一种地表可燃物含水率的预测方法及系统、服务器与流程
本发明涉及一种预测方法及系统,特别是涉及一种地表可燃物含水率的预测方法及系统、服务器。
背景技术:
森林火灾是当今世界发生面广、突发性强、破坏性大、处置扑救较为困难的自然灾害。随着全球气候变暖,火灾有上升的趋势。近年来我国特大和重大森林火灾的发生也呈上升趋势。因此,我国森林防火形势一直处于严峻的状态。
森林地表可燃物的含水率是森林火灾发生及蔓延的主要影响因子,也是是森林火险预报的关键参数之一。因此,如何准确地预测森林地表可燃物含水率对预测森林火灾的发生以及森林火灾的扑救防范工作有着重大意义。
地表可燃物含水率受环境条件影响较大。目前,野外气象站布设愈发健全,气象数据精度也在逐渐提高,其适用性广的优势日益凸显,是我国进行可燃物含水率预测的主要方法,所获取的预测值较为准确。但是,该预测方法的工作量大,受地域因素以及可燃物类型的限制导致适用范围有限。
技术实现要素:
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种地表可燃物含水率的预测方法及系统、服务器,基于部署在森林监测区内的多个传感器实时实地所获取的森林环境中的多个参数,利用多传感器信息融合的方法进行森林环境中可燃物含水率的快速预测,且准确度高。
为实现上述目的及其他相关目的,本发明提供一种地表可燃物含水率的预测方法,包括以下步骤:获取作为采集样本的地表可燃物在各个样本周期的地表可燃物含水率;在每个采集样本对应的样本周期,在采集样本所在地表,获取微型气象站实时监测的地表气象数据、红外水分仪实时监测的地表可燃物含水率、以及土壤水分仪实时监测的地表可燃物的温度、地表可燃物含水率和地表下方一定距离处的土壤温度和土壤湿度;以采集样本的含水率为目标属性,基于采集样本所在地表的气象数据、地表可燃物的温度以及地表下方一定距离处的土壤温度和土壤湿度,采用随机森林算法获取地表可燃物含水率的初次预测值;以采集样本的含水率为目标属性,基于地表可燃物含水率的初次预测值、土壤水分仪和红外水分仪获取的地表可燃物含水率的测量值,使用支持向量回归机算法获取地表可燃物含水率的最终预测值。
于本发明一实施例中,所述微型气象站所获取的气象数据包括地表上方一定距离处的空气温度、空气湿度、风速和太阳光照强度,以及地表的降水量。
于本发明一实施例中,通过微型气象站实时获取地表的气象数据还包括对所述微型气象站获取的原始数据进行预处理;所述预处理包括:
a)计算过去一定时间段的总降水量,过去一定时间段的最高气温、最低气温、平均风速
和总降水量,以及过去一定时间段的平均风速、平均湿度、平均光照和平均温度;
b)将光照强度等频划分为若干个区间,确定所获取的光照强度所在区间;
c)将空气湿度等宽离散为若干个区间,确定所获取的空气湿度所在区间;
d)对风速进行分级,确定所获取的风速的级别。
于本发明一实施例中,所述随机森林算法采用怀卡托智能分析环境平台实现,迭代次数为100次,随机种子为1,不进行剪枝处理。
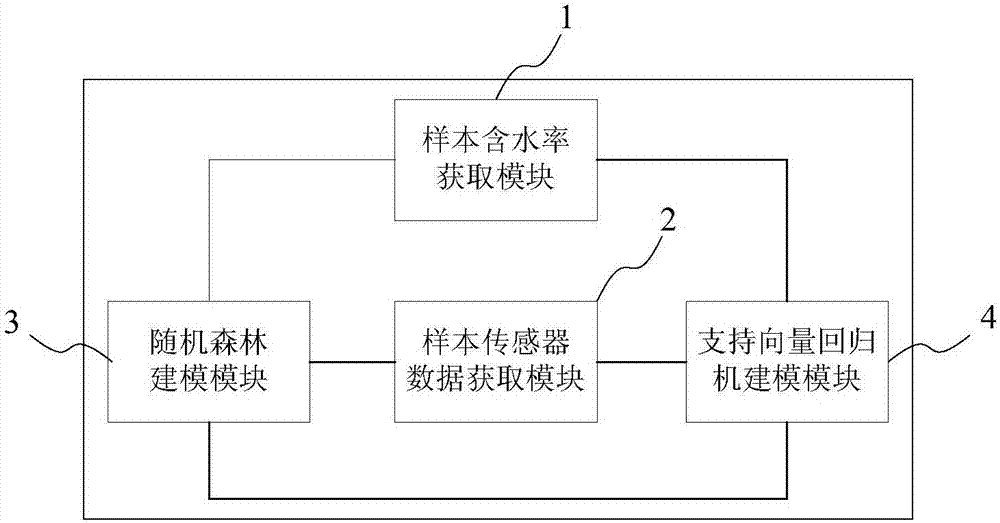
同时,本发明还提供一种地表可燃物含水率的预测系统,包括样本含水率获取模块、样本传感器数据获取模块、随机森林建模模块和支持向量回归机建模模块;
所述样本含水率获取模块用于获取作为采集样本的地表可燃物在各个样本周期的地表可燃物含水率;
所述样本传感器数据获取模块用于在每个采集样本对应的样本周期,在采集样本所在地表,获取微型气象站实时监测的地表气象数据、红外水分仪实时监测的地表可燃物含水率、以及土壤水分仪实时监测的地表可燃物的温度、地表可燃物含水率和地表下方一定距离处的土壤温度和土壤湿度;
所述随机森林建模模块用于以采集样本的含水率为目标属性,基于采集样本所在地表的气象数据、地表可燃物的温度和地表下方一定距离处的土壤温度和土壤湿度,采用随机森林算法获取地表可燃物含水率的初次预测值;
所述支持向量回归机建模模块用于以采集样本的含水率为目标属性,基于地表可燃物含水率的初次预测值、土壤水分仪和红外水分仪获取的地表可燃物含水率的测量值,使用支持向量回归机算法获取地表可燃物含水率的最终预测值。
于本发明一实施例中,所述微型气象站所获取的气象数据包括地表上方一定距离处的空气温度、空气湿度、风速和太阳光照强度,以及地表的降水量。
于本发明一实施例中,通过微型气象站实时获取地表的气象数据还包括对所述微型气象站获取的原始数据进行预处理;所述预处理包括:
a)计算过去一定时间段的总降水量,过去一定时间段的最高气温、最低气温、平均风速和总降水量,以及过去一定时间段的平均风速、平均湿度、平均光照和平均温度;
b)将光照强度等频划分为若干个区间,确定所获取的光照强度所在区间;
c)将空气湿度等宽离散为若干个区间,确定所获取的空气湿度所在区间;
d)对风速进行分级,确定所获取的风速的级别。
于本发明一实施例中,所述随机森林算法采用怀卡托智能分析环境平台实现,迭代次数为100次,随机种子为1,不进行剪枝处理。
另外,本发明还提供一种服务器,包括上述任一的地表可燃物含水率的预测系统。
相应地,本发明还提供一种地表可燃物含水率的预测系统,包括上述的服务器,以及设置在监测区域且与所述服务器通信连接的微型气象站、土壤水分仪和红外水分仪;
所述微型气象站用于实时获取监测区域的地表的气象数据;
所述土壤水分仪用于实时获取监测区域的地表可燃物的温度、地表可燃物含水率和地表下方一定距离处的土壤温度和土壤湿度;
所述红外水分仪用于实时获取监测区域的地表可燃物含水率;
所述服务器用于根据所获取的各个样本周期内采集样本的地表可燃物的含水率,以及微型气象站、土壤水分仪和红外水分仪获取的采集样本的传感数据,预测监测区域的地表可燃物含水率。
如上所述,本发明的地表可燃物含水率的预测方法及系统、服务器,具有以下有益效果:
(1)通过部署在森林监测区内的多个传感器来实时实地来获取森林环境中的多个参数;
(2)利用多传感器信息融合的方法进行森林环境中可燃物含水率的快速预测,实现多传感信息的互补集成,改善不确定环境中的决策过程,提高了地表可燃物含水率的预测精度;
(3)能够方便快捷地对需要监测的目标实行全天候的快速监测。
附图说明
图1显示为本发明的地表可燃物含水率的预测方法的流程图;
图2显示为本发明的地表可燃物含水率的预测系统的一优选实施例的结构示意图;
图3显示为本发明的服务器的结构示意图;
图4显示为本发明的地表可燃物含水率的预测系统的另一优选实施例的结构示意图。
元件标号说明
1样本含水率获取模块
2样本传感器数据获取模块
3随机森林建模模块
4支持向量回归机建模模块
10微型气象站
20土壤水分仪
30红外水分仪
40服务器
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
在本发明的地表可燃物含水率的预测方法及系统、服务器中,可燃物含水率是指可燃物的质量含水率,即可燃物中水分的重量与相应固相物质重量的比值。
多传感器数据融合技术不同于一般信号处理,也不同于单个或多个传感器的监测和测量,而是基于多个传感器测量结果基础上的更高层次的综合决策过程。多传感器数据融合的定义可以概括为:把分布在不同位置的多个同类或不同类传感器所提供的局部数据资源加以综合,采用计算机技术对其进行分析,消除多传感器信息之间可能存在的冗余和矛盾,加以互补,降低其不确实性,获得被测对象的一致性解释与描述,从而提高系统决策、规划、反应的快速性和正确性,使系统获得更充分的信息。其中,信息融合在不同信息层次上出现,包括数据层融合、特征层融合、决策层融合。多传感器数据融合比单一传感器信息有很多优点,如容错性、互补性、实时性、经济性。因此,多传感器数据融合逐步得到推广应用,除军事领域外,已适用于自动化技术、机器人、海洋监视、地震观测、建筑、空中交通管制、医学诊断、遥感技术等方面。
本发明的地表可燃物含水率的预测方法及系统、服务器即基于多传感器数据融合技术来实现的。具体地,本发明的地表可燃物含水率的预测方法及系统、服务器同时接收微型气象站、红外水分仪、土壤水分仪等多种传感数据,并进行融合处理。其中,融合算法选用三层处理结构。第一层对接收到的多种传感数据进行预处理;第二层通过随机森林算法融合第一层的输出,对可燃物含水率进行初步预测;第三层使用支持向量回归机将第二层的输出与红外水份仪、土壤水份仪的可燃物含水率测量值进行融合,从而得到一个综合的地表可燃物含水率的预测结果。
参照图1,本发明的地表可燃物含水率的预测方法包括以下步骤:
步骤s1、获取作为采集样本的地表可燃物在各个样本周期的地表可燃物含水率。
下面通过具体实施例来详述如何获取各个样本周期内,作为采集样本的地表可燃物的含水率。
设定作为采集样本的地表可燃物采集于上海市郊区的一个林场,该林场位于东经121°13′50″,北纬31°23′28″。地表可燃物样本为林下地表的死可燃物,包括枯落物和一年生草本植物。
从2016年5月1日至-2016年6月30日,在上海郊区设置的观测地的观测数据。观测区域为50cm*50cm的区域。设定早、中、晚各为一个时间段来采集地表可燃物作为采集样本,总计获取约200份左右的采集样本。为方便样本测重和尽量减少可燃物的质量损耗,将采集完的样本放入33cm*22.5cm的牛皮纸袋中保存。该牛皮纸袋不吸水,且具有较好的透气性。
样本数据的采集过程如下:
1)样本采集前,使用电子秤称量牛皮纸袋的原质量。
2)在样本采集现场,将采集的样本装入牛皮纸袋中;同时为了防止受样本空气湿度变化的影响,将牛皮纸袋封入塑料密封袋中。
3)将采集完的样本带回实验室;将牛皮纸袋从塑料密封袋中取出,使用电子秤称量内含采集的可燃物样本的牛皮纸袋总质量。
4)将牛皮纸袋放入恒温干燥箱中,在105℃条件下连续烘干12h至干重,取出称牛皮纸袋和内部样本的总干重。
5)将袋中的落叶取出,称量牛皮纸袋经烘干过后的干质量。
6)利用下述公式计算采集样本的可燃物质量含水率:
地表可燃物含水率=((总湿重-原袋重)-(总干重-干袋重))/(总干重-干袋重)*100%
优选地,所述一定时间段可以为连续的时间段,如连续的3小时、4小时,也可以为离散的时间段,如早中晚三个时间段。只要能体现不同状况下的地表可燃物含水率即可。
步骤s2、在每个采集样本对应的样本周期,在采集样本所在地表,获取微型气象站实时监测的地表气象数据、红外水分仪实时监测的地表可燃物含水率、以及土壤水分仪实时监测的地表可燃物的温度、地表可燃物含水率和地表下方一定距离处的土壤温度和土壤湿度。
优选地,土壤水分仪实时获取地表下方10cm处的土壤温度和土壤湿度。土壤水分仪采用fdr土壤水分仪。fdr(frequencydomainreflectometry,频域反射)土壤水分仪是利用电磁脉冲原理,根据电磁波在介质中传播频率来测量土壤的表观介电常数,从而得到土壤容积含水率,具有简便安全、快速准确、定点连续、自动化、宽量程、少标定等优点。
具体地,微型气象站所获取的气象数据包括地表上方一定距离处的空气温度、空气湿度、风速和太阳光照强度,以及地表的降水量。优选地,微型气象站所获取的气象数据包括地表上方20cm处的空气温度、空气湿度、风速和光照强度。
需要说明的是,微型气象站所获取的气象数据和土壤水分仪所获取的地表可燃物的温度、土壤温度和土壤湿度可以是能够直接使用的数据,也可以是原始数据。当微型气象站和土壤水分仪所获取的数据为原始数据时,还需要对原始数据进行预处理,使之成为可以直接使用的数据。
对原始数据的预处理用于计算若干统计量以及对连续属性的光照、风速、湿度进行离散化处理。具体地,预处理包括:
a)计算过去一定时间段,如72小时的总降水量,过去一定时间段,如24小时的最高气温、最低气温、平均风速和总降水量,以及过去一定时间段,如1小时的平均风速、平均湿度、平均光照和平均温度。
b)将光照强度等频划分为若干个区间,如10个区间,确定微型气象站所获取的光照强度所在区间。
c)将空气湿度等宽离散为若干个区间,如10个区间,确定微型气象站所获取的空气湿度所在区间。
d)对风速进行分级,如0-12级,确定微型气象站所获取的风速的级别。
对于本领域技术人员而言,上述预处理过程为数据处理的常用手段,故在此不再赘述。
步骤s3、以采集样本的含水率为目标属性,基于采集样本所在地表的气象数据、地表可燃物的温度和地表下方一定距离处的土壤温度和土壤湿度,采用随机森林算法获取地表可燃物含水率的初次预测值。
随机森林是一种比较新的机器学习模型,其将分类树组合成随机森林,即在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树的结果。随机森林在运算量没有显著提高的前提下提高了预测精度。随机森林对多元公线性不敏感,结果对缺失数据和非平衡的数据比较稳健,可以很好地预测多达几千个解释变量的作用。
具体地,本发明使用怀卡托智能分析环境(waikatoenvironmentforknowledgeanalysis,weka)平台训练随机森林算法模型,具体参数为weka平台提供的随机森林算法的默认参数,即迭代次数为100次,随机种子为1,不进行剪枝处理。
步骤s4、以采集样本的含水率为目标属性,基于地表可燃物含水率的初次预测值、土壤水分仪和红外水分仪获取的地表可燃物含水率的测量值,使用支持向量回归机算法获取地表可燃物含水率的最终预测值。
在机器学习领域,支持向量机(supportvectormachine,svm)是一个有监督的学习模型,通常用来进行模式识别、分类、以及回归分析。svm的主要思想可以概括为以下:1)针对线性可分情况进行分析;对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能;2)基于结构风险最小化理论之上在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界。svm根据应用不同,分为支持向量分类(supportvectorclassification,svc)和支持向量回归(supportvectorregression,svr)。svr主要是通过升维后,在高维空间中构造线性决策函数来实现线性回归。
其中,支持向量回归机算法使用weka算法提供的classifier-functions-smoreg算法,核函数选取的是rbf-kernel,regoptimizer参数选择regsmoimproved,其他参数都使用weka的默认设置。
通过上述步骤,即可基于多传感器信息融合,通过采集样本实现地表可燃物含水率的预测,其能够改善不确定环境中的决策过程,提高了地表可燃物含水率的预测精度;同时通过对需要监测的目标全天候的监测,能够实时获取地表可燃物含水率的预测值,以供生产生活参考。
参照图2,本发明的地表可燃物含水率的预测系统包括样本含水率获取模块1、样本传感器数据获取模块2、随机森林建模模块3和支持向量回归机建模模块4。
样本含水率获取模块1用于获取作为采集样本的地表可燃物在各个样本周期的地表可燃物含水率。
下面通过具体实施例来详述如何获取各个样本周期内,作为采集样本的地表可燃物的含水率。
设定作为采集样本的地表可燃物采集于上海市郊区的一个林场,该林场位于东经121°13′50″,北纬31°23′28″。地表可燃物样本为林下地表的死可燃物,包括枯落物和一年生草本植物。
从2016年5月1日至-2016年6月30日,在上海郊区设置的观测地的观测数据。观测区域为50cm*50cm的区域。设定早、中、晚各为一个时间段来采集地表可燃物作为采集样本,总计获取约200份左右的采集样本。为方便样本测重和尽量减少可燃物的质量损耗,将采集完的样本放入33cm*22.5cm的牛皮纸袋中保存。该牛皮纸袋不吸水,且具有较好的透气性。
样本数据的采集过程如下:
1)样本采集前,使用电子秤称量牛皮纸袋的原质量。
2)在样本采集现场,将采集的样本装入牛皮纸袋中;同时为了防止受样本空气湿度变化的影响,将牛皮纸袋封入塑料密封袋中。
3)将采集完的样本带回实验室;将牛皮纸袋从塑料密封袋中取出,使用电子秤称量内含采集的可燃物样本的牛皮纸袋总质量。
4)将牛皮纸袋放入恒温干燥箱中,在105℃条件下连续烘干12h至干重,取出称牛皮纸袋和内部样本的总干重。
5)将袋中的落叶取出,称量牛皮纸袋经烘干过后的干质量。
6)利用下述公式计算采集样本的可燃物质量含水率:
地表可燃物含水率=((总湿重-原袋重)-(总干重-干袋重))/(总干重-干袋重)*100%
优选地,所述一定时间段可以为连续的时间段,如连续的3小时、4小时,也可以为离散的时间段,如早中晚三个时间段。只要能体现不同状况下的地表可燃物含水率即可。
样本传感器数据获取模块2用于在每个采集样本对应的样本周期,在采集样本所在地表,获取微型气象站实时监测的地表气象数据、红外水分仪实时监测的地表可燃物含水率、以及土壤水分仪实时监测的地表可燃物的温度、地表可燃物含水率和地表下方一定距离处的土壤温度和土壤湿度。
优选地,土壤水分仪实时获取地表下方10cm处的土壤温度和土壤湿度。土壤水分仪采用fdr土壤水分仪。fdr(frequencydomainreflectometry,频域反射)土壤水分仪是利用电磁脉冲原理,根据电磁波在介质中传播频率来测量土壤的表观介电常数,从而得到土壤容积含水率,具有简便安全、快速准确、定点连续、自动化、宽量程、少标定等优点。
具体地,微型气象站所获取的气象数据包括地表上方一定距离处的空气温度、空气湿度、风速和太阳光照强度,以及地表的降水量。优选地,微型气象站所获取的气象数据包括地表上方20cm处的空气温度、空气湿度、风速和光照强度。
需要说明的是,微型气象站所获取的气象数据和土壤水分仪所获取的地表可燃物的温度、土壤温度和土壤湿度可以是能够直接使用的数据,也可以是原始数据。当微型气象站和土壤水分仪所获取的数据为原始数据时,还需要对原始数据进行预处理,使之成为可以直接使用的数据。
对原始数据的预处理用于计算若干统计量以及对连续属性的光照、风速、湿度进行离散化处理。具体地,预处理包括:
a)计算过去一定时间段,如72小时的总降水量,过去一定时间段,如24小时的最高气温、最低气温、平均风速和总降水量,以及过去一定时间段,如1小时的平均风速、平均湿度、平均光照和平均温度。
b)将光照强度等频划分为若干个区间,如10个区间,确定微型气象站所获取的光照强度所在区间。
c)将空气湿度等宽离散为若干个区间,如10个区间,确定微型气象站所获取的空气湿度所在区间。
d)对风速进行分级,如0-12级,确定微型气象站所获取的风速的级别。
对于本领域技术人员而言,上述预处理过程为数据处理的常用手段,故在此不再赘述。
随机森林建模模块3与样本含水率获取模块1和样本传感器数据获取模块2分别相连,用于以采集样本的含水率为目标属性,基于采集样本所在地表的气象数据、地表可燃物的温度和地表下方一定距离处的土壤温度和土壤湿度,采用随机森林算法获取地表可燃物含水率的初次预测值。
随机森林是一种比较新的机器学习模型,其将分类树组合成随机森林,即在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树的结果。随机森林在运算量没有显著提高的前提下提高了预测精度。随机森林对多元公线性不敏感,结果对缺失数据和非平衡的数据比较稳健,可以很好地预测多达几千个解释变量的作用。
具体地,本发明使用怀卡托智能分析环境(waikatoenvironmentforknowledgeanalysis,weka)平台训练随机森林算法模型,具体参数为weka平台提供的随机森林算法的默认参数,即迭代次数为100次,随机种子为1,不进行剪枝处理。
支持向量回归机建模模块4与样本含水率获取模块1、样本传感器数据获取模块2和随机森林建模模型3分别相连,用于以采集样本的含水率为目标属性,基于地表可燃物含水率的初次预测值、土壤水分仪和红外水分仪获取的地表可燃物含水率的测量值,使用支持向量回归机算法获取地表可燃物含水率的最终预测值。
在机器学习领域,支持向量机(supportvectormachine,svm)是一个有监督的学习模型,通常用来进行模式识别、分类、以及回归分析。svm的主要思想可以概括为以下:1)针对线性可分情况进行分析;对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能;2)基于结构风险最小化理论之上在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界。svm根据应用不同,分为支持向量分类(supportvectorclassification,svc)和支持向量回归(supportvectorregression,svr)。svr主要是通过升维后,在高维空间中构造线性决策函数来实现线性回归。
其中,支持向量回归机算法使用weka算法提供的classifier-functions-smoreg算法,核函数选取的是rbf-kernel,regoptimizer参数选择regsmoimproved,其他参数都使用weka的默认设置。
如图3所示,本发明还公开一种服务器,包括上述地表可燃物含水率的预测系统。
如图4所示,本发明还公开一种地表可燃物含水率预测系统,包括设置在监测区域的微型气象站10、土壤水分仪20和红外水分仪30,以及上述服务器40。服务器40与微型气象站10、土壤水分仪20和红外水分仪30分别通信连接。
微型气象站10用于实时获取监测区域的地表的气象数据。
土壤水分仪20用于实时获取监测区域的地表可燃物的温度、地表可燃物含水率和地表下方一定距离处的土壤温度和土壤湿度。
红外水分仪30用于实时获取监测区域的地表可燃物含水率。
服务器40用于根据所获取的各个样本周期内采集样本的地表可燃物的含水率,以及微型气象站10、土壤水分仪20和红外水分仪30获取的采集样本的传感数据,预测监测区域的地表可燃物含水率。
优选地,服务器40与微型气象站10、土壤水分仪20和红外水分仪30分别通过wifi、蓝牙、zigbee方式中的一种或多种组合通信连接。
综上所述,本发明的地表可燃物含水率的预测方法及系统、服务器通过部署在森林监测区内的多个传感器来实时实地来获取森林环境中的多个参数;利用多传感器信息融合的方法进行森林环境中可燃物含水率的快速预测,实现多传感信息的互补集成,改善不确定环境中的决策过程,提高了地表可燃物含水率的预测精度;能够方便快捷地对需要监测的目标实行全天候的快速监测。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!