一种数据聚类的方法及装置与流程
本发明属于计算机技术领域,尤其涉及一种数据聚类的方法及装置。
背景技术:
随着计算机与信息技术的密切结合,海量的数据在互联网上快速的产生和传播,金融、电信等多个行业需要从海量的数据中获取具有潜在意义的信息,才能在瞬息万变中把握住经济命脉的先机,在科技的发展下,需要处理和分类的信息量与日俱增,信息获取的速度越来越快,信息的种类也越来越复杂,如何对这些种类繁多、对象不明确、不完全的大量信息进行有效地分类,并从中挖掘出我们需要的、有用的信息,是当今业界重要的研究课题。
目前,可通过聚类算法实现这个课题,常用的k-均值聚类算法具有快速的收敛性、良好的伸缩性等优点,在聚类过程中通常能聚类出一较好的结果,然而该算法的聚类效果比较依赖聚类中心的初始值,同时在聚类时易陷入局部解、易受到“噪音”干扰,导致从海量的数据中获取的信息不够准确、聚类的质量不佳。
技术实现要素:
本发明的目的在于提供一种数据聚类的方法及装置,旨在解决聚类结果的好坏对初始聚类中心的依赖性较大,聚类过程易陷入局部最优解、易受“噪音”干扰,导致聚类质量不佳的问题。
一方面,本发明提供了一种数据聚类的方法,所述方法包括下述步骤:
接收输入的待聚类的数据集,为所述数据集生成对应的当前种群,所述当前种群中每个个体包含预设数目个聚类中心;
计算所述当前种群中每个个体的适应度值,并根据所述所有适应度值和所述当前种群的自适应指数,生成所述每个个体的选择概率;
根据所述当前种群中每个个体中的所有聚类中心,将所述数据集中的样本划分到相应的聚类中,并根据所述所有选择概率,进化所述当前种群,生成下一代种群;
当当前进化代数未超过预设的最大进化代数时,获取所述当前种群进化为所述下一代种群时生成优异个体的数目,并根据所述优异个体数目,计算所述下一代种群的自适应指数,将所述下一代种群设置为所述当前种群,跳转至执行计算所述当前种群中每个个体的适应度值的操作;
当所述当前进化代数超过所述最大进化代数时,根据所述下一代种群中的最优个体,生成并输出所述数据集的聚类。
另一方面,本发明提供了一种数据聚类的装置,所述装置包括:
初始化模块,用于接收输入的待聚类的数据集,为所述数据集生成对应的当前种群,所述当前种群中每个个体包含预设数目个聚类中心;
计算模块,用于计算所述当前种群中每个个体的适应度值,并根据所述适应度值和所述当前种群的自适应指数,生成所述每个个体的选择概率;
进化模块,用于根据所述当前种群中每个个体中的所有聚类中心,将所述数据集中的样本划分到相应的聚类中,并根据所述所有选择概率,进化所述当前种群,生成下一代种群;
循环模块,用于当当前进化代数未超过预设的最大进化代数时,获取所述当前种群进化为所述下一代种群时生成优异个体的数目,并根据所述优异个体数目,计算所述下一代种群的自适应指数,将所述下一代种群设置为所述当前种群,跳转至执行计算所述当前种群中每个个体的适应度值的操作;以及
聚类生成模块,用于当所述当前进化代数未超过所述最大进化代数时,根据所述下一代种群中的最优个体,生成并输出所述数据集的聚类。
本发明对数据集的当前种群进行最大进化代数次的进化,从最后进化得到的最优个体中获取数据集的聚类中心,最后根据这些聚类中心对数据集中的样本进行划分,实现对数据集中样本的聚类。其中,在当前种群生成下一代种群的进化过程中,本发明根据当前种群中每个个体的适应度值和当前种群的自适应指数,确定当前种群中每个个体的选择概率,在根据该选择概率对当前种群进行进化生成下一代种群后,根据当前种群进化得到优异个体的数目,计算下一代种群的自适应指数。从而通过进化使得个体的质量在每次聚类时都有所提高,改善了聚类中心的敏感性所带来的不足,通过进化过程中的变异操作有效地避免了聚类过程受到“噪音”点的干扰,通过自适应值的更新调整好个体被选择的概率,有效地跳出局部最优解,进而有效地提高了聚类质量。
附图说明
图1是本发明实施例一提供的数据聚类的方法的实现流程图;
图2是本发明实施例二提供的数据聚类的装置的结构示意图;以及
图3是本发明实施例二提供的数据聚类的装置的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
以下结合具体实施例对本发明的具体实现进行详细描述:
实施例一:
图1示出了本发明实施例一提供的数据聚类的方法的实现流程,为了便于说明,仅示出了与本发明实施例相关的部分,详述如下:
在步骤s101中,接收输入的待聚类的数据集,为数据集生成对应的当前种群,当前种群中每个个体包含预设数目个聚类中心。
在本发明实施例中,待聚类的数据集由多个样本点构成。在数据集中随机选取预设数目个样本点,将这些样本点分别设置为聚类中心,由这些预设数目个聚类中心可构成当前种群中的一个个体,通过重复前述步骤即可生成当前种群中的所有个体。
作为示例地,当数据集中每个样本点的属性维数为d、且当前种群中每个个体包含k个聚类中心时,当前种群中每个个体的长度为d×k,当当前种群大小为n时,初始化后当前种群中第i个个体可表示为xi,0=(ci,1,ci,2,…,ci,k),ci,k为当前种群中第i个个体的第k个聚类中心。该种群编码方式简单,且个体的长度较短,便于从中分解出最好的聚类中心。
在步骤s102中,计算当前种群中每个个体的适应度值,并根据所有适应度值和当前种群的自适应指数,生成每个个体的选择概率。
在本发明实施例中,通过预设的目标函数(例如,误差平方函数),可计算得到当前种群中每个个体的适应度值,适应度值是用来衡量个体好坏的一个数值。在计算得到所有适应度值后,可生成当前种群中所有个体的优劣等级,再根据优劣等级和自适应指数,计算每个个体的选择概率。
具体地,计算得到所有适应度值后,将当前种群中所有个体按照适应度值的大小进行排列,根据排列顺序进行优劣等级划分。例如,排在第一位的个体的优劣等级为1,排在第二位的个体的优劣等级为2,以此类推,当种群的规模为n时,排在最后一位的个体的优劣等级为n。
具体地,当个体按照适应度值从差到好进行排序后,优劣等级越高的个体越优异,此时根据优劣等级和当前种群的自适应指数,计算当前种群中每个个体的选择概率的公式为:
在步骤s103中,根据当前种群中每个个体中的所有聚类中心,将数据集中的样本划分到相应的聚类中,并根据所有选择概率,进化当前种群,生成下一代种群。
在本发明实施例中,根据当前种群中个体中的聚类中心,可对数据集中的样本进行划分,具体地,可根据数据集中样本与聚类中心之间的距离,将样本划分到相应的聚类中。
其中,根据选择概率,进化当前种群,生成下一代种群,可通过下述步骤实现:
(1)根据选择概率,在当前种群中选择目标个体进行变异和交叉,生成新个体。
具体地,根据选择概率,在当前种群中进行选取不同的个体作为基向量和差分向量的末端向量,选择优劣等级较高的个体作为末端向量,由末端向量引导整个向量的走向,使得整个进化过程处于优异个体的引导中,从而有效提高进化过程的收敛效率。
(2)将新个体的适应度值与目标个体的适应度值比较,当新个体优于目标个体时,将新个体设置为下一代种群中的个体,并将优异个体的数目加一,否则将目标个体设置为下一代种群中的个体。
具体地,在进化得到新个体后,计算新个体的适应度值,并将新个体的适应度值与目标个体的适应度值进行比较。在每次进化中,都将优异个体的数目初始化为零,通过优异个体的数目来统计当前进化过程中生成优于原个体的新个体数目。
在步骤s104中,判断当前进化代数是否超过预设的最大进化代数。
在本发明实施例中,当前进化代数用来记录当前对种群进化的次数,最大进化代数用来限制对种群进化的总次数,当当前进化代数超过最大进化代数时,可认为当前种群中个体中的聚类中心以达到最优。当当前进化代数不超过最大进化代数时,执行步骤s105,否则,执行步骤s106。
优选地,在计算得到当前种群中所有个体的适宜度值时,获取所有适应度值中的最优适应度值,可通过判断该最优适应度值是否满足预设的阈值(例如,不超过该预设阈值),来确定当前的聚类中心是够达到最优,从而有效地提高进化过程的效率和聚类的效果。
在步骤s105中,获取当前种群进化为下一代种群时生成优异个体的数目,并根据优异个体数目,计算下一代种群的自适应指数,将下一代种群设置为当前种群。
在本发明实施例中,在当前进化代数未超过预设的最大进化代数时,通过统计的优异个体数目,计算下一代种群的自适应指数,并跳转至执行计算当前种群中每个个体的适应度值的操作,以对下一代种群进行进化。
具体地,在计算下一代种群的自适应指数时,先根据当前种群进化为下一代种群时的优异个体数目,计算对应的优异个体比例。接着,将该优异个体比例与预设的期望值进行比较,根据比较结果,计算下一代种群的自适应指数。
具体地,优异个体比例的计算公式为:
具体地,期望值为u·sr(g),其中,u为预设参数,sr(g)为进化代数为g-1时当前种群进化生成的优异个体比例。
具体地,当优异个体比例不小于期望值时,下一代种群自适应指数的计算公式为λ(g+1)=min(λ(g)+δ·sr(g+1),λmax),否则下一代种群自适应指数的计算公式为λ(g+1)=max(λmin,λ(g)-δ·(1-sr(g+1))),其中,λmin、λmax、δ、u为预设参数。
在步骤s106中,根据下一代种群中的最优个体,生成并输出数据集的聚类。
在本发明实施例中,当当前进化代数超过最大进化代数时,不再循环执行种群的进化操作,此时从下一代种群中获取适应值最优的个体,即最优个体,对该最优个体进行解码,获取其中所有的聚类中心,根据这些聚类中心,将数据集中的样本划分到相应的聚类中去。
在本发明实施例中,根据待聚类的数据集,初始化当前种群,根据当前种群中个体的适应度值,对个体划分优劣等级,并根据当前种群的自适应指数,为不同的个体生成不同的选择概率,好的个体对应较高的选择概率,根据生成的选择概率,进化当前种群,使得好的个体去引导整个进化的收敛方向,当当前进化代数未超过最大进化代数时,根据当前种群进化到下一代种群生成的优异个体数目,调整下一代种群的自适应指数,并根据调整后的自适应指数,更新下一代种群中不同个体的选择概率,对下一代种群进行进化,直至当前进化代数超过最大进化代数,最后,根据最后进化得到的当前种群,得到数据集的聚类结果,从而通过多次的进化,提高数据集的聚类中心的生成质量,并根据进化过程中生成优异个体的数目,调节个体的选择概率,有效地调高了进化过程收敛到较好聚类中心的效率,避免陷入局部最优。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于一计算机可读取存储介质中,所述的存储介质,如rom/ram、磁盘、光盘等。
实施例二:
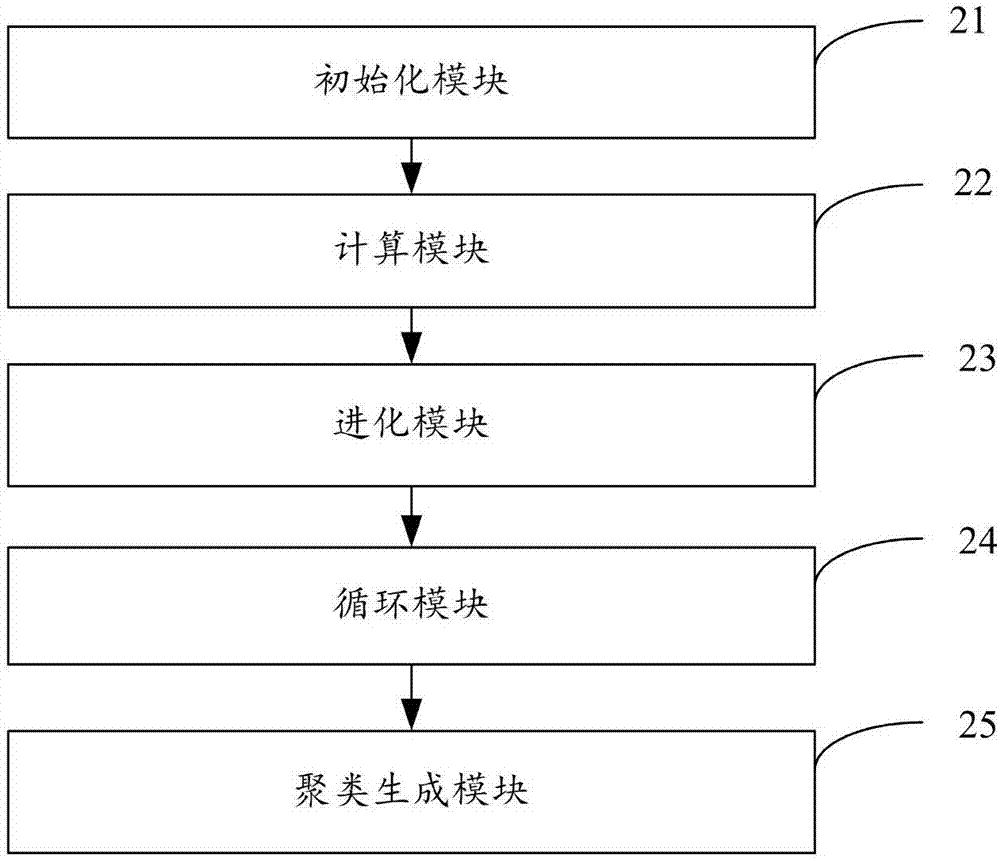
图2示出了本发明实施例二提供的数据聚类的装置的结构,为了便于说明,仅示出了与本发明实施例相关的部分,其中包括:
初始化模块21,用于接收输入的待聚类的数据集,为数据集生成对应的当前种群,当前种群中每个个体包含预设数目个聚类中心;
计算模块22,用于计算当前种群中每个个体的适应度值,并根据适应度值和当前种群的自适应指数,生成每个个体的选择概率;
进化模块23,用于根据当前种群中每个个体中的所有聚类中心,将数据集中的样本划分到相应的聚类中,并根据所有选择概率,进化当前种群,生成下一代种群;
循环模块24,用于当当前进化代数未超过预设的最大进化代数时,获取当前种群进化为下一代种群时生成优异个体的数目,并根据优异个体数目,计算下一代种群的自适应指数,将下一代种群设置为当前种群,跳转至执行计算当前种群中每个个体的适应度值的操作;以及
聚类生成模块25,用于当当前进化代数未超过最大进化代数时,根据下一代种群中的最优个体,生成并输出数据集的聚类。
优选地,如图3所示,初始化模块21包括聚类中心选取模块311、种群生成模块312,其中:
聚类中心选取模块311,用于在数据集中随机预设数目个样本点,将预设数目个样本点分别设置为聚类中心;以及
种群生成模块312,用于将预设数目个聚类中心组合成当前种群中的一个个体,重复随机选取操作,生成当前种群中的所有个体。
优选地,如图3所示,计算模块22包括适应度值计算模块321、选择概率计算模块322,其中:
适应度值计算模块321,用于根据预设的目标函数,计算当前种群中每个个体的适应度值;以及
选择概率计算模块322,用于根据所有适应度值,生成当前种群中每个个体的优劣等级,并根据所有优劣等级和当前种群的自适应指数,计算当前种群中每个个体的选择概率。
优选地,如图3所示,进化模块23包括个体进化模块331、新种群生成模块332,其中:
个体进化模块331,用于根据选择概率,在当前种群中选择目标个体进行变异和交叉,生成新个体;以及
新种群生成模块332,用于将新个体的适应度值与目标个体的适应度值比较,当新个体优于目标个体时,将新个体设置为下一代种群中的个体,并将优异个体数目加一,否则将目标个体设置为下一代种群中的个体。
优选地,如图3所示,循环模块24包括比例计算模块341、自适应指数更新模块342,其中:
比例计算模块341,用于根据优异个体的数目,计算当前种群进化为下一代种群时的优异个体比例;以及
自适应指数更新模块342,用于将优异个体比例和预设的期望值进行比较,根据比较结果,计算下一代种群的自适应指数。
在本发明实施例中,根据待聚类的数据集,初始化当前种群,根据当前种群中个体的适应度值,对个体划分优劣等级,并根据当前种群的自适应指数,为不同的个体生成不同的选择概率,好的个体对应较高的选择概率,根据生成的选择概率,进化当前种群,使得好的个体去引导整个进化的收敛方向,当当前进化代数未超过最大进化代数时,根据当前种群进化到下一代种群生成的优异个体数目,调整下一代种群的自适应指数,并根据调整后的自适应指数,更新下一代种群中不同个体的选择概率,对下一代种群进行进化,直至当前进化代数超过最大进化代数,最后,根据最后进化得到的当前种群,得到数据集的聚类结果,从而通过多次的进化,提高数据集的聚类中心的生成质量,并根据进化过程中生成优异个体的数目,调节个体的选择概率,有效地调高了进化过程收敛到较好聚类中心的效率,避免陷入局部最优。
在本发明实施例中,数据聚类的装置的各单元可由相应的硬件或软件单元实现,各单元可以为独立的软、硬件单元,也可以集成为一个软、硬件单元,在此不用以限制本发明。本发明实施例中各模块的具体实施方式可参考前述实施例一中各步骤的描述,在此不再赘述。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!