一种基于汉字属性向量表示的文本相似性计算方法及系统与流程
本发明涉及中文文本挖掘技术领域,尤其涉及一种基于汉字属性向量表示的文本相似性计算方法及系统。
背景技术:
互联网尤其是移动互联网的快速发展使得社交媒体成为了人们传递信息的主要平台。每天在社交媒体上都产生着难以计数的信息交互,其中文本是这种信息交互的主要载体,此外互联网上产生的信息大多以短文本形式存在。
文本相似度计算是中文文本挖掘领域中的关键问题,其应用场景非常广泛;如在推荐系统中,基于内容相似性的推荐;论文文献查重以及文本聚类、分类等;在做文本相似度计算之前需要对文本进行向量化表示,传统的处理过程中常基于向量空间模型(Vector Space Model,VSM),然而此种表示方法不仅维度较高空间开销大而且无法表征语义信息;此外,也有基于奇异值分解来获取词的语义信息的方法,可是其计算复杂度偏高。
而当下对于短文本相似性的计算方法中:传统的TF-IDF(词频-逆文档频率)及其他相关向量化文本的方法依赖于词语的共现,但语义相关与否并非与是否有共同的词语一定相关;基于主题模型(Latent Dirichlet Allocation,LDA)的方法,由于短文本的语义的稀疏性问题,也不适用。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于汉字属性向量表示的文本相似性计算方法及系统,能够得到准确有效的短文本分析结果,有利于从海量短文本消息中挖掘出有价值的信息,方便于用户使用。
本发明的目的是通过以下技术方案来实现的:一种基于汉字属性向量表示的文本相似性计算方法,包括以下步骤:
S1.基于汉字属性的向量表示构建文本相似性计算模型;
S2.基于带标注的短文本集,对构建的相似性计算模型进行训练以获取模型的参数,得到成熟的文本相似性计算模型;
S3.将待计算相似度的短文本消息输入成熟的文本相似性计算模型中,得到短文本对之间的相似性,并结果并反馈给用户。
步骤S1中所述文本相似性计算模型的数据处理方式包括以下子步骤:
S11.基于汉字属性将短文本消息向量化;
S12.提取向量化后短文本消息的特征语义向量;
S13.依据短文本的语义特征向量,计算短文本消息的相似性。
所述的步骤S11包括以下子步骤:
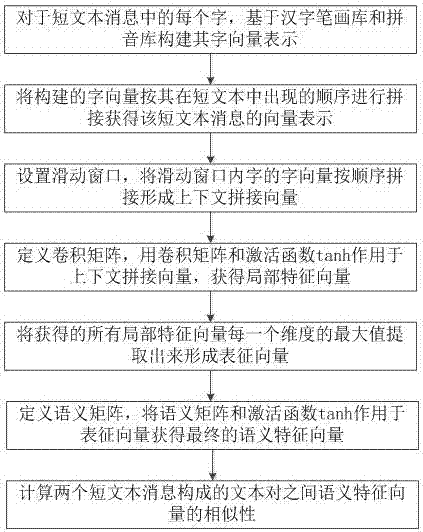
S111.对于短文本消息中的每个字,基于汉字笔画库和拼音库构建其字向量表示,获得该短文本消息中的各个字向量ci,其中ci表示该短文本中第i个字的字向量;
S112.将构建的字向量按其在短文本中出现的顺序进行拼接获得该短文本消息的向量表示。
所述的字向量ci的维度为32位,1-5位分别为该字中包含的横、竖、撇、捺、折的个数,6-31位为汉字对应的26个拼音,第32位为汉字拼音的声调。
所述的步骤S12包括以下子步骤:
S121.设置滑动窗口d,将滑动窗口内字的字向量按顺序拼接形成上下文拼接向量:
第i个滑动窗口内的字向量由第i-d,i-d+1,...i,i+1,i+2,...i+d个字的字向量拼接而成,记为Li:
S122.定义卷积矩阵为WL,用卷积矩阵WL和激活函数tanh作用于上下文拼接向量Li,获得局部特征向量Fi:
Fi=tanh(WL*Li);
S123.将获得的所有局部特征向量Fi每一个维度的最大值提取出来形成表征向量R;
S124.定义语义矩阵为WS,将语义矩阵WS和激活函数tanh作用于表征向量R获得最终的语义特征向量y:
y=tanh(WS*R)。
所述的步骤S13包括:基于距离度量方法func计算两个短文本消息构成的文本对之间语义特征向量(y1,y2)的相似性:
式中,y1表示文本对中第一个短文本消息的语义特征向量,y2表示文本对中第二个短文本消息的语义特征向量。
所述的步骤S2包括以下子步骤:
S21.获取带有相似性标注的短文本集;
S22.利用短文本相似性计算模型,将短文本集中的短文本消息表征为语义特征向量;
S23.利用短文本相似性计算模型,计算短文本对之间的语义相似性;
S24.根据短文本集中的标注与计算得到的短文本对之间的语义相似性,构建最小化误差损失函数作为目标,并利用随机梯度下降训练获得相似性计算模型中的卷积矩阵参数WL和语义矩阵参数WS,获得成熟的相似性计算模型。
所述步骤S3包括以下子步骤:
S31.将至少两个待计算的相似度的短文本消息输入成熟的相似性计算模型中;所述成熟的相似性计算模型,即训练得到的已知卷积矩阵参数WL和语义矩阵参数WS的计算模型;
S32.利用成熟的相似性计算模型,将各个输入短文本消息表征为语义特征向量;
S33.利用成熟的相似性计算模型,计算各个短文本消息两两之间的语义相似性;
S34.将计算得到的结果反馈给用户。
所述的一种基于汉字属性向量表示的文本相似性计算方法采用的系统,包括服务端和客户端;
所述服务端,用于提供文本相似性计算服务,包括:
汉字属性库,包括汉字笔画库和拼音库,用于存储中文汉字的笔画和拼音,为模型构建提供依据;
模型构建模块,用于根据汉字属性的向量表示构建文本相似性计算模型;
模型训练模块,用于根据带标注的短文本集,对构建的相似性计算模型进行训练以获取模型的参数,得到成熟的文本相似性计算模型;
数据管理模块,用于与客户端通讯,将来自客户端的短文本消息输入成熟的计算模型中,得到相似性分析结果,并反馈给客户端;
存储模块,用于将带标注的短文本集、用户输入待分析的短文本消息以及相似性分析结果进行存储;
所述客户端,用于为用户提供输入的接口便于用户输入待分析的短文本消息,同时将分析结果呈现给用户。
所述模型构建模块构建的文本相似性计算模型包括:
短文本消息向量化单元,用于根据短文本消息中的汉字属性,将短文本消息向量化;所述的汉字属性包括汉字的笔画和拼音;
语义特征提取单元,用于提取向量化后短文本消息的特征语义向量;
相似性计算单元,用于依据短文本的语义特征向量,计算短文本消息的相似性。
本发明的有益效果是:本发明基于汉字结构属性和拼音属性构建了中文字向量的表示方法,从而以更简单更低的空间消耗表征了短文本消息,并且实现了自动提取短文本消息的语义特征的功能,从而有效、准确地计算出短文本消息之间的语义相似性,进而有利于从海量短文本消息中挖掘出有价值的信息,方便于用户使用。
附图说明
图1为本发明的方法流程图;
图2为文本相似性计算模型的数据处理流程图;
图3为文本相似性计算模型的训练流程图;
图4为待分析的短文本消息相似性计算流程图;
图5为本发明的系统原理框图。
具体实施方式
下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。
如图1所示,一种基于汉字属性向量表示的文本相似性计算方法,包括以下步骤:
S1.基于汉字属性的向量表示构建文本相似性计算模型;
S2.基于带标注的短文本集,对构建的相似性计算模型进行训练以获取模型的参数,得到成熟的文本相似性计算模型;
S3.将待计算相似度的短文本消息输入成熟的文本相似性计算模型中,得到短文本对之间的相似性,并结果并反馈给用户。
如图2所示,步骤S1中所述文本相似性计算模型的数据处理方式包括以下子步骤:
S11.基于汉字属性将短文本消息向量化;
具体地,所述的步骤S11包括以下子步骤:
S111.对于短文本消息中的每个字,基于汉字笔画库和拼音库构建其字向量表示,获得该短文本消息中的各个字向量ci,其中ci表示该短文本中第i个字的字向量;
S112.将构建的字向量按其在短文本中出现的顺序进行拼接获得该短文本消息的向量表示。
所述的字向量ci的维度为32位,1-5位分别为该字中包含的横、竖、撇、捺、折的个数,6-31位为汉字对应的26个拼音,第32位为汉字拼音的声调。如潆(ying),表示为(2,3,1,5,3,0,0,0,0,0,0,1,0,1,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,1,0,2);
S12.提取向量化后短文本消息的特征语义向量;
具体地,所述的步骤S12包括以下子步骤:
S121.设置滑动窗口d,将滑动窗口内字的字向量按顺序拼接形成上下文拼接向量:
第i个滑动窗口内的字向量由第i-d,i-d+1,...i,i+1,i+2,...i+d个字的字向量拼接而成,记为Li:
S122.定义卷积矩阵为WL,用卷积矩阵WL和激活函数tanh作用于上下文拼接向量Li,获得局部特征向量Fi:
Fi=tanh(WL*Li);
S123.将获得的所有局部特征向量Fi每一个维度的最大值提取出来形成表征向量R;
S124.定义语义矩阵为WS,将语义矩阵WS和激活函数tanh作用于表征向量R获得最终的语义特征向量y:
y=tanh(WS*R)。
S13.依据短文本的语义特征向量,计算短文本消息的相似性。
具体地,所述的步骤S13包括:基于距离度量方法func计算两个短文本消息构成的文本对之间语义特征向量(y1,y2)的相似性:
式中,y1表示文本对中第一个短文本消息的语义特征向量,y2表示文本对中第二个短文本消息的语义特征向量。
如图3所示,所述的步骤S2包括以下子步骤:
S21.获取带有相似性标注的短文本集;
S22.利用短文本相似性计算模型,将短文本集中的短文本消息表征为语义特征向量;
S23.利用短文本相似性计算模型,计算短文本对之间的语义相似性;
S24.根据短文本集中的标注与计算得到的短文本对之间的语义相似性,构建最小化误差损失函数作为目标,并利用随机梯度下降训练获得相似性计算模型中的卷积矩阵参数WL和语义矩阵参数WS,获得成熟的相似性计算模型。
其中,带有相似性标注的短文本集,标注出了与每一个短文本消息相似性最高的短文本消息;(可以理解成带有相似性标注的短文本集由多个短文本对构成,任意一个短文本消息在短文本集中,相似度最高的短文本消息,就是与其构成短文本对的短文本消息)
例如,在本申请的一个实施例中,带标注的短文本集中包含的2n个短文本消息,n为正整数:
A1、A1′、A2、A2′、...、Aj、Aj′、...、An、An′,j=1,2,…,n;
该短文本集中标注的内容为:A1、A1′为最相似文本对,A2、A2′为最相似文本对,Aj、Aj′为最相似文本对,An、An′为最相似文本对。
由于步骤S23中,已经利用模型计算出带标注短文本集中,短文本消息两两之间组成的短文本对的相似性,故在带标注的短文本集中,任意两个短文本消息之间的相似性已经得到;
步骤S24中,根据短文本集中的标注与计算得到的短文本对之间的语义相似性,获取最大化的差距,具体如下:
(1)从带标注的短文本集中随机取出一个最相似短文本对Aj、Aj′,j=1,2,…,n;
(2)将步骤S23中计算得到的Aj、Aj′之间的相似性x1,与Aj和其他短文本消息(带标注的短文本集中除Aj′外任意一个随机短文本消息)之间的相似性x1′求差,得到第一个样本值;
重复上述(1)~(2)过程N次,得到N个样本值,将N个样本值求和,即可得到差距δ;实际上模型希望δ达到最大,即差距达到最大,因此定义误差损失函数为:,
其中Ω为训练集,WL和WS为模型参数,为可调比例因子。此时目标为使误差损失函数最小,因为其可微,所以利用随机梯度下降训练,便可获得相似性计算模型中的卷积矩阵参数WL和语义矩阵参数WS,即获得成熟的相似性计算模型。
如图4所示,所述步骤S3包括以下子步骤:
S31.将至少两个待计算的相似度的短文本消息输入成熟的相似性计算模型中;所述成熟的相似性计算模型,即训练得到的已知卷积矩阵参数WL和语义矩阵参数WS的计算模型;
S32.利用成熟的相似性计算模型,将各个输入短文本消息表征为语义特征向量;
S33.利用成熟的相似性计算模型,计算各个短文本消息两两之间的语义相似性;
S34.将计算得到的结果反馈给用户。
如图5所示,所述的一种基于汉字属性向量表示的文本相似性计算方法采用的系统,包括服务端和客户端;
所述服务端,用于提供文本相似性计算服务,包括:
汉字属性库,包括汉字笔画库和拼音库,用于存储中文汉字的笔画和拼音,为模型构建提供依据;
模型构建模块,用于根据汉字属性的向量表示构建文本相似性计算模型;
模型训练模块,用于根据带标注的短文本集,对构建的相似性计算模型进行训练以获取模型的参数,得到成熟的文本相似性计算模型;
数据管理模块,用于与客户端通讯,将来自客户端的短文本消息输入成熟的计算模型中,得到相似性分析结果,并反馈给客户端;
存储模块,用于将带标注的短文本集、用户输入待分析的短文本消息以及相似性分析结果进行存储;
所述客户端,用于为用户提供输入的接口便于用户输入待分析的短文本消息,同时将分析结果呈现给用户。
所述模型构建模块构建的文本相似性计算模型包括:
短文本消息向量化单元,用于根据短文本消息中的汉字属性,将短文本消息向量化;所述的汉字属性包括汉字的笔画和拼音;
语义特征提取单元,用于提取向量化后短文本消息的特征语义向量;
相似性计算单元,用于依据短文本的语义特征向量,计算短文本消息的相似性。
在本申请的实施例中,使用浏览器为载体:在创建文本相似性计算模型后,将公开的带标注的短文本数据集存储服务端的存储模块,对模型进行训练,得到成熟的计算模块。
设计用户端页面,方便用户输入待分析的短文本集,同时也为用户呈现分析结果。
在用户输入待分析的短文本集(至少两个短文本消息),通过成熟的计算模型对用户输入的短文本集进行相似性分析(短文本消息向量化,语义特征提取,相似性计算),并反馈给用户端界面。
需要说明的是,对具体实施方案的描述仅仅是为帮助理解本发明,而不是用来限制本发明的,任何本领域技术人员均可以利用本发明的思想进行一些改动和变化,只要其技术手段没有脱离本发明的思想和要点,仍然在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!