基于反向工作流调度的子期限获取优化方法与流程
本发明属于网格计算、云计算领域,具体地说,是一种涉及有期限约束的工作流在一组固定资源上调度时任务子期限获取优化方法。
背景技术:
在有期限约束的dag工作流共享一组静态资源的调度中,子期限通常作为判定每个任务优先级的计算参数之一。另外,有关用户调度费用的优化,为了得到最合理的资源分配,考虑到每个任务允许费用优化的程度,子期限通常是一个重要指标[1,2]。因此,合理获取每个任务的子期限具有重要的现实意义。
与著名的heft调度算法[3]假设相同,假定一个dag多个任务节点需要映射到一组异构分布式计算资源r上并行调度。每个有向边两端的节点对应于父、子任务之间的,由于控制和数据依赖关系的存在,所有的父任务完成后子任务才能执行。根据著名的heft算法假设,每个任务ni在各计算资源上的执行时间花费已知的,资源带宽假定为1,ci,j表示任务ni传递到nj的数据通信时间花费,映射在同一资源上的任务间通信时间花费为0。在dag中,没有任何父任务的任务被称为入口任务,表示为nentry,而没有任何子任务的任务被称为出口任务,表示为nexit。如果给定工作流在dag中包含了多于一个的入口任务或出口任务,可以生成一个零花费的伪入口任务。这样的假设并不会影响到工作流调度时的执行花费[4]。
heft算法其关键思想分为两步,第一是根据任务的执行时间以及与父任务的数据传输时间计算得到这个任务到出口任务之间的最大距离,即向上权值ranku(ni),如公式(1):
其中:
根据这个数值进行任务优先级排序。
第二个阶段是根据第一个阶段得到的任务排序,选取未被调度的任务中优先级最高的任务,遍历每个处理机,查找到能够最早完成任务的处理机,插入到可用的空闲时间中。
现有文献[1,2]关于获取dag任务子期限的方法通常是基于计算当前任务到出口任务的近似关键路径进行定义的,如公式(2)。
其中:succ(ni)为任务ni的所有直接子任务,nj属于succ(ni),
这种获取子期限的方法并没有考虑到并行任务的多少对子期限的影响,在衡量任务紧急程度方面不够准确,具有较大的改进的空间。
技术实现要素:
本发明针对提出了对有期限约束的dag反向调度获取任务子期限的方法。子期限就是要找到所有任务在一组资源上调度时的最迟允许完成时间,也就是每个任务尽可能的推迟完成,直到再推迟会造成整个dag超出期限。为了达到每个任务的最大推迟完成,用dag反向逐个调度获取最早完成时间及最早开始时间,通过期限反转即可得到子期限和最迟运行开始时间。dag的反向调度策略首先对dag中所有的边做反向处理,即直接子任务和直接父任务的角色交换,然后再采用让每个任务具有最早完成时间的heft算法进行调度。实际调度时,为了更快捷地得到反向dag采用heft算法的调度结果,并不需要对dag做实际反向,只需要基于heft算法,实现反向heft调度的rheft方法。具体步骤如下:
步骤(1):计算每个任务ni的到入口任务nentry的最大平均距离参数,也就是任务ni的反向权值rankr(ni),如公式(3),反向是相对于heft算法中的向上权值而定义的。
其中:prec(ni)表示任务ni的所有直接父任务,np为任务ni的其中一个直接父任务,
步骤(2):任务排序。
按照dag中每个任务的rankr(ni)降序排列,得到任务到资源的调度映射列表,使得出口任务nexit优先调度,入口任务nentry最后调度。
步骤(3):选择资源。
从调度列表中按顺序取出第一个任务,从所有资源中寻找具有最早可完成时间的任务的资源时隙。若第一个任务为nexit,直接判定各资源的最小执行时间就可找到资源;否则,由于反向,所取出的第一个任务ni所有子任务均已经映射到资源,先要计算出ni的所有子任务到每个资源的最大传递时间。当前任务在满足最大传递依赖的基础上找到各个资源上的可用时隙,取具有最小结束时间的资源实现调度映射。例如一个简单的四任务dag的反向调度结果如图1所示,任务ni映射到资源后可以求得其执行最早开始时间estrheft(ni)和最早结束时间eftrheft(ni)。
步骤(4):计算任务子期限和最迟开始时间。
任务ni的子期限或者最迟完成时间subdl(ni)可定义为:
subdl(ni)=d-estrheft(ni)(4)
其中:d为dag期限
任务ni最晚开始时间lst(ni)可定义为:
lst(ni)=d-eftrheft(ni)(5)
步骤(5):调度列表中去除任务ni,重复步骤(3)(4)(5),
直到dag所有任务完成向资源的调度映射,输出每个任务计算结果subdl(ni)、lst(ni)。
通过本发明所获取到有期限dag在一组资源上调度时的每个任务子期限和最迟开始时间,由于是真正调度得到的结果,每个任务在子期限前完成均可保证所在dag中剩余任务的如期完成,比起现有以关键路径思想获取的子期限更具有可信性。子期限的获取还可进一步应用到费用优化的算法中,作为费用优化时选择资源的判定基准。
附图说明:
图1:反向dag采用heft算法调度结果示例
图2:低并行度简单dag示例数据
图3:具有高并行度的简单dag示例数据
具体实施方式
有期限约束工作流调度的子期限获取优化方法的算法描述如下:
输入:一组计算资源r,一个dag各任务在资源组上的运行时间矩阵w,任务间数据传递矩阵c,dag期限d
1:根据任务所在层倒序排列任务,同一层按原有顺序排列
2:根据公式(2)计算每个任务ni反向权值rankr(ni)
3:对所有任务按反向权值排序得到未映射任务列表unmaplist
4:while(unmaplist≠φ)do
5:取出反向权值最大的任务ni
6:根据dag反向调度思想所有子任务(反向父任务)已被映射到资源,获取ni的所有子任务
7:对各处理器上计算ni的最早可结束时间ft,(ft=子任务执行结束时间+与子任务数据传递时间+该处理器上的执行时间)的,得到任务映射到各处理器的最早完成时间eftrheft(ni)及对应最早开始时间estrheft(ni)。
8:从unmaplist去除任务ni
9:对gk每个任务ni根据公式(4)计算subdl(ni)和公式(5)计算最晚开始时间lst(ni)
10:endwhile
11:返回dag中各任务子期限和最迟开始时间
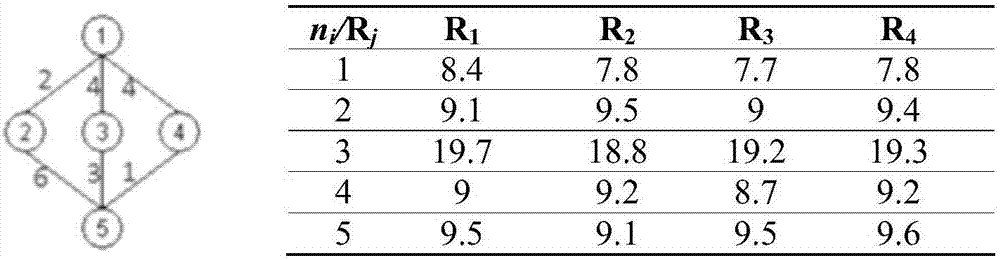
设置dag并行度0.5(每层并行任务均值与处理器个数关系),随机生成简单dag1(a)如图2,图中的圆圈表示任务号,任务之间的边方向均为反向,边权重为数据传递时间花费,并给出了各任务在一组处理器上的任务执行时间花费。
若dag期限为38.8,根据rheft算法,按照本专利的实现方法进行逐步计算:
步骤(1):通过上述给定dag示例数据,基于公式(3)计算每个任务的反向权值rankr(ni):
rankr(a1):7.925rankr(a2):19.175rankr(a3):31.175
rankr(a4):20.95rankr(a5):43.6
步骤(2):按照dag中每个任务的rankd(ni)降序对任务排序,得到任务调度顺序为:a5,a3,a4,a2,a1,依次放到调度映射列表。
步骤(3):从调度列表中按顺序取出一个任务,从所有资源中寻找具有最早可完成时间的任务的资源时隙。
假定反向后子任务先调度,子任务传递给父任务,对于每个资源所有已调度子任务传递数据到达该资源的最大传递时间。当前任务在满足传递依赖的基础上找到各个资源上的可用时隙,取具有最早结束时间eft的资源实现调度映射,同时得到近似最早开始时间est。a5从0开始,在r2具有最小执行时间9.1,因此选择资源r2。第二轮取任务时会取出a3,由于反向传递,a5传递数据给a3时间花费为9.1,选择r1、r3、r4上的允许开始时刻是9.1+3=12.1,r2上传递时间为0,允许开始时刻为9.1,因此a3在四个处理器最早结束时间分别为32.3、27.9、31.7、31.9,因此选择资源r2。其他任务依次类推,每轮选择一个计算,最后得到a1的est、eft。具有dag1(a)的反向调度结果示意如图2所示,调度过程中可以求得每个任务反向执行最早开始时间和最早完成时间,est、eft及对应选择的资源具体结果见表1:
表1
步骤(4):按照公式(4)、(5)计算每个任务子期限subdl和最迟开始时间lst,并公式(2)计算任务subdl进行对比,对比结果见表2。
表2
由两类方法获取的子期限可知,在dag每层任务并行度较小使得最多任务数小于处理器个数时,公式(2)方法计算出来各任务子期限通常是大于rheft方法获取的子期限。另外rheft方法同一层上的任务子期限有更大的差别,且大小顺序与反向权值一致,而公式(2)方法计算出来各任务子期限同一层大小相对集中,未考虑跟权值的关系。当采用同样的并行度随机生成更多任务的dag时(20/50/100个任务),依然具有这样的规律。另外,若按公式(2)计算出的任务a1的子期限为3.9,对于任务a1在各个处理器上的执行时间最小为7.7,所以在子期限内根本没有办法执行该任务。事实上,当采用heft算法对dag1(a)进行调度时,得到的最大完成时间是36.4<38.8,也就说明期限内是可以完成所有任务的,由此也可以看出公式(2)计算子期限方法的不合理。
若设置随机产生dag的并行度提高到2(约2倍于处理器个数随机生成各层任务),仍采用四个处理器,即某些层中任务并行个数远大于处理器个数,对应具有高并行度的dag2(b)结构及数据参数如图3,期限为27。对应依然采用两种方法所计算出来子期限进行对比,对比结果见表3。从这个对比结果我们可以看到,rheft方法获取的任务子期限仅有n6的子期限是大于现有方法的,而这个任务在各个处理器平均执行时间显然大于其他任务,属于关键路径中的一个任务。当处理器数目保持不变,并行度依然为2,继续随机产生更多任务的dag时(20/50/100个任务),同样,现有方法仅有关键路径中的任务子期限是小于rheft方法获取的任务子期限。因此,当dag任务具有高并行度并大于处理器个数时,rheft方法得到的任务子期限通常大于现有方法得到的任务子期限。
表3
从二者的对比可以看到,基于rheft算法获取的任务子期限更分散,大小顺序与反向权值一致,约束会更合理。当每个任务临近其子期限时刻执行完成后,比其优先级更低的任务仍然可以执行完成,而基于公式(2)获取的子期限由于没考虑任务的并行性,在高优先级任务临近其子期限剩余时间则有可能完成不了全部剩余任务。
参考文献
[1]abrishamis,naghibzadehm,epemadhj.deadline-constrainedworkflowschedulingalgorithmsforinfrastructureasaserviceclouds[j].futuregenerationcomputersystems,2013,29(1):158-169.
[2]jiay,buyyar,chenkt.cost-basedschedulingofscientificworkflowapplicationonutilitygrids[c]//internationalconferenceone-scienceandgridcomputing.dblp,2006:8pp.-147.
[3]topcuogluh.,hariris.andmin-youw..performance-effectiveandlow-complexitytaskschedulingforheterogeneouscomputing.ieeetransactionsonparallelanddistributedsystems,2002(13):260-274.
[4]sakellariour.,zhaoh..ahybridheuristicfordagschedulingonheterogeneoussystems[c]//parallelanddistributedprocessingsymposium,2004.proceedings.international.ieee,2004:111.
- 还没有人留言评论。精彩留言会获得点赞!