基于Spark技术的ETL系统及其方法与流程
本发明涉及一种ETL系统及其方法,尤其涉及一种基于Spark技术的ETL系统及其方法。
背景技术:
随着大数据的发展,企业越来越重视数据相关的开发和应用,从而获取更多的市场机会,大数据应用离不开海量数据的清洗和加工,企业通常采用主流的ETL(数据抽取、转换和加载)产品,或直接采用数据库存储过程编码进行数据处理。
目前,主流的ETL产品大多基于单机架构,在处理海量数据时,IO吞吐量、系统资源存在瓶颈,扩展困难且价格昂贵;另一方面,ETL产品注重操作界面的易用性,每个数据加工过程通过画图进行设计,但元数据管理和ETL产品分离,导致数据结构变更时需手动变更相关设计;数据库存储过程编码存在同样的问题,且开发低效,维护困难。
随着Hadoop的出现,分布式平台的线性扩展和低成本,很好地解决了单机搭建数据平台的不足;在Hadoop平台上采用Hive进行数据加工得到较多的认可,但Hive是基于MapReduce分布式计算架构,有先天性不足,MapReduce的每步计算需要读写磁盘,属于高延时迭代。
综上,有必要设计一种基于Spark技术的ETL系统及其方法来弥补上述缺陷。
技术实现要素:
本发明提出一种基于Spark技术的ETL系统及其方法,其解决了现有技术中在处理海量数据时,IO吞吐量、系统资源存在瓶颈,扩展困难且价格昂贵的缺陷。本发明基于Spark技术,可以线性平滑扩展,运行速度快,运行无需人工干预,且易于管理和维护,能充分满足各行业特别是大企业在数据ETL方面的需要。
本发明的技术方案是这样实现的:
本发明公开一种基于Spark技术的ETL系统,其包括数据抽取模块、数据处理模块、数据整合模块、数据输出模块、元数据管理模块和数据存储模块;数据存储模块包括中转数据存储库、整合数据存储库和元数据控制文件;数据抽取模块用于抽取源数据,并根据数据分块规则在分布节点上动态生成多个Spark RDD,再通过线程池启动多个线程来调用数据处理模块对每个Spark RDD进行并行处理;数据处理模块用于读取数据抽取模块生成的Spark RDD,经过元数据匹配检查和一系列数据转换,得到处理后的数据,并保存在中转数据存储库中;数据整合模块用于对当天的中转数据和上一天的整合数据进行全量数据整合或历史数据整合,得到当天整合后数据,并保存在整合数据存储库中;数据输出模块用于根据数据应用系统对数据格式的要求,对当天整合后数据进行格式转换并输出;元数据管理模块用于将系统各种要素进行参数化定义和管理。
其中,数据抽取模块包括数据接入模块和第一分布式数据集生成模块;数据接入模块通过离线抽取和在线抽取的方式直接读取压缩格式的数据文件,并传送至第一分布式数据集生成模块进行后续处理;第一分布式数据集生成模块通过数据接入模块读取源数据,并根据数据分块规则在分布节点上动态生成多个Spark RDD,待数据处理模块进一步处理。
其中,数据处理模块包括数据检查模块和数据转换模块;数据检查模块通过元数据匹配对数据进行检查并生成数据检查报告;数据转换模块用于对数据进行清理和转换。
其中,数据整合模块包括第二分布式数据集生成模块、全量数据整合模块和历史数据整合模块;第二分布式数据集生成模块用于分别读取当天的中转数据和上一天的整合数据,在分布式节点上生成对应的Spark RDD;全量数据整合模块用于读取第二分布式数据集生成模块生成的Spark RDD,根据中转数据中的增、删、改标识,相应对上一天的整合数据Spark RDD中相同健值的数据进行增、删、改操作,处理完成后,形成中转数据Spark RDD存入到整合数据存储库中;历史数据整合模块用于读取当天的中转数据Spark RDD,根据中转数据中的增、删、改标识,对上一天的整合数据Spark RDD中相同健值的数据做相应处理,处理完成后,存入到整合数据存储库中。
其中,数据输出模块包括第三分布式数据集生成模块和目标数据输出模块;第三分布式数据集生成模块用于读取当天的整合数据,在分布式节点上生成对应的Spark RDD;目标数据输出模块用于读取第三分布式数据集生成模块生成的Spark RDD,对当天整合后数据进行格式转换并输出。
其中,元数据管理模块包括元数据定义模块、元数据检查模块和元数据导出模块;元数据定义模块用于使用Excel直接进行元数据定义和维护,其中元数据包括:数据源信息、源数据结构、目标数据格式、目标数据结构、数据转换规则和表达式;元数据检查模块用于根据一系列的元数据规范对元数据进行检查,并输出元数据检查报告;元数据导出模块用于将Excel中的元数据导出为元数据控制文件。
本发明还公开一种基于Spark技术的ETL系统的方法,其包括如下步骤:(S01)抽取源数据,并根据数据分块规则在分布节点上动态生成多个Spark RDD,再通过线程池启动多个线程来调用数据处理模块对每个Spark RDD进行并行处理;(S02)读取数据抽取模块生成的Spark RDD,经过元数据匹配检查和一系列数据转换,得到处理后的数据,并保存在中转数据存储库中;(S03)对当天的中转数据和上一天的整合数据进行全量数据整合或历史数据整合,得到当天整合后数据,并保存在整合数据存储库中;(S04)根据数据应用系统对数据格式的要求,对当天整合后数据进行格式转换并输出;(S05)将系统各种要素进行参数化定义和管理。
其中,步骤(S01)包括如下步骤:(S11)通过离线抽取和在线抽取的方式直接读取压缩格式的数据文件,并传送至第一分布式数据集生成模块进行后续处理;(S12)读取源数据,并根据数据分块规则在分布节点上动态生成多个Spark RDD,待数据处理模块进一步处理。
其中,步骤(S02)包括如下步骤:(S21)通过元数据匹配对数据进行检查并生成数据检查报告;(S22)使用元数据定义的规则或表达式对数据进行清理和转换。
其中,步骤(S03)包括如下步骤:(S31)分别读取当天的中转数据和上一天的整合数据,在分布式节点上生成对应的Spark RDD;(S32)读取步骤(S31)中生成的Spark RDD,根据中转数据中的增、删、改标识,相应对上一天的整合数据Spark RDD中相同健值的数据进行增、删、改操作,处理完成后,形成中转数据Spark RDD存入到整合数据存储库中;(S33)读取步骤(S32)形成的当天的中转数据Spark RDD,根据中转数据中的增、删、改标识,对上一天的整合数据Spark RDD中相同健值的数据做相应处理,处理完成后,存入到整合数据存储库中。
其中,步骤(S04)包括如下步骤:(S41)读取当天的整合数据,在分布式节点上生成对应的Spark RDD;(S42)读取步骤(S41)生成的Spark RDD,对当天整合后数据进行格式转换并输出。
其中,步骤(S05)包括如下步骤:(S51)使用Excel直接进行元数据定义和维护,其中元数据包括:数据源信息、源数据结构、目标数据格式、目标数据结构、数据转换规则和表达式;(S52)根据一系列的元数据规范对元数据进行检查,并输出元数据检查报告;(S53)将Excel中的元数据导出为元数据控制文件。
与现有技术相比,本发明具有如下优点:
1、元数据管理,简单易用,维护方便。本发明采用简单易用的Excel表管理和配置;元数据变更直接在Excel表里进行维护,一目了然。
2、无需编程,开箱即用,自动运行。本发明快速部署,开箱即用,成熟完备的ETL工具箱,涵盖常用的银行数据ETL需求;元数据一旦设置完成,系统自动流水线式运行数据抽取、数据处理、数据整合、数据输出等模块,无需人工干预。源数据变更,只需修改相应的元数据,无需编程。
3、内存计算,性能翻倍,线性拓展。本发明采用Scala编程语言完美结合Spark;利用Spark分布式内存并行计算技术,将中间计算结果缓存在内存,减少磁盘I/O;采用多线程并发运行处理作业提高ETL的性能和资源利用率;本发明较单机ETL工具软件和Hadoop MapReduce,运行速度有数倍的提升。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明基于Spark技术的ETL系统的结构框图。
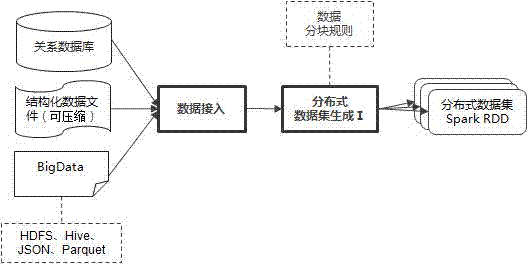
图2为本发明数据抽取模块的结构框图。
图3为本发明数据处理模块的结构框图。
图4为本发明数据整合模块的结构框图。
图5为本发明数据输出模块的结构框图。
图6为本发明元数据管理模块的结构框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为了有助于和澄清随后的实施例的描述,在对本发明的具体实施方式进行详细说明之前,对部分术语进行解释,下列的解释应用于本说明书以及权利要求书。
本发明中出现的ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程,ETL一词较常用在数据仓库,但其对象并不限于数据仓库;ETL是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。
RDD的英文全称为Resilient Distributed Datasets,指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用;Spark RDD的中文名称为弹性分布式数据集。
本发明出现的其他英文均为代码,无任何其它意义。
参照图1至图6,本发明公开本发明公开一种基于Spark技术的ETL系统,其包括数据抽取模块、数据处理模块、数据整合模块、数据输出模块、元数据管理模块和数据存储模块;数据存储模块包括中转数据存储库、整合数据存储库和元数据控制文件,本发明中转数据存储库、整合数据存储库采用列式数据库(如Parquet),显著减少存储空间和提升查询性能;本发明元数据控制文件采用XML文件保存元数据,使元数据管理变得简单和通用。
本发明数据抽取模块支持关系型数据库、结构化数据文件(可压缩)、BigData(如HDFS、Hive、JSON、Parquet)等多种异构数据源,其用于抽取源数据,并根据数据分块规则在分布节点上动态生成多个Spark RDD,再通过线程池启动多个线程来调用数据处理模块对每个Spark RDD进行并行处理;数据处理模块用于读取数据抽取模块生成的Spark RDD,经过元数据匹配检查和一系列数据转换,得到处理后的数据,并保存在中转数据存储库中;数据整合模块用于对当天的中转数据和上一天的整合数据进行全量数据整合或历史数据整合,得到当天整合后数据,并保存在整合数据存储库中;数据输出模块用于根据数据应用系统对数据格式的要求,对当天整合后数据进行格式转换并输出,其中,数据输出格式支持结构化数据文件(可压缩)、关系型数据库、Hive等。
本发明元数据管理模块用于将系统各种要素进行参数化定义和管理;其中,系统各种要素包括数据源信息、源数据结构、目标数据格式、目标数据结构、数据转换规则及表达式等。本发明元数据一旦设置完成,系统自动流水线式运行数据抽取、数据处理、数据整合、数据输出等模块,无需人工干预。且源数据变更,只需修改相应的元数据,无需再编程。
其中,数据抽取模块包括数据接入模块和第一分布式数据集生成模块;数据接入模块通过离线抽取和在线抽取的方式直接读取压缩格式的数据文件,并传送至第一分布式数据集生成模块进行后续处理;第一分布式数据集生成模块通过数据接入模块读取源数据,并根据数据分块规则在分布节点上动态生成多个Spark RDD,待数据处理模块进一步处理。
本发明数据接入模块即为接口层,是本发明连接数据源的统一数据通道,通过该通道可以高并发、高可靠地抽取源数据,数据接入模块支持关系型数据库、结构化数据文件(可压缩)、BigData(如HDFS、Hive、JSON、Parquet)等多种异构数据源。本发明数据接入模块支持离线抽取和在线抽取两种数据抽取方式,离线抽取方式是指源系统生成数据文件,压缩之后通过文件传输软件(如FTP)传送到本系统,再通过数据接入加载到本系统;在线抽取方式是指通过数据接入在线实时抽取源数据到本系统。本发明数据接入模块还支持直接读取压缩格式的数据文件,并进行后续处理,整个过程数据缓存在内存不写磁盘,较以往先解压缩文件然后再读取数据文件的传统做法,在速度上有显著的提升,同时也减少了数据文件的网络传输。
本发明数据分块规则的基本原理是根据数据总量大小和数据记录大小进行动态计算,得到Spark RDD的个数,并按规则将数据加载到各个Spark RDD中。数据分块规则解决了Spark基于缺省参数HDFS Block大小生成Spark RDD的不足,让单条数据记录完整地不被分割地分配到同一个Spark RDD中,从而减少跨Spark RDD计算,提高了数据处理的性能。
其中,数据处理模块包括数据检查模块和数据转换模块;数据检查模块通过元数据匹配对数据进行检查并生成数据检查报告;数据转换模块用于对数据进行清理和转换。数据检查报告提供给数据管理员了解源数据质量,也可以提供给源系统的系统管理员参考。
数据检查模块对元数据匹配检查时,根据预先定义的元数据对读取的数据进行检查,包括数据字段的数量、字段数据类型、字段长度、字段数据格式、是否符合业务校验表达式等方面的检查,检查完成后输出数据检查报告,记录有问题的数据和时间,以及总体的检查情况,如全部数据多少条,其中有问题的数据多少条等。
数据转换模块的功能包括:编码转换、数据格式化、增加字段、按表达式转换等;其中编码转换支持GBK、UTF-16、ANSI编码转换为UTF-8编码。数据格式化为:根据元数据定义的数据格式转换要求,转换为目标格式,如日期,格式为MMDDYYYY转换为YYYY-MM-DD。增加字段为:根据元数据定义的新增字段要求,生成新字段,新增字段的值是固定值,或者是由其它字段组合或计算得到,如新增年龄字段,它的值由出生日期字段值计算得到。按表达式转换为:数据转换功能调用表达式引擎,对元数据定义的表达式进行解析,并按解析后的表达式进行数据转换。表达式支持TRIM、SUBSTRING、CONCAT、REPLACE、IF-ELSE-FI 判断逻辑、基础数学运算、正则表达操作函数等。
其中,数据整合模块包括第二分布式数据集生成模块、全量数据整合模块和历史数据整合模块;第二分布式数据集生成模块用于分别读取当天的中转数据和上一天的整合数据,在分布式节点上生成对应的Spark RDD;全量数据整合模块用于读取第二分布式数据集生成模块生成的Spark RDD,根据中转数据中的增、删、改标识,相应对上一天的整合数据Spark RDD中相同健值的数据进行增、删、改操作,其中删除只做逻辑删除,删除标识置为’1’,处理完成后,形成中转数据Spark RDD存入到整合数据存储库中;历史数据整合模块用于读取当天的中转数据Spark RDD,根据中转数据中的增、删、改标识,对上一天的整合数据Spark RDD中相同健值的数据做相应处理,处理完成后,存入到整合数据存储库中,其中,删标识的,给数据的删除标识置为’1’,失效日期置为源数据日期的前一天;增标识的,新增一条数据,生效日期置为源数据日期,失效日期置为’9999-01-01’;改标识的,修改最近一条数据内容,失效日期置为源数据日期的前一天,并新增一条数据,生效日期置为源数据日期,失效日期置为’9999-01-01’。
其中,数据输出模块包括第三分布式数据集生成模块和目标数据输出模块;第三分布式数据集生成模块用于读取当天的整合数据,在分布式节点上生成对应的Spark RDD;目标数据输出模块用于读取第三分布式数据集生成模块生成的Spark RDD,根据数据应用系统对数据格式的要求,对当天整合后数据进行格式转换并输出,其数据输出格式支持结构化数据文件(可压缩)、关系型数据库、Hive等。
其中,元数据管理模块包括元数据定义模块、元数据检查模块和元数据导出模块;元数据定义模块用于使用Excel直接进行元数据定义和维护,简单易用,一目了然,其中元数据包括:数据源信息、源数据结构、目标数据格式、目标数据结构、数据转换规则和表达式;元数据检查模块用于根据一系列的元数据规范对元数据进行检查,并输出元数据检查报告;元数据导出模块用于将Excel中的元数据导出为元数据控制文件,元数据控制文件采用XML文件保存元数据,使元数据管理变得简单和通用。
本发明是建立在大数据平台和分布式内存并行计算技术的ETL产品,其采用分布式大数据平台Hadoop作为基础支撑和存储平台,采用Spark核心组件搭建数据加工框架,利用Spark先进的DAG执行引擎及性能强大的基于内存的多轮迭代计算技术,对源数据进行深度加工。
本发明采用Scala编程,Scala是运行在JVM之上的面向对象的静态函数式编程语言,具有速度快、简洁API、易于和Hadoop、YARN集成等特点,Spark内核是由Scala语言开发的,本发明与Spark完美结合,直达Spark内核,提高了编程效率和大数据处理性能,同时保证了系统的高容错性和高可伸缩性。
本发明以元数据定义和管理ETL的各种要素;采用Scala编程语言完美结合Spark;利用Spark分布式内存并行计算技术,将中间计算结果缓存在内存,减少磁盘I/O;采用多线程并发运行处理作业提高ETL的性能和资源利用率,故本发明较传统单机架构的ETL产品和Hadoop MapReduce,运行速度有数倍的提升。
本发明还公开一种基于Spark技术的ETL系统的方法,其包括如下步骤:(S01)抽取源数据,并根据数据分块规则在分布节点上动态生成多个Spark RDD,再通过线程池启动多个线程来调用数据处理模块对每个Spark RDD进行并行处理;(S02)读取数据抽取模块生成的Spark RDD,经过元数据匹配检查和一系列数据转换,得到处理后的数据,并保存在中转数据存储库中;(S03)对当天的中转数据和上一天的整合数据进行全量数据整合或历史数据整合,得到当天整合后数据,并保存在整合数据存储库中;(S04)根据数据应用系统对数据格式的要求,对当天整合后数据进行格式转换并输出;(S05)将系统各种要素进行参数化定义和管理。
其中,步骤(S01)包括如下步骤:(S11)通过离线抽取和在线抽取的方式直接读取压缩格式的数据文件,并传送至第一分布式数据集生成模块进行后续处理;(S12)读取源数据,并根据数据分块规则在分布节点上动态生成多个Spark RDD,待数据处理模块进一步处理。
其中,步骤(S02)包括如下步骤:(S21)通过元数据匹配对数据进行检查并生成数据检查报告;(S22)使用元数据定义的规则或表达式对数据进行清理和转换。
其中,步骤(S03)包括如下步骤:(S31)分别读取当天的中转数据和上一天的整合数据,在分布式节点上生成对应的Spark RDD;(S32)读取步骤(S31)中生成的Spark RDD,根据中转数据中的增、删、改标识,相应对上一天的整合数据Spark RDD中相同健值的数据进行增、删、改操作,处理完成后,形成中转数据Spark RDD存入到整合数据存储库中;(S33)读取步骤(S32)形成的当天的中转数据Spark RDD,根据中转数据中的增、删、改标识,对上一天的整合数据Spark RDD中相同健值的数据做相应处理,处理完成后,存入到整合数据存储库中。
其中,步骤(S04)包括如下步骤:(S41)读取当天的整合数据,在分布式节点上生成对应的Spark RDD;(S42)读取步骤(S41)生成的Spark RDD,对当天整合后数据进行格式转换并输出。
其中,步骤(S05)包括如下步骤:(S51)使用Excel直接进行元数据定义和维护,其中元数据包括:数据源信息、源数据结构、目标数据格式、目标数据结构、数据转换规则和表达式;(S52)根据一系列的元数据规范对元数据进行检查,并输出元数据检查报告;(S53)将Excel中的元数据导出为元数据控制文件。
本发明是建立在Hadoop基础数据平台和Spark分布式内存并行计算框架的一种ETL产品,其计算过程是基于内存的多轮迭代计算,运行速度较传统单机架构的ETL产品和Hadoop MapReduce快了数倍;随着集群的平滑扩展和内存加大,本发明的ETL性能可获得线性的提升;另外,本发明嵌入元数据管理组件,元数据一旦设置完成,系统自动流水线式运行数据抽取、数据处理、数据整合、数据输出等模块,无需人工干预;且本发明的源数据结构变更,只需修改相应的元数据,无需再编程,易于管理和维护。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!