一种大数据分布式实时查询方法及系统与流程
本发明涉及大数据处理技术领域,尤其是指一种大数据分布式实时查询方法及系统。
背景技术:
随着计算机和信息技术的迅猛发展和普及应用,行业应用系统的规模迅速扩大,行业应用所产生的数据呈爆炸性增长。动辄达到数百tb甚至数十至数百pb规模的行业/企业大数据已远远超出了现有传统的计算技术和信息系统的处理能力,因此,寻求有效的大数据处理技术、方法和手段已经成为现实世界的迫切需求。如果能利用飞速发展的大数据技术对各个大数据业务领域数据进行挖掘和统计分析,可为各行各业的决策者制定方针提供参考依据,实现创新性的大数据服务,从而进一步推进各行各业的工程建设。
大数据的挖掘与分析从采集源数据到最终获得分析结果一般要经过几个主要步骤,包括数据采集、数据预处理、数据存储与管理、实时查询处理、联机分析处理(olap)、数据挖掘、数据可视化等。其中,实时查询处理负责对查询语句及查询脚步文件进行解析和分析、生成查询计划树、执行查询阶段和整合结果集,最后返回到数据可视化模块进行结果可视化,或者成为联机分析处理的分析结果。数据实时查询是数据分析流程中对处理性能要求最高,响应时间要求最高,同时也是数据仓库中非常重要的一环,该部分的工作直接关系到数据仓库的查询速度,从而影响到联机分析处理的性能。尤其在面对海量数据的处理需求时,高效迅速低响应时间的实时查询系统的设计更是突显出它在数据仓库中的重要性。系统的结构设计主要包含查询语句解析和分析、生成查询计划树、执行查询阶段以及查询结果集的整合。
现有业务系统的实时查询系统是基于传统的关系型数据库或nosql数据库进行实时查询。在对大数据进行实时查询中,若全部数据存储在单一服务器上会占据巨大的空间,并且如果出现服务器故障将导致大量的数据丢失。而将数据分布式的存储在多个服务器上能有效的降低单服务器在空间上的负担同时降低服务器故障导致的数据丢失风险。但使用现有业务系统对分布式集群进行查询需要在每台服务器上安装数据库,并且还需对查询结果进行整合,这使得传统的关系型数据库或nosql数据库不足以进行大数据处理,因此如何有效扩展实时查询服务器的性能显得十分必要。因此需要设计一个稳定高效完成分布式数据仓库实时查询的分布式实时查询系统。
现有实时查询系统仅支持在单台服务器上进行数据的实时查询,因此只需直接执行查询语句就能得到最终结果。但对于分布式数据仓库,数据是分别存储在不同服务器上,直接执行查询语句或查询脚本得到的结果是分散的,并且每台服务器都完整执行查询语句或查询脚本并不能很好的提升分布式实时查询的性能,因此如何对查询语句及查询脚本进行解析和分析,并分配到各个服务器上以及对查询结果集的整合,是实现分布式实时查询系统的重大难点。同时,对于分布式数据仓库,数据分布在各个子节点上,要进行实时查询就需要对各个子节点上的数据都访问。只有子服务器主要查询本地数据的减少网络io才能减少数据访问时间,从而减少查询时间,提高实时查询性能。因此,如何进行调度,尽量减少io调度,将是将会是影响分布式实时查询系统查询性能的一个重要瓶颈。
同时系统也需要一个健康监控中心来是实现对各个节点上的查询组件的健康状态检查。当某个查询组件由于硬件错误、软件错误或其他原因导致离线时,就需要监控中心通知其他节点从而避免其他节点对该离线节点发送请求,同时也需要根据各个节点的监控状态对查询语句以及查询脚本的解析分配进行更改。因此,需要健康监控中心保证分布式实时查询系统的可靠性。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供了一种大数据分布式实时查询方法及系统,充分利用实时查询云服务器的处理性能,提供一定的可扩展性,避免了服务器与分布式文件系统数据节点之间多余的数据访问,从而提高分布式实时查询的效率。
为实现上述目的,本发明所提供的技术方案,如下:
一种大数据分布式实时查询方法,首先,将通过sqlapp和odbc/jdbc得到的查询语句和查询脚本文件进行解析和分析,如果是查询脚本文件则将其分割为多个查询语句分别进行处理,对于单个查询语句则通过关键字进行划分,随后查询协调器将划分的各个部分用不同的节点表示不同的操作,然后根据节点的执行顺序生成基本的查询计划树,查询计划树的根节点是用于汇聚结果并返回,而查询计划树的叶子节点为scan操作,用于获取相关表数据,对于复杂度低的查询计划树,主服务器将为查询计划树分配一个或多个线程进行处理,分配了多个线程的节点成为并行查询计划树,处理并行查询计划树即启动多个线程同时工作,仅包含单线程的查询计划树将是单方向进行处理,而对于复杂度高的查询计划树,选择以分布式集群的方式执行,集群由云平台上搭建的分布式实时查询服务器组成,包括一台主服务器和多台子服务器,系统会对基本的查询计划树进行分布式修改,groupby&localagg之下包括自身的子节点都能够在各个子服务器上的查询组件上分布式执行,而之上的只能在查询协调器上处理,因此将查询计划树划分成多个查询阶段,并且每个查询阶段将会被分配到相应的子服务器的查询组件上进行处理,在每个查询组件都处理完得到相应查询结果集后,都会汇聚到查询协调器进行处理,包括对相关节点数据进行aggregation以及进行orderby和limit处理,得到最终的结果并返回。
上述的大数据分布式实时查询方法,包括以下步骤:
1)云平台为云服务器分配所需资源,并初始化实时查询云服务器集群;
2)云平台获取主服务器并作为查询协调器进行工作,查询协调器负责获取查询语句和查询脚本文件并进行解析和分析并决定哪个查询组件进行哪个查询;
3)云服务器通过sqlapp和odbc/jdbc获取查询语句和查询脚本文件并发送给查询协调器处理,查询协调器对查询语句和查询脚本文件进行解析和分析;
4)查询协调器根据对查询语句的解析分析结果生成基本的查询计划树,查询计划树包含多个节点,不同的操作对于不同的节点,根节点为返回最终结果,叶子节点为scan操作,分别获取相关表数据;
5)云服务器对生成的查询计划树按以下步骤执行:
5.1)云服务器获取当前查询计划树,根据元数据获取查询节点名称以及查询计划树的复杂程度,判断是否并行执行查询计划树,若不是,执行步骤5.2),若是,执行步骤5.3);
5.2)主服务器处理查询计划树,执行整个查询计划并将最终的查询结果返回给查询协调器,执行步骤5.4);
5.3)查询协调器对基本的查询计划树进行分布式修改,划分成多个查询阶段,同时查询协调器根据分布式查询计划树决定哪些子服务器执行查询阶段,然后将各个查询阶段分配到对应的子服务器的查询组件并行的执行查询操作,最后各个查询组件将各自的结果集返回给查询协调器,查询协调器整合结果集并得到最终查询结果,执行步骤5.4);
5.4)判断有无后续查询操作,若有,则执行步骤5.1)。
一种大数据分布式实时查询系统,包括:
查询解析模块,用于对查询语句以及查询脚本文件进行解析和分析,所述查询语句的解析和分析是对单独的查询语句根据关键字进行划分,然后分析其组成部分,所述查询脚本文件用于多个查询语句组合成的脚本文件,先将其分割成多个独立的查询语句然后对单个查询语句进行解析和分析;
查询计划树模块,用于对查询解析模块分析出来的各个组成部分用不同的节点表示不同的操作,然后根据节点的执行顺序生成基本的查询计划树,其中计划树的根用于汇聚结果返回给用户,计划树的叶子节点为scan操作;
查询阶段模块,用于对上述生成的查询计划树进行分布式修改,将整个查询计划树划分成多个查询阶段,并将各个查询阶段分配给不同的子服务器进行查询操作,子服务器通过对各自的查询阶段进行查询将得到各自的查询结果集;
结果整合模块,对各个子服务器得到的查询结果集进行汇总,并整合处理为最终的结果,同时,将结果返回给大数据可视化系统进行查询结果的可视化以及返回给联机分析处理系统进行后续的联机分析处理。
所述结果整合模块包含有nosql缓存单元,该nosql缓存单元将查询得到的结果写入nosql缓存数据库中,使得在有效期内相同的查询能够直接从nosql缓存数据库中直接返回查询结果。
本发明与现有技术相比,具有如下优点与有益效果:
1、采用多线程的方式执行实时查询作业,并为实时查询作业配置集群执行方式,可充分发挥分布式实时查询云服务器的处理性能,同时由于云平台规模具有强大的可伸缩性,这为分布式实时查询系统的性能提供了可扩展性;通过分布式实时查询能有效降低单服务器的查询压力,将查询处理分配到多台子服务器上同时子服务器查询数据量的减少能有效降低子服务器的查询时间,提高分布式实时查询系统的查询效率。
2、借助健康监控中心对各个子服务器中的查询组件的健康状态进行检查。当某个子服务器中的查询组件出现硬件错误、软件错误或其他原因导致离线,健康监控中心会通知其他节点的查询组件,避免其他节点向其发送请求,同时查询协调器会根据健康监控中心返回的信息对分布式查询计划树进行相应的修改。
3、借助nosql数据库高性能、易扩展的特点,采用基于纯内存的nosql数据库进行缓存优化,缓存短期内处理过的查询语句的结果,有效降低短期内集群对重复查询的操作频率,从而降低分布式实时查询系统对重复查询的耗时,提供对重复查询的性能。
4、使用了支持datalocality的i/o调度机制,通过尽量满足数据的局部性,将扫描数据的进程尽量靠近数据本身所在的物理机器上。这样可以尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。同时为了加快实时查询速度,在查询过程中不会有写磁盘操作,所有的中间计算结果都会保持在内存之中。
附图说明
图1为分布式实时查询系统仅包含单线程数据操作节点的实时查询流程图。
图2为采用实时查询云服务器集群执行的实时查询流程图。
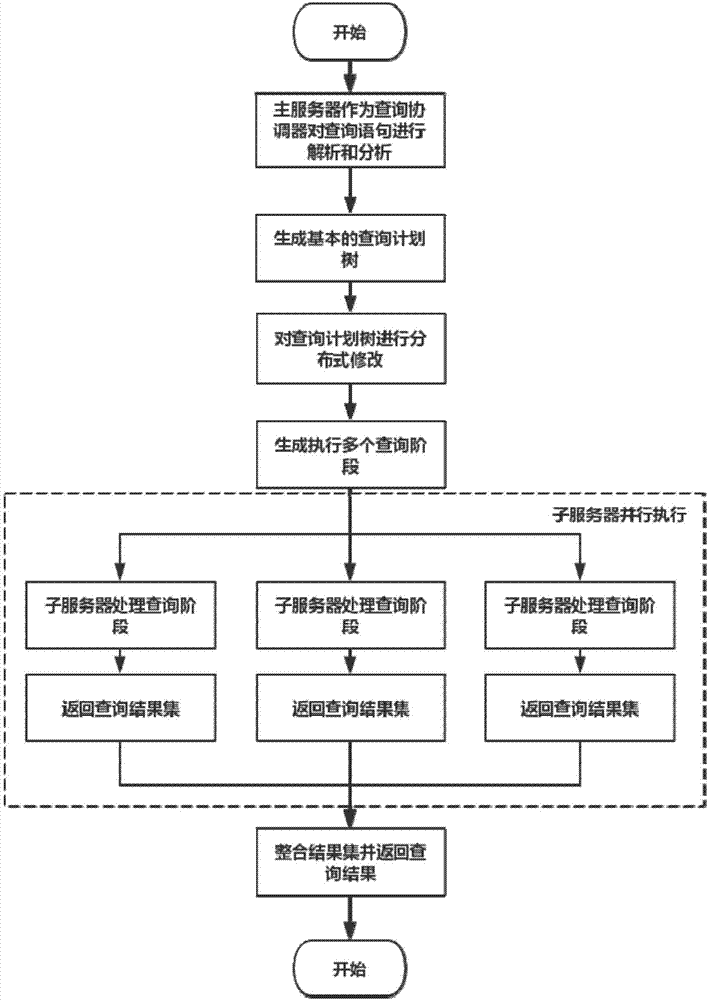
图3为大数据分布式实时查询方法的流程图。
图4为查询计划树样例示意图。
图5为查询计划树分布式划分为多个查询计划的样例示意图。
图6为大数据分布式实时查询系统网络图。
图7为用卡行为分析综合业务平台总体方案示意图。
具体实施方式
下面结合具体实施例对本发明作进一步说明。
本实施例所提供的大数据分布式实时查询方法,首先,将通过sqlapp和odbc/jdbc得到的查询语句和查询脚本文件进行解析和分析,如果是查询脚本文件则将其分割为多个查询语句分别进行处理。对于单个查询语句则通过关键字进行划分,如limit、groupby、joinon等。随后查询协调器将划分的各个部分用不同的节点表示不同的操作,然后根据节点的执行顺序生成基本的查询计划树,如图4所示。查询计划树的根节点是用于汇聚结果并返回,而查询计划树的叶子节点一般是scan操作,用于获取相关表数据。
对于复杂度低的查询计划树,主服务器将为查询计划树分配一个或多个线程进行处理,分配了多个线程的节点成为并行查询计划树,处理并行查询计划树即启动多个线程同时工作。如图1所示,仅包含单线程的查询计划树将是单方向进行处理。主服务器对叶子节点进行相关表数据获取,然后返回到上级子节点进行joinon、groupby等其他操作。最后将结果返回到查询计划树的根节点,查询协调器得到查询计划树根节点的查询结果并返回给数据可视化模块和联机事务处理模块进行下一步处理。
对于复杂度比较高的查询计划树,可选择以分布式集群的方式执行。集群由云平台上搭建的分布式实时查询服务器组成,包括一台主服务器(master)和多台子服务器(slave)。系统会对基本的查询计划树进行分布式修改,groupby&localagg之下(包括自身)的子节点都可以在各个子服务器上的查询组件上分布式执行,而之上的只能在查询协调器上处理。因此将查询计划树划分成多个查询阶段,如图5所示,并且每个查询阶段将会被分配到相应的子服务器的查询组件上进行处理。在每个查询组件都处理完得到相应查询结果集后,都会汇聚到查询协调器进行处理,包括对相关节点数据进行aggregation以及进行orderby和limit处理,得到最终的结果并返回,具体的流程如图2所示。
上述大数据分布式实时查询方法的处理流程如图3所示,具体步骤如下:
1)云平台为云服务器分配所需资源,并初始化实时查询云服务器集群;
2)云平台获取主服务器并作为查询协调器进行工作,查询协调器负责获取查询语句和查询脚本文件并进行解析和分析并决定哪个查询组件进行哪个查询;
3)云服务器通过sqlapp和odbc/jdbc获取查询语句和查询脚本文件并发送给查询协调器处理,查询协调器对查询语句和查询脚本文件进行解析和分析;
4)查询协调器根据对查询语句的解析分析结果生成基本的查询计划树。查询计划树包含多个节点,不同的操作对于不同的节点,根节点为返回最终结果,叶子节点为scan操作,分别获取相关表数据;
5)云服务器对生成的查询计划树按以下步骤执行:
5.1)云服务器获取当前查询计划树,根据元数据获取查询节点名称以及查询计划树的复杂程度;判断是否并行执行查询计划树,若不是,执行步骤5.2),若是,执行步骤5.3);
5.2)主服务器处理查询计划树,执行整个查询计划并将最终的查询结果返回给查询协调器,执行步骤5.4);
5.3)查询协调器对基本的查询计划树进行分布式修改,划分成多个查询阶段。同时查询协调器根据分布式查询计划树决定哪些子服务器执行查询阶段,然后将各个查询阶段分配到对应的子服务器的查询组件并行的执行查询操作,最后各个查询组件将各自的结果集返回给查询协调器,查询协调器整合结果集并得到最终查询结果。执行步骤5.4);
5.4)判断有无后续查询操作,若有,则执行步骤5.1)。
基于上述的大数据分布式实时查询方法进行结构设计,本实施例提供的大数据分布式实时查询系统,包括查询解析模块、查询计划树模块、查询阶段模块和结果整合模块。
查询解析模块,负责对查询语句以及查询脚本文件的解析和分析。所述查询语句的解析和分析是对单独的查询语句根据关键字进行划分,然后分析其组成部分。对于查询脚本文件先将其分割成多个独立的查询语句然后对单个查询语句进行解析和分析。
查询计划树模块,用于对查询解析模块中分析出来的各个组成部分用不同的节点表示不同的操作,然后根据节点的执行顺序生成基本的查询计划树。计划树的根节点用于汇聚结果返回给用户,计划树的叶子节点一般是scan操作。从叶子节点到根节点需经过多个节点的操作,包括joinon、groupby、orderby以及limit等。
查询阶段模块,用于对上述生成的查询计划树进行分布式修改,将整个查询计划树划分成多个查询阶段,并将各个查询阶段分配给不同的子服务器进行查询操作,子服务器通过对各自的查询阶段进行查询将得到各自的查询结果集,并将结果集返回给相关的查询组件进行下一步处理。
结果整合模块,用于对各个查询组件得到的查询结果集进行汇总,并整合处理为最终的结果,同时,将结果返回给大数据可视化系统进行查询结果的可视化以及返回给联机分析处理系统进行后续的联机分析处理。该模块还包含有nosql缓存单元,该单元将查询得到的结果写入nosql缓存数据库中,在有效期内对重复查询可直接从nosql缓存数据库中直接返回查询结果不需要重复进行查询。
为了测试本发明的分布式实时查询方式和系统的应用效果,我们将这一技术应用到一个用卡行为分析综合业务平台上。用卡行为分析综合业务平台通过对用户用卡行为进行分析,输出统计报表,对关键信息进行分析和趋势预测,辅助相关部门为管理和应用优化提供决策依据。用卡行为是指持卡人使用卡做了某项业务操作。该平台主要包括四个子系统:预处理系统、分布式实时查询系统、联机分析处理系统、数据可视化系统,如图7所示。
其中分布式实时查询系统如图7中a区域所示。分布式实时查询系统的网络图如图6所示,系统获取查询语句和查询脚本文件后进行查询语句的解析和分析,然后生成基本的查询计划树并对其进行分布式修改划分成多个查询阶段。之后对于每个查询阶段利用nosql高速缓存的特性,如果nosql缓冲区中以及存在查询结果就直接返回nosql中的查询结果。若没有就将查询阶段分配到各个子服务器的查询组件中进行查询,最后将查询结果保持到nosql缓冲区中并返回给查询协调器整合成最终结果,并返回查询结果给联机分析处理系统和数据可视化系统进行下一步操作。同时nosql缓冲区还能为公共服务平台的联机分析处理系统提供数据读缓存,进一步提升平台分析处理性能。
以上所述实施例只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!