一种基于手机信令数据的用户出行驻留行为识别方法与流程
本发明涉及多大数据技术领域,尤其是一种基于手机信令数据的用户出行驻留行为识别方法。
背景技术:
了解城市居民的出行状况是城市规划师、交通规划师在对城市布局、路网规划时的重要考虑环节,其中包括市民出行的驻留点及驻留点所对应的到达时间和驻留时长。而传统的获取市民出行状况的方法主要是通过发放调查问卷的人工方法。传统方法的主要不足在于调查成本高、所获取的样本量小、准确率受人为因素干扰大、信息更新频率低,这使得规划师无法准确、及时地了解城市居民的出行需求。
随着信息化和大数据技术的普及,通过手机信令数据获取城市居民的出行状况等技术手段开始出现。手机信令数据相较传统的人工调查数据而言,具有获取成本低、样本全、能及时反映市民出行需求变化等优点。然而,现有的通过手机信令数据提取用户出行状况的方法存在以下不足:(1)由于手机通信基站在地理空间中的非均匀分布特性,现有方法需要通过人为反复调节、观察实验的方式去设定空间阈值从而识别出用户的驻留点;(2)考虑到手机通信基站在市区和郊区的分布密度不同,设定统一空间阈值导致郊区出行和市区出行的驻留点识别准确率存在折中现象。以上不足使得现有方法难以被规划师等使用者直接使用,给使用者通过手机信令数据分析市民出行状况增加了学习难度和不必要的工作量,且使得市区与郊区出行的驻留点识别准确率无法兼顾。
技术实现要素:
本发明所要解决的技术问题在于,提供一种基于手机信令数据的用户出行驻留行为识别方法,能够在大规模计算集群上实现分布式部署,高效处理海量手机信令数据。
为解决上述技术问题,本发明提供一种基于手机信令数据的用户出行驻留行为识别方法,包括如下步骤:
(1)对手机信令数据进行清洗、转换及分割;
(2)利用无监督分类方法,设置多个聚类数目,对信令数据单元中的空间点进行聚类,并通过聚类评分指标评价每一个聚类结果,评分高者为最佳聚类;
(3)根据最佳聚类得出信令数据单元中所有候选驻留点及相关时间的信息集合;
(4)根据时间阈值及各候选驻留点的信息集合,对候选驻留点驻留时长进行计算和筛选,输出每用户每天各驻留点空间位置、到达时间及驻留时长。
优选的,步骤(1)中,清洗的步骤具体为:获取城市某一段时期内的手机信令数据后,去除其中时空间信息残缺的记录条目;转换的步骤具体为:得到清洗好的信令数据后,将信令记录中的基站编号替换成相应的基站空间坐标,若基站空间坐标为经纬度坐标,则还需将经纬度坐标转换成投影坐标;分割的步骤具体为:得到清洗、转换好的信令数据后,将信令数据先按天做划分,再将数据按用户做划分,从而得到每天当中各用户的所有信令记录条目,以一天当中一个用户的所有信令数据作为一个信令数据单元,记为DataUnit,对每个单元按照接下来的步骤进行计算。
优选的,步骤(2)中,利用无监督聚类方法,设置聚类数目依次为2,3,4,……,30,对DataUnit中的空间点进行聚类,并通过聚类评分指标评价每一个聚类结果,评分高者为最佳聚类;对于一个DataUnit,将DataUnit中每条信令记录中基站空间坐标作为一个空间点,利用k-means无监督聚类方法对该信令数据单元中的所有空间点进行聚类,若有坐标相同的空间点均算作不同点;聚类过程中,依次设置k=2,3,…,30,对于每一个k值,使用Dunn指标对聚类结果进行评分,评分最高的k值,则为最佳k值,其所对应的聚类结果为最佳聚类结果。
优选的,步骤(3)具体包括如下步骤:
(31)生成候选驻留点的信息集合InfoSet:通过步骤(2)获取该DataUnit中空间点的最佳聚类结果后,将DataUnit中的记录条目按照时间先后顺序进行排列,并将每条记录条目的空间点所在的类作为该记录条目的类;将时间顺序上相邻且同类的记录条目合并为一个集合,作为一个候选驻留点的信息集合InfoSet,即:
其中,Li表示第i个信息点的空间位置,ti表示第i个信息点的记录时间,|InfoSet|表示驻留点信息集合中信息点的个数;
(32)计算候选驻留点相关参数:对于一个候选驻留点的信息集合InfoSet,计算该集合中空间点的平均位置,将其作为该候选驻留点的空间位置,即:
将集合中记录条目最早的时间作为该候选驻留点的到达时间tarr,将集合中记录条目最晚的时间作为该候选驻留点的离开时间tdep,用该候选驻留点的离开时间减去到达时间作为该候选驻留点的驻留时长tdur,即:
tarr=t1
tdep=t|InfoSet|
tdur=tdep-tarr。
优选的,步骤(4)具体包括如下步骤:
(41)根据时间阈值筛选候选驻留点:对于通过阶段3所得的一个DataUnit中的所有候选驻留点,将驻留时长小于15分钟的候选驻留点去掉,剩下的候选驻留点则为该DataUnit输出的驻留点;
(42)输出识别结果:将该DataUnit的所有驻留点的空间位置及其对应的到达时间和驻留时长结合起来,即(LInfoSet,tarr,tdur),并按到达时间先后顺序排列,即为对应用户在对应某天中的出行驻留行为的最终识别结果,即:
其中,|Result(user,day)|表示对应用户在对应某天中所识别出的实际出行驻留点个数。
本发明的有益效果为:使用简单方便,无需使用人员反复调节参数,获取手机信令数据后,可得到每天当中每一个用户出行驻留行为,无需规划师通过反复调节观察实验来确定空间阈值,避免了人为主观判断带来的干扰;可以适应基站分布不均匀的特性,通过用户信令轨迹的自身特性进行空间聚类,避免了市区与郊区基站分布不均匀的特性带来的识别准确率的折中现象;具有良好的可扩展性,能够在大规模计算集群上实现分布式部署,高效处理海量手机信令数据。
附图说明
图1为本发明的方法流程示意图。
图2为本发明的原理示意图。
图3为本发明的实例示意图。
具体实施方式
如图1所示,一种基于手机信令数据的用户出行驻留行为识别方法,包括如下步骤:
(1)对手机信令数据进行清洗、转换及分割。
清洗:获取城市某一段时期内的手机信令数据后,去除其中时空间信息残缺的记录条目。
转换:得到清洗好的信令数据后,将信令记录中的基站编号替换成相应的基站空间坐标。若基站空间坐标为经纬度坐标,则还需将经纬度坐标转换成投影坐标。本专利不对投影坐标系有任何依赖性,可以选择国际通用的投影方法,如:Mercator投影、Gauss-Kruger投影、Lambert投影等。
分割:得到清洗、转换好的信令数据后,将信令数据先按天做划分,再将数据按用户做划分,从而得到每天当中各用户的所有信令记录条目。以一天当中一个用户的所有信令数据作为一个信令数据单元,记为DataUnit,对每个单元按照接下来的步骤进行计算。
(2)利用无监督聚类方法,设置聚类数目依次为2,3,4,……,30,对DataUnit中的空间点进行聚类,并通过聚类评分指标评价每一个聚类结果,评分高者为最佳聚类。
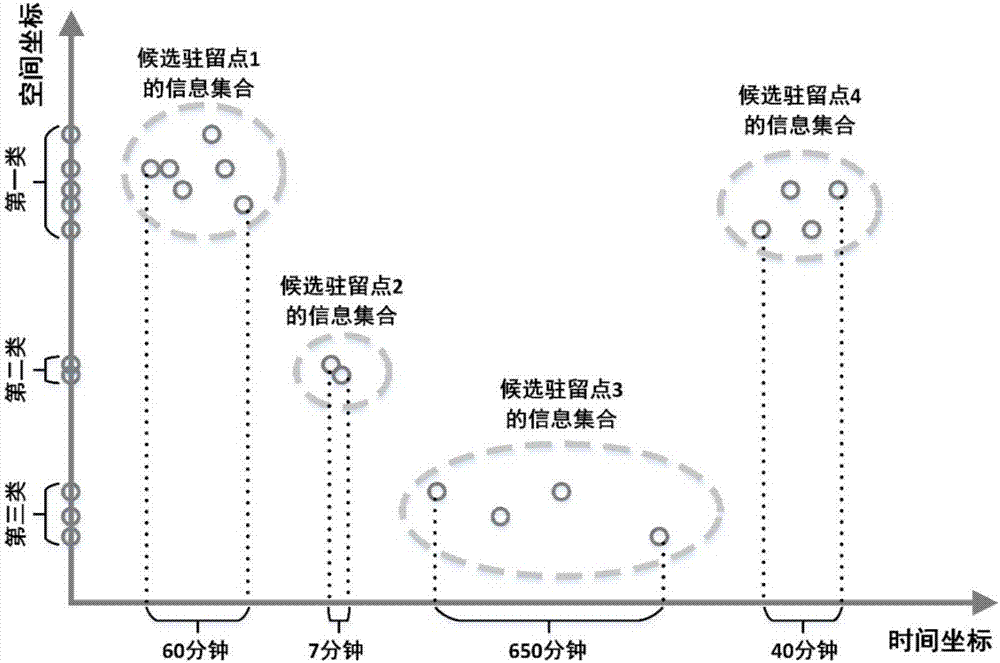
对于一个DataUnit,将DataUnit中每条信令记录中基站空间坐标作为一个空间点,利用k-means无监督聚类方法对该信令数据单元中的所有空间点进行聚类。若有坐标相同的空间点均算作不同点。聚类过程中,依次设置k=2,3,…,30,对于每一个k值,使用Dunn指标对聚类结果进行评分。评分最高的k值,则为最佳k值,其所对应的聚类结果为最佳聚类结果。如图2所示,图中纵坐标用于简要表示空间坐标,空间坐标轴上展示的是一个DataUnit中所有空间点的最佳聚类结果,即纵坐标轴上显示的3个类别。
(3)根据最佳聚类,得出DataUnit中所有候选驻留点及相关时间的信息集合。
(31)生成候选驻留点的信息集合InfoSet:通过阶段2获取该DataUnit中空间点的最佳聚类结果后,将DataUnit中的记录条目按照时间先后顺序进行排列,并将每条记录条目的空间点所在的类作为该记录条目的类。将时间顺序上相邻且同类的记录条目合并为一个集合,作为一个候选驻留点的信息集合InfoSet,即:
其中,Li表示第i个信息点的空间位置,ti表示第i个信息点的记录时间,|InfoSet|表示驻留点信息集合中信息点的个数。
如图2所示,图中横坐标表示时间坐标,一个DataUnit中的所有候选驻留点的InfoSet由图中的虚线圈出。
(32)计算候选驻留点相关参数:对于一个候选驻留点的信息集合InfoSet,计算该集合中空间点的平均位置,将其作为该候选驻留点的空间位置,即:
将集合中记录条目最早的时间作为该候选驻留点的到达时间tarr,将集合中记录条目最晚的时间作为该候选驻留点的离开时间tdep,用该候选驻留点的离开时间减去到达时间作为该候选驻留点的驻留时长tdur。即:
tarr=t1
tdep=t|InfoSet|
tdur=tdep-tarr
如图2所示,图中横坐标上标明了各候选驻留点的驻留时长tdur。
(4)根据时间阈值及各候选驻留点的信息集合,对候选驻留点驻留时长进行计算和筛选,输出每用户每天各驻留点空间位置LInfoSet、到达时间tarr及驻留时长tdur。
(41)根据时间阈值筛选候选驻留点:对于通过阶段3所得的一个DataUnit中的所有候选驻留点,将驻留时长小于15分钟的候选驻留点去掉,剩下的候选驻留点则为该DataUnit输出的驻留点。如图2所示,图中候选驻留点2由于驻留时长小于15分钟则被去掉,而其余候选驻留点的驻留时长大于15分钟则被保留,并作为驻留点。
(42)输出识别结果:将该DataUnit的所有驻留点的空间位置及其对应的到达时间和驻留时长结合起来,即(LInfoSet,tarr,tdur),并按到达时间先后顺序排列,即为对应用户在对应某天中的出行驻留行为的最终识别结果,即:
其中,|Result(user,day)|表示对应用户在对应某天中所识别出的实际出行驻留点个数。
图3展示了一个DataUnit通过本发明的用户出行驻留行为识别方法识别出的驻留行为实例。五角星表示识别出的用户驻留点位置,每个驻留点旁的信息框中展示了识别出的到达时间及驻留时间。
尽管本发明就优选实施方式进行了示意和描述,但本领域的技术人员应当理解,只要不超出本发明的权利要求所限定的范围,可以对本发明进行各种变化和修改。
- 还没有人留言评论。精彩留言会获得点赞!