改进的文档中多主题的关键词提取技术的制作方法
本发明涉及语义网络技术领域,具体涉及改进的文档中多主题的关键词提取技术。
背景技术:
关键词是文章主题的概括,常以词或短语的形式出现,是表达文本主题意义的最小单位,能够使读者在短时间内了解文章的大概内容,从而节省读者的时间。所以文档关键词可以帮助用户迅速的从大量的文档集合中找到用户需要或者与其相关的文档。但除学术论文包含关键词外,大量的文档没有关键词,尤其是上述提到的互联网上的众多网页。面对海量的文本数据,手工抽取关键词费时费力,而且主观性强,抽取不当还会对下一步的应用造成消极影响。传统的关键词抽取算法普遍缺少对文档结构特征的考虑,导致结构信息这一重要特征的缺失,在一定程度上影响了关键词提取的精确性,特别是不能抽取出真正反映文本内容的词汇。现有基于复杂网络或图模型的关键词抽取算法在构建文本复杂网络或图模型的过程中单纯以词形作为网络节点,这种算法虽然可以最大限度的保持文本的结构信息,但是由于没有进行语义标注,导致提取的关键词在语义上不具有可解释性,有可能会产生歧义。因此,为了改善文本检索的现状,人们积极研究人工智能和自然语言处理的各种技术,很多学者提出采用机器智能自动提取关键词的方法。由此可见,关键词自动抽取是文本自动处理的基础与核心技术,是解决信息检索的效率和准确度的关键技术,关键词是表述文本主题,为了满足上述需求,本发明提供一种改进的文档中多主题的关键词提取技术。
技术实现要素:
针对从多主题文档中找出一些非高频并且对主题贡献大的词作为关键词、实现自动提取文档中主题词的问题以及常用的关键词提取方法精度不高的不足,本发明提供了一种改进的文档中多主题的关键词提取技术。
为了解决上述问题,本发明是通过以下技术方案实现的:
步骤1:利用中文分词技术对文本进行分词处理;
步骤2:根据停用表对文本词汇进行去停用词处理,得到词汇集w;
步骤3:构造相关度函数re(wi,wj)对上述词汇集w进行从大到小排序处理,取前n个词语构成一个多主题网络模型m;
步骤4:构造目标函数
步骤5:构造叉函数
本发明有益效果是:
1、此方法比传统的词频-反文档频率方法得到的文本关键词集合的准确度更高。
2、把词语语义关系映射到主题网络模型图上,既考虑了多主题性,又区分了主题间的不同特征,提取的文本关键词更符合经验值;
3、为后续的文本相似度与文本聚类技术提供良好的理论基础。
4、此算法具有更大的利用价值。
5、此方法精确地计算了特征词汇中不同词汇对文本思想的贡献度。
6、此方法在初次提取关键词时,用精确的算法得到更为准确的文档特征,为后续文档关键词提取提供更好的铺垫。
附图说明
图1改进的文档中多主题的关键词提取技术的结构流程图
图2n元语法分词算法图解
图3中文文本预处理过程流程图
图4n个词语构成一个多主题网络模型图m
图5多主题网络模型图m′
具体实施方式
为了解决从多主题文档中找出一些非高频并且对主题贡献大的词作为关键词、实现自动提取文档中主题词的问题以及常用的关键词提取方法精度不高的问题、结合图1-图5对本发明进行了详细说明,其具体实施步骤如下:
步骤1:利用中文分词技术对文本进行分词处理,其具体分词技术过程如下:
步骤1.1:根据《分词词典》找到待分词句子中与词典中匹配的词,把待分词的汉字串完整的扫描一遍,在系统的词典里进行查找匹配,遇到字典里有的词就标识出来;如果词典中不存在相关匹配,就简单地分割出单字作为词;直到汉字串为空。
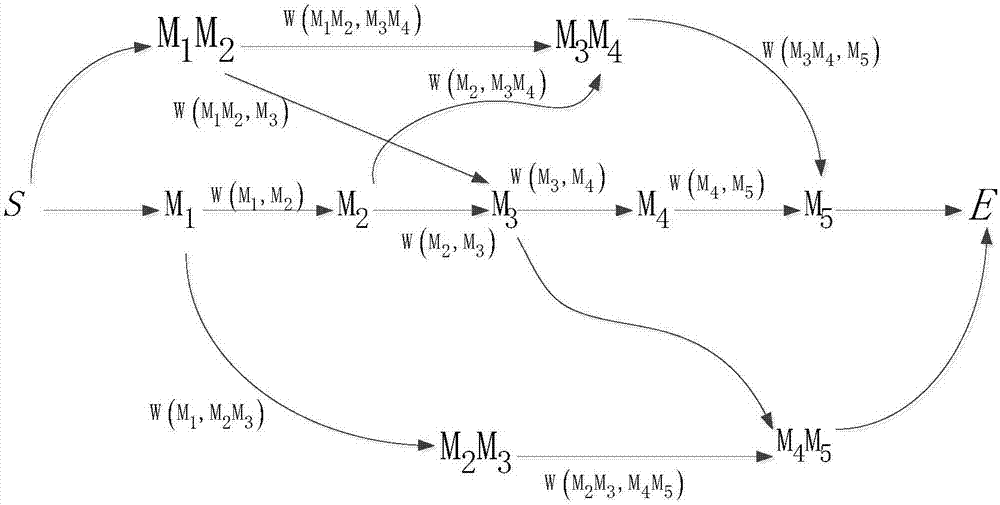
步骤1.2:依据概率统计学,将待分词句子拆分为网状结构,即得n个可能组合的句子结构,把此结构每条顺序节点依次规定为sm1m2m3m4m5e,其结构图如图2所示。
步骤1.3:基于信息论方法,给上述网状结构每条边赋予一定的权值,其具体计算过程如下:
根据《分词词典》匹配出的字典词与未匹配的单个词,第i条路径包含词的个数为ni。即n条路径词的个数集合为(n1,n2,…,nn)。
得min()=min(n1,n2,…,nn)
在上述留下的剩下的(n-m)路径中,求解每条相邻路径的权重大小。
在统计语料库中,计算每个词的信息量x(ci),再求解路径相邻词的共现信息量x(ci,ci+1)。既有下式:
x(ci)=|x(ci)1-x(ci)2|
上式x(ci)1为文本语料库中词ci的信息量,x(ci)2为含词ci的文本信息量。
x(ci)1=-p(ci)1lnp(ci)1
上式p(ci)1为ci在文本语料库中的概率,n为含词ci的文本语料库的个数。
x(ci)2=-p(ci)2lnp(ci)2
上式p(ci)2为含词ci的文本数概率值,n为统计语料库中文本总数。
同理x(ci,ci+1)=|x(ci,ci+1)1-x(ci,ci+1)2|
x(ci,ci+1)1为在文本语料库中词(ci,ci+1)的共现信息量,x(ci,ci+1)2为相邻词(ci,ci+1)共现的文本信息量。
同理x(ci,ci+1)1=-p(ci,ci+1)1lnp(ci,ci+1)1
上式p(ci,ci+1)1为在文本语料库中词(ci,ci+1)的共现概率,m为在文本库中词(ci,ci+1)共现的文本数量。
x(ci,ci+1)2=-p(ci,ci+i)2lnp(ci,ci+i)2
p(ci,ci+1)2为文本库中相邻词(ci,ci+1)共现的文本数概率。
综上可得每条相邻路径的权值为
w(ci,ci+1)=x(ci)+x(ci+1)-2x(ci,ci+1)
步骤1.4:找到权值最大的一条路径,即为待分词句子的分词结果,其具体计算过程如下:
有n条路径,每条路径长度不一样,假设路径长度集合为(l1,l2,…,ln)。
假设经过取路径中词的数量最少操作,排除了m条路径,m<n。即剩下(n-m)路径,设其路径长度集合为
则每条路径权重为:
上式
权值最大的一条路径:
步骤2:根据停用表对文本词汇进行去停用词处理,得到词汇集w,其具体描述如下:
停用词是指在文本中出现频率高,但对于文本标识却没有太大作用的单词。去停用词的过程就是将特征项与停用词表中的词进行比较,如果匹配就将该特征项删除。
综合分词和删除停用词技术,中文文本预处理过程流程图如图3。
步骤3:构造相关度函数re(wi,wj)对上述词汇集w进行从大到小排序处理,取前n个词语构成一个多主题网络模型m,其具体计算过程如下:
相关度函数re(wi,wj):
上式ε为修正系数,d(wi,wj)为词汇(wi,wj)间的差值。
d(wi,wj)=|r1(wi,wj)-r2(wi,wj)|
上式r1(wi,wj)、r2(wi,wj)都为词汇间相关度值,g(wi/wj)为wi相对于wj′的共现度,g(wj/wi)为wj相对于ci′的共现度,n(wi,wj)为两词汇(wi,wj)在一句话中出现的次数,n(wi)为词汇wi在文档中出现的次数,n(wj)为词汇wj在文档中出现的次数。
提取前n位作为文本的关键词,即根据re(wi,wj)值从大到小提取前n个关键词。
步骤4:构造目标函数
目标函数
上式ρ为修正系数,tj为主题影响因子。
上式j为第j个主题,主题个数为g个,h为主题中词汇的个数,它是个变量,主题不同,h的值就不同,
根据
步骤5:构造叉函数
叉函数:
上式g(ci′/wj′)为ci′相对于wj′的共现度,g(wj′/ci′)为wj′相对于ci′的共现度,上式mf为两词汇本体概念共同的父节点密度,sf为两词汇本体概念共同的父节点深度,nf为义原网状结构中对应父节点所在的树状结构中的最大节点密度值,df为义原网状结构中对应父节点所在的树状结构中的树的度
同理
上式n(ci′,wj′)为连接词ci′与词汇集中词汇wj′在一句话中出现的次数,n(wj′)为词汇集中词汇wj′在文档中出现的次数,n(ci′)为连接词ci′在文档中出现的次数,这里n(ci′)≠n(wj′)、n(ci′,wj′)=n(wj′,ci′)。
根据叉函数
改进的文档中多主题的关键词提取技术,其伪代码计算过程如下:
输入:一个文档
输出:提取文档中的核心关键词。
- 还没有人留言评论。精彩留言会获得点赞!