一种用于FPGA的三角脉动阵列结构QR分解装置的制作方法
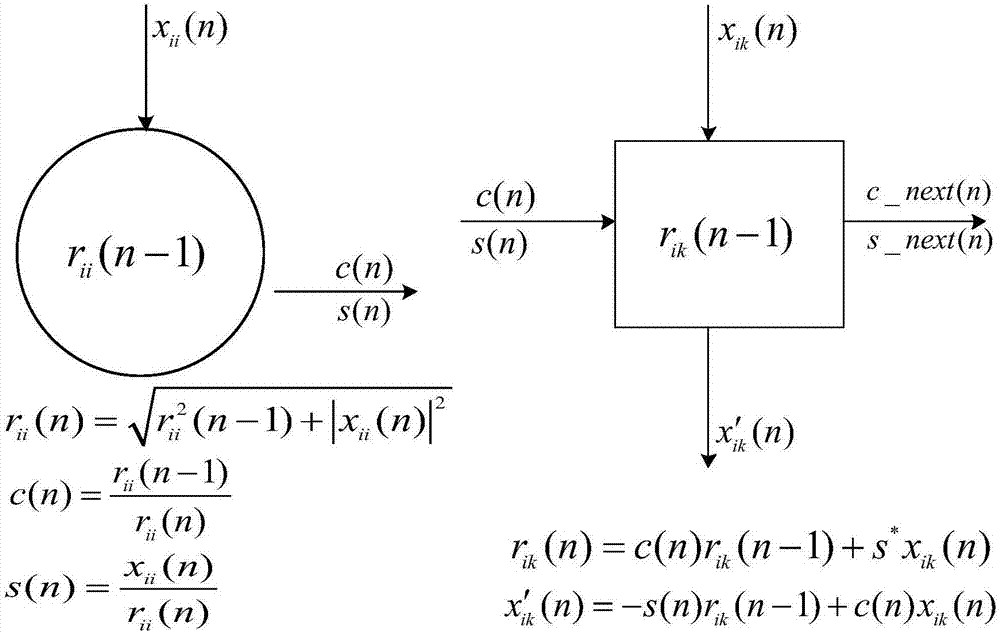
本发明属于信号与信息处理
技术领域:
,具体的说是涉及一种用于fpga的三角脉动阵列结构qr分解装置。
背景技术:
:矩阵的三角化是当矩阵为方阵时求解一般线性系统的所有直接方法的主要步骤,也是计算基于qr分解的最小二乘法和特征值求解中至关重要的一步,然而,矩阵三角化的计算代价很大,n×n矩阵三角化的计算复杂度为ο(n3),因此三角化已经成为一些实时应用的瓶颈。qr分解广泛应用于许多工程领域,旨在解决最小二乘问题,线性系统方程等实际应用。近年来,三角脉动阵列结构普遍被运用于三角矩阵r的求解的问题,这种阵列结构尤其适用于基于givens正交旋转法的矩阵三角化算法,但旋转因子的计算涉及到除法和平方根等复杂运算符,而这对fpga设计来说无疑是巨大的挑战。目前比较流行的处理方法都是基于cordic算法的流水结构,这种实现方法硬件实现较为简单,但处理周期长,流水级数普遍较深,在一定程度上限制了吞吐量。技术实现要素:本发明的目的在于,针对上述问题,提出一种规避了cordic算法实现过程中高处理周期的问题的qr分解装置,主要通过降低平方根倒数模块的处理周期,有效提升了包含该模块的三角阵列在进行矩阵qr分解时的吞吐量。本发明的技术方案为:一种用于fpga的三角脉动阵列结构qr分解装置,用于对n×n的矩阵r进行分解,其特征在于,包括边界计算模块和内部计算模块,所述边界计算模块位于三角阵列对角线上,内部计算模块位于三角阵列内部;其中,在n时刻,第一个边界计算模块从外部接收到矩阵r的第一列的第一个向量x11(n),第一个边界计算模块根据自身存储的数据r11(n-1)计算获得givens旋转因子c(n)和s(n)以及数据r11(n),根据获得的数据r11(n)更新自身存储的数据,并将获得的旋转因子c(n)和s(n)传递到三角阵列中第一行第一个内部计算模块;在n+1时刻,第一行第一个内部计算模块从外部接收到矩阵r的第二列的第一个向量x12(n),并根据接收到的givens旋转因子c(n)和s(n)以及自身存储的上一时刻自身输出值r12(n-1),计算获得当前时刻自身输出值r12(n)和经过线性变换后的x′12(n),根据获得的r12(n)更新自身存储的数据,并将givens旋转因子c(n)和s(n)传递到第一行第二个内部计算模块,同时将x′12(n)传递到与第一个内部计算模块相同列的第二个边界计算模块;与此同时,第一个边界计算模块从外部接收到矩阵r的第一列的第二个向量x21(n),第一个边界计算模块根据自身存储的数据r11(n)计算获得givens旋转因子c(n+1)和s(n+1)以及数据r11(n+1),根据获得的数据r11(n+1)更新自身存储的数据,并将获得的旋转因子c(n+1)和s(n+1)传递到三角阵列中第一行第一个内部计算模块;在n+2时刻,第一行第二个内部计算模块从外部接收到矩阵r的第三列的第一个向量x13(n),并根据接收到的givens旋转因子c和s以及自身存储的上一时刻自身输出值r13(n-1),计算获得当前时刻自身输出值r13(n)和经过线性变换后的x′13(n),根据获得的r13(n)更新自身存储的数据,并将givens旋转因子c和s传递到第一行第三个内部计算模块,同时将x′13(n)传递到与自身相同列的第二行第一个内部计算模块;与此同时,第一行第一个内部计算模块从外部接收到矩阵r的第二列的第二个向量x22(n),并根据接收到的givens旋转因子c(n+1)和s(n+1)以及自身存储的上一时刻自身输出值r12(n+1),计算获得当前时刻自身输出值r12(n+2)和经过线性变换后的x1′2(n+2),根据获得的r12(n+2)更新自身存储的数据,并将givens旋转因子c(n+1)和s(n+1)传递到第一行第二个内部计算模块,同时将x′12(n+2)传递到与第一个内部计算模块相同列的第二个边界计算模块;与此同时,第一个边界计算模块从外部接收到矩阵r的第一列的第三个向量x31(n),第一个边界计算模块根据自身存储的数据r11(n+1)计算获得givens旋转因子c(n+2)和s(n+2)以及数据r11(n+2),根据获得的数据r11(n+2)更新自身存储的数据,并将获得的旋转因子c(n+2)和s(n+2)传递到三角阵列中第一行第一个内部计算模块;以此类推,在每一个时刻,第一个边界计算模块获取一个矩阵r第一列中的一个数据,根据自身存储的上一个自身输出的数据计算获得givens旋转因子c和s以及新的自身输出数据,更新自身存储的数据,并将givens旋转因子c和s传递到相邻的内部计算模块;第一行的内部计算模块根据获得的givens旋转因子c和s、矩阵r中的一个数据以及自身存储的上一次输出数据,计算获得新的自身输出数据和将自身接收的数据线性变换,并将givens旋转因子c和s传递到相邻的同一行的内部计算模块,将线性变换后的自身接收的数据输入到相邻的同一列的内部计算模块或边界计算模块,设定每一个计算单元计算过程消耗一个时钟周期,并设定各计算单元的内部存储的初始值为0,则qr分解装置经过n+n个时刻后完成对矩阵qr的分解,边界单元和内部单元内所储存的值即为所求的r矩阵中相对应的非零值。值得注意的是,之前的描述假设边界单元和内部单元的处理的流水级数都为1,然而本发明中每个边界单元和内部单元都需要9个时钟周期处理数据。所以x12需要延迟9个周期送入,x13需要延迟2×9个周期送入,以此类推,直到填满流水线,矩阵数据就可以源源不断的送入了。因此,在实际qr装置中,经过9(2n-1)+n个时钟周期后,装置完成对矩阵的qr分解,此时边界单元rii和内部单元rik的值即为所求的r上三角矩阵中对角线上和非对角线上的非零值。进一步地,所述边界计算模块根据输入数据计算获得givens旋转因子c(n)和s(n)以及输出数据的具体方法为:采用如下公式1-3计算边界计算模块的输出值rii(n)、旋转因子c(n)和s(n):其中,rii(n-1)为边界计算模块中存储的上次输出数据,xii(n)为边界计算模块接收的外部输入数据,下标ii为qr分解装置为中边界计算模块的行列编号,因边界计算模块位于三角阵列对角线上,其行列编号是相同的。进一步的,所述内部计算模块根据输入数据、givens旋转因子c(n)和s(n)以及自身存储数据计算输出数据和线性化输入数据的具体方法为:采用如下公式4计算输出数据:rik(n)=c(n)rik(n-1)+s*xik(n)(公式4)采用如下公式5线性化输入数据:x′ik(n)=-s(n)rik(n-1)+c(n)xik(n)(公式5)其中,rik(n-1)为内部计算模块自身存储的数据,xik为输入内部计算模块的数据,下标ik为qr分解装置为中内部计算模块的行列编号,因内部计算模块位于三角阵列内部,同一行中具有k个不同的内部计算模块,每一行只有一个边界计算模块。进一步的,所述边界计算模块由第一乘法器、第二乘法器、第三乘法器、第四乘法器、第五乘法器、第六乘法器、第一加法器、第二加法器、平方根倒数单元和存储单元;其中,第一乘法器的两个输入端分别输入输入数据的实数部分,第二乘法器的两个输入端分别输入输入数据的虚数部分;第一加法器的两个输入端分别接第一乘法器的输出端和第二乘法器的输出端;第二加法器的一个输入端接第一加法器的输出端,第二加法器的另一个输入端接其自身输出端;平方根倒数单元的输入端接第二加法器的输出端,所述平方根倒数单元用于获取输入数据的平方根倒数;第三乘法器的一个输入端接平方根倒数单元的输出端,第三乘法器的另一个输入端接第二加法器的输出端,第三乘法器输出边界计算模块输出数据;第四乘法器的一个输入端接平方根倒数单元的输出端,第四乘法器的另一个输入端接第三乘法器的输出端,第四乘法器输出旋转因子c;第五乘法器的一个输入端接平方根倒数单元的输出端,第五乘法器的另一个输入端输入输入数据的实数部分,第五乘法器输出旋转因子s的实数部分;第六乘法器的一个输入端接平方根倒数单元的输出端,第六乘法器的另一个输入端输入输入数据的虚数部分,第六乘法器输出旋转因子s的虚数部分;第五乘法器和第六乘法器输出的数据存入存储单元。进一步的,所述内部计算单元包括输出数据实数计算部分、输出数据虚数计算部分和存储单元;所述输出数据实数计算部分包括第七乘法器、第八乘法器、第九乘法器、第三加法器和第四加法器;其中,第七乘法器的一个输入端输入旋转因子c,另一个输入端接第四加法器的输出端;第八乘法器的一个输入端接旋转因子s的实数部分,另一个输入端接输入数据的实数部分;第九乘法器的一个输入端接旋转因子s的虚数部分,另一个输入端接输入数据的虚数部分;第三加法器的一个输入端接第八乘法器的输出端,第三加法器的另一个输入端接第九乘法器的输出端;第四加法器的一个输入端接第三加法器的输出端,第四加法器的另一个输入端接第七乘法器的输出端,第四加法器的输出端输出输出数据的实数部分;所述输出数据虚数计算部分包括第十乘法器、第十一乘法器、第十二乘法器、第五加法器和第六加法器;其中,第十乘法器的一个输入端输入旋转因子c,另一个输入端接第六加法器的输出端;第十一乘法器的一个输入端接旋转因子s的实数部分,另一个输入端接输入数据的虚数部分;第十二乘法器的一个输入端接旋转因子s的虚数部分,另一个输入端接输入数据的实数部分;第五加法器的一个输入端接第十一乘法器的输出端,第五加法器的另一个输入端接第十二乘法器的输出端;第六加法器的一个输入端接第五加法器的输出端,第六加法器的另一个输入端接第十乘法器的输出端,第六加法器的输出端输出输出数据的虚数部分;第四加法器和第六加法器的输出数据存入存储单元;所述内部计算单元还包括线性化输入数据实数计算部分和线性化输入数据虚数计算部分;所述线性化输入数据实数计算部分包括第十三乘法器、第十四乘法器、第十五乘法器、第七加法器和第八加法器;其中,第十三乘法器的一个输入端输入旋转因子c,另一个输入端接输入数据的实数部分;第十四乘法器的一个输入端接旋转因子s的实数部分,另一个输入端接自身存储数据的实数部分;第十五乘法器的一个输入端接旋转因子s的虚数部分,另一个输入端接自身存储数据的虚数部分;第七加法器的一个输入端接第十四乘法器的输出端,第七加法器的另一个输入端接第十五乘法器的输出端;第八加法器的一个输入端接第七加法器的输出端,第八加法器的另一个输入端接第十三乘法器的输出端,第八加法器的输出端输出线性化输入数据的实数部分;所述线性化输入数据虚数计算部分包括第十六乘法器、第十七乘法器、第十八乘法器、第九加法器和第十加法器;其中,第十六乘法器的一个输入端输入旋转因子c,另一个输入端接输入数据的虚数部分;第十七乘法器的一个输入端接旋转因子s的实数部分,另一个输入端接自身存储数据的虚数部分;第十八乘法器的一个输入端接旋转因子s的虚数部分,另一个输入端接自身存储数据的实数部分;第九加法器的一个输入端接第十七乘法器的输出端,第九加法器的另一个输入端接第十八乘法器的输出端;第十加法器的一个输入端接第九加法器的输出端,第十加法器的另一个输入端接第十六乘法器的输出端,第十加法器的输出端输出线性化输入数据的虚数部分。本发明的有益效果为,规避了cordic算法实现过程中高处理周期的问题,通过降低平方根倒数模块的处理周期,有效提升了包含该模块的三角阵列在进行矩阵qr分解时的吞吐量。附图说明图1为4×4三角脉动阵列结构示意图;图2为边界单元和内部单元的运算逻辑示意图;图3为边界单元的逻辑结构示意图;图4为平方根倒数单元的输入数据格式示意图;图5为归一化后的平方根倒数单元的输入数据格式示意图;图6为平方根倒数单元的内部结构示意图;图7为内部计算模块中输出数据计算部分逻辑结构示意图,(a)为输出数据实数部分计算单元,(b)为输出数据虚数部分计算单元;图8为内部计算模块中线性化输入数据计算部分逻辑结构示意图,(a)为线性化输入数据实数部分计算单元,(b)为线性化输入数据虚数部分计算单元。具体实施方式下面结合附图和实例,详细描述本发明的技术方案:如图1所示,为一个4×4的三角阵列结构,以及矩阵元素的输入顺序。首先,假设每个计算单元消耗一个时钟周期的时间,这意味着计算结果相对于输入要延迟一个时钟周期。输入矩阵的行被当作脉动阵列的输入从阵列的顶部输入。当在t1时刻边界单元n11接收到数据x11后,n11便开始计算,它会根据x11和上一时刻的值r11(0)计算出c、s和r11(1),同时,在t2时刻将c和s的值输出到内部单元n12。在t2时刻,n12节点接收到c、s和x12,它将计算出r12(2)和x′12,并在t3时刻分别将c、s和x′12输出到内部单元n13和边界单元n12。在t3时刻,内部单元n13接收到数据c、s和矩阵元素x13,经过相同的内部单元计算流程后n13节点将会计算得到r13(3)和x′13,并在t4时刻分别将c、s和x′13输出到内部单元n14和同列的内部单元n23。在t4时刻,n14节点接收到来自同一行的c、s和矩阵同一列的x14,经过一个时钟周期的运算,n14节点将会计算得到r14(4)和x′14。至此,从t1到t4时刻矩阵的第一行相关的计算完成。由于三角阵列是按照流水线的方式在工作,当阵列第一行到第二行的第一个输出数据x′12在t3时刻到达边界单元n22时,阵列第二行节点的计算工作正式开始。n22节点以n11节点同样的方式计算得到旋转因子c2和s2,并在t4时刻将其输出到内部单元n23。在t4时刻,n23接单接收到c2、s2和来自于n13节点的输出x′13,计算得到r23(4)和x″13,并在t5时刻分别将c2、s2和x″13输出到内部单元n24和边界单元n33。在t5时刻,n24节点接收到c2、s2和x′14,计算得到r24(5)和x″14,并在t6时刻将x″14传递到内部单元n34。与第二行一样,第三行从首次接收到来自第二行的x″13时的t5时刻开始正式的计算工作,n33节点在t6时刻输出c3和s3到内部单元n34,n34节点在t6时刻接收到c3、s3和n24节点的输出x″14,计算得到r34(6)和x″′14,并在t7时刻将x″′14输出到边界单元n44。同样地,在t7时刻,边界单元n44第一次接收到来自n34节点的输出有效值x″′14,并在t8时刻输出计算得到的r44(7)。如图2所示,是阵列结构中边界计算模块和内部计算模块的简单示意图。图中给出了不同计算单元的输入和输出,分别以rii(n-1)和rik(n-1)表示计算单元的原有值,并且图中也给出了各计算单元的输出公式。如图3所示,边界单元电路里除了包含有加法、乘法等基本运算外,还包含有除法和平方根等复杂计算,而fpga本身并不适用于复杂运算符的计算,在进行加法和乘法运算的时候相对于除法和平方根要容易得多。cordic算法硬件简单,可以实现除法和平方根运算,但cordic算法延时大,且精度不高。所以本发明提供的边界计算模块,只涉及到加法和乘法两种基本运算,而不用关心式中除法和平方根的计算问题,这种设计可以在一定程度上提高模块的运算性能。从定义的数据格式看,输入数据x的实部和虚部均为32位宽度的有符号定点数,最高位代表符号位,若是负数符号位为1,若是正数,则符号位为0。中间9位代表整数部分,低22位代表小数部分,因此该32位定点数最大可以表示的十进制数约为511.999999,可以表示的最小十进制数为-512。取乘法器m1和m2输出结果的20位整数和12位小数作为加法器a1的输入,同时加法器a1和a2的输出均取20位整数和12位小数。将r2输入到下一个平方根倒数模块inverse_sqrt,结果为1/r,显然该值是为正,所以它的数据格式可以没有符号位,它的小数位宽直接影响到了整个设计的精度,综合考虑用23位无符号定点数表示,其中1位整数位,22位小数位。旋转因子c和s的绝对值都小于1,c一定是正数,s则正负数都有可能。c和s均用22位定点数表示,区别在于表示c的22位数全为小数位,表示s的22位数的最高位为符号位,剩下的21位为小数位,表1显示了边界单元内部各计算模块的功能和处理的字长:表1边界单元内部各计算模块的功能和处理的字长模块名功能处理字长乘法器m1x虚部的平方运算32×32乘法器m2x的实部平方运算32×32加法器a1x实部、虚部平方相加得到x的模的平方32加法器a2x模的平方与上一时刻的r2相加得到新的r232平方根倒数输入r2,输出1/r32乘法器m3根据r2和1/r计算r的值32×23乘法器m4根据r(n-1)和1/r计算c32×23乘法器m5根据1/r和x实部计算s的实部32×23乘法器m6根据1/r和x的虚部计算s的虚部32×23对于平方根倒数单元,若求传统查找表的方法是将数据记录在rom内,根据离散的地址值x查找到相应的函数y值,但如果x的等分间距没有足够小,不同x值极有可能会落在同一等分范围内,因此会查询得到相同的y值,这对于单调递减函数来说是不可能的,如若要使出现这种错误的概率减小就要不断缩小x的等分间距,但这样会增加斜率截距对的个数,从而使内存的使用量会大幅度增加,因此在有限硬件资源的情况下这种方式不可取。查找近似法则恰恰解决了这个问题,这种方法将x划分成等距区间,相邻的两个x对应的函数值生成近似直线,储存截距与斜率,这样,即使数值很接近的x处于划分范围的同一区间,并且会查询到相同的斜率截距对,但在带入到直线解析式后,由于x的不同,得到的y值一定不相同。虽然查找近似法可以使近似值无限逼近真实值,且相对于直接查找法有明显的优势,但在保证一定的精度前提下,还存在x点数划分过多的问题,因此就需要更大的内存来存储斜率k和截距b,由此带来巨大的存储资源消耗。因此,需要研究在不影响精度的前提下,用更少的x点数(同样代表近似线段的斜率和截距也会更少)实现查找近似法。若x的取值范围相同,则采样的距离越小,则精度越高,但同时采样的点数也越多。若既要采样的距离小,又要采样的点数少,则只有缩小x的取值范围。因此,查找近似法的改进方向是对x的取值范围进行变换,使其处于一个较小的区间,但又不影响最后的结果输出。下面介绍在查找近似法的基础上对输入的x进行归一化处理,归一化处理过后的x的范围将固定在[1,2),然后在[1,2)的范围内等间距地划分,这样即可以在一个较小的区间对x采样,而需要的采样点数又不会过大,这样便可以较少的存储资源来实现较高的精度。下面将从数学公式推导上证明该区间转换能够实现既定目标。将x乘以2-n,再乘以2n得到下式,该式与相同,其中n为正整数,令x乘以2-n的结果为xnormalized,且在区间[1,2)上,化简后为将上式中的乘数因子去掉,得到归一化处理后的ynormalized,对x进行归一化处理后的值xnormalized的范围已经处于一个较小的区间,然后在[1,2)区间上进行查找近似法需要的采样点数明显要比没有改进的查找近似法要少。反归一化的计算则回归到之前介绍的步骤,当求出ynormalized的值后再乘以反归一化因子2-n/2,即可得到y的实际值。硬件实现方法如下:归一化和反归一化处理时都需要参数n的值,数学方法上可以让x不断除以2,直到x处于区间[1,2)为止,2的个数即为n值。该方法在fpga上可以利用循环移位来实现。平方根倒数模块的输入r_sq为32位无符号定点数,并且不可能为负,图4显示了r_sq的数据格式。如图4所示,r_sq数据格式中的msb(mostsignificantbit)为1,msb左边均为0,r_sq的低12位为小数部分。归一化即是将上图中的小数点移动到msb的右边,移动的位数记为n,记归一化后的r_sq为rsq_normalized,则rsq_normalized的小数位宽为(12+n),整数部分的值为1。根据定点数到十进制转换规则,rsq_normalized的范围为[1,2),当且仅当小数部分全为0时取1。在计算n的时候,将r_sq设定为有符号型变量signed_rsq,设置中间变量k的初始值为0,然后用while语句进行循环判断,判断条件是signed_rsq>0,每循环一次,k的值加1,并将signed_rsq循环左移1位。循环结束后,msb位于最高位,如图5所示,k表示循环移位的次数,则n=19-k。查找近似法需要根据输入的的值查找到对应的斜率k和截距b,因此该查询地址必然要根据x(即r_sq)求解。综合考虑到x的范围和对精度的要求,取图3-8所示r_sq的数据格式中msb后12位作为查询地址,该12位二进制数据最大可以表示4096个地址,因此该地址可以查询得到4096个斜率截距对,即可以把区间[1,2)等间距地划分成4096个小区间,每个小区间对应一个斜率截距对。r_sq归一化处理后的rsq_normalized落在等分的哪一个小区间则查询到该小区间对应的斜率和截距,然后依据查询到的斜率和截距计算rsq_normalized对应的近似函数值,查询地址取msb后12位。需要说明的是,如果输入的两个x的msb后12位相同,但从第13位开始不同,那么两个不同的x具有相同的地址,因此查询到的对应斜率截距也相同,但因为x值不同,所以经过带入直线解析式求得的曲线近似值也不相同。如图6所示,为平方根倒数单元的内部结构,normalization模块实现了对输入r_sq的归一化处理,输出distance和查询地址。memory_k、memory_b、乘法器m_kx和加法器a1、a2实现了在区间[1,2)上的查找近似法,斜率k和截距b均为1位整数,21位小数的有符号定点数。加法器a1和a2的输入相同,输出kx_b1和kx_b2也相同,在这里使用两个相同的加法器是为了让其中一个输出到乘法器m_const与常数相乘,以实现反归一化中的步骤。最后,select_and_shift模块则根据输入distance的奇偶性选择输出移位过后的port1或者port2,即res为1位整数,22位小数。注意到输入到乘法器m_kx中的r_sq并不是从normalization模块输出的r_sq_normalized,而是r_sq本身,这是因为在做乘法的时候,我们把r_sq当作是已经归一化处理过的值,只需将r_sq的msb当作整数位,msb的低位全当作小数位即可。另外,truncate53to23模块的作用是将乘法器m_kx的输出截取成1位整数、22位小数的23位定点数kx_23,才能在与b相加时格式对齐。该结构根据各模块的特性,在各个模块之间添加适当的延迟单元,使整个数据流具有合理的流程,并通过适当的数据截取使得数据流在各个模块内具有正确的格式,并且由图6可知,平方根倒数模块的处理时长为6个时钟周期,在对整体频率影响不大的前提下,尽量减小流水级数可以提升系统吞吐量。将式内部单元rik计算公式按实部和虚部分开看,有rik的实部计算公式为:rik(n)_real=c·rik(n-1)_real+s_real·x_real+s_im·x_imrik的虚部计算公式为:rik(n)_im=c·rik(n-1)_im+(s_real·x_im-s_im·x_real)图7显示了rik实部虚部的实现结构。将式传递值x′ik计算公式按实部和虚部分开看,有x′ik的实部计算公式x′ik(n)_real=c·xik(n)_real-s_real·rik(n-1)_real+s_im·rik(n-1)_imx′ik虚部计算公式为x′ik(n)_im=c·xik(n)_im-s_real·rik(n-1)_im-s_im·rik(n-1)_real图8显示了x′ik实部虚部的实现结构。应当注意的是,rik的计算结果需要进行一级寄存输入到x′ik模块的对应输入,因为rik所得到的结果为“当前值”,而从x′ik的计算公式不难看出,送入乘法器的值应当是rik上一个时刻的值。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1