一种面向复杂网络的时序链路预测方法与流程
本发明涉及一种面向复杂网络的时序链路预测方法,属于复杂网络中时序链路预测技术领域。
背景技术:
目前主流的链路预测算法是基于网络的上一时刻的网络拓扑结构,然后根据一些节点相似指标,例如共同邻居指标、资源分配指标等等,计算得到节点之间的相似度,然后根据相似度阈值确定下一时刻链路的出现情况。不同于现有的主流预测算法,利用网络过去一段时间内的网络演化信息来预测未来的网络拓扑结构是一个较新的研究方向,这类预测方法更加符合现实中的网络具有动态特性的真实情况,往往具有较优的链路预测精度。此外,目前的链路预测算法主要基于矩阵计算的方式实现相似度计算,该方法在单机情况下计算简便,但是不适用于分布式环境。基于整体同步并行计算(bsp)模型设计算法的计算架构可使得算法运行于主流的分布式数据处理平台,从而提高算法的扩展性。
链路预测算法的性能指标包括准确率、auc等等。其中,准确率是算法的预测精度的直观展现,auc是对算法预测效果的整体考量。一些仅基于上一时刻网络拓扑结构的链路预测算法在网络平稳演化的时候能够具有良好的预测精度,不过现实中的网络往往会因为一些原因产生大幅波动,将导致预测精度大幅下降。还有一些链路预测算法利用网络中的文本语义信息来改进链路预测精度,但是由于不同的网络中文本语义差别比较大,而且文本信息存在难获取、难以保证正确性等问题,所以利用文本语义的链路预测算法不具有普适性且不能保证一定改进链路预测效果。此外大多数的链路预测算法仅仅考虑“有没有关系”而忽略了节点之间的链路往往是有紧密和疏远之分,忽略这一层信息也会使得链路预测的精度下降。
可见,网络的动态性和承载的信息的复杂性是链路预测技术面临的重大挑战,特别是现今社交网络的快速发展,各类社会网络承载的信息出现爆炸性增长,且网络的演化速度加快,对于一种适应于这类应用场景且具有良好扩展性的链路预测算法的需求十分迫切。
技术实现要素:
本发明所要解决的技术问题是:提供一种面向复杂网络的时序链路预测方法,该方法能够利用大规模的、具有动态特性的复杂网络中的动态演化信息进行时序链路预测,并具有良好的扩展性。
本发明为解决上述技术问题采用以下技术方案:
一种面向复杂网络的时序链路预测方法,包括如下步骤:
步骤1,对网络中所有出现过的节点进行编号,并将编号作为节点自身的id,每个节点的编号唯一;
步骤2,获取预测时刻过去一段时间内,网络中所有节点之间的交互行为以及每次交互行为发生的时间;
步骤3,将步骤2所述过去一段时间划分为多个时间片,并将每个交互行为划分到对应的时间片中,每个交互行为生成一个链路,链路的端点分别为交互的两个节点,且链路为无向边;
步骤4,统计每个时间片内相同链路的出现次数,作为该链路的权重,利用每个时间片内所有带权重的链路形成一个对应于该时间片的带权网络,最终得到带权网络序列;
步骤5,对带权网络序列进行压缩,压缩过程为:从带权网络序列中取出所有相同链路以及链路的权重信息,根据设定的时序影响系数δ计算压缩后链路的时序权重,计算公式为:
其中,wx,y表示链路(x,y)压缩后的权重,ci,i=1,2,…,t表示第i个时间片中链路(x,y)的权重;得到带有时序权重的链路的集合,并将时序权重小于0的链路过滤掉,进入步骤6;
步骤6,将带有时序权重的链路的集合构造成带权时序网络,初始化带权时序网络中的每个节点,在每个节点上生成一个“标签”,标签为一个键值对,该键值对以当前所在节点的id为键,以1为值;
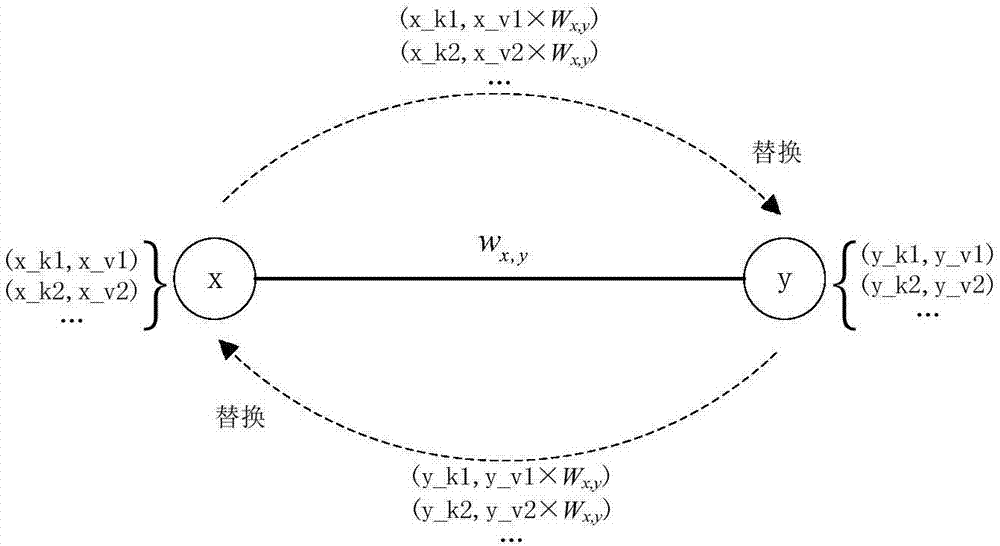
步骤7,每个节点将自身的初始化标签传播给其邻居节点,传播过程中利用标签经过的连边的权重与标签中值的乘积对标签中的值进行更新,传播完成后,每个节点将接收到的所有标签放到一个集合中,用该集合替换原来的初始化标签并保存;
步骤8,每个节点将经步骤7传播后接收到的标签集合再次向邻居节点传播,传播过程中利用经过的连边的权重与标签中值的乘积的α次方对标签中的值进行更新,α为修正系数,传播完成后,每个节点将接收到的所有标签放到一个集合中,并将该集合合并到步骤7保存的集合中;
步骤9,对每个节点中的标签按“键”聚合“值”,聚合后的值就是其所在节点和其对应的键代表的节点的链路评分;
步骤10,对所有的链路评分进行排序,将排名前m的链路作为预测链路,m为设定值。
作为本发明的一种优选方案,步骤5所述链路的权重,对于不存在链路(x,y)的时间片,将链路(x,y)在该时间片的权重设为0。
作为本发明的一种优选方案,步骤5所述时序影响系数δ的权值为0~1。
作为本发明的一种优选方案,步骤8所述修正系数α的权值为0~1。
作为本发明的一种优选方案,步骤9所述按“键”聚合“值”的方法为:将相同键对应的值相加求和。
作为本发明的一种优选方案,所述步骤7和8的分布式实现方式为:采用标签传播算法,结合整体同步并行计算模型,将每次标签传播过程拆分为针对每个链路的分别计算,链路的端点分别为传播源点、传播目标点,每个链路的传播过程如下:
步骤a,初始化一个空的集合dstarr;
步骤b,若传播源点中只有一个标签且标签的键为传播源点的id,则转步骤c,否则转步骤d;
步骤c,将以传播源点的id为“键”,源点中标签的值和链路连边权重的乘积为“值”的新标签添加到dstarr中,转步骤f;
步骤d,遍历传播源点中的标签,如果该标签的“键”不等于传播目标点的id,则创建一个以该标签的键为“键”,以该标签的值和链路连边权重乘积的α次方为“值”的新标签,并将该新标签添加到dstarr中;如果该标签的“键”等于传播目标点的id,则向dstarr添加一个空值,遍历结束后转步骤e;
步骤e,过滤掉dstarr中的空值,转步骤f;
步骤f,将dstarr发送给传播目标点。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
1、本发明不需要收集节点的文本属性信息,对于社交网络不涉及网络中的用户隐私,只需要得到网络的一段时间内的拓扑演化过程即可进行链路预测,该预测方案具有很好的普适性。
2、本发明在预测过程中,充分利用网络的拓扑演化过程信息,在一定程度上改进了链路预测的精度。
3、本发明采用改进的标签传播(labelpropagation)算法,将标签扩充为键值对形式,充分考虑一跳邻居和二跳邻居的相似度贡献,可以实现更全面的链路预测。
4、本发明采用整体同步并行计算模型对标签传播过程进行设计,使得算法具有良好的可扩展性,可以运行在主流的分布式数据处理平台之上,可以适用于大型复杂网络的处理。
附图说明
图1是本发明面向复杂网络的时序链路预测方法预测过程的示意图。
图2是本发明面向复杂网络的时序链路预测方法中第一轮标签传播的示意图。
图3是本发明面向复杂网络的时序链路预测方法中第二轮标签传播的示意图。
具体实施方式
下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
本发明所设计一种面向复杂网络的时序链路预测方法,在实际应用过程中,通过网络的历史演化信息,实现对未来时刻链路情况的预测。如图1所示,预测方法具体包括如下步骤:
步骤001.对社会网络中所有出现过的节点进行编号,每个节点的编号唯一,并作为自身的id;
步骤002.获取社会网络中节点的过去tδ(tδ可以人为设定)时间段内,节点之间的交互行为,以及每次交互行为发生的时间,然后进入步骤003;
步骤003.将交互行为按时间进行分片,即将每个交互行为划分到一个时间片中,每个交互行为生成一个链路,链路的端点分别为交互的两个节点,链路的特性为无向边。然后进入步骤004;
步骤004.统计每个时间片内的相同链路的出现次数,作为该链路的权重,利用每个时间片内的所有带有权重的链路形成一张对应于该时间片的带权网络,最终得到一个带权网络序列。然后进入步骤005;
步骤005.压缩上一步骤得到的网络序列,压缩过程针对每条链路分别进行,以节点x和节点y之间的链路的压缩过程为例:首先从网络序列中取出所有相同链路以及链路的权重信息{c1,c2,…,ct},ct表示第t个时间片中链路(x,y)的权重,再根据事先设定的衰减系数δ计算压缩后的时序权重,计算如下式所示:
不一定在每个时间片中都存在链路(x,y),如果某个时间片中链路(x,y)不存在,处理方式为:其权重设为0。压缩之后得到一个带有时序权重的链路的集合,过滤掉其中时序权重小于0的链路,然后进入步骤006;
步骤006.将时序链路集合构造成一幅时序信息网络,初始化每个节点,在每个节点上生成一个“标签”,标签为一个键值对,该键值对以当前所在节点的id为键,以数字1为值。然后进入步骤007;
步骤007.每个节点将自身的初始化标签传播给其邻居节点,传播过程中利用标签经过的连边的权重w对标签中的值v进行更新,修正方式如下式所示:
v=v×w
传播完成后,每个节点将接收到的所有标签放到一个集合中,并用该集合替换原来的初始化标签,如图2所示。第一轮传播结束后,进入步骤008;
步骤008.每个节点将第一轮传播后接收到的标签集合再次向邻居节点传播,传播过程中,利用经过的连边的权重w对标签中的值v进行更新,更新方式为:
v=(v×w)α
α为修正系数,取值为0~1,其具体取值可视网络的特性在取值范围内动态调整。传播结束后,每个节点将接受到的所有标签放到一个集合中,并将该集合合并到第一轮传播后保存的标签集合,如图3所示,进入步骤009;
其中对于步骤007和步骤008表述的标签传播过程,为了使算法适用于分布式环境,采用整体同步并行计算(bsp)模型设计计算过程。将每次网络的标签传播过程拆分为针对每个三元组(包括源点id和属性、边属性、目标点id和属性)的分别计算,实现适用于分布式环境的链路预测方法。对于每个三元组的计算过程,从源点传播标签到目标点有如下步骤:
步骤a01.初始化一个空的集合dstarr;
步骤a02.如果源点中只有一个标签且标签的键为源点的id则转步骤a03,否则转步骤a04;
步骤a03.以源点的id作为“键”,源点中的标签的值和连边权重的乘积作为“值”的新标签添加到dstarr中,转到步骤a06;
步骤a04.遍历源点中的标签,如果该标签的“键”不等于目标点的id,则创建一个以该标签的键为“键”,以修正后的值为“值”的新标签,并将该新标签添加到dstarr中如果该标签的“键”等于目标点的id则向dstarr添加一个空值。遍历结束后转到步骤a05;
步骤a05.过滤掉dstarr中的空值,转到步骤a06;
步骤a06.将dstarr发送给目标点。
从目标点传播标签到源点的步骤和上述步骤一致。
对于每个三元组的计算过程,每个节点接收到标签之后还需要对标签进行整理,步骤如下:
步骤b01.如果节点中只有一个标签且标签的“键”等于所在节点的id,则用接收到的标签集合替换原有标签,转b03。否则转步骤b02;
步骤b02.将接收到的标签集合合并到原有的标签集合,转步骤b03;
步骤b03.更新节点的属性信息。
步骤009.对每个节点中的标签按“键”聚合“值”,聚合方法为:将相同键对应的值加在一起。聚合结束后的值就是其所在节点和其对应的键代表的节点的链路评分,评分越高则两个节点之间出现连边的可能性就越大。下面进入步骤010;
步骤010.对所有节点中的链路评分进行排序,取出排名前m的链路作为预测链路。m的具体值一般视复杂网络的规模和预测需求而定。
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!