一种优化模糊鉴别向量提取的电子鼻鉴别食醋品种方法与流程
本发明涉及一种食醋品种鉴别的方法,具体涉及一种采用电子鼻鉴别食醋品种的方法。
背景技术:
食醋是家庭生活中必不可少的调味品,市场上食醋的种类繁多,其风味因产地、配料、发酵方式不同而各异。风味是食醋分类的重要指标之一,也是消费者接受的主要因素之一。然而,市场上的食醋产品繁多,在生产过程中发酵温度、翻醅深度、发酵时间大多凭借工人师傅的经验来控制,所以容易造成食醋质量参次不齐,同一批次的食醋质量不一。长期以来对气味的客观测定多是用气相色谱法,但是气相色谱法对实验环境要求苛刻,不适合现场检测。
电子鼻技术能对食醋进行快速、准确的定性分析。成剑峰等(提高食醋电子鼻识别率方法的研究[j].中国酿造,2015,34(9):109-114)中,利用德国pen3型成品电子鼻对31个食醋样品进行分类,该电子鼻由10个不同的金属氧化物传感器w1c、w5s、w3c、w6s、w5c、w1s、w1w、w2s、w2w、w3s阵列组成,其成本太高,不适合大规模应用。张厚博等(张厚博,梅笑冬,赵万,等.用于食醋品质预评价的电子鼻研究[j].传感器与微系统,2013,32(3):62-64.)利用主成分分析(pca)和线性判别分析(lda)对电子鼻数据进行分析,直接对采集的数据进行分类,没有传感器数据优选过程,为后续的样本处理增加复杂度。
模糊非相关判别转换方法(武小红,武斌,周建江:《模糊非相关判别转换及其应用》,中国图象图形学报,2009,14(9):1832-1836.)建立在模糊类间离散矩阵、模糊类内散射矩阵的基础上,满足了样本到模糊非相关判别向量上的投影是非相关的要求,在处理带有模糊性的线性特征提取方面有优势。但是它在提取sar图像向量的非相关鉴别向量时并没有考虑最大程度的保留有用信息,使得在提取特征时会丢失部分有用信息,影响分类准确率。
技术实现要素:
针对目前进行食醋分类成本过高、模式识别算法选用不同会影响分类准确率的问题,本发明提出了一种优化模糊鉴别向量提取的电子鼻鉴别食醋品种方法,提高食醋品种分类的准确率。
本发明采用的技术方案是:利用电子鼻采集不同品种的食醋样本,获得训练样本和测试样本,还具有以下步骤:
(1)从电子鼻的传感器里随机选择其中的几个传感器,从训练样本中提取对应于这几个传感器所采集的数据作为新训练样本,计算出新训练样本类均值和新训练样本总均值;
(2)根据新训练样本类均值和新训练样本总均值计算出新训练样本的类间离散度矩阵和类内离散度矩阵以及计算出类间离散度矩阵的迹和类内离散度矩阵的迹:
(3)根据类间离散度矩阵的迹和类内离散度矩阵的迹计算出最优值,将最优值最大时所选择的传感器对应的新训练样本作为最优训练样本;
(4)提取最优训练样本的鉴别信息,获得最优鉴别向量集,对最优鉴别向量集进行线性转换,得到投影样本集,对投影样本集进行分类,完成食醋品种的鉴别。
本发明采用上述技术方案后具有的优点是:
1、本发明根据类间离散度矩阵的迹和类内离散度矩阵的迹的比值最大化原则来进行传感器数据(即醋的品种数据)优选,能使传感器数据更容易为后续分类方法所分类,分类准确率得到提高。
2、本发明对测试样本进行鉴别信息提取,再计算训练样本的模糊隶属度的值和类中心的值,从而得到最优鉴别向量特征集,接着利用线性映射将食醋测试样本投影到线性特征空间,最后用k近邻分类器实现在线性特征空间里的分类,能够象模糊主成分分析那样在不丢失主要信息的基础上降低数据的维数,同时还具备提取模糊鉴别向量使得电子鼻数据在模糊鉴别向量上的投影更容易分类,降低噪声的影响,有助于提高食醋品种分类准确率。
附图说明
图1为本发明一种优化模糊鉴别向量提取的电子鼻鉴别食醋品种方法的流程图。
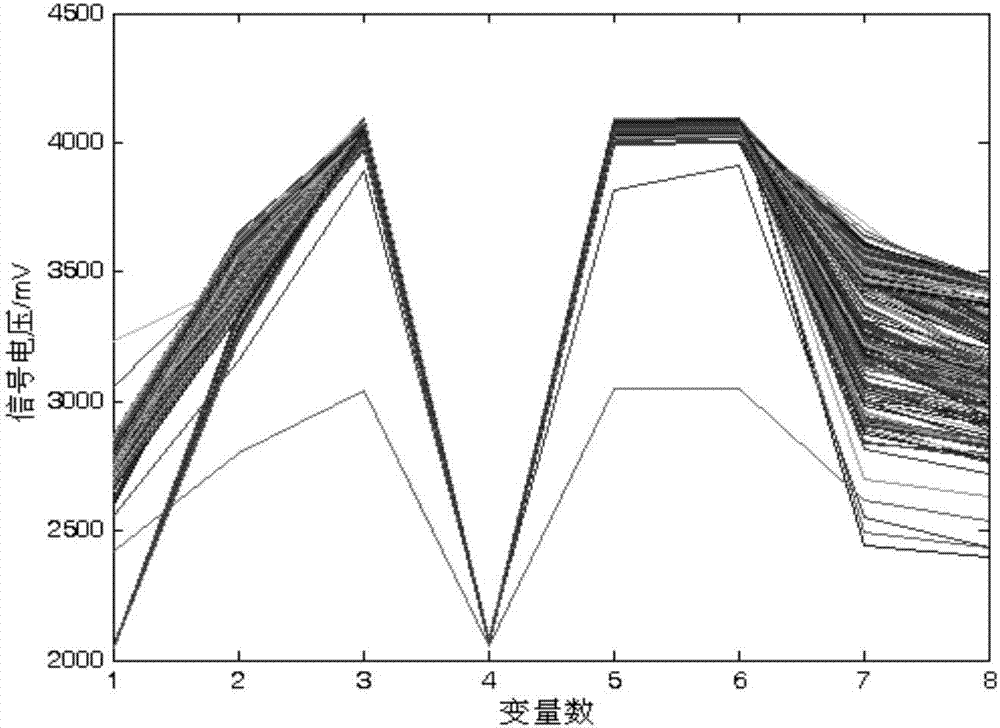
图2为实施例中最优训练样本数据图;
图3为实施例中最优训练样本经过snv处理后得到的数据图;
图4为实施例中最优训练样本的模糊隶属度图。
具体实施方式
如图1所示,利用电子鼻采集不同品种的食醋样本,电子鼻的传感器数量有a个:在室温20℃、湿度40%的环境下,将电子鼻通电,其传感器预热10分钟后,向烧杯中倒入10ml食醋并将其放入箱体中,迅速盖上箱盖;静置一段时间后,分别在60分钟、65分钟、70分钟的三个时间点进行数据采集,取三次采集结果的平均值作为一个食醋样本。完成一次食醋样本采集后,打开箱盖使得各传感器恢复初始状态,然后重复采集食醋样本过程,得到总样本。将总样本分为训练样本和测试样本,每个样本为1×10的向量,训练样本用来模式训练,测试样本用来检验模式识别正确率。
从电子鼻的a个传感器里随机选择其中的几个传感器且不作排序,针对所选择的这几个传感器,从训练样本中提取对应于这几个传感器所采集的数据作为新训练样本n,新训练样本n的类别数为c。采用常规的均值方法计算出第i类新训练样本类均值
根据新训练样本类均值
li为第i类的新训练样本数,xij代表第i类的第j个新训练样本,上标t代表矩阵转置运算。
然后根据类间离散度矩阵的迹trace(sb)和类内离散度矩阵的迹trace(sw)计算出最优值j:
当j达到最大的时候表示数据可分性最好,分类的准确度也最高。因此最优值j最大时所选择的传感器对应的新训练样本作为最优训练样本,将对应的新测试样本作为最优测试样本。
对最优训练样本数据进行预处理,提取特征值。具体如下:
先对最优训练样本进行标准归一化(snv)处理,然后通过进行主成分分析(pca)处理,计算得到主成分分析的前6个特征值。
分别计算最优训练样本的模糊隶属度的值uik和类中心的值vi:
式中,xk为第k个最优训练样本,
再计算模糊类间离散度矩阵sfb和模糊总体离散度矩阵sft:
式中,
根据下式求特征值λ和特征向量ψ:
其中,
计算得到最大特征值λ1和与之相对应的特征向量ψ1,将最大特征值对应的特征向量ψ1作为最优鉴别向量集的第一个向量。
计算最优鉴别向量集:
式中,
根据前r个最优鉴别向量ψ1,ψ2,...,ψr(r≥1)计算得到第(r+1)个最优鉴别向量ψr+1。经过以上计算,可以获得p个最优鉴别向量组成最优鉴别向量集{ψ1,ψ2,...,ψp}。
根据式y=[ψ1,ψ2,...,ψp]tx进行食醋测试样本的线性转换,其中,[ψ1,ψ2,...,ψp]t表示最优鉴别向量集的转置矩阵,x为测试样本集,y为测试样本集投影到最优鉴别向量集上得到的投影样本集。完成了测试样本从实数空间
以下提供本发明的一个实施例:
实施例
步骤一、利用电子鼻采集不同品种食醋样本:
将电子鼻通电,对5类食醋各进行51次采集,共采集255次,得到255个样本,将实验采集数据结果保存。总样本为255×10的数据矩阵,将总样本分为训练样本和测试样本:将每类食醋的51个样本中前25个作为训练样本,后26个作为测试样本。训练样本数为125个,每个样本为1×10的向量,得到125×10的数据矩阵;测试样本为130个,每个样本为1×10的向量,得到130×10的数据矩阵。
步骤二、对食醋样本数据进行优选:
1、从a个传感器里随机选择b个且不作排序,共有
2、将所取的8个传感器,从步骤一的训练样本(125×10矩阵)中提取对应数据作为新训练样本(125×8矩阵),计算新训练样本类均值
3、按照下式计算新训练样本的类间离散度矩阵sb和类内离散度矩阵sw、类间离散度矩阵的迹trace(sb)和类内离散度矩阵的迹trace(sw):
式中,
4、按如下规律计算最优值j:
根据45种不同的组合情况计算得到45个最优值j,当j达到最大的时候表示数据可分性最好,分类的准确度也最高。
新训练样本的部分最优值j如下表1所示:
表1新训练样本的部分最优值
所得j的最大值为4231.5,根据此时的j值推算出选取八个传感器编号分别为1,2,4,6,7,8,9,10,并将编号记录在编号索引中;对应传感器型号分别为tgs2610、tgs2620、tgs2600、mq135、mq3、tgs2602、tgs813、tgs2611,同时表明这8个传感器型号对应的新训练样本数据可分性最好,并将此新训练样本作为最优训练样本(125×8矩阵),数据显示如图2所示。将这8个传感器型号对应的新测试样本作为最优测试样本。
步骤三、提取最优训练样本的鉴别信息:
1、对最优训练样本数据进行预处理,提取特征值:
先对步骤二所得的最优训练样本(125×8矩阵)进行标准归一化(snv)处理,结果为如图3所示的125×8归一化矩阵。然后通过进行pca处理,计算得到pca前6个特征值:31.02,22.55,2.86,0.25,0.19,0.01;pca前6个特征向量为125×6的数据矩阵,如下表2所示。
表2pca前6个特征向量
2、使用优化模糊鉴别向量提取方法提取最优训练样本的鉴别信息:
对表2中得到的结果(125×6的数据矩阵)进行特征提取,具体步骤如下:
(1)分别计算模糊隶属度的值uik和类中心的值vi:
式中,xk为第k个样本,
选取c=5、n=125、m=2,经过计算可得到5个类中心值,每个类中心值均为一个6维的向量。最优训练样本的模糊隶属度如图4所示。
(2)计算模糊类间离散度矩阵和模糊总体离散度矩阵:
式中,
(3)根据下式求最大特征值和特征向量:
其中,
(4)计算最优鉴别向量集:
式中,
根据前r个最优鉴别向量ψ1,ψ2,...,ψr(r≥1)计算得到第(r+1)个最优鉴别向量ψr+1。经过计算,可以获得p(p=4)个最优鉴别向量组成最优鉴别向量集{ψ1,ψ2,...,ψp}。
步骤四、对最优鉴别向量集{ψ1,ψ2,...,ψp}进行线性转换:
y=[ψ1,ψ2,...,ψp]tx,[ψ1,ψ2,...,ψp]t表示最优鉴别向量集的转置矩阵,x为测试样本集,y为测试样本投影到最优鉴别向量集上得到的投影样本集。完成测试样本从实数空间
步骤五、将步骤四所得到的投影样本集y数据利用k近邻分类器进行分类,设置参数k的值为3,分类准确率可达90%。
- 还没有人留言评论。精彩留言会获得点赞!