一种用于核电厂DCS系统的基于FPGA的DMA协处理器及方法与流程
本发明涉及一种协处理器设计,具体涉及一种用于核电厂dcs系统的基于fpga的dma协处理器及其方法。
背景技术:
在核电厂中,应用dcs将现场的信息通过计算机网络连到电厂的控制系统,从而使得电厂操作人员通过dcs对全厂各个部分的设备进行集中监视、控制与管理。同时使生产运行、管理、维修、安全保卫、计划调度及行政等部门都可以及时有效地获得并利用这些信息,实现全厂信息共享,极大地提高了核电厂运行的管理效率。由此可见,这个作为电厂“大脑”和“神经系统”的科学管理系统是主线工作的关键因素,安全级显示单元是核电厂dcs平台的重要组成部分,用于实现现场数据显示及控制输入。安全级显示单元中存在较多的图形显示需求。目前,较为普遍的图形显示是由cpu直接驱动相关的显示设备来实现。在核电厂安全级dcs平台下,安全显示站主控制cpu需要完成较多任务,而图形显示由于数据量大,严重占用cpu时间,导致系统的实时性降低,图形显示效果差,难以满足核电厂dcs平台的要求。
所以急需设计一种能有效地提高系统实时性能和图形显示效果的协处理器及其方法。
技术实现要素:
本发明所要解决的技术问题是有效地提高系统实时性能和图形显示效果,目的在于提供一种用于核电厂dcs系统的基于fpga的dma协处理器,解决有效地提高系统实时性能和图形显示效果的问题。
本发明通过下述技术方案实现:
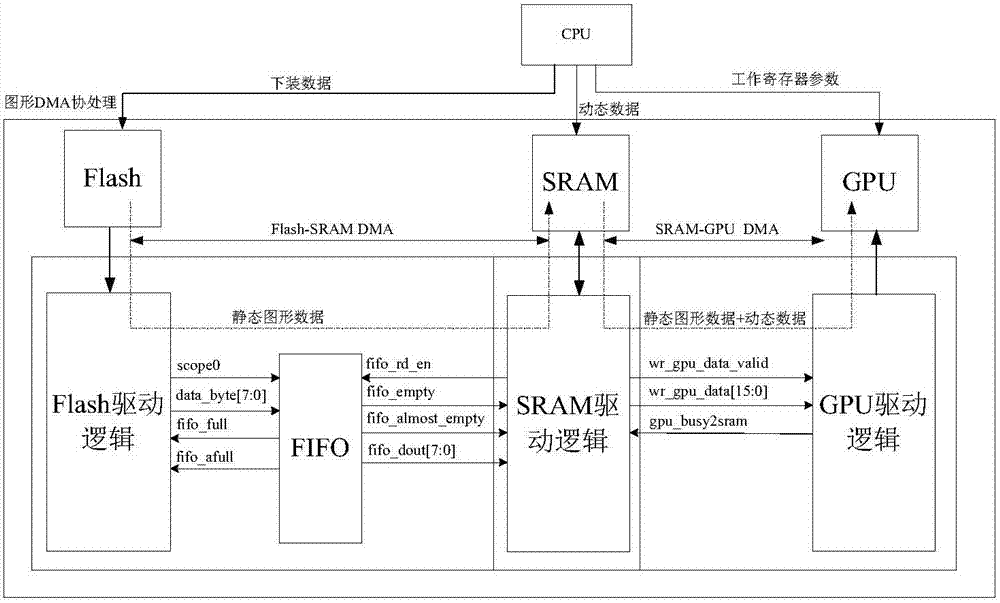
一种用于核电厂dcs系统的基于fpga的dma协处理器,包括cpu,cpu通过emif总线与dma协处理器互联,dma协处理器通过另外两组emif总线分别与flash,sram和gpu连接,其中flash和gpu存储设备共享地址总线和数据总线。dma协处理器利用其io端口配置灵活的优点,扩展出来两组emif总线,分别用于连接flash,sram和gpu。基于本发明的dma协处理器,由于fpga具有比基于cpu的软件更高效的时序控制机制,使得图形显示的刷新速度和刷新效果得到了显著提升。同时,dma协处理器与主cpu并行执行,使主cpu减少了在图形显示方面的时间开销,提高了主cpu响应其他事务的能力,系统实时性得到提高,解决了需要有效地提高系统实时性能和图形显示效果这一问题。
所述cpu对dma协处理器发出dma指令,并同时以透传的方式,将上层软件的图形组态数据下装到flash;将动态数据写入sram;在上电初始化后配置gpu的工作参数。运行过程中,dma协处理器根据主cpu的dma指令,将flash中存储的静态图形数据复制到sram,然后主cpu将动态数据写入sram。动态数据和静态图形数据在sram中合成后,dma协处理器再次根据主cpu的dma指令将sram中的数据复制到gpu中,实现图形显示更新。
所述dma协处理器:包括flash驱动逻辑、sram驱动逻辑、gpu驱动逻辑、数据缓存逻辑以及总线切换逻辑,通过emif总线切换为cpu提供访问flash、sram或gpu的通道。上层软件的数据单元可能是8位或16位。外部存储设备按照16位访问的效率最高。flash到gpu的数据复制中,如果上层软件的数据单元为8位,由于dma源地址和目的地址以及dma数据长度的原因,可能会造成无法使用16位数据宽度执行dma。本发明设计的dma协处理器克服了这个问题,使得无论上层软件的数据单元是8位还是16位,dma协处理器均按照16位宽度执行dma,提高了dma协处理器的兼容性和速度。
所述flash驱动,接收来自cpu的dma指令,并按照dma指令读取flash内部数据,写入数据宽度为8的fifo缓存。dma指令包括flash读起始字节地址、需要读取flash的字节数。接收到dma启动指令后,flash驱动首先将dma的字节起始地址addr_first、字节数addr_num通过换算,计算出实际读flash使用的起始字地址addr_flash_start、结束字地址addr_flash_end、页地址计数器初始值addr_flash_page、结束页地址addr_flash_page_end。参数换算如下表所示:
flash驱动逻辑通过流水线的方式将读flash数据与数据拆分缓存到fifo并行起来。scope0是fifo的写使能,data_byte是fifo数据输入端口,addr_flash_offset是flash的页内偏移地址,fpga总是以页地址为单位读取flash。当起始字地址的页内偏移地址不为0时,fpga仍然需要从页内偏移地址为0的地址空间开始读数据,起始字地址之前读取出来的数据不会被存储到fifo缓存中;当结束字地址的页内偏移地址不为0时,fpga仍然需要读取结束地址后的数据,直到页内偏移地址为0,结束字地址-1之后读取出来的数据不会被存储到fifo缓存中。从flash读取出来的数据是16位,实际存储过程中按照下表奇偶特殊处理方法执行存储操作。
所述sram驱动与flash驱动配合完成flash内部图形数据复制到sram内部,与gpu驱动配合完成将sram内部数据复制到gpu。sram写逻辑执行流程:将接收到的dma指令如写起始字节地址waddr_first_fpga、写字节数waddr_num_fpga换算为sram写操作的物理起始字地址waddr_first_fpga,字长度waddr_num_fpga。根据写起始字地址和写字长度,通过下表的参数换算方式计算出结束字地址waddr_end_fpga。
sram驱动判断flash驱动输出的fifo状态非空时,从fifo中读取数据。通常情况下,每次写sram,需要连续读取2次fifo,将fifo输出数据合并为1个16位数据写入sram存储器。写sram驱动时序如图6所示。需要奇偶特殊处理的如下表所示。
所述gpu驱动,将sram驱动传来的数据按照gpu的操作时序,写入gpu的存储器。空闲时,gpu驱动处于等待状态,当sram驱动传输过来的wr_gpu_data_valid有效时,启动写gpu,经过7个时钟周期完成写操作。
一种用于核电厂dcs系统的基于fpga的dma协处理器数据处理的方法,包括以下步骤,步骤1,将flash中存储的静态图形数据复制到sram,dma协处理器根据cpu的dma指令,按照dma指令读取flash内部数据,写入数据宽度为8的fifo缓存,sram驱动判断flash驱动输出的fifo状态非空时,从fifo中读取数据,将fifo输出数据合并为1个16位数据写入sram存储器;步骤2,cpu将动态数据写入sram,将接收到的dma指令写起始字节地址waddr_first_fpga、写字节数waddr_num_fpga换算为sram写操作的物理起始字地址waddr_first_fpga,字长度waddr_num_fpga。根据写起始字地址、写字长度计算出结束字地址waddr_end_fpga;步骤3,动态数据和静态图形数据在sram中合成,fifo_dout为缓存flash静态图形数据的fifo输出数据信号,通过构建写sram流水线的方式,在一个标准的sram写周期内,实现了连续读取1或2次fifo,并将1或2次获取的fifo输出数据合并后写入sram的操作合成;步骤4,dma协处理器再次根据,cpu的dma指令将sram驱动与gpu驱动配合完成将sram内部合成的图形数据复制到gpu中,实现图形显示更新。所述步骤4中,sram驱动通过插入等待周期,实现与gpu的速率匹配。
本发明与现有技术相比,具有如下的优点和有益效果:
1、本发明一种用于核电厂dcs系统的基于fpga的dma协处理器及其方法,dma协处理器与主cpu配合完成图形显示。通过这种机制,提高了图形显示控制速度,提高了显示效果,节约了主cpu时间,提升了核电厂安全级dcs系统的安全显示单元的实时性能;
2、本发明一种用于核电厂dcs系统的基于fpga的dma协处理器及其方法,用fpgaio管脚多、配置灵活的特点,dma协处理器扩展了图形显示中需要的外部存储设备控制、数据、地址总线,降低了对主cpu的io及总线资源的要求;
3、本发明一种用于核电厂dcs系统的基于fpga的dma协处理器及其方法,通过流水线等手段,在现有硬件平台的基础上,具有较高的数据吞吐量。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:
图1为本发明图形显示整体架构示意图;
图2为本发明dma协处理器实施功能图示意图;
图3为本发明读flash时序控制状态机示意图;
图4为本发明dma读flash时序示意图;
图5为本发明sram驱动状态机示意图;
图6为本发明写sram驱动时序示意图;
图7为本发明读sram,写gpu流水线示意图
图8为本发明写gpu状态机示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
实施例
如图1-8所示,本发明一种用于核电厂dcs系统的基于fpga的dma协处理器及其方法,dma协处理器包括cpu,cpu通过emif总线与dma协处理器互联,dma协处理器通过另外两组emif总线分别与flash,sram和gpu连接,其中flash和gpu存储设备共享地址总线和数据总线。所述cpu对dma协处理器发出dma指令,并同时以透传的方式,将上层软件的图形组态数据下装到flash;将动态数据写入sram;在上电初始化后配置gpu的工作参数。所述dma协处理器:包括flash驱动逻辑、sram驱动逻辑、gpu驱动逻辑、数据缓存逻辑以及总线切换逻辑,通过emif总线切换为cpu提供访问flash、sram或gpu的通道。所述flash驱动,接收来自cpu的dma指令,并按照dma指令读取flash内部数据,写入数据宽度为8的fifo缓存。flash驱动逻辑通过流水线的方式将读flash数据与数据拆分缓存到fifo并行起来。所述sram驱动与flash驱动配合完成flash内部图形数据复制到sram内部,与gpu驱动配合完成将sram内部数据复制到gpu。所述gpu驱动,将sram驱动传来的数据按照gpu的操作时序,写入gpu的存储器。fifo_dout为缓存flash静态图形数据的fifo输出数据信号。通过构建写sram流水线的方式,在一个标准的sram写周期内,实现了连续读取2次fifo个别情况是只读1次fifo,并将2次获取的fifo输出数据合并后写入sram的操作。sram驱动还需要与gpu驱动配合完成将sram内部合成的图形数据复制到gpu中实现图形显示更新。读sram,写gpu按照图所示的流水线执行。sram驱动通过插入等待周期,实现与gpu的速率匹配。gpu驱动负责将来自sram驱动的数据按照gpu的操作时序写入gpu的存储器中。包括以下步骤,步骤1,将flash中存储的静态图形数据复制到sram,dma协处理器根据cpu的dma指令,按照dma指令读取flash内部数据,写入数据宽度为8的fifo缓存,sram驱动判断flash驱动输出的fifo状态非空时,从fifo中读取数据,将fifo输出数据合并为1个16位数据写入sram存储器;步骤2,cpu将动态数据写入sram,将接收到的dma指令写起始字节地址waddr_first_fpga、写字节数waddr_num_fpga换算为sram写操作的物理起始字地址waddr_first_fpga,字长度waddr_num_fpga。根据写起始字地址、写字长度计算出结束字地址waddr_end_fpga;步骤3,动态数据和静态图形数据在sram中合成,fifo_dout为缓存flash静态图形数据的fifo输出数据信号,通过构建写sram流水线的方式,在一个标准的sram写周期内,实现了连续读取1或2次fifo,并将1或2次获取的fifo输出数据合并后写入sram的操作合成;步骤4,dma协处理器再次根据,cpu的dma指令将sram驱动与gpu驱动配合完成将sram内部合成的图形数据复制到gpu中,实现图形显示更新,sram驱动通过插入等待周期,实现与gpu的速率匹配空闲时,gpu驱动处于等待状态,当sram驱动传输过来的wr_gpu_data_valid有效时,启动写gpu,经过7个时钟周期完成写操作。写gpu状态机如图所示。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!