GPU任务调度方法及系统与流程
本发明涉及处理器技术领域,特别是涉及gpu技术领域,具体为一种gpu任务调度方法及系统。
背景技术:
随着互联网用户的快速增长,数据量的急剧膨胀,数据中心对计算的需求也在迅猛上涨。诸如深度学习在线预测、视频转码以及图片压缩解压缩等各类新型应用的出现对计算的需求已远远超出了传统cpu处理器的能力所及。gpu等有别于cpu的新型处理器的出现为数据中心带来了巨大的体系结构变革。
传统的高性能计算集群通过mpi等方式作为主要通信方式,利用队列系统让每个任务独占式地享用集群中的资源。相对于高性能计算集群中的独占式访问,数据中心需要同时为多个用户提供服务。因此为了提高数据中心的利用率,用户往往需要共享数据中心中的计算资源。另外,在实际环境中,不同的用户会有不同的应用请求服务,且不同的服务请求到达的时间也各不相同,在此情况下,如何有效地解决资源的竞争和共享成为了提高数据中心资源的利用率的关键。动态任务调度就是最常见的共享计算资源的解决方案。
对于多任务共享cpu以及cpu的任务调度,研究人员已经进行了大量的研究。而对于gpu,由于其产生之初便是为了高性能计算的独占式服务而设计的,因此其原本的硬件架构并不支持多任务共享gpu。gpukernel是一段在gpu上执行的代码。当调用gpu计算时,需要从cpu端将kernel和对应的输入参数传递到gpu上。kernel可以并发执行,目前,用户可通过定义可并行的kernelstream来实现kernel的并发执行。stream可理解为一堆异步的操作,同一stream中的操作有严格的执行顺序,而不同stream之间则没有该限制。利用不同stream异步执行的特性,就可以通过协调不同stream来提高资源的利用率。从软件角度来看,不同stream中的不同操作可以并行执行,但在硬件角度却不一定如此。kernel并行的程度依赖于pcie接口的带宽以及kernel在每个streamingmultiprocessor(sm)中可获得的资源,在资源不足的情况下,stream仍然需要等待其他的stream完成执行才能开始执行。因此,多任务共享gpu需要打破现有gpu硬件框架的限制。意识到该问题,学术界和工业界均开始重视起gpu的硬件级共享以及抢占支持。
cpu上的抢占式多任务是通过上下文切换实现的,上下文切换引入的额外的延迟和吞吐量损失对于cpu来说是完全可以接收的。而对于gpu来说,由于gpu架构以及相关特性与cpu存在较大的差异,在gpu上实现抢占式多任务将会引入相对cpu上大得多的额外开销。仅对于一个sm来说,上下文切换可能会涉及到近256kb大小的寄存器以及48kb的共享内存的内容切换。而目前gpu的性能在很大程度上受到内存带宽的限制,由于内存请求引入的延迟过大,即使gpu的多线程计算能力也无法完全掩盖内存延迟所带来的影响。考虑到内存请求对gpu性能的整体影响,在设计调度算法时也不能忽视调度算法所引起的额外的内存请求。
现有技术中,一种方式是chimera通过将不同的sm划分给不同的kernel实现多kernel共享一个gpu。另外,chimera针对不同的应用场景提出了以下三种不同的抢占策略:
1.contextswitching:即通过把一个sm上的正在运行的threadblock(tb)的上下文保存到内存里,并发射一个新的kernel来抢占当前sm。
2.draining:暂停发射新的kernel,直到一个正在运行的kernel的所有tb运行结束。
3.flushing:对于具有“幂等性”(idempotent)kernel,即使强制结束当前正在运行的tb,重新启动后也不会对kernel最后的结果产生影响,因此在上下文切换时可直接将其tb强行中止,且不需要保存任何上下文信息。
三种策略各有优劣,其中contextswitching所引入的额外开销对于延迟和吞吐量的影响居于另外两个策略之间;draining对吞吐量的影响最小,但对延迟的影响最大;flushing对延迟几乎没有影响,但若是抢占发生在tb即将运行结束时,则会对吞吐量造成很大的影响。
当有一个新的kernel到达时,chimera会根据三种策略所引入的开销以及当前正在运行的kernel的状态,选择将被抢占的sm,以及其上运行的tb被抢占的方式,从而达到以一个较小的开销实现抢占的效果。
chimera中采取的三种策略均存在比较严重的缺点,如果是通过内存进行切换,就会产生大量的内存访问,对性能产生影响。如果等待tb结束,则会导致不可预期的抢占延迟。而“幂等性”则对kernel本身有比较大的要求。
这三种策略的综合结果是能够在抢占发生时,如何根据当前运行环境的状态,尽量减少抢占过程所引入的开销,而对于任务动态到达的场景,chimera没有提出相对应的调度策略,无法实现全局的吞吐量优化。
现有技术中,还有一种方式是simultaneousmultikernel通过在每个sm增加抢占机制,实现部分上下文切换(partialcontextswitching)从而能够对正在运行的kernel进行部分资源的抢占,使得多个kernel可以共享一个sm的资源。对于多个kernel之间的资源分配,该研究采取的是主导资源公平算法(drf),drf是一种通用的多资源的max-minfairness分配策略。drf的主题思想是在多用户环境下一个用户的资源分配应该由用户的主导份额的资源决定,主导份额的资源指的是在所有已经分配给用户的多种资源中,占据最大份额的一种资源。在gpu中总共有四种资源:寄存器、共享内存、线程以及tb。
simultaneousmultikernel提供了让不同kernel共享gpu的硬件机制,但没有对共享gpu的kernel进行进一步限制。在数据中心的应用场景下,simultaneousmultikerne研究表明,不同的kernel具有不同的资源利用率。有些kernel几乎不使用scratchpad内存,而是频繁的访问l1缓存。而另一些kernel则正相反。这导致了gpu整体资源利用率的低下。虽然simultaneousmultikernel在硬件上允许kernel之间利用互补的资源,但其并没有给出调度动态到来的任务使其资源互补的算法。因此,在数据中心的应用场景下,simultaneousmultikernel无法彻底解决资源利用率的问题。
技术实现要素:
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种gpu任务调度方法及系统,用于解决现有技术中gpu任务调度存在的影响内存性能,延迟高以及资源利用率低的问题。
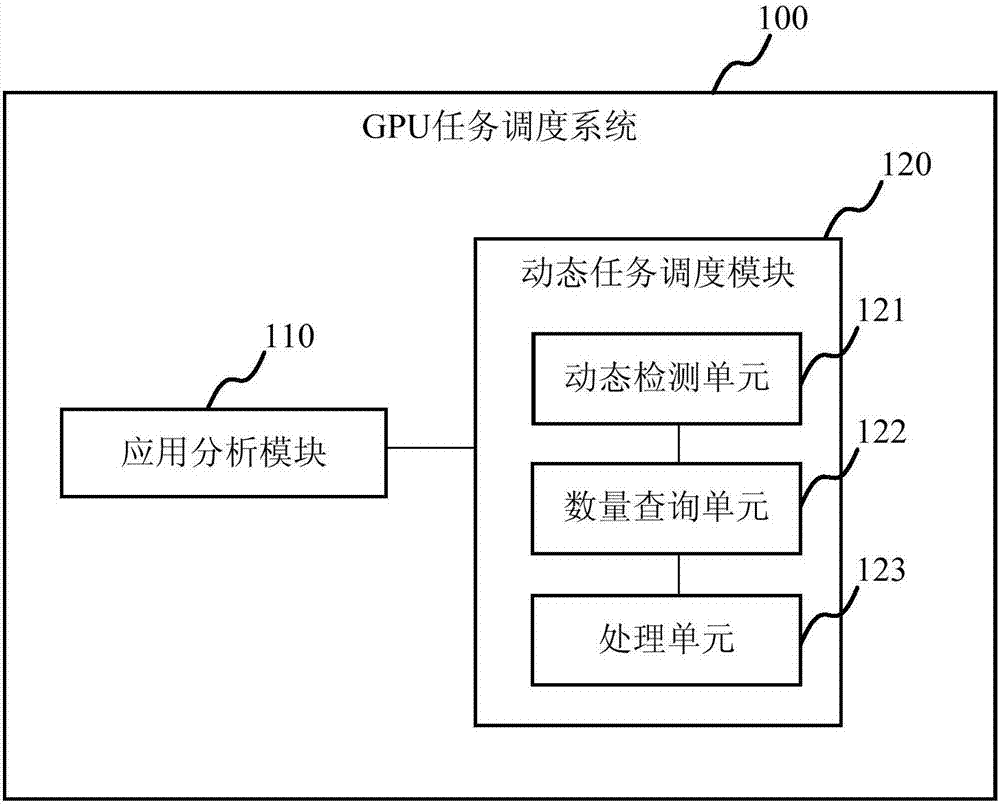
为实现上述目的及他相关目的,本发明在一方面提供一种gpu任务调度系统,所述任务调度系统包括:应用分析模块,用于接收用户的应用程序请求,分析应用程序,根据所述应用程序的类型和输入数据集的大小分析获取所述应用程序的各个kernel的指令数;动态任务调度模块,包括:动态检测单元,用于动态检测、接收用户的应用程序请求并将接收的用户的应用程序请求发送至所述应用分析模块;数量查询单元,用于从运行时系统查询当前运行的kernel数量;处理单元,用于判断当前运行的kernel数量是否达到预设的上限值,若否,则从被抢占的kernel以及新到达的kernel中挑选与当前运的kernel组合形成kernel组合优先级最高的kernel并将挑选的kernel发射至运行时系统,若是,则继续判断被抢占的kernel和新到达的kernel中是否存在与当前运行kernel进行组合得到更高优先级的kernel组合,若否,则保持当前运行的kernel状态,若是,则继续判断抢占程序后的gpu性能提升是否大于抢占过程所占用的gpu开销,若是,则进行抢占,若否,则保持当前运行的kernel状态。
于本发明的一实施例中,被抢占的kernel的优先级高于新到达的kernel的优先级,使得gpu性能越好的kernel组合的优先级越高。
于本发明的一实施例中,通过预设的归一化ipc衡量gpu性能,归一化ipc的计算公式为:
于本发明的一实施例中,抢占程序后的gpu性能提升根据抢占前归一化ipc和抢占后归一化ipc的对比获取,其中:抢占前归一化ipc为:
抢占后归一化ipc为:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb;
其中,normalized_ipci表示为第i个kernel的指令数,running1表示为正在运行的第一个kernel,running2表示正在运行的第二个kernel,rest_cycle表示为正在运行的两个kernel还能一起运行的时钟周期数,rest_instrunning1表示为正在运行的第一个kernel剩余的指令数,ipcrunning1表示为正在运行的第一个kernel所表现出的ipc,rest_instrunning2表示为正在运行的第二个kernel剩余的指令数,ipcrunning2表示为正在运行的第二个kernel所表现出的ipc,norm_ipci表示为第i个kernel所表现出的归一化ipc,preempt_cycle表示为抢占过程所持续的时钟周期数,miss_rate表示为未被抢占的kernel发生高速缓存缺失的频率,reg表示为被抢占的kernel中每个线程块占用寄存器的字节数,smem表示为被抢占的kernel中每个线程块占用共享内存的字节数,tb表示为被抢占的kernel中线程块的数量。
于本发明的一实施例中,抢占过程所占用的gpu开销通过抢占过程中归一化ipc衡量,所述抢占过程中归一化ipc为:
norm_ipcrunning1×decay_rate×preempt_cycle;
其中,norm_ipcrunning1表示为未被抢占kernel所表现出的归一化ipc,decay_rate表示为未被抢占的kernel由于抢占过程而导致的ipc衰减率,preempt_cycle表示为抢占过程所持续的时钟周期数,kernel∈memory_intensive表示为未被抢占的kernel属于内存密集型kernel,kernel∈compute_intensive表示为未被抢占的kernel属于计算密集型kernel。
实现上述目的,本发明在另外一方面还提供一种芯片,所述芯片为异构多核硬件结构,所述芯片内装设有如上所述的gpu任务调度系统。
实现上述目的,本发明在另外一方面还提供一种gpu任务调度方法,所述任务调度方法包括:动态检测并接收用户的应用程序请求,分析应用程序,根据所述应用程序的类型和输入数据集的大小分析获取所述应用程序的各个kernel的指令数;从运行时系统查询当前运行的kernel数量,并判断当前运行的kernel数量是否达到预设的上限值,若否,则从被抢占的kernel以及新到达的kernel中挑选与当前运的kernel组合形成kernel组合优先级最高的kernel并将挑选的kernel发射至运行时系统,若是,则继续判断被抢占的kernel和新到达的kernel中是否存在与当前运行kernel进行组合得到更高优先级的kernel组合,若否,则保持当前运行的kernel状态,若是,则继续判断抢占程序后的gpu性能提升是否大于抢占过程所占用的gpu开销,若是,则进行抢占,若否,则保持当前运行的kernel状态。
于本发明的一实施例中,被抢占的kernel的优先级高于新到达的kernel的优先级,使得gpu性能越好的kernel组合的优先级越高。
于本发明的一实施例中,通过预设的归一化ipc衡量gpu性能,归一化ipc的计算公式为:
其中,norm_ipc表示为归一化ipc,ipcshare表示为kernel与其他kernel共享gpu时gpu表现出的ipc,ipcalone表示为kernel独占gpu时gpu表现出的ipc。
于本发明的一实施例中,抢占程序后的gpu性能提升根据抢占前归一化ipc和抢占后归一化ipc的对比获取,其中:
抢占前归一化ipc为:
抢占后归一化ipc为:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb;
其中,normalized_ipci表示为第i个kernel的指令数,running1表示为正在运行的第一个kernel,running2表示正在运行的第二个kernel,rest_cycle表示为正在运行的两个kernel还能一起运行的时钟周期数,rest_instrunning1表示为正在运行的第一个kernel剩余的指令数,ipcrunning1表示为正在运行的第一个kernel所表现出的ipc,rest_instrunning2表示为正在运行的第二个kernel剩余的指令数,ipcrunning2表示为正在运行的第二个kernel所表现出的ipc,norm_ipci表示为第i个kernel所表现出的归一化ipc,preempt_cycle表示为抢占过程所持续的时钟周期数,miss_rate表示为未被抢占的kernel发生高速缓存缺失的频率,reg表示为被抢占的kernel中每个线程块占用寄存器的字节数,smem表示为被抢占的kernel中每个线程块占用共享内存的字节数,tb表示为被抢占的kernel中线程块的数量。
于本发明的一实施例中,抢占过程所占用的gpu开销通过抢占过程中归一化ipc衡量,所述抢占过程中归一化ipc为:
norm_ipcrunning1×decay_rate×preempt_cycle;
其中,norm_ipcrunning1表示为未被抢占kernel所表现出的归一化ipc,decay_rate表示为未被抢占的kernel由于抢占过程而导致的ipc衰减率,preempt_cycle表示为抢占过程所持续的时钟周期数,kernel∈memory_intensive表示为未被抢占的kernel属于内存密集型kernel,kernel∈compute_intensive表示为未被抢占的kernel属于计算密集型kernel。
如上所述,本发明的一种gpu任务调度方法及系统,具有以下有益效果:
1、本发明提供了一个高性能的gpu抢占式任务调度系统,其基于硬件式抢占机制和高性能任务调度算法,可以在无需升级硬件设备的情况下,应对应用请求动态到达的情况,有效降低延迟,提高资源利用率,提高gpu的性能。
2、本发明的成果可以用于构建具有商业意义的、基于cpu和异构计算芯片gpu的异构数据中心,面向用户提供程序动态任务调度服务。
3、本发明简单实用,具有良好的市场前景和广泛的适用性。
附图说明
图1显示为本发明的一种gpu任务调度方法的流程示意图。
图2显示为本发明的一种gpu任务调度系统的原理框图。
图3显示为本发明与现有的软件层的关系架构图。
图4显示为本发明的gpu任务调度方法及系统的实施过程示意图。
元件标号说明
100gpu任务调度系统
110应用分析模块
120动态任务调度模块
121动态检测单元
122数量查询单元
123处理单元
s101~s108步骤
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
本实施例的目的在于提供一种gpu任务调度方法及系统,用于解决现有技术中gpu任务调度存在的影响内存性能,延迟高以及资源利用率低的问题。以下将详细阐述本发明的一种gpu任务调度方法及系统的原理及实施方式,使本领域技术人员不需要创造性劳动即可理解本发明的一种gpu任务调度方法及系统。
具体地,本实施例旨在实现一个高性能的gpu抢占式任务调度,其基于硬件抢占机制和高性能任务调度算法,分别完成基于gpu的多任务共享以及抢占和在任务动态到达的情况下动态调度的工作。便于开发人员在无需关心硬件系统以及调度细节的前提下获得高吞吐和低延迟。
以下对本实施例的gpu任务调度方法及系统进行详细说明。
如图1所示,本实施例提供一种gpu任务调度方法,所述任务调度方法包括:
步骤s101,动态检测并接收用户的应用程序请求,分析应用程序,根据所述应用程序的类型和输入数据集的大小分析获取所述应用程序的各个kernel的指令数。
步骤s102,从运行时系统查询当前运行的kernel数量。
步骤s103,判断当前运行的kernel数量是否达到预设的上限值,若否,则执行步骤s104,若是,则执行步骤s105。
步骤s104,从被抢占的kernel以及新到达的kernel中挑选与当前运的kernel组合形成kernel组合优先级最高的kernel并将挑选的kernel发射至运行时系统。
步骤s105,继续判断被抢占的kernel和新到达的kernel中是否存在与当前运行kernel进行组合得到更高优先级的kernel组合,若否,则执行步骤s106,若是,则执行步骤s107。
步骤s106,保持当前运行的kernel状态。
步骤s107,继续判断抢占程序后的gpu性能提升是否大于抢占过程所占用的gpu开销,若是,则执行步骤s108,进行抢占,若否,则返回步骤s106保持当前运行的kernel状态。
以下对本实施例的gpu任务调度方法进行详细说明。
根据kernel在运行过程中对不同类型资源的需求程度不同,可将kernel分为内存密集型和计算密集型两种类型。计算密集型的kernel对计算资源的需求较大,而内存密集型的kernel在运行过程中对内存的访问表现的比较频繁。由于两种类型的kernel对资源的需求表现为互补,因此当两者共享gpu时,可最大程度的提高资源的利用率,且在最大程度上避免发生资源争抢。另外,由于gpu的性能在很大程度上被内存带宽所限制,内存密集型的kernel共享gpu时所表现出的性能结果要差于计算密集型的kernel共享gpu时的性能结果。根据不同组合的kernel所表现出的性能结果,将性能表现更好的kernel组合赋予更高的优先级。该优先级便作为调度过程中进行发射kernel以及实施抢占的重要依据。另外,出于对延迟的考虑,已经被抢占的kernel在优先级上要高于新到达的kernel,即在组合优先级相等的情况下,优先会将已经被抢占过的kernel发射上去。
所以于本实施例中,被抢占的kernel的优先级高于新到达的kernel的优先级,使得gpu性能越好的kernel组合的优先级越高。
当需要发生抢占时,除了考虑优先级的影响,还要考虑抢占过程所引入的额外开销。于本实施例中,通过预设的归一化ipc(instructionpercycle,每周期执行指令数)衡量gpu性能,归一化ipc的计算公式为:
其中,norm_ipc表示为归一化ipc,ipcshare表示为kernel与其他kernel共享gpu时gpu表现出的ipc,ipcalone表示为kernel独占gpu时gpu表现出的ipc。
为了实现吞吐量的最大化,则要尽可能保持各时刻运行分kernel的归一化ipc之和最大。若被抢占的kernel或者新到达的kernel与正在运行的kernel能到组合出比当前运行的kernel组合更高优先级的组合,则进一步考虑是否进行抢占。判断是否抢占的逻辑取决于抢占前和抢占后的归一化ipc的对比,即抢占程序后的gpu性能提升根据抢占前归一化ipc和抢占后归一化ipc的对比获取。抢占前的归一化ipc取决于当前正在运行的kernel,动态调度模块可通过向运行时系统层发出请求获取当前正在运行的kernel的状态,其中包括各个kernel已经运行的指令数和实际运行的ipc,结合程序分析模块分析出的各个kernel的总指令数,则可以预测出抢占前归一化ipc为:
抢占后归一化ipc为:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb;
其中,normalized_ipci表示为第i个kernel的指令数,running1表示为正在运行的第一个kernel,running2表示正在运行的第二个kernel,rest_cycle表示为正在运行的两个kernel还能一起运行的时钟周期数,rest_instrunning1表示为正在运行的第一个kernel剩余的指令数,ipcrunning1表示为正在运行的第一个kernel所表现出的ipc,rest_instrunning2表示为正在运行的第二个kernel剩余的指令数,ipcrunning2表示为正在运行的第二个kernel所表现出的ipc,norm_ipci表示为第i个kernel所表现出的归一化ipc,preempt_cycle表示为抢占过程所持续的时钟周期数,miss_rate表示为未被抢占的kernel发生高速缓存缺失的频率,reg表示为被抢占的kernel中每个线程块占用寄存器的字节数,smem表示为被抢占的kernel中每个线程块占用共享内存的字节数,tb表示为被抢占的kernel中线程块的数量。
于本实施例中,抢占过程所占用的gpu开销通过抢占过程中归一化ipc衡量,所述抢占过程中归一化ipc为:
norm_ipcrunning1×decay_rate×preempt_cycle;
其中,norm_ipcrunning1表示为未被抢占kernel所表现出的归一化ipc,decay_rate表示为未被抢占的kernel由于抢占过程而导致的ipc衰减率,preempt_cycle表示为抢占过程所持续的时钟周期数。
抢占后的归一化ipc由两个阶段组成,一部分是抢占过程中的ipc表现,另一部分是抢占完成后的ipc表现。抢占发生时,未被抢占的kernel仍在继续运行,而被抢占的kernel需要先将相关的上下文保存到内存中,这其中涉及到大量的内存访问操作。根据实际测试情况可知,当未被抢占的kernel属于内存密集型类型的kernel时,其ipc会减小到原来的83%~97%不等,而计算密集型的kernel基本不受影响,因此根据kernel的类型,decay_rate定义如下:
kernel∈memory_intensive表示为未被抢占的kernel属于内存密集型kernel,kernel∈compute_intensive表示为未被抢占的kernel属于计算密集型kernel
抢占过程所占用的时钟周期数(cycle)受到两个因素的影响:第一个因素为被换出的kernel的上下文的大小,其中包括该kernel所占用的tb,以及每个tb所占用的寄存器数量和共享内存的大小,这些数量决定了保存完整上下文所需要执行的内存访问操作的数量,通过统计测试结果可知,抢占过程所持续的cycle数与所要保存的字节数成正相关,且可通过线性模型对两者的关系进行拟合;另一个因素是未被换出的kernel执行内存访问操作的频繁程度,由于抢占过程中涉及到较多的内存操作,若未被抢占的kernel也涉及到较多的内存操作,会更加拖慢抢占过程,可通过l2cachemiss的频率来衡量kernel涉及内存操作的频率,研究过程中发现,抢占过程cycle数和上下文切换字节数的线性模型的斜率与正在运行的kernel的cachemiss频率成正相关,且成线性关系。因此抢占过程的cycle数可大致拟合以下关系式:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb。
抢占过程中归一化ipc定义为:norm_ipcrunning1×decay_rate×preempt_cycle。
抢占后的ipc无法精确得知,可通过历史数据获取一个经验值,抢占后的归一化ipc定义为:
根据抢占前归一化ipc和抢占后归一化ipc的对比获取抢占程序后的gpu性能提升,即
两者相减。具体地,计算抢占前归一化ipc和抢占后归一化ipc的差值,获取抢占程序后的gpu性能提升。
为实现上述gpu任务调度方法,本实施例提供一种gpu任务调度系统100,如图2所示,所述gpu任务调度系统100包括:应用分析模块110和动态任务调度模块120。以下对本实施例中的任务用分析模块和动态任务调度模块120进行详细说明。
如图3所示,本实施例中gpu任务调度系统100的软件架构分为三层:应用层、调度层和运行时系统层。其中,应用层主要由用户应用所组成,用户遵循一般的gpu编程规则,编写能在gpu上运行的kernel程序,即可在本发明所提供的软件架构中运行。所述gpu任务调度系统100运行于调度层,即调度层运行应用分析模块110和动态任务调度模块120。运行时系统层是系统的主要组成部分之一,在用户可执行程序运行时,运行时系统通过调度层的调度结果调度任务或者对正在运行的程序进行抢占。运行时系统层通过在每个sm增加抢占机制,实现了部分上下文切换,从而能够对正在运行的kernel进行部分资源的抢占,使得多个kernel可以共享一个sm的资源。当运行时系统层接收到调度层发射的新的kernel,运行时系统层优先使用各sm中未被占用的资源为新kernel分配tb,当资源不足时,需要抢占部分正在运行的kernel的资源。被换出的tb的上下文被保存到内存中,换出过程结束后,新的kernel的tb被换入,整个上下文切换过程中正在运行的kernel的tb不会被打断。需要进行抢占时,被换出的kernel的tb会被全部换出,其上下文同样被保存到内存中。
其中,1、用户与应用层的交互包括:a)用户根据gpu编程规范编写用户应用程序;b)
经过本地调试后,确保程序正确。
2、用户与调度层的交互包括:a)用户向调度层提交应用请求;b)应用分析模块110接收用户请求。
3、用户与运行时系统层的交互包括:a)运行时系统层向用户返回运行结果。
4、调度层之间的交互包括:a)应用分析模块110向动态任务调度模块120转移用户请求;b)应用分析模块110向动态任务调度模块120发送应用分析结果。
5、调度层与运行时系统层的交互包括:a)调度层向运行时系统层发送发射应用请求;b)
调度层向运行时系统层发送抢占请求;c)运行时系统层向调度层发送运行kernel状态。
具体地,于本实施中,所述应用分析模块110负责接收用户的应用请求并分析用户应用程序,通过机器学习算法,根据所输入的应用程序类型以及输入数据集的大小,分析出应用程序的指令数,其输出信息将作为动态任务调度模块120的重要参考信息。具体地,所述应用分析模块110用于接收用户的应用程序请求,分析应用程序,根据所述应用程序的类型和输入数据集的大小分析获取所述应用程序的各个kernel的指令数。
所述动态任务调度模块120与所述应用分析模块110是一个有机整体,但各司其职。所述动态任务调度模块120接收来自用户和应用分析程序的输入信息,并根据综合信息做出调度判断。所述动态任务调度模块120的第一个功能是接收用户的请求。由于用户的请求是动态到达,因此需要周期性地检查是否有新的用户请求到达,新到达的用户程序需要首先经过应用分析程序的分析,新的应用和其相关的分析结果将一起被发送到所述动态任务调度模块120;所述动态任务调度模块120的第二个功能是根据当前正在运行的程序状态以及新到达的应用的特征,判断是否向底层发射新的任务或者对正在运行的程序进行抢占。
具体地,所述动态任务调度模块120包括:动态检测单元121,数量查询单元122以及处理单元123。所述动态检测单元121用于动态检测、接收用户的应用程序请求并将接收的用户的应用程序请求发送至所述应用分析模块110。所述数量查询单元122用于从运行时系统查询当前运行的kernel数量。
所述处理单元123用于判断当前运行的kernel数量是否达到预设的上限值,若否,则从被抢占的kernel以及新到达的kernel中挑选与当前运的kernel组合形成kernel组合优先级最高的kernel并将挑选的kernel发射至运行时系统,若是,则继续判断被抢占的kernel和新到达的kernel中是否存在与当前运行kernel进行组合得到更高优先级的kernel组合,若否,则保持当前运行的kernel状态,若是,则继续判断抢占程序后的gpu性能提升是否大于抢占过程所占用的gpu开销,若是,则进行抢占,若否,则保持当前运行的kernel状态。
根据kernel在运行过程中对不同类型资源的需求程度不同,可将kernel分为内存密集型和计算密集型两种类型。计算密集型的kernel对计算资源的需求较大,而内存密集型的kernel在运行过程中对内存的访问表现的比较频繁。由于两种类型的kernel对资源的需求表现为互补,因此当两者共享gpu时,可最大程度的提高资源的利用率,且在最大程度上避免发生资源争抢。另外,由于gpu的性能在很大程度上被内存带宽所限制,内存密集型的kernel共享gpu时所表现出的性能结果要差于计算密集型的kernel共享gpu时的性能结果。根据不同组合的kernel所表现出的性能结果,将性能表现更好的kernel组合赋予更高的优先级。该优先级便作为调度过程中进行发射kernel以及实施抢占的重要依据。另外,出于对延迟的考虑,已经被抢占的kernel在优先级上要高于新到达的kernel,即在组合优先级相等的情况下,优先会将已经被抢占过的kernel发射上去。
所以于本实施例中,被抢占的kernel的优先级高于新到达的kernel的优先级,使得gpu性能越好的kernel组合的优先级越高。
当需要发生抢占时,除了考虑优先级的影响,还要考虑抢占过程所引入的额外开销。于本实施例中,通过预设的归一化ipc衡量gpu性能,归一化ipc的计算公式为:
其中,norm_ipc表示为归一化ipc,ipcshare表示为kernel与其他kernel共享gpu时gpu表现出的ipc,ipcalone表示为kernel独占gpu时gpu表现出的ipc。
为了实现吞吐量的最大化,则要尽可能保持各时刻运行分kernel的归一化ipc之和最大。若被抢占的kernel或者新到达的kernel与正在运行的kernel能到组合出比当前运行的kernel组合更高优先级的组合,则进一步考虑是否进行抢占。判断是否抢占的逻辑取决于抢占前和抢占后的归一化ipc的对比,即抢占程序后的gpu性能提升根据抢占前归一化ipc和抢占后归一化ipc的对比获取。抢占前的归一化ipc取决于当前正在运行的kernel,动态调度模块可通过向运行时系统层发出请求获取当前正在运行的kernel的状态,其中包括各个kernel已经运行的指令数和实际运行的ipc,结合程序分析模块分析出的各个kernel的总指令数,则可以预测出抢占前归一化ipc为:
抢占后归一化ipc为:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb;
其中,normalized_ipci表示为第i个kernel的指令数,running1表示为正在运行的第一个kernel,running2表示正在运行的第二个kernel,rest_cycle表示为正在运行的两个kernel还能一起运行的时钟周期数,rest_instrunning1表示为正在运行的第一个kernel剩余的指令数,ipcrunning1表示为正在运行的第一个kernel所表现出的ipc,rest_instrunning2表示为正在运行的第二个kernel剩余的指令数,ipcrunning2表示为正在运行的第二个kernel所表现出的ipc,norm_ipci表示为第i个kernel所表现出的归一化ipc,preempt_cycle表示为抢占过程所持续的时钟周期数,miss_rate表示为未被抢占的kernel发生高速缓存缺失的频率,reg表示为被抢占的kernel中每个线程块占用寄存器的字节数,smem表示为被抢占的kernel中每个线程块占用共享内存的字节数,tb表示为被抢占的kernel中线程块的数量。
于本实施例中,抢占过程所占用的gpu开销通过抢占过程中归一化ipc衡量,所述抢占过程中归一化ipc为:
norm_ipcrunning1×decay_rate×preempt_cycle;
其中,norm_ipcrunning1表示为未被抢占kernel所表现出的归一化ipc,decay_rate表示为未被抢占的kernel由于抢占过程而导致的ipc衰减率,preempt_cycle表示为抢占过程所持续的时钟周期数,kernel∈memory_intensive表示为未被抢占的kernel属于内存密集型kernel,kernel∈compute_intensive表示为未被抢占的kernel属于计算密集型kernel。
抢占后的归一化ipc由两个阶段组成,一部分是抢占过程中的ipc表现,另一部分是抢占完成后的ipc表现。抢占发生时,未被抢占的kernel仍在继续运行,而被抢占的kernel需要先将相关的上下文保存到内存中,这其中涉及到大量的内存访问操作。根据实际测试情况可知,当未被抢占的kernel属于内存密集型类型的kernel时,其ipc会减小到原来的83%~97%不等,而计算密集型的kernel基本不受影响,因此根据kernel的类型,decay_rate定义如下:
kernel∈memory_intensive表示为未被抢占的kernel属于内存密集型kernel,kernel∈compute_intensive表示为未被抢占的kernel属于计算密集型kernel。
抢占过程所占用的时钟周期数受到两个因素的影响:第一个因素为被换出的kernel的上下文的大小,其中包括该所占用的tb,以及每个tb所占用的寄存器数量和共享内存的大小,这些数量决定了保存完整上下文所需要执行的内存访问操作的数量,通过统计测试结果可知,抢占过程所持续的cycle数与所要保存的字节数成正相关,且可通过线性模型对两者的关系进行拟合;另一个因素是未被换出的kernel执行内存访问操作的频繁程度,由于抢占过程中涉及到较多的内存操作,若未被抢占的kernel也涉及到较多的内存操作,会更加拖慢抢占过程,可通过l2cachemiss的频率来衡量kernel涉及内存操作的频率,研究过程中发现,抢占过程cycle数和上下文切换字节数的线性模型的斜率与正在运行的kernel的cachemiss频率成正相关,且成线性关系。因此抢占过程的cycle数可大致拟合以下关系式:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb。
抢占过程中归一化ipc定义为:norm_ipcrunning1×decay_rate×preempt_cycle。
抢占后的ipc无法精确得知,可通过历史数据获取一个经验值,抢占后的归一化ipc定义为:
根据抢占前归一化ipc和抢占后归一化ipc的对比获取抢占程序后的gpu性能提升,即具体地,计算抢占前归一化ipc和抢占后归一化ipc的差值,获取抢占程序后的gpu性能提升。
此外,本实施例还提供一种芯片,所述芯片为异构多核硬件结构,所述芯片内装设有如上所述的gpu任务调度系统1001。上述已经对所述gpu任务调度系统1001进行了详细说明,在此不再赘述。
为使本领域技术人员进一步理解本实施例中的gpu任务调度系统100和方法,如图4所示,以下以具体实例说明本实施例中gpu任务调度系统100和方法的实施过程。
于本实施例中,底层硬件是一个基于numa(nonuniformmemoryaccessarchitecture,非统一内存访问)内存系统的异构多核架构。
1、用户编写应用程序:属于应用层,用户按照gpu编程规范,编写能在gpu上运行的kernel程序。
2、用户提交应用请求:用户将应用提交给调度层。
3、应用分析模块110分析应用:应用分析模块110接收到用户提交的请求,分析用户提交的应用,判断应用所属的类型以及估计应用的指令数。
4、提交应交到动态任务调度模块120:应用分析模块110将应用以及相关的分析数据提交到动态任务调度模块120。
5、查看当前运行kernel状态:动态调度模块向运行时系统层查询当前运行的kernel数量。
6、若未达到运行数量上限,则从被抢占的kernel以及新到达的knew中挑选与当前运行kernel组合优先级最高的kpreempted并进行发射。
7、若已达到运行数量上限,则判断是否需要进行抢占。判断被抢占的kernel以及新到达的knew中是否存在与当前运行kernel进行组合得到更高优先级的kernel。
8、若存在更优的组合,则判断抢占后的性能提升能否掩盖抢占的开销。
9.、若能掩盖,则进行抢占。
综上所述,本发明提供了一个高性能的gpu抢占式任务调度系统,其基于硬件式抢占机制和高性能任务调度算法,可以在无需升级硬件设备的情况下,应对应用请求动态到达的情况,有效降低延迟,提高资源利用率,提高gpu的性能;本发明的成果可以用于构建具有商业意义的、基于cpu和异构计算芯片gpu的异构数据中心,面向用户提供程序动态任务调度服务;本发明简单实用,具有良好的市场前景和广泛的适用性。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
上述实施例仅例示性说明本发明的原理及功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!