一种短期风速预测方法与流程
本发明涉及一种短期风速预测方法,尤其涉及到一种基于局域均值分解和改进粒子群算法优化神经网络的短期风速预测方法。
背景技术:
在20世纪70年代由于爆发了两次大规模的世界性能源危机,能源问题和环境问题日益突出。风能的利用越来越受到人们的重视。风能是一种无污染、可再生能源。目前,开发和利用风能的主要形式是风力发电。风力发电是发展最快和最成熟的可再生能源发电技术,已具有大规模商业开发的技术和经济条件。世界风力发电从1990年开始了迅猛发展。据世界风能协会的统计,截至2015年底,全球风电总装机容量达到432.4GW,其中2015年的新增装机容量达到63GW。而中国目前是世界上风电装机容量最多发展最迅速的国家,截至2015年底的风电总装机容量达到145.1GW,约占我国总装机容量的2.5%,年增长率达到26.6%。风电功率的高度非线性主要是由风速的非线性和非平稳造成的。风电的不稳定性将成为风电系统与主电网结合的障碍之一。故提高风速/风电功率的预测精度对电网运行有着重要意义。
风速预测方法按照预测模型的不同可分为:物理方法、统计方法和机器学习方法。统计方法主要有时间序列法、卡尔曼滤波法、灰色预测法、空间相关法等。常用的学习方法有人工神经网络法(ANN)、小波分析法、支持向量机和极限学习机,其中BP神经网络由于其具有自适应的特点而得到广泛应用。但单一的预测方法已很难满足预测精度的要求。风速时间序列具有风险性强和非平稳性高的特点,BP神经网络很难对波动较大的风速序列进行准确预测,且在模型训练阶段未考虑不同数据输入维数对预测结果的影响。因此,上述缺陷是亟需解决的问题。
技术实现要素:
本发明所要解决的技术问题,就是提供一种基于局域均值分解和改进粒子群算法优化神经网络的短期风速预测方法,可应用于风能相关领域的科学研究和工程应用,其可提高预测模型的稳定性和泛化能力,获得较单一预测方法更高精度的短期风速预测结果。
解决上述技术问题,本发明所采用的技术方案如下:
一种短期风速预测方法,其特征是包括以下步骤:
S1、获取原始风速时间序列,根据局域均值分解对原始风速时间序列进行分解,得到多个PF分量和一个余量;
S2、对余量和全部PF分量构建各自的训练数据集和测试数据集;
S3、对余量和全部PF分量分别建立改进粒子群算法优化神经网络的风速预测模型;
S4、将训练数据集中余量和全部PF分量的训练样本逐一输入改进粒子群算法优化神经网络的风速预测模型进行训练,针对不同PF分量设定数据输入维数学习反馈机制,得到各自对应的风速预测子模型;
S5、将测试数据集输入到各自对应的风速预测子模型进行预测,得到每个风速预测子模型的预测输出值;
S6、将每个风速预测子模型的预测输出值进行叠加处理(全部取和),得到最终的风速预测结果。
所述步骤S1的局域均值分解对原始风速时间序列进行分解的具体步骤为:
1)找出原始信号x(t)所有的局部极值点ni,求出所有相邻的局部极值点的平均值:
式中:i代表局部极值点的个数,原始信号x(t)代表风速信号,t代表风速信号数据个数;
将所有相邻的平均值点mi用直线连接起来,然后用滑动平均法进行平滑处理,得到局部均值函数m11(t);
2)求出包络估计值点ai:
将所有相邻的估计值点ai用直线连接起来,然后用滑动平均法进行平滑处理,得到包络估计函数a11(t);
3)将局部均值函数m11(t)从原始信号x(t)中分离出来,得到:
h11(t)=x(t)-m11(t);h11(t)代表第一次分离计算得到的余量函数;
4)用h11(t)除以包络估计函数a11(t),以对h11(t)进行解调,得到:
s11(t)=h11(t)/a11(t);s11(t)代表第一次解调后的调频信号。
对s11(t)重复步骤1)-2),得到s11(t)的包络估计函数a12(t);
假如a12(t)不等于1,说明s11(t)不是一个纯调频信号,需重复上述步骤1)-4)n次,直至s1n(t)为一个纯调频信号,也就是s1n(t)的包络估计函数a1(n+1)(t)=1,所以有:
式中,
h11(t),h12(t),…,h1n(t)代表从第1次计算到第n次计算得到的n个余量函数;m11(t),m12(t),…,m1n(t)代表第1次计算到第n次计算得到的n个局部均值函数;s11(t),s12(t),…,s1n(t)代表第1次计算到第n次计算得到的n个调频信号;a11(t),a12(t),…,a1n(t)代表第1次计算到第n次计算得到的n个包络估计函数。
迭代终止条件为:
式中,a1n(t)为第n次计算得到的包络估计函数。
实际应用中,在不影响分解效果的前提下,为了减少迭代次数,降低运算时间,可设置一个变量Δ,使得当满足1-Δ≤a1n(t)≤1+Δ时,终止迭代;
5)将迭代过程中所产生的全部包络估计函数相乘,得到第一个分量的包络信号(瞬时幅值函数):
式中,a1q(t)代表第q次计算得到的包络估计函数,q=1,2,...,n。
6)将包络信号a1(t)和纯调频信号s1n(t)相乘得:
PF1(t)=a1(t)s1n(t);
式中,PF1(t)为信号x(t)的第一个PF分量,包含了原始信号的最高频成分,是一个单分量的调幅-调频信号,瞬时频率f1(t)由调频信号s1n(t)求出:
从原始信号x(t)中将第一个PF分量PF1(t)分离出来,得到剩余信号u1(t),由于剩余信号u1(t)中还包含较多频率成分,因此将u1(t)作为原始数据重复上述步骤1)到6)k次对其进行分解,得到第二个PF分量,重复这个过程直到uk(t)为一个单调函数(单调递增或单调递减函数)为止;如此得到一定数量的PF分量:
式中,u1(t),u2(t),…,un(t)为第1次到第k次分解计算得到的k个剩余信号;PF1(t),PF2(t),…,PFk(t)为第1次到第k次分解计算得到的k个PF分量。
最终信号x(t)表示为k个PF分量和余量之和:
式中,PFp(t)为第p个PF分量,p=1,2,...,k;uk(t)为残余函数,代表信号的平均趋势。
所述骤S2的构建自训练数据集和测试数据集的方法具体为:
PF分量PFk和余量uk的训练数据集Trn包含模型的输入数据Xn和输出数据Yn,输入数据和输出数据是对PF分量和余量的时间序列进行连续采集而来,输入数据其中m为预测模型输入个数,输出数据l的取值由预测模型输出个数决定;
PF分量PFk和余量uk的训练数据集Ten包含模型的输入数据XXn和输出数据YYn,输入数据和输出数据是在训练数据集采集完成后,接着对PF分量和余量的时间序列进行连续采集而来,输入数据其中m为预测模型输入个数,输出数据l的取值由预测模型输出个数决定。
所述步骤S3的建立改进粒子群算法优化神经网络的风速预测模型具体为:
1)神经网络包括一个输入层、一个隐含层和一个输出层,输入层神经元个数等于模型输入个数m,输出层神经元个数等于模型输出个数l,隐含层神经元个数a为1~10中的自然数;其中隐含层神经元激活函数使用sigmoid函数,sigmoid函数计算公式为:
式中,x为隐含层神经元的输入,f(x)为隐含层神经元的输出。
输出层神经元激活函数使用线性函数,线性函数计算公式为:
f'(x)=w*x'+b
其中,x'为输出层神经元的输入,f'(x)为输出层神经元的输出,w表示隐含层神经元单元到输出层神经元单元的联接权值系数,b表示输出层神经元的阈值;
神经网络需要优化的变量个数为:
num=m×s+s+s×l+l;
2)改进粒子群算法优化神经网络过程如下:
随机生成一组粒子作为初始值来拟合改进粒子群算法优化神经网络模型:
i=1,2,...,M
其中,IW为输出层到隐含层权值,有m×s个;Ib为隐含层阈值,有s个;LW为隐含层到输出层权值,有s×l个;Lb为输出层阈值,有l个;M为种群大小,共M个粒子;Xi为第i个粒子。
用这些粒子探索目标空间,在目标空间的k次迭代中,由分别描述每一个粒子的位置和速度,每个粒子记录下它们最好的位置在k+1次迭代中,粒子的速度由下式得到:
式中,r1、r2和r3分别是0和1之间的随机数,w为惯性权重系数,c1、c2和c3是训练系数,Pgbest为粒子全局最优位置,Pgworst为粒子全局最差位置;
w采用混沌惯性权值,其计算公式如下:
w=wmin+(wmax-wmin)×z(k);
其中,z(k)=μz(k-1)(1-z(k-1)),μ=4,z(1)=0.8,wmax为0.9,wmin为0.4,在每次迭代中,每个粒子的新位置是由它原来位置和它当前的速度相加得到的,如以下公式:
所述步骤S4的针对不同PF分量设定数据输入维数学习反馈机制具体为:
在模型训练过程中针对每个PF分量进行多次训练,每次训练选取不同的输入维数m(3<m<12),比较维数在3到12维之间时的模型学习效果,选出每个分量最佳的输入维数,采用均方误差公式MSE评价不同输入维数下模型的学习效果,MSE表示如下:
式中,为训练功率输出值;yi为功率实际值;N为样本数;
每次训练结束后比较MSE,选取最佳的输入维数建立风速预测模型。
本发明的有益效果是:本发明的基于局域均值分解和改进粒子群算法优化神经网络的短期风速预测方法,首先针对风速序列非线性强的特点,采用局域均值分解自适应的将原始风速序列分解为多个PF分量和一个余量,然后对各个分量建立改进粒子群算法优化神经网络的预测模型,同时针对不同分量各自的序列特性建立输入维数学习反馈机制,从而建立各分量最佳的预测模型,提高预测模型的稳定性和泛化能力;最后叠加全部分量的预测值得到真实的风速预测结果;本方法能获得较单一预测方法更高精度的短期风速预测结果。
附图说明
下面将结合附图及实施例对本发明做进一步的详细说明。
图1是本发明预测模型结构图;
图2是本发明实施例的流程图;
图3是本发明实施例的改进粒子群算法优化神经网络的流程图;
图4是发明实施例的输入维数学习反馈机制流程图;
图5是发明实施例的LMD-EPSO-NN模型预测效果图;
图6是发明实施例的三种预测模型预测效果对比。
具体实施方式
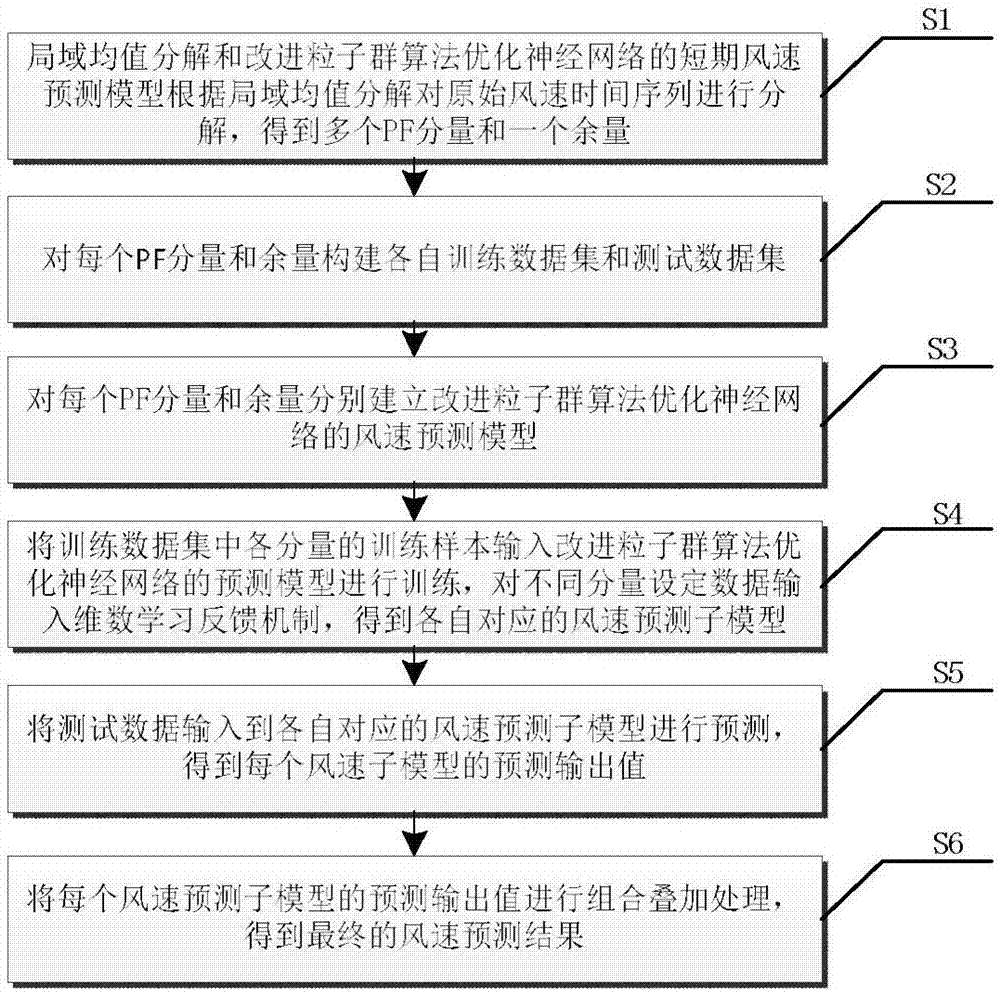
如图2所示,本发明的基于局域均值分解和改进粒子群算法优化神经网络的短期风速预测方法实施例,包括以下步骤:
S1、根据局域均值分解对原始风速时间序列进行分解,得到多个PF分量和一个余量;
具体步骤为:
1)找出原始信号x(t)所有的局部极值点ni,求出所有相邻的局部极值点的平均值:
将所有相邻的平均值点mi用直线连接起来,然后用滑动平均法进行平滑处理,得到局部均值函数m11(t)。
2)求出包络估计值:
将所有相邻的平均值点ai用直线连接起来,然后用滑动平均法进行平滑处理,得到包络估计函数a11(t)。
3)将局部均值函数m11(t)从原始信号x(t)中分离出来,得到:
h11(t)=x(t)-m11(t)
4)用h11(t)除以包络估计函数a11(t),以对h11(t)进行解调,得到:
s11(t)=h11(t)/a11(t)
对s11(t)重复上述步骤便能得到s11(t)的包络估计函数a12(t),假如a12(t)不等于1,说明s11(t)不是一个纯调频信号,需重复上述迭代过程n次,直至s1n(t)为一个纯调频信号,也就是s1n(t)的包络估计函数a1(n+1)(t)=1,所以有:
式中,
迭代终止条件为:
实际应用中,在不影响分解效果的前提下,为了减少迭代次数,降低运算时间,可设置一个变量Δ,使得当满足1-Δ≤a1n(t)≤1+Δ时,终止迭代。
5)将迭代过程中所产生的全部包络估计函数相乘,得到包络信号(瞬时幅值函数):
6)将包络信号a1(t)和纯调频信号s1n(t)相乘得:
PF1(t)=a1(t)s1n(t)
式中,PF1(t)为信号x(t)的第一个PF分量,包含了原始信号的最高频成分,是一个单分量的调幅-调频信号,瞬时频率f1(t)则可由调频信号s1n(t)求出:
从原始信号x(t)中将第一个PF分量PF1(t)分离出来,得到剩余信号u1(t),由于剩余信号u1(t)中还包含较多频率成分,因此将u1(t)作为原始数据重复以上步骤对其进行分解,得到第二个PF分量,重复这个过程知道uk为一个单调函数为止,如此便可得到一定数量的PF分量:
最终信号x(t)可表示为k个PF分量和余量之和:
式中,uk(t)为残余函数,代表信号的平均趋势。
S2、对每个PF分量和余量构建各自的训练数据集和测试数据集;
具体为:
PF分量PFk和余量uk的训练数据Trn包含模型的输入数据Xn和输出数据Yn,输入数据和输出数据是对PF分量的时间序列进行连续采集而来,输入数据其中m为预测模型输入个数,输出数据l的取值由预测模型输出个数决定;
PF分量的测试数据集Ten的选取方式与训练数据集Trn的选取方式相同。
S3、对每个PF分量和余量分别建立改进粒子群算法优化神经网络的风速预测模型;
具体为:
1)神经网络包括一个输入层、一个隐含层和一个输出层,输入层神经元个数等于模型输入个数m,输出层神经元个数等于模型输出个数l,隐含层神经元个数a为1~10中的自然数;其中隐含层神经元激活函数使用sigmoid函数,sigmoid函数计算公式为:
输出层神经元激活函数使用线性函数,线性函数计算公式为:
f(x)=w*x+b
其中,w表示隐含层神经元单元到输出层神经元单元的联接权值系数,b表示输出层神经元的阈值。
神经网络需要优化的变量个数为:
num=m×s+s+s×l+l
2)改进粒子群算法优化神经网络过程如下:
随机生成一组粒子作为初始值来拟合改进粒子群算法优化神经网络模型。
i=1,2,...,M
其中,IW为输出层到隐含层权值,有m×s个;Ib为隐含层阈值,有s个;LW为隐含层到输出层权值,有s×l个;Lb为输出层阈值,有l个;M为种群大小,共M个粒子。
用这些粒子探索目标空间,在目标空间的k次迭代中,由分别描述每一个粒子的位置和速度,每个粒子记录下它们最好的位置在k+1次迭代中,粒子的速度由下式得到:
式中,r1、r2和r3分别是0和1之间的随机数,w为惯性权重系数,c1、c2和c3是训练系数,Pgbest为粒子全局最优位置,Pgworst为粒子全局最差位置;
w采用混沌惯性权值,其计算公式如下:
w=wmin+(wmax-wmin)×z(k)
其中,z(k)=μz(k-1)(1-z(k-1)),μ=4,z(1)=0.8,wmax为0.9,wmin为0.4,在每次迭代中,每个粒子的新位置是由它原来位置和它当前的速度相加得到的,如以下公式:
改进粒子群算法优化神经网络的流程图如图3所示。
S4、将训练数据集中全部PF分量和余量的训练样本逐一输入改进粒子群算法优化神经网络的风速预测模型进行训练,针对不同PF分量设定数据输入维数学习反馈机制,得到各自对应的风速预测子模型;
针对不同PF分量设定数据输入维数学习反馈机制具体为:
在模型训练过程中针对每个PF分量进行多次训练,每次训练选取不同的输入维数m(3<m<12),比较维数在3到12维之间时的模型学习效果来选出每个分量最佳的输入维数,采用均方误差公式MSE评价不同输入维数下模型的学习效果,MSE表示如下:
式中,为训练功率输出值;yi为功率实际值;N为样本数。
输入维数学习反馈机制流程图如图4所示。
每次训练结束后比较MSE,选取最佳的输入维数建立风速预测模型。
S5、将测试数据输入到各自对应的风速预测子模型进行预测,得到每个风速子模型的预测输出值;
S6、将每个风速预测子模型的预测输出值进行组合叠加处理,得到最终的风速预测结果。
实验验证:基于局域均值分解和改进粒子群算法优化神经网络的短期风速预测实验
本实验首先建立各分量预测模型EPSO-NN,最后将各分量的预测结果进行累加得到模型最终的总体预测值,并与单独的BP-NN和EPSO-NN模型进行对比。图5为LMD-EPSO-NN的预测效果图。
将单独的神经网络模型(BP-NN)、改进粒子群算法优化神经网络模型(EPSO-NN)和本发明预测模型(LMD-EPSO-NN)做误差对比分析,误差对比如表1所示。其中模型LMD-EPSO-NN(no)是未加入输入维数学习反馈机制的预测模型,LMD-EPSO-NN是加入输入维数学习反馈机制的预测模型。
表1多模型风速预测误差对比
从表1可以看出,从传统的BP-NN神经网络预测,到EPSO-NN改进粒子群算法优化神经网络的预测,再到未加入输入维数学习反馈机制的LMD-EPSO-NN模型预测,最后到加入输入维数学习反馈机制的LMD-EPSO-NN模型预测,模型的预测精度和性能在一步步提高。各个模型的预测结果如图6所示。
综上所述,本发明提出了一种基于局域均值分解和改进粒子群算法优化神经网络的短期风速预测方法,该方法首先针对风速时间序列的非线性和非平稳性,使用局域均值分解将风速时间序列自适应的分解为多个PF分量和一个余量,然后对全部分量分别建立改进粒子群算法优化神经网络的模型进行预测,同时针对各分量不同的特点建立模型输入维数学习反馈机制,有效提高了模型的预测精度和泛化能力,为提高短期风速预测精度提供了一个新的方法。
- 还没有人留言评论。精彩留言会获得点赞!