基于遗传算法的一种新型一维排演下料方法与流程
本发明涉及计算机算法应用设计领域,尤其涉及基于遗传算法的一种新型一维排演下料算法设计。
背景技术:
一维排样下料问题是把棒状原料切割成若干长度子零件,在满足实际生产需求的前提下,尽可能提高生产利用率的np难问题。一维下料的问题广泛的存在于机械、制造、建筑、电力等诸多的实际工程中而受到各行各业的专家、学者的重视。近几年,随着国家大力倡导节能减排,优化资源配置、提高利用合理化、管理的科学化和综合化,目的是寻求最优化生产技术方案来获取最大的效益,以期在经济效益和生态效益寻得一合理的平衡点,以促进国民经济稳步健康发展。因此,寻求一种最优化的设计加工方案无疑能节约生产成本,提高企业市场竞争力,同时能降低能耗,减少对环境的伤害。
一维问题作为组合问题中的经典问题,从其计算规模的复杂度上看,其属于np完全问题,并且其具体求解受限于实际工程条件,因而对该问题的精确求解依赖于其实际的计算规模和工程约束条件。对于工程实际,一维排样下料问题,本身具有一定的限制条件,诸如原料种类、原料数量、产品种类、对应产品种类数量、具体生产订单要求等许多约束条件,对具体问题建立数学模型,寻找可行域内存在的最优解集,可想而知,该问题的解集十分庞大,并且基本不存在适用于任何情况的算法,对算法的设计提出了很大的要求。目前国内外对该问题的研究,都得到一个几乎相同的结论。对于小规模计算模型的一维排样下料,可通过一定的方法,在有限制可行域空间内寻得其全局最优解;但是对于大规模、超大规模的计算模型,当前尚缺乏一种行之有效的方法求得其全局最优解,仅能通过遗传算法、启发式算法等尽可能的寻得其全局近似最优解。遗传算法作为组合问题求解的常用的方法,在一定程度上能解决相当一部分的一维下料问题,但是由于遗传算法存在参数配置难、一旦参数配置偏差会陷入局部最优而无法寻得全局最优的情况,计算时间冗长等缺点;对于启发式算法的优点是计算速度快,缺点是其计算效果难以保证。
为克服现有技术的不足,本发明提出基于遗传算法提出的一种新型一维排演下料算法设计,适用于许多需要大量消耗棒料的实际工程。寻找一种最优化的设计加工方案无疑能节约最大的成本开销,更能为相关企业带来直接的经济效应,降低企业排放指标。
技术实现要素:
(一)要解决的技术问题
为了克服现有方法的不足,本发明公开了基于遗传算法提出的一种新型一维排演下料算法设计。
(二)技术方案
为解决上述问题,本发明提供了基于遗传算法提出的一种新型一维排演下料算法设计,包括步骤:
s1.把输入的产品根据不同长度,按照降序的方法排序,最小编码为1,依次推之,最后一个编号为最小零件。
s2.依据产品的长度和数量,搭建编码序列,例如:(1112222233.........)如此的编码序列,意思即是,1号产品有2件、2号产品需要5件,3号产品需要2件等...根据编码序列很容易换算得到对应的产品信息。例如product_length[1]即可取得产品1号的长度等信息(编码序列与产品信息搭建换算关系)通过基因编码原理,成功把多重嵌套循环转化成单次循环。
s3.三档优化阈值(1档、2档、3档),阈值逐渐递减,通过单循环,从基因编码中取出编码,加入到累积变量之中,判断(累积变量/输入原材料长度)与设定阈值关系,达标break;作为一次成功扫描。
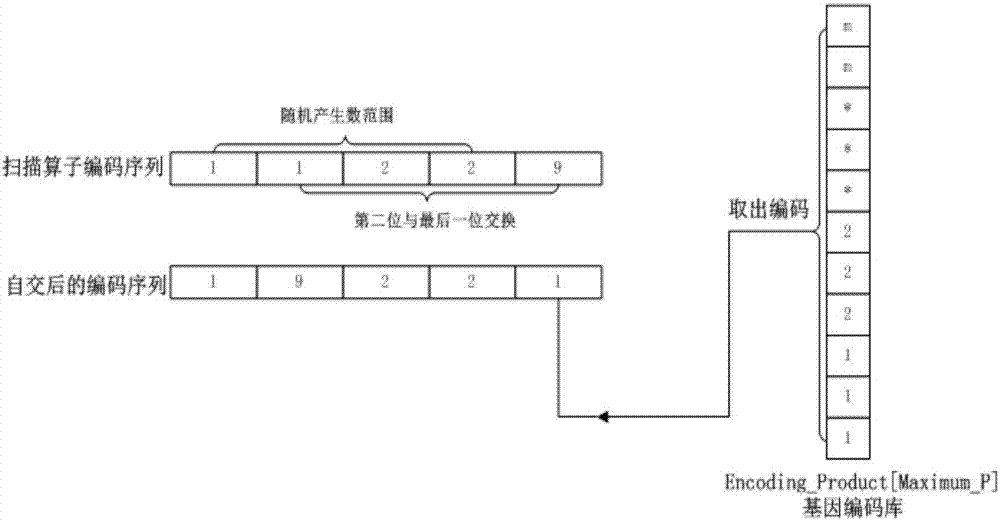
s4.扫描算子失败后(无法达到最小阈值目标),启动变异算子。由于扫描算子,采用顺序累加计算利用率与阈值的关系作为循环终止条件,存在一定局限性。而变异算子,只是需要补充这点局限性,增加基因型的可能类型。例如:结果扫描算子运算得出的编基因型:11112,利用率可以达到93%(低于最小扫描目标,触发变异算子)。
第一步:自交换。随机选择前面的(n-1)个数,与最后面的第n个数交换。例如交换3和5,得到新的基因型11211
第二步:(利用总长)减(交换后前面n-1个数的长度和)等于新的余料长度.。
第三布:新的余长从剩余的编码库中取值带入,根据利用率作为终止判断条件。若变异后的基因型(对应的利用率优于变异前的,称为成功变异)将其基因型替换原来的基因型,给予保留。若变异失败,则保留变异前的。
s5.用继承算子继承先前父代的优秀基因编码作为新的子代基因编码,如此可以大大加快算法的运算速度。父代的优秀基因编码可能在部分基因在产品序列编码中不存在,则称为继承失败。父代的优秀基因编码在产品序列编码中能找得到,则即可组合成优良品种。
优选地,本发明所述的基于遗传算法提出的一种新型一维排演下料算法设计,其中步骤s1具体为:把待处理的子零件按照(长度较长的子零件排列在前)的原则进行排序,把排序完成后的新子零件序列的长度信息和数量信息分别存入product_length[]和product_length_number[]相应数组;把待切的原材料序列根据用户意愿,按照优先处理级别高的原材料排列在前的原则,把排列后的新子序列存入长度raw_material_length[]和数量raw_material_number[]。
优选地,本发明所述的基于遗传算法提出的一种新型一维排演下料算法设计,其中步骤s2具体为:构建遗传编码序列(如图1所示)。根据前文设定原料长度为l1,l2,l3,…,ln-1,ln;其相应数量为:n1,n2,n3,…,nn-1,nn;我们用数字1,2.....n代表对应原材料的编码,根据数组里面出现1的次数来代表1号原材料相应在库存中的数量,从而我们可以搭建起如下的原材料编码序列,
encoding_raw_materials[maximum_rm]={1,1,1,,2,2,2,...,n,n,n};(1)
优选地,本发明所述的基于遗传算法提出的一种新型一维排演下料算法设计,其中步骤s3具体为:算法求解问题由双层循环构成,外层循环从encoding_raw_materials[]每次取出一根待处理原材料送入迭代器,内层循环依次从encoding_product[]从取出一根子零件长度送入迭代器中的累加器,累加器每叠加一根子零件长度后,即产生判断,若新加入的子零件让累加器溢出(超出送入迭代器的原材料长度),即把最后一次叠加的子零件剔除,若新加入的子零件未让累加器溢出,则保留本次加入结果。每次计入新的子零件进入累加器,通过计算累加器与输入原材料长度的比值(单根利用率)是否达到所设定的阈值,若达到设定第一阈值目标,则本次作为一次成功试验,保留加入叠加器的子零件编码。并且把子零件编码从encoding_product[]剔除,而所输入迭代器的原材料也需要从encoding_raw_materials[]剔除。
倘若未能达到第一阈值目标,可尝试修改迭代器的循环变量步长,进行调整,若调整后的利用率能达到第二阈值或者第三阈值目标,都视为合格试验,重复上述刷新编码序列的工作。如果调整迭代器中循环变量的步长后仍然无法满足条件,可以尝试变异算子进行优化。
优选地,本发明所述的基于遗传算法提出的一种新型一维排演下料算法设计,其中步骤s4具体为:变异算子分为以下三个步骤:(1)自交换。随机选择基因编码的前面的(n-1)个数,与最后面的第n个数交换。(2)计算新产生的基因编码前面的(n-1)个数所计算得到的总长,从而可求得新的余料长度。(3)把新的余料长度代入扫描算子的迭代器中进行运算。若变异后的基因编码组合优于变异之前,称为有利变异,则替代原先的基因型,若变异效果未能优于先前基因编码,则不予处理,重复变异算子,直到寻得合适基因型。如若10次变异都无法寻得合适的基因编码,则视为失败变异。
优选地,本发明所述的基于遗传算法提出的一种新型一维排演下料算法设计,其中步骤s5具体为:继承先前父代的优秀基因编码作为新的子代基因编码,如此可以大大加快算法的运算速度。父代的优秀基因编码可能在部分基因在产品序列编码中不存在,则称为继承失败。父代的优秀基因编码在产品序列编码中能找得到,则即可组合成优良品种。
(三)本发明具有如下有益效果:
算法思想,同时考虑的计算时间和模型计算的复杂程度,能在多约束条件下(包括约束条件不确定的情况下)求解一维下料问题,通过采用扫描算子三挡优化阈值、变异算子以及继承算子的方式,以单根原料的利用率最大化作为设定目标,进行寻求近似最优解,使得在实际生产过程中最大限度的利用了原材料,节约了资源,降低了企业生产成本又保障了实际生产的利用率。
附图说明
图1为本发明的构建遗传编码序列拓扑图。
图2为本发明的变异算子原理图。
图3为本发明的一个系统程序框图。
具体实施方式
下面将结合说明书附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明的技术方案。
本发明的基于遗传算法提出的一种新型一维排演下料算法设计,把输入的产品根据不同长度,按照降序的方法排序,依据产品的长度和数量,搭建编码序列,利用扫描算子的三档优化阈值(1档、2档、3档),阈值逐渐递减,是否达到所设定的阈值,若无法达到最小阈值目标,启动变异算子,若变异后的基因编码组合优于变异之前,称为有利变异,则替代原先的基因型,反之,不处理,最后利用继承算子继承上一代中,基因型较为好的品种,从而实现材料利用率最大化的目标,具体包括以下步骤:
s1.排序”把待处理的子零件按照(长度较长的子零件排列在前)的原则进行排序,把排序完成后的新子零件序列的长度信息和数量信息分别存入product_length[]和product_length_number[]相应数组;把待切的原材料序列根据用户意愿,按照优先处理级别高的原材料排列在前的原则,把排列后的新子序列存入长度raw_material_length[]和数量raw_material_number[]。
s2.依据产品的长度和数量,构建遗传编码序列(如图1所示)。根据前文设定原料长度为l1,l2,l3,…,ln-1,ln;其相应数量为:n1,n2,n3,…,nn-1,nn;我们用数字1,2.....n代表对应原材料的编码,根据数组里面出现1的次数来代表1号原材料相应在库存中的数量,从而我们可以搭建起如下的原材料编码序列,
encoding_raw_materials[maximum_rm]={1,1,1,,2,2,2,...,n,n,n};(1)
例如:(1112222233.........)如此的编码序列,意思即是,1号产品有2件、2号产品需要5件,3号产品需要2件等...根据编码序列很容易换算得到对应的产品信息。例如product_length[1]即可取得产品1号的长度等信息(编码序列与产品信息搭建换算关系)通过基因编码原理,成功把多重嵌套循环转化成单次循环。
s3.算法求解问题由双层循环构成,外层循环从encoding_raw_materials[]每次取出一根待处理原材料送入迭代器,内层循环依次从encoding_product[]从取出一根子零件长度送入迭代器中的累加器,累加器每叠加一根子零件长度后,即产生判断,若新加入的子零件让累加器溢出(超出送入迭代器的原材料长度),即把最后一次叠加的子零件剔除,若新加入的子零件未让累加器溢出,则保留本次加入结果。每次计入新的子零件进入累加器,通过计算累加器与输入原材料长度的比值(单根利用率)是否达到所设定的阈值,若达到设定第一阈值目标,则本次作为一次成功试验,保留加入叠加器的子零件编码。并且把子零件编码从encoding_product[]剔除,而所输入迭代器的原材料也需要从encoding_raw_materials[]剔除。
s4.扫描算子失败后(无法达到最小阈值目标),启动变异算子(如图2所示)。由于扫描算子,采用顺序累加计算利用率与阈值的关系作为循环终止条件,存在一定局限性。而变异算子,只是需要补充这点局限性,增加基因型的可能类型。例如:结果扫描算子运算得出的编基因型:11112,利用率可以达到93%(低于最小扫描目标,触发变异算子)。
第一步:自交换。随机选择前面的(n-1)个数,与最后面的第n个数交换。例如交换3与5,得到新的基因型11211
第二步:(利用总长)减(交换后前面n-1个数的长度和)等于新的余料长度.。
第三布:新的余长从剩余的编码库中取值带入,根据利用率作为终止判断条件。若变异后的基因型(对应的利用率优于变异前的,称为成功变异)将其基因型替换原来的基因型,给予保留。若变异失败,则保留变异前的。
s5.用继承算子继承先前父代的优秀基因编码作为新的子代基因编码,如此可以大大加快算法的运算速度。父代的优秀基因编码可能在部分基因在产品序列编码中不存在,则称为继承失败。父代的优秀基因编码在产品序列编码中能找得到,则即可组合成优良品种。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!