一种根据多数据源防欺诈的方法和系统与流程
本发明涉及大数据技术领域,尤其涉及一种根据多数据源防欺诈的方法和系统。
背景技术:
诚信是中华民族的传统的美德,但当下不诚信的人、不诚信的事出现的频率越来越高,已经对人们的生活造成了巨大的影响,因此公民诚信系统的建立显得迫在眉睫。
现有技术中,人民银行的征信系统对有业务来往的客户建立诚信系统,为其他银行提供信用参照。公安部对每个公民建立户籍系统并建立案底档案,教育部对每个受教育者建立教育档案,其他民间机构也对相应个体建立相关方面的档案资料。实际操作中,各大银行可以根据征信系统来提供借贷服务,铁道部可以通过户籍系统来实现实名制,公安局可以通过互联网来追捕逃犯,教育部可以通过学生档案来实现升学等等。
现有技术的缺点是只能针对采集的数据对个人目前某个方面状态进行评估,而不能对从整体上来评估一个人。还有现有技术在局部征信只能面对大企业或者行政机构,不能点对点的实现诚信的评估。
大数据技术是近些年新兴的科学技术,其逐渐应用于社会的各行各业。在大数据的框架下,有用的数据在大量的数据下被掩盖,只有将这些数据通过数据漂白、清洗,然后分类出有用的数据。通过对有用的数据进行分析评估,得出自己想要的分析结果。然而数据量如此之大,如何使用这些数据,使用其中有用的数据就成为当今一个重要的课题。
信息聚合是通过客户端软件或网络应用程序将诸如新闻头条、博客、播客等网络信息聚合到单一地点以方便用户浏览。web2.0环境下信息海量增长,尤其是用户自产生内容的发展,用户每天在各种微博、sns创造着庞大数量的内容,既多又杂。此外,政府组织和个人正把越来越多的数据信息放到网络上。另外,随着越来越多现实中的物体通过物联网技术和互联网连接,互联网即将迎来一次数据信息的大爆炸。如何过滤并重组这些数据信息使之最终变成个人化的信息,将是这些海量信息存在的价值所在。
目前,网络爬虫技术已广泛应用于信息聚合。例如,申请号为201210495699.4的中国发明专利申请,公开了一种网络爬虫,包括一内核以及一ajax抓取配置,该内核以及该ajax抓取配置均集成有htmlunit,该ajax抓取配置用于指定一网页的地址以及该网页中的待抓取的数据,该内核用于驱动搜索引擎,并基于该ajax抓取配置提取该待抓取的数据。该发明能够支持ajax的执行方式抓取网页页面的数据,并且支持异步请求的技术,可以使用javascript向服务器提出请求并处理响应,而且不会阻塞用户。
然而,目前仍然没有通过大量的云数据分析,对客户的信用度进行准确评价的方法,往往无法防止网络欺诈、电话欺诈等事件的发生。
技术实现要素:
为解决以上问题,本发明的目的是通过以下技术方案实现的。
本发明提出了一种根据多数据源防欺诈的方法,其包括:
步骤一,采集多维度信息数据;
步骤二,信息聚合整理,将所述多维度信息数据预处理为统一格式的预处理数据;
步骤三,将上述预处理数据代入高维动态协方差矩阵,计算信息匹配度;
步骤四,根据上述计算的结果判断用户行为。
优选的,如上所述的根据多数据源防欺诈的方法,步骤一中采用网络爬虫方法进行目标抓取。
优选的,如上所述的根据多数据源防欺诈的方法,所述网络爬虫方法包括如下步骤:
(一)、使用杜威十进分类法,在网页特征提取阶段,快速找出网页文本与锚文本关键词主题相近的关键词。
(二)、提取主题候选链接特征文本;
(三)、使用朴素贝叶斯文本分类器对候选链接主题边缘文本进行分类,获取主题相关网页;如果文本属于特定主题,那么相对应的候选链接以分类权值作为优先级值,以优先级的大小顺序插入爬行队列,爬虫优先访问分类值大的链接,如果文本不属于特定主题,则丢弃候选链接;
(四)、对相关网页的web链接信息用hits算法计算出其对应的权威度和中心度,综合锚文本、锚文本附近信息、反向网页、反向链接的兄弟链接、url链接,预判待爬取网页与主题的相关度。
优选的,如上所述的根据多数据源防欺诈的方法,所述提取主题候选链接特征文本包括如下步骤:
(1)对网页的锚文本和正文进行分词处理,去掉停用词,得到关键词;
(2)查找关键词的杜威分类号码;
(3)运用杜威十进制分类法的特性并结合二维坐标提取主题候选链接特征文本;把关键词分类号码的长度作为x轴,关键词分类号码作为y轴,将关键词对应的杜威十进分类号码在二维坐标中绘制相应的点。
(4)提取二维坐标中锚文本关键点以及锚文本周围的关键点对应的关键词作为主题候选链接特征文本。
优选的,如上所述的根据多数据源防欺诈的方法,所述信息聚合整理包括如下步骤:
(1)、基于opend服务访问相关网站信息;
(2)、根据网站提供的开放式api接口获取网站上的相关用户个性化数据;
(3)、对不同网站获取的用户个性化数据进行预处理;
(4)、基于模糊自适应信任度的值的信息聚合处理;
(5)、基于mash-up技术根据用户个性化需求进行页面聚合显示。
优选的,如上所述的根据多数据源防欺诈的方法,上述步骤(3)的预处理过程如下:对用户id进行识别,然后规划出用户的会话路径,采用浏览器本地缓存技术对路径完整性和正确性进行检测,得到完整的正确路径后,根据网站的拓扑结构进行事务分割,生成事务数据文件存储到事务数据库中;根据抽取的日志数据获取用户的频繁路径长度和深度,并且识别用户的最大前向访问路径集mfps,根据mfps得到频繁最大前向访问路径集f-mfps,再由f-mfps集合搜索得到用户的f-mfps访问路径的页面标签和资源集合。
优选的,如上所述的根据多数据源防欺诈的方法,所述信息匹配度为上述矩阵的正定或负定情况。
优选的,如上所述的根据多数据源防欺诈的方法,所述步骤四的具体方法为:若所述高维动态协方差矩阵为正定的,则认为用户正常行为,如果所述结果为非正定的,则认为所述用户行为有欺诈行为,采取相应的限制措施进行防范。
根据本发明的另一个方面,一种根据多数据源防欺诈的系统,包括顺序连接的如下模块:
数据采集模块,用于采集多维度信息数据;
信息聚合模块,用于信息聚合整理,将所述多维度信息数据预处理为统一格式的预处理数据;
匹配度计算模块,用于将上述预处理数据代入高维动态协方差矩阵,计算信息匹配度;
判断模块,用于根据上述计算的结果判断用户行为。
优选的,如上所述的根据多数据源防欺诈的系统,所述信息聚合模块包括顺序连接的如下单元:
访问单元,用于基于opend服务访问相关网站信息;
数据获取单元,用于根据网站提供的开放式api接口获取网站上的相关用户个性化数据;
预处理单元,用于对不同网站获取的用户个性化数据进行预处理;
信息聚合单元,用于基于模糊自适应信任度的值的信息聚合处理;
页面聚合显示单元,用于基于mash-up技术根据用户个性化需求进行页面聚合显示。
通过本发明可以从大量的数据提取有用数据来评价用户是否为合法用户,降低了被诈骗的可能性,从而保护用户利益,提高用户体验。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
附图1示出了根据本发明实施方式的根据多数据源防欺诈的方法流程图。
附图2示出了根据本发明实施方式的信息聚合整理的方法流程图。
附图3示出了根据本发明实施方式的根据多数据源防欺诈的系统模块图。
附图4示出了根据本发明实施方式的信息聚合模块的结构图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施方式。虽然附图中显示了本公开的示例性实施方式,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本发明的根据多数据源防欺诈,采用多维度信息认证,该方法包括采用网络爬虫进行目标抓取,通过高维动态协方差矩阵计算信息匹配度,实现防欺诈,其应用于诚信,征信,个人信息保护,投融资,大数据平台,为金融、通信运营商、婚恋交友、租车、物流、家政、招聘等行业提供根据多数据源防欺诈。
具体的,如图1所示,本发明提出了一种根据多数据源防欺诈的方法,其包括如下步骤:
步骤s101、采集多维度信息数据。
以上多个数据源包括多种数据来源。例如,公安系统、教育系统、征信系统、诚信系统、金融系统、投融资系统等等。由于所有的系统都涉及公民的姓名、身份证号等基本公民信息。通过这些基本公民信息,可以将所有这些的系统中产生的数据形成关联,从而形成本发明的多数据源的数据。
在本发明的优选实施例中,上述采集采用网络爬虫技术进行目标抓取。网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(generalpurposewebcrawler)、聚焦网络爬虫(focusedwebcrawler)、增量式网络爬虫(incrementalwebcrawler)、深层网络爬虫(deepwebcrawler)。实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
通用网络爬虫又称全网爬虫(scalablewebcrawler),爬行对象从一些种子url扩充到整个web,主要为门户站点搜索引擎和大型web服务提供商采集数据。由于商业原因,它们的技术细节很少公布出来。这类网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,但需要较长时间才能刷新一次页面。虽然存在一定缺陷,通用网络爬虫适用于为搜索引擎搜索广泛的主题,有较强的应用价值。
聚焦网络爬虫(focusedcrawler),又称主题网络爬虫(topicalcrawler),是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网络爬虫相比,增加了链接评价模块以及内容评价模块。聚焦爬虫爬行策略实现的关键是评价页面内容和链接的重要性,不同的方法计算出的重要性不同,由此导致链接的访问顺序也不同。
由于本发明面向特定的数据源,因此采用了主题网络爬虫算法。本发明把网页正文,锚文本、锚文本附近信息、反向网页、反向链接的兄弟链接、url链接结合起来,使用一种混合爬行策略。针对每步待抓取网页的特点,采用差异化的url预测方法来提高网页与主题的相关度。具体的,本发明采用了独特的主题网络爬虫算法,包括如下步骤:
(一)、使用杜威十进分类法,在网页特征提取阶段,快速找出网页文本与锚文本关键词主题相近的关键词。例如,通过可以迅速查找出包含用户姓名的网页和包含该姓名的锚文本。
(二)、提取主题候选链接特征文本。这个步骤的实现过程包括如下四个步骤:
(1)对网页的锚文本和正文进行分词处理,去掉停用词,得到关键词;
(2)查找关键词的杜威分类号码;
(3)运用杜威十进制分类法的特性并结合二维坐标提取主题候选链接特征文本。把关键词分类号码的长度作为x轴,关键词分类号码作为y轴,将关键词对应的杜威十进分类号码在二维坐标中绘制相应的点。
(4)提取二维坐标中锚文本关键点以及锚文本周围的关键点对应的关键词作为主题候选链接特征文本。
(三)、使用朴素贝叶斯文本分类器对候选链接主题边缘文本进行分类,获取主题相关网页。如果文本属于特定主题,那么相对应的候选链接以分类权值作为优先级值,以优先级的大小顺序插入爬行队列,爬虫优先访问分类值大的链接,如果文本不属于特定主题,则丢弃候选链接。例如如果文本属于用户姓名这个主题,就赋予它较高的优先级,但如果文本不属于用户姓名主题,就丢弃其中的候选链接。
(四)、对相关网页的web链接信息用hits算法计算出其对应的权威度(authority)和中心度(hub),综合锚文本、锚文本附近信息、反向网页、反向链接的兄弟链接、url链接,预判待爬取网页与主题的相关度。
例如,通过这个步骤,能够很准确的预判出待爬取的网页与用户姓名的相关度,有些网页虽然包含用户姓名,但相关度并不一定很高,也是可以摒弃的。
步骤s102、信息聚合整理,将所述多维度信息数据预处理为统一格式的预处理数据。由于本发明的数据源来自多个数据源系统,例如公安系统、教育系统、金融系统、身份证系统等等,由于每个系统中数据的格式是不统一的,因此,需要将其预处理为统一的格式,以利于后续的统一处理。
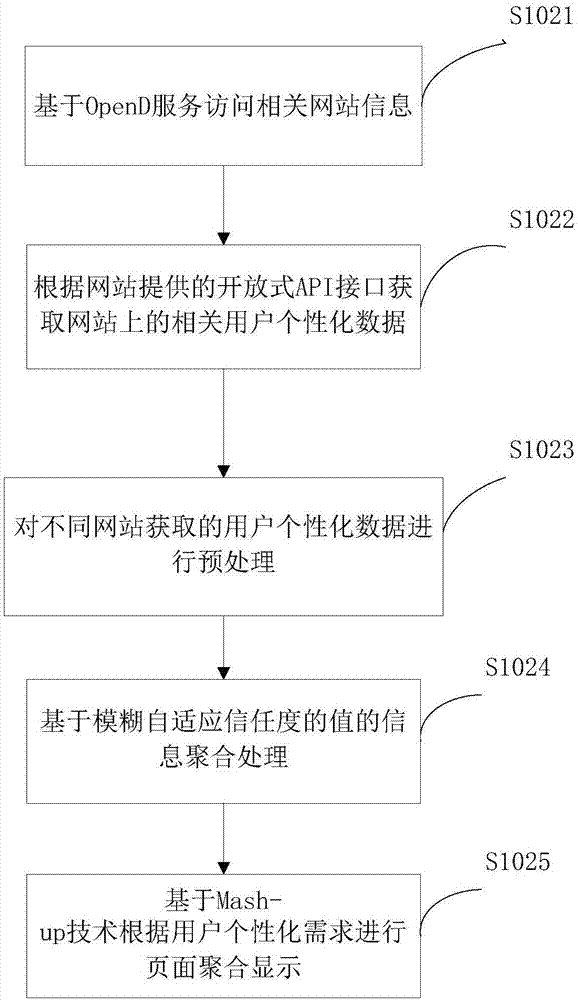
本发明采用了独特的信息聚合算法,如图2所示,包括如下步骤:
s1021、基于opend服务访问相关网站信息。
s1022、根据网站提供的开放式api接口获取网站上的相关用户个性化数据。获取用户的兴趣信息,主要从日志系统中访问相关的用户记录。
s1023、对不同网站获取的用户个性化数据进行预处理。这里,主要是对用户id进行识别,然后规划出用户的会话路径,采用浏览器本地缓存技术对路径完整性和正确性进行检测,得到完整的正确路径后,根据网站的拓扑结构进行事务分割,生成事务数据文件存储到事务数据库中。接着根据抽取的日志数据获取用户的频繁路径长度和深度,并且识别用户的最大前向访问路径集mfps,根据mfps得到频繁最大前向访问路径集f-mfps,再由f-mfps集合搜索得到用户的f-mfps访问路径的页面标签和资源集合。
s1024、基于模糊自适应信任度的值的信息聚合处理;根据不同站点的用户个性化数据访问集合,聚合生成新的用户个性化信息访问集合,也就是访问资源和标签集合,即用户需求。
s1025、基于mash-up技术根据用户个性化需求进行页面聚合显示。通过ajax技术,根据用户需求进行页面聚合显示,生成更加准确的推荐页面。通过最终的页面聚合显示,本发明将来自各个不同数据源系统的数据进行统一的聚合并展示,为下一步利用这些数据进行用户行为预测奠定基础。
所述统一格式的预处理数据,仅仅是格式的统一。数据内容并不相同,因为来自不同数据源的数据是不相同的。其中,所述预处理数据包括用户行为参数和形成所述用户行为的时间参数。从来自不同的数据源的数据提取相应的用户行为数据,使用不同的数值表示不同的用户行为,形成用户行为参数。
以网购活动为例,其与用户行为有关的数据可能包括:客户姓名、中英文全称、性别代码、国籍代码、民族代码、客户编号、开始日期、结束日期、产品代码、历史交易、产品合约编号、产品合约修饰符、产品合约名称、产品合约描述、生命周期状态编码、签约日期、终止日期、签约机构、产品合约对应的借记卡合约编号、账户关键字、机构编码、机构中英文名称、机构类别、总行机构编号、总行机构名称、一级行结构编号、一级行机构名称、二级行机构编号、二级行机构名称、支行编号、支行名称、开业日期、机构描述、详细地址、邮政编码等等。这些仅仅是举例说明,实际产生的数据要比这个大得多。所有以上的数据都会有一个时间相关的数据。
步骤s103、将上述预处理数据代入高维动态协方差矩阵,计算信息匹配度。
在本发明中,使用高维动态协方差矩阵:记n维随机向量x=(x1,x2,l,xn)t,若其每个分量的数学期望都存在,则称:
为该随机变量x的协方差矩阵,记为:var(x)。
其中,在本发明里,每个预处理数据均可以表示为一个随机变量x,将所述具有统一格式的预处理数据代入所述高维动态协方差矩阵,计算信息匹配度(即计算所述矩阵的正定或负定情况),计算结果中上述矩阵呈现正定或负定两种情形。
步骤104、根据上述计算的结果判断用户行为。
其具体包括:若所述高维动态协方差矩阵为正定的,则认为用户正常行为,如果所述结果为非正定的,则认为所述用户行为有欺诈行为,采取相应的限制措施进行防范。例如对用户提出告警提示,或者直接屏蔽上述被认定为欺诈的用户,或者将这类用户加入黑名单。
如图3所示,本发明还提供了一种根据多数据源的防欺诈系统100,其包括顺序连接的如下模块:
数据采集模块101,用于采集多维度信息数据;
信息聚合模块102,用于信息聚合整理,将所述多维度信息数据预处理为统一格式的预处理数据;
匹配度计算模块103,用于将上述预处理数据代入高维动态协方差矩阵,计算信息匹配度;
判断模块104,用于根据上述计算的结果判断用户行为。
其中所述信息聚合模块102包括顺序连接的如下单元:
访问单元1021,用于基于opend服务访问相关网站信息;
数据获取单元1022,用于根据网站提供的开放式api接口获取网站上的相关用户个性化数据;
预处理单元1023,用于对不同网站获取的用户个性化数据进行预处理;
信息聚合单元1024,用于基于模糊自适应信任度的值的信息聚合处理;
页面聚合显示单元1025,用于基于mash-up技术根据用户个性化需求进行页面聚合显示。
该防欺诈系统可以提供web单条、web批量、web页面、webservice、api、sdk等多种接入形式。
通过本发明可以从大量的数据提取有用数据来评价用户是否为合法用户,降低了被诈骗的可能性,从而保护用户利益,提高用户体验。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!