基于用户兴趣的个性化推荐方法与流程
本发明具体涉及一种基于用户兴趣的个性化推荐方法。
背景技术:
随着经济技术的发展和人们生活水平的提高,消费者对于更高品质的生活的追求也越来越明显。
中国作为一个餐饮大国,菜品的种类和样式随着经济的发展不断增加和丰富,各式各样的餐厅、饭店等餐饮服务场所越来越多,同时随着互联网经济和网上消费的发展,海量的在线餐饮服务平台也如雨后春笋般出现。然而,伴随着各种不同的餐饮服务平台的出现,越来越多的用户在就餐时,对于菜品的选择则花费了更多的时间和精力。
推荐系统在电子商务领域有广泛的应用,也有针对美食和餐厅的推荐系统,但还没有真正意义上针对菜品的推荐系统,能够为用户某次就餐提供菜品的推荐。而且,现在推荐系统普遍采用协同过滤算法,该算法是一种基于“人以群分”理念的算法,即兴趣偏好相同的人对商品的偏好也是相似的。因此,协同过滤推荐最重要的是找到和目标用户兴趣相似的最近邻居,根据最近邻居对推荐对象的评分来预测目标用户对未评分的推荐对象的评分,选择预测评分最高的的若干个推荐对象作为推荐结果反馈给用户。
但协同过滤推荐算法存在冷启动、数据稀疏和系统可扩展性等问题:传统协同过滤算法中存在的问题在菜品推荐时尤为突出,新用户就餐时常常需要推荐,但此时新用户还没有产生就餐记录;用户点菜数相对较少,导致用户菜品矩阵稀疏;餐厅中用户数量和菜品数会随着时间逐渐增加,推荐系统中的数据量会因此骤增,传统算法的应对能力也会因此下降。此外,即使传统算法能处理海量的数据,但是由于基于用户的协同过滤中“最近邻搜索”过程随着用户数量的增加,计算量也会线性增长,如何实时的为上千万的用户提供推荐,并且能够应对新用户的注册和新商品的添加则是现在大多数推荐系统都面临的严重问题;最后,现在大多的协同过滤推荐系统都需要用户显示输入评分信息才能为其提供服务,虽然在获取信息方面有用户的积极参与可以提高信息的准确度,但是给用户使用系统也带来了不便。
技术实现要素:
本发明的目的在于提供一种计算效率高、菜品推荐准确率高、菜品推荐效果好的基于用户兴趣的个性化推荐方法。
本发明提供的这种基于用户兴趣的个性化推荐方法,包括如下步骤:
对菜品进行分类的步骤;
获取每个用户在每个餐厅的就餐数据,并依据用户的就餐数据将用户在每个餐厅进行专家用户类别划分;
依据每个用户的兴趣,为每个用户进行兴趣建模的步骤;
当用户在某餐厅发起菜品推荐请求时,选取当前餐厅中对用户兴趣具有权威的候选专家用户,并获取该候选专家用户的初步推荐菜品的步骤;
计算用户与候选专家的相似度的步骤;
依据用户与候选专家的相似度,进行最终的菜品推荐的步骤。
所述的对菜品进行分类为按照层次进行分类,具体分为两类:第一层分类为按照烹饪方法、主食、饮品和外国菜进行分类,第二层分类为依据食材进行分类。
所述的将用户在每个餐厅进行专家用户类别划分,具体为采用如下步骤进行分类:
1.依据获取的每个用户在每个餐厅的就餐数据,将餐厅中所有的数据划分为n个用户菜品矩阵,所述n为预定义的菜品种类个数,用户菜品矩阵中的每一项对应用户对某种菜品的品尝次数;
2.利用HITS模型计算每个用户在不同类别的专家权威度。
所述的利用HITS模型计算每个用户在不同类别的专家权威度,具体为采用如下步骤进行计算:
1)设置初始权威值和枢纽值为用户点菜次数;
2)采用如下公式计算某一类别中某菜品的权威值:
式中dc.a表示类别c中菜品d的权威值;uc.h表示用户对类别c的枢纽值,且
3)用An和Hn分别表示餐厅中第n轮的权威值和枢纽值,M表示用户菜品矩阵,并通过下述两个公式的迭代计算得到最终每个用户和菜品的相应得分:
An=MT·M·An-1
Hn=M·MT·Hn-1
4)选取拥有较高枢纽分数的用户作为某类型的专家用户。
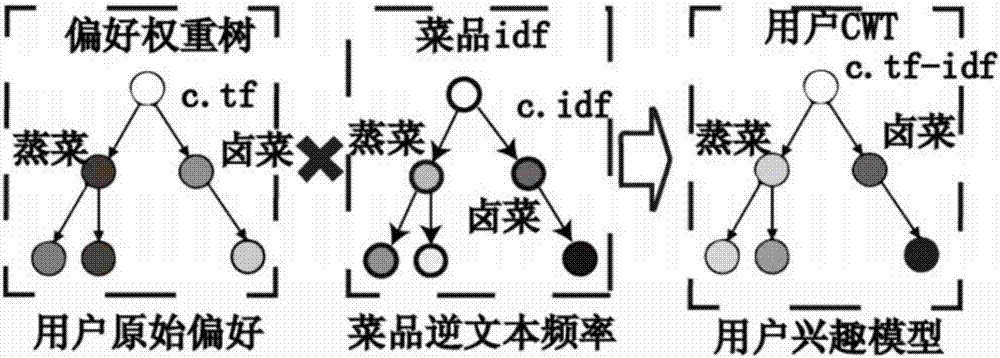
所述的为每个用户进行兴趣建模,具体为采用用户就餐数据中的菜品信息构建种类权重树对用户兴趣进行建模。
所述的利用种类权重树对用户兴趣进行建模,具体为采用如下步骤进行建模:
A.利用用户就餐数据中的点菜记录映射到一个偏好权重树,所述偏好权重树中的节点权重值TF表示用户对该类菜品的原始偏好;
B.计算菜品的逆向文件频率IDF;
C.将步骤A得到的节点权重值和步骤B得到的逆向文件频率相乘得到用户种类权重树的每个节点的权重值,具体为采用如下算式进行计算:
式中第一部分是用户u点菜记录中种类c'的TF值,第二部分表示该种类的IDF值;|{u.di:di.c=c'}|表示用户对种类c’的品尝次数,|u.D|表示用户点的所有菜品的总数,{uj.c′:uj∈U}表示餐厅所有用户u中点过种类c’菜品的用户总和。
所述的选取当前餐厅中对用户兴趣具有权威的候选专家用户,并获取该候选专家用户的推荐菜品,具体为采用兴趣感知算法进行计算和获取当前餐厅中对用户兴趣具有权威的候选专家用户,并获取该候选专家用户的初步推荐菜品。
所述的兴趣感知算法进行计算和获取当前餐厅中对用户兴趣具有权威的候选专家用户,并获取该候选专家用户的初步推荐菜品,具体包括如下步骤:
a.当用户在T时刻在餐厅R发出菜品推荐请求,且要求请求推荐的菜品为K种,则系统计算将产生2K种推荐菜品;
b.专家的选择从用户兴趣对应的种类权重树的底层开始进行:若底层的菜品推荐结果的数量不能满足要求,就移动到种类权重树的上一层继续进行推荐;
c.在某一层进行菜品选择推荐时,首先选择拥有最小权重值的结点或种类,然后使用公式|u.wc/wmin|计算k值,从而确定种类c中需要选择本地专家的个数,并将排名前k位的用户作为候选专家集合e;
d.将候选专家集合e中每个专家的点菜记录加入到候选菜品集合D中,同时将候选专家集合e加入到专家集合E中,直至菜品数量达到要求或者专家数目达到餐厅R中的用户总数,从而得到初步的菜品推荐结果。
所述的计算用户与候选专家的相似度,具体为采用如下步骤进行计算:
Ⅰ.利用如下公式计算用户兴趣对应的种类权重树的同一层次间的相似度,重叠结点c中的最小偏好权重用于表示用户间的共同兴趣;
Ⅱ.采用如下公式计算每层的熵,所述每层的熵用于表示用户偏好的多样性:
式中P(c)为用户点种类为c的菜品的可能性;
Ⅲ.利用如下公式计算两个用户兴趣对应的种类权重树间的相似度:
式中β用来平衡不同层次的权重。
所述的依据用户与候选专家的相似度进行最终的菜品推荐,具体为采用协同过滤算法计算最终的菜品推荐。
所述的采用协同过滤算法计算最终的菜品推荐,具体为采用如下步骤进行计算:
ⅰ.采用如下公式计算用户的遗忘函数F(t):
式中e为自然对数,a、b、c、t0、t均为变量,其中t表示用户请求时间T距离用户最近一次对菜品评分的时间差,单位为天;
ⅱ.选取a=20,b=0.42,c=0.0225,t0=0.00255;
ⅲ.采用如下算式计算得到考虑了时间遗忘因子的用户菜品偏好预测值:
式中o(u',d)为用户u’点菜品d的次数,sim(u,u')为用户的相似度,F(t)为步骤ⅱ得到的遗忘函数。
本发明提供的这种基于用户兴趣的个性化推荐方法,结合用户的兴趣偏好分布,所处餐厅的专家用户意见和用户用餐的时间,为用户推荐满足其个性化需求的菜品,提高了菜品推荐的效率和准确率,同时精确的实时推荐结果可转化为消费行为,提高用户满意度和商家效益;而且,兴趣感知选择算法通过选择每种类别的专家用户减轻相似性计算的运算量,从而实现对用户菜品的实时推荐,通过菜品分类的方法有效解决了菜品多别名,新用户冷启动和系统的可扩展性问题;通过引入时间因子,改进兴趣感知算法和菜品偏好预测效果,进一步提高推荐的准确率。
附图说明
图1为本发明方法的系统结构图。
图2为本发明的用户菜品种类权重树示意图。
图3为本发明的兴趣感知选择算法的流程示意图。
具体实施方式
如图1所示为本发明方法的系统结构图:本发明提供的这种基于用户兴趣的个性化推荐方法,包括如下步骤:
对菜品进行分类的步骤;具体分为两类:第一层分类为按照烹饪方法、主食、饮品和外国菜进行分类,第二层分类为依据食材进行分类
获取每个用户在每个餐厅的就餐数据,并依据用户的就餐数据将用户在每个餐厅进行专家用户类别划分;具体为采用如下步骤进行分类:
1.依据获取的每个用户在每个餐厅的就餐数据,将餐厅中所有的数据划分为n个用户菜品矩阵,所述n为预定义的菜品种类个数,用户菜品矩阵中的每一项对应用户对某种菜品的品尝次数;
2.利用HITS模型计算每个用户在不同类别的专家权威度:
1)设置初始权威值和枢纽值为用户点菜次数;
2)采用如下公式计算某一类别中某菜品的权威值:
式中dc.a表示类别c中菜品d的权威值;uc.h表示用户对类别c的枢纽值,且
3)用An和Hn分别表示餐厅中第n轮的权威值和枢纽值,M表示用户菜品矩阵,并通过下述两个公式的迭代计算得到最终每个用户和菜品的相应得分:
An=MT·M·An-1
Hn=M·MT·Hn-1
4)选取拥有较高枢纽分数的用户作为某类型的专家用户;
上述的获取每个用户在每个餐厅的就餐数据,并依据用户的就餐数据将用户在每个餐厅进行专家用户类别划分的步骤,为在离线状态下进行,并且用于在线推荐时使用,从而能够有效减少在线部分的计算量,保证系统的可扩展性和快速响应的特性;
依据每个用户的兴趣,为每个用户进行兴趣建模的步骤;具体为采用用户就餐数据中的菜品信息构建种类权重树(示意图如2所示)对用户兴趣进行建模:
A.利用用户就餐数据中的点菜记录映射到一个偏好权重树,所述偏好权重树中的节点权重值TF表示用户对该类菜品的原始偏好;
B.计算菜品的逆向文件频率IDF;
C.将步骤A得到的节点权重值和步骤B得到的逆向文件频率相乘得到用户种类权重树的每个节点的权重值,具体为采用如下算式进行计算:
式中第一部分是用户u点菜记录中种类c'的TF值,第二部分表示该种类的IDF值;|{u.di:di.c=c'}|表示用户对种类c’的品尝次数,|u.D|表示用户点的所有菜品的总数,{uj.c′:uj∈U}表示餐厅所有用户u中点过种类c’菜品的用户总和;
当用户在某餐厅发起菜品推荐请求时,选取当前餐厅中对用户兴趣具有权威的候选专家用户,并获取该候选专家用户的初步推荐菜品的步骤;具体为采用兴趣感知算法(如图3所示)进行计算和获取当前餐厅中对用户兴趣具有权威的候选专家用户,并获取该候选专家用户的初步推荐菜品:
a.当用户在T时刻在餐厅R发出菜品推荐请求,且要求请求推荐的菜品为K种,则系统计算将产生2K种推荐菜品;
b.专家的选择从用户兴趣对应的种类权重树的底层开始进行:若底层的菜品推荐结果的数量不能满足要求,就移动到种类权重树的上一层继续进行推荐;
c.在某一层进行菜品选择推荐时,首先选择拥有最小权重值的结点或种类,然后使用公式|u.wc/wmin|计算k值,从而确定种类c中需要选择本地专家的个数,并将排名前k位的用户作为候选专家集合e;
d.将候选专家集合e中每个专家的点菜记录加入到候选菜品集合D中,同时将候选专家集合e加入到专家集合E中,直至菜品数量达到要求或者专家数目达到餐厅R中的用户总数,从而得到初步的菜品推荐结果;
计算用户与候选专家的相似度的步骤;具体为采用如下步骤进行计算:
Ⅰ.利用如下公式计算用户兴趣对应的种类权重树的同一层次间的相似度,重叠结点c中的最小偏好权重用于表示用户间的共同兴趣;
Ⅱ.采用如下公式计算每层的熵,所述每层的熵用于表示用户偏好的多样性:
式中P(c)为用户点种类为c的菜品的可能性;
Ⅲ.利用如下公式计算两个用户兴趣对应的种类权重树间的相似度:
式中β用来平衡不同层次的权重;
依据用户与候选专家的相似度,进行最终的菜品推荐的步骤:具体为采用协同过滤算法计算最终的菜品推荐:
ⅰ.采用如下公式计算用户的遗忘函数F(t):
式中e为自然对数,a、b、c、t0、t均为变量,其中t表示用户请求时间T距离用户最近一次对菜品评分的时间差,单位为天;
ⅱ.选取a=20,b=0.42,c=0.0225,t0=0.00255;
ⅲ.采用如下算式计算得到考虑了时间遗忘因子的用户菜品偏好预测值:
式中o(u',d)为用户u’点菜品d的次数,sim(u,u')为用户的相似度,F(t)为步骤ⅱ得到的遗忘函数。
- 还没有人留言评论。精彩留言会获得点赞!