基于向量处理器的深度神经网络多核加速实现方法与流程
本发明涉及大规模神经网络计算技术领域,尤其涉及一种基于向量处理器的深度神经网络多核加速实现方法。
背景技术:
深度神经网络dnn(deepneuralnetwork,dnn)主要是指一种含有多个隐藏层的全连接神经网络,其中相邻层之间全连接、层内无连接,是深度学习中的一种重要神经网络模型。如图1所示,dnn模型一般有3层以上,每层的计算节点也有很多,相邻层的计算模型可以抽象成一个矩阵向量乘法操作,模型通过bp(backpropagation,bp)算法进行训练。
由于深度神经网络模型往往有多层且每层有大量的节点,因此其计算属于典型的计算密集型,采用单核系统计算大规模多层的神经网络,往往不能取得很好的计算效果,基于单芯片已难以满足深度神经网络所需的高密集、实时运算等应用时的计算需求。
向量处理器是一种包括标量处理部件(spu)和向量处理部件(vpu)的处理器结构,如图2所示为一个单核向量处理器的典型结构,其中标量处理部件负责标量任务的计算和流控,向量处理部件负责密集型且并行程度较高的计算,包括若干向量处理单元(vpe),每个处理单元上包含丰富的运算部件,具有非常强大的计算能力,可以大幅提高系统的计算性能。
向量处理器中向量处理部件内包含大量的向量处理单元(pe),这些处理单元都有各自的运算部件和寄存器,向量处理单元间则通过规约指令或混洗操作进行数据交互,如向量处理单元之间的数据相乘、比较等;标量处理单元主要负责流控和逻辑判断指令的处理,以及一些标量的数据访问操作、dma的数据传输模式的配置等,其中向量处理单元运算所用的数据由向量数据存储单元提供,标量数据处理单元运算所用数据由标量数据存储单元提供。
应用向量处理器计算深度神经网络,可以有效提高深度神经网络的计算性能,但是目前通过向量处理器计算深度神经网络模型时,通常都是基于单核向量处理器实现,其仍然无法很好的满足深度神经网络所需的高密集、实时运算等的计算需求。因此,亟需提供一种基于多核向量处理器实现深度神经网络方法,以提高深度神经网络在高密集、实时运算等的计算性能。
技术实现要素:
本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种实现方法简单、所需成本低、能够充分利用多核向量处理器的特性实现dnn的并行加速,且并行性以及加速效果好的基于向量处理器的深度神经网络多核加速实现方法。
为解决上述技术问题,本发明提出的技术方案为:
一种基于向量处理器的深度神经网络多核加速实现方法,步骤包括:
s1.将待处理数据按一维向量输出,并作为输入值输入至目标深度神经网络;
s2.由向量处理器中各个核依次计算目标深度神经网络中相邻两个隐层的权值矩阵,每次计算时,将输入值广播至各个核内的标量存储体中,同时加载相邻两个隐层的权值矩阵,将加载的所述权值矩阵进行划分后分别传输至各个核内的向量存储体中,启动各个核并行计算后得到多个向量计算结果并作为下一次计算的输入值。
作为本发明的进一步改进:所述步骤s2中每次计算时,具体通过启动dma的广播传输模式,将输入值广播至各个核内的标量存储体中。
作为本发明的进一步改进:所述步骤s2中每次计算时,将加载的所述权值矩阵进行划分后,具体通过启动各个核dma点对点传输方式,将划分后权值矩阵分别传输至各个核内的向量存储体中。
作为本发明的进一步改进:所述步骤s2中每次计算时,得到多个向量计算结果后,具体通过启动各个核的dma将得到的多个向量计算结果输出至外部ddr中。
作为本发明的进一步改进:所述步骤s2中每次计算时,具体将加载的所述权值矩阵按列平均划分成多份。
作为本发明的进一步改进:所述步骤s2中每次计算时,得到多个向量计算结果后还包括由各个核对得到的所述向量计算结果进行激活函数处理,得到最终的向量计算结果步骤。
作为本发明的进一步改进:所述激活函数为sigmoid函数、relu函数、tanh函数中的一种。
作为本发明的进一步改进:所述步骤s2中每次计算前,还包括判断当前次所需计算的权值矩阵的状态,若判断到满足预设条件时,直接由指定核执行当前权值矩阵的计算。
作为本发明的进一步改进:所述预设条件具体为权值矩阵不能平均划分或权值矩阵规模小于预设值。
作为本发明的进一步改进:所述步骤s1中具体按列或行输出一维的向量数据作为目标深度神经网络的输入值。
与现有技术相比,本发明的优点在于:
1)本发明基于向量处理器的深度神经网络多核加速实现方法,通过多核向量处理器计算深度神经网络,在每次计算相邻两个隐层的权值矩阵时,将输入值广播至各个核内的标量存储体sm中,加载的权值矩阵进行划分后分别传输至各个核内的向量存储体am中,使得待处理数据及每一层的计算结果采用标量取,层与层之间的权值矩阵则采用向量取,能够结合深度神经网络的计算特点以及多核向量处理器的结构特性,实现深度神经网络多核并行加速,核与核之间可以完全不相关的执行各自的任务,实现方法简单、所需的实现成本低,且并行执行效率高,能够满足大规模深度神经网络的高密集、实时运算等计算性能需求;
2)本发明基于向量处理器的深度神经网络多核加速实现方法,进一步通过在多核计算过程中配置不同的dma传输方式,将数据通过dma的广播传输模式传输至标量存储体sm,通过dma点对点传输模式传输至对应的向量存储体am,能够有效配合各核实现深度神经网络的并行计算;
3)本发明基于向量处理器的深度神经网络多核加速实现方法,进一步基于深度神经网络的计算特点,通过将每层计算任务进行平均分配,结合各核的dma的相互配合,使得各核之间可以完全不相关的执行各自的任务,多核并行执行深度神经网络计算,大大提高了深度神经网络的计算效率;
4)本发明基于向量处理器的深度神经网络多核加速实现方法,进一步结合多核并行处理方式,当权值矩阵不能平均划分或权值矩阵规模小于预设值时,直接由指定核执行当前权值矩阵的计算,以避免使用多核难以获取好的加速效果,从而能够进一步提高整体加速效果。
附图说明
图1是深度神经网络结构的原理示意图。
图2是典型的单核向量处理器的结构示意图。
图3是本实施例基于向量处理器的深度神经网络多核加速实现方法的实现流程示意图。
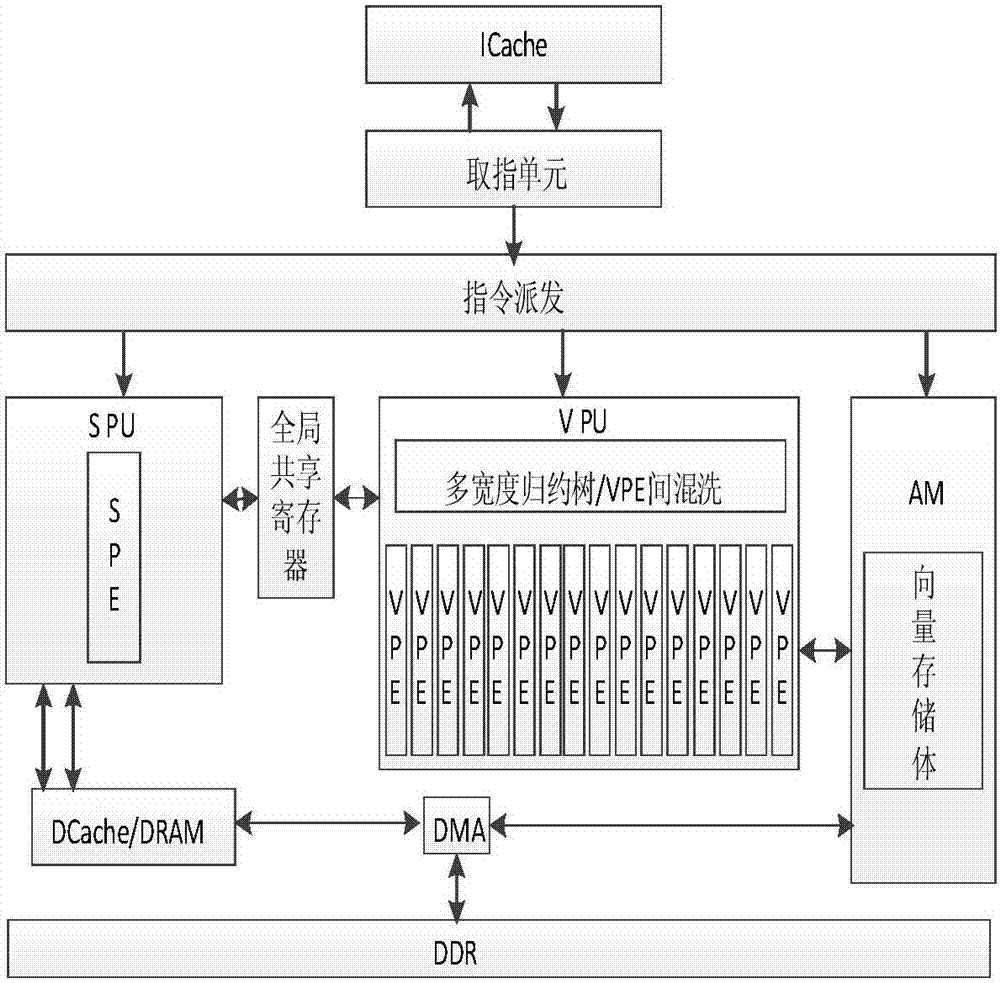
图4是本实施例采用的多核向量处理器的结构示意图。
图5是本实施例步骤s2多核并行执行计算的详细流程示意图。
图6是本发明具体实施例(三层全连接神经网络)中深度神经网络的结构示意图。
图7是本发明具体实施例(三层全连接神经网络)中输入层与隐层之间权值矩阵划分原理示意图。
图8是本发明具体实施例(三层全连接神经网络)中单核矩阵向量乘法计算的原理示意图。
图9是本发明具体实施例(三层全连接神经网络)中从ddr广播至标量存储体的原理示意图。
图10是本发明具体实施例(三层全连接神经网络)中执行隐层与输出层计算的原理示意图。
具体实施方式
以下结合说明书附图和具体优选的实施例对本发明作进一步描述,但并不因此而限制本发明的保护范围。
如图3所示,本实施例基于向量处理器的深度神经网络多核加速实现方法,步骤包括:
s1.将待处理数据对输入图像的像素矩阵进行预处理,按列或行输出一维的向量数据后作为输入值输入至目标深度神经网络;
s2.待处理处理作为输入值由向量处理器中各个计算核共享,各个核依次计算目标深度神经网络中相邻两个隐层的权值矩阵,每次计算时,将输入值广播至各个核内的标量存储体sm中,同时加载相邻两个隐层的权值矩阵,将加载的权值矩阵进行划分后分别传输至各个核内的向量存储体am中,启动各个核并行计算后得到多个向量计算结果并作为下一次计算的输入值。
本实施例中深度神经网络具体包含有一个输入层、n个中间隐层以及一个输出层,每层有数量不等的神经元节点,输入层节点对应的是输入的待处理数据,输出层节点对应为完成整个深度神经网络模型的计算结果。
本实施例上述基于多核向量处理器计算深度神经网络,在每次计算相邻两个隐层的权值矩阵时,将输入值广播至各个核内的标量存储体sm中,即待处理输入数据及每次的计算结果置入标量存储体sm中,加载的权值矩阵进行划分后分别传输至各个核内的向量存储体am中,即权值矩阵置入向量存储体am中,使得待处理数据及每一层的计算结果采用标量取,层与层之间的权值矩阵则采用向量取,核与核之间可以完全不相关的执行各自的任务,各核的计算结果再汇总输出,实现深度神经网络多核并行加速。
本实施例中,步骤s2中每次计算时,具体通过启动dma的广播传输模式,将输入值广播至各个核内的标量存储体sm中;将加载的权值矩阵进行划分后,通过启动各个核dma点对点传输方式,将划分后权值矩阵分别传输至各个核内的向量存储体am中;以及得到多个向量计算结果后,通过启动各个核的dma将得到的多个向量计算结果输出至外部ddr中。通过在多核计算过程中配置上述不同的dma传输方式,将数据通过dma的广播传输模式传输至标量存储体sm,通过dma点对点传输模式传输至对应的向量存储体am,能够有效配合各核实现深度神经网络的并行计算。
本实施例中,步骤s2中每次计算时,具体将加载的权值矩阵按列平均划分成多份,每份划分后权值矩阵通过dma传输至各个核内的向量存储体am中,以将权值矩阵平均分配给各个计算核。针对深度神经网络的计算特点,通过将每层计算任务进行平均分配,结合各核的dma的相互配合,使得各核能够并行执行深度神经网络计算,核与核之间可以完全不相关的执行各自的任务,大大提高了深度神经网络的计算效率。
本实施例中,步骤s2中每次计算时,得到多个向量计算结果后还包括由各个核对得到的向量计算结果进行激活函数处理,得到最终的向量计算结果步骤,激活函数具体可以为sigmoid函数,如sigmoid(f(x)=1/(1+e-x)),或为relu激活函数,如relu′(f(x)=max(0,x)),或tanh函数,如
本实施例中,步骤s2中每次计算前,还包括判断当前次所需计算的权值矩阵的状态,若判断到满足预设条件时,如权值矩阵不能平均划分或权值矩阵规模小于预设值,此时由于使用多核难以取得好的加速效果,则直接由指定核执行当前权值矩阵的计算,能够进一步提高整体加速效果。
本实施例多核向量处理器如图4所示,包括m个核core0~corem,每个核包括标量处理单元spu、标量存储体sm以及向量处理单元vpu、向量存储体am,各个核之间通过dma传输数据。通过如图4所示向量处理器实现图像数据深度神经网络多核加速时,将输入图像的像素矩阵进行预处理,按列或行输出一维的向量数据后作为输入值输入至目标深度神经网络,如图5所示,步骤s2的详细步骤如下:
s21.准备输入图像数据和相邻层的权值矩阵;
s22.执行输入层与第一个隐层的权值矩阵计算,广播一维的图像数据至m个核的核内标量存储体中,同时加载输入层与第一个隐层的权值矩阵,并将该权值矩阵按列平均划分成m份,每份计算任务由相应的dma传输至对应核的内部向量存储体am中;
s23.m个计算核同时完成m个的矩阵向量乘法,得出m个一维的向量结果,由m个核同时对该m个向量结果进行激活函数处理,通过m个核的内部dma将m个向量计算结果输出至外部ddr中;
s24.将上次计算输出至ddr中的数据通过广播传输至m个核的标量存储体sm中,同时加载第n1个隐层与第n1+1个隐层的权值矩阵,并将该矩阵按列的划分方式平均划分成m份,并由m个核的dma传输至对应的核内am中;
s25.m个计算核同时完成m个所分配矩阵向量乘法计算任务,得出m个一维的向量结果,由m个核同时对各自的矩阵向量乘法的结果进行激活函数处理,通过m个核的内部dma将m个向量计算结果输出值外部ddr中;
s26.重复步骤s23~s25以完成下一相邻层的权值矩阵计算,直至完成整个深度神经网络的计算,输出最终计算结果。
本实施例由具体的向量处理器的结构、指令集以及所需计算的深度神经网络的规模,按照上述步骤生成对应的执行代码,实现不同规模多层的深度神经网络计算,实现原理简单且执行效率高。
以下以基于多核向量处理器实现三层的神经网络加速为例,进一步说明本发明。
本实施例多核向量处理器的核数m为12,深度神经网络的输入层节点对应的是输入图像的像素矩阵,输出层节点对应的是图像的分类目标值类别。如图6所示,本实施例深度神经网络输入图像尺寸为28×28,中间隐层节点为1152,输出层节点为10,根据输入数据需为一维向量数据且数据长度即为输入节点数,使得输入节点为784,实现深度神经网络多核加速的具体步骤为:
步骤1、对输入图像的像素矩阵进行预处理,并按列或行输出至一维的向量数据,作为深度神经网络的输入值,即1×784;
步骤2、通过核0启动dma的广播传输模式,将1×784的标量数据广播至core0~core11的核内标量存储体中,即sm0~sm11中;
步骤3、输入层与隐层的权值矩阵为784×1152,将此权值矩阵根据列平均划分成12份,即1152/12=96,如图7所示,每个核被分到的数据矩阵为784×96;
步骤4、同时启动12个核dma点对点传输方式,将784×96×12的数据量依次传入12个核的向量存储体中,即am0~am11中;
步骤5、12核同时进行矩阵向量乘法操作,每个核计算出96个结果元素,并进行激活函数处理,12核一共同时计算出96×12个向量元素;
单核矩阵向量乘法计算如图8所示,通过核内dma每次一维的计算结果(784×1)置入标量存储体sm中,将划分后的权值矩阵(784×96)置入向量存储体am中,经过计算后得到1×96的向量计算结果。
步骤6、同时启动12核的dma将96×12个计算结果由核内am导出至核外ddr存储体,数据从ddr广播至各核标量存储体sm具体如图9所示;
步骤7、启动dma的广播传输,将步骤6中计算出的96×12个结果元素广播至12核的sm中;由于隐层至输出层的权值矩阵为1152×10,列数为10,列数过小不满足12核的划分方式,该计算任务则指定由core0来完成计算,如图10所示;
步骤8、由core0启动dma将隐层至输出层的权值矩阵1152×10传输至core0的am中,由core0完成最终的计算,并输出结果。
上述只是本发明的较佳实施例,并非对本发明作任何形式上的限制。虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明。因此,凡是未脱离本发明技术方案的内容,依据本发明技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均应落在本发明技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!