非侵入式Hadoop应用性能分析装置和方法与流程
本发明涉及大数据处理分析领域,具体涉及一种非侵入式hadoop应用性能分析装置和方法。
背景技术:
在大数据时代,越来越多的公司、研究机构及政府部门都在源源不断地从互联网、传感器网络或社交网络中收集海量的数据。从海量的数据中挖掘出有效的信息目前正得到越来越多的关注。hadoop是apache软件基金会中的一个开源分布式数据处理框架,也是当前使用最为广泛的大数据分析与处理平台。由于hadoop具有高可扩展性、容错处理机制以及数据并行处理等特性,目前已经被很多公司和学术机构采用。
得益于hadoop提供的基础数据处理平台,用户可以基于mapreduce编程模型快速地开发海量数据处理应用,并可以充分地利用hadoop所提供的数据高度并行处理的特性。这使得处理海量数据变得高效且易于操作。用户可以从分布式数据处理的很多混乱而复杂的细节中抽离出来,诸如数据分割、任务分布、任务调度、负载均衡、容错处理、节点通信等。用户只需要关注数据处理的业务逻辑,而无须关注更底层的实现细节。这一举措虽然简化了用户编写分布式数据处理应用的复杂度,但是由于hadoop框架隐藏了底层的实现细节,却也使得用户很难理解这些应用在分布式集群中的运行时行为。这样所带来的后果在于,用户可以基于hadoop简单而快速地编写处理海量数据的应用,但是对这些应用的性能进行分析却难以着手。
目前,分析hadoop应用程序运行性能的主要手段是通过监控系统的资源利用情况(如cpu、内存、磁盘的利用率)或者通过查看hadoop的系统日志来了解应用程序的运行时的状态。但是,这种方式只能够获取到hadoop应用运行时系统的整体概况,无法动态获取应用程序运行时较为关键应用级的性能数据。另外,hadoop框架支持在指定的任务中使用传统的java性能分析工具,如hprof[1],但这会带来较高的性能开销,因而通常只能用于少量的子任务中。随着分布式系统及大数据应用的不断发展,陆续也有一些分布式系统的跟踪框架被提出来,如magpie[2],x-trace[3]及dapper[4]等。这类系统的设计目标是将追踪元数据作为请求在系统中进行传播,进而对性能事件进行追踪。但是,如果要使用这一类系统对hadoop应用进行动态追踪,需要对hadoop应用的源码及消息模式进行修改,难以直接在生产环境中加以使用。
动态获取hadoop应用运行时的性能数据并进行性能分析比较复杂且难度较大。其原因主要如下:首先,为了应对大规模数据的分析与处理,基于hadoop平台编写的大数据应用通常都运行在由很多台机器组成的分布式集群中,分布式集群中的多个节点需要协同进行工作。其次,一个应用在提交至hadoop平台中运行时,为了充分地达到并行处理的效果,该作业会被分解为大量的map与reduce子任务,每个子任务都由单独的进程来完成。在hadoop2.0之后引入了新的资源管理系统yarn,yarn通过将计算资源封装为容器的方式动态分配给子任务,底层的资源管理和分配对应用而言是透明的。此外,在对hadoop应用进行性能分析时为了保证其可用性,该方法应该具备非侵入的特征,即不修改既有的hadoop的部署环境和运行方式,且引入的性能开销不应该影响到应用程序的正常运行。
技术实现要素:
本发明要解决的技术问题是提供一种非侵入式hadoop应用性能分析装置和方法,本发明能够动态获取应用程序的运行时信息并重构出高层的应用运行时数据流模型和行为特性,帮助用户了解hadoop应用程序的性能,为应用程序的性能调优指明方向。
为了解决上述技术问题,本发明提供一种非侵入式的hadoop应用性能分析装置,包括依次信号相连的动态追踪模块,数据聚合模块和数据分析模块;
所述动态追踪模块,用于为子任务添加jvm代理程序,在子任务启动时通过二进制代码动态插桩的方式动态注入字节码,对子任务的性能事件进行动态追踪,并将性能事件记录在性能日志文件中;
所述数据聚合模块,用于将集群所有节点中由动态追踪模块所记录的性能日志文件进行汇总处理;
所述数据分析模块,用于对通过数据聚合模块所汇总处理后得到的性能事件进行分析,生成应用程序性能分析结果。
作为本发明的非侵入式的hadoop应用性能分析装置的改进:所述数据聚合模块包括依次信号相连的数据转发模块、数据收集模块和数据存储模块;所述数据转发模块与动态追踪模块信号相连;
数据转发模块在集群的所有从节点中运行,用于将当前节点中由动态追踪模块所记录的性能日志文件转发到主节点中;
数据收集模块在集群的主节点中运行,用于将所有从节点中通过数据转发模块转发的性能日志文件汇聚到主节点中;
数据存储模块在集群的主节点中运行,用于对主节点中所有经数据收集模块汇聚的性能日志文件进行持久化处理,将性能事件结构化存储在数据库中。
备注说明:在分布式系统中,系统由许多台机器构成集群,集群中的每一台机器即为一个节点。hadoop采用主从式结构,主节点负责管理和协调其它的所有从节点。数据转发模块运行在集群中所有的从节点中,数据收集模块在hadoop集群的主节点中运行。
作为本发明的非侵入式的hadoop应用性能分析装置的进一步改进:所述数据分析模块包括依次信号相连的查询统计模块和可视化模块;所述查询统计模块与数据存储模块信号相连;
查询统计模块,用于查询数据存储模块所结构化存储在数据库中原始的性能事件,生成统计信息;
可视化模块,根据查询统计模块所生成的性能事件统计信息生成可视化图表,还原应用程序在hadoop集群中运行时的性能特性;
所述可视化图表包括:
时间轴维度,还原应用程序在hadoop集群中运行时子任务的调度、子任务的并行度等信息;
数据分布维度,反映出应用程序运行过程中数据的流动、数据分布的均匀性等信息;
时间热点维度,还原应用程序中不同操作的耗时信息、识别热点操作。
本发明还同时提供了一种非侵入式hadoop应用性能分析方法,包含以下步骤:
1)、启用性能分析(提交作业时添加控制参数启用性能分析):
用户在提交作业时通过添加相应的控制参数为应用程序启用性能分析;
2)、添加代理程序(代理程序动态注入字节码):
在分布式集群的所有节点中,通过动态追踪模块为子任务添加jvm代理程序,子任务的jvm代理程序在子任务启动时通过二进制代码动态插桩的方式动态注入字节码;
3)、动态追踪并记录(对子任务的性能事件进行动态追踪,生成性能日志文件):
在分布式集群的所有节点中,动态追踪模块对所有子任务的性能事件进行动态追踪,生成性能日志文件;
4)、汇总性能日志文件(汇总分散在集群中的性能日志):
数据聚合模块对分散在集群所有节点中的性能日志进行聚合,将所有从节点中的性能日志文件汇总到主节点中;
5)、获取应用性能分析结果(分析性能事件,获取应用性能分析结果):
数据分析模块分析通过数据聚合模块汇总的所有子任务的性能事件,获取应用性能分析结果。
作为本发明的hadoop应用性能分析方法的改进:所述步骤2)中,使用java标准api中提供的java.lang.instrument包为子任务添加jvm代理程序,jvm代理程序在jvm执行类加载操作时对字节码进行修改,向原始的java类中的目标方法中注入字节码,注入的字节码会在目标方法调用时执行,从而动态追踪子任务运行时的性能事件。
作为本发明的hadoop应用性能分析方法的进一步改进:所述步骤3)中,动态追踪模块为子任务添加的jvm代理程序会创建一个新的事件处理线程,在该线程中使用事件监听模式监听指定的性能事件,从而降低动态追踪的性能开销。
作为本发明的hadoop应用性能分析方法的进一步改进:所述步骤4)中,主节点中的数据收集模块和所有从节点中的数据转发模块进行通信,通过网络传输的方式将所有从节点中的性能日志文件汇总到主节点中。
作为本发明的hadoop应用性能分析方法的进一步改进:所述步骤4)中,主节点中的数据收集模块在对所有从节点中的性能日志文件进行汇总后,为了便于后续的查询和管理,使用数据存储模块将所有的性能事件在数据库中进行结构化存储。
作为本发明的hadoop应用性能分析方法的进一步改进:所述步骤5)中,在查询统计模块对所有的性能数据进行统计分析的基础上,通过可视化模块生成可视化的图表,从时间轴、数据分布和时间热点这三个维度重构出高层的应用运行时数据流模型和行为特性。
本发明具有如下技术优势:
1.本发明在进行性能事件动态追踪时使用了一种非侵入的方式,通过二进制字节码动态插桩技术在任务运行时动态注入监听性能事件的字节码,无需修改hadoop系统的源码,也无需修改已经部署的hadoop集群环境。
2.本发明采用分布式架构,可以在集群所有节点中针对应用程序的所有子任务进行动态追踪,从而获取到更加全面的性能数据。
3.本发明利用采集的性能数据重构出高层的应用运行时数据流模型和行为特性,并通过可视化图表直观还原出应用程序的行为特性。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细说明。
图1为本发明的非侵入式hadoop应用性能分析装置的示意性框图。
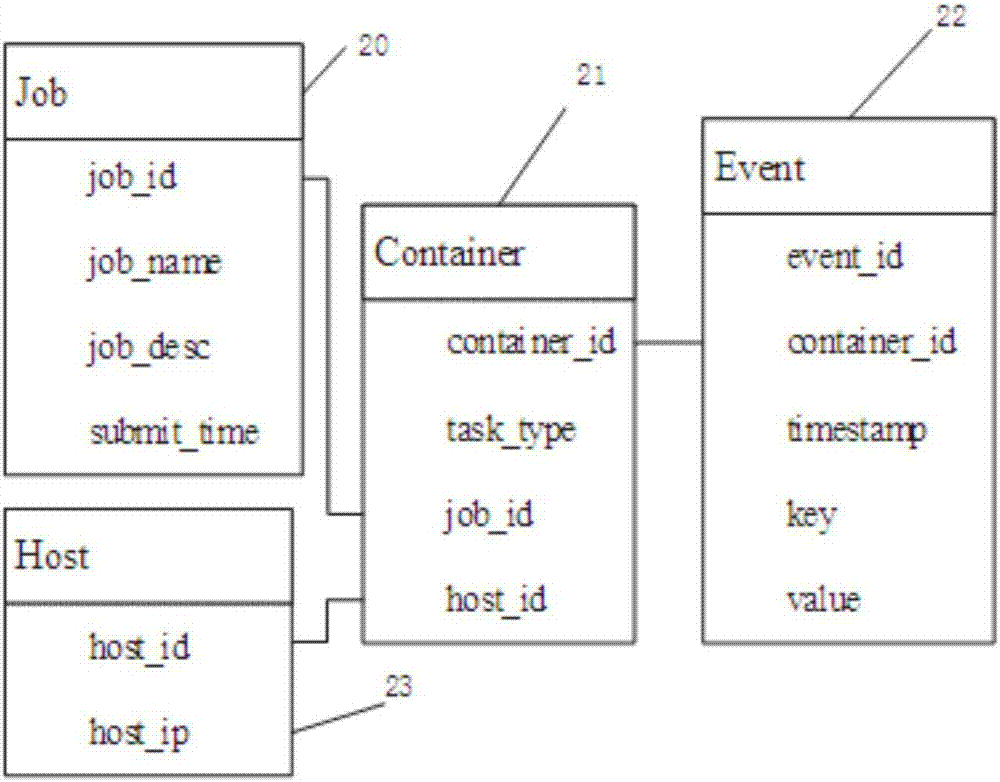
图2为图1中数据存储模块123在结构化存储数据时使用的实体-关系模型。
图3为本发明的非侵入式hadoop应用性能分析方法的流程图。
具体实施方式
下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此。
实施例1、一种非侵入式hadoop应用性能分析装置,如图1、2所示,包括依次信号相连的动态追踪模块110、数据聚合模块120、数据分析模块130。
动态追踪模块110用于动态追踪所有子任务中发生的性能事件,并将性能事件记录在性能日志文件中。在动态追踪模块110中,针对hadoop应用程序运行时如任务启动和结束、进入或退出关键的函数等关键性能事件制订了一系列事件触发规则,当这些规则描述的事件发生时,该规则相关联的如记录事件发生的时间、获取方法执行时间、获取函数运行时实参等动作就会被触发,相应的运行时信息被记录在性能日志中。性能日志中的每一条记录由三个字段构成:1)时间戳(timestamp)记录了该条记录的获取时间;2)键(key)字段保存当前记录对应的事件的描述,如所处的容器、类和方法;3)值(value)字段则用于保存所追踪到的事件的详细信息,如当前操作花费的时间、处理的数据量的大小等。hadoop框架是基于java语言实现的,且在mapreduce应用提交运行时会为每一个map或reduce任务启动一个单独的jvm(javavirtualmachine)进程,即为每一个子任务分配一个容器;一个jvm进程运行时会经历jvm启动、类加载、字节码解释执行等过程,通过二进制字节码动态插桩技术可以在运行时动态修改jvm加载的类的字节码。本实施例中动态追踪模块110采用二进制字节码动态插桩技术来实现动态追踪每一个子任务的性能事件。动态追踪模块110基于java标准api中提供的java.lang.instrument包为运行子任务的jvm添加代理程序,jvm代理程序在jvm执行类加载操作时对字节码进行修改,向原始的java类中的目标方法中注入处理事件触发操作的字节码。注入的字节码的主要功能就是将当前发生的性能事件记录在性能日志中。
数据聚合模块120用于汇总处理集群所有节点中的性能日志。数据聚合模块120包括依次信号相连的数据转发模块121、数据收集模块122和数据存储模块123。所述数据转发模块121在hadoop集群的所有从节点中运行,与动态追踪模块110信号相连,负责将当前节点中通过动态追踪模块110所生成的性能日志文件转发到主节点中;数据收集模块122在hadoop集群的主节点中运行,负责收集集群所有节点通过数据转发模块121转发至主节点的性能日志文件;数据存储模块123在hadoop集群的主节点中运行,负责将数据收集模块122汇聚在主节点中所有的性能日志文件进行持久化处理,将性能事件结构化存储在数据库中。该数据库中包含四张表,对应的实体-关系模型如图2所示。其中job表20中存储作业相关的信息,包括作业的编号job_id、作业的名称job_name、作业的描述信息job_desc以及提交时间summit_time;container表21中存储了作业运行过程中运行所有子任务的容器相关的信息,包括容器的编号container_id、容器中运行的子任务的类型task_type、当前容器所属的作业的编号job_id、当前容器所在的节点的编号host_id;event表22中存储了动态追踪模块110收集的所有子任务运行时性能事件相关的信息,包括性能事件的编号event_id、事件所在的容器的编号container_id、事件捕获时的时间戳timestamp、描述事件详细状态的键key和对应的值value;host表23存储了当前集群中所有节点的编号host_id及其对应的ip地址host_ip。不同表之间通过数据库的外键约束加以关联,其中container表和job表通过job_id属性建立链接,container表和host表通过host_id属性建立链接,event表和container表则通过container_id建立链接。
数据分析模块130用于对性能事件进行分析,生成应用程序性能分析结果。数据分析模块130包括依次信号相连的查询统计模块131和可视化模块132。所述查询统计模块131与数据存储模块123信号相连,用于查询原始的性能事件,并生成统计信息。可视化模块132根据查询统计模块131生成的性能事件统计信息生成可视化图表,还原应用程序在hadoop集群中运行时的性能特性。可视化模块132可以从三个维度还原应用程序的运行时细节:时间轴维度,还原应用程序在hadoop集群中运行时子任务的调度、子任务的并行度等信息;数据分布维度,反映出应用程序运行过程中数据的流动、数据分布的均匀性等信息;时间热点维度,还原应用程序中不同操作的耗时信息,识别热点操作。
通过以上所述的非侵入式hadoop应用性能分析装置可以实现本发明实施例的非侵入式hadoop应用性能分析方法,流程如图3所示,具体包括以下步骤:
1、提启用性能分析(交作业时添加控制参数启用性能分析):用户在提交作业时通过添加相应的控制参数为应用程序启用性能分析。本发明实施例中非侵入式hadoop应用性能分析装置中动态追踪模块110提供了一个tracker.jar包作为子任务运行时的代理程序,在提交作业时只需要添加参数:
-dmapreduce.child.java.opts=“-javaagent:tracker.jar=enable=true”
即可为应用程序开启非侵入式hadoop应用性能分析装置进行性能分析。
2、添加代理程序(代理程序动态注入字节码):开启性能分析后,在分布式集群的所有节点中,动态追踪模块110会为子任务添加jvm代理程序,子任务的jvm代理程序在子任务启动时通过二进制代码动态插桩的方式动态注入用于性能追踪的字节码。
3、动态追踪并记录(对子任务的性能事件进行动态追踪,生成性能日志文件):在分布式集群的所有节点中,动态追踪模块110对所有子任务的性能事件进行动态追踪,在目标性能事件发生时将相应的性能事件记录在性能日志文件中。并且为了减少在一些频繁执行的操作上运用动态追踪技术造成主线程阻塞而导致的性能开销,动态追踪模块110为子任务添加的jvm代理程序会创建一个新的事件处理线程,在该线程中使用事件监听模式监听指定的性能事件,从而降低动态追踪的性能开销。
4、汇总性能日志文件(汇总分散在集群中的性能日志):当hadoop应用的一个作业运行完成后,非侵入式hadoop应用性能分析装置运行在主节点中的数据收集模块122与运行在所有从节点中的数据转发模块121进行通信,通过网络传输的方式将分散在不同节点中的性能日志文件进行汇聚。当集群所有节点中的性能日志文件通过数据收集模块122汇聚完成后,主节点中会存在大量零散的性能日志文件。此时主节点中的数据存储模块将123进一步解析汇总的性能日志文件,将解析的结果结构化存储在数据库中。
5、获取应用性能分析结果(分析性能事件,获取应用性能分析结果):数据分析模块130分析汇总的所有子任务的性能事件,获取应用性能分析结果。首先查询统计模块131从数据库中查询原始的性能事件,并生成统计信息;之后可视化模块132根据查询统计模块131所生成的性能事件统计信息生成可视化图表,从时间轴、数据分布和时间热点这三个维度重构出高层的应用运行时数据流模型和行为特性,从而帮助用户发现潜在的性能优化方向。
本发明实施例在对hadoop应用进行性能事件追踪及性能分析时使用的是一种非侵入的方式,通过二进制字节码动态插桩技术在任务运行时动态注入监听性能事件的字节码,不需要修改hadoop系统的源码,也无需修改已经部署的hadoop集群环境;本发明实施例采用了分布式架构,可以在集群所有节点中针对应用程序的所有子任务进行动态追踪,从而获取到更加全面的性能数据,并且在作业完成后对分散的数据加以聚合,结构化存储在数据库中;本发明利用采集的性能数据重构出高层的应用运行时数据流模型和行为特性,并通过可视化图表直观还原出应用程序的行为特性。
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的思想所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!