一种基于HBase的物联网大数据存取方法与流程
本发明一种基于HBase的物联网大数据存取方法属于物联网数据处理技术领域,特别是一种基于HBase数据库的物联网大数据存取方法。
背景技术:
物联网(Internet of things, IoT),即通过GPS、RFID、传感器等设备,按约定的协议,把任何物品与互联网连接起来,进行信息交换和通讯,以实现智能化识别、定位、跟踪、监控和管理的一种网络。简而言之,物联网就是“物物相连的互联网”。其中被连接入互联网的物品即为终端。通常一批具有相同通信协议、数据格式和指令集合的终端被定义为终端类型。通过定义终端类型可以为后续的分表、鉴权等操作提供依据。
在物联网通讯过程中,终端上传的数据信息一般包含以下几个字段:终端ID(terminalID),数据发送时间戳(timestamp),指令编码(cmdID),消息体内容(msgBody)。
HBase是一个分布式、可扩展的大数据存储,能够满足用户对大数据的随机、实时地读写需求。该项目的目标是利用普通的服务器来管理十亿行乘以百万列级大表。HBase中的一行由行键(rowkey)和一个或多个列及其值组成,各行按字母顺序存储。HBase中的一列由一个列族和一个列限定符组成。HBase中的数据存储在一个名为HFile的物理文件中,对于同一个HFile中的所有数据其列族名都是相同的。为了实现表的分布式存储,HBase按rowkey的范围划分了多个region。当HBase集群出现数据倾斜时,HMaster会对region进行分割、迁移。一个好的rowkey设计能够在数据导入时避免多余的region拆分、迁移等操作;在数据读取时,能够提高读取性能,避免复杂的过滤操作。在查询方法上,HBase提供了两种查询方式:针对某一条记录的Get操作以及对某一范围内连续数据的Scan操作。
传统物联网解决方案通常是把数据存储在关系型数据库中,其突出的问题是无法解决大数据量的高频插入和查询,并且方案的成本高昂、可扩展性不佳。而目前相对流行的非关系型数据库(NoSQL)解决方案,虽然能较好地解决大数据量的高频插入,但其对用户的使用限制较多,可用的查询方式也相对单一。针对上述情况,本文发明了一种基于HBase的物联网大数据存取方法,通过对rowkey的合理设计与对HBase的优化配置,实现了为用户提供高效地存储和查询性能的同时,封装出了友好的查询接口,从而真正发挥HBase大数据的性能优势以满足用户的实际需求。
技术实现要素:
本发明的目的是针对上述不足之处提供一种基于HBase的物联网大数据存取方法,以支持海量终端上报数据的可靠存储和高效查询。
本发明是采取以下技术方案实现的:
一种基于HBase的物联网大数据存取方法,包括如下步骤:
1)创建HBase表
每一种终端类型对应一张HBase表,将终端类型名作为HBase的表名,指定列族名称Column Family、列限定符名称Column和Region的拆分策略;
2)将上报数据导入HBase表
在上报数据导入到HBase表的过程中,记录的rowkey生成方法和value的存储方法,包括如下步骤:
2-1) 将上报数据中的终端ID通过hashCode方法获取其hashcode值,对该hashcode值取模,获得一个rowkey前缀;
2-2) 根据上报数据的发送时间以倒排的形式,即Long类型的最大值减去当前时间的时间戳,生成rowkey的时间字段;
2-3) 将步骤2-1)得到的rowkey前缀、经过Base64加密的终端ID字段、分隔符字段以及步骤2-2)的倒排的时间字段共同组成每条数据的rowkey;
2-4) 固定列族名称,将上报数据中的指令编码cmdID作为列名,其余数据作为value存入到HBase中,即完成上报数据的导入;
3)数据查询
基于HBase的物联网大数据存取方法包括两种查询接口,即根据终端ID和时间范围获取该终端该时间范围内的所有按时间排序的数据和根据终端ID获取其当前状态数据信息。
步骤3)中进行数据查询的具体步骤如下:
3-1)根据终端ID计算出前缀,方法与步骤2-1)相同;
3-2)对终端ID进行Base64加密处理,如果需要获取的是当前状态数据则见步骤3-3)到步骤3-6),如果是需要获取某一时间段内的数据则见步骤3-7)到步骤3-10);
3-3)用Long.MAX_VALUE减去当前时间生成时间字段;
3-4)将步骤3-1)中计算的前缀、步骤3-2)中经过处理的终端ID字段、分隔符字段以及3-3)中得到的时间戳字段共同拼接成HBase Scan对象的startRowKey;
3-5)调用HBase Scan对象中的setBatch(1);
3-6) 利用以上生成的Scan对象获取当前状态数据;
3-7)用Long.MAX_VALUE减去指定时间范围中的起始时间戳得到endRowKey的时间字段;
3-8)用Long.MAX_VALUE减去指定时间范围中的终止时间戳得到startRowKey的时间字段;
3-9) 将步骤3-1)中计算的前缀、步骤3-2)中经过处理的终端ID字段、分隔符字段以及步骤3-7)和步骤3-8)中得到的时间戳字段共同拼接成HBase Scan对象的startRowKey和endRowKey;
3-10) 利用以上生成的Scan对象获取当前状态数据。
在步骤1)中每一种终端类型对应一张HBase表,是用于实现对查询操作的权限控制,将HBase表与所属用户的对应关系存储到关系型数据库中,在进行查询操作时,先根据关系型数据库中的结果判断用户是否有查询权限,再根据所调用的查询接口的不同,对scan对象进行设置返回查询结果。
步骤1)中将列族名称设置为长度为1个字节的字符(-128~127均可):为了减少空间浪费,列族名称的内容设置的尽可能的短,最短的内容大小为一个字节,只要是一个字节长度的内容即可,这里将列族名称设置为1。
步骤1)中将列限定符名称设置为每条数据中cmdID字段里的内容。
步骤1)中将HBase Region的拆分策略设置为KeyPrefixRegionSplitPolicy,该策略指定的前缀长度设为2。
步骤2-1)中获得的rowkey前缀的长度为2个字节,与步骤1)中Region的拆分策略的前缀长度相对应;hashcode值模值的选取将直接影响到HBase集群的数据平衡性和可扩展性,最佳设置为32767。
步骤2-3)中所述的分隔符字段用于将各个终端ID的数据分隔开,因为生产环境中相同终端类型的终端ID长度可能不同,通过插入分隔符字段能够起到分隔作用,避免针对某一终端进行scan操作后,所得到的查询结果里有与其他终端数据相互混杂的情况;
步骤2-3)中所述分隔符字段为字节‘0’。
步骤2-4)中将所有数据存储在同一个列族中,能够尽可能地减少跨文件检索数据所造成的开销,同时将列族名设计的尽可能简单也有利于节省存储空间。
本发明的优点:本发明充分考虑了物联网应用领域特点和HBase列式存储的特性,设计了合适的rowkey结构和存储规则,实现了数据的高效存储,并以此为基础提供了多种查询接口(根据终端ID和时间范围查询某一范围内的所有按时间排序的数据以及根据终端ID查询最近上报终端状态数据),满足了用户不同应用场景下的需求,并有效地兼顾了系统的可扩展性和数据均衡。
附图说明
以下将结合附图对本发明作进一步说明:
图1是本发明中将上报数据导入HBase表的流程示意图;
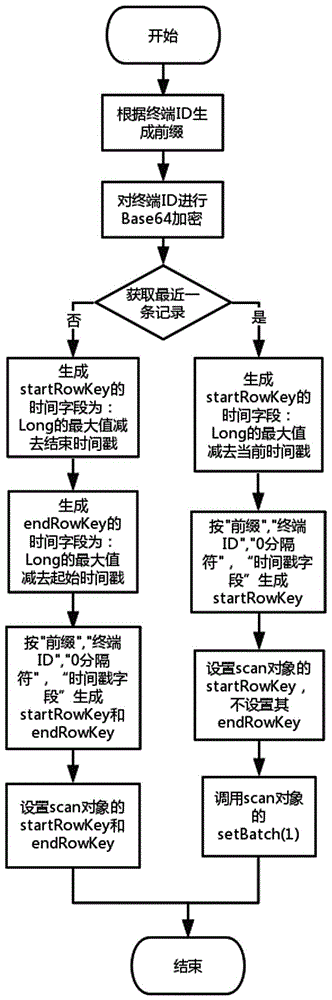
图2是本发明中数据查询的流程示意图。
具体实施方式
为了使本发明的内容和优势更加清晰,下面结合流程图,对其中的技术方案进行完整地描述。
具体实施例:
本发明一种基于HBase的物联网大数据存取方法包括:
1)按如下存储规则创建HBase表
为每一种终端类型建立一张HBase表,每一张表中设置列族的名称为“1”,列限定符名为cmdID,上传的消息体内容为value(如表一所示),指定HBase Region的拆分策略为“KeyPrefixRegionSplitPolicy”,前缀的长度为2。
表一
其中存入HBase的每条数据的rowkey生成规则(如图1所示)如下:
a. 模值选取与集群中regions的个数息息相关,并会直接影响到集群可扩展性,在这里我们可以定义模值的大小为32767,保证生成的前缀为2个字节;
b.根据terminalID计算出对应的hash值,并利用该hash值对上述步骤中设置的region number取模,根据所得到的值转成两个字节的rowkey前缀,具体生成公式:
short prefix = (short) (String.hashCode(terminalID) % <module value>);
c. 考虑到实际应用中终端ID的形式会多种多样,甚至在有些场景下会出现由不可读字节组成的情况。因此我们对terminalID进行Base64加密处理,从而实现了在不影响响应时间的前提下,既方便对终端ID的传输和存储,又将终端ID转换成了一种不易被人直接识别的形式;
d. 根据上报数据的发送时间(timestamp)以倒排的形式生成rowkey的时间字段,即Long.MAX_VALUE-timestamp;
e. 将上述前缀、终端ID、一个字节‘0’以及上述倒排的时间字段共同组成每条数据的rowkey。固定列族名为‘1’,上报数据中的cmdID作为列名,其余数据作为value存入到HBase中,如表二所示;
表二
在物联网领域的实际应用中,用户主要根据一个终端ID获取某一个时间范围内的数据以及某一个终端最近一条状态数据。本发明中基于HBase的rowkey设计和存储规则为实现上述查询方式提供了基础,其原因在于:通过rowkey的前缀设置,能够很好的将数据均匀的分散在HBase每个RegionServer的所有region上,从而避免了数据倾斜,提高了数据查询时的并发性。更为重要的是,在终端ID字段后增加一个字节‘0’能够有效避免数据的混乱交叉,保证在一次针对某一个terminalID的scan操作不会夹杂不相关terminalID的数据,减少了额外地筛选和过滤,提高了查询效率。而时间倒排能够自动地将最近的数据记录存放在数据文件的最前面,避免在查询结束后还要对结果进行额外排序操作。
对于查询接口的实现方案如图2所示,每种查询方案的说明如下:
1)查询某一终端ID下某一时间范围内的数据:假设查询的时间范围为[startTime, endTime],则在调用HBase的scan方法时,将startrowkey的时间字段设置为endTime,endrowkey的时间字段设置为startTime;
2)查询某一终端ID的最近一条历史数据时:在调用HBase的scan方法时,将startrowkey的时间字段设置为Long的最大值,并调用Scan对象的setBatch(1)。
进行数据查询的具体步骤如下:
3-1)根据终端ID计算出前缀,方法与步骤2-1)相同;
3-2)对终端ID进行Base64加密处理,如果需要获取的是当前状态数据则见步骤3-3)到步骤3-6),如果是需要获取某一时间段内的数据则见步骤3-7)到步骤3-10);
3-3)用Long.MAX_VALUE减去当前时间生成时间字段;
3-4)将步骤3-1)中计算的前缀、步骤3-2)中经过处理的终端ID字段、分隔符字段以及3-3)中得到的时间戳字段共同拼接成HBase Scan对象的startRowKey;
3-5)调用HBase Scan对象中的setBatch(1);
3-6) 利用以上生成的Scan对象获取当前状态数据;
3-7)用Long.MAX_VALUE减去指定时间范围中的起始时间得到endRowKey的时间字段;
3-8)用Long.MAX_VALUE减去指定时间范围中的终止时间得到startRowKey的时间字段;
3-9) 将步骤3-1)中计算的前缀、步骤3-2)中经过处理的终端ID字段、分隔符字段以及步骤3-7)和步骤3-8)中得到的时间戳字段共同拼接成HBase Scan对象的startRowKey和endRowKey;
3-10) 利用以上生成的Scan对象获取当前状态数据。
- 还没有人留言评论。精彩留言会获得点赞!