用于在计算机处理器中调度指令的方法和系统与流程
背景技术:
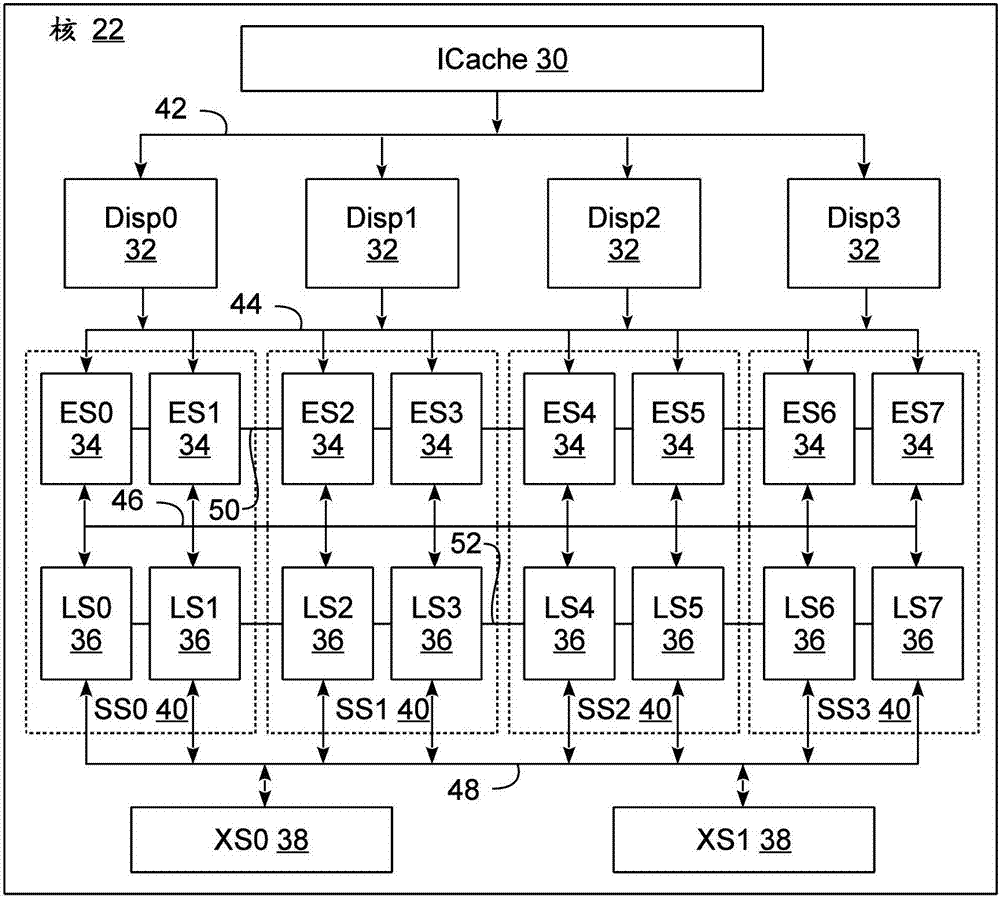
:本发明总体上涉及数据处理,并且具体涉及在计算机处理器中调度指令。随着半导体技术继续逐渐更接近在时钟速度的增加方面的实际限制,架构师越来越关注处理器架构中的并行化以获得性能提升。在芯片级别,多个处理器核通常被设置在同一芯片上,以与分离的处理器芯片大致相同的方式进行工作,或者在某种程度上,以与完全分离的计算机大致相同的方式进行工作。此外,即使在核内,并行化通过专用于处理某些类型的操作的多执行单元的使用而被采用。管线化(pipelining)在很多情况下也被采用,以使得可能花费多个时钟周期来执行的某些操作被分成多个阶段,使能其他操作在更早的操作完成之前开始。多线程化(multithreading)也被采用,以使得多个指令流被并行地执行,使能更多的总体工作在任何给定时钟周期中被执行。在一些已有设计中,具体的资源和管线通常被分派用于不同指令流的执行,而且多个管线允许程序执行甚至在一条管线忙碌的情况下可以继续。然而,资源可能仍然被捆绑到忙碌的管线,并且当被分配给指令流的所有(多个)管线都忙碌时,该指令流可能变得停滞,降低了处理器核的潜在吞吐量。技术实现要素:在根据本发明的某些实施例中,一种电路布置包括:多个可以动态组合的并行执行片段(slice),被配置为执行来自一个或多个指令流的指令,调度逻辑,被耦合到多个执行片段并且被配置为向多个执行片段调度来自一个或多个指令流的指令的逻辑,以及多个第一指令端口,分别被设置在多个执行片段中并且被配置为从调度逻辑接收具有多达n个源操作数(operand)的指令。多个执行片段中的第一执行片段包括第二指令端口和发出逻辑(issuelogic),第二指令端口被配置为从调度逻辑接收补充指令,发出逻辑被耦合到第一执行片段的第二指令端口和相应第一指令端并且被配置为当在调度周期期间在第一指令端口和第二指令端口两者处接收到指令时,将把从多个第一指令端口中的至少一个接收到的至少一个源操作数用作在第二指令端口处接收到的指令的源操作数的两个指令排队。此外,调度逻辑被进一步配置为在第一调度周期期间,通过向多个第一指令端口中的至少一个传送针对补充指令的至少一个源操作数,来在将多个指令调度给多个执行片段中的相应第一指令端口的同时选择性地将补充指令调度给第二指令端口。此外,在根据本发明的某些实施例中,一种电路布置包括:多个可动态组合的并行执行片段,被配置为执行来自一个或多个指令流的指令,多个执行片段被配置为以包括至少第一线程模式和第二线程模式的多个线程模式操作,第一线程模式和第二线程模式分别支持第一数目的硬件线程和第二数目的硬件线程;以及调度逻辑,被耦合到多个执行片段并且被配置为向多个执行片段调度来自一个或多个指令流的指令。当多个执行片段正以第一线程模式操作时,调度逻辑被配置为向多个执行片段中的每一个调度指令以用于在第一数目的硬件线程中的执行;并且当多个执行片段正以第二线程模式工作时,调度逻辑被配置为向多个执行片段中的第一子集调度与第二数目的硬件线程的第一子集中的任何硬件线程相关联的指令以及向多个执行片段中的第二子集调度与第二数目的硬件线程的第二子集中的任何硬件线程相关联的指令。一些实施例也可以包括结合任何前述概念的方法、集成电路芯片、设备、系统和/或程序产品。表征了本发明的这些和其他的优点和特征被阐述在本文所附并构成本文一部分的权利要求中。然而,为了更好的理解本发明以及通过其使用所达到的优点和目标,应当参考附图和所附描述性内容,其中描述了本发明的示例实施例。附图说明图1是示出本文所公开的各种技术可以被实践在其中的示例数据处理系统的框图。图2是示出图1中所引用的处理器核之一的示例实施方式的进一步细节的框图。图3是示出图2的处理器核的示例指令调度的框图。图4是示出图2的处理器核的另一示例指令调度的框图。图5是示出图2的处理器核的附加细节的框图。图6是示出在图2的处理器核中的执行/高速缓存片段对之一的示例实施方式的框图。图7是示出示图6中引用的调度路径网络的示例实施方式的一部分的框图。图8是示出图2的处理器核中的补充指令调度的框图。图9是示出图2的处理器核中以smt2模式的寄存器克隆的框图。图10是示出在图2的处理器核中以smt4模式的寄存器克隆的框图。具体实施方式在根据本发明的实施例中,旋转调度(rotationaldispatch)可以被用于将指令从一个或多个指令流调度给能够被任意分配用于执行指令的多个执行片段,例如,当执行流的当前指令的片段为忙碌时,其中片段能够被实时组合以执行较宽的指令或需要多个片段来处理多个数据的单指令多数据(simd)指令,等等。在某些情况下,补充指令调度可以被用于调度附加的指令(被称为补充指令)到执行片段的补充指令端口并且使用一个或多个执行片段的主指令端口为这样的补充指令供应一个或多个源操作数。此外,在某些情况下,取代附加指令调度或除了附加指令调度之外,选择性片段划分也可以被用于基于这样的执行片段正在其中执行的线程模式来选择性地划分执行片段的组。在所示出的实施例中的并行片段处理器核可以被认为是实现多个可动态组合的执行片段的处理器核,这些多个可动态组合的执行片段通常可以被任意分配用于执行各种类型的指令并且可以被动态地(即,即时)组合用于执行多宽度指令或单指令多数据(simd)指令中的一者或两者,simd指令包括要由同一指令处理的多个数据值。在某些实施方式中,对指令的任意分配到执行片段的支持可以使得来自特定指令流的指令在处理该指令流的不同执行片段忙碌时可以被路由到不同的执行片段,同时对多宽度和/或simd指令的支持增强了处理不同类型的工作负载的灵活性和通用性,例如,生产力工作负载、图形工作负载、科学工作负载、网络工作负载等。对所示实施例的多种变化和修改对于本领域技术人员来说将是清楚的。因此,本发明不限于本文所讨论的具体实施方式。硬件和软件环境现在转向附图,其中贯穿多个视图,相同附图标记表示相同部分,图1示出了根据本发明某些实施例的示例数据处理系统10。数据处理系统10包括一个或多个处理器12,一个或多个处理器12经由一个或多个通信路径20被耦合到各种附加组件,诸如系统存储器(memory)14、输入/输出(i/o)16以及储存器(storage)18,一个或多个通信路径20例如使用一个或多个总线、网络、互连等而被实现。每个处理器12可以包括一个或多个处理器核22和本地储存器24,例如,包括内部系统存储器和/或一个或多个级别的高速缓存存储器。在某些实施例中,每个处理器12可以被类似地配置,而在其他实施例中不同配置的处理器可以一起被使用。此外,在多核处理器实施方式中,每个核22可以与同一个处理器12中的其他核22类似或不同地被配置。将理解,被发明可以以各种各样的系统配置而被利用,包括单处理器和/或多处理器配置,以及单核和/或多核配置。此外,本发明可以在各种类型的专用处理器中被利用,例如,图形处理器、网络处理器、协处理器、服务处理器、嵌入式处理器等。在某些实施例中,系统存储器14可以包括表示该系统的主要易失性储存的随机访问存储器(ram)。此外,在某些实施例中,可以支持单个系统存储器14,而在其他实施例中,存储器可以被分布在多个节点,其中一个或多个处理器12被实现在每个节点内并且对该系统中的相同或不同节点上的存储器部分具有非均匀存储器访问。节点也可以被布置成各种层级,例如,在不同的机柜、机架、卡、插槽等内,并且经由高速网络互连。系统10也可以包括各种输入/输出(i/o)接口和设备16,其可以基于系统的类型而变化。例如,在某些系统中,i/o16可以包括到一个或多个外部网络的适配器和/或接口,诸如专用网络、公共网络、有线网络、无线网络等。此外,对于诸如台式计算机、膝上型计算机、平板电脑、移动设备等的单用户系统,i/o16还可以包括用户输入设备,诸如鼠标、键盘、触摸屏、麦克风、成像设备等,以用于接收用户输入和图像显示和/或音频播放设备以播放信息。系统10也可以包括储存子系统18,其可以包括诸如固态磁盘驱动器,硬盘驱动器之类的不可拆卸的大容量储存驱动器和诸如闪存驱动器、光驱动器之类的可拆卸驱动器,可拆卸驱动器可以例如被用于读取存储在诸如光盘26的计算机可读介质上的程序代码和/或数据。示例程序代码28例如被图示在存储器24中,示例程序代码28可以表示可以由处理器12的核22执行的各种类型的指令,包括例如用户级应用、操作系统、固件、中间件、设备驱动器、虚拟化程序代码等。将理解,程序代码28有时也可以被存储在其他计算机可读介质中,包括各种类型的非易失性或易失性存储器,诸如高速缓存存储器、系统存储器、外部储存装置、可拆卸介质等。虽然图1中的系统被用于提供本发明的处理器架构可以被实现在其中的系统的说明,要理解,所描述的架构并非限制性的并且旨在提供本文公开的各种技术可以被应用在其中的合适计算机系统的示例。此外,将理解,本文所描述的技术可以被实现在电路布置内,该电路布置通常表示物理设备或系统(例如,一个或多个集成电路设备/芯片、卡、板、组件、系统等),该物理设备或系统包括被配置为实现这样的技术的硬件并且在某些情况下包括软件。此外,还将理解,利用本文描述的技术的实施方式可以至少部分以程序产品的形式被分布,该程序产品包括定义电路布置并且被存储在计算机可读介质上的逻辑定义代码,并且本发明同等适用而不管用于实际执行该分布的计算机可读介质的具体类型如何。逻辑定义程序代码例如可以包括通用门级网表(genericgatenetlist),可合成形式(synthesizableform),例如以诸如verilog或vhdl之类的硬件描述语言,诸如gdsii之类的更低级物理描述,或能够定义所制造的电路布置的功能和/或布局的各种级别的细节的其他类型程序代码。计算机可读介质的示例包括但不限于非暂态、物理、可记录型介质,诸如易失性或非易失性存储器设备、软盘、硬盘驱动器、cd-rom和dvd(除其他之外)。现在参见图2,图1的处理核22的示例实施方式的细节被图示。处理器核22可以包括指令高速缓存(icache)30,其存储从高阶高速缓存或系统存储器中获取的多个指令流并且将(多个)指令流给予多个调度队列(disp0-dips3)32。处理器核22内的控制逻辑控制从调度队列32到多个执行片段(es0-es7)34的调度,这些执行片段(es0-es7)34被耦合到多个加载/存储片段(ls0-ls7)36(本文中也被称为高速缓存片段),这些加载/存储片段(ls0-ls7)36进而被耦合到多个转译片段(xs0-xs1)38,多个转译片段(xs0-xs1)38提供对可以被集成在处理器核22中或外部的下一更高阶级别的高速缓存或系统存储的访问。在某些实施例中,两对或更多对相关联的执行片段34以及高速缓存片段36的集合可以被逻辑地耦合在一起成为超片段(superslice)(例如,ss0-ss3)40,例如用以支持多宽度指令和/或simd指令。然而,在其他实施例中,可以不支持这样的逻辑耦合。执行片段34经由允许指令从任何调度队列32到任何执行片段34的调度路由网络44被耦合到调度队列32,尽管完整的交叉点路由(例如,从任何调度队列32到任何执行片段34的路由)可能在某些实施例中不被支持。执行片段34按照期望实现逻辑、数学和其他操作的序列化和执行,以便实现针对一个或多个指令流中的指令的指令周期的执行周期部分,并且执行片段34可以是相同的通用执行片段。然而,在其他实施例中,处理器核22可以包括一个或多个专用执行片段34,例如用以提供特定类型指令的优化执行,因此在某些实施例中执行片段34的不同实例可以彼此不同。在某些实施例中,执行片段34也可以包括多个内部管线,用于执行多个指令和/或指令的多个部分。因此,特定执行片段34是否被认为“忙碌”可以基于不同管线的可用性和/或当前正在被特定执行片段执行的指令的类型而变化。在某些实施例中,执行片段34还可以由如下执行片段通信网络50而被耦合到另一个执行片段,通过该执行片段通信网络可以在执行片段34中交换值,例如当由一个执行片段实现对由另一个执行片段生成的值的进一步处理时。在某些实施例中,完全路由(或交叉点)网络可以被用于实施执行片段通信网络50。可替代地,执行片段34之间的连接也可以仅在特定组的执行片段之间被建立,例如,在某些实施例中仅邻居片段可以被连接。执行片段网络50也可以被用于利用了并行/协调执行的simd或大操作数指令的串接执行,尽管在某些实施例中这样的指令的执行可以以解耦合的方式被实现。指令执行周期的加载存储部分(即,不同于内部寄存器读/写的被执行用以维持高速缓存一致性的操作)可以由高速缓存或加载/存储片段36执行,高速缓存或加载/存储片段36通过回写(write-back)(结果)路由网络46耦合到执行片段34。在图示的实施例中,任何加载/存储片段36可以被用于实现任何执行片段34的加载-存储操作,但是在其他实施例中加载/存储片段36可以被限制为仅处理执行片段34的子集的加载-存储操作。此外,执行片段34可以同时向多个管线发出内部指令,例如,执行片段可以同时实现执行操作以及加载/存储操作和/或可以使用多个内部管线执行多个算数或逻辑运算。内部管线可以是相同的,也可以是离散类型,诸如浮点、标量、加载/存储等。此外,给定的执行片段可以具有一个以上的到回写路由网络46的端口连接,例如,一个端口连接可以专用于到加载/存储片段36的加载-存储连接,而另一个端口连接可以被用于传送来自和去往其他片段(诸如专用片段或其他执行片段)的值。回写结果可以从执行片段34不同的内部管线被调度到将执行片段34连接到回写路由网络46的(多个)回写端口。加载-存储路由52可以将加载/存储片段36彼此耦合,以便为simd指令的执行、数据宽度大于单个加载/存储片段36宽度的指令的处理和/或其他需要加载/存储片段36之间的数据转译或重新对齐的操作提供转换传送。i/o路由网络48可以被用于将加载/存储片段36耦合到一个或多个转译片段38,转译片段38提供对下一更高阶级别的高速缓存或系统存储器的访问,下一更高阶级别的高速缓存或系统存储器可以被集成在处理器核22内或被集成到处理器核22外部。尽管所示的示例显示数目匹配的加载/存储片段36和执行片段35,在实践中,不同数目的每个类型的片段都可以根据特定实施方式的资源需要而被提供。此外,尽管图2示出了四个调度队列32,八个执行片段34,八个加载/存储片段36以及两个转译片段38,将理解,这些组件的每一个的数目可以在不同实施例中改变。此外,掌握本发明益处的本领域普通技术人员能够理解,各种网络和互连42-52可以以多个不同的方式被实现,包括单向网络、交叉点网络、复用互连以及点对点互连,等等。因此,本发明不限于图2中所示的特定配置。图3和图4接下来示出根据本发明的一些实施例的到执行片段34的指令路由的各种示例类型。在图3中,例如,示出了三个执行片段34,也被称为es0、es1和es2。对于本文给出的示例,将理解,被调度到执行片段34的指令可以是完全的外部指令或者是外部指令的一部分,即被解码的“内部指令”。此外,在给定周期期间,被调度到执行片段es0、es1和es2中的任何执行片段的内部指令的数目可以大于1,同时并不是每个执行片段es0、es1和es2在给定周期内都必须接收内部指令。图3描绘了三个列,分别示出被发送到执行片段es0、es1和es2的指令序列。行对应于这些指令的指令调度序列,并且尽管这些行被对齐以简化描述,应当理解,在实践中调度不需要同时发生,并且列之间并没有关于执行片段何时完成或接收具体指令的任何约束。在行1-2,独立的指令被图示为被调度到执行片段es0、es1和es2中的每一个。在行3,需要更宽执行单元的指令通过动态组合执行片段es1和es2而被调度用以执行,同时执行片段es0被发送具有与执行片段es0、es1和es2宽度匹配的宽度的另一条指令。在行4-5,独立的指令再次被调度到执行片段es0、es1和es2中的每一个。在行6-7,具有三个数据值的simd指令通过链接执行片段es0、es1和es2来实现并行操作而被执行,在行8-9,具有两个数据值的simd指令通过连接执行片段es0和es1而被执行,同时执行片段es2被发送其他的独立指令。在行10,执行片段es0、es1和es2再次开始指令的独立执行。现在参见图4,其示出了处理器核22内的指令执行的另一个示例,并且该示例虽然单独在图4中被示出但也可以与图3的示例中提供的执行片段重新配置的部分或者全部进行组合。图4中特别示出了三个列,分别示出被发送到执行片段es0、es1和es2的指令的序列。如在图3中一样,行对应于指令序列,并且每个框中示出的数是正被执行的指令所属的从0到2编号的指令流的编号。在行1-2,针对对应指令流0-2中的每一个,指令被图示为被调度到执行片段es0、es1和es2中的每一个。行3描绘了执行片段es1变得忙碌的点,例如由于执行片段es1仍然在处理指令流1中的当前指令而变得忙碌。因此,在行4中,无论是由于优先化、循环或是由于其他允许指令流的指令被路由到不同于由于该指令流的默认执行片段之外的其他执行片段的机制,执行片段es2被调度了指令流1的指令。同样,在行5,执行片段es1被图示为从行4接受指令后变得忙碌,并且执行片段es1被图示为变得可用于接受另外的指令,因此执行片段es1被图示为接收来自指令流1的下一条指令的调度,同时执行片段es2同时执行指令流1的另一条指令。在行6,执行片段es0被示出为仍然忙碌,并且执行片段es1和es被分别示出为恢复执行指令流1和2的执行。然而,在行7,执行片段es1被图示为被指派执行指令流0的下一条指令,同时执行片段es0仍然忙于执行当前指令而执行片段es2执行指令流2的另一条指令。在行8中,执行片段es1执行指令流1的指令,同时执行片段es2执行指令流2的另一条指令。接着,在行9和10中,所有执行片段变得可用于接受指令,因此每个执行片段es0-es2被示为接收来自每个指令流0-2的相应的指令。将理解,图3和图4中提供的示例仅仅是说明性的并且被提供用于示出在处理器核22中提供的动态重新配置的灵活性。可以看出,可配置性提供了维持所有执行片段34在执行各种类型的操作时处于活跃执行状态的可能性,这些各种类型的操作诸如执行simd或者可变带宽指令流。可配置性也提供了即使遇到某些执行片段处于忙碌状况时也维持所有指令流处于活跃执行状态的可能性。现在参见图5,处理器核22的示例实施方式的进一步细节被示出。该实施例中的处理器核22可以包括一个分支执行(br)单元60,控制指令的提取的指令提取单元(ifetch)62以及控制指令的定序的指令定序器单元(isu)62。自学习指令缓冲器(ib)62也可以被包括用于对指令进行分组以便执行重新配置、诸如图3示出的那些重新配置,即在调度队列中布置指令以建立simd和可变宽度操作的指令。指令缓冲器(ibuf)64可以被划分以为每个指令流维持调度队列(例如,图2中的调度队列32)。此外,调度路由网络44被图示为将ibuf64耦合到分段执行和高速缓存片段66,其表示图2中的执行片段34和加载/存储片段36。在所图示的实施例中的指令流和网络控制框68被配置为实现对分段执行和高速缓存片段66和调度路由网络44的控制,以实现图3和图4中所图示的对片段的动态控制、以及下文进一步详细描述的其他操作。指令完成单元70被包含在指令流和网络控制框68中以追踪由isu62定序的指令的完成并且控制分段执行和高速缓存片段66内的高速缓存片段的回写操作。此外,在一些实施例中,电源管理系统(powermanagementunit)72也可以被用于例如通过减少或增加分段执行和高速缓存片段66内的活跃片段34、36的数目,来选择性激活或停用个体片段34、36和/或其他相关联的电路以减少能耗。现在转向图6,将理解,处理器核22中的每个执行片段34和加载/存储片段36的内部配置可以在不同实施例中显著变化,例如,以提供通用的处理功能,或者提供针对特定类型的指令或工作负载而优化的专用处理功能。图6图示了单个执行片段(es)34和加载/存储片段(ls)36的一个示例实施方式,该实施方式也可以适于在本发明某些实施例中用于实现处理器核22中的所有执行片段34和加载/存储片段36。在该实施例中,来自调度队列的输入经由调度路由网络44被寄存器阵列100接收,从而操作数和指令可以被排队在被设置于发出队列106中的执行预留站(er)107中。在某些实施例中,寄存器阵列100可以被构建为具有针对独立指令流或simd指令的独立寄存器集合,而在例如多个执行片段正执行非simd指令或者(多个)相同指令流的simd指令的同一片段的情况下,作为跨多个执行片段的克隆,从属寄存器集合可以被构建。别名映射器(aliasmapper)102可以将寄存器阵列中的值映射到任何外部引用,诸如通过回写路由网络46与其他片段交换的回写值。历史缓冲器(hb)104可以被用于为由执行片段34执行的指令的寄存器目标提供恢复能力。从回写路由网络46选择的结果值和来自寄存器阵列100的操作数值可以由算术逻辑单元(alu)输入复用器108选择并且在由alu110在其上操作。结果缓冲器112可以从alu110接收结果,并且复用器114可以被用于使结果缓冲器112的值可用于回写路由网络46的一个或多个信道,取决于操作的目标,该一个或多个信道可以由处理该指令流的下一条指令的下一执行片段34使用或者由加载/存储片段36使用来存储结果。复用器114也可以提供经由执行片段通信网络50到其他执行片段的连接。回写路由网络46也可以通过回写缓冲器116被耦合到er107、hb104和alu输入复用器108,从而资源值的回写、已完成指令的收回以及对结果的进一步计算都可以分别被支持。此外,在采用超片段的实施例中,另外的连接性可以被提供在被放置于超片段中的执行片段的相应发出队列106之间,用以提供支持执行单个指令流的执行片段之间的协调,该另外的连接线例如由被耦合在发出队列106与执行片段34’的发出队列106’之间的互连117所图示。对于加载/存储(ls)片段36,加载/存储访问队列(lsaq)118可以被耦合到回写路由网络46,去往回写路由网络46和lasq118的直接连接可以由复用器120选择,该复用器120从lsaq118或从回写路由网络46向数据高速缓存122的高速缓存目录124提供输入。到其他加载/存储片段36的连接可以由加载-存储路由网络52提供,该加载-存储路由网络52可以被耦合以从数据高速缓存122接收并且提供数据到另一个加载/存储片段36的数据非对齐框126。数据格式化单元128可以被用于经由缓冲器130将加载/存储片段36耦合到回写路由网络46,从而回写结果可以通过从一个执行片段被写到另一个执行片段的资源中。数据高速缓存122也可以被耦合到i/o路由网络48,以用于从更高阶高速缓存/系统内存中加载值以及用于从数据高速缓存122中清除或逐出值。在其他实施例中,可以对图6中所示的组件做出各种修改和/或增强。例如,在某些实施例中,执行片段还可以包括多个内部执行管线,这些多个内部执行管线支持一个或多个指令流中的指令的乱序和/或同时执行,其中被不同执行管线执行的指令是实施通过调度路由网络44接收到的指令的部分的内部指令,或者可以是直接通过调度路由网络44接收到的指令,即,指令的管线可以由指令流自身支持,或者指令的解码可以在执行片段的上游被实现。在某些实施例中,取决于将由特定执行片段实施方式执行的指令的类型,单个执行片段内的多个管线可以在设计和功能上有所不同,或者一些或者所有的管线可以是相同的。例如,在某些实施例中,特定管线可以被提供用于地址计算、标量或矢量运算、浮点运算,等等。将理解,复用器的各种组合也可以被合并以提供去往/来自结果缓冲器的执行结果的路由以及回写结果到以下网络的路由:回写路由网络46、i/o路由网络48、以及可以被提供用于路由用于片段之间的共享的特定数据或被发送给一个或多个加载/存储片段36的回写操作的其他路由网络。此外,在某些实施方案中,回写路由网络46可以被分段并且可以具有采用八个总线的交叉点集合形式的一个分段,该分段允许偶数编号的执行片段es0、es2、es4和es6中的每一个与图2中被选择的对应的偶数编号的加载/存储片段ls0、ls2、ls4和ls6之间同时的双向通信。集群栅栏(clusterfence)(未示出)可以被用于将该分段回写路由网络46耦合到执行片段和加载/存储片段的其他组(集群)中的其他回写路由网络分段,例如,图2的执行片段es1、es3、es5和es7以及高速缓存片段ls1、ls3、ls5和ls7。此外,将理解,关于双向通信,用于执行片段结果的回写的加载/存储片段可能与用于数据的加载的加载/存储片段不同,因为如图3至图4中所示,指令的序列可以在指令流之间交替,并且在这种情况下当改变被用于执行指令流的序列中的下一指令的执行片段时,通常期望将加载/存储片段连接到不同的执行片段。此外,加载/存储片段与执行片段之间的关系也可以任意变化,例如,对于引用大量数据的指令,多个加载/存储片段可以被分配给加载,而对于修改大量数值的指令,多个加载/存储片段可以被分配给结果回写操作。通过提供支持加载/存储片段与执行片段之间的任意连接的回写路由网络46,分段执行可以通过实现从一个或多个生成片段到如下一个或多个接收片段的数值的传送而被有效地支持,该一个或多个接收片段可以是与生成片段同样类型的片段或者可以是另一种片段类型,例如,(多个)专用片段。本发明的实施例可以在以上结合图1至图6所描述的硬件和软件环境内被实现。然而,得益于本发明的本领域普通技术人员应当理解,本发明可以在多种不同环境中被实现,同时在不脱离本发明精神和范围的情况下,也可以对前述硬件和软件实施例做出其他修改。因此,本发明不限于本文公开的具体硬件和软件环境。支持补充指令调度和/或选择性片段划分的旋转调度根据本发明的实施例可以提供指令调度功能,该指令调度功能扩展了在属于eisen等人的美国公开no.2015/0324204中公开的指令调度功能,该申请被转让给了本申请的同一受让人,并且通过引用并入本文。具体地,在某些根据本发明的实施例中,当在调度周期中至少要被调度的其他指令的子集具有比最大支持操作数更少的操作数的数目时,上述指令调度功能可以被扩展为包括对该调度周期中的一个或多个补充指令的调度的支持。在某些实施例中,例如,片段对(例如,超片段)可以被配置为支持两个指令的调度,其具有每个调度周期多达三个操作数和一个目的地,但是如果所有三个指令各自仅使用不超过2个源操作数,则允许附加指令被调度给这些片段之一。因此,这些实施例可以允许额外的指令(本文称作补充指令)在减少了硬件需求的给定调度周期中被调度到片段对。此外,在一些实施例中,上述指令调度功能可以被扩展以,以替代或除了对补充指令调度的支持之外,还支持通过线程模式的选择性片段划分。特别地,在某些实施例中,多线程模式可以被支持,包括两个或更多的单线程模式、双线程模式、四线程模式、八线程模式或任何其他数目的同时多线程模式,并且多个片段和/或片段的组可以被配置为供应执行资源以支持在处理器核中被实现的一个或多个硬件线程的执行。在某些模式中,硬件线程的状态可以跨多个片段被克隆或遮蔽,从而针对特定硬件线程的指令可以被维持硬件的线程遮蔽或克隆状态的任何片段所执行。另一方面,在其他模式中,在处理器核中的片段可以被划分成子集,这些子集仅支持可用硬件线程的子集,并且从而减少储存量(例如,寄存器空间)以及维持每个硬件线程的状态的克隆或遮蔽副本所需要的同步。划分可以基于个体片段或片段组。术语“超片段”在本文中可以被用于指代片段的组,并且同时在某些实施例中,超片段指的是逻辑上被耦合在一起的片段对,并且在某些实施例中可以包括附加的连接性,以减少与其间的同步(尤其是与simd指令和/或多宽度指令的联合执行相关的)相关联的延迟,但该术语不限于此。因此,在某些实施例中,超片段也可以包括两个以上的片段,并且此外,本发明的原理可以应用于片段的任何分组,不管其是否被称为超片段。例如,图7示出了包括本文所描述功能的调度路由网络44的示例实施方式。在该实施例中,多达六个指令(表示为i0-i5)可以被调度到四个片段140、141、142和143的组,该组被布置成一对超片段ssa和ssb。片段140和142也被称为偶数片段,片段141和143也被称为奇数片段。此外,在该实施例中,调度路由网络44在支持多个线程模式的处理器核内被实现,多个线程模式例如是单线程(st)、双线程(smt2)和四线程(smt4)模式。片段通过以下方式被划分成超片段:该方式避免在smt4模式中必须为所有的线程克隆所有的寄存器、但允许st/smt2模式使用两个超片段。此外,在st/stm2模式中,两个线程都被克隆到两个超片段,但是在smt4模式中,线程0/2被划分到超片段ssa,但线程1/3被划分到超片段ssb。将理解,线程模式的其他组合可以在其他实施例中被支持,例如支持八个线程的smt8模式、支持十六个线程的smt16模式等。接下来将更清楚的是,图7中所图示的实施例中的每个片段140-143包括64位指令路径和在每个调度周期期间接收64位指令的主指令端口。每个片段能够操作多达三个64位源操作数和一个64位目的地,并且每个超片段能够使用两个片段中的64位数据路径共同处理128位数据。每个片段也包括能够接收附加的64位指令的补充指令端口以支持根据本发明的补充指令调度,并且当超片段中的两个片段都需要少于两个源操作数时,针对每个片段的第三源操作数可以被需要两个或更少源操作数的补充指令所使用。如此,提供了对将三个指令调度到超片段的支持,其中针对每个指令,是两个或更少的源操作数。补充指令可以根据可用性和最优分配而被路由到偶数片段或奇数片段。将理解,在其他实施例中,片段的多个组可以在给定处理器核中被支持,并且此外,在每个组中可以支持不同数目的片段。此外,在其他实施例中,每个片段和超片段可以被配置为支持不同的组合和/或大小的指令。因此,本发明不限于图7所图示的实施方式。调度路由网络44包括六个锁存器(latch)的三个集合144、146和148,这三个集合分别定义了两个调度前阶段(pd0,pd1)以及一个片段传送阶段(sx0)。六个7:1复用器150的集合输出到锁存器144并且起到移位网络的作用,其中每个复用器150包括接收新指令i0-i5的一个输入以及接收之前被存储在六个锁存器144中任何一个的指令的六个输入。在每个复用器150上的控制由移位/复用控制框52提供,其为调度路由网络44实现至少一部分的路由逻辑。框152接收六个指令i0-i5作为输入并且针对每个复用器150输出控制信号以将指令从pd0阶段传递到pd1阶段(锁存器146)。在某些实施例中,框152还可以处理被存储于锁存器144中的指令之间的周期内的依赖性,从而响应于与其他锁存器144中存储的其他指令之间的任何未解决的依赖性,延迟锁存器144之一的指令的调度。框152还可以输出控制信号到锁存器154,该锁存器154进而配置交叉开关156,该交叉开关156将pd1阶段中的锁存器146一起耦合到sx0阶段的锁存器148。在某些实施例中,交叉开关156可以被配置为将任何锁存器146中的指令路由到任何锁存器148,而在其他实施例中,交叉开关156可以被限制为仅在锁存器146、148之间的路径的可能组合的子集之间路由指令。交叉开关156输出的指令包括主指令x0、x1、x2和x3,这些主指令分别被引导至片段140、141、142和143的主指令端口,输出的指令还包括两个补充指令xa、xb,这些补充指令分别被引导至超片段ssa和ssb的两个片段的补充指令端口。指令i0-i5通过调度路由网络44接收并且进入阶段pd0,其中框152检查指令类型,连同从片段140-143中每一个接收的多个片段忙碌输入一起。通过这些输入,移位/复用控制框150确定pd0阶段能够将多少指令路由到片段,并且然后确定向哪里路由这些指令。基于在pd0阶段期间所确定的移位控制,指令路由本身发生在pd1阶段。这些控制被锁存,并且然后实际复用/交叉开关发生在pd1阶段的开始处,以允许更快的周期时间。框152还确定在特定调度周期内多少指令能够被路由到片段140-143。在某些实施例中,该确定可以对于改进周期时间而言不最优的,只要指令路由类型约束仍被满足即可。在pd0和pd1阶段中的指令处于位置顺序,即,i0比i5更老;然而,在sx0阶段中的指令没有此限制。在一个实施例中,框152可以接收六个忙碌输入作为输入:x0_busy,x1_busy,xa_busy,x2_busy,x3_busy和xb_busy。x0_busy-x3_busy信号分别指示片段140-143的x0-x3主指令端口是否具有任何可用的槽。xa_busy信号在片段140或片段141都没有两个可用槽的时候被断言(asserted),而xb_busy信号在片段142或片段143都没有两个可用槽的时候被断言。框152还接收六个4位指令类型信号:i0_instruction_type-i5_instruction_type,分别来自与指令i0-i5相对应的锁存器144。每个指令类型信号从以下多个指令类型中选择:单-具有两个或更少源操作数的64位指令;3src-需要三个源操作数的指令(即,超片段不能调度第三指令);双-128位指令,需要超片段的两个片段;route2-需要接下来两个指令被调度到同一超片段的指令;以及route3-需要接下来三个指令被调度到同一超片段的指令。尽管在其他实施例中不同的编码也可以被使用,在示出的实施例中,以下编码可以用于ix_instruction_type信号:单(0000),3src(1000),双(x100),route2(xx10),route3(xxx1)。框152还接收四个4位片段启动信号:start_slice_0-start_slice_3,这些启动信号指示启动路由指令的优选位置。尽管在其他实施例中不同的编码也可以被使用,在示出的实施例中,表1中所示的编码可以被使用:表i:startslice编码如上所述,框152被配置为控制复用器150和交叉开关156以将指令i0-i5调度到片段指令端口x0-x3和xa-xb。每个复用器150具有自己的七个选择,这七个选择是零(zero)或一热码(onehot)并且处理对称多线程(smt)要求。框152然后响应前述输入,将指令调度到片段140-143以支持st、smt2和stm4线程模式,使得在smt4模式中,i0、i1和i2始终被路由到超片段ssa中的指令端口x0、x1或xa,并且i3、i4和i5总是被路由到超片段ssb中的指令端口x2、x3或xb。在st/smt模式中,如果指令i0-i5满足该指令的适当路由的要求,指令i0-i5可以被路由到x0-x3、xa和xb指令端口中的任何指令端口。此外,框152处理针对3src、双、route2和route3指令的对齐要求,以及调度忙碌的片段(由前述的xi_busy信号指示)。此外,在某些实施例中,贪婪(greedy)和最优调度可以被支持。通过贪婪调度,指令被保持年龄顺序(尽管指令可能被旋转),并且利用最优调度,指令在调度组阶段内可以按乱序被调度,并且依赖性检查可以在调度前和调度之间被实现,因此调度将与指令一起发送正确的组内依赖性信息,以在指令路由限制和忙碌片段的特定情况下允许更多的指令被调度。在给定每种类型的片段忙碌状态的计数以及指令路由要求下,最优调度可以计算能够被调度的指令的最优数目,并且首先基于对齐要求进行调度、然后在剩余可用的端口中调度不受限制的指令。例如,表ii示出了通过贪婪和最优调度方法的示例指令调度:表ii:贪婪与最优i0i1i2i3i4i5ix_instruction_type单双单单不关心不关心ix_busy000010贪婪i0----------最优i1i1--i0i2i3如上所述,框152也可以响应片段的可用性来旋转调度到其他片段。例如,在一个实施例中,框152可以在等效的非忙碌片段处启动搜索,首先调度被限制的指令,但在如果没有忙碌片段则指令将被调度的同一个位置处启动对片段的搜索。例如,表iii至表v示出了在考虑不同start_slice_x信号时若干指令的示例调度:表iii:start_slice_x=1000(st模式在片段x0处启动调度)表iv:startslicex=0001(st模式在片段x3处启动调度)表v:start_slice_x=1001(smt4模式针对线程0在片段x0处启动调度,或者针对线程1在片段x3处启动调度)将理解,得益于本发明的本领域普通技术人员能够将前述的逻辑实施到框152中。此外,将理解,其他逻辑也可以被用于实施本文描述的功能。因此,本发明不限于本文公开的特定调度逻辑。现在转到图8,该图更详细地描述了图7中的超片段ssa的补充指令的调度。每个片段140、141都包括被耦合到相应发出队列164的主指令端口160和补充指令端口162。片段140的主指令端口160从调度路由网络44的x0输出接收指令,而片段141的主指令端口160从调度路由网络44的x1输出接收指令,并且每一个主指令端口将接收到的指令转发给相应发出队列164的第一输入166。每个片段140、141的补充指令端口162从调度路由网络44的xa输出接收指令并且将接收的指令转发给相应发出队列164的第二输入168。此外,如上所述,每个片段140、141被配置为支持三个源指令,并且每个超片段被配置为每个调度周期接收至少两个指令。因此,图8图示了主指令端口160,该主指令端口160向发出队列164提供操作码(opcode)、目的地和三个源操作数(被标记为src0-2)。此外,根据本发明,每个超片段被进一步配置为当在输出x0和x1处接收的指令的每一个具有两个或更少的操作数时支持通过输出xa将第三指令调度到片段140、141之一,该指令被提供到发出队列164的第二输入168。然而,在所图示的实施例中,补充指令端口162仅为补充指令提供操作码和目的地,而多达两个源操作数通过主指令端口160提供,例如,来自主指令、经由来自主指令端口160的每一个的路径170提供的src2操作数。在某些实施例中,例如,补充指令的scr0操作数可以通过从来自片段140的主指令端口160的src2操作数中被取出,而src1操作数可以从来自片段141的主指令端口160的src2操作数中被取出。因此,在所图示实施例中,超片段中总共六个源操作数通路可以支持两个三源指令和三个两源指令,并且支持使用越少的操作数通路,并且因此支持相比在超片段中支持三个指令所需要的更少的硬件需求。接下来,图9至图10更详细地示出了在根据本发明的另一个实施例中对选择性片段划分的支持。在该实施方式中,四个片段200、201、202、203被耦合到调度路由网络204并且被分组到两个超片段206、208。每个片段200-203包括发出队列210和寄存器的集合212。此外,尽管在某些实施方式中每个片段200-203可以包括对补充指令调度的支持,片段200-203被图示为分别按每个片段200-203仅支持通过相应输出x0-x3的一个指令调度。因此,将理解,补充指令调度和选择性片段划分概念可以在本发明的一些实施例中彼此分开来实现。例如,图9示出了针对smt2模式配置的片段200-203,其中两个硬件线程(被标记为t0和t1)由片段执行。在这种模式中,t0/t1线程的状态都被跨四个片段200-203克隆或者遮蔽,例如,由框214、216所表示,其分别表示了线程t0、t1的状态或上下文。因此,在smt2模式中,所有线程都可以使用超片段206、208中的所有四个片段200-203的执行资源而被执行。类似地,在st模式中,其中仅有一个硬件线程(例如,线程t0)被执行,超片段206、208的所有四个片段200-203可以被用于执行单个线程,从而线程t0的状态数据214可以跨所有四个片段200-203而被克隆或遮蔽。另一方面,在smt4模式中,片段划分可以被用于在不同片段和/或超片段之中划分硬件线程,以避免需要克隆或遮蔽所有四个片段中的所有四个线程的状态数据。例如,图10示出了片段200-203的划分,以使得线程t0和t2由超片段206的片段200和201执行,并且线程t1和t3由超片段208的片段202和203执行。t0-t3的每个线程t0-t3的状态数据214在一个划分中在片段内被克隆或遮蔽,而不是跨所有四个片段,例如,线程t0和t2的状态数据214、218在片段200和201中被克隆或遮蔽,线程t1和t3的状态数据216、220在片段202和203中被克隆或遮蔽。通过采用这种方式划分超片段,支持多线程所需要的储存被减少,从而减少硬件需求和/或释放处理器核内的另外储存。在所示实施例中,硬件线程状态的克隆或遮蔽可以使用控制逻辑来实现,该控制逻辑被设置于每个执行片段200-203内,并且在某些情况下,被设置于每个发出队列210中。然而,在其他实施例中,执行片段中的其他逻辑以及执行片段外部的其他逻辑可以跨多执行片段协调硬件线程的遮蔽或克隆。得益于本发明的本领域普通技术人员容易想到这种逻辑的实施方式。本发明的各种实施例的说明已经处于描述的目的而被给出,但无意穷举或限制到所公开的实施例。在不脱离所描述实施例的范围和精神的情况下,许多修改和变化对于本领域普通技术人员而言是清楚的。本文所使用的术语被选择以最佳地解释实施例的原理,在市场中获得的对技术的实际应用或技术改进,或使得本领域技术人员能够理解本发明公开的实施例。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1