一种基于显著性指导的端到端的弱监督目标检测方法与流程
本发明涉及图像目标检测方法,具体涉及了一种基于显著性指导的端到端的弱监督目标检测方法。
背景技术:
目标检测旨在用矩形框标记出图像中的目标及其类别。传统的基于机器学习的目标检测方法,一般属于监督学习的方法,它需要带有矩形框真值的训练数据。但是在大数据场景下,标记大量的矩形框需要耗费大量的人力,因此限制了监督学习的方法在大规模数据集上的应用。
为了解决训练数据昂贵的问题,近年来,研究者发展出了基于弱监督标记的学习方法。弱监督标记虽然监督能力比监督标记弱,但是获得弱监督标记的代价要远远小于监督标记。比如对于目标检测问题来说,图像级标签是一类弱监督标记,标记图像级标签,即标记出图像中有哪些类别的目标,所需的工作量要远远小于标记出每个目标的具体位置。
另一方面,随着社交网络的兴起,互联网上有大量用户标记的数据,这类标记通常都是图像级的标签,因此,弱监督学习方法可以利用这些免费的海量标记,从而进一步减少标记的工作量。这样弱监督学习的方法相比监督学习的方法在大数据时代有更大的用武之地。
然而弱监督的目标检测是一个十分困难的问题,原因在于弱监督标记缺少位置信息,导致无法对目标进行精确的建模。为了改善位置信息缺失的问题,一些方法尝试恢复位置信息,如bilen等人通过在网络中加入一个新的分支,得到每个候选目标区域是否为目标的分数。但是这些方法仅利用深度神经网络中的特征来获得,没有挖掘图像中更多的信息,因此对目标检测性能的提升不大。
技术实现要素:
本发明的目的在于提供一种基于显著性指导的端到端的弱监督目标检测方法。本方法将类别相关的显著图引入弱监督目标检测中,首先从显著图中获取置信度较高的种子候选目标区域,从而恢复少量置信度高的位置信息,然后利用高质量的位置信息监督训练用来恢复位置信息的显著性子网络,同时也用来监督训练检测器。
本发明采用的技术方案是包括如下步骤:
(1)采集一幅已知图像级标签的图像i,图像级标签为y=[y1,y2,...,yc],其中yc代表图像中具有第c个类别物体所对应的标签,标签分为前景标签和背景标签,每个标签属性为前景标签或者背景标签,yc∈{1,-1},yc=1表示图像中具有第c个类别物体,yc=-1表示图像中不具有第c个类别物体,一个标签对应一个类别物体,c为类别物体总数,记t={c|yc=1}为图像i具有的图像级标签的集合;
(2)对图像i进行处理获得与每个类别物体对应的类别相关显著图mc、候选目标区域
(3)对于每个类别物体下的每个候选目标区域进行处理计算获得上下文显著值差异
其中,λc表示种子目标区域在候选目标区域集合
然后获得图像i具有的图像级标签的集合对应的种子目标区域的下标序数值集合λs={λc,yc=1};
(4)构建类别相关显著图指导的深度神经网络;
(5)将图像i及其候选目标区域输入到深度神经网络中,利用带动量(momentum)的sgd算法训练深度神经网络,获得深度神经网络的参数;
(6)采用训练后的深度神经网络对未知图像级标签的待测图像进行处理获得目标检测结果。
所述步骤(2)具体为:
使用dcsm算法对图像i进行处理得到多个类别相关显著图m,第c个类别物体具有一个类别相关显著图mc;
使用cob算法对图像i进行处理,分割提取得到多个超像素以及由超像素组合构成的多个候选目标区域,并且为每个候选目标区域
多个超像素的集合表示为
例如为第i个候选目标区域
所述步骤(3)以第i个候选目标区域
(3.1)首先采用以下公式计算平均显著值
其中,
(3.2)再采用以下公式计算与第i个候选目标区域
其中,
(3.3)采用以下公式计算得到上下文显著值差异
其中,σ表示面积权重的标准差。
所述步骤(4)构建的深度神经网络具体包含convs模块、spp模块、ssn(saliencysub-network)模块、sum模块、cln(classification-localizationsub-network)模块、显著性损失函数模块
所述的convs模块包含传统深度神经网络中vgg16网络conv5之前的所有运算;
所述的spp模块为一个空间金字塔池化层(spatialpyramidpooling);
所述的sum模块采用以下公式定义:
其中,τc是sum模块的输出,表示第c个标签的分类分数,φc,i表示cln模块的输出,i表示每个候选目标区域;
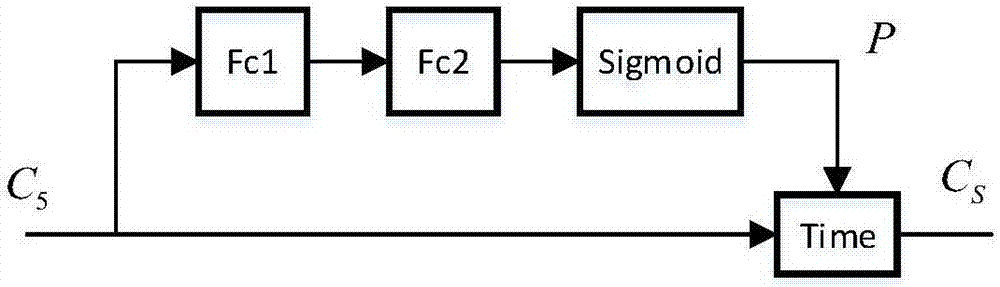
所述的ssn模块主要由fc1层、fc2层、sigmoid层和time层构成,fc1层和time层的输入作为ssn模块的输入,即spp模块输出到fc1层和time层,fc1层依次经fc2层、sigmoid层后输出到time层,time层输出作为ssn模块的输出;其中的fc1层是由一个输出神经元个数为n1的全连接层和一个relu层构成,fc2层是由一个输出神经元个数为n2的全连接层和一个relu层构成。
所述的cln模块主要由fc3层、fc4层、fc5层、fc6层、softmax3层、softmax4层和time层构成,其中的fc3层是由一个输出神经元个数为n3的全连接层和一个relu层构成,fc4层是由一个输出神经元个数为n4的全连接层和一个relu层构成,fc5层是由一个输出神经元个数为n5的全连接层和一个relu层构成,fc6层是由一个输出神经元个数为n6的全连接层和一个relu层构成,softmax3层表示在第三个维度进行softmax操作,softmax4层表示在第四个维度上进行softmax操作,time层表示两个输入的点乘运算,
所述的显著性损失函数模块lss采用以下公式运算:
其中,p是ssn模块中sigmoid层的输出,表示候选目标区域的显著值,
其中,显著值的真值q采用以下公式计算:
其中,m表示λs集合中每个元素的下标,λs()表示种子目标区域下标的集合,l0为背景标签集合,lf为前景标签集合;公式中是分别将背景标签下类别物体和前景标签下类别物体对应的种子目标区域作为显著性的负样本和正样本来计算判别。
所述的图像级分类损失函数模块lic采用以下公式运算:
其中,c为类别物体总数,c为类别物体的序数;
所述的种子区域分类损失函数lsc采用以下公式运算:
其中,t={c|yc=1}为图像i具有的图像级标签的集合;
所述的损失函数模块l(w)采用以下公式运算:
其中,w为深度神经网络中的参数,λ1、λ2、λ3分别为种子区域分类损失函数、显著性损失函数和深度神经网络正则项的权重。
所述步骤(6)具体为:针对未知图像级标签的待测图像采用所述步骤(2)处理获得候选目标区域,将待测图像及其候选目标区域输入到训练后且去掉了损失函数模块l(w)的深度神经网络中进行前向传播,得到输出矩阵φ,输出矩阵φ的每一列作为待测图像中对应的候选目标区域的分数,例如第一列对应第一个候选目标区域,每一列的最大值为所对应候选目标区域的最终分类分数,选出最终分类分数大于阈值η的候选目标区域,在待测图像上构建选出的候选目标区域外的最小外接矩形作为目标检测结果。
本发明方法构造了一个深度神经网络,在弱监督分类器网络的基础上增加目标框的显著性子网络,同时利用弱监督方法训练得到的类别相关的显著图,用上下文差异的准则选取类别相关的种子目标框,用来监督训练显著性子网络和分类器子网络。
本发明的有益效果是:
本发明方法利用类别相关显著图得到种子目标区域,一方面利用种子区域监督训练显著性子网络,从而能够选择出更有可能是目标的区域;一方面直接利用种子区域监督检测网络的分类器;从而从两方面恢复在弱监督训练中缺失的位置信息,与以往的弱监督目标检测方法相比,得到了更好的性能,同时只需要图像级标签进行训练,减少了标注训练数据的工作量。
附图说明
图1是本发明深度神经网络的模块结构框图。
图2是ssn(saliencysub-network)模块的具体结构框图。
图3是cln(classification-localizationsub-network)模块的具体结构框图。
图4是实施例选择出的种子目标区域结果图。
图5是实施例目标检测结果图。
具体实施方式
下面对本发明进行进一步说明。
本发明的实施例及其实施过程是:
(1)采集一幅已知图像级标签的图像i,图像级标签为y=[y1,y2,...,yc],其中yc代表图像中具有第c个类别物体所对应的标签,标签分为前景标签和背景标签,每个标签属性为前景标签或者背景标签,yc∈{1,-1},yc=1表示图像中具有第c个类别物体,yc=-1表示图像中不具有第c个类别物体,一个标签对应一个类别物体,c为类别物体总数;
(2)对图像i进行处理获得与每个类别物体对应的类别相关显著图mc、候选目标区域
使用dcsm算法对图像i进行处理得到多个类别相关显著图m,第c个类别物体具有一个类别相关显著图mc;具体实施中,dcsm算法采用shimodaw,yanaik.distinctclass-specificsaliencymapsforweaklysupervisedsemanticsegmentation文献中的计算方法。
使用cob算法对图像i进行处理,分割提取得到多个超像素以及由超像素组合构成的多个候选目标区域,并且为每个候选目标区域
(3)对于每个类别物体下的每个候选目标区域进行处理计算获得上下文显著值差异
其中,λc表示种子目标区域在候选目标区域集合
然后获得每个类别物体(图像级标签)对应的种子目标区域的下标序数值集合λs={λc,yc=1}。图4展示了通过以上方法选择出的种子目标区域,可见本方法能够利用不完美的类别相关显著图,选择出正确的种子目标区域,从而恢复出训练数据中缺失的目标位置信息,用来监督深度神经网络的训练。
(4)构建深度神经网络。
如图1所示,具体包含convs模块、spp模块、ssn(saliencysub-network)模块、sum模块、cln(classification-localizationsub-network)模块、显著性损失函数模块lss、图像级分类损失函数模块lic、种子区域分类损失函数模块lsc和损失函数模块l(w);图像i输入到convs模块中,convs模块输出依次经spp模块、ssn模块后分别输出到显著性损失函数模块lss和cln模块,cln模块分别输出到种子区域分类损失函数模块lsc和sum模块,sum模块输出到图像级分类损失函数模块lic,显著性损失函数模块lss、种子区域分类损失函数模块lsc和图像级分类损失函数模块lic一起输出到损失函数模块l(w)。
所述的ssn模块如图2所示,所述的cln模块如图3所示。
(5)将图像i及其候选目标区域输入到深度神经网络中,利用带动量(momentum)的sgd算法训练深度神经网络,获得深度神经网络的参数;
具体实施中,动量设置为0.9,一共迭代20个纪元(epoch),前10个纪元的学习率为10-5,后10个纪元的学习率为10-6。训练结束后,保存深度神经网络的参数。
(6)针对未知图像级标签的待测图像采用所述步骤(2)处理获得候选目标区域,将待测图像及其候选目标区域输入到训练后且去掉了损失函数模块l(w)的深度神经网络中进行前向传播,得到输出矩阵φ,输出矩阵φ的每一列作为待测图像中对应的候选目标区域的分数,例如第一列对应第一个候选目标区域,每一列的最大值为所对应候选目标区域的最终分类分数,选出最终分类分数大于阈值η的候选目标区域,阈值η取0.1,在待测图像上构建选出的候选目标区域外的最小外接矩形作为目标检测结果。图5展示实施例一些目标检测结果。
本实施例最后使用标准数据集voc2007(m.everingham,l.vangool,c.kiwilliams,j.winn,anda.zisserman.thepascalvisualobjectclasses(voc)challenge.internationaljournalofcomputervision,88(2):303–338,2010)进行测试,使用数据集中的trainval部分进行训练,使用数据集中test部分进行测试。使用目标检测的标准评判标准map进行评测,表1给出了本方法与最新的弱监督目标检测方法的map值,map值越大,说明性能越好。
表1本方法与最新方法在voc2007数据集上的比较
从上表可见,本方法的map值达到43.5,都高于其他常见的方法的map值,其中wsddnvgg16等价于本方法去掉显著性指导之后的方法,从本方法与wsddnvgg16的比较来看,本方法提出的显著性指导方法,是十分有效的。同时与最新的弱监督目标检测方法相比,本发明具有其突出显著的技术效果。
- 还没有人留言评论。精彩留言会获得点赞!