一种基于混合编码网络的端到端对话控制方法与流程
本发明涉及对话控制领域,尤其是涉及了一种基于混合编码网络的端到端对话控制方法。
背景技术:
随着现代语音识别技术和对话控制系统的发展,采用问答形式的自然语言对话系统是当前对话系统领域的研究热点,其包括了自然语言理解、对话管理、信息抽取和自然语言生成等技术。对话控制可以应用在公众场合,如机场、车站、银行等的信息查询系统,移动信息查询终端,在线应答服务等。目前,许多网站都提供了在线应答服务,但其系统需要较多训练数据,学习复杂性高,准确性却较低。
本发明提出了一种基于混合编码网络的端到端对话控制方法,先将用户话语作为文本形成词袋矢量,通过实体抽取、实体跟踪将特征分量级联成特征向量,再将载体递给rnn计算隐藏状态,传递到softmax激活的密集层,标准化后选择动作模板并传递到实体输出,在实体中替换并完全形成动作,若动作是文本,则呈现给用户,并循环重复。本发明中hcn以相当少的训练数据实现相同的性能,同时保持端到端可训练性,降低了学习的复杂性,提高了准确性;节省人力资源,提高工作效率。
技术实现要素:
针对需要较多训练数据,学习复杂性高等问题,本发明的目的在于提供一种基于混合编码网络的端到端对话控制方法,先将用户话语作为文本形成词袋矢量,通过实体抽取、实体跟踪将特征分量级联成特征向量,再将载体递给rnn计算隐藏状态,传递到softmax激活的密集层,标准化后选择动作模板并传递到实体输出,在实体中替换并完全形成动作,若动作是文本,则呈现给用户,并循环重复。
为解决上述问题,本发明提供一种基于混合编码网络的端到端对话控制方法,其主要内容包括:
(一)混合编码网络(hcn)模型;
(二)应用循环神经网络(rnn)学习“端到端”模型;
(三)监督学习评价;
(四)通过监督学习或强化学习来训练神经网络。
其中,所述的混合编码网络(hcn)模型,hcn的四个组件是递归神经网络、特定领域的软件、特定领域动作模板、用于标识文本中的实体引用的常规实体抽取模块;rnn和开发者代码都保持状态;每个操作模板可以是文本交际操作或应用程序接口(api)调用。
进一步地,所述的hcn模型,当用户提供话语作为文本时,周期开始;形成词袋矢量;再使用预建话语嵌入模型形成话语嵌入;接着,实体抽取模块标识实体;然后将文本和实体提及传递给由开发者提供的实体跟踪代码,将文本映射到数据库中的特定行;该代码可以返回动作掩码,指示当前时间步骤允许的动作,作为位向量;它还可以可选地返回上下文特征,有助于区分动作的特征;
特征分量级联形成特征向量;该载体被传递给rnn,rnn计算隐藏状态(向量),为下一个时间步长保留隐藏状态,并将其传递到softmax激活的密集层,输出维度等于不同系统动作模板的数量,输出是动作模板分布;接下来,将动作掩模应用为逐元素乘法,并且将结果归一化回概率分布,使非允许的动作采用概率零;从所得到的分布选择动作;当强化学习活动时,从分布中采样动作;当强化学习不活动时,选择最佳动作,即选择具有最高概率的动作;
接下来,所选择的动作被传递到实体输出开发人员代码,可以在实体中替换并产生完全形成的动作;如果它是api动作,api充当传感器并返回与对话相关的特征,因此被添加到下一个时间步长中的特征向量;如果动作是文本,则将其呈现给用户,并且循环然后重复;在下一时间步骤中将所采取的动作作为特征提供给rnn。
其中,所述的应用循环神经网络(rnn)来学习“端到端”模型,从可观察的对话历史直接映射到输出字序列;这些系统可以通过添加特殊的“api调用”动作,将数据库输出枚举为标记序列,然后使用存储器网络、门控存储器网络、查询减少网络和复制网络来学习rnn,从而应用于面向任务的域;在这些架构的每一个中,rnn学习操纵实体值;通过生成标记序列(或排列所有可能的表面形式)来产生输出;hcn还使用rnn累积对话状态并选择动作;hcn使用开发者提供的动作模板,可以包含实体引用。
其中,所述的监督学习评价,应用hcn的简单域专用软件要先对实体提取使用简单的字符串匹配,其具有预定义的实体名称列表;其次,在上下文更新中,创建用于跟踪实体的简单规则,其中在输入中识别的实体覆盖现有条目;然后,系统动作被模板化;当数据库结果接收到实体状态,按评级排序;最后创建编码常识依赖性的动作掩码。
进一步地,所述的监督学习评价,使用特定领域的软件在训练集上训练hcn,使用优化器为循环层选择长短期记忆网络(lstm);使用开发集来调整隐藏单元的数量和时期的数量;通过使用对数据使用公开可用的300维词嵌入模型,通过平均词嵌入形成语言嵌入;在训练中,每个对话形成一个小批次,并且在完全展开(即,通过时间的非截断的反向传播)上进行更新。
进一步地,所述的对话框数据标记,用户通过输入问题的简短描述开始使用对话系统,对话框数据标记如下:首先,列举在数据中观察到的唯一系统动作;然后对每个对话框检查每个系统操作,并确定它是否是现有系统动作之中最合适的动作;如果是,保留原样并继续下一个系统操作;如果不是,将其替换为正确的系统操作,并放弃对话框的其余部分;结果数据集包含完整和部分对话框的混合,仅包含正确的系统操作;将这个集合划分为训练和测试对话框。
进一步地,所述的对话框,从对话框开始,检查哪个方法产生更长的连续的正确系统动作序列;
其中,c(hcn-win)是基于规则的方法在hcn之前输出错误动作的测试对话框的数量;c(rule-win)是测试对话框的数量,其中hcn在基于规则的方法之前输出错误的动作;c(all)是测试集中的对话数;当δp>0时,hcn更经常地从对话开始产生连续的正确动作序列。
其中,所述的通过监督学习或强化学习来训练神经网络,应用监督学习训练lstm模仿系统开发者提供的对话;一旦系统大规模操作,与大量用户交互,期望系统使用强化学习继续自主学习;使用强化学习,代理在不同情况下探索不同的动作序列,并且进行调整以便最大化反馈的预期折扣和,表示为g;
为了优化,选择策略渐变方法,在基于策略梯度的强化学习中,模型π由w参数化,并输出在每个时间步长对动作进行采样的分布;在对话结束时,计算该对话的返回g,并且计算针对模型权重采取的动作的概率的梯度;然后通过采用与返回成正比的梯度步长来调整权重:
其中,α是学习率;at在时间步长t采取的行动;ht是在时间t的对话历史;g是返回对话框;
进一步地,所述的监督学习和强化学习,对应于更新权重的不同方法,可以应用于相同的网络;但不能保证最优强化学习策略将与监督学习训练集合一致;因此,在每个强化学习梯度步骤之后,检查更新的策略是否重构训练集;如果没有,在训练集上重新运行监督学习梯度步骤,直到模型再现训练集;这种方法允许在强化学习优化期间的任何时间添加新的训练对话。
附图说明
图1是本发明一种基于混合编码网络的端到端对话控制方法的系统框架图。
图2是本发明一种基于混合编码网络的端到端对话控制方法的hcn模型。
图3是本发明一种基于混合编码网络的端到端对话控制方法的对话框数据标记。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
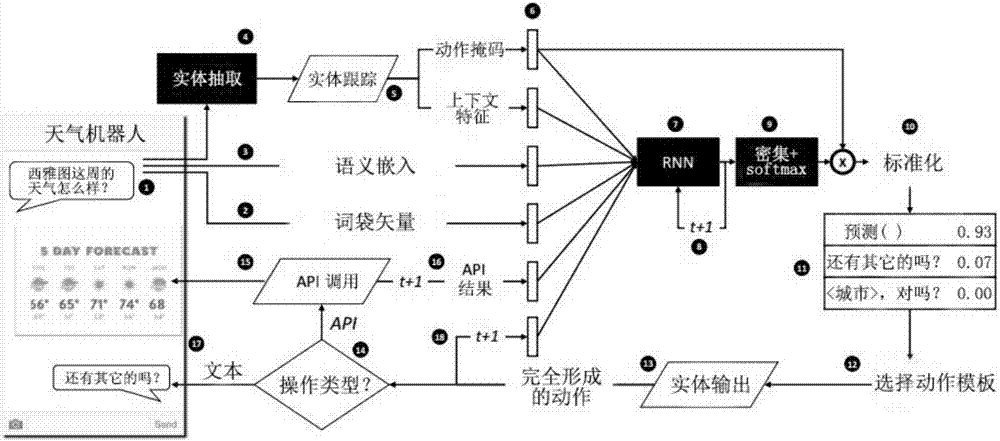
图1是本发明一种基于混合编码网络的端到端对话控制方法的系统框架图。主要包括混合编码网络(hcn)模型,应用循环神经网络(rnn)学习“端到端”模型,监督学习评价,通过监督学习或强化学习来训练神经网络。
应用循环神经网络(rnn)来学习“端到端”模型,从可观察的对话历史直接映射到输出字序列;这些系统可以通过添加特殊的“api调用”动作,将数据库输出枚举为标记序列,然后使用存储器网络、门控存储器网络、查询减少网络和复制网络来学习rnn,从而应用于面向任务的域;在这些架构的每一个中,rnn学习操纵实体值;通过生成标记序列(或排列所有可能的表面形式)来产生输出;hcn还使用rnn累积对话状态并选择动作;hcn使用开发者提供的动作模板,可以包含实体引用。
监督学习评价,应用hcn的简单域专用软件要先对实体提取使用简单的字符串匹配,其具有预定义的实体名称列表;其次,在上下文更新中,创建用于跟踪实体的简单规则,其中在输入中识别的实体覆盖现有条目;然后,系统动作被模板化;当数据库结果接收到实体状态,按评级排序;最后创建编码常识依赖性的动作掩码。
使用特定领域的软件在训练集上训练hcn,使用优化器为循环层选择长短期记忆网络(lstm);使用开发集来调整隐藏单元的数量和时期的数量;通过使用对数据使用公开可用的300维词嵌入模型,通过平均词嵌入形成语言嵌入;在训练中,每个对话形成一个小批次,并且在完全展开(即,通过时间的非截断的反向传播)上进行更新。
通过监督学习或强化学习来训练神经网络,应用监督学习训练lstm模仿系统开发者提供的对话;一旦系统大规模操作,与大量用户交互,期望系统使用强化学习继续自主学习;使用强化学习,代理在不同情况下探索不同的动作序列,并且进行调整以便最大化反馈的预期折扣和,表示为g;
为了优化,选择策略渐变方法,在基于策略梯度的强化学习中,模型π由w参数化,并输出在每个时间步长对动作进行采样的分布;在对话结束时,计算该对话的返回g,并且计算针对模型权重采取的动作的概率的梯度;然后通过采用与返回成正比的梯度步长来调整权重:
其中,α是学习率;at在时间步长t采取的行动;ht是在时间t的对话历史;g是返回对话框;
对应于更新权重的不同方法,可以应用于相同的网络;但不能保证最优强化学习策略将与监督学习训练集合一致;因此,在每个强化学习梯度步骤之后,检查更新的策略是否重构训练集;如果没有,在训练集上重新运行监督学习梯度步骤,直到模型再现训练集;这种方法允许在强化学习优化期间的任何时间添加新的训练对话。
图2是本发明一种基于混合编码网络的端到端对话控制方法的hcn模型。hcn的四个组件是递归神经网络、特定领域的软件、特定领域动作模板、用于标识文本中的实体引用的常规实体抽取模块;rnn和开发者代码都保持状态;每个操作模板可以是文本交际操作或应用程序接口(api)调用。
当用户提供话语作为文本时,周期开始;形成词袋矢量;再使用预建话语嵌入模型形成话语嵌入;接着,实体抽取模块标识实体;然后将文本和实体提及传递给由开发者提供的实体跟踪代码,将文本映射到数据库中的特定行;该代码可以返回动作掩码,指示当前时间步骤允许的动作,作为位向量;它还可以可选地返回上下文特征,有助于区分动作的特征;
特征分量级联形成特征向量;该载体被传递给rnn,rnn计算隐藏状态(向量),为下一个时间步长保留隐藏状态,并将其传递到softmax激活的密集层,输出维度等于不同系统动作模板的数量,输出是动作模板分布;接下来,将动作掩模应用为逐元素乘法,并且将结果归一化回概率分布,使非允许的动作采用概率零;从所得到的分布选择动作;当强化学习活动时,从分布中采样动作;当强化学习不活动时,选择最佳动作,即选择具有最高概率的动作;
接下来,所选择的动作被传递到实体输出开发人员代码,可以在实体中替换并产生完全形成的动作;如果它是api动作,api充当传感器并返回与对话相关的特征,因此被添加到下一个时间步长中的特征向量;如果动作是文本,则将其呈现给用户,并且循环然后重复;在下一时间步骤中将所采取的动作作为特征提供给rnn。
图3是本发明一种基于混合编码网络的端到端对话控制方法的对话框数据标记。用户通过输入问题的简短描述开始使用对话系统,对话框数据标记如下:首先,列举在数据中观察到的唯一系统动作;然后对每个对话框检查每个系统操作,并确定它是否是现有系统动作之中最合适的动作;如果是,保留原样并继续下一个系统操作;如果不是,将其替换为正确的系统操作,并放弃对话框的其余部分;结果数据集包含完整和部分对话框的混合,仅包含正确的系统操作;将这个集合划分为训练和测试对话框。
从对话框开始,检查哪个方法产生更长的连续的正确系统动作序列;
其中,c(hcn-win)是基于规则的方法在hcn之前输出错误动作的测试对话框的数量;c(rule-win)是测试对话框的数量,其中hcn在基于规则的方法之前输出错误的动作;c(all)是测试集中的对话数;当δp>0时,hcn更经常地从对话开始产生连续的正确动作序列。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!