基于贝叶斯的模糊c均值算法实现搜索引擎关键词优化的制作方法
本发明涉及语义网络技术领域,具体涉及基于贝叶斯的模糊c均值算法实现搜索引擎关键词优化。
背景技术:
随着互联网经济的迅速发展以及网络的深入普及,搜索引擎已经成为企业展示自己的一种很重要的舞台,很多企业尤其是中小型企业为了使自己的网站排名靠前,选择了成本低,操作容易,符合用户搜索偏好的搜索引擎优化方式。目前关于搜索引擎优化方法的理论研究已较为丰富,但借助实证去分析搜索引擎优化方法带来的效果的却很少。如何获得较好的搜索引擎自然排名,增加网站的曝光率与转化率,最终实现直接销售,是中小企业普遍关注的焦点问题。搜索引擎优化,简称通俗的讲是通过对网站整体架构,网页内容、关键词以及网页内的链接进行相关的优化工作,提高其在特定搜索引擎上搜索结果中的排名,从而提高网站访问量,最终提升网站的销售能力或宣传能力的技术。搜索引擎优化技术包括黑帽技术和白帽技术,其中黑帽技术表示违反搜索引擎优化规则的恶意优化技术,在关键词优化技术中表现为在页面中堆砌关键词或放置无关关键词以提高在搜索引擎中的排名,目前各搜索引擎已经引入相关技术和规则对使用黑帽技术的网站进行惩罚;白帽技术则表示被搜索引擎认可的优化技术。目前国内外对关键词优化的理论研究和技术应用比较多,但暂未提出一个有效的方法来简化关键词分析流程,也没有一个完善的机制来管理关键词优化策略和进度。基于上述需求,本发明提供了一种基于贝叶斯的模糊c均值算法实现搜索引擎关键词优化。
技术实现要素:
针对于关键词优化实现搜索引擎优化的技术问题,本发明提供了一种基于vsm的模糊c均值聚类算法实现搜索引擎关键词优化。
为了解决上述问题,本发明是通过以下技术方案实现的:
步骤1:根据企业业务确定核心关键词,利用搜索引擎搜集相关关键字,这些关键字在搜索引擎中有相应数据项,如本国每月搜索量、竞争程度和估算每次点击费用(cpc)等
步骤2:结合企业产品和市场分析,筛选降维上述搜索到的相关关键字集合;
步骤3:针对筛选降维后的关键词集合,通过搜索引擎搜索关键词对应的页面,这里记录首页网页数和总搜索页面数,即每个关键词由五维向量再降维为四维的。
步骤4:基于贝叶斯的模糊c均值算法,对上述关键词进行聚类处理,其具体子步骤如下:
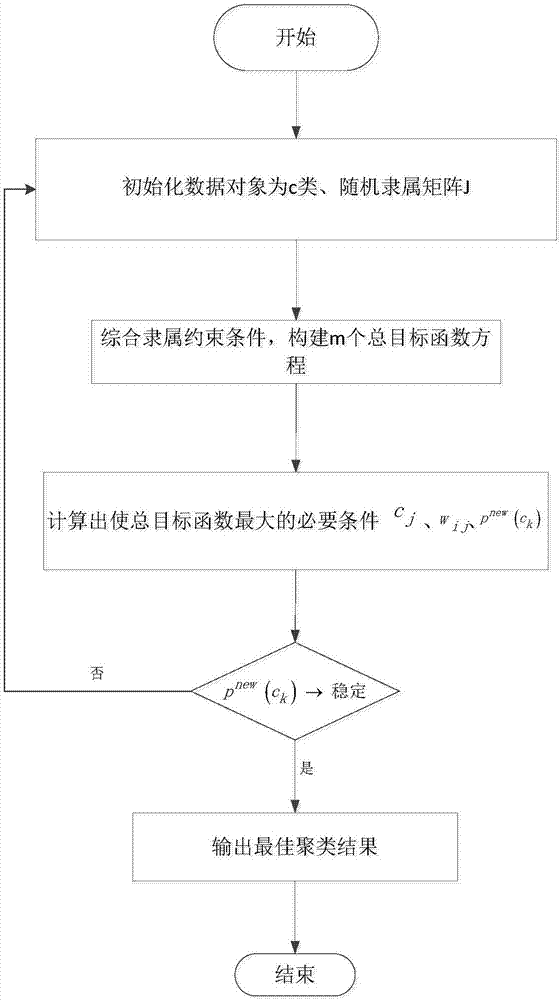
步骤4.1:利用基于ε领域的k-means算法初始化为c类。
步骤4.2:用值[0,1]间的随机数初始化隶属矩阵j,使其满足隶属的整个约束条件
步骤4.3:初始化每个ε领域的概率分布,构建c类总目标函数
步骤4.4:根据上式wij、cj、pnew(ck)的收敛性,重新计算各簇中心
步骤4.5:如果pnew(ck)发生变化,则转到步骤4.2,重新计算隶属矩阵j,否则迭代结束,输出聚类结果。
步骤5:根据企业具体情况,综合关键词效能优化和价值率优化,选择合适的关键词优化策略达到网站优化目标。
本发明有益效果是:
1,此算法可以精简关键词分析流程,进而减少整个网站优化工作量。
2,此算法的运行时间复杂度低,处理速度更快。
3、此算法具有更大的利用价值。
4、能帮助网站在短时间内快速提升其关键词的排名。
5、为企业网站带来一定的流量和询盘,从而达到理想的网站优化目标。
6、此算法应用了贝叶斯原理得到的分类结果更符合经验值。
7、减少了孤立点对聚类结果的影响。
8、结合模糊c均值算法可以避免过早收敛,避免陷入局部最优解。
附图说明
图1基于贝叶斯的模糊c均值算法实现搜索引擎关键词优化结构流程图
图2基于贝叶斯的模糊c均值算法在聚类分析中的应用流程图
具体实施方式
为了解决关键词优化实现搜索引擎优化的技术问题,结合图1-图2对本发明进行了详细说明,其具体实施步骤如下:
步骤1:根据企业业务确定核心关键词,利用搜索引擎搜集相关关键字,这些关键字在搜索引擎中有相应数据项,如本国每月搜索量、竞争程度和估算每次点击费用(cpc)等。
步骤2:结合企业产品和市场分析,筛选降维上述搜索到的相关关键字集合;
步骤3:针对筛选降维后的关键词集合,通过搜索引擎搜索关键词对应的页面,这里记录首页网页数和总搜索页面数,即每个关键词由五维向量再降维为四维的,其具体计算过程如下:
这里相关关键词个数为m,既有下列m×5矩阵:
ni、ldi、cpci、nis、niy依次为第i个关键词对应的本国每月搜索量、竞争程度、估算每次点击费用(cpc)、首页网页数、总搜索页面数。
再降维为四维,即
xi∈(1,2,…,m)为搜索效能,zi∈(1,2,…,m)为价值率,即为下式:
步骤4:基于贝叶斯的模糊c均值聚类算法,对上述关键词进行聚类处理,其具体子步骤如下:
步骤4.1:利用基于ε领域的k-means算法初始化为c类。
步骤4.2:用值[0,1]间的随机数初始化隶属矩阵j,使其满足隶属的整个约束条件;其具体计算过程如下:
根据ε领域初始化数据对象集合d划分为c类;
初始化隶属矩阵j为m×c:
wij为关键词i属于j类的程度系数,即j∈(1,2,…,c)、i∈(1,2,…,m)。
隶属的整个约束条件为:
步骤4.3:初始化每个ε领域的概率分布,构建c类总目标函数
上式xi为关键词,cj为j类。
上式
综合隶属约束条件,构建m个方程组:
λi(i=1,…,m)是m个约束式的拉格朗日算子,对上述式子进行求导,对所有输入参量求导,即可求得使
wij=p(cj\xi)
上式
步骤4.4:根据上式wij、cj、pnew(ck)的收敛性,重新计算各簇中心,其具体计算过程如下:
当pnew(ck)收敛于一定值时,wij就收敛一定值,进而cj收敛于一定值,则找到了最佳聚类结果,否则没有找到。
步骤4.5:如果pnew(ck)发生变化,则转到步骤4.2,重新计算隶属矩阵j,否则迭代结束,输出聚类结果。
基于贝叶斯的模糊c均值聚类算法的具体结构流程如图2。
步骤5:根据企业具体情况,综合关键词效能优化和价值率优化,选择合适的关键词优化策略达到网站优化目标。
基于贝叶斯的模糊c均值算法实现搜索引擎关键词优化,其伪代码过程
输入:网站提取的核心关键词,基于ε领域初始化为c簇
输出:wij、cj、pnew(ck)收敛的c个簇或总目标函数
- 还没有人留言评论。精彩留言会获得点赞!