的方式导入hbase数据库(也叫hadoop数据库,简称habase,是一种分布式非关系型列数据库,hadoop是一个由apache基金会所开发的分布式系统基础架构)。
采用上述进一步方案的有益效果是:索引数据只保存与记录数据有关的最关键的信息,简洁且不缺少必需信息;hbase数据库中的mapreduce的方式特别适合在大数据和分布式计算方面应用,在处理大文件方面具有处理能力强,速度快的优势。
进一步,所述hbase数据库中,对插入的有相同索引值的索引数据按进入hbase数据库的先后顺序分版本号全部保存;
所述s5中,所述剔除重复记录的过程包括:将所述迟到记录数据的索引数据查找出来,对相同索引值的索引数据的不同版本号中的记录数据文件名和记录数据的序号与最早版本比较,若两项信息不完全相符,则是重单,将该迟到记录数据输出到重单文件,若两项信息完全相符,则不是重单,将该迟到记录数据输出为迟到记录出口文件给下游使用。
采用上述进一步方案的有益效果是:hbase数据库具有海量存储的优势,且能保留多个版本的索引数据,能应对时间跨度大的海量记录数据,为数据剔重提供了长久有效的保障;hbase数据库中对每一条索引数据分版本号记录,在数据剔重时只需要与最早版本比较,而不需要依次比较,提高了剔重效率。
一种云化架构下的记录数据剔重处理系统,所述系统包括:
预处理模块,用于根据预先设定的发生时间与收到时间的间隔范围,将从上游收到的记录数据分为及时记录数据和迟到记录数据;
及时记录剔重模块,用于将从上游收到的及时记录数据插入分布式内存数据库,提取及时记录数据的关键信息作为索引数据保存到分布式内存数据库中的索引表,剔除重复记录后将被保留的及时记录数据输出为及时记录出口文件给下游使用,并将对应的索引数据输出至及时记录索引文件;
及时记录入库模块,用于根据预处理模块中预先设定的发生时间与收到时间的间隔范围,按发生时间段将及时记录剔重模块中输出的及时记录索引文件中的索引数据导入hbase数据库;
迟到记录入库模块,用于在及时记录索引文件导入hbase数据库的状态为已完成后,将从上游收到的迟到记录数据插入hbase数据库,提取迟到记录数据的关键信息作为索引数据保存到hbase数据库中;
迟到记录剔重模块,用于在hbase数据库中对迟到记录数据进行剔除重复记录,将非重复的迟到记录数据输出为迟到记录出口文件给下游使用。
本发明的有益效果是:将记录数据按发生时间和接收时间的间隔分类处理,充分利用了分布式内存数据库处理速度快和hbase数据库的海量存储空间的优势,实现了云化系统下对记录数据的高速剔重处理和较长时间的保存,提高了系统效率且节省了存储费用。
在上述技术方案的基础上,本发明还可以做如下改进:
进一步,所述及时记录剔重模块还用于,将所述从上游收到的及时记录数据插入所述分布式内存数据库,根据该次插入操作的返回值判断该及时记录数据是否为重单,若是重单,则将该及时记录数据输出到重单文件,若不是重单,则将该及时记录数据作为被保留的及时记录数据进行后续处理。
采用上述进一步方案的有益效果是:根据插入操作的返回值来判断及时记录数据是否为重单,不占用多余存储空间和系统运行资源,简单高效。
进一步,所述及时记录剔重模块对所述分布式内存数据库的索引表按时间轮流顺序建立多个分索引表,根据所述预处理模块中预先设定的发生时间与收到时间的间隔范围定时将过期的分索引表清空。
采用上述进一步方案的有益效果是:建立分索引表后定时将已过期分索引表数据清空,能及时释放空间,给新的索引数据提供空间,能节约布置系统需要的软硬件资源,提高了系统整体运行效率。
进一步,所述索引数据包括以下内容:索引值、记录数据文件名和记录数据的序号;所述及时记录入库模块还用于将及时记录索引文件中的索引数据采用mapreduce的方式导入所述hbase数据库。
采用上述进一步方案的有益效果是:索引数据只保存与记录数据有关的最关键的信息,简洁且不缺少必需信息;hbase数据库中的mapreduce的方式特别适合在大数据和分布式计算方面应用,在处理大文件方面具有处理能力强,速度快的优势。
进一步,所述hbase数据库中,对插入的有相同索引值的索引数据按进入hbase数据库的先后顺序分版本号全部保存;
所述迟到记录剔重模块还用于将所述迟到记录数据的索引数据查找出来,对相同索引值的索引数据的不同版本号中的记录数据文件名和记录数据的序号与最早版本比较,若两项信息不完全相符,则是重单,将该迟到记录数据输出到重单文件,若两项信息完全相符,则不是重单,将该迟到记录数据输出为迟到记录出口文件给下游使用。
采用上述进一步方案的有益效果是:hbase数据库具有海量存储的优势,且能保留多个版本的索引数据,能应对时间跨度大的海量记录数据,为数据剔重提供了长久有效的保障;hbase数据库中对每一条索引数据分版本号记录,在数据剔重时只需要与最早版本比较,而不需要依次比较,提高了剔重效率。
附图说明
图1为本发明实施例1中一种云化架构下的记录数据剔重处理方法流程图;
图2为本发明实施例2中一种云化架构下的记录数据剔重处理系统的框图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
实施例1
如图1所示,一种云化架构下的记录数据剔重处理方法,包括以下步骤:
s1,根据预先设定的发生时间与收到时间的间隔范围,将从上游收到的记录数据分为及时记录数据和迟到记录数据;
s2,将从上游收到的及时记录数据插入分布式内存数据库,提取及时记录数据的关键信息作为索引数据保存到分布式内存数据库中的索引表,剔除重复记录后将被保留的及时记录数据输出为及时记录出口文件给下游使用,并将对应的索引数据输出至及时记录索引文件;
s3,根据s1中预先设定的发生时间与收到时间的间隔范围,按发生时间段将s2中输出的及时记录索引文件中的索引数据导入hbase数据库;
s4,在及时记录索引文件导入hbase数据库的状态为已完成后,将从上游收到的迟到记录数据插入hbase数据库,提取迟到记录数据的关键信息作为索引数据保存到hbase数据库中;
s5,在hbase数据库中对迟到记录数据进行剔除重复记录,将非重复的迟到记录数据输出为迟到记录出口文件给下游使用。
具体的,例如,在云化环境下,电信支撑系统中对cdr数据(即calldetailrecords,用户使用详细记录)基本上做到“准实时”;据统计,99.9%的cdr数据在3小时内到达支撑系统,即可称为及时cdr数据,只有一小部分的cdr数据,在3小时之后陆续到达,可称为迟到cdr数据。因此,将类似此种情况下的记录数据分类后进行剔重处理,能实现云化系统下对记录数据进行高速剔重处理,从而适应系统云化后高效的特点。
由于s2中输出的及时记录索引文件中的索引数据是按照发生时间段导入hbase数据库的,因此在最近发生时间段内的及时记录索引文件导入hbase数据库的状态为已完成后,将该发生时间段的起始时间以后从上游收到的迟到记录数据插入hbase数据库,提取迟到记录数据的关键信息作为索引数据保存到hbase数据库中;在hbase数据库中对在最近发生时间段的起始时间以后收到的迟到记录数据进行剔除重复记录,将非重复的迟到记录数据输出为迟到记录出口文件给下游使用。
本发明将记录数据按发生时间和接收时间的间隔分类处理,充分利用了分布式内存数据库处理速度快和hbase数据库的海量存储空间的优势,实现了云化系统下对记录数据的高速剔重处理和较长时间的保存,提高了系统效率且节省了存储费用。
进一步,s2中,剔除重复记录的过程包括:将从上游收到的及时记录数据插入分布式内存数据库,根据该次插入操作的返回值判断该及时记录数据是否为重单,若是重单,则将该及时记录数据输出到重单文件,若不是重单,则将该及时记录数据作为被保留的及时记录数据进行后续处理。
具体的,在分布式内存数据库中,插入语句操作后会有返回值,如果插入及时记录数据到分布式内存数据库中时,分布式内存数据库中已经存在一条及时记录数据对应的索引数据与该及时记录数据对应的索引数据有相同索引值,则该及时记录数据不能被插入到分布式内存数据库中,会有返回值提示操作失败,根据此返回值可以判断本次插入的及时记录数据是重单;否则,会有返回值提示操作成功,则根据此返回值可以判断本次插入的及时记录数据不是重单。
该改进中,根据插入操作的返回值来判断及时记录数据是否为重单,不占用多余存储空间和系统运行资源,简单高效。
进一步,s2中,分布式内存数据库的索引表按时间轮流顺序建立多个分索引表,根据s1中预先设定的发生时间与收到时间的间隔范围定时将过期的分索引表清空。
具体的,分布式内存数据库的索引表,按时间进行轮流,分布式内存数据库里只保留较短时间内的索引数据,保证满足对及时记录数据进行剔重即可,对索引表按时间进行分索引表组织,及时把过期的表内容清空。
该改进中,建立分索引表后定时将已过期分索引表数据清空,能及时释放空间,给新的索引数据提供空间,能节约布置系统需要的软硬件资源,提高了系统整体运行效率。
进一步,索引数据包括以下内容:索引值、记录数据文件名和记录数据的序号;s3中,及时记录索引文件中的索引数据采用mapreduce的方式导入hbase数据库。
具体的,从上游接收到的记录数据都有表示其来源的记录数据文件名和记录数据的序号,可以提取成索引数据用于剔重处理。hbase数据库是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用hbase数据库可搭建起大规模结构化存储集群,实时性能不是很高,但很适合海量的数据存储查询。mapreduce方式在大数据和分布式计算方面的具有较明显的速度和性能优势,用于大规模数据集的并行运算,及时数据索引文件一般是大文件,基于大文件的mapreduce导入能充分体现其优势。在电信支撑系统中,利用hbase数据库海量的优点,能满足由于迟到cdr的存在而导致系统中索引的跨度较长时间的要求。
该改进中,索引数据只保存与记录数据有关的最关键的信息,简洁且不缺少必需信息;hbase数据库中的mapreduce的方式特别适合在大数据和分布式计算方面应用,在处理大文件方面具有处理能力强,速度快的优势。
进一步,hbase数据库中,对插入的有相同索引值的索引数据按进入hbase数据库的先后顺序分版本号全部保存;
s5中,剔除重复记录的过程包括:将在该发生时间段的起始时间以后收到的迟到记录数据的索引数据查找出来,对相同索引值的索引数据的不同版本号中的记录数据文件名和记录数据的序号与最早版本比较,若两项信息不完全相符,则是重单,将该迟到记录数据输出到重单文件,若两项信息完全相符,则不是重单,将该迟到记录数据输出为迟到记录出口文件给下游使用。
具体的,迟到记录数据的入库和剔重是在相同发生时间段的及时记录数据的索引数据导入hbase数据库之后进行的,如果迟到记录数据和及时记录数据是重复的,那么由于迟到记录数据接收时间较晚,在核对相同索引值的不同版本号的索引数据的记录数据文件名和记录数据的序号时,因为最先插入hbase数据库的索引数据的版本最小,所以迟到记录数据的索引数据的版本不是最小的,且迟到记录数据的索引数据的记录数据文件名和记录数据的序号不会与最小版本的索引数据完全相符,因此迟到记录数据会被判断为重单且进行剔除。
迟到记录数据是在最近发生时间段内的及时记录索引文件导入hbase数据库的状态为已完成后进行入库和剔重的,同一条迟到记录数据可能会被多次接收,产生多个版本的索引数据保存在hbase数据库,因此在对相同索引值的不同版本号的索引数据与最小版本号的索引数据的记录数据文件名和记录数据的序号进行比较时,若与最小版本号的索引数据的记录数据文件名和记录数据的序号完全相符,则是同一条迟到记录数据,不能判断为重单;如果不完全相符,则说明后进入hbase数据库的那一条索引数据对应的迟到记录数据与最先进入的那一条重复,则应该被判断为重单且进行剔除。
该改进中,hbase数据库具有海量存储的优势,且能保留多个版本的索引数据,能应对时间跨度大的海量记录数据,为数据剔重提供了长久有效的保障;hbase数据库中对每一条索引数据分版本号记录,在数据剔重时只需要与最早版本比较,而不需要依次比较,提高了剔重效率。
实施例2
如图2所示,一种云化架构下的记录数据剔重处理系统,包括:
预处理模块,用于根据预先设定的发生时间与收到时间的间隔范围,将从上游收到的记录数据分为及时记录数据和迟到记录数据;
及时记录剔重模块,用于将从上游收到的及时记录数据插入分布式内存数据库,提取及时记录数据的关键信息作为索引数据保存到分布式内存数据库中的索引表,剔除重复记录后将被保留的及时记录数据输出为及时记录出口文件给下游使用,并将对应的索引数据输出至及时记录索引文件;
及时记录入库模块,用于根据预处理模块中预先设定的发生时间与收到时间的间隔范围,按发生时间段将及时记录剔重模块中输出的及时记录索引文件中的索引数据导入hbase数据库;
迟到记录入库模块,用于在最近发生时间段内的及时记录索引文件导入hbase数据库的状态为已完成后,将从上游收到的迟到记录数据插入hbase数据库,提取迟到记录数据的关键信息作为索引数据保存到hbase数据库中;
迟到记录剔重模块,用于在hbase数据库中对在最近发生时间段的起始时间以后收到的迟到记录数据进行剔除重复记录,将非重复的迟到记录数据输出为迟到记录出口文件给下游使用。
具体的,例如,在云化环境下,电信支撑系统中对cdr数据(即calldetailrecords,用户使用详细记录)基本上做到“准实时”;据统计,99.9%的cdr数据在3小时内到达支撑系统,即可称为及时cdr数据,只有一小部分的cdr数据,在3小时之后陆续到达,可称为迟到cdr数据。因此,将类似此种情况下的记录数据分类后进行剔重处理,能实现云化系统下对记录数据进行高速剔重处理,从而适应系统云化后高效的特点。
由于s2中输出的及时记录索引文件中的索引数据是按照发生时间段导入hbase数据库的,因此在最近发生时间段内的及时记录索引文件导入hbase数据库的状态为已完成后,将该发生时间段的起始时间以后从上游收到的迟到记录数据插入hbase数据库,提取迟到记录数据的关键信息作为索引数据保存到hbase数据库中;在hbase数据库中对在最近发生时间段的起始时间以后收到的迟到记录数据进行剔除重复记录,将非重复的迟到记录数据输出为迟到记录出口文件给下游使用。
本发明将记录数据按发生时间和接收时间的间隔分类处理,充分利用了分布式内存数据库处理速度快和hbase数据库的海量存储空间的优势,实现了云化系统下对记录数据的高速剔重处理和较长时间的保存,提高了系统效率且节省了存储费用。
进一步,及时记录剔重模块还用于,将从上游收到的及时记录数据插入分布式内存数据库,根据该次插入操作的返回值判断该及时记录数据是否为重单,若是重单,则将该及时记录数据输出到重单文件,若不是重单,则将该及时记录数据作为被保留的及时记录数据进行后续处理。
具体的,在分布式内存数据库中,插入语句操作后会有返回值,如果插入及时记录数据到分布式内存数据库中时,分布式内存数据库中已经存在一条及时记录数据对应的索引数据与该及时记录数据对应的索引数据有相同索引值,则该及时记录数据不能被插入到分布式内存数据库中,会有返回值提示操作失败,根据此返回值可以判断本次插入的及时记录数据是重单;否则,会有返回值提示操作成功,则根据此返回值可以判断本次插入的及时记录数据不是重单。
该改进中,根据插入操作的返回值来判断及时记录数据是否为重单,不占用多余存储空间和系统运行资源,简单高效。
进一步,及时记录剔重模块对分布式内存数据库的索引表按时间轮流顺序建立多个分索引表,根据预处理模块中预先设定的发生时间与收到时间的间隔范围定时将过期的分索引表清空。
具体的,分布式内存数据库的索引表,按时间进行轮流,分布式内存数据库里只保留较短时间内的索引数据,保证满足对及时记录数据进行剔重即可,对索引表按时间进行分索引表组织,及时把过期的表内容清空。
该改进中,建立分索引表后定时将已过期分索引表数据清空,能及时释放空间,给新的索引数据提供空间,能节约布置系统需要的软硬件资源,提高了系统整体运行效率。
进一步,索引数据包括以下内容:索引值、记录数据文件名和记录数据的序号;及时记录入库模块还用于将及时记录索引文件中的索引数据采用mapreduce的方式导入hbase数据库。
具体的,从上游接收到的记录数据都有表示其来源的记录数据文件名和记录数据的序号,可以提取成索引数据用于剔重处理。hbase数据库是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,基于h利用hbase数据库可搭建起大规模结构化存储集群,实时性能不是很高,但很适合海量的数据存储查询。mapreduce方式在大数据和分布式计算方面的具有较明显的速度和性能优势,用于大规模数据集的并行运算,及时数据索引文件一般是大文件,基于大文件的mapreduce导入能充分体现其优势。在电信支撑系统中,利用hbase数据库海量的优点,能满足由于迟到cdr的存在而导致系统中索引的跨度较长时间的要求。
该改进中,索引数据只保存与记录数据有关的最关键的信息,简洁且不缺少必需信息;hbase数据库中的mapreduce的方式特别适合在大数据和分布式计算方面应用,在处理大文件方面具有处理能力强,速度快的优势。
进一步,hbase数据库中,对插入的有相同索引值的索引数据按进入hbase数据库的先后顺序分版本号全部保存;
迟到记录剔重模块还用于将该发生时间段的起始时间以后收到的迟到记录数据的索引数据查找出来,对相同索引值的索引数据的不同版本号中的记录数据文件名和记录数据的序号与最早版本比较,若两项信息不完全相符,则是重单,将该迟到记录数据输出到重单文件,若两项信息完全相符,则不是重单,将该迟到记录数据输出为迟到记录出口文件给下游使用。
具体的,迟到记录数据的入库和剔重是在相同发生时间段的及时记录数据的索引数据导入hbase数据库之后进行的,如果迟到记录数据和及时记录数据是重复的,那么由于迟到记录数据接收时间较晚,在核对相同索引值的不同版本号的索引数据的记录数据文件名和记录数据的序号时,因为最先插入的索引数据的版本最小,所以迟到记录数据的索引数据的版本不是最小的,且迟到记录数据的索引数据的记录数据文件名和记录数据的序号不会与最小版本的索引数据完全相符,因此迟到记录数据会被判断为重单且进行剔除。
迟到记录数据是在最近发生时间段内的及时记录索引文件导入hbase数据库的状态为已完成后进行入库和剔重的,同一条迟到记录数据可能会被多次接收,产生多个版本的索引数据保存在hbase数据库,因此在对相同索引值的不同版本号的索引数据与最小版本号的索引数据的记录数据文件名和记录数据的序号进行比较时,若与最小版本号的索引数据的记录数据文件名和记录数据的序号完全相符,则是同一条迟到记录数据,不能判断为重单;如果不完全相符,则说明后进入hbase数据库的那一条索引数据对应的迟到记录数据与最先进入的那一条重复,则应该被判断为重单且进行剔除。
该改进中,hbase数据库具有海量存储的优势,且能保留多个版本的索引数据,能应对时间跨度大的海量记录数据,为数据剔重提供了长久有效的保障;hbase数据库中对每一条索引数据分版本号记录,在数据剔重时只需要与最早版本比较,而不需要依次比较,提高了剔重效率。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!