一种基于新型随机分形理论的动态数据挖掘方法与流程
本发明属于非线性动力学、分形行为及时间序列建模与分析理论在大数据中的动态数据挖掘应用技术领域,尤其涉及一种基于新型随机分形理论的动态数据挖掘方法。
背景技术:
识别时间序列的分形行为是动态数据挖掘中最具挑战性的问题之一。典型的随机分形行为包括统计自相似性、幂律、及长记忆性(即长程相关性),这些行为广泛发生在自然、医学、生态、水利、工程、网络、经济及金融等复杂系统。发现自相似序列、增长或缩短长相关程度等方法带来各种用途。例如,自相似在网络流量、股市动态、生理信号等许多领域有着重要应用。股票收益长记忆性意味着股价波动具有一种持久性或长期依赖性,对资产定价模型的效力具有潜在的重要影响,因而增长股市收益长记忆性具有重大经济价值。
分形数据挖掘利用数据集分形维数的意义对数据集进行挖掘,目前在分形维数在特征属性选择、聚类、关联规则、分类和预测等方向上,在网络数据挖掘、金融数据分析、地理信息挖掘等领域中有一定的应用。分形数据挖掘技术面临诸多挑战,比如如何判断数据集具有分形特征、如何快速计算数据集的分形维数、如何在计算机上模拟实现、如何解释数据集分形维数的实际意义等。这些问题主要归因于分形维数自身,包括1)分形维数作为普适的复杂性标度律被引进,然而它即不是一个合格的标定律,又不能确定一个分形模式。分形维数有很多定义方式,如豪斯道夫维数、信息维数、关联维数、相似维数、容量 维数、多重分形谱、填充维数、分配维数、李雅普洛夫指数、集团维数、质量维数、微分维数、布里格维数、模糊维数、广义维数等。同一对象的分形维数估计值可以由于计算方法不同而不同,相同的分形维数可以对应不同的分形模式。2)分形维数的难以估计导致无法快速计算数据集的分形维数。大多通过统计或近似的方法得到,例如计算最常用的豪斯多夫维数,一般要通过计盒维数估计到它的一个上界和通过局部维数估计到它的一个下界。3)经典的分形过程如离散的分形布朗运动,它的不可迭代性使得难于在计算机上实现模拟。4)分形维数与分形行为之间,无论是解析关系还是直观关系都不清楚,阻碍了分形方法参与精确建模,像对石油储层裂缝这样的分形现象的精细描述还依然是石油地质界未能完全解决的世界性难题。分形维数被编入经典的时间序列模型试图实现精确建模,但是又带来新的问题,例如经典的ARFIMA分形过程建模需要计算非常大的样本逆矩阵。5)分形维数作为标度律没有明确的物理意义,所以无法提供关于分形行为及其相关现象的成因。例如无法解释为什么新兴市场普遍存在长记忆性,而像美国那样的国际性市场却不存在显著的长记忆性的现象。
识别时间序列的生成机制是动态数据挖掘的最高宗旨。利用数据生成机制可望揭示动态特征的形成和控制机制、以及对未来的数据进行推断和预测。然而现有的动态数据和分形数据挖掘方法不提供数据集的生成过程。许多模型如时间序列ARMA和ARCH模型,技术如模糊建模、神经网络、遗传算法、数学优化及自组织法,被用于提取动态数据中有用信息,通常得出结果,而不能解释结果,更不提供数据集的生成过程。另一方面,动态特征和分形行为与观察尺度密切相关,过小的观察尺度会影响完整地反映数据生成机制,过大的观察尺度会因为样本的时间跨度过大,使得无法收集到足够反映系统的样本数,或者导致资源浪费和因为时效失去数据价值。因此识别足够反映复杂系统的动态 特征和分形行为的最小观察尺度的生成过程将产生重大价值。例如水文尺度问题就被列入21世纪水文学基础研究的前沿课题。从目前学术研究或专利来看,尚无基于物理学原理从系统入手导出的模型被用于非线性动态特征和随机分形行为的方法和技术。近年、通过牛顿运动第二定律在一类随机自律恢复调节系统的应用、然后经过离散化,导出一类非线性自回归整合(NLARI)过程。这类具有自律恢复调节的系统也称随机弹性系统广泛地存在于自然、生态、医学、工程、经济和社会等许多实际系统中。NLARI过程可以被特定如下:
让Yt=Xt-μt,方程(1)可被改写为
在那里
其中ω表示外部扰动的期待值,σ表示外部扰动的标准差,εt为标准方差σ的高斯白噪音,α是阻力系数,β是恢复力系数,κ1是在阻力上的时间滞后,κ2是在恢复力上的时间滞后。当σ=0或对所有时间t有εt=0,方程(2)是一个确定性系统,相对恢复力系数γ控制了该系统的稳定性与分岔:作为κ2=1,它是一个渐近稳定的零不动点在0<γ<1,一个渐近稳定的二周期环在一个不稳定的二周期环在 注意这里的稳定性是局部而不是全局稳定。当γ=0,NLARI过程退化 为一个线性的自回归整合ARI(2,1)过程。本发明将基于NLARI模型的动力学特征和统计性质发展一种新型的分形理论,从而导出识别时间序列的不同分形水平及其控制和生成机制的方法。
综上所述,现有技术中除了传统的技术外还包括新颖的数据流挖掘、分形数据挖掘、联机分析挖掘、经验模态分解、联系发现、趋势分析、偏差分析等,通过统计学和数学算法如模糊建模、神经网络、遗传算法、优化、自组织法等方法,在属性约简、分类、聚类、关联规则、序列模式、预测、离群点分析、空间数据分析等方向上有了一定的应用。很多方面还停留在对传统静态方法的改进上,面临诸多问题。动态数据挖掘技术只提供结果,不能解释结果,不提供数据集的生成过程。分形数据挖掘面临难于估计分形维数、建模分形过程、在计算机上实现模拟,不能揭示分形成因、控制机制和实际意义的困难。而且多数分形维数之间的关系、分形维数与分形行为的关系、分形维数与动态模式的关系都不明确。这些问题影响了分形数据挖掘。为了彻底解决分形数据挖掘问题,本发明将基于NLARI模型建立的一个新的随机分形理论;证明非线性动态特征和分形行为分别作为同一复杂系统的内生结构性质和系统对外部扰动的响应性质;提供同时识别数据集的自相似性幂律和长记忆性的分形行为、稳定不动点稳定及不稳定周期环的非线性动态特征、以及它们的控制参数的方法;提供足够反映复杂系统的动态特征和分形行为的最小观察尺度和生成过程的方法。
技术实现要素:
本发明的目的在于提供一种基于新型随机分形理论的动态数据挖掘方法,旨在解决过小和过大的观察尺度不仅影响完整反映数据生成机制,还会带来样 本数少,资源浪费,数据因时效失去价值;传统时间序列模型提取动态数据中,不能解释结果,不能提供数据生成过程的问题。
本发明是这样实现的,一种基于新型随机分形理论的动态数据挖掘方法,所述基于新型随机分形理论的动态数据挖掘方法通过加聚时间序列即放大观察尺度来改变NLARI的分形斜率指数参数和波幅指数参数,识别长记忆性、自相似性、兼有长记忆性和自相似性的不同分形水平的最小聚集度的时间序列生成过程和动力学特征。
进一步,通过控制时间序列的聚集度来识别不同分形水平和动力学特征的时间序列生成过程;具体包括:
步骤一,数据绝对值缩小化处理,记为X=(Xt:t=1,…,T);
步骤二,使用X计算最小二乘法回归直线使用及
ΔYt=Yt-Yt-1,对作最小二乘法估计获得参数估值记Y=(Y′10,…,Y′1t,…,Y′1T-1)′,s11和s22分别表示矩阵的第一行第一列的元素和第二行第二列的元素;
步骤三,计算θ1的置信区间其中是t分布在置信水平的临界值以及归无假说γ=0的统计量如果θ1的置信区间被包含在区间(-1,1)内并且归无假说γ=0被拒绝、接受对立假说γ>0的话,则证据支持数据来自NLARI过程,执行步骤四,否则对j=j+1(初值j=1),计算j重聚集时间序列Xj,记为X=Xj,执行步骤二;如果循环时间序列到不能继续被聚集,输出结果X是一个非NLARI过程或一个具有γ=0的退化ARI(2,1)过程,退出分析;
步骤四,记j1=j,让执行分形识别,获得j2重聚集序列分形度为(δ1,k,δ2,k),记为或无分形
步骤五,对和分别执行步骤二获得θ1的置信区间θ2的置信区间以及γ的置信区间其中如果θ1,θ2,γ的置信区间被包含在区间(-1,1),(0,4),(0,1)内,则证据支持X来自稳定不动点域上的NLARI过程;如果θ1,θ2,γ的置信区间被包含在区间内,则证据支持X来自稳定周期环域上的NLARI过程;如果θ1,θ2,γ的置信区间被包含在区间 内,则证据支持X来自不稳定周期环域上的NLARI过程;否则X来自临界值上的NLARI过程;输出具有这些动态特征的分形序列 和无分形序列包括模型参数作为结论。
进一步,识别不同长记忆水平的最小聚集度时间序列方法,包括:
1)选定一个正值递减序列δ1,k,设初值k=j=1和X1=X;
2)计算第j重聚集时间序列Xj;
3)计算Xj的样本自相关系数ρn作为n=1,…,N和LM(Xj);如果LM(Xj)<δ1,k,则执行步骤4),否则对j=j+1执行步骤2),当循环到时间序列不能继续被聚集时输出结果最小聚集度的长记忆性时间序列Xj-1(δ1,k-1)及模型参数在那里Xj(δ1,0)意味着原时间序列无长记忆性;
4)如果k<K,则令j=1和k=k+1,执行步骤2),否则输出结论最小聚集度的长记忆性时间序列Xj(δ1,K)及模型参数。
进一步,识别不同自相似水平的最小聚集度时间序列方法,包括:
A、选定一个正值递减序列δ2,k,设初值k=j=1和X1=X;
B、计算第j重聚集时间序列Xj;
C、计算Xj的样本相似比rh(i,im)和SShm(Xj)作为m=1,…,M,h=1,…,H和i=1,…,n;如果SShm(Xj)<δ2,k成立作为给定的m=1,…,M和h=1,…,H,则执行步 骤D,否则对j=j+1执行步骤B,当循环到时间序列不能继续被聚集时,输出结果最小聚集度的自相似性时间序列Xj-1(δ2,k-1)及模型参数在那里Xj(δ2,0)意味着原时间序列没有自相似性;
D、如果k<K,则令j=1和k=k+1,执行步骤B,否则输出结论最小聚集度的自相似性时间序列Xj(δ2,K)及模型参数。
进一步,识别不同分形水平的最小聚集度时间序列方法,包括:
a、选定两个正值递减序列δ1,k和δ2,k,设初值k=j=1和X1=X;
b、计算第j重聚集时间序列Xj;
c、计算Xj的样本自相关系数ρn作为n=1,…,N和LM(Xj)。如果LM(Xj)<δ1,k,则执行步骤d,否则对j=j+1执行步骤b,当时间序列不能继续被聚集时,输出结果最小聚集度的分形时间序列Xj-1(δ1,k-1,δ2,k-1)及模型参数,(δ1,0,δ2,0)为原序列 无分形结构;
d、计算Xj的样本相似比rh(i,im)作为i=1,…,n和SShm(Xj)作为m=1,…,M和h=1,…,H;如果SShm(Xj)<δ2,k作为h=1,…,H和m=1,…,M成立,则执行步骤e,否则对j=j+1执行步骤b;
e、如果k<K,则令j=1和k=k+1,执行步骤b,否则输出结论最小聚集度的分形时间序列Xj(δ1,K,δ2,K)及模型参数;通过限制δ1,k和δ2,k值识别不同长记忆和自相似水平的时间序列生成过程。
进一步,新型随机分形理论,包括:
(一)作为分形参数的斜率指数η1=ω/α和波幅指数η2=σ/β基于一类描述随机弹性系统的NLARI过程:
其中εt为白噪音,g(x)是满足条件g(-x)=-g(x)及xg(x)<0的恢复力函数,ω为外部扰动的期待值,σ为外部扰动的标准差,α是阻力系数,β是恢复力系数,κ1是在阻力上的时间滞后,κ2是在恢复力上的时间滞后;
(二)j重聚集时间序列其中充分加大聚集度j将同时导致一个相对大的|η1|和一个相对小的η2从而产生长记忆和自相似行为;
(三)自协方差rh的相似比rh(i,im)=rh(Xi)/rh(Xim),如果时间序列是自相似的话,它会随着i的增大趋于一条水平直线作为给定的h=1,…,H,m=1,…,M;
(四)长记忆水平指标和自相似水平指标
进一步,步骤四中,识别分形方法,包括:
一)计算j重聚集时间序列Xj、它的自相关系数ρn作为n=1,…,N和相似比rh(i,im)作为h=1,…,H,m=1,…,M和i=1,…,n;
二)加大聚集度j直到满足长记忆水平条件LM(Xj)<δ1,k和自相似水平条件SShm(Xj)<δ2,k对于所有h=1,…,H和m=1,…,M,其中δ1,k和δ2,k是两个正值递减数列;
三)通过改变δ1,k和δ2,k的值控制长记忆水平和自相似水平。
进一步,识别动力学特征方法包括:
基于t分布的θ1,θ2,γ的置信区间检定和归无假说γ=0对立假说γ>0的统计量检定,如果
证据支持数据具有NLARI的稳定不动点结构,如果
证据支持数据具有NLARI的稳定周期环结构,如果
证据支持数据具有NLARI的不稳定周期环结构。
进一步,检定方法,包括:使用X=Xj计算最小二乘法回归直线通过对ΔYt=θ1ΔYt-1+θ2g(Yt-1)+εt作最小二乘法估计在那里ΔYt=Yt-Yt-1,获得参数估值
本发明公开的NLAR1分形过程和经典的ARFIMA分形过程可以展现出非常类似的长记忆性(数据对比请参阅具体实施方式中的图1)。然而ARFIMA分形过程不能揭示分形维数和长记忆性的物理意义以及显示长记忆性的成因和控制因素。与此相比,本发明给出了NLARI过程的分形行为的控制机制和明确的物理意义:波动的均线斜率指标η1=ω/α控制了系统的长程相关程度,长相关性是系统遭受外部扰动水平相对于内部阻力系数的强度较大时系统的一种响应特性;波幅指标η2=σ/β确定了系统是否具有自相似性,自相似性是系统遭受外部扰动变化相对于内部恢复力系数较小时系统的一种响应特性;波动的均线斜率和波幅取决于系统外部对内部的相对作用强度,然而加大观察尺度会使斜率指标的绝对值递增同时使波幅指标递减,从而分别导致长记忆性和自相似性。这 就是说,只要系统存在自律恢复调节力,足够大的观察尺度上必然出现分形行为。基于这些性质,本发明提供同时识别不同水平的分形行为和生成机制及动力学特征;识别最小观察尺度即聚集尺度的自相似序列,从而为动态数据采样、压缩、特征抽取提供了科学标准;本发明的识别数据生成机制、诠译分形成因、调节记忆长度、利用或避免分形结构会产生各种用途;本发明虽然建立新型分形理论的途径非常复杂,但是该理论提供的分形方法却异常简单。
附图说明
图1是本发明实施例提供的显示NLARI过程可以展现出非常类似于经典ARFIMA分形过程长记忆性的一个实例图。
图2是本发明实施例提供的NLARI过程的分形参数即斜率指数η1和波幅指数η2与长记忆性关系。
图3是本发明实施例提供的NLARI过程的波幅指数η2与自相似性关系。
图4是本发明实施例提供的通过加聚时间序列来增大斜率指数|η1|和减小波幅指数η2的分形识别原理图。
图5是本发明实施例提供的识别时间序列的生成过程和动态特征的流程示意图。
图6是本发明实施例提供的识别不同长记忆水平的最小聚集度时间序列生成过程的流程示意图。
图7是本发明实施例提供的识别不同自相似水平的最小聚集度时间序列生成过程的流程示意图。
图8是本发明实施例提供的识别不同分形水平的最小聚集度时间序列生成过程的流程示意图。
图9是本发明实施例提供的分形参数与心跳时间序列的分形水平关系的一 个实例。
图10是本发明实施例提供的本发明识别不同分形水平的最小聚集度时间序列生成过程的一个示范例。
图11是本发明实施例提供的基于新型随机分形理论的动态数据挖掘方法原理示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明实施例提供的基于新型随机分形理论的动态数据挖掘方法,所述基于新型随机分形理论的动态数据挖掘方法通过加聚时间序列即放大观察尺度来改变NLARI的分形斜率指数参数和波幅指数参数,识别长记忆性、自相似性、兼有长记忆性和自相似性的不同分形水平的最小聚集度的时间序列生成过程和动力学特征。
下面结合附图及实施例对本发明作详细描述。
本发明所述的新型随机分形理论,包括:
(一)作为分形参数的斜率指数η1=ω/α和波幅指数η2=σ/β基于一类描述随机弹性系统的NLARI过程:
其中εt为白噪音,g(x)是满足条件g(-x)=-g(x)及xg(x)<0的恢复力函数,ω为外部扰动的期待值,σ为外部扰动的标准差,α是阻力系数,β是恢复力系数,κ1是在阻力上的时间滞后,κ2是在恢复力上的时间滞后;
(二)j重聚集时间序列其中充分加大聚集度j将同时导致一个相对大的|η1|和一个相对小的η2从而产生长记忆和自相似行为;
(三)自协方差rh的相似比rh(i,im)=rh(Xi)/rh(Xim),如果时间序列是自相似的话,它会随着i的增大趋于一条水平直线作为给定的h=1,…,H,m=1,…,M,
(四)长记忆水平指标和自相似水平指标
本发明所述的识别分形方法,包括:
(一)计算j重聚集时间序列Xj、它的自相关系数ρn作为n=1,…,N和相似比rh(i,im)作为h=1,…,H,m=1,…,M和i=1,…,n;
(二)加大聚集度j直到满足长记忆水平条件LM(Xj)<δ1,k和自相似水平条件SShm(Xj)<δ2,k对于所有h=1,…,H和m=1,…,M,其中δ1,k和δ2,k是两个正值递减数列;
(三)通过改变δ1,k和δ2,k的值控制长记忆水平和自相似水平。
所述的识别动力学特征方法,包括:基于t分布的θ1,θ2,γ的置信区间检定和归无假说γ=0对立假说γ>0的统计量检定,在那里如果
证据支持数据具有NLARI的稳定不动点结构,如果
证据支持数据具有NLARI的稳定周期环结构,如果
证据支持数据具有NLARI的不稳定周期环结构。
所述的检定方法,其特征在于使用X=Xi计算最小二乘法回归直线 通过对ΔYt=θ1ΔYt-1+θ2g(Yt-1)+εt作最小二乘法估计在那里ΔYt=Yt-Yt-1,获得参数估值
下面结合附图对本发明的应用原理作进一步描述。
本发明旨在提供一种新型随机分形理论的动态数据挖掘方法,它基于如下模型及性质:
一.描述一类随机弹性系统的一般NLARI过程:如图1所示;
方程(3)可以被改写为
在那里Yt=Xt-μt=X0-(ω/α)t并且
其中εt是白噪音,g(x)满足条件g(-x)=-g(x)及xg(x)<0为恢复力函数,其他各项、参数和物理含义与方程(1)相同。NLARI过程,方程(4)的参数域为
当g(x)=-x exp(-x2)和κ2=1,稳定不动点域上的NLARI过程的参数域为
稳定二周期环域上的NLARI过程的参数域为
不稳定二周期环域上的NLARI过程的参数域为
上述性质被用于识别数据的生成机制和动力学特征。本发明者通过模拟实验显示了上述性质并不拘泥于恢复力函数g(x)的具体结构,即别的形式的恢复力函数也有类似的动力学特征。首先要指出的是NLARI过程有一个分形结构,比如它可以很好地模拟一个经典的ARFIMA分形过程展现出的长记忆性(如图1所示,在那里g(x)=-x/(1+x2))。
二.分形参数:
性质1 在NLARI过程(3)上,导入斜率指数和波幅指数作为分形参数。
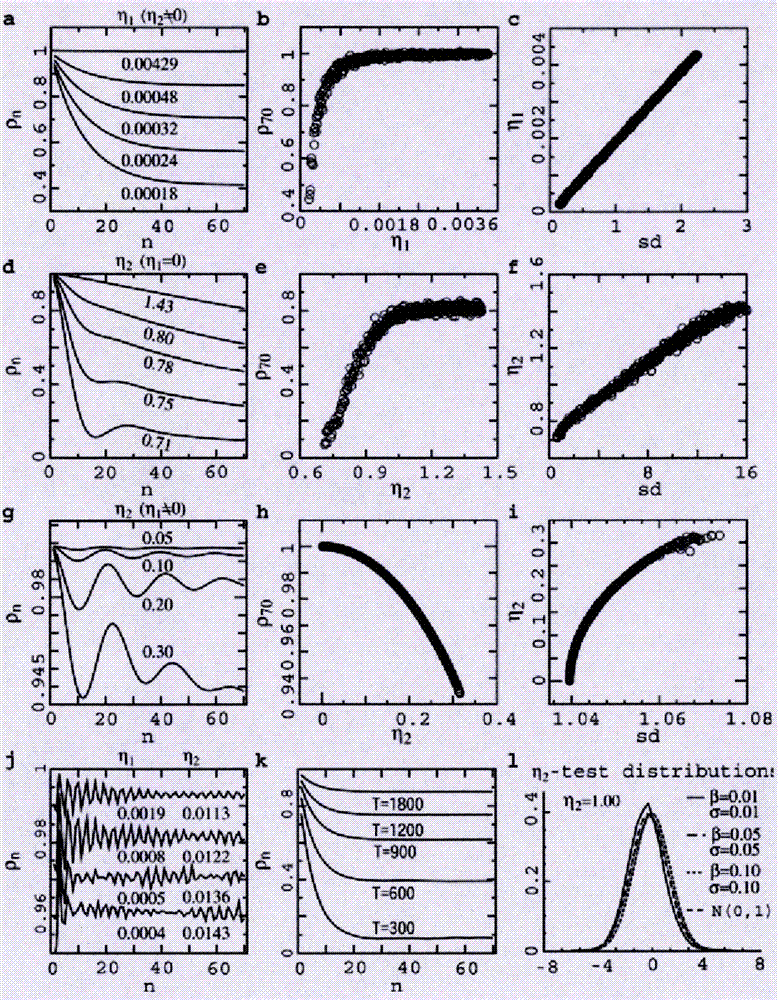
能够证明μt=E(Xt|X0,X-1)=X0+(ω/α)t依然成立,所以η1代表了波动平均线的斜率。样本标准差sd与η1完全正相关(如图2中的2c所示,相关系数r=1作为g(-x)=-x),与波幅指数η2完全正相关(当η1=0,如图2中的2f所示,r=1作为g(x)=-xexp(-x2))或者强正相关(当η1≠0,如图2中的2i所示,r=0.945作为g(x)=-x(1+x4)-1)。由于sd衡量了样本波动大小,所以η2被称为波幅指数。
三.长记忆性:
性质2 如果样本自相关系数作为n=1,…,N随滞后阶数n增大以低于指数衰减率缓慢下降,表明Xt有长记忆性。
性质3 NLARI过程(3)的长记忆性归因于一个相对大的斜率指数的绝对值|η1|,或者一个相对大的波幅指数η2当η1=0,或一个相对大的|η1|伴随一个相对小的|η2|。
由于总体自相关系数是未知的,考虑大量重复的模拟样本自相关系数的平均值(依然使用ρn来表示)作为总体自协方差的近似,这样的模拟ρn被用于发现长记忆性的控制机制。能够证实当相对恢复力系数γ 被增大,(i)随着斜率指数|η1|的增大,ρn随滞后阶数n的增大其下降程度减慢(如图2中的2a所示),|η1|和ρ70(最末一个自相关系数,它的绝对值反映了相关程度)完全正相关(如图2中的2b所示),这意味着相对大的|η1|将导致长记忆性出现作为η2≠0;(ii)当η1=0时,随着斜率指数η2的增大,ρn随滞后阶数n的增大其下降程度减慢(就像图2中的2d所示),|η1|和ρ70完全正相关(如图2中的2e所示),意味着相对大的η2将导致长记忆性出现;(iii)然而当η1≠0时,随着斜率指数η2的增大,ρn随滞后阶数n的增大其下降程度增大(就像图2中的2g所示),η2和ρ70负相关(如图2中的2h所示),意味着当η1≠0,增大η2会降低记忆长度。当相对恢复力系数γ被固定时,随着|η1|的增大和η2的减小,ρn随滞后阶数n的增大其下降程度减慢(如图2中的2j所示,在那里γ=0.7)。这说明一个相对大的|η1|或一个相对大的η2当η1=0,或者一个相对大的|η1|伴随一个相对小的η2可以导致时间序列的长记忆性。该发现解释了新兴市场比成熟市场有更长的记忆是因为其内生系统更为薄弱,即α和β更小,它们导致|η1|和η2的值比成熟市场更大。过小样本会遮挡长记忆性(如图2中的2k所示)。
四.自相似性:
由于分布意义上的统计自相似性是否存在尚缺乏证据,所以本发明考虑二阶自相似性,它涉及时间序列的聚集度(或观察尺度)。例如月度物价指数(指以月为单位的平均价格变动)和年度物价指数(指以年为单位的平均价格变动)的聚集度分别为月和年。
性质4 让X=(Xh:h=1,…,T)表示原时间序列和表示j重聚集序列如果对于任意整数m存在一个常数δ使得滞后阶数h的自协方差rh满足条件rh(Xm)=mδrh(X),则称X有二阶自相似性。
这里δ的分量容许为负数,也不要求X必须是稳定的。由于总体自协方差是未知的,这里通过大量重复的模拟样本自协方差的平均(仍用rh表示)作为总体自协方差的近似。作为自相似性序列X,有rh(X)=i-εrh(Xi)及rh(Xm)=i-δrh(Xim),于是
成立。称rh(i,im)为相似比,为平均m相似比。显然有如下性质:
性质5 如果X是自相似序列,那么对于给定的m=2,…,M和h=1,…,H,相似比rh(i,im)伴随聚 集度i的增长展现出一条水平直线,并且平均相似比rhm服从幂律m-δ。
性质6 NLARI过程(3)的自相似性归功于一个相对小的波幅指数η2。
本发明证实了当η2的值小到一定程度,NLARI过程(3)将展现出自相似性。比如随着η2的值从1.3降到0.1,自相似比随着i的增大由一条向下倾斜线逐渐变成一条水平直线(图3中的3a),自相似比r5(i,2i)随着i的增大由向下倾斜曲线趋向于一条水平直线(图3中的3b);当η2=0.025时,作为m=2,…,20,自相似比r5(i,im)随着i的增大展现出一条水平直线(图3中的3c);平均相似比r5m服从幂律m-3.022(图3中的3d)。
性质7 充分加聚NLARI过程(3)产生的时间序列,即让聚集度(或观察尺度)j充分大,可以同时获得一个相对大的斜率指数的绝对值|η1|和一个相对小的波幅指数η2,它们将导致聚集时间序列产生长记忆性和自相似性。
随着滞后阶数j的增大,聚集时间序列Xj的斜率指数的绝对值|η1(Xj)|几乎呈直线增大(如图4中的4a所示)而波幅指数η2(Xj)呈指数减小(如图4中的4b所示)。这二者将分别导致长记忆性和自相似性的出现,比如随着聚集度j从5加大到100,自相关系数ρn对滞后阶数n的曲线从迅速下降到几乎不下降、直至成为一条水平直线,显示了很高的长记忆性(如图4中的4c所示);自相似比sd(i,2i)对i的曲线逐步由下降曲线变成水平直线,显示了很高的自相似性(如图4中的4d所示)。可见NLARI的分形行为(长记忆性和自相似性)可以通过加聚它的时间序列而呈现。
性质8 称为长记忆水平指标在那里n0和N分别是初始终滞后阶数。称为自相似水平指标。
初始滞后阶数n0不一定为1,譬如n0=2。通常0≤LM(Xj)≤1和0≤SShm(Xj)≤1。分形水平指标愈小意味着分形水平愈高。
下面结合具体实施例对本发明的应用原理作进一步描述。
本发明实施例提供的新型随机分形理论的挖掘动态数据方法,以g(x)=-x(1+x2)-1,κ1=κ2=1及εt是高斯白噪音i.i.d.N(0,σ2)为例,说明本发明公开的统计分形理论应用于动态数据挖掘方法由四部分组成,分别按如下具体步骤实现:
第一部分 识别时间序列的生成过程和动态特征:
步骤1 数据绝对值缩小化处理,记为X=(Xt:t=1,…,T)。
步骤2 使用X计算最小二乘法回归直线使用及
ΔYt=Yt-Yt-1,对作最小二乘法估计获得参数估值记Y=(Y′10,…,Y′1t,…,Y′1T-1)′,Y1t=(ΔYt,-Yt(1+Yt2)-1),s11和s22分别表示矩阵的第一行第一列的元素和第二行第二列的元素(如图5中的501)。
步骤3 计算θ1的置信区间其中是t分布在置信水平的临界值以及归无假说γ=0的统计量如果θ1的置信区间被包含在区间(-1,1)内并且归无假说γ=0被拒绝、接受对立假说γ>0的话,则证据支持数据来自NLARI过程,执行步骤4(如图5中的502),否则对j=j+1(初值j=1),计算j重聚集时间序列Xj(如图5中的503),记为X=Xj,执行步骤2。如果循环时间序列到不能继续被聚集,输出结果“X是一个非NLARI过程或一个具有γ=0的退化ARI(2,1)过程)”退出分析(如图5中的504所示)。
步骤4 记j1=j,让执行第二部分分形识别,获得j2重聚集序列分形度为(δ1,k,δ2,k),记为或无分形(如图5中的505所示)。
步骤5对和分别执行步骤2获得θ1的置信区间θ2的置信区间以及γ的置信区间其中如果θ1,θ2,γ的置信区间被包含在区间(-1,1),(0,4),(0,1)内,则证据支持X来自稳定不动点域上的NLARI过程;如果θ1,θ2,γ的置信区间被包含在区间(-1,1),内,则证据支持X来自稳定周期环域上的NLARI过程;如果θ1,θ2,γ的置信区间被包含在区间(-1,1),(0,+∞),内,则证据支持X来自不稳定周期环域上的NLARI过程;否则X来自临界值上的NLARI过程(如图5中的506所示)。输出具有这些动态特征的分形序列和无分形序列包括模型参数作为结论。
第二部分 识别不同长记忆水平的最小聚集度时间序列
步骤1 选定一个正值递减序列δ1,k,设初值k=j=1和X1=X(如图6中的6的601)。
步骤2 计算第j重聚集时间序列Xj(如图6中的602所示)。
步骤3 计算Xj的样本自相关系数ρn作为n=1,…,N和LM(Xj)。如果LM(Xj)<δ1,k,则执行步骤4(如图6中的603所示),否则对j=j+1执行步骤2,当循环到时间序列不能继续被聚集时输出结果“最小聚集度的长记忆性时间序列Xj-1(δ1,k-1)及模型参数在那里Xj(δ1,0)意味着原时间序列无长记忆性”(如图6中的604所不)。
步骤4 如果k<K,则令j=1和k=k+1,执行步骤2(如图6中的605所示),否则输出结论“最小聚集度的长记忆性时间序列Xj(δ1,K)及模型参数”(如图6中的606)。
第三部分 识别不同自相似水平的最小聚集度时间序列
步骤1 选定一个正值递减序列δ2,k,设初值k=j=1和X1=X(如图7中的7的701)。
步骤2 计算第j重聚集时间序列Xj(如图7中的702所示)。
步骤3 计算Xj的样本相似比rh(i,im)和SShm(Xj)作为m=1,…,M,h=1,…,H和i=1,…,n。如果SShm(Xj)<δ2,k成立作为给定的m=1,…,M和h=1,…,H(如图7中的703所示),则执行步骤4,否则对j=j+1执行步骤2,当循环到时间序列不能继续被聚集时,输出结果“最小聚集度的自相似性时间序列Xj-1(δ2,k-1)及模型参数在那里Xj(δ2,0)意味着原时间序列没有自相似性”(如图7中的704所示)。
步骤4 如果k<K,则令j=1和k=k+1,执行步骤2(如图7中的705所示),否则输出结论“最小聚集度的自相似性时间序列Xj(δ2,K)及模型参数”(如图7中的707)。
第四部分 识别不同分形水平的最小聚集度时间序列
步骤1 选定两个正值递减序列δ1,k和δ2,k,设初值k=j=1和X1=X(如图8中的801)。
步骤2 计算第j重聚集时间序列Xj(如图8中的802所示)。
步骤3 计算Xj的样本自相关系数ρn作为n=1,…,N和LM(Xj)。如果LM(Xj)<δ1,k,则执行步骤4(如图8中的803所示),否则对j=j+1执行步骤2,当时间序列不能继续被聚集时,输出结果“最小聚集度的分形时间序列Xj-1(δ1,k-1,δ2,k-1)及模型参数,在那里(δ1,0,δ2,0)意味着原序列无分形结构”(如图8中的804所示)。
步骤4 计算Xj的样本相似比rh(i,im)作为i=1,…,n和SShm(Xj)作为m=1,…,M和h=1,…,H。如果SShm(Xj)<δ2,k作为h=1,…,H和m=1,…,M成立,则执行步骤5,否则对j=j+1执行步骤2(如图8中的805所示)。
步骤5 如果k<K,则令j=1和k=k+1,执行步骤2(如图8中的806),否则输出结论“最小聚集度的分形时间序列Xj(δ1,K,δ2,K)及模型参数”(如图8中的807)。
通过限制δ1,k和δ2,k值利用上述方法可以识别不同长记忆和自相似水平的时间序列生成过程。
下面结合具体实施例对本发明的应用原理作进一步描述。
图9显示了本发明用于一个心跳时间序列(无心脏病、年龄34岁、男性、52200个样本值)的一个实例。由于样本不够长,因此数据未被加聚,即j1=1。原始心跳数据经过对数转换的缩小化处理被用于估计NLARI过程的参数,获得最小二乘法估计值κ1=κ2=1,基于这些估计值的θ1,θ2,γ的置信区间在稳定不动点的理论参数域(-1,1),(0,4),(0,1)内。作为检定归无假说γ=0的统计量为γn=85,由于P(γn>11.9)<1%,所以证据支持对立假说γ>0。这些结果支持心跳时间序列来自稳定不动点域上的NLARI过程。该心跳时间序列进一步被划分为29个时间序列,每一个时间序列有1800个样本值,各段展现出不同水平的长记忆性(如图9中的9a所示),随着|η1|和η2的增大,样本自相关系数ρn对滞后阶数n的曲线的下降程度愈慢,证实了愈大的|η1|或η2会导致愈长的记忆水平(图9中的9b)。在较小的m(比如m=2)处,sd(i,mi)展现出粗略近似的水平直线(如图9中的9c所示),它的平均sdm符合一个幂函数m1.02(如图9中的9d所示),然而rh(i,mi)和η2(i,mi)以及在较大m的sd(i,mi)没有展现出近似水平直线,这是因为该心跳时间序列有一个相对大的η2值0.3140。
图10显示了本发明识别最小聚集度分形过程的一个示范例。考虑数据产生于一个稳定不动点域的NLARI过程,在那里j1=1,θ0=-4.475×10-7,θ1=0.5027,θ2=0.0794,σ=0.0249,η1=-8.999×10-7,η2=0.3136,γ=0.0264,T=1.8×107,N=70,n=50,m=20。获得在分形水平指标和的最小聚集度j2=100的分形,自相关系数ρn随着滞后阶数n的增大展现出几乎为一条水平的直线,显示了高度长记忆性(如图10中的10a所示),相似比对i几乎是水平直线,平均相似比服从于一个幂律m-0.97,显示X100有高度的自相似性(如图10中的10b所示)。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,其中包括基于本发明的精神和原则创造一个满足不同水平分形和动力学特征要求的最小尺度时间序列生成过程的应用,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!