一种基于硬件排序MapReduce的数据处理方法与流程
本发明是关于计算机领域,具体涉及云计算和并行计算领域,尤其一种基于硬件排序mapreduce的数据处理方法。
背景技术:
mapreduce框架是云计算和大数据处理中普遍采用的一种分布式编程框架,当数据量很大时排序操作消耗的时间很长,而mapreduce通常用于大数据处理。如图1所示,在传统的mapreduce框架中,对中间结果数据的处理非常复杂,需要对数据进行四次排序操作,而基于cpu的排序操作性能不高,影响mapreduce整体性能的提升。
gpu因其强大的计算能力以及相对较低的性能价格比,通常用gpu替代cpu用以提高任务处理性能。使用gpu对mapreduce进行优化的方法主要有两类,一是与用户程序相关的优化方法,即对mapreduce框架进行扩展,使mapreduce程序执行过程中可以使用gpu设备替代cpu,提高程序执行效率;二是与用户程序无关的优化方法,即修改mapreduce框架或者组件,使mapreduce框架更好的发挥gpu性能,从而提高效率。
用户程序相关的优化方法需要用户参与进行任务分配,需要用户对程序的处理流程和gpu的编程规范非常熟悉,并且不同的用户程序之间优化方法不可重用。而现有的基于gpu排序的mapreduce优化方法只针对第一次排序过程的优化,即将基于cpu的快速排序算法替换成基于gpu的快速排序算法或者基于gpu的双调排序算法,而对于其他三次排序操作并不关注,对mapreduce性能的提升有限。
技术实现要素:
本发明提出一种基于硬件排序mapreduce的数据处理方法,将mapreduce执行流程中的四次排序操作全部使用gpu执行,提高中间数据处理速度,进而提升mapreduce的性能。
为了达到上述目的,本发明采用的技术方案为:
一种基于硬件排序mapreduce的数据处理方法,包括以下步骤:
a、map阶段,所述map阶段包括如下子步骤:(1)数据读入(read),即从分布式文件系统中读入数据;(2)map执行(map),即执行用户编写的map()函数;(3)数据收集(collect),即将map产生的结果存入缓冲区;(4)缓存溢写(spill),即将溢写文件采用基于gpu的快速排序方法进行排序,当缓存中数据量超过阈值时,将缓存中的数据写入本地硬盘;(5)溢写合并(merge),即多次缓存溢写会产生多个溢写文件,需要将所有的溢写文件采用基于gpu的归并排序的方法合并成一个输出文件。
b、shuffle阶段,所述shuffle阶段包括如下子步骤:(1)中间数据传输(copy),即将map端的中间结果通过网络传输到reduce端的缓冲区:(2)缓存溢写(spill),即reduce端的缓冲区数据量超过阈值时,将缓冲区数据写入本地硬盘,每次写入形成一个shuffle文件。
c、reduce阶段,所述reduce阶段包括如下子步骤:(1)shuffle文件合并(merge),即在reduce端先将大量的shuffle文件采用基于gpu的归并排序方法合并形成少量的大文件,再采用基于gpu的归并排序方法将多个大文件合并形成一个有序的大文件;(2)reduce执行(reduce):执行用户编写的reduce()函数;(3)数据输出(ourput):将reduce产生的结果输出到分布式文件系统。
优选的,基于gpu的归并排序方法包括以下步骤:a1:将待归并的序列两两分组,分成m组,每次对一组的两个序列a1和b1进行归并;a2:子序列归并前的准备;a3:子序列进入归并第一环节;a4:子序列进入归并第二环节;a5:重复步骤a3和a4直到序列a1和b1归并完成,输出归并结果c1;a6:进行下一组序列a2和b2的归并,直到所有序列归并完成,产生结果归并结果c2,...,cm;其中ci(1≤i≤m)表示原始序列ai和bi归并完成后产生的有序序列;a7:重复步骤(1)-(6)对归并结果c1,c2,...,cm进行归并,直到产生最终归并结果。
优选的,步骤a2包括:分别将a1和b1划分成n个子序列,每个线程块对a1的一个子序列和b1的一个子序列进行归并,共需进行log2n+1轮子序列的归并即可将序列a1和b1归并为一个有序序列。
优选的,步骤a3包括:对于a1和b1的第k轮归并(0≤k≤log2n),产生n/2k个归并结果r1,r2,...,rkr,并将每个归并结果ri(1≤i≤kr)划分为2k个子序列ri,1,ri,2,...,ri,kn;其中kr(kr=n/2k)表示序列a1和b1的第k轮归并产生的归并结果数量,r1、r2和rkr分别表示第1个、第二个以及第kr个归并结果,kn(kn=2k)表示序列a1和b1的第k轮归并产生的每个归并结果划分的子序列个数,ri,1、ri,2和ri,kn分别表示第i(1≤i≤kr)个归并结果划分后的第1个、第2个和第kn个子序列。
优选的,步骤a4包括:在a1和b1的第k+1轮归并(0≤k<logn)中,将第k轮产生的n/2k个归并结果依次两两分组(r1,r2),...,(rkr-1,rkr),每一组归并结果(ri-1,ri)(1≤i≤n/2k)相同位置的子序列由同一线程块进行归并,即子序列ri-1,1和ri,1、ri-1,2和ri,2、...、ri-1,kn和ri,kn分别由一个线程块进行归并,本轮参与归并操作的线程块数量为n。
优选的,基于gpu的快速排序方法,包括以下步骤:b1:将数据存入gpu的全局存储空间,并划分成m个互不重叠的数据块,每个数据块由一个线程块处理;b2:m个线程块并行地遍历对应的数据块,每个线程块内部n个线程并行地遍历对相应数据块的一部分,并记录大于和小于分界值的元素的个数;b3:遍历多线程并进行计数;b4:统计线程计数值并累加;b5:多线程数据交换并排序;b6:对步骤b5中产生的子序列分别重复执行步骤b1-b5,直到子序列个数与线程块数量相等;b7:每个线程块对一个子序列进行排序;b8:合并所有线程排序后的子序列,加入分界值,即可得到有序的序列。
优选的,步骤b3包括:依次统计每个线程的相对计数值,如线程块bk(1≤k≤m)中的每个线程的计数值分别为lk,1,...,lk,n和rk,1,...,rk,n,则第i(1≤i≤n)个线程的相对计数值分别为
优选的,步骤b4包括:依次统计每个线程块的计数值和相对计数值,线程块bk(1≤k≤m)的计数值分别为
优选的,步骤b5包括:所有线程进行数据交换,序列分成大于分界值和小于分界值的两个子序列。首先每个线程块中每个线程将其遍历的小于分界值的数据依次交换到分界值左侧,大于分界值的数据依次交换到分界值右侧,如第k个线程块的第i个线程中小于分界值的数据从序列的slk+blk,i位置依次存放至slk+blk,i+lk,i位置。然后每个线程块将对应位置的数据块写入辅助单元,根据分界值将序列分成比分界值小和比分界值大的两个子序列。
一种采用基于硬件排序mapreduce的数据处理方法的数据处理设备,数据处理设备内部设有gpu(图形处理器)与cpu。
与现有技术相比,本发明的优点和积极效果在于:
1、用基于gpu的排序算法替代基于cpu的排序算法,充分利用gpu的强大计算能力,提高中间数据处理速度,进而提升mapreduce性能。
2、不需要对mapreduce框架进行修改,只替换对中间结果的排序算法,实现难度较小。
3、可以与其他基于用户程序的优化方法以及基于mapreduce框架的优化方法同时使用,适用范围广泛。
4、由于gpu设备的应用越来越多,很多服务器和个人计算机均已配置gpu设备,因此本发明可以充分发挥现有gpu设备的计算能力,即便新购买gpu设备的硬件成本也不高。
附图说明
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本申请的其它特征、目的和优点将会变得更明显:
图1传统的mapreduce框架中对中间结果数据的处理
图2基于gpu的快速排序流程框图
图3基于gpu的归并排序流程框图
具体实施方式
本发明提出一种基于硬件排序mapreduce的数据处理方法,将mapreduce执行流程中的四次排序操作全部使用gpu执行,提高中间数据处理速度,进而提升mapreduce的性能。
cpu(centralprocessingunit中央处理)器,是一块超大规模的集成电路,是一台计算机的运算核心和控制核心。
gpu(graphicsprocessingunit图形处理器),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备上图像运算工作的微处理器。
spill(缓存溢写),当缓存中数据量超过阈值时,将缓存中的数据写入本地硬盘。
merge(溢写合并):多次缓存溢写会产生多个溢写文件,需要将所有的溢写文件合并成一个输出文件
下面结合附图和实施例对本申请作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与发明相关的部分。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
总体方案如下:在map阶段的spill过程中将基于cpu的快速排序替换为基于gpu的快速排序;在map阶段的merge过程中将基于cpu的归并排序替换为基于gpu的归并排序;在reduce阶段的merge过程中,将基于cpu的归并排序和堆排序均替换为基于gpu的归并排序,因为在gpu的实现归并排序的性能比堆排序的性能更优,且merge过程中的堆排序本质上是将有序的大文件合并为一个大文件。具体实施方式如下:
具体实施例1:
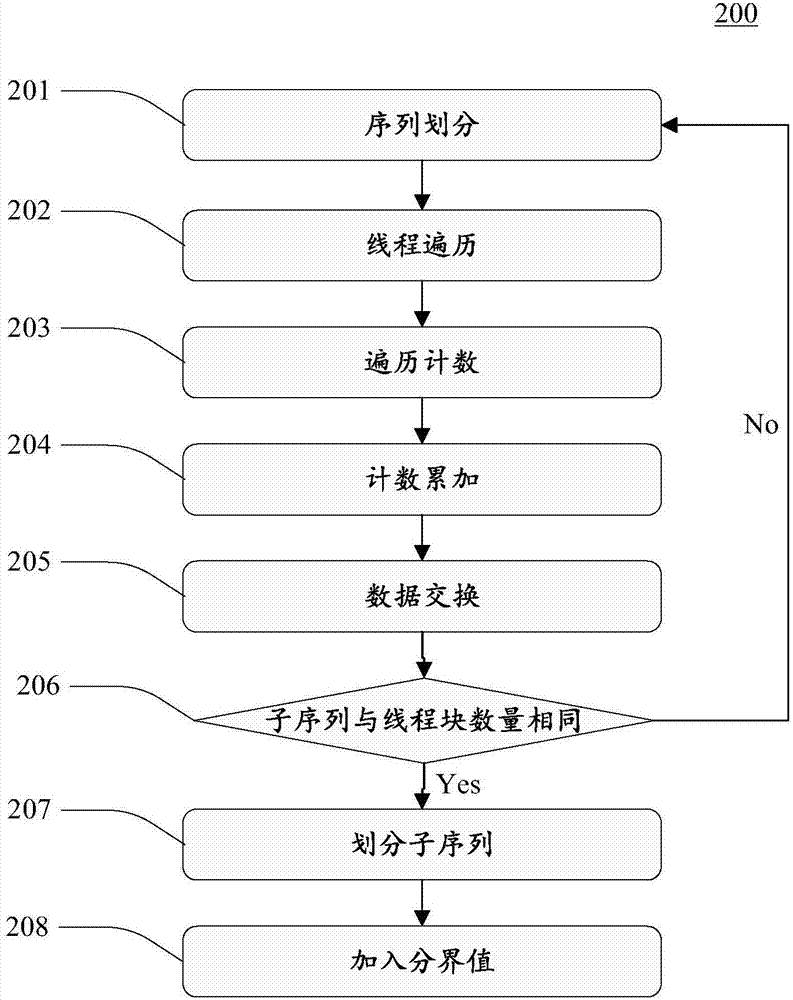
基于gpu的快速排序流程如图2所示,具体操作步骤如下:
201、序列划分:将数据存入gpu的全局存储空间,并划分成m个互不重叠的数据块,每个数据块由一个线程块处理;
202、线程遍历:m个线程块并行地遍历对应的数据块,每个线程块内部n个线程并行地遍历对相应数据块的一部分,并记录大于和小于分界值的元素的个数;
203、遍历计数:依次统计每个线程的相对计数值,如线程块bk(1≤k≤m)中的每个线程的计数值分别为lk,1,...,lk,n和rk,1,...,rk,n,则第i(1≤i≤n)个线程的相对计数值分别为和;
其中lk,1和rk,1分别表示线程块bk中第1个线程遍历的数据中比分界值小的数据个数和比分界值大的数据个数,lk,n和rk,n分别表示线程块bk中第n个线程遍历的数据中比分界值小的数据个数和比分界值大的数据个数;blk,i和brk,i分别表示线程块bk中第i个线程的相对计数值,即该线程块中前i-1个线程遍历的数据中比分界值小的数据总量和比分界值大的数据总量。
204、计数累加:依次统计每个线程块的计数值和相对计数值,线程块bk(1≤k≤m)的计数值分别为和,线程块bk的相对计数值分别为和;
其中lk、lj和rk、rj分别表示线程块bk和bj遍历的数据块内小于分界值的数据总量和大于分界值的数据总量,slk和srk分别表示线程块bk之前的k-1个线程块遍历的数据块中小于分界值的数据总量和大于分界值的数据总量。
205、数据交换:所有线程进行数据交换,序列分成大于分界值和小于分界值的两个子序列。首先每个线程块中每个线程将其遍历的小于分界值的数据依次交换到分界值左侧,大于分界值的数据依次交换到分界值右侧,如第k个线程块的第i个线程中小于分界值的数据从序列的slk+blk,i位置依次存放至slk+blk,i+lk,i位置。然后每个线程块将对应位置的数据块写入辅助单元,根据分界值将序列分成比分界值小和比分界值大的两个子序列。
206、子序列与线程块数相等:对步骤(5)中产生的子序列分别重复执行步骤201-205,直到子序列个数与线程块数量相等。
207、划分子序列:每个线程块对一个子序列进行排序。
208、加入分界值:合并所有线程排序后的子序列,加入分界值,即可得到有序的序列。
通过上述过程,在map阶段的spill过程中将基于cpu的快速排序替换为基于gpu的快速排序,充分利用gpu的强大计算能力,提高中间数据处理速度,进而提升mapreduce性能。
具体实施例2:
基于gpu的归并排序方法流程如图3所示,具体操作步骤如下:
301、序列分组:将待归并的序列两两分组,分成m组,每次对一组的两个序列a1和b1进行归并;
302、划分子序列:分别将a1和b1划分成n个子序列,每个线程块对a1的一个子序列和b1的一个子序列进行归并,共需进行log2n+1轮子序列的归并即可将序列a1和b1归并为一个有序序列;
303、子序列归并:对于a1和b1的第k轮归并(0≤k≤log2n),产生n/2k个归并结果r1,r2,...,rkr,并将每个归并结果ri(1≤i≤kr)划分为2k个子序列ri,1,ri,2,...,ri,kn;
其中kr(kr=n/2k)表示序列a1和b1的第k轮归并产生的归并结果数量,r1、r2和rkr分别表示第1个、第二个以及第kr个归并结果,kn(kn=2k)表示序列a1和b1的第k轮归并产生的每个归并结果划分的子序列个数,ri,1、ri,2和ri,kn分别表示第i(1≤i≤kr)个归并结果划分后的第1个、第2个和第kn个子序列。
在a1和b1的第k+1轮归并(0≤k<log2n)中,将第k轮产生的n/2k个归并结果依次两两分组(r1,r2),...,(rkr-1,rkr),每一组归并结果(ri-1,ri)(1≤i≤n/2k)相同位置的子序列由同一线程块进行归并,即子序列ri-1,1和ri,1、ri-1,2和ri,2、...、ri-1,kn和ri,kn分别由一个线程块进行归并,本轮参与归并操作的线程块数量为n;
重复步骤(3)和(4)直到序列a1和b1归并完成,输出归并结果c1;
进行下一组序列a2和b2的归并,直到所有序列归并完成,产生结果归并结果c2,...,cm;
其中ci(1≤i≤m)表示原始序列ai和bi归并完成后产生的有序序列。
305、子序列归并结束:重复步骤(1)-(6)对归并结果c1,c2,...,cm进行归并,直到产生最终归并结果。
通过上述过程,在map阶段的merge过程中将基于cpu的归并排序替换为基于gpu的归并排序;在reduce阶段的merge过程中,将基于cpu的归并排序和堆排序均替换为基于gpu的归并排序,因为在gpu的实现归并排序的性能比堆排序的性能更优,充分利用gpu的强大计算能力,提高中间数据处理速度,进而提升mapreduce性能,该方法尤其适用于大数据领域。
以上描述仅为本申请的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本申请中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离所述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本申请中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!