一种面向数据库一体机的内存数据仓库查询处理实现方法与流程
本发明涉及一种数据仓库实现方法,特别是关于一种面向数据库一体机的内存数据仓库查询处理实现方法。
背景技术:
数据库一体机是一种面向数据库大数据存储和高性能查询处理应用特点而设计的软、硬件一体化设计解决方案。在硬件设计方面,数据库一体机通常是以机柜为单位的服务器集群架构,通过内置的高速网络和服务器集群提供可扩展性的大数据存储和处理能力。在机柜内提供不同的服务器集群规模扩展能力,并以机柜为单位实现横向扩展;数据库一体机通常采用小规模的高性能计算服务器集群用于复杂查询处理服务和大规模低端存储服务器集群用于大数据存储服务,是一种不对称的服务器集群架构;数据库一体机通常采用特殊的硬件加速其存储访问及查询处理性能,如Oracle Exadata数据库一体机采用大容量PCI-e闪存缓存磁盘数据,提高数据访问性能,IBM Netezza使用现场可编程门阵列FPGA作为专用的数据库加速卡,用于处理计算代价较大的解压缩、投影、过滤等简单操作,而多核CPU则处理较为复杂的聚合、连接、汇总等操作。在软件方面,数据库系统需要面向数据库一体机特殊的硬件架构优化软件设计,如优化数据分布存储策略,优化面向不对称集群的查询处理策略,优化面向新型闪存设备及新型加速卡设备(如FPGA、GPU、Intel MIC Phi等)的查询优化技术。
数据仓库是数据库一体机最重要的应用领域,随着新型存储和处理器技术的发展,内存数据仓库正逐渐成为新兴的实时OLAP分析处理平台,面向数据库一体机架构的内存数据仓库能够更好地满足大数据实时OLAP应用需求。当前的内存数据仓库技术主要面向同构服务器集群的硬件架构,在面向不对称服务器集群及新型存储、计算设备等方面的优化技术研究还不成熟。因此,如何针对性地面向内存数据仓库一体机架构的特点,以及新型存储及计算设备的特点而系统地设计内存OLAP查询处理技术框架成为目前亟需解决的技术问题:其关键问题是如何适应内存数据仓库一体机的硬件架构特点,充分发挥内存数据仓库一体机的硬件性能优势,提高内存OLAP的整体性能。
技术实现要素:
针对上述问题,本发明的目的是提供一种面向数据库一体机的内存数据仓库查询处理实现方法,该方法能适应内存数据仓库一体机不对称硬件架构下的内存OLAP性能加速需求,充分发挥内存数据仓库一体机的硬件性能优势,提高内存OLAP的整体性能。
为实现上述目的,本发明采取以下技术方案:一种面向数据库一体机的内存数据仓库查询处理实现方法,其特征在于包括以下步骤:1)构建内存数据仓库存储模型;2)构建内存数据仓库一体机分布式存储模型;3)高性能计算服务器集群数据更新策略:当高性能计算服务器集群内存容量不足时,采用循环队列更新策略淘汰最久的数据,更新为最新的数据;4)实现内存数据仓库一体机OLAP查询处理。
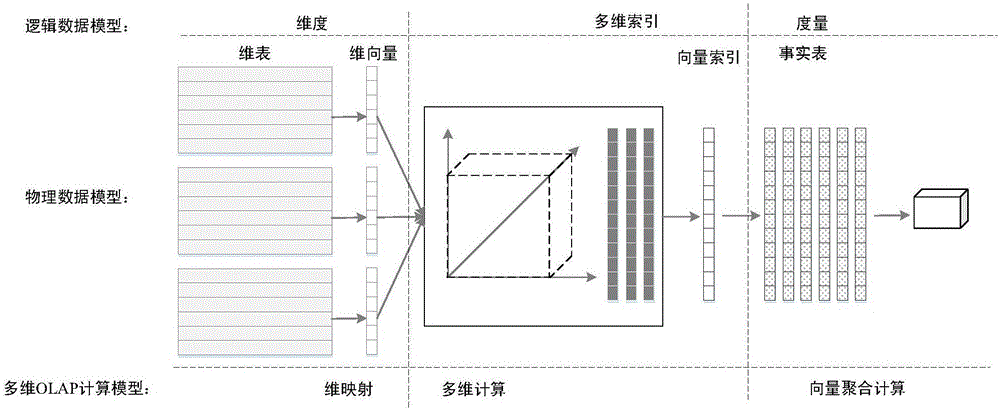
所述步骤1)中,内存数据仓库存储模型采用融合的多维关系OLAP模型,多维关系OLAP模型构建过程如下:1.1)逻辑数据模型:将数据仓库的多维数据集结构划分为维度、多维索引和度量三种数据结构;1.2)物理数据模型:维度存储为维表和维向量,维表采用行存储或列存储数据库引擎,维向量以数组结构表示维度,数组下标映射为维度坐标;多维索引采用列存储模型;度量存储为事实表,采用列存储;1.3)多维OLAP查询模型包括维映射、多维索引计算和聚合计算三个处理阶段。
所述步骤1.3)中,具体处理过程为:1.3.1)维映射:将OLAP查询映射到相关维表,生成维向量,维向量中的非空值标识当前OLAP查询对应的多维数据子集在各相关维度上的分量值;1.3.2)多维索引计算:将多维索引映射到相应的维向量实现对度量数据的多维过滤,并创建向量索引,标识满足当前OLAP查询的多维索引项,向量索引中的非空值代表OLAP查询分组属性所构造的聚合数据立方体的多维地址;通过多维过滤获得满足OLAP查询条件数据的度量数据集合,为度量数据创建向量索引;1.3.3)聚合计算:度量数据基于向量索引完成分组聚集计算。
所述步骤2)中,内存数据仓库一体机分布式存储模型采用以下两种分布式存储策略:2.1)维表、多维索引集中存储,事实表分布存储策略;2.2)维表集中存储,多维索引、事实表分布存储策略。
所述步骤2.1)中,具体存储策略如下:2.1.1)较小的维表集中存储于高性能计算服务器集群;当计算集群配置较高时,内存数据仓库的多维索引集中存储于高性能计算服务器集群节点;2.1.2)庞大的事实表数据采用水平分片方式分布存储于存储服务集群节点上;2.1.3)多维计算生成的向量索引传输到相应的存储服务器集群节点,完成聚合计算。
所述步骤2.2)中,具体存储策略为:当高性能计算服务器集群内存容量相对存储服务集群内存容量较小且无法存储内存数据仓库全部的多维索引数据时,采用维表集中存储于高性能计算服务器集群,多维索引和事实表采用水平分片方式分布地存储于高性能计算服务器集群和存储服务器集群中。
所述步骤4)中,具体的内存OLAP查询处理方法如下:4.1)OLAP查询在高性能计算服务器集群执行,OLAP查询命令分解为相关维表上的维向量生成命令,过滤维表记录,投影出分组属性并对分组属性进行字典编码,以字典表编码作为维表记录对应的维向量单元值,不满足过滤条件的维表记录对应的维向量单元置为空值,创建OLAP查询相关的各维向量;4.2)采用多维索引集中存储,事实表分布存储策略时,多维索引按事实表物理分片进行逻辑分片;4.3)采用多维索引、事实表分布存储策略时,每个服务器节点保存完整的多维索引和事实数据分片,各服务器节点从高性能计算服务器集群下载维向量到本地节点,完成本地化的OLAP计算;4.4)当服务器节点配置有众核协处理器加速卡时,采用协处理器加速卡加速多维索引计算方法;4.5)在存储服务器节点端,当内存容量小于数据分片时,采用优化策略一完成多维索引计算。
所述步骤4.2)中,OLAP查询包括以下三个步骤:4.2.1)多维索引根据OLAP查询生成的维向量进行多维过滤计算,生成相应的向量索引,向量索引中的空值单元用于过滤事实表记录,非空值代表事实表记录在OLAP查询中的分组编码;当多维索引在OLAP查询相关维向量映射的位置取值均为非空时,将相关维向量映射值对应的分组数据立方体多维坐标转换为一维坐标存储在向量索引对应的单元中;4.2.2)将创建的向量索引按逻辑分片发送到存储服务器集群相应的节点上,通过向量索引过滤度量列,并进行聚合计算;4.2.3)存储服务器集群节点上的聚合结果传输回高性能计算服务器集群进行全局聚合结果归并操作,获得全局聚合结果,并将聚合结果对应的分组数据立方体的多维坐标映射到各维向量分组字典表,转换为分组属性,输出OLAP查询处理结果。
所述步骤4.4)中,具体步骤如下:4.4.1)按照协处理器加速卡内存容量对多维索引和向量索引进行划分,按最大化协处理器加速卡内存利用率的原则分配适合协处理器加速卡内存容量的最大分片,并复制到协处理器加速卡内存;4.4.2)查询执行时,将维向量复制到协处理器加速卡内存,通过协处理器加速卡完成基于维向量映射的多维索引计算,生成向量索引,并复制回内存,更新相应的向量索引分片;4.4.3)内存多维索引分片基于维向量由CPU完成多维索引计算,并生成相应的向量索引分片;4.4.4)CPU与协处理器加速卡处理不同的多维索引数据分片,两个多维索引分片上的计算并行执行。
所述步骤4.5)中,优化策略一如下:4.5.1)当节点内存能够存储多维索引和部分度量列时,多维索引全部内存存储,事实数据以列为存储单位,按LRU算法在内存存储频繁访问的度量列,不频繁访问的度量列存储于闪存;4.5.2)当节点内存不能存储全部多维索引列时,多维索引以列为单位存储于节点服务器内存或闪存;多维索引以列为单位按LRU算法选择频繁使用的多维索引列存储于内存;4.5.3)在多维索引计算时,内存中的多维索引列先执行维向量映射操作,向量索引记录内存多维索引列的部分计算结果,并且以向量索引中非空值位置作为索引访问闪存中的多维索引列,完成其余的多维索引计算任务。
本发明由于采取以上技术方案,其具有以下优点:1、本发明通过构建面向数据库一体机高性能计算服务器集群和存储服务器集群、众核协处理器加速卡及闪存等新型计算、存储硬件的内存OLAP数据模型,将数据仓库多维数据集划分为维度、多维索引和度量三类数据,分别对应高性能计算服务器集群及众核协处理器加速卡内存及计算资源,存储服务器集群的内存、闪存及计算资源,实现数据存储和计算特征与数据库一体机硬件特点相适应;将内存OLAP查询处理简化为维映射计算、多维索引计算和聚合计算,将数据库最复杂的连接操作转换为基于简单向量数据结构的多维索引计算,使数据结构和算法设计更加适合众核协处理器加速卡的程序设计特点,通过新型计算硬件加速OLAP核心性能;将OLAP查询任务在数据库一体机高性能计算服务器集群、众核协处理器加速卡和存储服务器集群上进行优化配置,提高数据库一体机不对称存储与计算资源的利用率,提高内存OLAP整体性能;OLAP查询处理任务分解为在不同计算平台之间的流水处理任务,可以进一步将多个查询的不同处理阶段在数据库一体机平台上流水并行处理,提高系统OLAP查询吞吐性能。2、本发明针对数据库一体机不对称的服务器集群架构和闪存、协处理器加速卡的硬件配置提出面向硬件特性的内存OLAP查询优化技术,最大化内存数据仓库一体机通过硬件对内存OLAP性能的优化作用。3、在内存数据库仓库一体机不对称硬件架构下,在存储模型上,本发明采用将较小的维度和多维索引数据集中存储于高性能计算服务器集群,将较大的度量数据存储于存储服务器集群的数据分布策略,使数据仓库的数据特点与数据库一体机高性能计算服务器集群与存储集群的存储容量特点相适应。4、在计算模型上,本发明采用通过众核协处理器加速内存OLAP查询处理技术,利用众核协处理器加速卡(如FPGA、GPU、Intel MIC Phi等)并行计算能力强大、价格低、能耗低的特点加速内存OLAP的多维索引计算处理阶段,提高整体OLAP查询处理性能。
综上所述,本发明适用于面向内存数据仓库一体机的内存OLAP应用场景,能够适应数据库一体机不对称硬件架构下的内存OLAP性能加速需求。
附图说明
图1是数据库一体机硬件架构示意图;
图2是本发明所使用的逻辑数据模型、物理数据模型和多维OLAP计算模型示意图;
图3是本发明维表、多维索引集中存储,事实表分布存储策略示意图;
图4是本发明维表集中存储,多维索引、事实表分布存储策略;
图5是本发明高性能计算服务器集群数据更新策略示意图;
图6是本发明面向CPU和众核协处理器架构的多维索引计算示意图;
图7是本发明基于数据库一体机集群的OLAP查询处理示意图;
图8是本发明多查询流水并行执行方法示意图;
图9是本发明实施例OLAP查询处理过程示意图。
具体实施方式
下面结合附图和实施例对本发明进行详细的描述。
本发明提供一种面向数据库一体机的内存数据仓库查询处理实现方法,该方法面向数据库一体机不对称硬件架构,以及闪存、众核协处理器加速卡等新型存储和计算硬件进行优化设计,使之与内存OLAP查询处理特点相适应,提供高性能内存数据仓库OLAP查询处理能力,其具体步聚如下:
1)构建内存数据仓库存储模型:
如图1所示,数据库一体机在硬件架构上通常采用不对称结构,通常由高性能计算服务器集群和存储服务集群构成:高性能计算服务器集群硬件配置较高,如配置有大容量内存或多块高性能众核协处理器加速卡;存储服务集群硬件配置通常相对较低,内存容量相对较小,可能配置少量的协处理器加速卡。根据硬件配置特点,高性能集群主要负责内存数据仓库主要的多维计算任务,而存储集群则适合处理计算复杂度较低的数据处理任务。
针对数据库一体机的硬件架构特点,如图2所示,本发明内存数据仓库存储模型采用融合的多维关系OLAP模型,多维关系OLAP模型构建过程如下:
1.1)逻辑数据模型
将数据仓库的多维数据集结构划分为维度、多维索引和度量三种数据结构。维度对应内存数据仓库多维数据立方体的空间坐标轴,用于构建数据仓库多维数据立方体模型;多维索引对应事实数据在多维数据立方体中的空间坐标,用于映射度量数据在多维数据立方体中的多维空间位置;度量则对应事实数据的各个属性。
1.2)物理数据模型
在物理数据模型中,维度存储为维表和维向量,维表可以采用行存储或列存储数据库引擎,每一条维表记录映射为维度上的唯一坐标值,维向量以数组结构表示维度,数组下标映射为维度坐标;多维索引采用列存储模型,多维坐标存储为独立的多维索引列,标识事实数据在多维数据立方体空间中的多维坐标分量,向量索引是与度量列等长的数组,用于检索多维索引对应的事实数据;度量存储为事实表,采用列存储技术提高数据压缩比和分析处理性能。
1.3)多维OLAP查询模型
OLAP查询是面向多维数据立方体结构的多维操作。基于多维关系OLAP模型的OLAP查询处理包括三个处理阶段:
1.3.1)维映射:将OLAP查询映射到相关维表,生成维向量,维向量中的非空值标识当前OLAP查询对应的多维数据子集在各相关维度上的分量值;
1.3.2)多维索引计算:将多维索引映射到相应的维向量(多维索引值对应相关维向量数组下标值)实现对度量数据的多维过滤,并创建向量索引,标识满足当前OLAP查询的多维索引项,向量索引中的非空值代表OLAP查询分组属性所构造的聚合数据立方体的多维地址;通过多维过滤获得满足OLAP查询条件数据的度量数据集合,为度量数据创建向量索引;
1.3.3)聚合计算:度量数据基于向量索引完成分组聚集计算。
2)构建内存数据仓库一体机分布式存储模型:
在数据仓库中,维表通常较小且增长缓慢,事实表庞大且增长较快,但事实表数据为只读追加模式(即insert-only模式)。在本发明的数据库一体机硬件架构下,根据硬件的配置情况,采用以下两种分布式存储策略:
2.1)维表、多维索引集中存储,事实表分布存储策略:
2.1.1)如图3所示,较小的维表集中存储于高性能计算服务器集群;当计算集群配置较高,如配置有大容量内存、配置多块众核协处理器等加速卡设备时,内存数据仓库的多维索引集中存储于高性能计算服务器集群节点,利用高性能计算服务器集群强大的计算性能完成内存OLAP查询的多维计算任务;
2.1.2)庞大的事实表数据采用水平分片方式分布存储于存储服务集群节点上。
2.1.3)多维计算生成的向量索引传输到相应的存储服务器集群节点,完成聚合计算。
其中,当多维索引超过高性能集群节点存储容量时,按多维索引数据的物理存储顺序将最早的多维索引数据降级为冷数据,分发到相应事实表数据分片所在的存储服务器集群节点,将该部分多维索引计算下推到存储服务器集群节点。
2.2)维表集中存储,多维索引、事实表分布存储策略:
如图4所示,当高性能计算服务器集群内存容量相对存储服务集群内存容量较小且无法存储内存数据仓库全部的多维索引数据时,采用维表集中存储于高性能计算服务器集群,多维索引和事实表采用水平分片方式分布地存储于高性能计算服务器集群和存储服务器集群中。
3)高性能计算服务器集群数据更新策略:当高性能计算服务器集群内存容量不足时,采用循环队列更新策略淘汰最久的数据(如图5所示),更新为最新的数据。具体如下:
多维索引和事实数据采用列存储,列以行组为单位存储,行组列的大小为闪存I/O数据块大小的整数倍,根据列数据访问性能设置行组大小(如1M、2M、4M…行)。根据存储策略(高性能服务器集群只存储多维索引或存储多维索引与事实数据)、列数据宽度和服务器可用内存容量计算内存可容纳的最大行组数n,新增加的数据以行组为单位存储于数据列中。当行组数超过阈值,如最大行组数的90%,则异步地将起始行组对应的列数据同步到闪存中,当全部行组存储满后,将起始行组作为新插入数据的存储单元。整个行组用作一个循环队列,队列尾的行组用于插入新记录,队列首的行组用于淘汰旧数据到闪存。闪存中淘汰的数据通过异步的方式复制到存储服务器集群节点,同步完成后删除高性能计算服务器集群节点闪存中的数据分片。
如图3所示的存储策略中,高性能计算服务器集群集中存储多维索引数据,淘汰的多维索引行组数据根据事实数据在存储服务器集群的分布策略从高性能计算服务器集群节点闪存同步到相应的存储服务器节点内存,保持多维索引行组数据与相应的事实表行组数据存储于相同的节点,将部分多维索引计算下推到存储服务器节点。在图4所示的存储策略中,高性能服务器节点存储多维数据和事实数据。内存数据淘汰策略如图5所示,淘汰的行组由多维索引和事实数据组成,闪存中行组数量达到一定阈值(如32、64…,行组的数量决定向存储服务器数据复制的粒度)时,将闪存中的若干行组作为一个数据分片,按存储服务器集群的数据分布策略分配到存储服务器集群节点,完成旧数据从高性能计算服务器集群向存储服务器集群的转移。
4)实现内存数据仓库一体机OLAP查询处理:
数据库一体机的高性能计算服务器集群和存储服务器集群在存储能力和处理能力的不对称性,服务器节点内处理器和众核协处理器加速卡处理能力的不对称性,以及内存和闪存在存储容量和性能上的不对称要求内存数据仓库一体机的OLAP查询处理是一种松耦合的分布式计算机制,不同的计算阶段可以根据硬件配置分配给不同的存储和计算资源。结合内存数据仓库一体机不同的硬件配置及数据分布策略,具体的内存OLAP查询处理方法如下:
4.1)OLAP查询在高性能计算服务器集群执行,OLAP查询命令分解为相关维表上的维向量生成命令,过滤维表记录,投影出分组属性并对分组属性进行字典编码,以字典表编码作为维表记录对应的维向量单元值,不满足过滤条件的维表记录对应的维向量单元置为空值,创建OLAP查询相关的各维向量。
每个维向量的分组编码构成一个分组数据立方体,维向量中的分组值代表在该维上分组数据立方体的维坐标分量。
4.2)采用多维索引集中存储,事实表分布存储策略时,多维索引按事实表物理分片进行逻辑分片。OLAP查询包括以下三个步骤:
4.2.1)多维索引根据OLAP查询生成的维向量进行多维过滤计算,生成相应的向量索引,向量索引中的空值单元用于过滤事实表记录,非空值代表事实表记录在OLAP查询中的分组编码。当多维索引在OLAP查询相关维向量映射的位置取值均为非空时,将相关维向量映射值对应的分组数据立方体多维坐标转换为一维坐标存储在向量索引对应的单元中;
4.2.2)将创建的向量索引按逻辑分片发送到存储服务器集群相应的节点上,如图2所示,通过向量索引过滤度量列,并进行聚合计算;
4.2.3)存储服务器集群节点上的聚合结果传输回高性能计算服务器集群进行全局聚合结果归并操作,获得全局聚合结果,并将聚合结果对应的分组数据立方体的多维坐标映射到各维向量分组字典表,转换为分组属性,输出OLAP查询处理结果。
4.3)采用多维索引、事实表分布存储策略时,每个服务器节点保存完整的多维索引和事实数据分片,各服务器节点从高性能计算服务器集群下载维向量到本地节点,完成本地化的OLAP计算。
在本地节点,多维索引计算、生成向量索引、聚合计算可以形成流水线,提高OLAP查询处理性能,生成的本地聚合结果返回高性能计算服务器集群节点,由高性能服务器集群节点完成全局聚合结果的归并及输出查询结果任务。
4.4)当服务器节点配置有众核协处理器加速卡时,采用协处理器加速卡加速多维索引计算方法,具体步骤如下:
4.4.1)按照协处理器加速卡内存容量对多维索引和向量索引进行划分,按最大化协处理器加速卡内存利用率的原则分配适合协处理器加速卡内存容量的最大分片,并复制到协处理器加速卡内存;
4.4.2)查询执行时,将维向量复制到协处理器加速卡内存,通过协处理器加速卡完成基于维向量映射的多维索引计算,生成向量索引,并复制回内存,更新相应的向量索引分片;
4.4.3)内存多维索引分片基于维向量由CPU完成多维索引计算,并生成相应的向量索引分片;
4.4.4)CPU与协处理器加速卡处理不同的多维索引数据分片,两个多维索引分片上的计算可以并行执行。
4.5)在存储服务器节点端,当内存容量小于数据分片时,采用如下优化策略多维索引计算:
4.5.1)当节点内存能够存储多维索引和部分度量列时,多维索引全部内存存储,事实数据以列为存储单位,按LRU(最近最少访问)算法在内存存储频繁访问的度量列,不频繁访问的度量列存储于闪存;
4.5.2)当节点内存不能存储全部多维索引列时,多维索引以列为单位存储于节点服务器内存或闪存。多维索引以列为单位按LRU算法选择频繁使用的多维索引列存储于内存;
4.5.3)在多维索引计算时,内存中的多维索引列先执行维向量映射操作,向量索引记录内存多维索引列的部分计算结果,并且以向量索引中非空值位置作为索引访问闪存中的多维索引列,完成其余的多维索引计算任务。
综上所述,本发明涉及的内存数据库一体机OLAP查询处理技术将OLAP查询任务划分为维映射计算、多维索引计算和聚合计算三个流水执行阶段,如图7所示,当OLAP查询处理的维映射计算、多维索引计算和聚合计算三个计算阶段分别分布在高性能计算服务器集群CPU、高性能计算服务器集群协处理器和存储服务器集群节点时,每个阶段的计算结果以向量方式传递给下一个硬件平台继续执行。如图8所示,多个OLAP查询的不同执行阶段可以流水并行,提高数据库一体机不对称硬件平台中各计算资源的利用率,提高系统查询吞吐性能。流水并行计算的理想条件是三个阶段的计算时间相近,各阶段的计算时间由数据量、计算复杂度、处理器内存大小、处理器数量、处理器性能等多个因素决定,需要通过优化配置硬件使三个阶段的计算时间相对均匀,提高数据库一体机硬件平台的计算效率。
下面结合实施例对本发明做进一步的介绍。
如图9所示,在本实施例中,整个OLAP查询处理过程被分为三个处理阶段。内存数据库一体机的高性能服务器集群作为主节点,接受OLAP查询。
在维表处理阶段,高性能服务器集群的CPU将SQL命令中维表上的选择、投影、分组操作应用于相应的维表,投影出分组属性,然后对分组属性进行字典表压缩,为不重复值分配唯一的顺序编号,然后更新维表分组投影为分组投影向量,用字典表编码代替原始分组属性值。如customer表上按WHERE子句c_region=’AMERICA’投影出分组属性c_nation,其中的属性值’Canada’和’Brazil’的字典编码分别为0和1,生成与维表具有一一位置映射关系的维向量。同理,supplier表上生成维向量,分组属性三个成员的字典表编码分别为0,1,2。两个维表对应生成两个维向量。
在多维索引计算阶段,多维索引直接映射到维向量相应的偏移位置,读取对应的分组值,当任一多维索引映射位置为空值时,当前事实表记录不满足查询的输出条件,对应的向量索引位置设置为空值;当两个多维索引值映射的维向量位置均不为空时,将对应的分组编码存储为多维数组下标,如多维索引第一条记录索引列l_CK,l_SK值为2和0,分别映射到维向量取值为1和0的位置,将多维数组A[1][0]下标转换为一维数组下标3,存储于向量索引的第一个位置。当配置充足的众核协处理器加速卡时,多维索引计算在协处理器加速卡上执行。维向量复制到协处理器加速卡内存,与存储于协处理器加速卡内存的多维索引列共同执行多维索引计算,生成向量索引,并复制回内存。当协处理器加速卡内存不能够执行全部多维索引计算时,在内存与协处理器加速卡内存的多维索引列分片上可以并行地执行多维索引计算任务。生成的向量索引用于度量列上的聚合计算,向量索引按与度量数据分片对应的方式划分为向量分片,传输到存储服务器集群对应的节点。
在聚合计算阶段,顺序扫描向量索引并按向量索引非空位置访问对应的度量列记录位置进行聚集计算。如扫描向量索引第一个单元,读取值3,访问度量列l_revenue第一个单元,将度量值946映射到多维数组Agg对应的单元A[1][0](或A[3])中进行累加计算。
当完成所有的聚集计算后,得到多维数组Agg。各存储服务器节点的多维数组在高性能计算服务器集群节点进行聚集结果归并,并将其各数组单元下标映射到维表字典表对应的位置,读取实际的分组属性值,生成查询结果记录。如A[1][0]分别对应customer表中nation取值为Brazil和supplier表中nation取值为Japan,将多维数组下标还原为分组属性值,并与数组单元中的聚集值组合为输出记录。
在OLAP查询执行时间占比最高的多维索引计算阶段,算法使用定长的维表向量、多维索引列和向量索引,连接操作简化为多维索引在维向量上的位置映射,基于数组访问的算法设计能够更好地适应众核协处理器加速卡大规模集成简单核心的硬件特点,更好地发挥其并行计算能力。多维索引计算在内存数据仓库一体机架构下被设计为独立的计算过程,可以利用新型众核协处理器加速卡进一步提高多维索引计算性能,生成的向量索引能够较显著地提高存储服务器节点上度量数据上的聚合计算性能,简化存储服务器节点上的计算复杂度,提高聚合计算效率。
综上所述,数据库一体机是一种不对称硬件架构,高端计算服务器集群和低端存储服务器集群分别面向高性能复杂计算和高扩展存储访问服务,新型闪存和众核协处理器加速卡硬件技术进一步提高了数据库一体机的存储与计算性能。对于内存数据仓库应用而言,提高内存实时OLAP查询处理性能需要根据不同硬件的存储和计算性能特点,有针对性地优化数据分布存储和分布计算任务,利用先进硬件加速OLAP查询处理性能。本发明面向数据库一体机不对称硬件架构而设计了多维关系OLAP模型,将数据仓库划分为较小的维度、中等大小的多维索引和较大的度量数据三部分,与高性能计算服务器集群、众核协处理器加速卡内存以及存储服务器集群的存储能力相适合,优化数据分布存储策略;同时,将OLAP查询处理过程分解为维映射计算、多维索引计算和聚合计算三个阶段,将OLAP查询处理主要计算代价集中到多维索引计算阶段,并通过新型的众核协处理器加速卡硬件加速多维索引计算过程,通过先进硬件提升内存OLAP查询处理性能。
上述各实施例仅用于说明本发明,各部件的数据结构、数据类型、应用位置及实现技术都是可以有所变化的,在本发明技术方案的基础上,凡根据本发明原理对个别部件进行的改进和等同变换,均不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!