基于稀疏表示的改进耦合字典学习的脑部CT/MR图像融合方法与流程
本发明涉及图像处理技术领域,特别是涉及基于稀疏表示的改进耦合字典学习的脑部ct/mr图像融合方法。
背景技术:
在医学领域,医生需要对同时具有高空间和高光谱信息的单幅图像进行研究和分析,以便于对疾病进行准确诊断和治疗。这种类型的信息仅从单模态图像中无法获取,例如,ct成像能够捕捉人体的骨结构,具有较高的分辨率,而mr成像能够捕捉人体器官的软组织如肌肉、软骨、脂肪等细节信息。因此,将ct和mr图像的互补信息相融合以获取更全面丰富的图像信息,可为临床诊断和辅助治疗提供有效帮助。
目前应用于脑部医学图像融合领域比较经典的方法是基于多尺度变换的方法:离散小波变换(dwt)、平稳小波变换(swt)、双树复小波变换(dtcwt)、拉普拉斯金字塔(lp)、非下采样contourlet变换(nsct)。基于多尺度变换的方法能很好地提取图像的显著特征,但是对图像误配准敏感,传统的融合策略也使得融合结果无法保留源图像的边缘、纹理等细节信息。随着压缩感知的兴起,基于稀疏表示的方法被广泛用于图像融合领域,并取得了极佳的融合效果。yang.b等使用冗余的dct字典稀疏表示源图像,并使用“选择最大”的规则融合稀疏系数。dct字典是一种由dct变换形成的隐式字典,易于快速实现,但是其表示能力有限。m.elad等提出k-svd算法用于从训练图像中学习字典。与dct字典相比,学习的字典是一种自适应于源图像的显式字典,具有较强的表示能力。学习的字典中将仅从自然图像中采样训练得到的字典称为单字典,单字典可以表示任意一幅与训练样本类别相同的自然图像,但对于结构复杂的脑部医学图像,使用单字典既要表示ct图像又要表示mr图像,难以得到精确的稀疏表示系数。b.ophir等提出小波域上的多尺度字典学习方法。即在小波域上对所有子带分别使用k-svd算法训练得到所有子带对应的子字典。多尺度字典有效地将解析字典和学习的字典的优势相结合,能够捕捉图像在不同尺度和不同方向上包含的不同特征。但是所有子带的子字典也是单字典,使用子字典对所有子带进行稀疏表示仍然难以得到精确的稀疏表示系数,并且分离的字典学习时间效率较低。yu.n等提出基于联合稀疏表示的图像融合方法兼具去噪功能。这种方法是对待融合的源图像本身进行字典学习,根据jsm-1模型提取待融合图像的公共特征和各自特征,再分别组合并重构得到融合图像。这种方法由于是对待融合源图像本身训练字典所以适用于脑部医学图像,可以得到精确的稀疏表示系数。但是对于每对待融合的源图像都需要训练字典,时间效率低,缺乏灵活性。
技术实现要素:
本发明实施例提供了基于稀疏表示的改进耦合字典学习的脑部ct/mr图像融合方法,可以解决现有技术中存在的问题。
一种基于稀疏表示的改进耦合字典学习的脑部ct/mr图像融合方法,该方法包括:
预处理阶段:对于已经配准的脑部ct/mr源图像ic,ir∈rmn,rmn表示具有m行n列的向量空间,使用步长为1的滑动窗把源图像ic,ir分别分割为
其中,
融合阶段:使用coefromp算法求解
其中,||α||0表示稀疏系数α中非零元素的个数,ε表示允许偏差的精度,df表示字典dc和dr融合后得到的融合字典;
将稀疏系数的l2范数作为源图像的活跃度测量,则稀疏系数
均值
其中,
重建阶段:对所有的图像块都执行预处理阶段和融合阶段以得到所有图像块的融合结果,对于每个块向量
优选地,在融合阶段中,所述融合字典通过以下方法计算获得:
使用高质量ct和mr图像作为训练集,从训练集中采样得到向量对{xc,xr},定义
在字典学习代价函数基础上加入支撑完整的先验信息,交替地更新dc,dr和a,对应的训练优化问题如下:
其中,a是xc和xr的联合稀疏系数矩阵,τ是联合稀疏系数矩阵a的稀疏度,⊙表示点乘,掩膜矩阵m由元素0和1组成,定义为m={|a|=0},等价于如果a(i,j)=0则m(i,j)=1,否则为0,引入辅助变量:
则式(1)可以等价的转化为:
式(3)的求解过程分为稀疏编码和字典更新两个步骤:
首先,在稀疏编码阶段,随机矩阵初始化字典
分别对联合稀疏系数矩阵a中每一列的非零元素进行处理,而保持零元素完备,则式(4)可以转换为下式:
式中,
其次,在字典更新阶段,式(3)的优化问题转化为:
则式(6)的补偿项写为:
式中,
最后,循环执行稀疏编码和字典更新这两个阶段,直至达到预设的迭代次数为止,输出一对耦合的dc和dr字典。
优选地,使用以下方法对字典dc和dr进行融合:
lc(n)和lr(n),n=1,2,…,n分别代表ct字典和mr字典的第n个原子的特征指标,融合公式表示如下:
此处设λ=0.25。
本发明实施例提供的基于稀疏表示的改进耦合字典学习的脑部ct/mr图像融合方法,能分别对正常脑部、脑萎缩和脑肿瘤三组脑部医学图像进行融合,多次实验结果表明本发明提出的icdl方法与基于多尺度变换的方法、传统稀疏表示的方法、基于k-svd字典学习的方法以及多尺度字典学习的方法相比,不仅提高了脑部医学图像融合的质量,而且有效降低了字典训练的时间,能为临床医疗诊断提供有效帮助。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的基于稀疏表示的改进耦合字典学习的脑部ct/mr图像融合方法流程图;
图2为作为训练集的高质量的ct和mr图像;
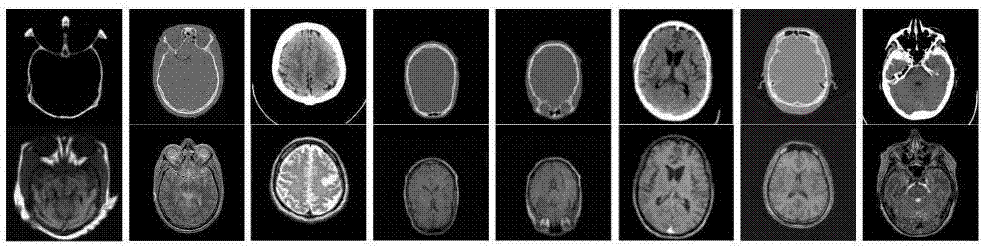
图3为正常脑部的ct/mr融合结果,其中a为ct图像,b为mr图像,c为dwt(离散小波变换)图像,d为swt(平稳小波变换)图像,e为nsct(非下采样contourlet变换)图像,f为srm(传统稀疏表示方法)图像,g为srk(基于k-svd字典学习方法)图像,h为mdl(基于多尺度字典学习方法)图像,i为本发明使用的icdl(improvedcoupleddictionarylearning)图像;
图4为脑萎缩的ct/mr融合结果;
图5为脑肿瘤的ct/mr融合结果。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参照图1,本发明实施例中提供的基于稀疏表示的改进耦合字典学习的脑部ct/mr图像融合方法,该方法包括以下步骤:
步骤100,预处理阶段:对于已经配准的脑部ct/mr源图像ic,ir∈rmn,rmn表示具有m行n列的向量空间,使用步长为1的滑动窗把源图像ic,ir分别分割为
其中,
步骤200,融合阶段:使用coefromp算法求解
其中,||α||0表示稀疏系数α中非零元素的个数,ε表示允许偏差的精度,df表示字典dc和dr融合后得到的融合字典,其具体计算方法如下:
使用图2所示的高质量ct和mr图像作为训练集,从训练集中采样得到向量对{xc,xr},定义
本发明的耦合字典训练使用改进的k-svd算法,该算法在传统的字典学习代价函数基础上加入支撑完整的先验信息,交替地更新dc,dr和a,对应的训练优化问题如下:
其中,a是xc和xr的联合稀疏系数矩阵,τ是联合稀疏系数矩阵a的稀疏度,⊙表示点乘,掩膜矩阵m由元素0和1组成,定义为m={|a|=0},等价于如果a(i,j)=0则m(i,j)=1,否则为0。因此a⊙m=0能使a中所有零项保持完备。引入辅助变量:
则式(3)可以等价的转化为:
式(5)的求解过程分为稀疏编码和字典更新两个步骤。
首先,在稀疏编码阶段,随机矩阵初始化字典
分别对联合稀疏系数矩阵a中每一列的非零元素进行处理,而保持零元素完备,则式(6)可以转换为下式:
式中,
其次,在字典更新阶段,式(5)的优化问题可以转化为:
则式(8)的补偿项可以写为:
式中,
最后,循环执行稀疏编码和字典更新这两个阶段,直至达到预设的迭代次数为止,输出一对耦合的dc和dr字典。然后使用以下方法对字典dc和dr进行融合:
lc(n)和lr(n),n=1,2,…,n分别代表ct字典和mr字典的第n个原子的特征指标,由于脑部ct和mr图像是对应于人体同一部位由不同成像设备获取的图像,因此两者之间一定存在着公共特征和各自特征。本发明提出将特征指标相差较大的原子看作各自特征,使用“选择最大”规则融合。特征指标相差较小的原子看作公共特征,使用“平均”的规则融合,公式表示如下:
此处设λ=0.25,根据医学图像的物理特性,使用信息熵作为特征指标。这种方法将稀疏域和空间域的方法结合起来,考虑了医学图像的物理特性计算字典原子的特征指标,与稀疏域的方法相比,具有更加明确的物理意义。
由于字典更新阶段同时更新字典和稀疏表示系数的非零元素,使得字典的表示误差更小且字典的收敛速度更快。在稀疏编码阶段,考虑到每次迭代时都忽略前一次迭代的表示,coefromp算法提出利用上次迭代的稀疏表示残差信息进行系数更新,从而更快地得到所要求问题的解。
计算得到融合字典df后,将稀疏系数的l2范数作为源图像的活跃度测量,则稀疏系数
均值
其中,
步骤300,重建阶段:对所有的图像块都执行上述两个步骤以得到所有图像块的融合结果。对于每个块向量
为验证本发明方法的有效性,选取三组已经配准的脑部ct/mr图像进行融合,分别为正常脑部ct/mr如图3中a和b所示,脑萎缩ct/mr如图4中a和b所示,脑肿瘤ct/mr如图5中a和b所示,图片大小均为256×256。选取的对比算法有:离散小波变换(dwt)、平稳小波变换(swt)、非下采样contourlet变换(nsct)、传统稀疏表示的方法(srm)、基于k-svd字典学习的方法(srk)、基于多尺度字典学习的方法(mdl),融合结果分别见图3中c、d、e、f、g、h,图4中c、d、e、f、g、h和图5中c、d、e、f、g、h。
基于多尺度变换的方法中,对于dwt和swt方法,分解水平都设为3,小波基分别设为“db6”和“bior1.1”。nsct方法使用“9-7”金字塔滤波器和“c-d”方向滤波器,分解水平设为{22,22,23,24}。基于稀疏表示的方法中滑动步长为1,图像块大小均为8×8,字典大小均为64×256,误差ε=0.01,稀疏度τ=6,icdl方法使用改进的k-svd算法,执行6个多重字典更新周期(duc)和30次迭代。
由图3-5可以看出,dwt方法的融合图像边缘纹理模糊,图像信息失真且存在块效应;与dwt方法相比,swt和nsct方法的融合质量相对较好,图像的亮度、对比度、清晰度有了很大的提升,但仍存在边缘亮度失真,软组织和病灶区域存在伪影的问题;srm和srk方法较基于多尺度变换的方法图像的骨组织和软组织更加清晰,伪影也有所减少,能很好地识别病灶区域;mdl方法与srm和srk方法相比能保留更多的细节信息,图像质量取得进一步的改善,但仍有部分伪影存在;本发明提出的icdl方法在图像的亮度、对比度、清晰度和细节的保持度上都优于其他方法,融合图像没有伪影,骨组织、软组织和病灶区域显示清晰,有助于医生诊断。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!