自动特征分析、比较和异常检测的方法与流程
本申请是申请日为2013年11月11日,申请号为201380058287.7,发明名称为“自动特征分析、比较和异常检测的方法(原发明名称为:自动特征分析、比较和异常检测)”的申请的分案申请。相关申请的交叉引用本申请要求2012年11月9日递交的美国临时专利申请号为61/724,813的优先权,其公开内容通过引用以其整体并入本文。利益声明在政府的支持下根据陆军研究办公室(aro)授权的资助w81xwh-09-1-0266做出了本发明。政府对本发明具有一定的权利。本公开内容涉及自动数据分析。更具体地,其涉及用于自动特征分析、比较和异常检测的系统、设备和方法。
背景技术:
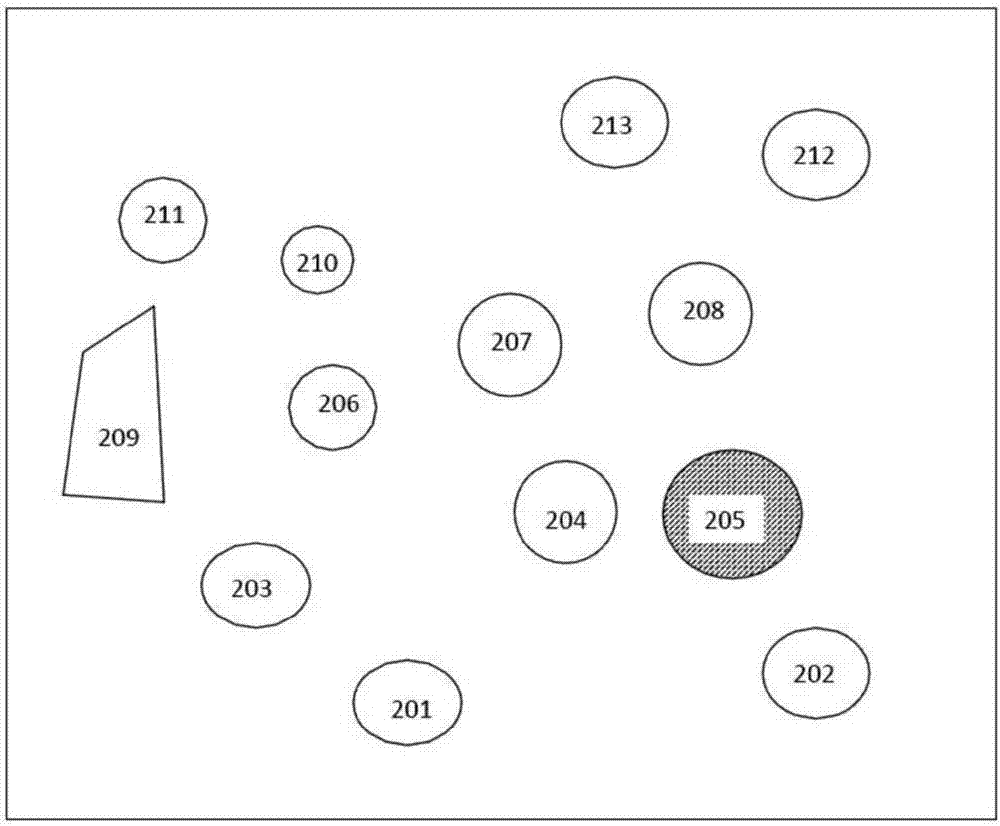
:用于从一组数据提取特征的类似技术可适用于不同组的数据。例如,地质调查可收集关于地球或火星的区域数据。收集的数据可包括可视化的图像、x射线图像、质谱分析、化学样品,等等。某些可视化特征可说明某些矿物的存在,而x射线图像或超光谱图像可给出该矿物存在的不同可能性。在这种情况下,人为干预通常可能是必要的,以确定每组数据(诸如可视化图像相对x射线图像)的相对重要性和可靠性。技术实现要素:在本公开的第一方面中,描述了计算机实现方法,计算机实现方法包括:提供感测和分析设备,该感测和分析设备包括配置成检测描述多个物理对象的多个物理特征的多个传感器;基于多个物理特征,由感测和分析设备产生表示多个对象的多个特征向量,其中多个特征向量包括描述多个物理特征的多个分量,其中多个分量的每个分量具有一个数值范围,其中多个物理特征中的每个物理特征由在每个特征向量内的至少一个分量表示;由感测和分析设备将每个分量的数值范围转换为0到1之间的范围,其中所述转换是通过以下公式执行的:其中f1ij是第i个对象和第j个特征分量的归一化值,origfij是第i个对象的第j个原特征分量值,minfj和maxfj是第j个特征分量的最小值和最大值,从而获得第一多个归一化的特征向量,其包括第一多个归一化分量,且还包括关于第一多个归一化特征向量的每个第一归一化特征向量的每个物理特征的分量的总数;对于第一多个特征向量的每个第一归一化特征向量,由感测和分析设备将每个第一归一化特征向量的每个物理特征的多个归一化分量除以第一归一化特征向量的每个物理特征的分量的总数,从而获得第二多个归一化特征向量;由感测和分析设备通过以下公式对第二多个归一化特征向量进行归一化:其中f2ij是第二多个归一化特征向量的特征向量的分量,且f3ij是第三多个归一化特征向量的每个特征向量的合成分量;由感测和分析设备对第三多个归一化特征向量进行聚类,从而获得多个聚类的归一化特征向量;由感测和分析设备将主要分量分析应用于多个聚类的归一化特征向量,从而获得距离标志值和第一评估的多个归一化特征值;由感测和分析设备基于阈值,通过对多个聚类的归一化特征向量的每个特征向量进行计数来计算数量标志值,从而获得第二评估的多个归一化特征向量;基于第一评估的多个归一化特征向量和第二评估的多个归一化特征向量,由感测和分析设备分析多个物理对象。本申请还涉及以下内容:1)一种计算机实施的方法,包括:提供感测和分析设备,所述感测和分析设备包括配置成检测描述多个物理对象的多个物理特征的多个传感器;通过所述感测和分析设备,基于所述多个物理特征产生表示多个对象的多个特征向量,其中,所述多个特征向量包括描述所述多个物理特征的多个分量,其中,所述多个分量的每个分量具有数值范围,其中,所述多个物理特征的每个物理特征由每个特征向量中的至少一个分量表示;通过所述感测和分析设备,将每个分量的所述数值范围转换至0和1之间的范围,其中,所述转换通过以下公式执行其中,f1ij是第i个对象和第j个特征分量的归一化的值,origfij是第i个对象的第j个原特征分量值,minfj和maxfj是第j个特征分量的最小值和最大值,从而获得第一多个归一化特征向量,其包括第一多个归一化分量,且还包括所述第一多个归一化特征向量的每个第一归一化特征向量的每个物理特征的全部数量的分量;对于所述第一多个特征向量的每个第一归一化特征向量,由所述感测和分析设备将每个第一归一化特征向量的每个物理特征的所述多个归一化分量除以所述第一归一化特征向量的每个物理特征的分量的总数,从而获得第二多个归一化特征向量;由所述感测和分析设备通过以下公式归一化所述第二多个归一化特征向量:其中,f2ij是所述第二多个归一化特征向量的特征向量的分量,且f3ij是第三多个归一化特征向量的每个特征向量的合成分量;通过所述感测和分析设备,聚类所述第三多个归一化特征向量,从而获得多个聚类的归一化特征向量;通过所述感测和分析设备将主分量分析应用到所述多个聚类的归一化特征向量,从而获得距离标志值和第一评估的多个归一化特征向量;通过所述感测和分析设备,基于阈值通过计数所述多个聚类的归一化特征向量的每个特征向量计算数量标志值,从而获得第二评估的多个归一化特征向量;通过所述感测和分析设备基于所述第一评估的多个归一化特征向量或所述第二评估的多个归一化特征向量分析所述多个物理对象。2)根据1)所述的计算机实施的方法,其中,所述聚类包括:通过所述感测和分析设备定义第一参数t1和第二参数t2,其中,所述第二参数大于所述第一参数;通过所述感测和分析设备计算聚类cj的聚类中心cj,其中,j是第一计数参数;通过所述感测和分析设备计算所述第三多个归一化特征向量的每个特征向量和所述聚类中心cj之间的距离d(f3i,cj),其中,每个特征向量称为f3i,且其中,i是第二计数参数;通过所述感测和分析设备基于所述第一参数t1和所述第二参数t2分配所述第三多个归一化特征向量的每个特征向量f3i到所述聚类cj,其中,所述分配包括迭代步骤a)-c):a)如果所述距离d(f3i,cj)小于所述第一参数t1,则所述特征向量f3i被分配到具有所述聚类中心cj的聚类cj;b)如果所述距离d(f3i,cj)大于所述第二参数t2,则所述特征向量f3i不被分配到具有所述聚类中心cj的所述聚类cj,增加j且所述特征向量f3i被分配到具有所述聚类中心cj的所述聚类cj;c)如果所述距离d(f3i,cj)大于所述第一参数t1,但小于所述第二参数t2,则推后所述分配;其中,一旦达到所期望的条件,就停止所述迭代,且聚类每个特征向量f3i,从而获得多个聚类的归一化特征向量。3)根据1)所述的计算机实施的方法,其中,所述聚类采用有序聚类、k均值聚类或水平集分析聚类。4)根据1)-3)中任一项所述的计算机实施的方法,其中,所述多个物理特征包括:颜色;反照率;形状;程度;倾斜度;紧密度;大小;材质;多光谱数据;超光谱数据;光谱数据;生物污染浓度;化学污染浓度;放射性污染。5)根据1)-4)中任一项所述的计算机实施的方法,其中,所述分析用于感兴趣区域的划分或划定;异常检测;自主交通工具控制;或勘探设备的指导。6)根据1)-5)中任一项所述的计算机实施的方法,其中,所述分析用于地质、采矿、资源分配、或侦察。7)根据1)-3)中任一项所述的计算机实施的方法,其中,所述分析用于医学诊断并且所述多个物理特征包括:患者特定数据;血液检查结果;尿液或粪便检查结果;x射线、ct、mri、fmri、或超声图像;多光谱数据;超光谱数据;脉冲;心率;眼压;颅内压;血压;肺容积。8)根据1)-3)中任一项所述的计算机实施的方法,其中,所述分析用于金融市场并且所述多个物理特征包括数据线上感测的电信号,其中,所述电信号描述了数据,所述数据包括:股票价值;开盘价;收盘价;整个交易期间的出价;黄金价格;股票指数;交易量。9)根据1)-3)中任一项所述的计算机实施的方法,其中,所述分析用于视野,并且所述多个物理特征包括:盲区周界、圆齿、不可见的测试位置的绝对数量、受损视野的面积、绝对视觉山体积损失、损失的面积等级、保存的面积等级、损失面积等级的倒数、保存面积等级的倒数。10)根据1)-9)中任一项所述的计算机实施的方法,其中,minfj和maxfj由用户定义。11)根据2)所述的计算机实施的方法,其中,所述距离是欧几里得距离。12)根据1)-11)中任一项所述的计算机实施的方法,还包括通过所述感测和分析设备基于时变分析所述多个物理对象。附图说明并入本说明书中并构成本说明书的一部分的附图示出了本公开内容的一个或多个实施例,并与示例性实施例的描述一起,用于解释本公开内容的原理和实现。图1示出了agfa的一般工作流程。图2示出了作为聚类的示意性实例的一批几何形状。图3示出了示例性感测和分析设备。图4描述了用于实现本公开内容的实施例的目标硬件的示例性实施例。具体实施方式本公开内容涉及自动数据分析,其可应用数据聚合和提取来自各种应用领域的特征。用于从一组数据提取特征的类似技术可适用于不同组的数据。例如,地质调查可收集关于地球或火星的区域数据。收集的数据可包括可视化的图像、x射线图像、质谱分析、化学样品,等等。在本公开内容中,描述方法以在特征空间中聚合这些数据,定义描述它们的数学实体,从数据提取特征,并输出得到的分析。例如,某些可视化特征可说明某些矿物的存在,而x射线图像或超光谱图像可给出该矿物存在的不同可能性。在这种情况下,人为干预通常可能是必要的,以确定每组数据(诸如可视化图像相对x射线图像)的相对重要性和可靠性。在本公开内容中,数学实体(即特征向量)被用于以允许自动比较分析的格式(特征向量)来表达包含在不同组的数据(例如,可视化图像和x射线图像)中的信息。本公开内容的自动化系统、设备或方法可因此执行不同组的数据的特征的自动化分析。相似的方法可用于其它应用,例如医疗诊断、金融系统和军事侦察。因此,这样的方法、设备或系统可称为自动全局特征分析器(agfa)。对于每个应用,agfa可提取和递送组成特征向量的特征。一旦产生特征向量,则agfa框架可运行。因此,agfa可聚类数据,并可基于特征空间找到异常。换句话说,数据可被在特征空间中转换并且然后可以被在该空间中分析。通过该转换,数据的自动分析是可能的,而与数据的来源无关。此外,agfa也可允许对象基于其各自的特征向量,彼此相互比较。在一些实施例中,也可通过分析在不同时间的特征向量之间的差异进行时变分析。例如,相同的特征向量可在时间1和时间2与其自身相比较。图1示出了agfa(105)如何可以适用于特征空间(110)中的各种应用,并且可以针对每个应用(110)给出输出(115)。例如,关于地质、采矿、资源分配、和(军事)侦察的应用,特征空间将包含由特定特征组成的特征向量。在一些实施例中,待包括在特征向量中的一系列特征可包括:颜色;反照率(亮度);分割对象的圆周的椭圆拟合,得到半长轴和半短轴,其比率可以是对象有多圆的量度;程度;倾斜度(angularity);紧密度;大小;用于质地评估的伽柏滤波器;多光谱数据;超光谱数据;光谱数据;生物污染浓度;化学污染浓度;放射性污染。对以上特征应用agfa之后,一些可能的结果可包括:感兴趣区域的划分/划定;异常检测;自主交通工具控制;勘探设备的指导。在一些实施例中,本公开内容的方法可适用于小行星开采。作为另一个实例,用于医学诊断的,可能的特征可包括:病人的特定数据,诸如:年龄、身高、体重、性别;血液检查结果;尿液/粪便检查结果;x射线、ct、mri、fmri、超声波的图像/结果;多光谱数据;超光谱数据;脉冲;心率;眼压;颅内压;血压;肺活量。对以上特征应用agfa之后,一些可能的结果可包括:医疗诊断;手术(如腹腔镜手术)设备的指导;用于肿瘤治疗的感兴趣区域的划分/划定;异常检测。作为另一个实例,关于金融市场的,可能的特征可包括:股票价值;开盘价;收盘价;整个交易期间的出价;黄金价格;股票指数(道琼斯、标普500等);交易量(例如,股票的交易量)。对以上特征应用agfa之后,一些可能的结果可包括:买入/持有/卖出的决定;趋势的异常检测。agfa应用的另一个实例是视野。在某些情况下,在人眼中的视野缺损的医疗诊断可大规模地进行(例如,全世界的数千到数百万人),或其可仅远程地进行,例如,在地球上偏远地区、或对于在到火星的空间任务的宇航员的情况、或对于居住在月球上的人类。在这样的情况下,用于视野缺损的检测的自动化系统可以是有利的。在这样的情况下,在没有临床专家时,根据下列数值方法,集成的自动特征描述系统可分析3d计算机化的阈值阿姆斯勒网格(3d-ctag)视野数据,并客观地确定和特征化存在的视野缺损(例如,盲区,如以缺少的视觉面积的形式):(1)视野数据转换,包括视野损失的面积和体积,丢失和保存的面积等级,以及斜率分布;和(2)盲区数据转换,包括盲区周界/圆齿(scallopedness)和盲区中心位置。如对于本领域的技术人员已知的是,阿姆斯勒测试是视野测试。agfa框架还可同样适用于其它视野测试数据,例如,适用于汉弗里(humphrey)视野分析器。视野数据转换每对比度水平视野面积损失计算可系统地评估原始3d-ctag数据,首先针对在数据中呈现的差异对比度敏感度水平的数量n,然后针对平方度的数量(例如,网格点)中的面积(表示为ai,其中0%≤i≤100%代表百分比对比度水平)和在每个对比度水平的视野损失的百分比百分比和面积因此记录了视野损失,其为对比度敏感度的函数,带有指示在呈现的最低对比度的完好视力的最高水平(100)。计算损失和保存的面积等级:通过将在最高测试对比度水平的盲区面积(ah)除以在最低测试对比度水平的盲区面积(a100)来计算损失面积等级(lag)。该面积比例然后乘以对比度敏感度比例因子其包括盲区深度(100-h)除以总深度(100),然后求平方值,以消除简并。完整的量度因此是通过将在最低测试对比度水平的保留的视野面积(a100)除以在最高测试对比度水平的保留的视野面积(ah),然后乘以如上所述的对比度敏感度比例因子来计算保留的面积等级(pag):如果对比度敏感度比例因子不被平方,则在这两项量度中(即lag和pag)可发生简并:例如,浅的盲区可具有这样的大的面积比率,以致于其lag和pag与具有充分小的面积比例的陡峭盲区的lag和pag相匹配。视野损失的体积计算:在对比度敏感度小于100的每个水平的数据点的数量乘以在每个数据点的对比度敏感度中的损失以确定视野损失的体积(∑{i}ai(100-i))。视野损失的体积然后除以全部测试的视野体积以确定损失的视野体积的百分比。视野损失的斜率等级(和斜率等级的直方图):例如,在水平(x)方向和垂直(y)方向上独立地确定斜率等级。斜率等级定义为对比度敏感度的损失(例如,100-i)除以其中发生损失的等级数(δx或δy):针对水平斜率等级是和针对垂直斜率等级是斜率直方图描述了在垂直方向或水平方向的斜率等级的分布。可用相同的方式处理从盲区的中心计算的径向斜率等级。盲区数据转换盲区中心对于每个测试的对比度敏感度水平的所有盲区数据点的x值和y值进行平均以获得在每个测试对比度敏感度水平的盲区中心的坐标。各自的中心与整个视野的数据点一起以3d方式绘制。随后对中心进行平均以获得平均中心。然后,计算从每个中心到平均中心的距离的平均距离和标准差。所有中心和每个盲区的平均中心然后被绘制到散点图上。盲区周界通过扫描关于点的盲区中的点列表,确定和记录在每个测试对比度敏感度水平的盲区周界点,所述点水平和/或垂直邻近于在各自水平的非盲区的点(即,具有大于当前水平的对比度敏感度水平的对比度敏感度水平)。圆齿圆齿测量评估了在关于曲率波动的每个对比度敏感度水平的盲区周界。在周界上的所有的点按顺序编号。从第一点(p=1)开始,计算沿着周界(p)的每个点和向下了用户定义的索引偏移(x)的周界点的列表(p+x)的点之间的欧几里得距离。对所有欧几里德距离进行平均,并随后显示为直方图。例如,使用两个不同的用户定义索引偏移对每个对比度敏感度水平执行该过程。尖峰的直方图(即,一个峰)说明带光滑周界(不是圆齿的)的盲区;朝向直方图左端的峰值说明更紧密弯曲的周界(即,小曲率半径),而朝向直方图右端的峰值说明带大曲率半径的周界。指数的一般集合也对视物变形症做出解释为了也对视物变形症的现象做出解释(即阿姆斯勒网格线的失真或起伏代替了那些网格线的缺失),可为在3d中的失真视觉(即,视物变形症)和视野缺损(即,盲区)的自动特征描述应用更普遍的算法的超集。可以使用描述了视野缺损的以下客观的特征指数:不可见测试位置的绝对#:不考虑对比度,不可见阿姆斯勒网格点的数值计数。不可见测试位置的相对#:不考虑对比度,不可见测试位置的绝对数量除以可用测试位置的全部数量的百分比表示。在xx%对比度的受损的视野面积:在给定的阿姆斯勒网格对比度标记为不可见的阿姆斯勒网格点的数量;在xx%对比度的受损的视野的相对面积:在给定的阿姆斯勒网格对比度标记为不可见的阿姆斯勒网格点的数量除以在给定的以[百分比]表示的阿姆斯勒网格对比度的可用测试位置的全部数量;绝对视觉山(hill-of-vision)“体积”损失:不可见的视野面积的总和乘以各自的以[deg2百分比]形式测量的测试对比度水平(以%形式)。相对视觉山“体积”损失:绝对体积损失除以以[百分比]形式测量的全部测试视觉山。损失面积等级(lag):在最高测试对比度水平的现有盲区面积除以在最低测试对比度水平的现有盲区面积,乘以以[百分比]对比度形式测量的实际盲区深度。保存面积等级(pag):在最低测试对比度水平的现有保存的视野面积除以在最高测试对比度水平的现有保存的视野面积,乘以以[百分比]对比度形式测量的实际盲区深度。损失面积等级倒数(ilag):在最低测试对比度水平的现有盲区面积除以在最高测试对比度水平的现有盲区面积,乘以以[百分比]对比度形式测量的实际盲区深度。保存面积等级倒数(ipag):在最高测试对比度水平的现有保存的视野面积除以在最低测试对比度水平的现有保存的视野面积,乘以以[百分比]对比度形式测量的实际盲区深度。上面的特征指数使被检者的视野的时变的定性分析和定量分析成为可能。存在以上列出的指数和本领域技术人员已知的其它指数的修改的实施例。在下文中,将使用视野测试的实例来描述agfa的不同特性。本领域技术人员将理解,虽然用特定的实例描述了agfa方法,但是可预期不同的应用。在一些实施例中,agfa可包括标志计算的步骤。标志计算步骤可包括特征向量归一化过程。特征向量归一化过程agfa可用于分析对象。例如,对象可以是视野数据集、图像中的岩石等。每个对象可具有分配的带全部特征分量值的特征(分量)向量。换句话说,特征向量可包括不同的分量,每个分量具有特定的值。特征分量值可具有不同的范围(按照最大值和最小值)。此外,特征分量可具有离散值或连续值。为了比较图像中的对象,有必要对它们进行归一化,以便使特征分量值独立于特征中的分量的范围和数量。换句话说,可给对象分配特征向量。特征向量可包括不同的分量。每个分量可具有不同于其它分量的一定的范围。为了比较特征向量,可以有利地归一化每个分量的范围以使比较特征向量成为可能。例如,基于两个特征,诸如颜色(r、g、b分量,每个具有整数值范围[0,255])和倾斜度(具有仅一个分量且实际值范围[0,1]),比较两个对象是不可能的。在该实例中,如相比于倾斜度特征,颜色特征具有三倍数量的分量。因此,如果基于分量的数量分配权重,则颜色特征将具有三倍于倾斜度特征的权重。此外,相比于倾斜度特征的[0,1],每个颜色分量将具有[0,255]的范围。因此,颜色分量可贡献比倾斜度高的255倍权重。为了克服这个问题,可应用三步归一化过程,以便归一化每个分量到[0,1]的范围。该归一化过程也使得该比较独立于特征中的分量的数量。在一些实施例中,在归一化的第一步中,被称为最小-最大归一化,使用下面公式将特征分量值转换为[0,1]的实际值范围内:其中,f1ij是第i个对象和第j个特征分量的最小-最大归一化值,origfij是第i个对象的第j个原特征分量值,minfj和maxfj是第j个特征分量的最小值和最大值。每个特征分量的最小值和最大值可以是关于模型内的特征的理论范围,例如,对于rgb颜色,范围为[0,255]。在其它实施例中,最小值和最大值可以是理论范围的特定子集范围,例如对于在对象的特定集合中的rgb颜色,最小值和最大值可以是理论范围的特定子集范围[20,120],其中不存在低于20或高于120的值。在又一些其它实施例中,最小值和最大值可以是用户定义的。在归一化的第二步中,其也可被称为特征维度归一化,每个特征分量值可通过以下公式除以在该特征中分量的数量:其中f2ij是第i个对象和第j个特征分量的特征维度归一化值,且nj是第j个特征的维度数量。在归一化的第三步中,其也被称为绝对归一化,应用下面的公式:上述三个归一化步骤确保特征值在实际值范围[0,1]内,并独立于分量的数量。这确保了每个特征分量值在对象的特征分析中发挥相同作用,例如,以确定对象是否是异常的。在特征向量归一化过程之后,标志计算步骤可包括有序聚类。有序聚类在一些实施例中,在先前步骤中获得的特征分量向量可表征图像中的对象。针对确定一个对象或多个对象是否异常的下一个步骤是将对象分类到不同的组中。在一个实施例中,可应用有序聚类方法,其实时将输入的向量分组到自然数数目的聚类中。这种方法优于其它聚类方法(如k-均值聚类)的可能的优点是不需要提供向量将被分组成的聚类的数量。该方法不仅对向量进行聚类,而且确定聚类的自然数数目。存在可使用的其它(监督或无监督)聚类方法,例如水平集合分析。这种算法自动根据数据本身确定聚类的自然数数目,并为本领域技术人员所熟知。如本领域技术人员所熟知的,基本有序聚类方法包括单个阈值,具有与聚类中心的距离低于该阈值的向量被分组到特定聚类中,基本上一遍(onepass)聚类所有向量。在一些实施例中,本公开内容中实现的有序聚类方法不同于所述基本方法,其实质在于,存在两个阈值,并且聚类所有向量的遍数可多于一遍。在有序聚类的基本形式中,第一输入向量被分类成第一聚类,且也成为它的中心。如果向量到特定聚类中心之间的距离低于预先定义的阈值,则下一个输入向量被分类到现有聚类中的一个,且如果向量到特定聚类中心之间的距离不低于预先定义的阈值,则向量被分类到新的聚类。本方法的可能的缺点是聚类的构造和聚类的成员取决于向量在其中到达的顺序,因为所有的向量在一遍中被聚类。另一个可能的缺点是,阈值的选择影响结果,即,改变阈值产生不同数量的聚类或带不同成员的相同数量的聚类。在本公开内容的一些实施例中,应用不同的方法,当计算向量和聚类中心之间的距离时其考虑欧几里得距离。其构成了标准有序聚类方法的改进版本。在本公开内容中,该改进方法可被称为确定性有序聚类。在确定性有序聚类中,选择两个阈值t1和t2(t2>t1),使得如果向量f3i和最近的聚类中心cj之间的欧几里德距离d(f3i,cj)低于t1,则向量属于相应的聚类。如果d(f3i,cj)高于t2,则向量f3i不属于聚类cj。然而,如果t1<d(f3i,cj)<t2,则向量f3i不一定属于cj,并推迟对其分类。两个阈值的引入克服了选择只有一个最能反映该数据的阈值的值的难度。此外,在不确定情况下推迟向量的分类导致了多遍的情况,并且克服了由于输入数据或向量的顺序引起的可能的缺点。例如,在1989年的patternrecognition的22:449-53中的trahaniasp等人的anefficientsequentialclusteringmethod中描述了确定性有序聚类,其公开内容通过引用以其整体并入本文。在其它实施例中,也可使用k均值聚类,然而其与有序聚类不同,要求事先提供聚类的数量。有序聚类之后,标志计算步骤可包括主分量分析。主分量分析在上一部分中解释的特征分量向量的聚类可根据在图像和数据集中检测的其它对象来提供关于处于异常的任何对象的信息。该异常可以是特征中的任何一个特征或一组特征或特征的组合(例如,“指纹”)。然而,该方法可不必能够确定异常是否对进一步研究的兴趣是真实的。图2示出了作为聚类的示意性实例的几何形状的集合。在图2中,每个几何形状代表一个对象。在图2中,对象(201、202、203、204、206、207、208、210、211、212、213)由于它们具有相似的形状所以可聚类在一起,而对象号(205)是例外,其具有与其它对象(201、202、203、204、206、207、208、210、211、212、213)相似的形状,但具有不同的图案或纹理,且对象号(209)也是例外,其具有不同于其它对象(201、202、203、204、206、207、208、210、211、212、213)的形状。因此,两个对象(205、209)不应与剩余的对象(201、202、203、204、206、207、208、210、211、212、213)聚类。两个对象(205、209)是异常的,并应聚类到其自身。根据对图2的人类视觉检查,可能理解对象(205、209)具有不同的形状或图案或纹理。然而,就其意义而言,没有人类视觉检查的自动聚类方法,不指定什么程度的异常为“真”异常。换句话说,对象(205)的图案或纹理异常或对象(209)的形状异常是否对于进一步研究具有任何真实意义,且如果具有任何真实意义,到什么程度。因此,异常的意义不能脱离聚类步骤单独量化。可通过主分量分析步骤执行异常意义的这种量化。在其它实例中,可存在其它差异,诸如颜色而不是图案或纹理。主分量分析(pca)可定义为正交线性变换,其将数据变换到新的坐标系,使得由该数据的任何投影的最大方差位于第一坐标(称为第一主分量),第二最大方差在第二主分量上,等等。这种方法对于本领域技术人员是已知的,并且,例如在2002年的wileyonlinelibrary的jolliffei.t.的principalcomponentanalysis中进行了描述,其公开内容通过引用以其整体并入本文。主分量的数量不大于变量或向量的数量。目的在于确定每个聚类的第一主分量,其可表示用于在特征向量空间中沿着该分量或这些分量的方向的特征向量的组成分量或多个组成分量的最大方差。在图2中的对象的聚类在表1中详细说明。表1:使用确定性有序聚类获得的聚类和关于在图2中的对象的特征分量向量的对应成员。所用的阈值为t1=0.15和t2=0.17。聚类号属于聚类的对象号1201、202、203、204、206、207、208、210、211、212、21322053209在图2的对象的实例中,目的是确定每个聚类的第一主分量。特征分量值的数量n变为特征分量向量的维度。如果f是m×n的矩阵,其中m是在聚类中的特征分量向量的数量,且每个向量形成矩阵的一行,则用于评估主分量的典型方法是分解f的协方差矩阵以确定其特征值和特征向量。例如,在1992年的cambridgeuniversitypress的press等人的numericalrecipesinc中,可找到这个过程的实例,其公开内容通过引用以其整体并入本文。特征向量是沿着主分量的单位向量,且特征值是其对应的大小。使用以下公式,利用单值分解(singlevaluedecomposition)可确定特征向量和特征值:covf=u*d*v'其中covf是矩阵f的n×n的协方差矩阵,u是矩阵covf的特征向量的n×n的酉矩阵,d是具有n个对角线值为特征值的n×m的矩形对角矩阵,而v'是m×n的酉矩阵。最大特征值是聚类的第一主分量的大小,换句话说,最大特征值量化具有在该聚类内的向量的最大方差的方向。特征值是特征向量的长度,其中,特征向量给出了聚类的主分量的最大方差的方向。例如,表2给出了表1和图2的聚类的最大特征值。表2:使用表1中的确定性有序聚类确定的聚类中的每个聚类的最大特征值。为了确定两个聚类是否不相交,可在特征空间中进行聚类中心之间的欧几里德距离与每个聚类的最大特征值的总和的比较。如果欧几里得距离小于总和,则两个聚类重叠,如果欧几里得距离不小于总和,则这两个聚类在特征空间上是不相交的。在另一个实施例中,属于各个特征值的相应的特征向量可投影到两个聚类之间的各自距离向量上,以获得更准确的距离测量值。如果两个聚类是不相交的,即,该欧几里得距离小于最大特征值的总和,则很可能属于聚类之一的对象与属于其它聚类的对象关于它们的特征显著不同。如果聚类重叠,则没有异常。该性质可通过距离标志进行量化;如果聚类是不相交的,则距离标志可设置为红色(用数字表示,例如,值1),且如果聚类重叠,则距离标志可设置为绿色(用数字表示,例如,值0)。继续表1和2的实例,表3给出了表2的三个聚类之间的成对关系的距离标志值。从表3中可见,所有聚类各自不相交,因为它们距离标志具有值1。本领域技术人员将理解,不同的值可用于说明聚类是不相交的。例如,在一些实施例中,距离标志可设置为0以说明不相交的聚类,或在又一个实施例中,距离标志可取与重叠或分离的程度成比例的连续值(例如,0和1之间)。在一些实施例中,可采用不同类型的距离代替欧几里得距离。表3:使用表1中的确定性有序聚类确定的聚类对之间的距离标志。聚类号码聚类号码距离标志121131231聚类是否是异常的不一定由距离标志单独决定。可假定,具有较少数量的对象的聚类是异常的且该性质可由数量标志来表示。例如,如果在聚类中的对象的数量小于其它聚类中的对象的数量的10%(例如,用户定义的阈值),则数量标志可设置为红色(用数字表示,例如,值1),否则数量标志可设置为绿色(用数字表示,例如,值0)。继续表3的实例,该步骤的结果在表4中详细说明。从表4可见,聚类1和2的数量标志是1,聚类1和3的数量标志是1,且聚类2和3的数量标志是0。在其它实施例中,对于数量标志可使用不同的值。在一些实施例中,可使用不同的阈值。例如,该阈值可以是20%而不是10%,或甚至不同于10%或20%的另一个所选的值。在另一个实施例中,数量标志可取反映一个聚类和另一个聚类之间的聚类成员的数量的比例的连续值(例如,在0和1之间)。表4:使用表1中的确定性有序聚类确定的聚类对之间的数量标志。聚类号码聚类号码数量标志121131230可基于每个不同的聚类对之间的距离和相应聚类的最大特征值的总和设置该距离标志。在其它实施例中,可使用不同的标志。可基于各个聚类中的成员数量设置数量标志。在其它实施例中,可使用不同的标志。标志计算之后,特征向量的分析可应用于所期望的特定应用。例如,标志计算可应用于视野比较和时变分析。视野比较和时变分析为了视野分类目的,上述方法中得到的指数,可一起用于形成特征向量,其是特定检查结果(即,视野)的特征。其结果是,例如,用基于网页的综合视野测试和诊断系统评估的视野,可经由它们各自的特征向量相互比较(在特征向量的适当归一化后),并可检测到异常。本公开内容包括在按照上述方法(例如包括距离标志指数和数量标志指数)确定这些向量之后,允许特征向量进行比较的优势。可基于自动全局特征分析仪(agfa)由自动分类系统来执行视野之间的比较、以及一组视野(诸如随时间推移而获得的特定患者的一组视野)之间的异常检测。在视野数据分类的情况下,特征向量可包括本公开内容中上面列出的相对特征指数:不可见测试位置的相对#,相对于视觉山的体积损失、lag、ilag、pag、ipag。如与绝对特征指数相对,使用特征向量的相对特征指数的原因是得到的特征向量大部分独立于各自的视野检查规范,诸如测试的视野面积和呈现的对比度水平。另外,在不同的测试机器上用不同的检测参数设置进行的不同视野的比较可能成为有问题的。在其它应用中,特征指数可不同于所列出的用于视场比较的那些特征指数。例如,本公开内容中上述已列出的用于金融市场和其它应用的特征指数。对于视野比较的情况,特征向量可使被检者视野的时变的定性分析和定量分析两者成为可能。可通过计算下面每个被检者的不同3d-ctag检查结果之间的比可比量化特性来评估这些时变:重叠参数:定义为两个特征向量之间的范围从-1到+1的n维标量积,用-1表示两个视野彼此完全相反/不相似的情况,0表示两个视野彼此正交的情况,并用+1表示两个视野相同的情况,当然还包括在这些值之间的所有连续变化。重叠参数是两个特征向量之间的相似性的量度。海明距离(hammingdistance):定义为特征向量分量之间的平方差之和,除以特征向量的维度n。海明距离总是>=0,且是两个特征向量之间的相似性的量度。欧几里得距离:定义为特征向量分量之间的平方差之和的平方根。欧几里得距离总是>=0,且也是两个特征向量之间的相似性的量度。此外,除其它聚类技术外,agfa还可执行有序聚类以基于各自的特征向量将一个患者或几个患者的视野检查分组到相似的聚类中,并可随后基于聚类间的比较执行异常分析。异常被定义为特定的特征向量,或特定特征向量的分量(例如,不可见测试位置的相对#,相对于视觉山的体积损失、lag、ilag、pag、ipag),其与其它特征向量(或在其它特征向量中相同的分量)显著不同。结合重叠参数、海明距离和欧几里得距离,聚类和异常检测可提供视野分类和比较的手段。此外,由agfa提供的该工具集可允许通过分析代表在给定时间的各个视野的基本特征向量来评估随时间的推移(即,时变)的视野恶化或改善。特征向量也可用作到人工神经网络(诸如单层或多层感知器系统,以及用于初步诊断生成的霍普菲尔德吸引子网络)的输入。特别地,霍普菲尔德吸引子网络对在给定检查站/设备上被测试的各个视野面积和几何结构的适应是简单的,因为无需关于给定的检查站/设备的实际视野几何结构做出霍普菲尔德吸引子网络的神经元的空间排列假设。客观上推导的视野、盲区、以及视物变形特征数据可以:1、经由统计方法和人工神经网络(例如参见,如在2004年第49(13)期的physmedbiol的第2799-2809页的finkw的“neuralattractornetworkforapplicationinvisualfielddataclassification”中描述的视野分类神经网络的3d-ctag适应版本;其公开内容通过引用以其整体并入本文)概率预测疾病。2、使用来源于自主行星探索的分类方法,表示随着时间变化的患者视野中的定性和定量的时变二者(参见例如,自动全局特征分析器agfa(fink等人,2005;fink等人,2008);其公开内容通过引用以其整体并入本文)。同样地,成熟的综合视野测试和诊断系统能够:1、检测和诊断早期影响视觉性能的条件,允许治疗对策的及时应用;2、监测随着时间推移的条件的治疗性处理的效率和效能。在本公开内容中所描述的方法可以是通过硬件设备来实现的计算机。这种硬件设备可包括处理器和存储器,以及多个传感器。如本领域技术人员所理解的,传感器可包括多种不同的传感器。例如,摄像机传感器、放射性传感器、磁传感器、电传感器、化学传感器、红外传感器、光谱分析仪、质谱传感器、压力传感器、湿度传感器、血糖传感器、温度传感器、地震传感器、盐度传感器、速度传感器和加速度计、电压表、磁力计等。在一些实施例中,硬件设备可称为感测和分析设备。在一些实施例中,该设备可以是智能电话或平板电脑。图3示出了示例性感测和分析设备,包括处理器(305)、存储器(310)和多个传感器(320、325、330、335、340、345)。图4是用于实施图1和2的实施例的目标硬件(10)(例如,计算机系统)的示例性实施例。该目标硬件包括处理器(15)、内存条(20)、本地接口总线(35)和一个或多个输入/输出设备(40)。处理器可执行关于图1和2的实现的且如基于存储在存储器(20)中的一些可执行程序(30)由操作系统(25)提供的一个或多个指令。这些指令经由本地接口(35)被传送至处理器(15),并如由特定于本地接口和所述处理器(15)的某些数据接口协议制定。应注意的是,本地接口(35)是一些元件的符号表示,诸如一般针对在基于处理器的系统的多个元件之间提供地址、控制和/或数据连接的控制器、缓存(高速缓存)、驱动器、中继器和接收器。在一些实施例中,处理器(15)可装配有一些本地存储器(高速缓存),其中其可存储将被执行以增加一些执行速度的指令中的一些指令。通过处理器执行指令可能需要使用一些输入/输出设备(40),诸如从存储在硬盘上的文件的输入数据、从键盘输入命令、从触摸屏输入数据和/或命令、将数据输出到显示器、或将数据输出到usb闪存驱动器。在一些实施例中,操作系统(25)通过作为中心元件,来收集程序执行所需的各种数据和命令并提供这些数据和命令到微处理器来促进这些任务。在一些实施例中,虽然目标硬件设备(10)的基本架构将如在图4中所描述的保持不变,但可不存在操作系统,且所有任务在处理器(15)的直接控制下。在一些实施例中,可并行配置使用多个处理器以提高执行速度。在这种情况下,可以专门为并行执行定制可执行的程序。此外,在一些实施例中,处理器(15)可执行图1和图2的实施的一部分,且可使用放置在由目标硬件(10)经由本地接口(35)可访问的输入/输入位置的专门硬件/固件来实施某个其它部分。目标硬件(10)可包括多个可执行程序(30),其中每个都可独立地或以彼此组合的方式运行。在本公开内容中描述的方法和系统可在硬件、软件、固件或它们的任意组合中实施。描述为框、模块或部件的特征可一起(例如,在逻辑设备(诸如集成逻辑设备)中)或单独(例如,作为单独连接的逻辑设备)实施。本公开内容的方法的软件部分可包括计算机可读介质,其包括指令,当执行时其执行至少一部分所描述的方法。该计算机可读介质可包括,例如,随机存取存储器(ram)和/或只读存储器(rom)。该指令可由处理器(例如,数字信号处理器(dsp)、专用集成电路(asic)、现场可编程逻辑阵列(fpga)、图形处理单元(gpu)或通用gpu)执行。已经描述了本公开的一些实施例。然而,应理解的是,可做出各种修改而不脱离本公开内容的精神和范围。因此,其它实施例在所附权利要求的范围之内。提供以上所阐述的实例给本领域普通技术人员,作为如何制造和使用本公开内容的实施例的完整的公开和描述,且不旨在限制一个发明者/多个发明者视为其公开内容的范围。对于本领域技术人员是明显的以上描述的用于执行本文公开的方法和系统的模式的修改旨在处于所附权利要求的范围之内。在说明书中提到的所有专利和出版物表明本公开内容所属的
技术领域:
的技术人员的技术水平。在本公开内容中引用的所有参考通过引用并入到如同每个参考已经通过引用以其整体单独地并入的相同程度。应当理解的是,本公开内容并不限于特定的方法或系统,其当然可以变化。还应当理解的是,本文所用的术语仅用于描述特定实施例的目的,并不旨在进行限制。如在本说明书和所附权利要求中使用的,单数形式“一(a)”、“一个(an)”和“该(the)”包括复数的参照对象,除非内容另有明确说明。术语“多个”包括两个或多于两个参照对象,除非内容另有明确说明。除非另有定义,否则本文使用的所有技术和科学术语具有如本公开内容所属的
技术领域:
的一个普通技术人员通常理解的相同含义。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1