一种面向Twitter观点分类的情感增强词嵌入学习方法与流程
本发明涉及计算机
技术领域:
,特别涉及一种面向twitter观点分类的情感增强词嵌入学习方法。
背景技术:
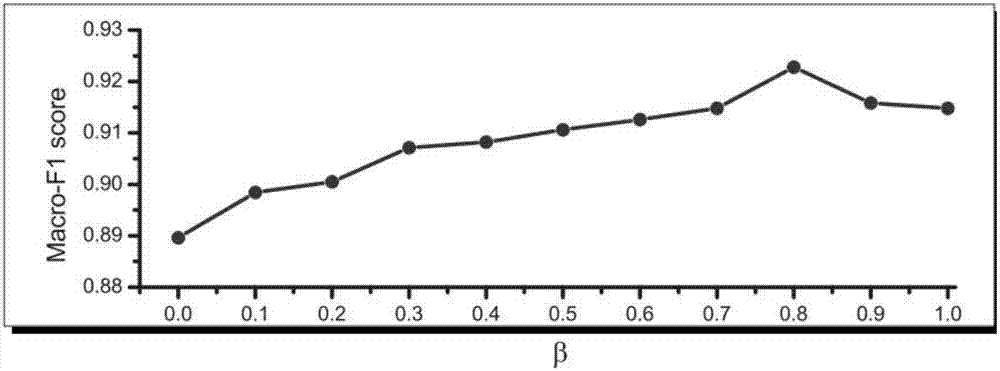
:twitter是互联网上最大的微博网站之一,目前已成为在线观点和情绪发布的重要来源之一。由于其海量的、多样化的以及稳步上升的用户基础,twitter中的包含的观点信息已经成功的应用于多种任务,如股票市场走势预测、政要信息监控以及推断公众事件民意等。因此,高效的正面、负面及中性观点的识别性能是应用任务的根本所在。学者们提出了多种方法来提高twitter的观点分析性能。特别是近年来深度神经网络的发展,证明了文本表示学习(词级别、句子级别以及文档级别的表示)对自然语文处理任务的重要性。传统的词嵌入方法主要是对句法上下文信息建模。在此基础上,tang等人提出情感相关的词嵌入(sentiment-specificwordembedding,sswe)学习方法用于twitter观点分类,其目的主要是针对两个观点极性相反的词具有相似的上下文信息这种现象,此现象会导致单纯的利用上下文信息学习到的词嵌入无法区分两个词的观点极性的问题。在sswe基础上,ren等人进一步提出主题和情感增强的词嵌入(topicandsentiment-enrichedwordembedding,tswe)模型来学习主题增强的词嵌入,其目的是进一步考虑情感词的多义现象。然而,已有的工作仅利用twitter总体的观点极性标签来进行情感相关的词嵌入学习,实际上有很多的经典的情感词典可以利用。此外,这些工作在传统方法基础上加入距离监督(distantsupervised)的tweet极性标签来学习情感相关的词嵌入,但传统的词嵌入学习方法是局部的上下文模型,而tweet极性标签属于全局文档级别信息。为了利用tweet极性标签,情感词嵌入方法假设观点上下文窗口中的每个词都影响着上下文极性,局部上下文的极性与tweet全局极性一致。换言之,他们直接将tweet级别的全局极性分配给局部的上下文而不经过任何修正。另一方面,从词典获取的词的极性对观点极性分类任务而言,仍然是一个非常有用的信息。因此,一个能够同时利用多级别(词级别与tweet级别)极性标签的词嵌入统一学习框架成为解决此问题的关键,同时这也是一个挑战性的问题。实事上,sswe模型将多个学习目标结合到了一个函数中,其目标分别是句法学习和情感极性学习。更进一步,tswe模型同时编码主题信息、情感信息和句法信息到神经网络的优化目标中。然而,多数情况下,多个目标不能直接采用一个统一的框架进行优化,例如,词情感极性与tweet观点极性。尽管多级别情感表示可以看成多任务,但与标准多任务学习有着不同的输入:(1)词及其上下文和(2)整个tweet。两个输入分别对应于词的情感极性和tweet的观点极性,而多任务深度学习方法通常只有一个统一的文档(tweet)输入。因此,无法直接使用已有的多任务深度学习框架处理此问题。技术实现要素:本发明实施例提供了一种面向twitter观点分类的情感增强词嵌入学习方法,用以解决现有技术中存在的问题。一种面向twitter观点分类的情感增强词嵌入学习方法,该方法包括:输入tweetd包含n个上下文窗口c,将每一个所述上下文窗口c输入至一个共享单元,所述共享单元的词嵌入维度是d,隐藏层维度是h,每个所述共享单元均包含一个词嵌入层和一个线性层,每一个所述上下文窗口c中具有t个词,将所述上下文窗口c输入至所述词嵌入层后,输出是:其中,xi+1,xi+2,...,xi+ti≤n表示第i个所述上下文窗口c中的t个词,将所述词嵌入层的输出xi+1:i+t输入至所述线性层,得到词嵌入向量:其中,f()表示线性函数,w11∈r(t*d)×h和为所述线性层的参数,r为实数空间,其上标表示空间维度,*表示数值相乘,×表示维度叠加;所述共享单元输出的词嵌入向量ei经过左子网络的激活层输出a1=htanh(ei),然后将a1经过两个线性变换处理后分别得到n-gram预测分值和词级别的情感预测分值:其中,fngm为n-gram预测分值,fws为词级别的情感预测分值,和均为所述左子网络的参数;在模型训练时,输入所述上下文窗口c和其变异体到左子网络,因此词级别的损失函数通过下式计算:lossws(c)=max(0,1-φ(0)fws(c)+φ(1)fws(c))其中,α是线性插值权重,φ(·)是所述上下文窗口c的中心词的观点极性指示函数:其中y是词的标准情感标签,当使用2维向量来表示y,即负面极性表示为[1,0],正极性表示为[0,1];将n个所述共享单元输出的词嵌入向量e1,e2,...,ei,...,en输入至右子网络,所述词嵌入向量e1,e2,...,ei,...,en组成的集合用e表示,对e分别采用max-pooling、average-pooling和min-pooling三种池化方法处理后分别获得固定维度的特征max(e)、avg(e)和min(e),对该些特征经过线性层进行线性处理后得到:其中,w12∈rt*h×h和为线性层的参数,经过softmax层预测得到的tweet观点极性为:fds=softmax(a2)因此,tweet级别的损失函数为:其中,g(·)是tweet在[positive,negative]上的黄金标准情感分布;根据所述词级别的损失函数和tweet级别的损失函数计算最终优化目标的总体分数:其中,β为词级别和tweet级别之间的权重调和系数;以所述最终优化目标的总体分数为训练目标,采用基于词典资源和大规模的距离监督tweet语料训练所述左子网络和右子网络,得到修正后的词嵌入向量;使用有监督学习算法对使用所述修正后的词嵌入向量表示的tweet进行极性分类。优选地,使用随机梯度下降法来优化训练所述左子网络和右子网络,并采用mini-batch来加速训练过程。优选地,在所述左子网络和右子网络训练时采用两个不同的batch大小,主batch大小是针对tweet级别,次batch大小则与每条tweet中设置的所述上下文窗口数相同。优选地,使用一个神经网络分类器来完成极性分类任务,具体包括:首先,一个多过滤器的卷积层处理输入的tweet,然后,一个maxpooling层取每个卷积核的最大值做为特征,下一层是全连接隐藏层,其激活函数是relu,主要用于学习隐含的特征表示,最后一层是全连接层,其2维输出采用softmax来预测正/负极性分布。本发明的有益效果在于:当同时建模词级别n-gram和极性信息时,本发明的方法不仅建模tweet文档级别的情感极性信息,还集成了词级别情感信息,并自然地将词级别输入卷积后作为tweet级别的输入。当使用学习到的词嵌入到twitter观点极性分类任务中,在标准的数据集上的实验结果表明本发明的方法胜过目前的同类方法。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明实施例提供的一种面向twitter观点分类的情感增强词嵌入学习方法的流程图;图2为采用不同β值的mswe方法的macro-f1变化曲线。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。如图1所示,本发明公开了一种面向twitter观点分类的情感增强词嵌入学习方法,该方法包括:步骤100,预处理输入tweet。具体地,输入tweetd包含n个上下文窗口c,将每一个所述上下文窗口c输入至一个共享单元,所述共享单元的词嵌入维度是d,隐藏层维度是h,每个所述共享单元均包含一个词嵌入层和一个线性层,每一个上下文窗口c中具有t个词,将所述上下文窗口c输入至所述词嵌入层后,输出是:其中,xi+1,xi+2,...,xi+ti≤n表示第i个所述上下文窗口c中的t个词,将所述词嵌入层的输出xi+1:i+t输入至所述线性层,得到词嵌入向量:其中,f()表示线性函数,w11∈r(t*d)×h和为所述线性层的参数,r为r为实数空间,其上标表示空间维度,*表示数值相乘,×表示维度叠加。步骤110,计算词级别的损失函数。具体地,所述词嵌入向量ei经过左子网络的激活层输出a1=htanh(ei),然后将a1经过两个线性变换处理后分别得到n-gram预测分值和词级别的情感预测分值:其中,fngm为n-gram预测分值,fws为词级别的情感预测分值,和均为所述左子网络的参数。在模型训练时,输入所述上下文窗口c和其变异体到左子网络,因此词级别的损失函数通过下式计算:lossws(c)=max(0,1-φ(0)fws(c)+φ(1)fws(c))其中,α是线性插值权重,φ(·)是所述上下文窗口c的中心词的观点极性指示函数:其中y是词的标准情感标签,当使用2维向量来表示y,即负面极性表示为[1,0],正极性表示为[0,1]。值得注意的是,如果c的中心词不是情感词,则只优化n-gram预测分值。所述变异体由用一个不同的词替换c的中心词后得到。步骤120,计算tweet级别的损失函数。具体地,将n个所述共享单元输出的词嵌入向量e1,e2,...,ei,...,en输入至右子网络,所述词嵌入向量e1,e2,...,ei,...,en组成的集合用e表示,对e分别采用max-pooling、average-pooling和min-pooling三种池化方法处理后分别获得固定维度的特征max(e)、avg(e)和min(e),对该些特征经过线性层进行线性处理后得到:其中,w12∈rt*h×h和为线性层的参数。经过softmax层预测得到的tweet观点极性为:fds=softmax(a2)因此,tweet级别的损失函数为:其中,g(·)是tweet在[positive,negative]上的黄金标准情感分布。步骤130,根据步骤110和步骤120中得到的损失函数计算最终优化目标的总体分数:其中,β为词级别和tweet级别之间的权重调和系数。步骤140,以步骤130计算得到的最终优化目标的总体分数为训练目标,采用基于词典资源和大规模的距离监督tweet语料训练所述左子网络和右子网络,得到修正后的词嵌入向量。其中距离监督tweet是基于正hashtag(如#happy、#joy和#happyness等)和负hashtag(如#sadness、#angry和#frustrated等)以及表情符(如:(:-(:(:):-):):d等)。本文爬取的tweet语料是从2015年3月1日至2015年4月30日。经过分割每条tweet,移除@user、网址urls、重复内容引用、垃圾内容以及其他非英文语言等预处理步骤,最终得到正负极性的tweet各500万条。本实施例中使用随机梯度下降法来优化训练目标,并采用mini-batch来加速训练过程。然而,对于词级别的预测,在tweet中有大量的有效词需要计算n-gram和极性损失。对于tweet级别预测,只有一个损失值。而且,为了计算tweet级别的极性损失分数,需要首先计算线性变换a1。因此,普通的mini-batch无法应用于本发明的方法。为此,本发明在两个子网络训练时采用两个不同的batch大小。主batch大小是针对tweet级别,次batch大小则与每条tweet中设置的窗口数相同。换言之,词级别batch大小是可变的,而tweet级别batch则是固定的。在训练时,本实施例中经验性的设置上下文窗口大小为3,词嵌入维度为50,隐藏层维度为20,主batch大小为32,学习率为0.01。步骤150,使用有监督学习算法,例如svm(支持向量机),对使用所述修正后的词嵌入向量表示的tweet进行极性分类。具体地,本实施例使用一个神经网络分类器来完成分类任务。首先,一个多过滤器的卷积层处理输入的tweet。然后,一个maxpooling层取每个卷积核的最大值做为特征。下一层是全连接隐藏层,其激活函数是relu,主要用于学习隐含的特征表示。最后一层是全连接层,其2维输出采用softmax来预测正/负极性分布。本文在输入层和隐藏层使用dropout做正则化来避免过拟合。此神经网络分类器采用后向传播来训练,参数更新采用adagrad方法。实验评估1、数据集及设置在如下两个数据集上进行实验:1)semeval2013,一个标准的twitter极性分类测试集;2)cst(context-sensitivetwitter),ren等人提供的最新的twitter极性分类数据集,他们爬取基本的观点tweet及其上下文来评估其模型,因为在其模型中使用到了上下文信息做为辅助训练语料。由于本发明的方法暂时不考虑上下文信息,因此在实验中仅使用基本的观点tweet而不包括上下文。表1展示了每个数据集的详细信息,评估方法采用正负分类的macro-f1值。表1数据集统计信息(cv表示采用10折验证)对于不同的任务需要仔细设置不同的参数,为了便于对比实验结果,本实施例采用统一的设置。这些超参数的设置值是在semeval2013开发集上的手工调试得到的。最终模型中包括7个超参数,分为网络参数(即词嵌入维度d、隐藏层维度h、卷积核大小s和卷积核数量n)和有监督训练参数(即输入层dropout概率d1、隐藏层dropout概率d2、学习率η)。表2列出了所有的设置值。表2最终模型中的超参设置值2、对比实验结果本发明的方法与一系列的最新方法进行了对比,实验结果如表3所示。所有方法可以分成两类:采用不同特征组合的传统分类器和神经网络分类器。在第一类包括:distsuper+uni/bi/tri-gram:在距离监督语料上训练的使用词典模型的liblinear分类器;svm+uni/bi/tri-gram:采用n-gram特征的svm分类器;svm+c&w:采用c&w词嵌入特征的svm分类器;svm+word2vec:采用word2vec词嵌入特征的svm分类器;nbsvm:综合naivebayes和nb-enhancedsvm的分类器;rae:使用wikipedia预训练词向量的递归自编码器;nrc:semeval2013twitter极性分类任务的最好系统,主要通过结合各种情感词典和手工设计的复杂特征;sswe:采用sswe词嵌入特征的svm分类器。其中sswe达到了同类方法最好的性能,此方法使用的是包含了n-gram和情感信息的词嵌入特征。nrc系获得了仅次于sswe的性能,因为使用了情感词典和很多手工设计的复杂特征。由于没有显示地利用情感信息,使用c&w和word2vec特征的分类结果相对较差。对于第二类包括:tswe:利用主题和情感增强的词嵌入特征的神经网络分类器;cnnm-local:利用上下文辅助训练资源的神经网络分类器。神经网络分类器可以很自然的使用词嵌入进行分类。tswe和cnnm-local由于使用了情感信息之外的其他信息,分别获得了目前最佳的性能。而在仅使用情感信息的条件下,本发明的方法效果要好于二者。本发明提出的方法与nrc都采用了情感词典信息并取得了较好性能,这也说明情感词典对twitter观点极性分类任务来说仍然是一项很有效的资源。表3实验对比结果modelsemeval2013sstdistsuper+uni/bi/tri-gram63.84-svm+uni/bi/tri-gram75.0677.42svm+c&w75.89-svm+word2vec76.31-nbsvm75.28-rae75.12-nrc(topsysteminsemeval)84.7380.24sswe84.9880.68tswe85.34-cnnm-local-80.90mswe(ourmodel)85.7581.343、参数β的影响β是用于平衡两类信息的系数。本发明在semeval2013开发集上调整β参数值。对于另一个系数α,本实施例采用设置值0.5。图2显示了是在semeval2013开发集上mswe模型的macro-f1值的变化曲线。可以看出,当β=0.8时,词级别信息的权重较高,其性能最佳。当β=1时模型退化为sswe,不同之处是训练时的情感标签是来自于词典,当β=0时表示仅使用tweet级别的情感信息。当β=0时效果最差,这表明n-gram信息是twitter极性分类任务一个不可或缺的特征。根据调试结果,本实施例选择β=0.8做为最终的实验设置值。本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1