信息智能检索系统的检索方法与流程
本发明涉及一种检索方法,具体涉及一种信息智能检索系统及检索方法,属于信息检索技术领域。
背景技术:
随着计算机技术、网络技术和通信技术的发展和应用,各行各业信息化也得到了突飞猛进的发展。近年来,随着大量的信息化系统的建设,系统存储的数据量以几何级开始增长。如何在庞大的信息中快速、精确地检索数据,已经成为信息化发展的重点,建全信息智能检索能够有效地满足这个需求。
建立一个全文检索系统,首先要将源文档转化为能够进行文本查找的全文数据库,包括全文的分割处理以及检索标识的提取,称为全文本的前处理工作。众所周知,英文是以词为单位的,单词之间以空格分割,而中文是字的序列,词与词之间没有间隔标记,使得词的界定缺乏自然标准。而“词”又是自然语言处理的一个基本单位,是最小的能够独立活动的有意义的语言成分。显而易见,自动识别词的边界,将书面汉字序列切分成正确的词串的中文分词问题,无疑是实现中文信息处理的首要问题。
同时,传统数据库的大数据检索,效率受限于磁盘io读写和传统数据库的框架,不能实现大数据量下的快速的检索。因此,迫切的需要一种新的方案解决该技术问题。
技术实现要素:
本发明正是针对现有技术中存在的技术问题,提供一种信息智能检索系统的检索方法,本发明实现自然语言处理分词,建立索引实现基于大数据量下的全文检索,对所需信息进行搜索内容快速匹配。
为了实现上述目的,本发明的技术方案如下,一种信息智能检索系统的检索方法,其特征在于,所述方法如下,1)平台系统首先从数据采集节点通过日志传输系统采集数据2)将采集的数据通过调取hadoopapi传入hadoop大数据集群的hdfs分布式文件存储存3)然后根据平台相关业务确定好词典,通过平台的接口进行定时处理,将hdfs存储的元数据进行预处理,清洗无意义的数据和因编码格式产生的中文乱码,4)在此基础上,根据词典的词元分词,将词进行倒排序,进行数据分片,分布式存储在集群磁盘中,形成索引,使得数据能够进行全文检索。所述通过存储在hdfs上的的信息数据,进行数据清洗,预处理,然后导入进信息智能检索平台,平台中现在有10亿条数据,能做到毫秒级的相应,对地址姓名等能做到模糊查询和关键字匹配。同时平台在舆情搜索中也有应用。
作为本发明的一种改进,所述步骤3)中需要进行分词处理,所述分词处理使用了“正向迭代最细粒度切分算法”,简单说来就是:segmenter会逐字识别加载在内存中的字典词元,从中选取最优的方案,其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典,若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来;如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理……;如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止,这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。上述技术方案中,在海量数据的信息中,进行毫秒级全文检索匹配,并返回相应的检索、分析结果。信息的内容很长很杂,搜索输入的内容可能没有连续性,传统数据库无法实现。需要从中提取关键字,进行关键字的倒排序和分类,以实现快速的检索匹配。因为信息的数据量很大,数据在hdfs进行分布式存储。需要先从hdfs存储中读取相应的数据进行转换,将数据导入智能检索平台进行存储转换。内存和磁盘需要进行充分使用,尽可能减少传统数据库或者检索中磁盘io所造成的性能瓶颈。
相对于现有技术,本发明具有如下优点,1)索引文件格式独立于应用平台,信息智能检索定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件;2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。对亿级别的海量数据能做到毫秒级的响应。查询实现中默认实现了布尔操作、模糊查询(fuzzysearch[11])、分组查询等等;3)能够有效的将hdfs数据清洗预处理,导入信息搜索平台,保证数据的准时实现。
附图说明
图1为倒排序原理图;
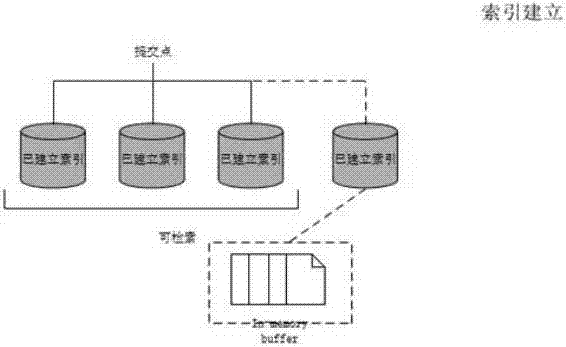
图2为索引建立示意图;
图3、图4为分词转换过程示意图;
图5为整个检索过程示意图。
具体实施方式:
为了加深对本发明的理解,下面结合附图对本实施例做详细的说明。
实施例1:参见图,5,一种信息智能检索系统的检索方法,所述方法如下,1)平台系统首先从数据采集节点通过日志传输系统采集数据2)将采集的数据通过调取hadoopapi传入hadoop大数据集群的hdfs分布式文件存储存3)然后根据平台相关业务确定好词典,通过平台的接口进行定时处理,将hdfs存储的元数据进行预处理,清洗无意义的数据和因编码格式产生的中文乱码,4)在此基础上,根据词典的词元分词,将词进行倒排序,进行数据分片,分布式存储在集群磁盘中,形成索引,使得数据能够进行全文检索。所述通过存储在hdfs上的的信息数据,进行数据清洗,预处理,然后导入进信息智能检索平台,平台中现在有10亿条数据,能做到毫秒级的相应,对地址姓名等能做到模糊查询和关键字匹配。同时平台在舆情搜索中也有应用。
参见图3,所述步骤3)中需要进行分词处理,所述分词处理使用了“正向迭代最细粒度切分算法”,简单说来就是:segmenter会逐字识别加载在内存中的字典词元,从中选取最优的方案,其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典,若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来;如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理……;如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止,这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。
在传统的数据库中,一个字段存一个值,但是这对于全文搜索是不足的。想要让文本中的而每个单词都可以被搜索,这意味着数据库需要多个值。支持一个字段多个值的最佳数据结构是倒排索引。倒排索引包含了出现在所有文档中唯一的值或或词的有序列表,以及每个词所属的文档列表,如图1,因为数据实时性,需要保证索引的动态更新。所以设计了使用不只一个的索引。新添额外的索引来反映新的更改来替代重写所有倒序索引。所以引入了per-segment搜索的概念一个segment是一个完整的倒序索引的子集,索引是一个segments的集合,每个segment都包含一些提交点新的文档建立时首先在内存建立索引buffer。然后再被写入到磁盘的segment。如图2。我们要找概率最大的分词结构的话,可以看做是一个动态规划问题,也就是说,要找整个句子的最大概率结构,对于其子串也应该是最大概率的。
对于句子任意一个位置t上的字,我们要从词典中找到其所有可能的词组形式,如上图中的第一个字,可能有:中、中国、中国人三种组合,第四个字可能只有民,经过整理,我们的分词结构可以转换成以下的有向图模型,如图4写的定时任务,调用hdfs接口,从hdfs到处数据,预处理数据,进行乱码、无意义字符清洗,导入到信息智能搜索中。
需要说明的是上述实施例,并非用来限定本发明的保护范围,在上述技术方案的基础上所作出的等同变换或替代均落入本发明权利要求所保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!