一种基于工业大数据挖掘的状态预测方法与流程
本发明属于工业大数据挖掘领域,特别涉及一种基于工业大数据挖掘的状态预测方法
背景技术:
随着工业系统日益大型化和复杂化,人们对系统运行的安全性和可靠性要求也越来越高。系统之间的连接更加紧密,一个零部件的故障会导致子系统故障甚至是整个系统瘫痪,这些问题都给企业带来巨大的经济损失,甚至会造成环境污染甚至是人员伤亡。提前估计系统的运行状态,预测发生异常的时间和位置,是及时排除潜在危险,维护系统的正常运行,提高安全性和经济效益的有效手段。
神经网络、Markov模型、Bayesian估计和ELM等是目前常见的预测方法。其中,ELM(极限学习机器,是一种泛化的单隐层前馈神经网络)方法更适合处理海量数据,具有训练速度快、人工干预少、泛化能力强等特点。OS-ELM(在线顺序极限学习机器)方法能够对系统状态进行在线实时预测,但是OS-ELM网络是基于序列输入数据随机产生的,预测效果可能遇到最差的情形。为了避免这种情形,EOS-ELM方法将若干个OS-ELM的预测结果取平均值,以便能适应不同的数据适应能力,提高方法的稳定性和可靠性。当输入数据连续地进入EOS-ELM系统,部分OS-ELM网络模型能够更快更好地适应新数据,这样能获取更好的预测结果。本发明就是利用EOS-ELM方法解决工业大数据的状态预测问题。
针对上诉问题,本发明人一种基于工业大数据挖掘的状态预测方法。
技术实现要素:
本发明的目的在于提供一种基于工业大数据挖掘的状态预测方法,以解决目前工业系统中系统状态难以预测的问题,提高预测的稳定性和可靠性。
为了实现上述目的,本发明采用如下技术方案:
一种基于工业大数据挖掘的状态预测方法,包括以下步骤:
步骤一,数据采集:将反映系统历史运行状态的样本作为训练集其中xi是系统状态变量,即模型的输入,ti是关注的预测指标,即模型的输出;
步骤二,OS-ELM模型:采用步骤一的训练样本建立若干个OS-ELM模型,并计算得到若干个预测值;
步骤三,EOS-ELM模型:对OS-ELM模型的的预测结果取平均值,得到EOS-ELM模型预测结果。
所述OS-ELM模型建立过程包括:
初始化之前,先确定网络初始参数:网络有L个隐含节点,首先确定隐含节点类型,隐含节点类型包括为RBF或additive隐含节点;
初始化阶段,从训练样本中选取部分样本进行初始化,该初始化阶段包括以下步骤:
步骤1:随机对输入参数赋值
其中,对RBF隐含节点,参数为中心点ai和影响因子bi;对additive隐含节点,参数为输入权重ai和偏差bi;
步骤2:计算初始的隐含层输出矩阵H0
其中,利用RBF隐含节点时,G(ai,bi,xj)=g(bi||xj-ai||),bi∈R+,当利用additive隐含节点时,G(ai,bi,xj)=g(ai·xj+bi),bi∈R;
步骤3:估计初始的输出权重β(0)
令权重求解问题转化为最小化||H0β-t0||;
由ELM算法的求解,可知最小化||H0β-t0||的求解结果为其中
步骤4:令k=0,k表示加入网络的数据块的数量;
连续学习阶段,包括以下步骤:
k+1数据块的观测值为:
其中,Nk+1是k+1数据块的观测值的数量;
步骤5:计算局部的隐含层输出矩阵Hk+1
步骤6:设置参数
步骤7:计算输出权重β(k+1)
步骤8:令k=k+1,返回步骤5;
当所有训练数据都参与训练时,循环结束,计算预测输出,即OS-ELM预测值;
步骤1-8重复J次,J为OS-ELM模型数量。
在所述连续学习阶段后,还包括模型评估阶段,该阶段具体为:
利用连续学习阶段产生的参数a、b、权重β以及测试的输入数据,得到预测输出,即EOS-ELM预测值。
对所述OS-ELM模型的的预测结果取平均值具体为:对所述变量xi,每个OS-ELM模型的输出为fj(xi),j=1,...,J,则EOS-ELM的预测输出为
在所述EOS-ELM算法前,使用变量选择与特征提取方法对步骤二得到的若干个预测值确定与输出相关的变量,以降低数据维数。
采用上述方案后,本发明有益效果是:本发明是将若干个OS-ELM模型预测结果取平均值,即得到EOS-ELM方法的预测结果,可避免OS-ELM模型可能遇到最差的预测结果,通过该方法准确对系统状态进行在线实时监控,泛化能力强,学习速率高,对海量数据的训练效果更为显著,计算成本低,还能为预警和故障诊断奠定基础。与传统的OS-ELM方法相比,还能避免可能出现的最差预测结果,增强模型对新数据的适应能力,提高预测的稳定性和可靠性。此外,该方法还能用到电池寿命估计、负荷预测等领域,适用范围广,实用性强。
下面结合附图对本发明做进一步的说明。
附图说明
图1为本发明基于工业大数据挖掘的状态预测流程图;
图2为非线性数值仿真的EOS-ELM方法预测输出图;
图3为非线性数值仿真的EOS-ELM与OS-ELM预测误差对比图。
具体实施方式
如图1所示本实施例揭示的一种基于工业大数据挖掘的状态预测方法,具体包括以下步骤:
步骤一,数据采集:将反映系统历史运行状态的样本作为训练集其中xi是系统状态变量,即模型的输入,ti是关注的预测指标,即模型的输出;
步骤二,OS-ELM模型:采用步骤一的训练样本建立若干个OS-ELM模型,并计算得到若干个预测值;
步骤三,EOS-ELM模型:对OS-ELM模型的的预测结果取平均值,得到EOS-ELM模型预测结果。
所述OS-ELM模型建立过程包括:
初始化之前,先确定网络初始参数:网络有L个隐含节点,确定隐含节点类型;
初始化阶段,从训练样本中选取部分样本进行初始化,该初始化阶段包括以下步骤:
步骤1:随机对输入参数赋值
其中,对RBF隐含节点,参数为中心点ai和影响因子bi;对additive隐含节点,参数为输入权重ai和偏差bi;
步骤2:计算初始的隐含层输出矩阵H0
其中,利用RBF隐含节点时,G(ai,bi,xj)=g(bi||xj-ai||),bi∈R+,当利用additive隐含节点时,G(ai,bi,xj)=g(ai·xj+bi),bi∈R;
步骤3:估计初始的输出权重β(0)
令权重求解问题转化为最小化||H0β-t0||;
由ELM算法的求解可知,可知最小化||H0β-t0||的求解结果为其中
步骤4:令k=0,k表示加入网络的数据块的数量;
连续学习阶段,包括以下步骤:
k+1数据块的观测值为:
其中,Nk+1是k+1数据块的观测值的数量;
步骤5:计算局部的隐含层输出矩阵Hk+1
步骤6:设置参数
步骤7:计算输出权重β(k+1)
步骤8:令k=k+1,返回步骤5;
当所有训练数据都参与训练时,循环结束,计算预测输出,即预测值;
步骤1-8重复J次,J为OS-ELM模型数量。
评估本发明的性能指标主要包括预测误差、算法的训练时间和测试时间,与其他预测算法相比,EOS-ELM算法的训练时间比较短,尤其在大数据领域效果更为突显,测试时间近似于0,适合于在线实时预测仿真,且EOS-ELM算法具有较强的泛化能力,能够避免局部最小化、不恰当的学习速率以及过拟合等问题,随着OS-ELM模型数量J的增加,预测效果也在不断改善,方法的稳定性和可靠性不断提高,但训练时间也随之增加,需要根据实际需求设置合理的J。
在连续学习阶段后,还包括模型评估阶段,该阶段具体为:
利用连续学习阶段产生的参数a、b、权重β以及测试的输入数据,得到预测输出,即预测值。
对OS-ELM模型的的预测结果取平均值具体为:对所述变量xi,每个OS-ELM模型的输出为fj(xi),j=1,...,J,则EOS-ELM的预测输出为
在EOS-ELM算法前,为了进一步降低算法计算量,提高算法在线实时预测能力,在使用EOS-ELM算法前,可以使用变量选择与特征提取方法,例如,基于偏最小二乘的变量选择方法,确定与输出相关的变量,降低数据维数,从而降低计算复杂度,提高在线实时预测性能。
以下为本发明以实际数据应用的实例,以采用非线性数值算例更明显地说明本发明的特点,结合本发明的原理说明其使用过程:
非线性数值算例为:
其中,变量t符合在[-1,1]上的均匀分布,εi(i=1,2,3,4)是在[-0.1,0.1]上均匀分布的噪声,y是输出;
在仿真中,具有10000个训练数据,1000个测试数据,隐含节点数为25,初始阶段的样本数为100,连续学习阶段每块的样本数为1;
步骤1,采用RBF隐含节点,对输入ai和影响因子bi进行随机初始化;
步骤2,计算初始的隐含层输出矩阵H0,H0∈R100×25,每个元素的计算公式为G(ai,bi,xj)=g(bi||xj-ai||);
步骤3,计算初始的输出权重β(0):
步骤4,令k=0
步骤5,计算局部的隐含层输出矩阵Hk+1,Hk+1∈R1×25;
步骤6,设置参数Tk+1,
步骤7,计算输出权重β(k+1);
步骤8,令k=k+1,返回步骤5,直至k=9900;
然后,利用训练得到的参数a、b和测试数据计算隐含层输出矩阵Hte,再结合训练得到的输出权重β,利用公式Yte=Hteβ计算得到预测输出;
分别重复上述步骤1-8,得到预测值J=5,J=10,J=15,J=20,J=25和J=30,并对预测结果取平均值,即为EOS-ELM;
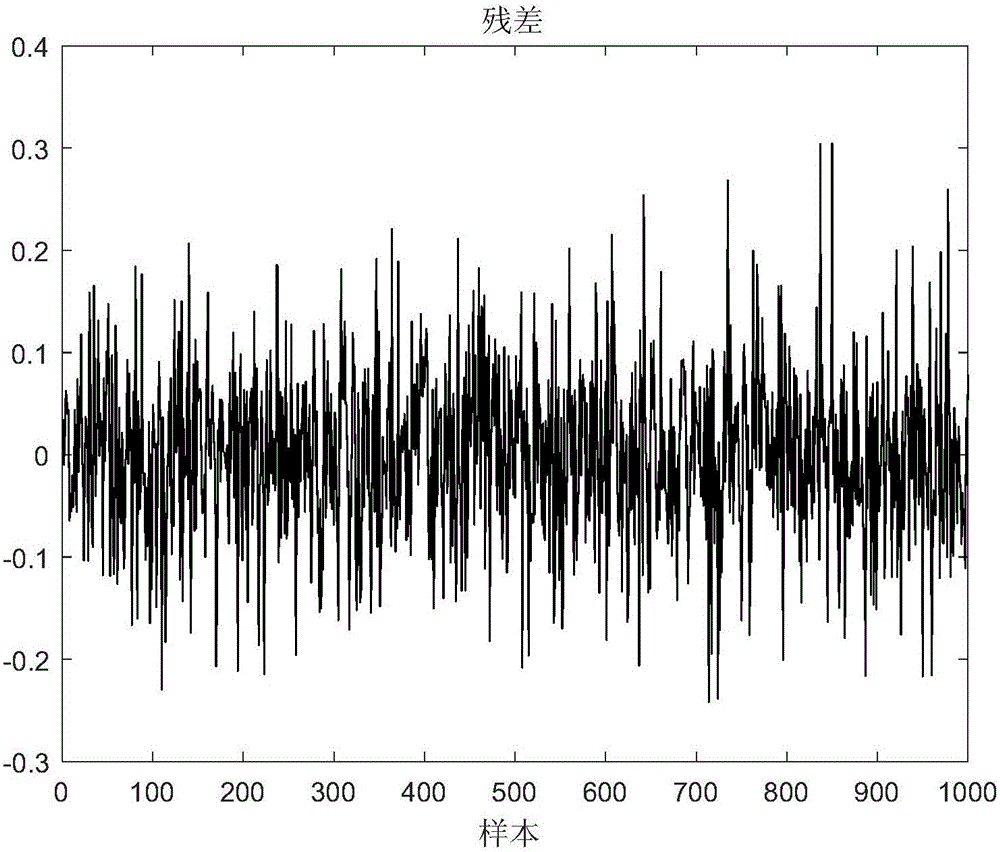
参见图2为J=10的EOS-ELM预测误差图;将OS-ELM方法和EOS-ELM方法进行比较,重复50次仿真实验,RMSE(标准误差)和测试的标准差的结果如表1所示;
测试标准差是重复仿真50次,测试过程50个RMSE值的标准差,能够反映方法的稳定性和可靠性;下表1:
衡量方法性能的指标训练时间、测试时间、训练精度、测试精度以及稳定性等,如表2所示;
表2
OS-ELM的预测误差对比如图3所示,图2和图3的对比进一步说明EOS-ELM方法的精度高。
上述说明示出并描述了本发明的优选实施例,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!